

深度学习笔记021 AlexNet
AlexNet:深度卷积神经网络,2012年左右提出。
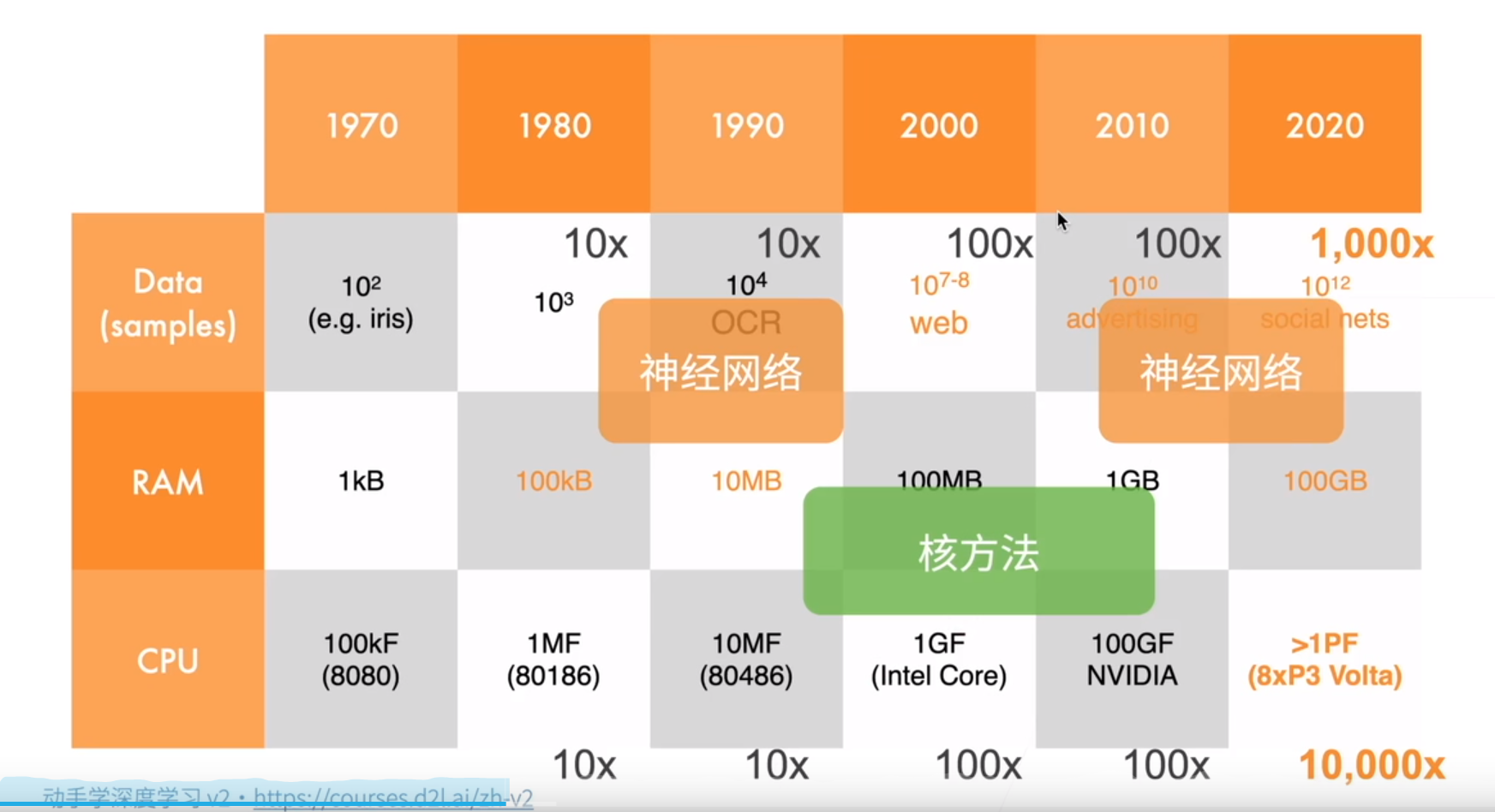
在这之前,2000年左右开始,最火的机器学习算法是核方法(Learn with kernels):用核函数,计算相关性。
机器学习,最核心最基础的一点,就是,能跑得动。
ImageNet的数据集:
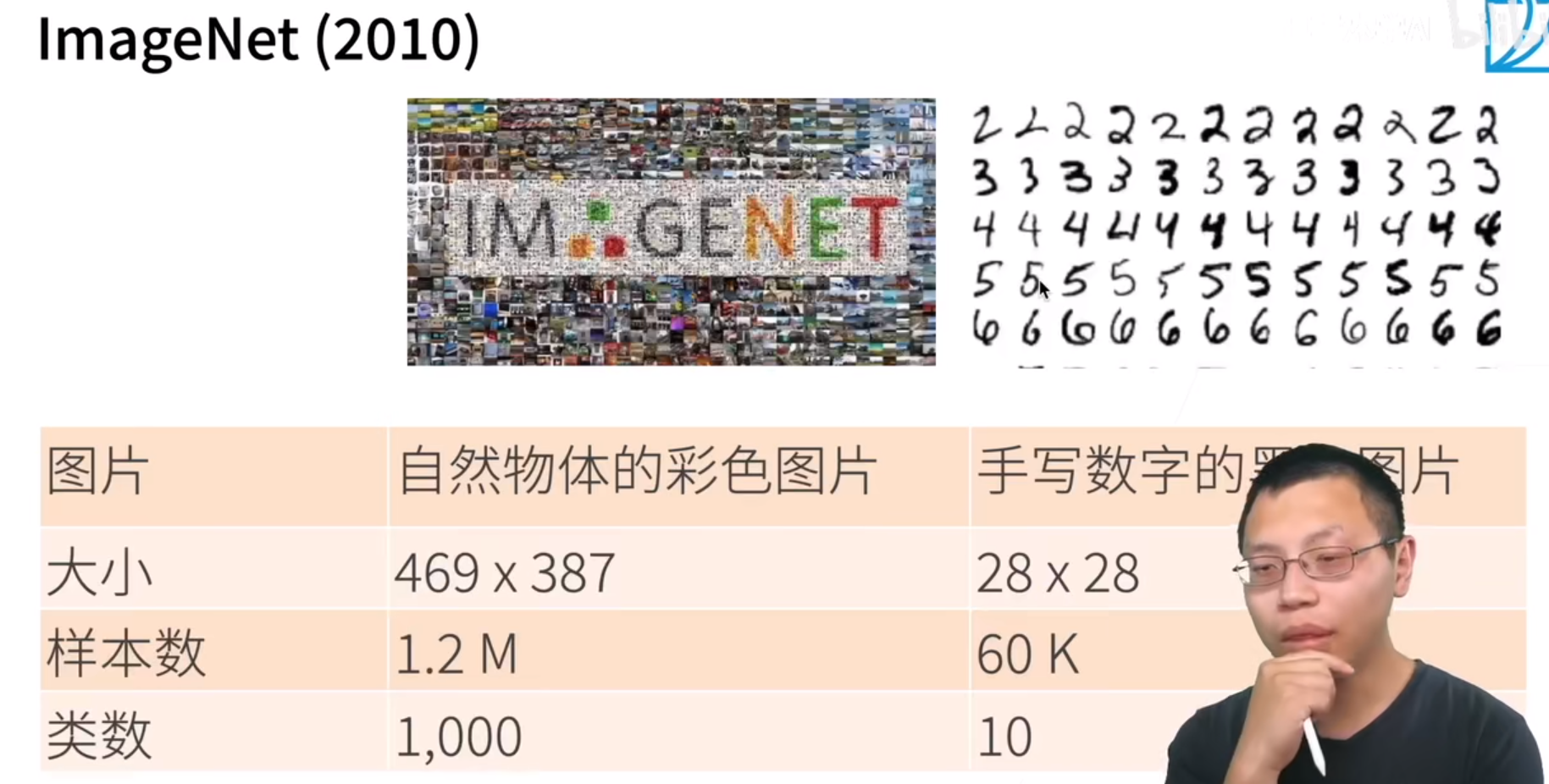
可以看到和手写数字识别的数据集相比,样本和类数都上升了几个数量级。
而在2012年ImageNet竞赛中,AlexNet获胜。
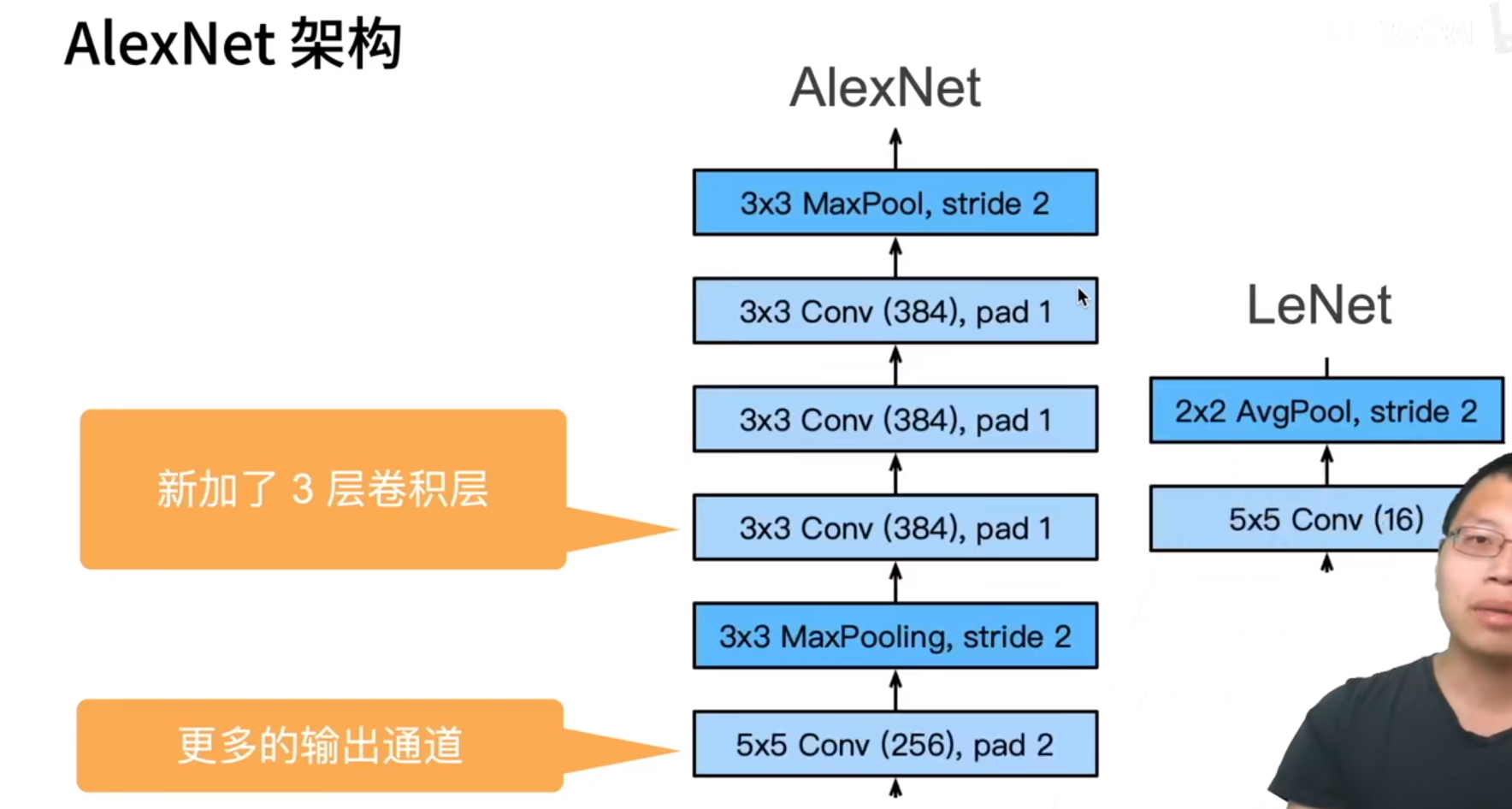
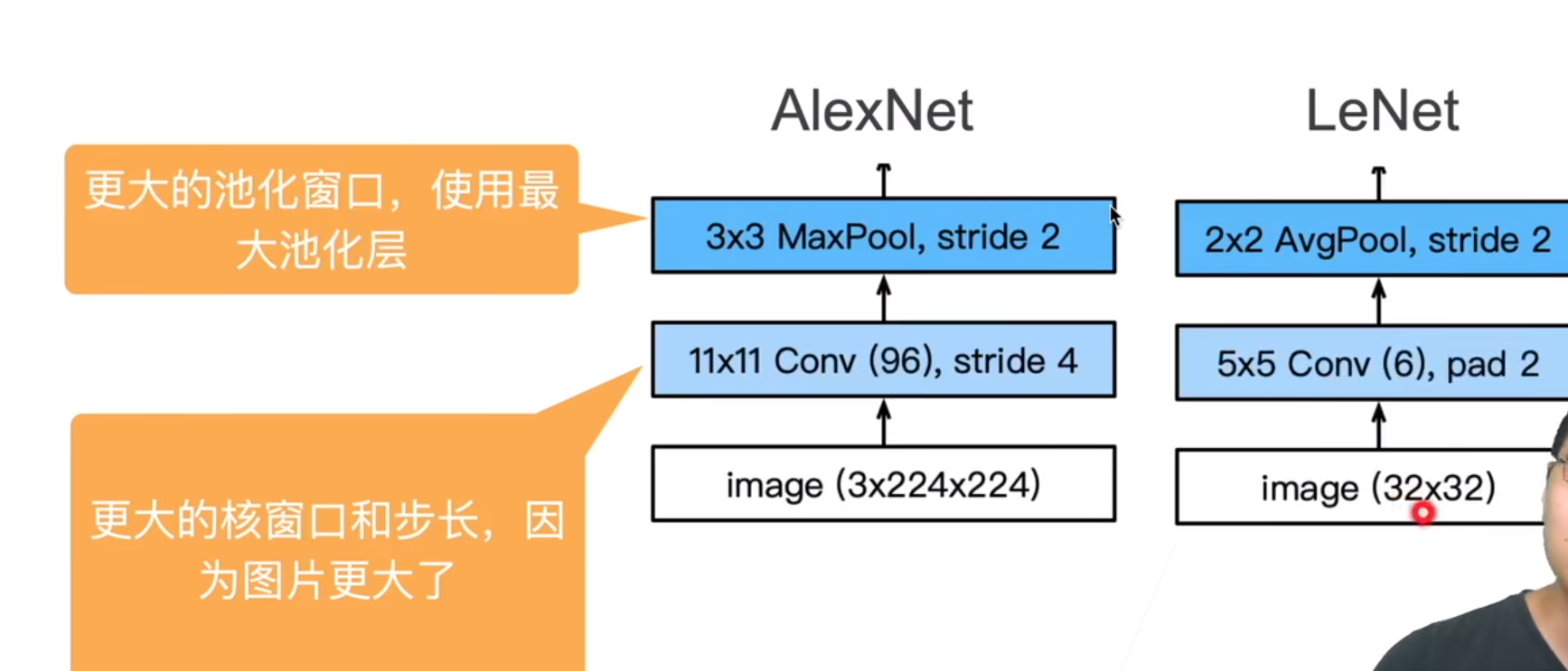
所谓AlexNet,其实就是更大、更深的LeNet。
相对于LeNet,主要改进的是:
丢弃法(控制模型不要太大,算是一种正则)、ReLu(相对于Sigmoid更适合更深的模型)、MaxPooling
AlexNet,在计算机视觉有一个很大的方法论的改变:
机器视觉以前都是人工提取特征,将特征人工转化成机器学习能识别的形式;
但是之后,特征就是CNN学习出来的,而CNN学习出来的特征基本就是Softmax回归最想要的特征。
AlexNet与LeNet区别
最后用隐藏层加输出层:
dence:全连接层
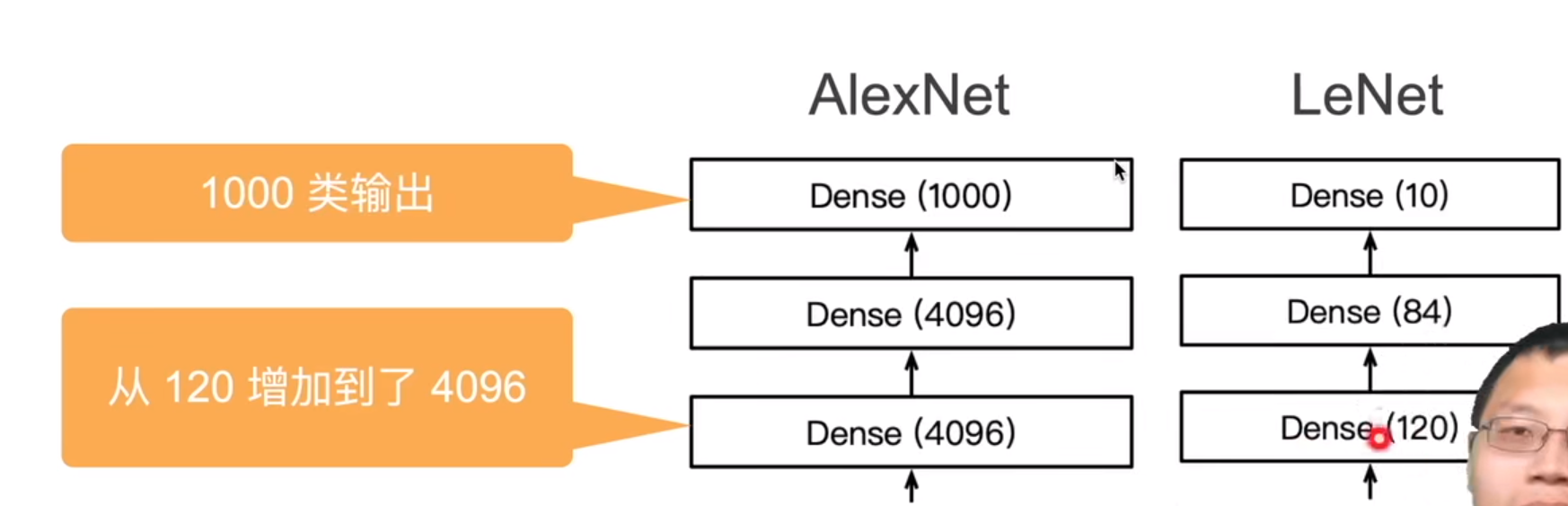
除此之外:
激活函数从sigmoid变成了Relu,减缓梯度消失;
隐藏全连接层后加入了丢弃层;
做了数据增强(原图截取一部分、原图调色温、亮度等方式)
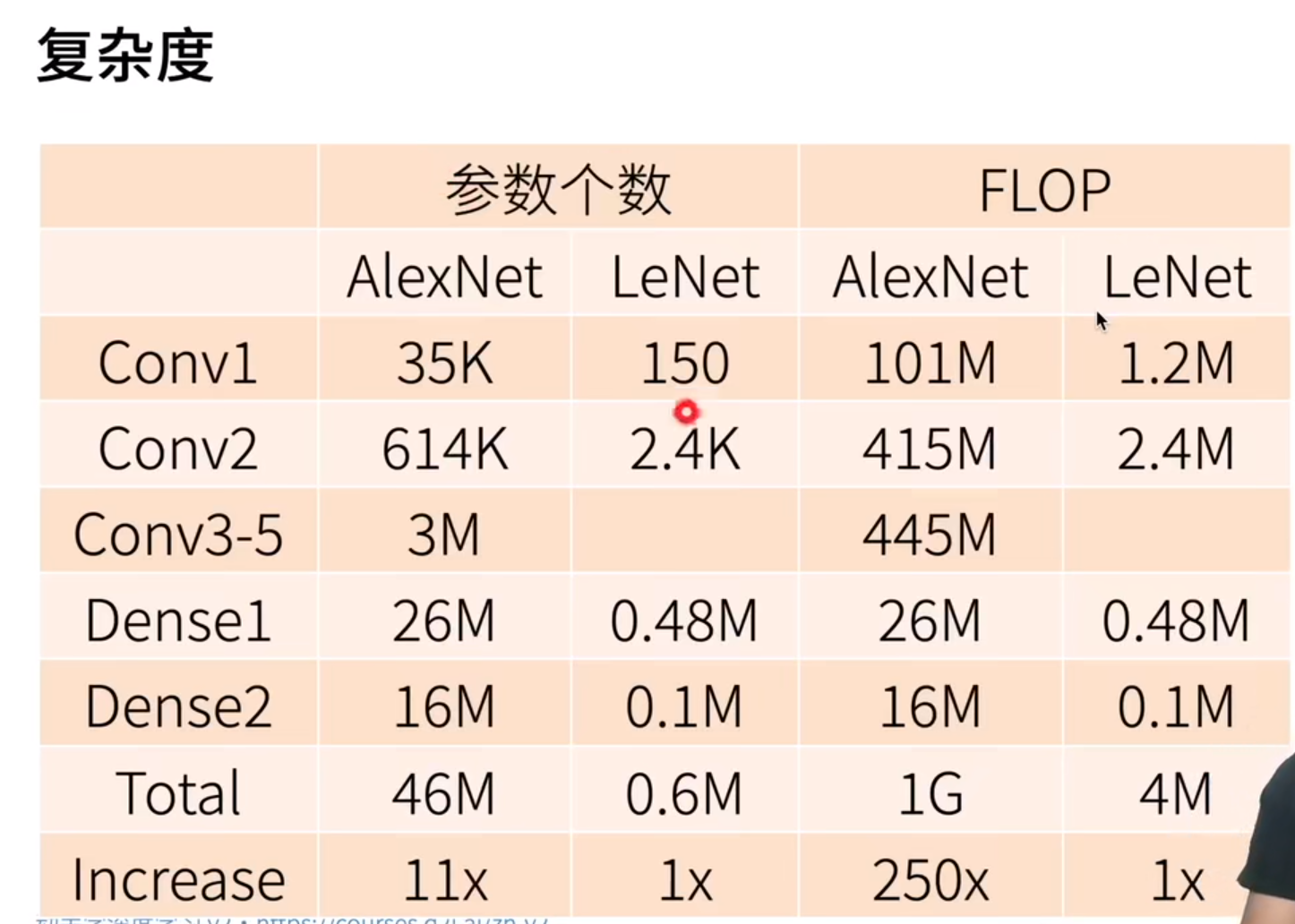
可见,总的参数上升了11倍,计算复杂度增加了250倍,数据从10M增加到了100G,磁盘都存不下,所以,对不起,电脑真跑不动了。
总算一下,我CPU跑LENet需要5min,跑AlexNet需要( 5x1/60x11x250x10^4 ) / 24 /364 =269年,也就是用我的电脑跑这个网络,需要269年才能跑完……
AlexNet赢下2012年的ImageNet之后,标志着新一轮的神经网络热潮的开始……
结果对比:
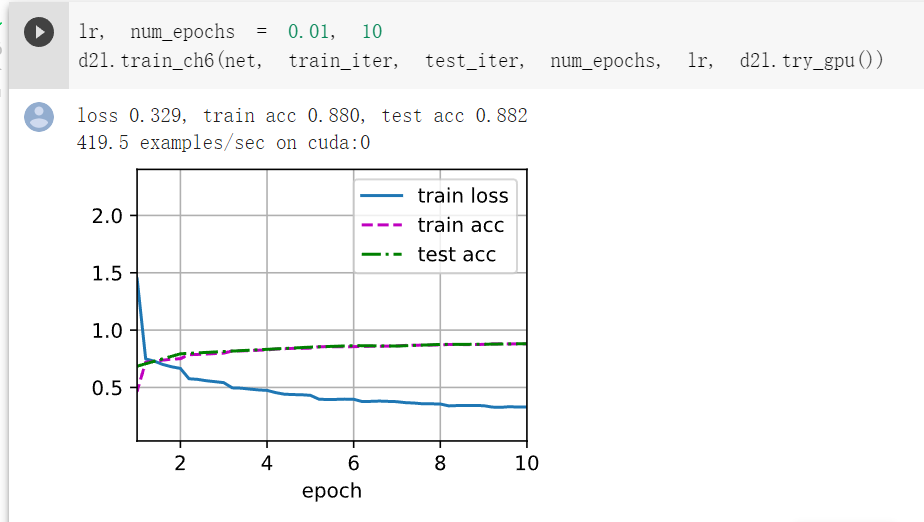
可以看到,同样的数据集,AlexNet在准确率上比LeNet上升了7%,AlexNet跑10次,大概是LeNet跑50次的准确率,具体可以参考上一篇学习笔记。
当然,LeNet跑10次用了两三分钟,而AlexNet用时:![]()
沐神的GPU需要跑3min,比我的快大概十倍。
我曾尝试用thinkpadCPU跑一跑:
但是,太心疼了,第一个epoch没跑完,电脑已经烫的不行了,处于对她的爱,我关了这个网络:
Q&A
1、ImageNet虽然是十年前在Google用了近100w美金雇人标注出来的,但是在现在也是很常用的数据集。
2、真正的AlexNet中还有一个LRN(Local Response Normalization),但是没什么用,只在AlexNet用过,不需要太了解。
3、两个4096x4096的全连接层,大的dense是非常好的模型,只用一个效果常常很差。
4、数据增强很复杂,简单的几何变换和颜色变换后模型变差是很正常的事情。
5、为什么LeNet不属于深度神经网络?其实,可以认为属于(这里比较滑稽)。
搞深度学习的其实就是太会包装了,所谓的“deep”,就是深度学习包装用的词语,要是LeNet也叫深度网络,那怎么显得出来我的工作呢?你看我的DeepLearning,听起来多牛逼,虽然我的AlexNet确实和LeNet差不多,但是如果说我也给LeNet叫DeepLearning,那不就去捧他了而不是捧我自己?(滑稽)
PS:以后我发论文的时候,一定要造一些比较牛逼的词【滑稽】
6、神经网络目前已经到了特别大的瓶颈了,所以新工作越来越少,但是Demo会多,因为这些技术已经很成熟了,该落地了,应该多去开发应用了。
代码

import torch from torch import nn from d2l import torch as d2l # 心狠手辣,在thinkpad的CPU上跑AlexNet net = nn.Sequential( # 这里,我们使用一个11*11的更大窗口来捕捉对象。 # 同时,步幅为4,以减少输出的高度和宽度。 # 另外,输出通道的数目远大于LeNet nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), # 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数 nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), # 使用三个连续的卷积层和较小的卷积窗口。 # 除了最后的卷积层,输出通道的数量进一步增加。 # 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度 nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), #沐神把这里256改成了384应该是出错了 nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), # 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合 nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), # 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000 nn.Linear(4096, 10)) X = torch.rand(size=(1, 1, 224, 224), dtype=torch.float32) for layer in net: X = layer(X) print(layer.__class__.__name__,'output shape: \t',X.shape) batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size,resize=224) #这里的resize是为了将图片拉成和ImageNet的大小,真实情况下不会干这个事情 # 训练代码和上一节课的一模一样 def evaluate_accuracy_gpu(net, data_iter, device=None): """使用GPU计算模型在数据集上的精度""" if isinstance(net, nn.Module): net.eval() # 设置为评估模式 if not device: device = next(iter(net.parameters())).device # 正确预测的数量,总预测的数量 metric = d2l.Accumulator(2) with torch.no_grad(): for X, y in data_iter: if isinstance(X, list): # BERT微调所需的(之后将介绍) X = [x.to(device) for x in X] else: X = X.to(device) y = y.to(device) metric.add(d2l.accuracy(net(X), y), y.numel()) return metric[0] / metric[1] def train_ch6(net, train_iter, test_iter, num_epochs, lr, device): """用GPU训练模型(在第六章定义)""" def init_weights(m): if type(m) == nn.Linear or type(m) == nn.Conv2d: nn.init.xavier_uniform_(m.weight) net.apply(init_weights) print('training on', device) net.to(device) optimizer = torch.optim.SGD(net.parameters(), lr=lr) loss = nn.CrossEntropyLoss() animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['train loss', 'train acc', 'test acc']) timer, num_batches = d2l.Timer(), len(train_iter) for epoch in range(num_epochs): # 训练损失之和,训练准确率之和,样本数 metric = d2l.Accumulator(3) net.train() for i, (X, y) in enumerate(train_iter): timer.start() optimizer.zero_grad() X, y = X.to(device), y.to(device) y_hat = net(X) l = loss(y_hat, y) l.backward() optimizer.step() with torch.no_grad(): metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) timer.stop() train_l = metric[0] / metric[2] train_acc = metric[1] / metric[2] if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1: animator.add(epoch + (i + 1) / num_batches, (train_l, train_acc, None)) test_acc = evaluate_accuracy_gpu(net, test_iter) animator.add(epoch + 1, (None, None, test_acc)) print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, ' f'test acc {test_acc:.3f}') print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec ' f'on {str(device)}') d2l.plt.show() lr, num_epochs = 0.01, 10 # 注意,这个train_ch6,沐神写到了d2l里,可以直接调用(见结果对比处在Google Colab上用的代码 train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)