


深度学习笔记017卷积层
看到一句话,其实卷积层就是一种滤波器,放大它感兴趣的,缩小它不感兴趣的,很有道理。
二维卷积层的数学表达:

这里这个W其实就是kernel,是在这里通过这种方式学习出来的参数,表现出来的就是一个矩阵。b是偏差,通过广播机制作用给Y。

二维交叉和二维卷积,就差一个翻转的关系:
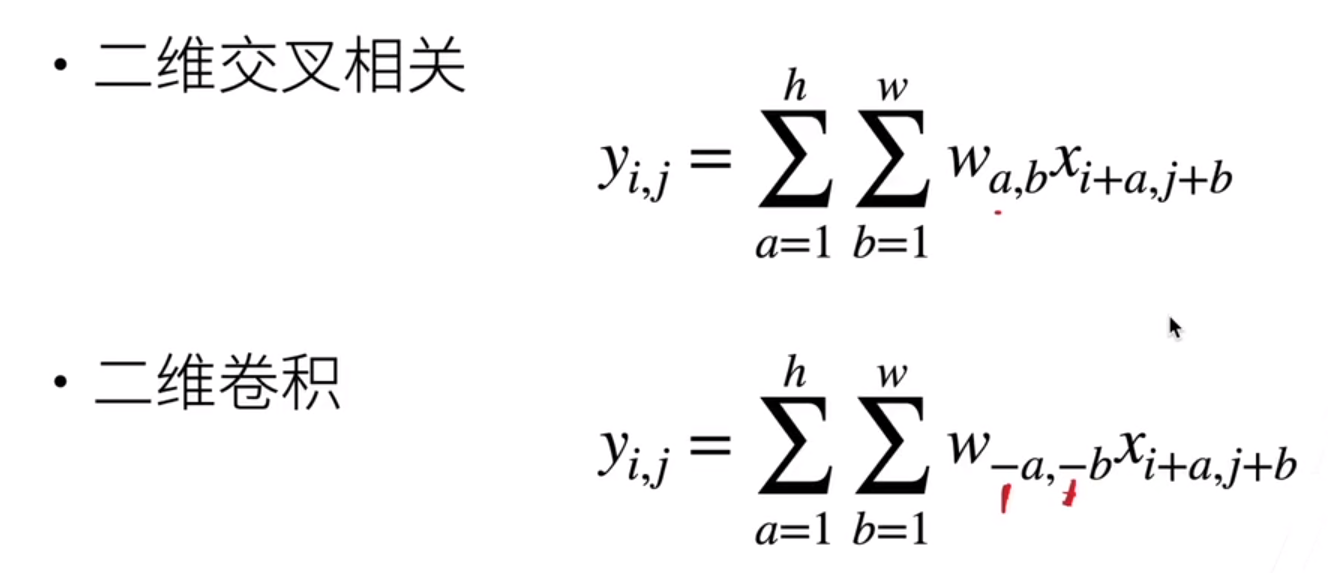
为了简单,我们把负号删掉了。所以在神经网络里虽然我们说在做卷积,其实是在做交叉相关。
图像处理领域一般都用二维的卷积层,但是一维和三维也在应用中很重要。
一维卷积:
文本、语言、时序序列
二维卷积:
视频、医学图像、气象地图
卷积层就是将输入和核矩阵进行交叉相关,再加上偏移之后,进行输出。
核矩阵和偏移是可学习的量。
核矩阵的大小是超参数。
Q&A:
1、Kernel大小主流用3x3,最多5x5。感受野不是越大越好,最终我们虽然会看到整张图,类似为什么是深度学习而不是广度学习一样,我们用大核少做几次和用小核多做几次,工作量一样,但是视野小一些会更棒。
卷积层控制输出大小的超参数:填充和步幅
填充:可以控制输出形状的减小量
步幅:可以成倍减小输出形状
填充:在输入的四周添加额外的行或列
通常利用填充,使得输出保持与输入一样的大小

步幅:是指滑行的行/列的步长,高度和宽度的步幅可以不同
步幅计算:

Q&A:
1、一般来说,填充会使得输出和输入不变,因为这样子算起来比较方便,否则需要一直想着输入输出变化的关系;
2、通常来讲,步幅常常=1,除非计算量明显太大了;
3、卷积的边长一般取奇数,因为取奇数时填充会方便一些,上下左右对称一些。但是效果上来说,奇偶差不多了。
4、机器学习本质上就是信息筛选,信息压缩,我们的信息一直都是丢失的,只要在操作,就是在丢失信息。只不过在压缩的时候,我们放大了我们感兴趣的特征。
5、一个特定的卷积层就是去匹配一种特定的纹理。
代码如下:

1 import torch 2 from torch import nn 3 from d2l import torch as d2l 4 5 6 # 定义一个计算二维相关的运算 7 def corr2d(X,K): 8 h,w=K.shape 9 Y=torch.zeros((X.shape[0]-h+1,X.shape[1]-w+1)) 10 for i in range(Y.shape[0]): 11 for j in range(Y.shape[1]): 12 Y[i,j]=(X[i:i+h,j:j+w]*K).sum() 13 return Y 14 15 16 X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) 17 K = torch.tensor([[0.0, 1.0], [2.0, 3.0]]) 18 print(corr2d(X, K)) 19 20 21 # 实现二维卷积层 22 class Conv2D(nn.Module): 23 def __init__(self,kernel_size): 24 super().__init__() 25 self.weight=nn.Parameter(torch.rand(kernel_size)) 26 self.bias=nn.Parameter(torch.zeros(1)) 27 28 def forward(self,x): 29 return corr2d(x,self.weight)+self.bias 30 31 32 # 简易应用:检测图像不同颜色的边缘 33 X=torch.ones((6,8)) #z做了一个有两条竖线边缘的矩阵 34 X[:,2:6]=0 35 print(X) 36 K=torch.tensor([[1.0,-1.0]]) 37 Y=corr2d(X,K) 38 print(corr2d(X,K)) 39 40 # # 类比做一个检测竖直边缘的算子 41 # X=torch.ones((10,8)) #z做了一个有两条竖线边缘的矩阵 42 # X[3:7,:]=0 43 # print(X) 44 # K=torch.tensor([[1.0],[-1.0]]) 45 # print(corr2d(X,K)) 46 47 # 学习由X生成的Y的卷积核 48 conv2d=nn.Conv2d(1,1,kernel_size=(1,2),bias=False) 49 X=X.reshape((1,1,6,8)) #将二维图片转换为四维,第一个是通道,第二个是样本维度(样本数),第三四个是长宽 50 Y=Y.reshape(1,1,6,7) 51 52 for i in range(10): 53 Y_hat=conv2d(X) 54 l=(Y_hat-Y)**2 55 conv2d.zero_grad() 56 l.sum().backward() 57 conv2d.weight.data[:]-=3e-2*conv2d.weight.grad 58 if(i+1)%2==0: 59 print(f'batch {i+1}, loss {l.sum():.3f}') 60 61 print(conv2d.weight.data.reshape((1,2)))# 不reshape就会输出四维 62 63 64 # 2维变为4维,用于下面的函数 65 XX=torch.zeros((2,3)) 66 print(XX) 67 XX=XX.reshape((1,1)+XX.shape) 68 print(XX) 69 70 # 填充和步幅 71 def comp_conv2d(conv2d,X): 72 X=X.reshape((1,1)+X.shape) #2维变为4维 73 Y=conv2d(X) 74 return Y.reshape(Y.shape[2:]) 75 76 conv2d=nn.Conv2d(1,1,kernel_size=3,padding=1) # 填充为1,上下左右各填充一行 77 X=torch.rand(size=(8,8)) 78 print(comp_conv2d(conv2d,X).shape) 79 80 conv2d=nn.Conv2d(1,1,kernel_size=(5,3),padding=(2,1)) # 前面为上下,后面为左右 81 print(comp_conv2d(conv2d,X).shape) 82 83 conv2d=nn.Conv2d(1,1,kernel_size=3,padding=1,stride=2) # 步幅为2 84 X=torch.rand(size=(8,8)) 85 print(comp_conv2d(conv2d,X).shape) 86 87 conv2d=nn.Conv2d(1,1,kernel_size=(3,5),padding=(0,1),stride=(3,5)) # 填充为1,上下左右各填充一行 88 X=torch.rand(size=(8,8)) 89 print(comp_conv2d(conv2d,X).shape)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!