
分布式消息队列:如何保证消息的顺序性
顺序会错乱的俩场景:
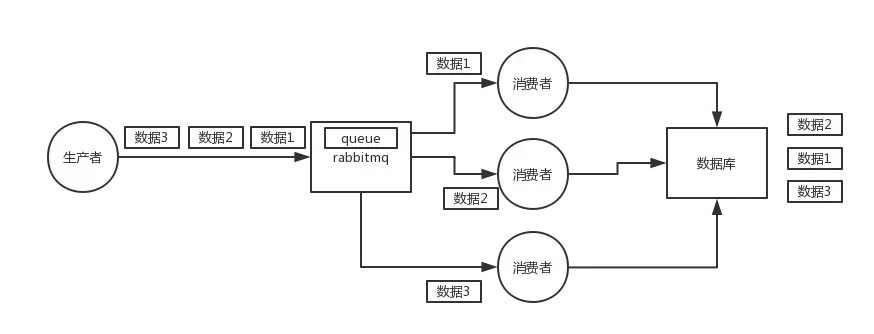
RabbitMQ:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者2先执行完操作,把 data2 存入数据库,然后是 data1/data3。这不明显乱了。

Kafka:比如说建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。

rabbitmq保证数据的顺序性
如果存在多个消费者,那么就让每个消费者对应一个queue,然后把要发送的数据全都放到一个queue,这样就能保证所有的数据只到达一个消费者从而保证每个数据到达数据库都是顺序的
rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理

Kafka
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。

立志如山 静心求实

 浙公网安备 33010602011771号
浙公网安备 33010602011771号