

深度学习笔记008MultilayerPerceptron多层感知机AssertionError
今天学的是感知机,代码放在下面,总结了几个问题。
1. MLP多层感知机与SVM支持向量机的区别:
1.MLP需要设置W和b,但是SVM对参数不敏感,所以相对方便一些;
2.SVM在数学上解释性更强;
3.SVM优化相对容易。
2.为什么是深度学习,而不是广度学习?——直觉解释,这玩意不会有理论依据
只有一个原因,广度学习不好训练,一口气吃成一个胖子,非常容易过拟合。
学习,应该从简单的开始学,从和输入层差不多的地方开始学,慢慢深入深入;
而不是把所有东西复杂的简单的一起扔到你的大脑。
3.三种函数的本质:

4.单层感知机的局限性
当初因为单层感知机不能解决XOR问题,导致了AI领域的第一次凛冬。
5. 极大似然估计讲的不错的视频:
https://www.bilibili.com/video/BV1Hb4y1m7rE/?spm_id_from=333.788.recommend_more_video.-1
源码如下:
感知机从0实现
1 import torch 2 from torch import nn 3 from d2l import torch as d2l 4 5 # 感知机从0实现 6 7 batch_size=256 8 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) #又是用这个数据集 9 10 num_inputs,num_outputs,num_hiddens=784,10,256 #输入输出是固定的,总像素784,10类,隐藏层大小自己定 11 # 定义参数,W1是第一层的权重矩阵,行列为输入层、隐藏层,W2自然就是隐藏层和输出层了;b则为输出的偏置矩阵 12 W1=nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad=True)*0.01) 13 b1=nn.Parameter(torch.zeros(num_hiddens,requires_grad=True)) 14 W2=nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True)*0.01) 15 b2=nn.Parameter(torch.zeros(num_outputs,requires_grad=True)) 16 17 params=[W1,b1,W2,b2] 18 19 # 激活函数,哈哈哈哈哈太简单沐神都轻蔑的笑了 20 def relu(X): 21 a=torch.zeros_like(X) 22 return torch.max(X,a) 23 24 # 定义网络 25 def net(X): 26 X=X.reshape((-1,num_inputs)) # 这里这个-1代表我不知道是几行(其实就是1行) 27 H=relu(X@W1+b1) 28 return H@W2+b2 29 30 num_epochs,lr=10,0.1 31 updater=torch.optim.SGD(params,lr=lr) 32 loss=nn.CrossEntropyLoss() 33 d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater) 34 d2l.plt.show()
感知机简洁实现
1 # 感知机简洁实现 2 net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10)) #扁平化,第一层,激活函数,第二层 3 4 # 权重初始化 5 def init_weights(m): 6 if type(m)==nn.Linear: 7 nn.init.normal_(m.weight,std=0.01) 8 net.apply(init_weights) 9 10 batch_size,lr,num_epochs=256,0.1,10 11 loss=nn.CrossEntropyLoss() 12 trainer=torch.optim.SGD(net.parameters(),lr) 13 14 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) 15 16 d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer) 17 d2l.plt.show()
从0实现(左侧)与简洁实现(右侧)的结果:
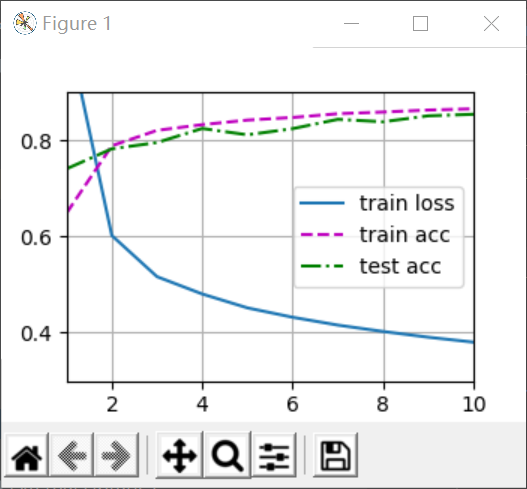
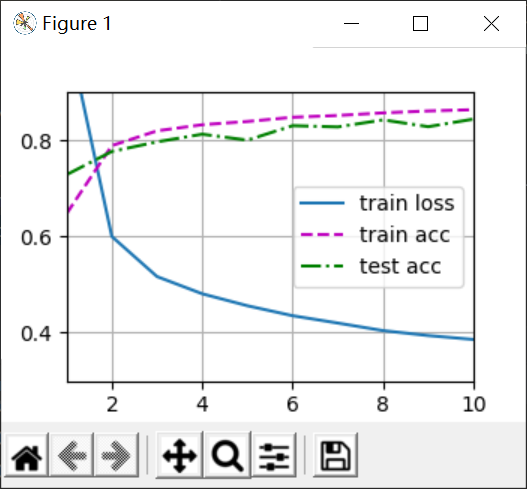
可以发现几乎没有什么区别,但是做简洁实现的时候我发现了一个问题,就是W不乘以0.01,会让训练的loss减小地非常缓慢,以至于在10次迭代中,loss不能降低到0.5,而Torch内部的训练函数输出时有一个断言,assert loss<0.5,这时候输出图像就会产生断言错误,如下:

解决这个问题的方式有两个,一个是用try catch将断言异常抛出:https://www.cnblogs.com/fanjc/p/10072556.html
另一个就是把loss训练的再小一些,因为这个断言本身就是为了我们结果的合理性写的,所以可以改大epoch增加迭代次数,比如改成30次,可以将loss降低到0.5左右如下:
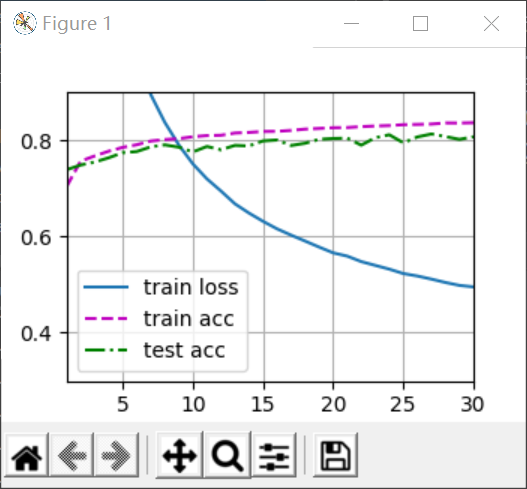
这才是正解。
但是我个人其实没有理解透彻为什么在W上缩小100倍,就能够加快训练速度,请看到这里的大佬在评论区指教一下谢谢哦~

