


深度学习笔记015GPU的安装与使用
我的thinkpad没有GPU(哭哭惹);
我家里那台顶配偏科机也没有GPU!!!(放声大哭);
所以只能在google上玩玩了,唉。
倒也还可以,最起码是免费的。
因为我没有GPU,自然也装不了cuda……
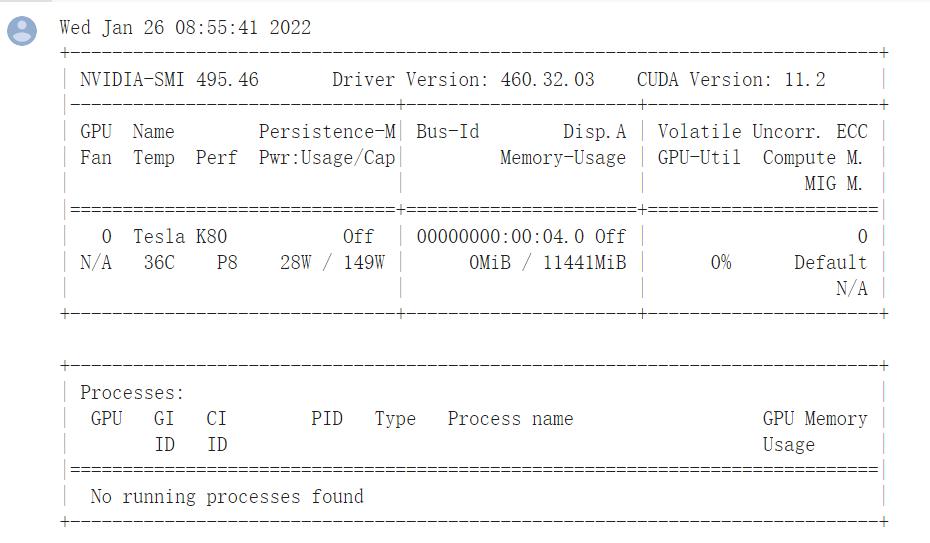
关于上述GPU参数:https://www.cnblogs.com/testzcy/p/13298748.html
但是咱可以用torch里面的api查看thinkpad:
1 print(torch.cuda.is_available()) 2 3 print(torch.device('cpu'),torch.cuda.device('cuda'),torch.cuda.device('cuda:1')) 4 5 # 查询可用gpu的数量: 6 print(torch.cuda.device_count())

在google上:

接下来是两个比较常用的GPu函数:
1 # 如果有gpu,就返回GPU(i),否则就返回CPU() 2 def try_gpu(i=0): 3 if torch.cuda.device_count()>=i+1: 4 return torch.device(f'cuda:{i}') 5 return torch.device('cpu') 6 7 # 返回所有GPU,如果没有GPU,就返回cpu 8 def try_all_gpus(): 9 devices=[torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())] 10 return devices if devices else [torch.device('cpu')] 11 12 # 测试一下 13 print(try_gpu()) 14 print(try_gpu(10)) 15 print(try_all_gpus())

1 # 查询张量所在的设备 2 x=torch.tensor([1,2,3]) 3 x.device

# 将X存储在GPU上 X=torch.ones(2,3,device=try_gpu()) X

# 可以给try_gpu里写编号,这里我只有一个gpu,就不写了 Y=torch.ones(2,3,device=try_gpu()) Y

# 在做运算的时候,必须保证两个变量都在同一个gpu上 # 这里假设Y在第一块GPU上,为了运算,我要将Y移动到第0块GPU Z=Y.cuda(0) # 参数为目标gpu编号 X+Z # 注意,X和Y本应可以在不同的device上存储,但是在GPU之间,或者GPu与CPU之间挪动数据,非常慢,会造成严重的性能问题。 # 因此,为了保证性能,设计者禁止了在跨设备之间的数据不允许运算。

Z.cuda(0) is Z # 自己往自己的设备copy不会发生任何事情,这也是性能的考虑

重点来了,神经网络与GPU:
# 神经网络与GPU net=nn.Sequential(nn.Linear(3,1)) net=net.to(device=try_gpu()) #将所有的参数在第0号GPU上copy一份,日后都是在第0号GPU运行 net(X)

net[0].weight.data.device

购买GPU
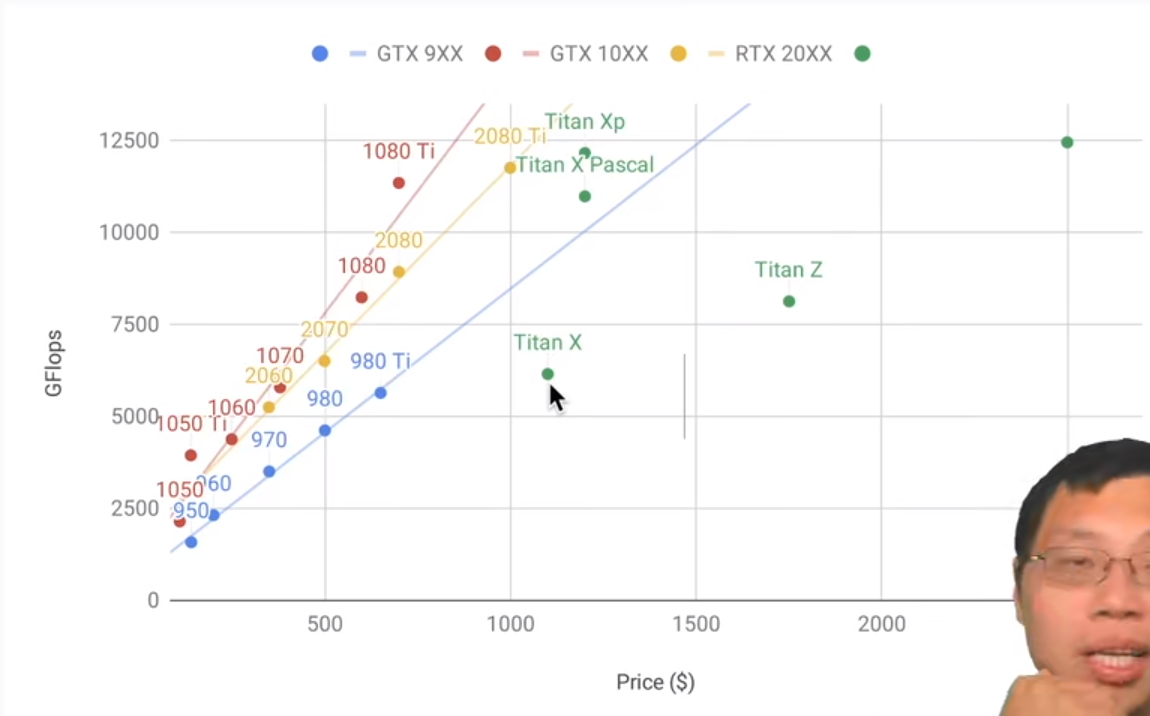
对于GPU,3件事比较重要:
1、现存
2、计算能力(每秒钟能完成的浮点数运算)
3、价格
Q&A
现存不够的时候,可以把batch_size调小;或者把模型规模调小。
GPU使用可以满负荷,但不要过热(大于80),容易烧卡。
一般使用gpu训练,data在net之前to gpu比较好。
