
迁移学习讲解、举例使用ResNet50进行迁移学习----猫狗分类
一、概念介绍
迁移学习
是指通过将一个已经在某一任务上训练好的模型,应用于另一个任务上。在迁移学习中,一般会将预训练模型的权重加载到新的模型中,然后对新的模型进行微调。
预训练模型
是指在大规模的数据集上训练好的模型这些模型通常具有很好的泛化能力,可以应用于各种任务,如图像分类、目标检测、语音识别等。
预训练模型可以作为迁移学习的基础,将其应用于新的任务中,可以显著提高模型的效果,并减少训练时间和计算资源的消耗。
微调
是指在新的数据集上对预训练模型进行进一步训练,以适应新的任务。微调通常包括两个步骤:
- 首先,固定预训练模型的一部分层的权重,只对新加入的层进行训练;
- 其次,逐步解除固定层的权重,继续对整个模型进行微调,以进一步提高模型的性能。
如下:
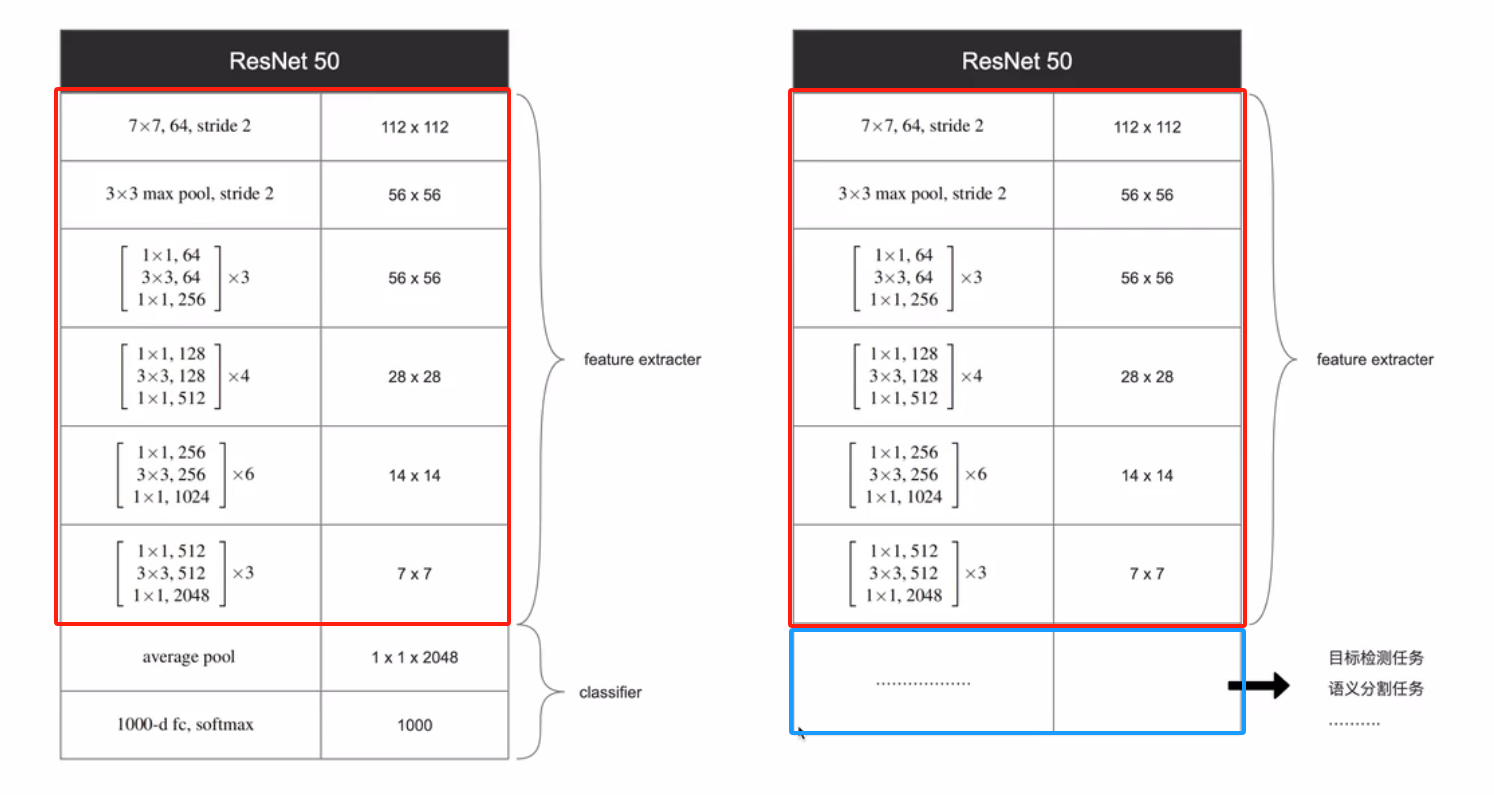
以ResNet50为例,上边是特征提取器,下边是分类器。特征提取器已经有很好的的泛化能力,只要将分类器(池化和全连接层)去掉,换成自己的功能任务,比如目标检测、语义分割等。
二、迁移学习的操作过程
1、模型查看、参数查看
- net.modules()、net.named modules()
- net.children()、net.named_children()
- net.parameters()、net.named_parameters()
- net.state_dict()
先上完整代码,如下:
1)net.modules()
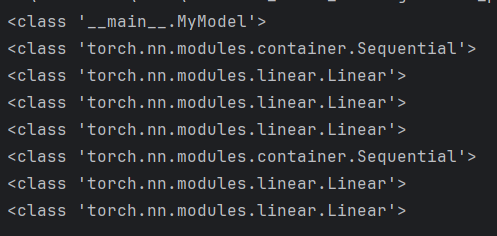
for layer in net.modules(): print(type(layer))
print(type(layer))打打印如下:
for layer in net.modules():
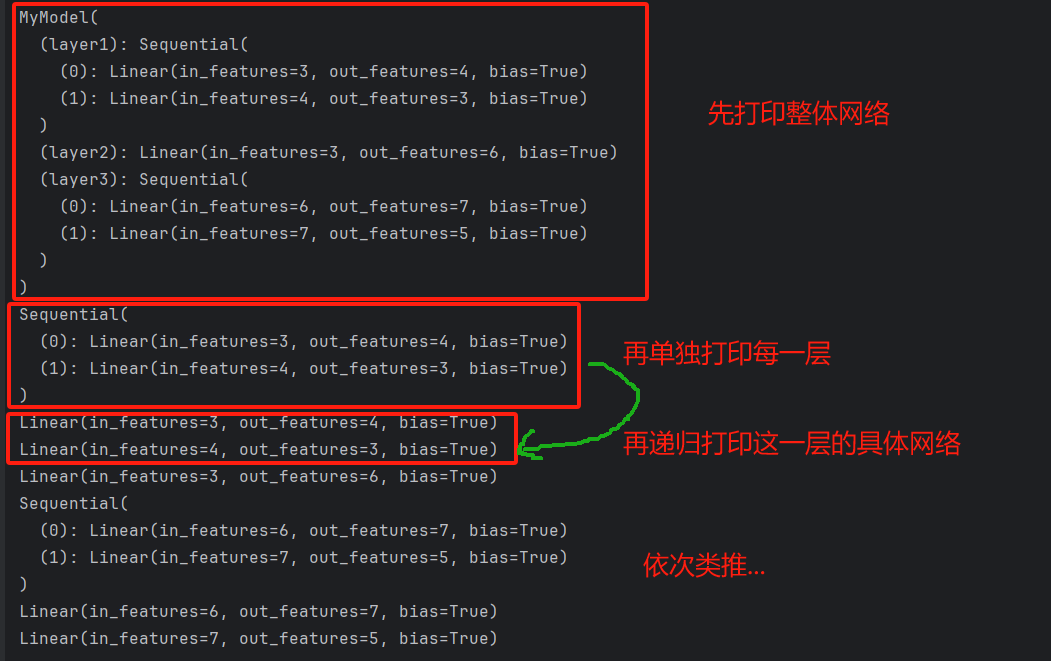
