

Attention Is All You Need transformer开山之作论文精读 笔记
参考资料
1、https://www.bilibili.com/video/BV1pu411o7BE/?spm_id_from=333.337.search-card.all.click&vd_source=920f8a63e92d345556c1e229d6ce363f 李沐老师讲解transformer开山之作
2、https://www.bilibili.com/video/BV1kT4y1v7RH/?spm_id_from=pageDriver&vd_source=920f8a63e92d345556c1e229d6ce363f 注意力机制的超神讲解
传统的encoder和decoder架构,往往是输入一个n维的向量到encoder,encoder输出一个m维的输出y1,生成y2的时候,y1也作为输入,即过去的输出也会作为现在的输入。
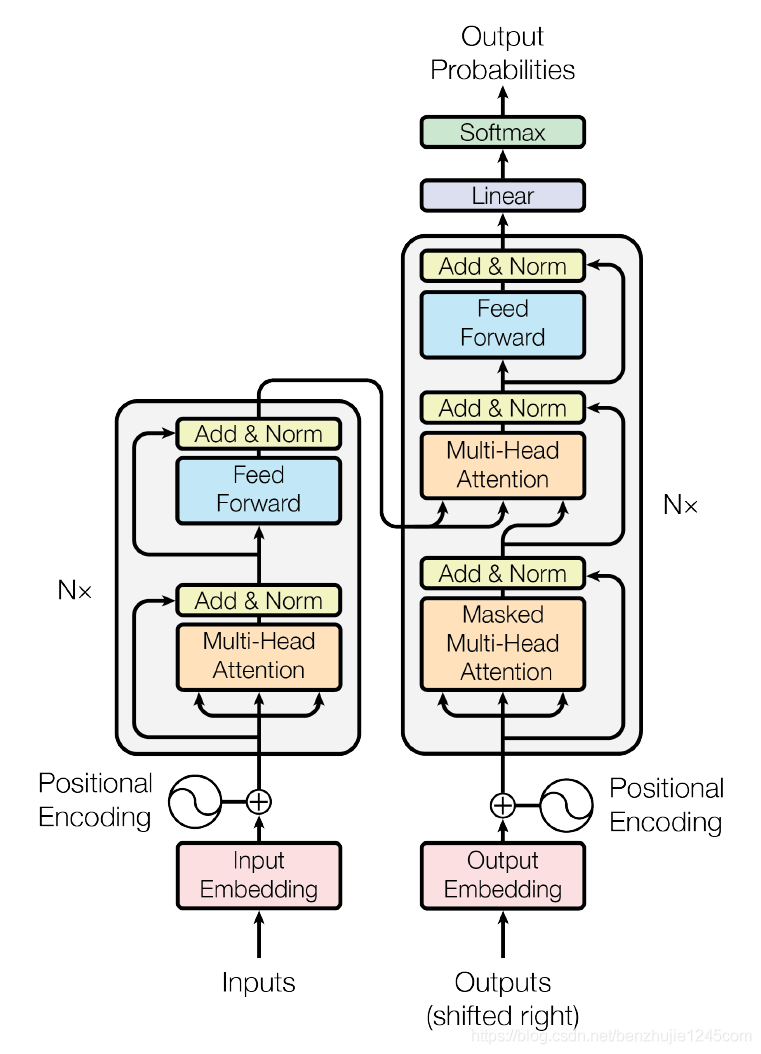
可以认为此图左侧的结构为编码器,右图为解码器。
相对于CNN等架构来说,transformer只需要调整两个参数,即encoder的N(层数,即为图中的Nx)和d(即为模型中的LayerNorm层的输出,因为有一个残差连接,需要保证输入和输出相加结果一致,所以固定了输出的维度)
batchNormalization和LayerNormalization的区别:
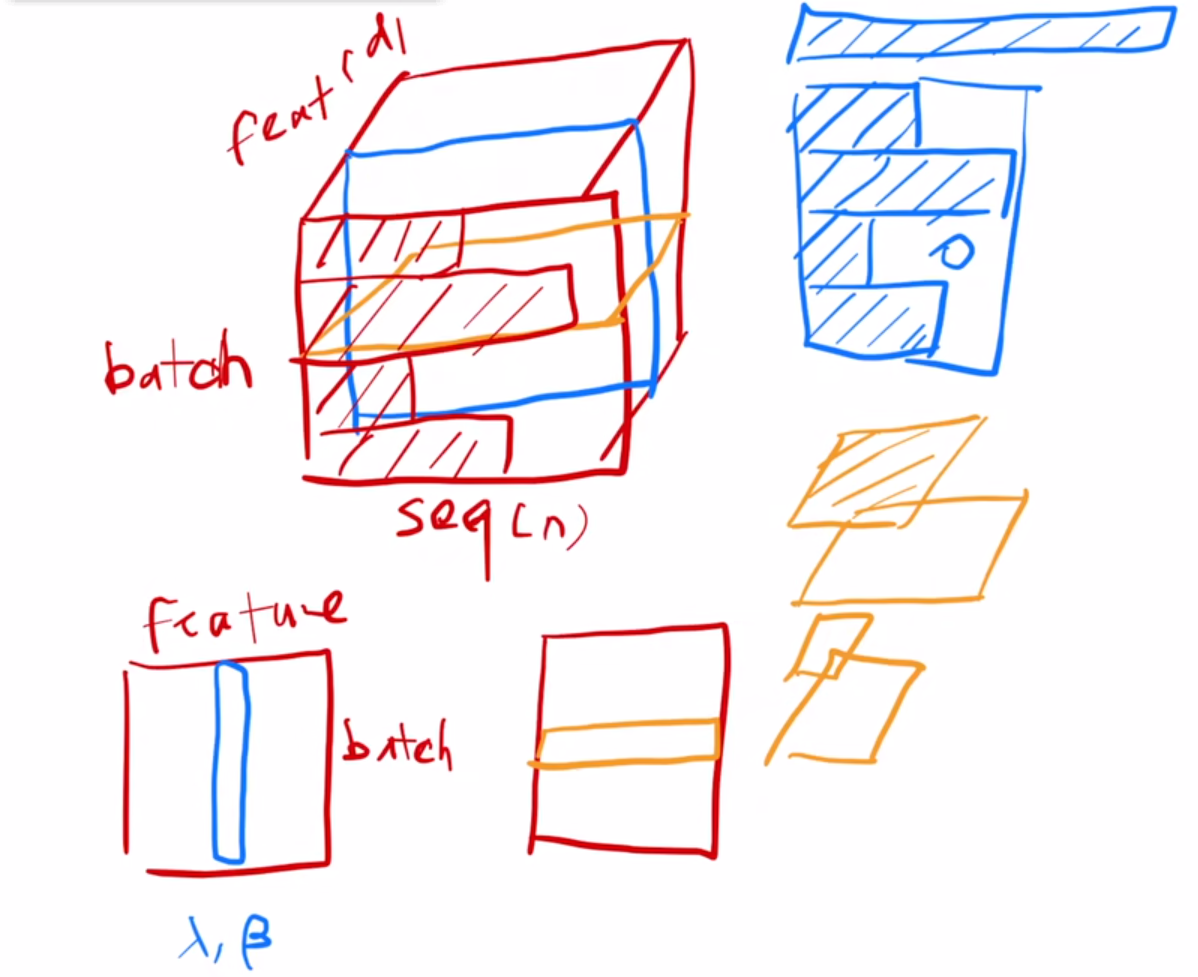
图中,蓝色代表了batchnormalization,黄色代表了layernormalization。
正如其名字,从下方二维数据中看,batchnormalization是在批次维度做normalization,即对于一组训练样本,横向排列一行为一个样本X,一列为这组样本的某一个特征,那么我们对这个batch的某一个特征来做normalization。
layerNormalization则是从feature维度做的normalization,即对每一个样本的所有特征做normalization。
但是在transformer里,数据往往都是三维的,因为往往涉及到时序问题,而且不同样本的长度可能有很大的区别。batchnormalization的做法仍然是在平行于batch维度的方向上做normalization,这个时候做的就是全部sequence和batch下的某一个特征的normalization;而layernormalization的做法是平行于feature维度,即做的是某一个batch下的所有时序下的样本的所有特征的normalization。
后序有论文讲解为什么用前者或者后者,但是,深度学习,没有为什么。
解码器和编码器相比,多了一个模块,即带mask的attention机制,保证在t时刻不应该看到t时刻后面的那些输入。

相较于传统的attention,论文增加了一个dk,即查询与Key除以其长度。因为有时候分子的矩阵结果差距会非常大,这样在做Softmax时,会容易出现相似度*价值特别大的数据的权重非常高甚至接近于1,因此这样容易出现梯度消失,模型训练不动的情况,加上这个运算可以改善这个情况。(根号下的dk只是一个经验参数)
在attention中加入一个mask的意思时,在做注意力机制运算的时候,仍然算所有的sequence,但是在输出时,或者说在Softmax时候,将之后的序列置零不输出即可。
Mulit_Head_Attention
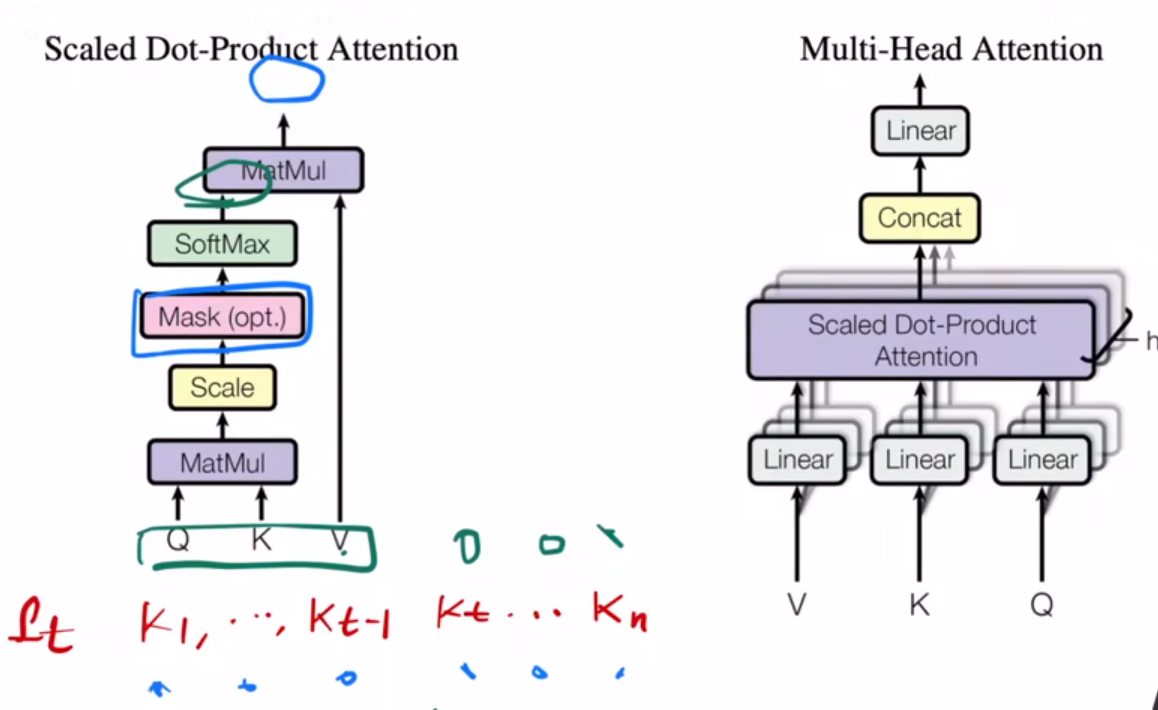
(左图是Scaled Dot-Product-Attention模块,即在原本的attention除以了一个dk而已。右图是多头注意力机制)
所谓的多头注意力机制,其实有点像CNN中的通道的意思。在处理VKQ时,不直接输入到注意力机制模块中,而是先将其投影到低维,这个投影的W参数是可以学一个参数,然后将这个低维的东西输入到Attention模块中。这个过程我们做了h次,每次我们希望投影的角度不同,即希望其学到不同的东西,也因此我们有多个不同的可以学习的W参数。随后,将这些输出直接进行concat,这样就得到了结果。在transformer中,h取的是8.
Transformer里的attention到底是怎么工作的
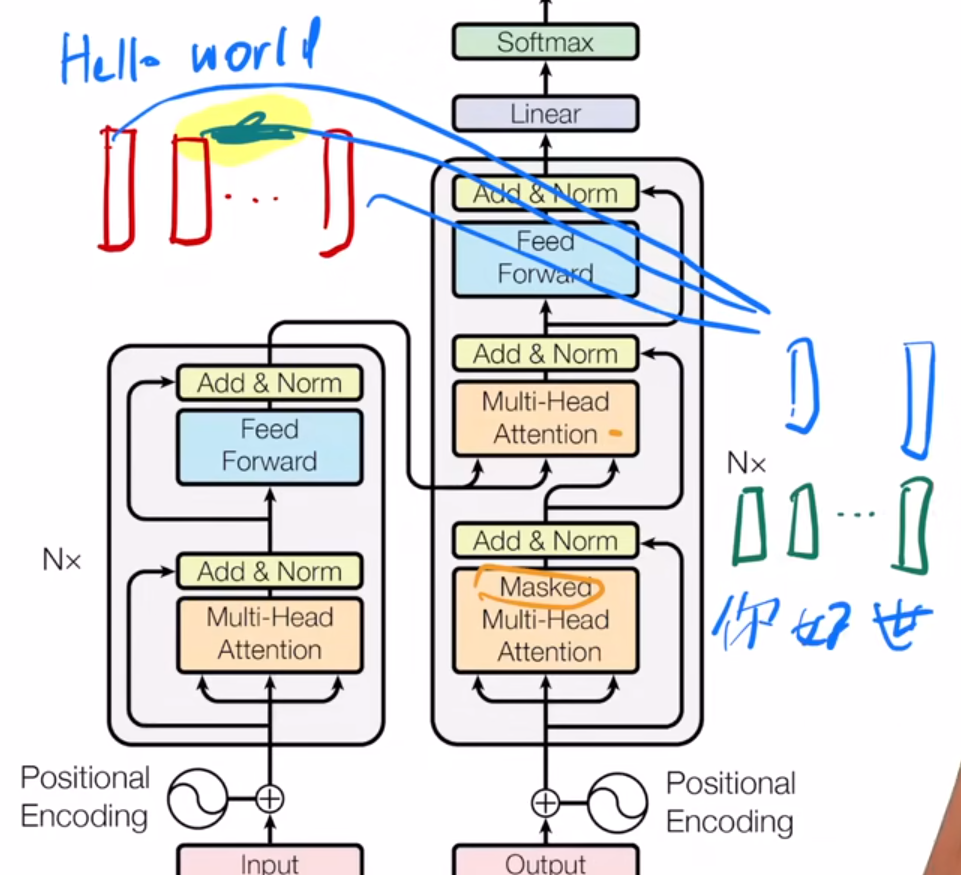
在transformer里一共有三个attention:
1、encoder里的这个attention,输入是一个n维的序列,看作一个n维的向量,分别作为Q、K、V输入(三者都是同一个向量),然后在多头的attention里,会被投影h份,最终拿到一个结果送入Feed Forward里面,得到结果。
2、Decoder的第一个attention,和encoder里基本的工作原理一样,也是输出一个结果,但是这里加入了前面所说的mask,即输出的内容不受当前位置后方的数据影响。
3、Decoder的第二个attention,它使用的Key value来自于encoder的输出,而Query则采用的是decoder上一层的输出。这是一个序列,要根据当前词与前面的词去预测当前的值,因此上一个attention中是含有mask的。随后,我们根据这个query,去查找与其相关性最高的经过encode之后的value,比如“你好世界”中的“好”,对应到encoder里的输出就与“hello”更加相关,因此这个值的权重就会比其他值高。
Feed Forward
这个地方其实就是一个简单的MLP,只不过这个MLP分别对每一个输出结果进行运算,如下图。
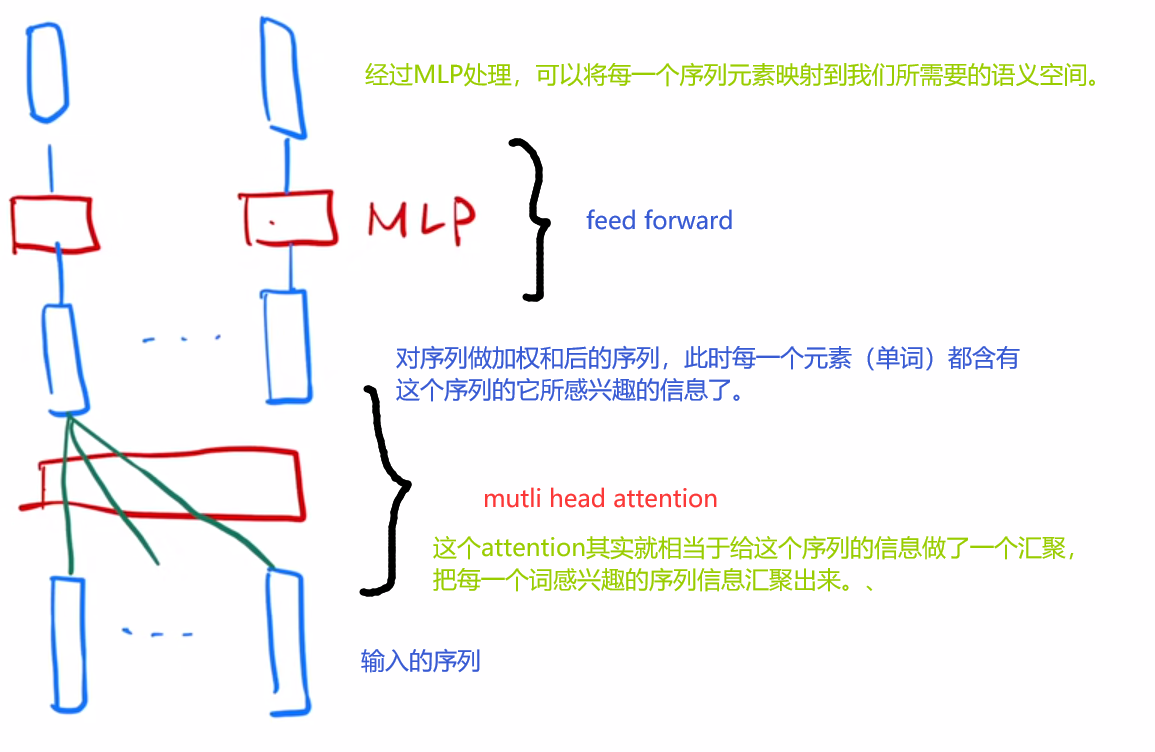
注意,虽然图中画了N个MLP,但是其实只是同一个MLP作用于所有的向量。
相对来说,RNN的训练就比这个简单一些:
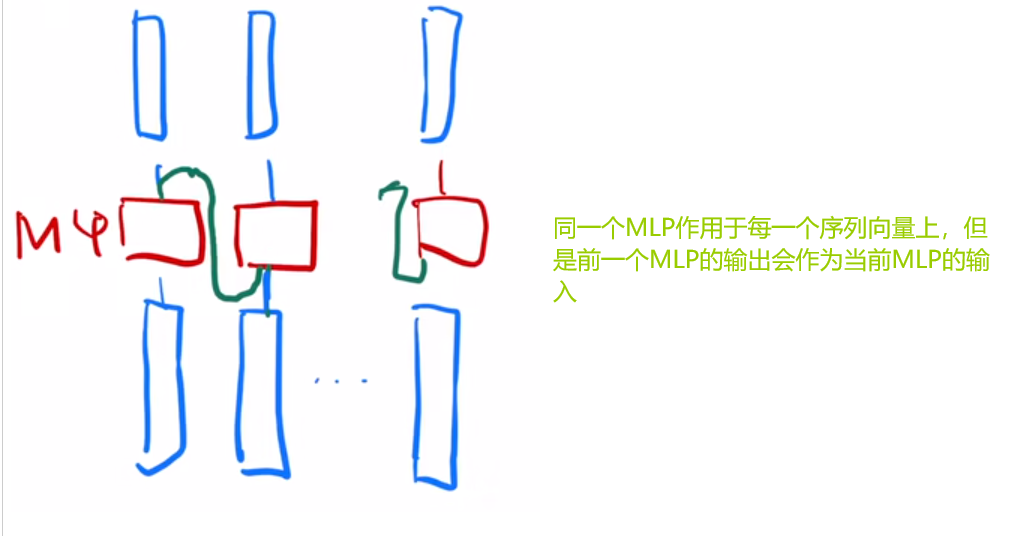
MLP将上一个的处理结果作为输入与当前输入一起进行计算,这样就能保证MLP的输出是包含当前向量的所有之前的向量信息了。
二者的区别也在这里,因为相对于注意力机制来说,RNN需要等待前面的向量运算结果出来之后才能继续计算,这也是attention的优势所在。
Embedding
其实就是将输入序列的每一个词映射成一个长度为d的向量。
在原文中,Embedding层都会乘以一个根号d。因为在将词Embedding到高维空间时,纬度越高,每一维度的值可能就会越小,为了保证与下面的位置编码相加时的scale相似(-1到1),从而作此操作。
Positional Encoding
位置信息的编码。
为什么会有这个东西?
因为Attention是没有时序信息的,即你输入一个序列,不管用什么顺序输入,其结果都是一致的。但是我们常做的机器翻译等工作,是需要考虑单词位置的,位置改变很多时候会改变语义,因此我们手动给这个序列进行位置编码。简单的编码就是从0,1,2,3……直接用数字进行编码(当然这种方法网络没办法学习)。
Transformer里的编码使用的是一个sin和cos的函数,最终结果在-1到1之间浮动,用其生成一个表示位置的512的向量,把这个表示位置的512的向量直接加到了Embedding之后的序列中,从而就认为这个序列拥有了位置信息,从而也认为Attention层的输出具有了时序信息。
相对来说,RNN就不需要考虑这个问题,因为其就是按时序做的训练,从前往后算,且使用前面的输出作为后面的输入,因此其本身就含有时序信息。
总结

可以看到,Self-Attention好像能够碾压其他架构。但其实,也只是在数据上这样。Attention对模型的假设做的比其他模型更少,所以其需要更多的数据和算力去训练才能达到其他模型的效果,所以基于transformer的模型会更大更贵。
也可能因为这样,也就只有Google这样的大公司可以玩得起这种模型,所以虽然2017年发了这样一篇工作,但是并没有出圈。
总之,Transformer最大的好处在于,它非常的通用。架构简单,而且能够解决不管是自然语言处理啊,还是图像处理、音频处理等等领域的许多问题,从而方便了许多后来人的工作。在以前,对于一个NLP任务,需要搭建不同的架构,用不同的方法训练,但是现在,你只需要学会一个transformer,几乎所有的任务都可以进行。这种简单、通用的特点,是它流行起来的主要原因。此外,transformer能够处理不同的数据,将不同模态的数据信息提取到同一个语义空间中,从而使用多模态数据训练更好更大的模型成为了一件可能的事情。未来在多模态融合领域,transformer一定还会继续被发扬光大。它还给了研究者信心,因为出了CNN、RNN之外,我们真的可以找到新的更优秀的架构!
当然了,Transformer只是实验性结果很优秀,但是我们对它的理解还非常浅薄。此外,题目“Attention is all you need”,但是出去残差网络、LayerNorm等,它都训练不出什么东西,所以你需要的不只是attention,而是整个transformer。而且Attention不会给数据的顺序做建模,相对于CNN来说,它没有任何空间上的假设,所以它抓取信息的能力变得更差了,需要更大的数据和模型才能训练,所以后续的transformer工作都非常昂贵,是有钱人的游戏。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话