


深度学习笔记29 多GPU训练实现
就是说,咱论文,咱实在是看的恶心的受不了,来看看李沐压压惊。
因为今天是多GPU训练,而我,作为一个一块GPU都没有的穷鬼,自然跑不了代码,同时,colab上也就只有一块GPU,所以记录一下听课的经验就行。
在从0实现中有一个特别有用的代码:

scatter这个函数可以根据你的GPU信息,自动把数据平均切分并放到每一块GPU上。
当然,这只适合偷懒一下,手动切分麻烦不了太多。而且这个函数只能平均分,对于那些性能不同的GPU,还是得手动切分。
在多GPU的时候,不比单GPU快,很正常,精度变低,也很正常。
1、数据集太小,可能不适合多GPU训练。
2、数据传输效率低,花费的时间远远大于网络训练的时间,这样多GPU训练也没太大意义。
3、多GPU,我们常常用N倍的batch_size和N倍的学习率。
Q&A
1、all_reduce是把所有东西相加再复制回去,all_gather是把所有东西合并起来,反义词是scatter切分;
2、为了得到更好的速度,我们需要把batch_size变大,这会带来收敛上的变化,因此一般会把lr调大;
3、对于精度来说,batch_size=1是最好的情况;
代码

import torch from torch import nn from d2l import torch as d2l # 一个计算量比LeNet大大概50倍的网络 # 注意这节课主要讲的是多GPU训练,对于网络没必要每一个都去了解 def resnet18(num_classes, in_channels=1): """稍加修改的ResNet-18模型""" def resnet_block(in_channels, out_channels, num_residuals, first_block=False): blk = [] for i in range(num_residuals): if i == 0 and not first_block: blk.append(d2l.Residual(in_channels, out_channels, use_1x1conv=True, strides=2)) else: blk.append(d2l.Residual(out_channels, out_channels)) return nn.Sequential(*blk) # 该模型使用了更小的卷积核、步长和填充,而且删除了最大汇聚层 net = nn.Sequential( nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(64), nn.ReLU()) net.add_module("resnet_block1", resnet_block( 64, 64, 2, first_block=True)) net.add_module("resnet_block2", resnet_block(64, 128, 2)) net.add_module("resnet_block3", resnet_block(128, 256, 2)) net.add_module("resnet_block4", resnet_block(256, 512, 2)) net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1,1))) net.add_module("fc", nn.Sequential(nn.Flatten(), nn.Linear(512, num_classes))) return net net = resnet18(10) # 获取GPU列表 devices = d2l.try_all_gpus() # 我们将在训练代码实现中初始化网络 def train(net, num_gpus, batch_size, lr): train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) devices = [d2l.try_gpu(i) for i in range(num_gpus)] def init_weights(m): if type(m) in [nn.Linear, nn.Conv2d]: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights) # 在多个GPU上设置模型 net = nn.DataParallel(net, device_ids=devices) # 给定一个network,告诉函数需要什么GPU,这个函数会把所有数据复制到指定的GPU trainer = torch.optim.SGD(net.parameters(), lr) loss = nn.CrossEntropyLoss() timer, num_epochs = d2l.Timer(), 10 animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs]) for epoch in range(num_epochs): net.train() timer.start() for X, y in train_iter: trainer.zero_grad() X, y = X.to(devices[0]), y.to(devices[0]) # 这里第一块为主卡(但是colab咱也只有一块卡) l = loss(net(X), y) l.backward() trainer.step() timer.stop() animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),)) print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,' f'在{str(devices)}') train(net, num_gpus=1, batch_size=256, lr=0.1) train(net, num_gpus=2, batch_size=512, lr=0.2)
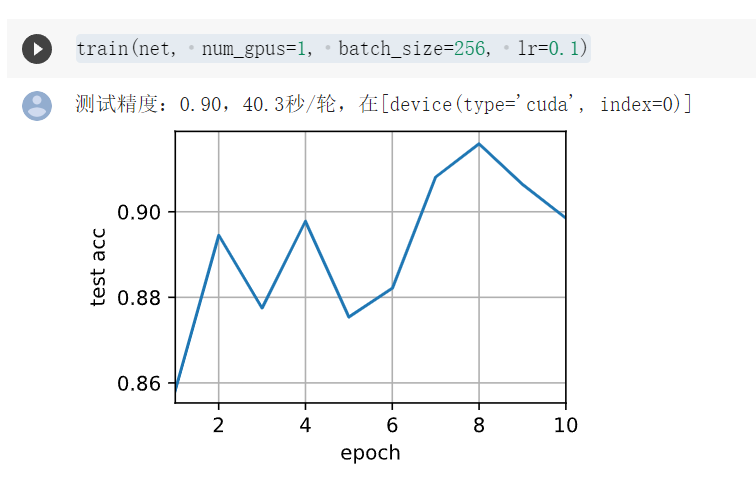
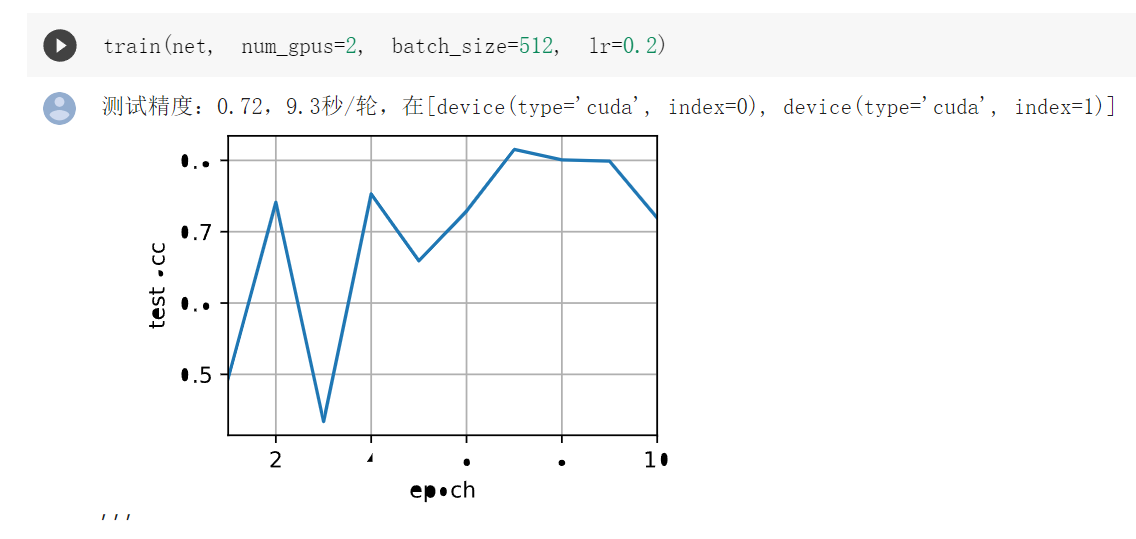
注意,第二章用两个GPU的图是李沐老师跑的,colab上我也只有一块显卡,跑不了这个函数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix