


深度学习笔记018卷积层的多个输入和输出通道
对于RGB这种多个输入通道的图:
每个通道都有一个卷积核,结果是所有通道卷积结果的和。
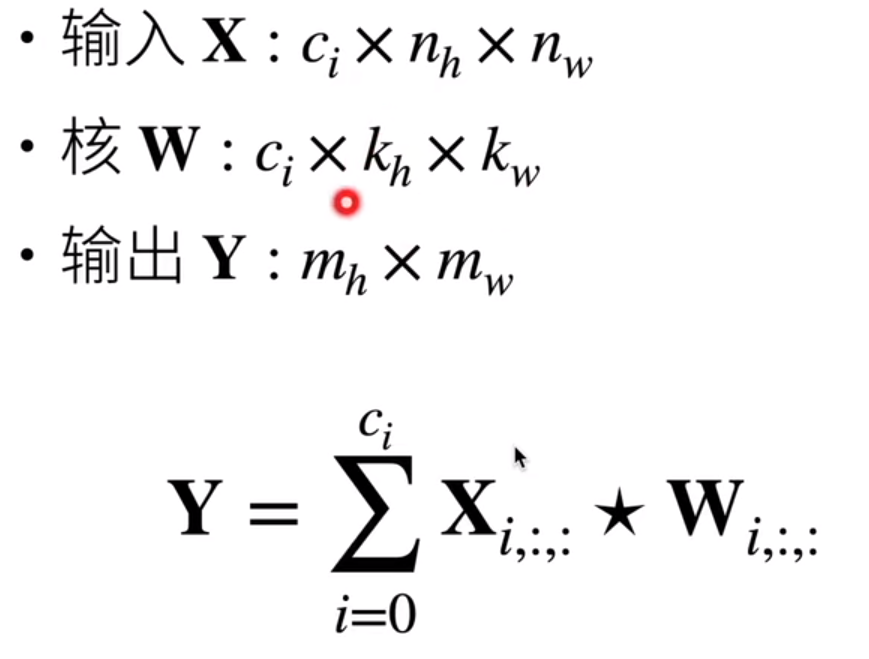
我们可以有多个输出通道:
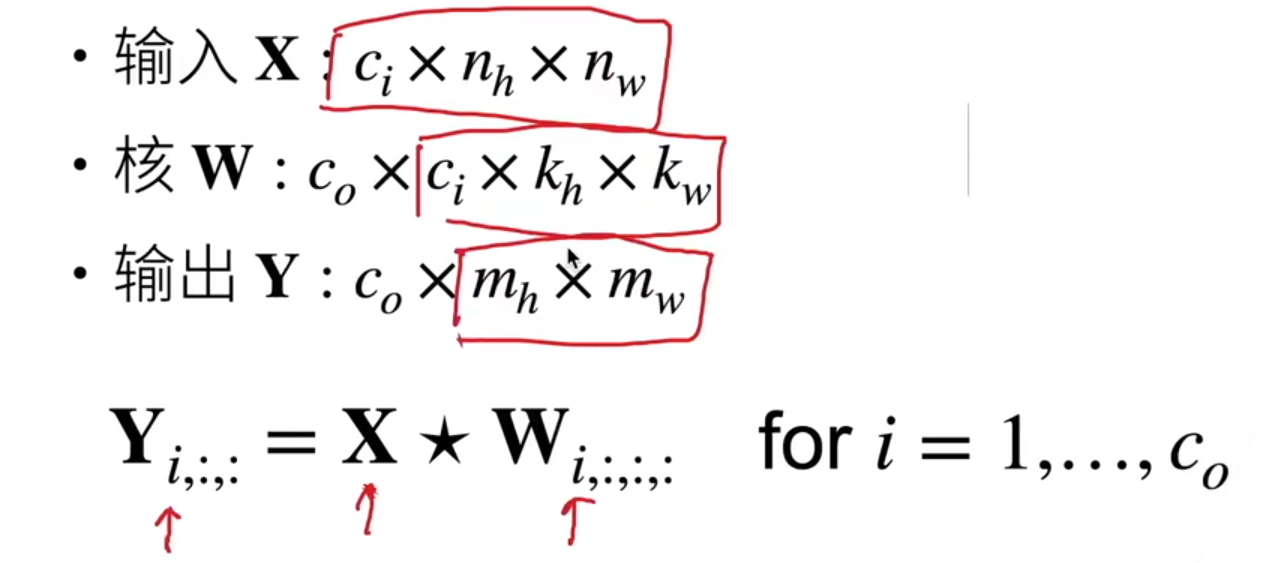
但是到目前为止我们只用到单输出通道。
多输入和输出通道,可以用多个卷积核提取不同的特定的模式,最后加权,得到一个组合的模式识别。
深度学习其实就是先用简单的卷积核识别这些最简单的纹理,然后进一步组合,得到有意义的信息。
1x1卷积层:不识别空间模式,只是融合通道(可以加权)。
1x1的卷积层可以认为是一个全连接层
-
多输入多输出通道可以用来扩展卷积层的模型。
-
当以每像素为基础应用时,1×11×1卷积层相当于全连接层。
-
1×11×1卷积层通常用于调整网络层的通道数量和控制模型复杂性。

import torch from d2l import torch as d2l # 多通道输入 def corr2d_multi_in(X,K): return sum(d2l.corr2d(x,k) for x,k in zip(X,K)) # 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起 #说白了,就是对各个通道分别做卷积,最后加和在一起 X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]], [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]]) K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]]) print(corr2d_multi_in(X, K)) def corr2d_multi_in_out(X, K): # 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。 # 最后将所有结果都叠加在一起 return torch.stack([corr2d_multi_in(X, k) for k in K], 0) # 换句话说,就是让四维的K的每一个k与X做互相关运算 K = torch.stack((K, K + 1, K + 2), 0) #把K变成一个四维的,卷积核数目为3(3通道) print(K.shape) print(K) print(corr2d_multi_in_out(X,K)) # 定义一个1x1矩阵的多输入多输出的卷积 def corr2d_multi_in_out_1x1(X, K): c_i, h, w = X.shape c_o = K.shape[0] X = X.reshape((c_i, h * w)) K = K.reshape((c_o, c_i)) # 全连接层中的矩阵乘法 Y = torch.matmul(K, X) return Y.reshape((c_o, h, w)) X = torch.normal(0, 1, (3, 3, 3)) K = torch.normal(0, 1, (2, 3, 1, 1)) print("--------------------------------------------------------------") print(X) print(K) Y1 = corr2d_multi_in_out_1x1(X, K) Y2 = corr2d_multi_in_out(X, K) assert float(torch.abs(Y1 - Y2).sum()) < 1e-6 print(Y1==Y2)
Q&A
1、很多padding,也就是在图像中填充很多的0,不会影响模型的性能。0与卷积相乘还是0,不会对网络造成太大的影响。
2、每个通道的卷积核是不一样的,不同通道的卷积核的大小是一样的。(老师口误,忘记了“大小”,意思很迷)
3、卷积层的bias用处不是很大。比如当数据不为0的时候,偏移一般等于数据平均值的负数。但是因为在工程中我们会做很多均一化操作,所以偏移在实际工程中影响不是很大。
这一节听得不是很懂,特别是输出通道为什么可以多通道,以及多通道的意义,理解不能,暂时不求甚解吧。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)