


深度学习笔记27 深度学习硬件 CPU GPU
举个例子,为什么不能用CPU做深度学习?
就拿Intel的i7来说,她每秒钟的运算是0.15TFLOPS,而NVIDIA的TitanX是12TFLOPS,两者差出80倍之多。
在实际中,你用GPU训练一个模型需要1小时的话,用CPU就需要80小时,你还玩个屁。
CPU:

左侧是集显区域,负责渲染图形界面,简单游戏等;中间是一些计算单元,Shared LLC是显存,其他地方都是通向其他组件的接口。
CPU的理论速度可能还算比较快,但是我们实际使用CPU的时候,远远达不到一个CPU的理论速度,主要原因就是主内存访问的延迟问题。
一个式子的计算,需要从主内存,进入到CPU的显存,再从显存进入到核,最后进入到寄存器,完成运算。而主存访问延时是到寄存器访问延时的200倍。
综上,提升CPU利用率的本质就是应该提升空间和时间的内存本地性,两种方法:
时间:重用数据使他保持在缓存中(cache提升速度)
空间:按序读写数据使得数据可以被预读取。(CPU读取的时候,可以提前读取数据)
样例:
如果一个矩阵是按列存储,访问一行会比访问一列要快。(这里说的是地址本身是按行还是按列,而不是数据本身的意义是按行还是按列)
CPU是按行读取,一次读取64个字节(一行,被称为缓存线),CPU会聪明地提前读取下一个(下一行,缓存线)
故一般按行访问会快一些。
提升CPU的利用率的另一个方式:加更多的核。上图是一个四核CPU,现在有些CPU的核能做到32,甚至64.
Intel提出了一个超线程,也就是更好的并行起来利用所有的核。
网上找到一些对于超线程的理解:
常规的CPU想要执行多线程的时候,CPU要在线程之间不断地调度,在开启了超线程之后,CPU可以更充分地利用好自身的资源(CPU某些硬件有多个备份,比如程序计数器和寄存器文件)。例如当开启了超线程之后,可以在一个线程执行整数指令集的时候,而恰好在这个时候,另一个线程执行浮点指令集,而这两个指令集整数指令单元和浮点指令单元来执行。再比如一个线程必须要等到某些数据被加载到高速缓存中,那CPU就可以继续去执行另一个线程。作者:AI草莓莓汁呀链接:https://www.zhihu.com/question/384468852/answer/1901583871
但是,超线程不一定能提升性能,比如对于计算密集型的运算,但是物理意义上的寄存器就那么几个,两个超线程会抢夺寄存器,因为他们在共享寄存器。而抢夺计算资源甚至可能会降低性能。作者:路并寻链接:https://www.zhihu.com/question/384468852/answer/1122097961你正常情况下五秒吃一口饭,然后休息两秒,吃下一口饭,这是单线程。
你有两个嘴,一个嘴五秒吃一口饭,休息两秒,吃下一口饭;另一个嘴两秒喝一口汤,休息一秒,喝下一口汤,这是双核双线程。
你有一个嘴,五秒吃一口饭,隔壁的老王拿起你的汤碗往你嘴里灌,于是在你原本用来休息吞咽饭的两秒你又喝下了一口汤,两秒后你又开始下一个吃一口饭的五秒。这是超线程的单核双线程。
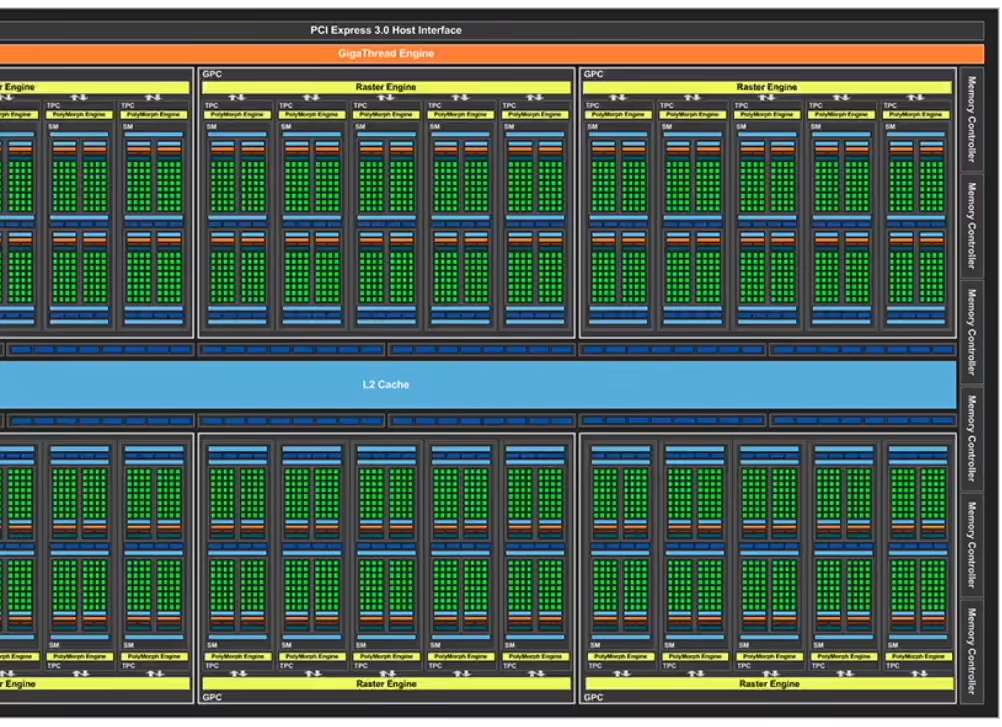
外框是一个大核,不同品质的显卡基本就是大核不同;
大核里面有小核(绿点),每一个小核都是一个计算单元,每一个小核都能开一个计算单元,所以可以看到我们每次可以开上千个线程。

上图的斜杠区分了两种品质,一般和高端。
可以看到,本质区别其实就是核的数目。
除此之外,GPU的内存带宽很高,这一点非常重要,因为很大的模型再加上很多的中间数据需要经常写来写去,这可能会引起读取速度限制核的运算,所以GPU的带宽做的非常大。
另外就是CPU的控制流很强,因为CPU是通用计算单元,需要处理很多if else的东西,必须预判接下来要算的是什么,是控制流还是其他什么东西,只留下了一小部分做计算单元;与此同时,GPU把逻辑运算删掉了,基本整个芯片都在用于数据的计算。
提高GPU的利用率:
1、并行,比如使用上千个线程(类似,1000维度的向量,就会产生1000个计算线程)
2、内存本地性。GPU为了节省面积,会把缓存做的比较小,架构更简单,但同时做大了内存。
3、tensor的运算要少用控制语句。
除此之外,就是CPU与GPU之间的带宽也是一个很大的问题。
有一种比喻很有意思,CPU就是几个博士生,擅长处理复杂问题;GPU就是一大堆成千上万的小学生,只会做简单的加减乘除。
CPU和内存有数据交互,同时CPU也会通过PCIE与GPU进行交互,而相对CPU与内存的带宽,CPU到GPU的带宽不是很高的,同时传输数据的时候GPU必须做好同步,这也是很大的一个开销。
所以我们不要在CPU和GPU之间传输数据,因为有带宽限制和同步开销。
CPU/GPU高性能编程:
CPU:用C++或者其他高性能语言,因为这种语言的编译器很成熟。
GPU:
NVIDIA上用CUDA,编译器和驱动成熟。
其他用OpenCL,质量取决于硬件厂商。
总结:

Q&A
1、模型大小和计算复杂度没有直接关系,比如AlexNet可能300MB,ResNet18可能18MB,但是ResNet运行起来要比AlexNet慢。
2、LLC,last level of cache,就是最后一层缓存的意思。
3、尽量能够用Tensor做的,不要写for loop,不要让GPU去算逻辑性的计算。
4、python进程有一个全局锁,因为这个锁会带来很多影响,所以python常常需要多进程。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix