

深度学习笔记022 VGG(使用块的网络)
AlexNet比LeNet更深更大,带来了更好的精度,那么是不是再深一些再大一些,我们就会更好?
更深更大,可以通过更多的全连接层(太贵)、更多的卷积层以及将卷积层组成块来实现。
VGG思想:将小块先组成大块,最后再去组合。
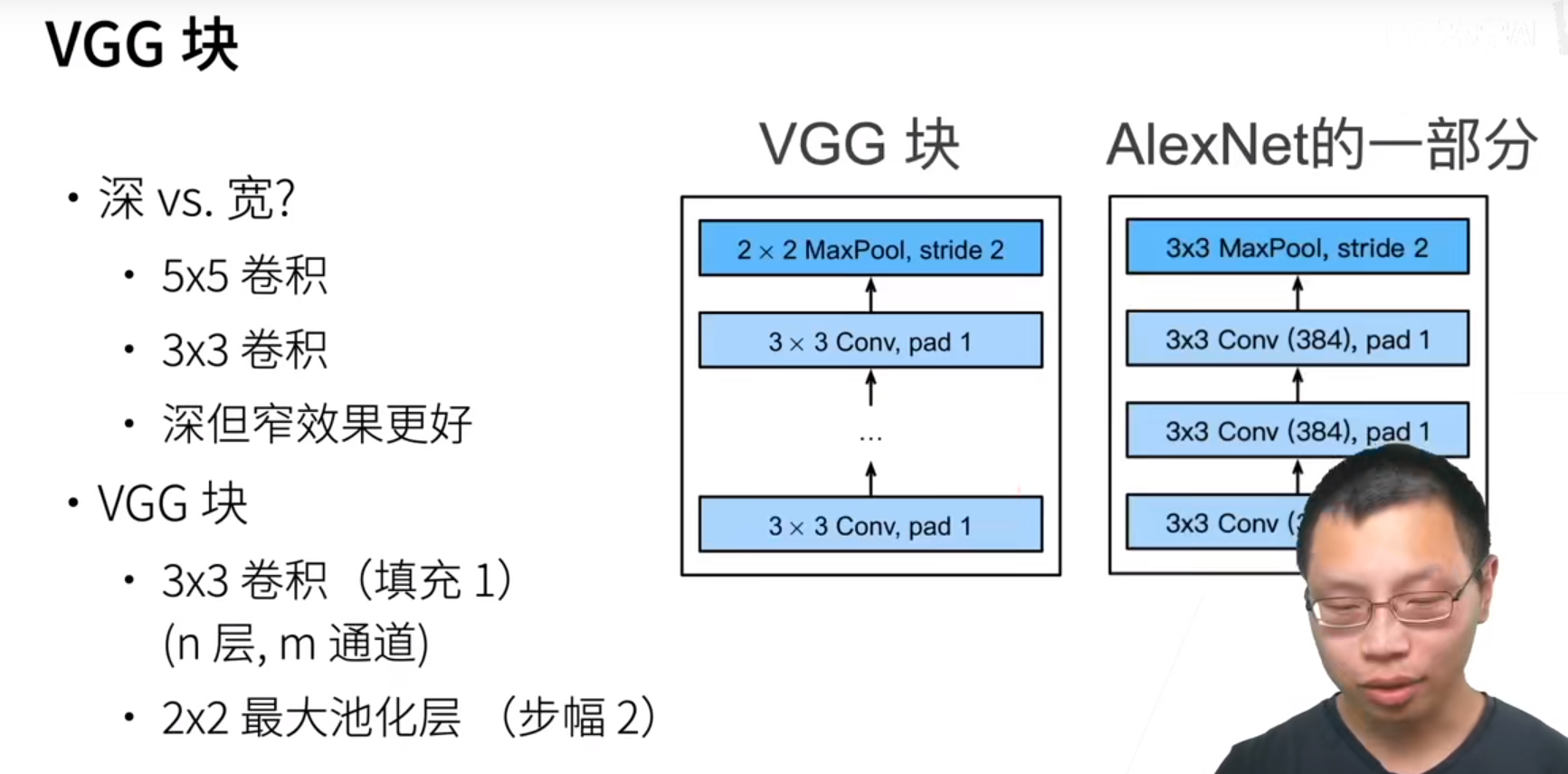
VGG块:用大量的3x3(一般再大效果会不好)的卷积层堆起来加一个池化层做VGG块,然后用这些VGG块组成网络。
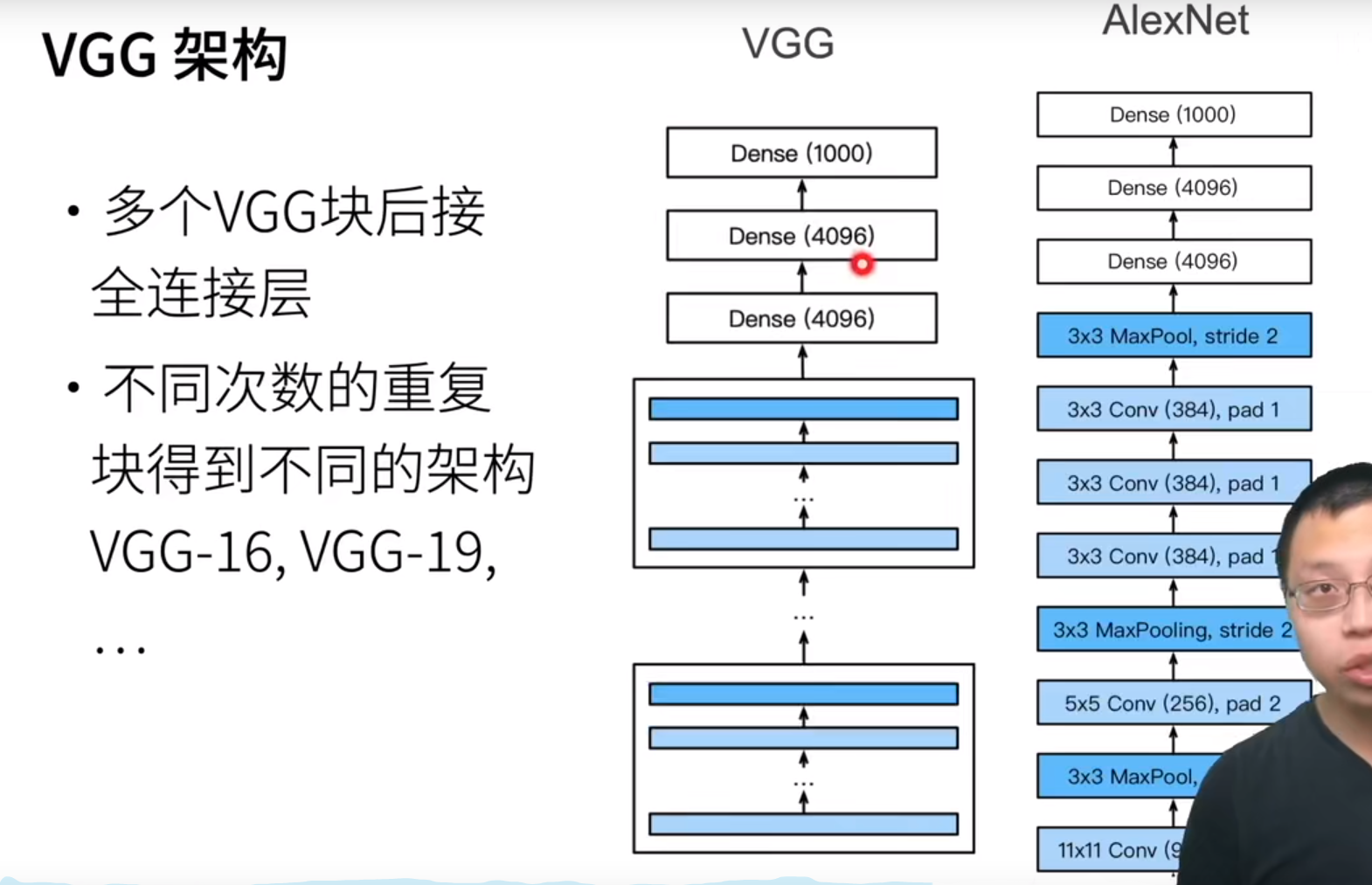
所谓的VGG网络,其实就是将AlexNet网络中看起来不规则的池化和卷积层规则化了一下,让网络看上去更加规则。
(但我还是感觉是在水论文,这两个的本质本身是一样的……)
目前三种网络:
LeNet:(1985)
2卷积层+池化层
2全连接层
AlexNet:(2012)
更大更深的网络
加入了ReLU,Dropout,数据增强
VGG:(2014)
更大更深的AlexNet(重复的VGG块)
结果
首先说明一下,这里将所有层的通道数缩小了4,也就是这是一个简化版的VGG网络,见代码详情。
沐神结果:
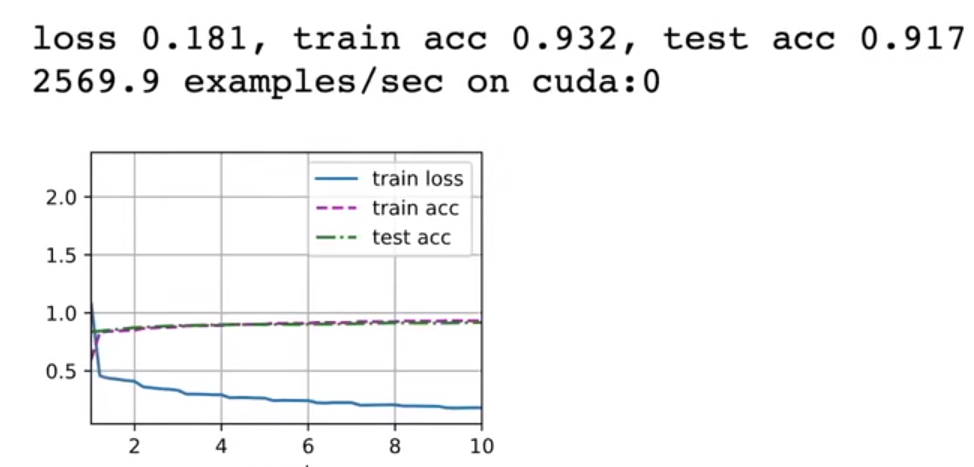
可以看到,即便是简化版的VGG网络,精确度却达到了91%,比AlexNet要高一些,那么如果不简化,精确度一定会更高。
当然,在这里我仍然不太认可VGG的成就,其本质不过是多加了几层卷积层而已,当年AlexNet要是多加几层卷积层,也能上90%,VGG只不过管理上方便一点。“更容易去管理每一层网络”,这是我认为VGG唯一的贡献,除此之外,我还是觉得他就是在水论文。
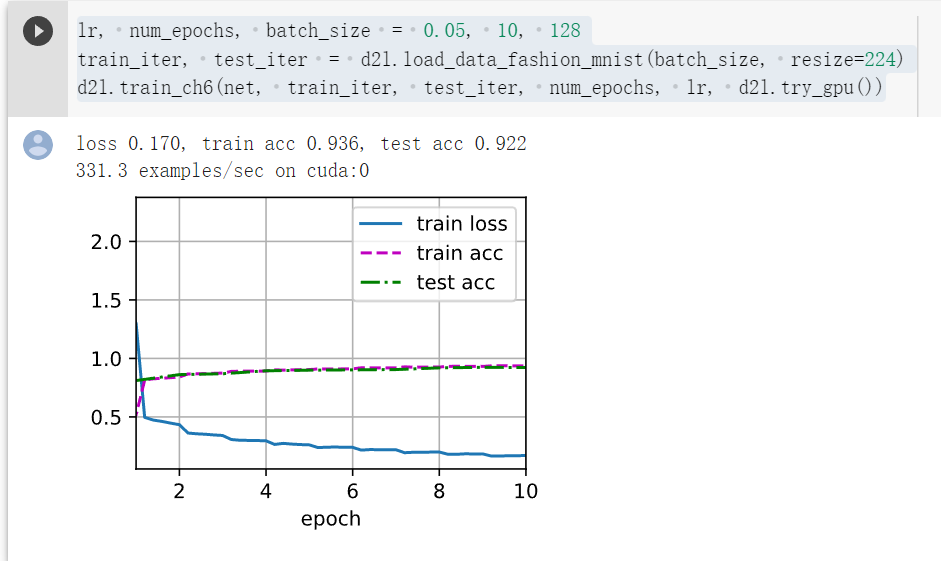
我的结果(我与沐神不同的是我最后两层卷积层的通道数是沐神的二倍)
Q&A
1、在以后发论文、出成果的时候,尽量用简单的东西,这样才可能被人们更广泛更重复地去使用。
代码
import torch from torch import nn from d2l import torch as d2l def vgg_block(num_convs, in_channels, out_channels): # 卷积层数,输入通道,输出通道 layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels,kernel_size=3, padding=1)) # 加入卷积层 layers.append(nn.ReLU()) in_channels = out_channels # 第一层之后,将in_channels改为out_channels,因为后序输出作为输入 layers.append(nn.MaxPool2d(kernel_size=2,stride=2)) # 最后加一层池化 return nn.Sequential(*layers) # 这便是我们最后的一个VGG块(本质上其实就是一个多层网络,和AlexNet换汤不换药的感觉……) conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 1024)) # 5个块 # 224除以2的5次方是7,不能在除了,所以就五块VGG(每块VGG最后的pool会将样本高宽缩小一半) # 第一个数字是卷积层数目,第二个数字是输出通道数目 def vgg(conv_arch): conv_blks = [] in_channels = 1 # 卷积层部分 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels # 第一层之后,将in_channels改为out_channels,因为后序输出作为输入 # 后面就很简单了,把卷积池化叠起来,最后拉成一个向量,随后在做相应的全连接层和ReLu激活,最后以对应的类别输出即可 return nn.Sequential( *conv_blks, nn.Flatten(), # 全连接层部分 nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)) net = vgg(conv_arch) X = torch.randn(size=(1, 1, 224, 224)) # 这里输出的形状,是以VGG块为单元输出的,相对AlexNet来说,更加清晰一些 for blk in net: X = blk(X) print(blk.__class__.__name__,'output shape:\t',X.shape) # [由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络],足够用于训练Fashion-MNIST数据集 # 这里的操作是将VGG块中的通道数统一除以4 ratio = 4 small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch] net = vgg(small_conv_arch) lr, num_epochs, batch_size = 0.05, 10, 128 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