print(layer)
print(layer)打打印如下:
2)net.named_modules()
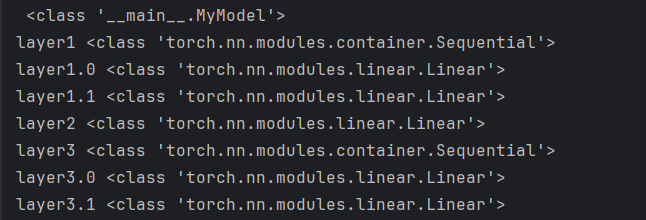
for name, layer in net.named_modules():
print(name, type(layer))
# print(name, layer)
print(name, type(layer))打印如下:
for name, layer in net.named_modules():
# print(name, type(layer))
print(name, layer)
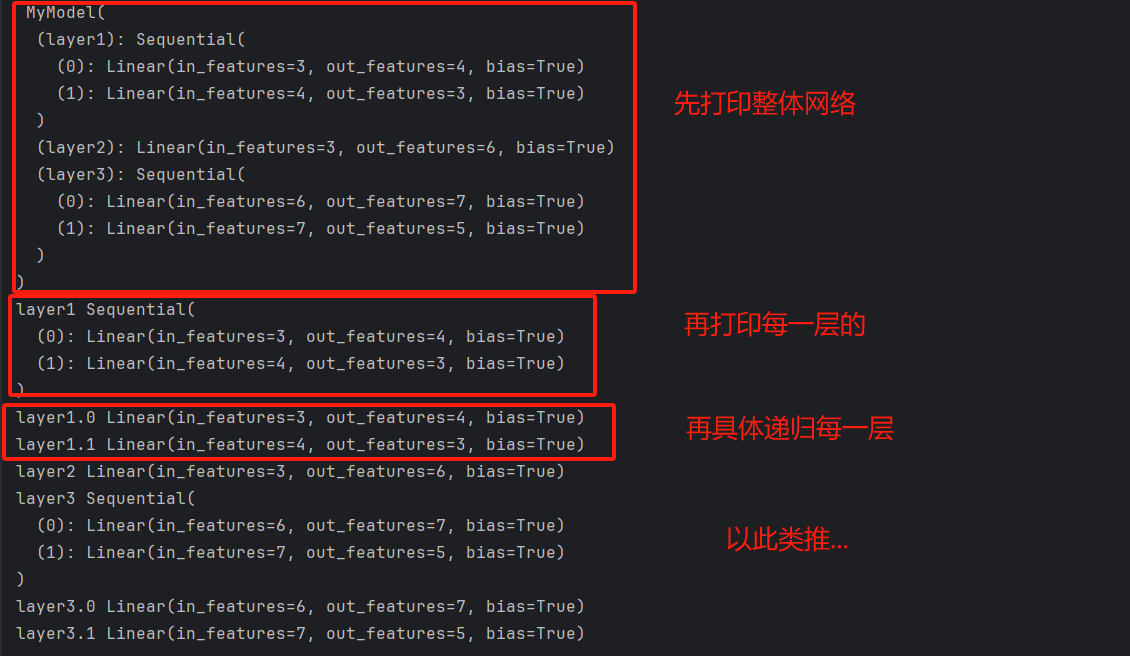
3)net.children() 不会递归打印每一层,只打印一遍
for layer in net.children():
print(layer)
打印如下:
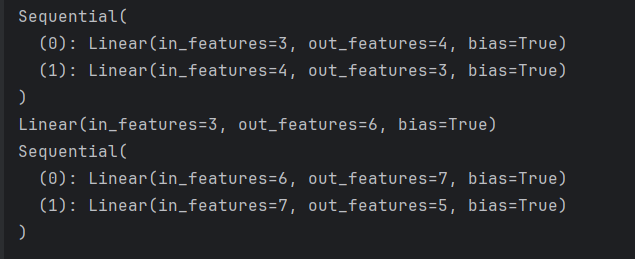
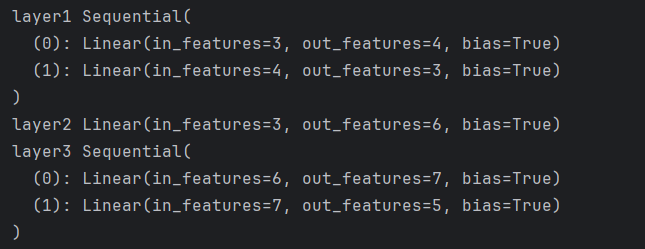
4)net.named_children()
for name, layer in net.named_children():
print(name, layer)
打印如下:
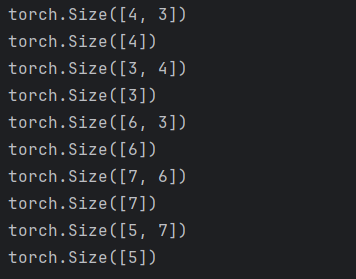
5)net.parameters()
for param in net.parameters():
print(param.shape)
打印如下:
6)net.named_parameters()
for name, param in net.named_parameters():
print(name, param.shape)
# print(name, param)
打印如下 :
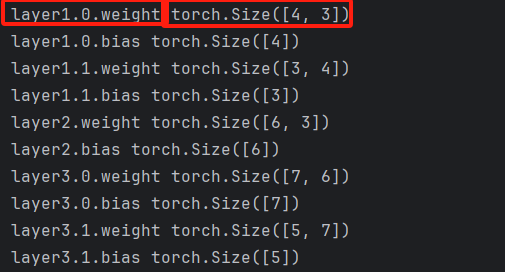
7)net.state_dict()
for key, value in net.state_dict().items():
print(key, value.shape)
# print(key, value)
打印如下:
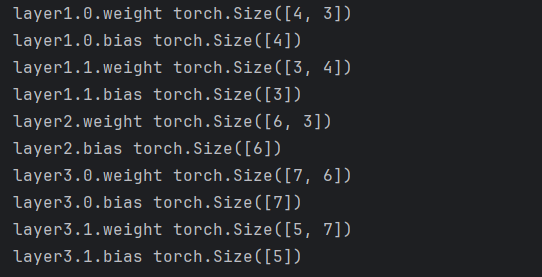
效果和net.named_parameters()一样。
8)完整代码
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer1 = torch.nn.Sequential(
torch.nn.Linear(3, 4),
torch.nn.Linear(4, 3)
)
self.layer2 = torch.nn.Linear(3, 6)
self.layer3 = torch.nn.Sequential(
torch.nn.Linear(6, 7),
torch.nn.Linear(7, 5)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
net = MyModel()
# print(net)
'''
net.modules()、net.named_modules()
会递归打印每一层
'''
# for layer in net.modules():
# print(type(layer))
# print(layer)
# for name, layer in net.named_modules():
# # print(name, type(layer))
# print(name, layer)
'''
net.children()、net.named_children()
这个不会递归打印每一层
'''
# for layer in net.children():
# print(layer)
# for name, layer in net.named_children():
# print(name, layer)
'''
net.parameters()、net.named_parameters()
'''
# for param in net.parameters():
# print(param.shape)
# print(param)
# for name, param in net.named_parameters():
# print(name, param.shape)
# # print(name, param)
'''
net.state_dict() 打印效果和net.named_parameter一样
'''
for key, value in net.state_dict().items():
print(key, value.shape)
# print(key, value)
2、模型下载、模型加载、模型保存、参数保存、
1)下载模型
- 只下载模型,权重参数需要自己训练,如:alexnet = models.alexnet(weights=None)
- 下载模型,同时加载预训练好权重参数,如:resnet50 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
①只下载模型,权重参数需要自己训练(不是没有权重参数,而是都是初始的参数,需要自己训练)
import torchvision.models as models# pytorch官网提供好的预训练模型:https://pytorch.org/vision/stable/models.html#classification
alexnet = models.alexnet(weights=None) # 只下载模型,权重参数需要自己训练(不是没有权重参数,而是都是初始的参数,需要自己训练)
print(alexnet)
打印如下:
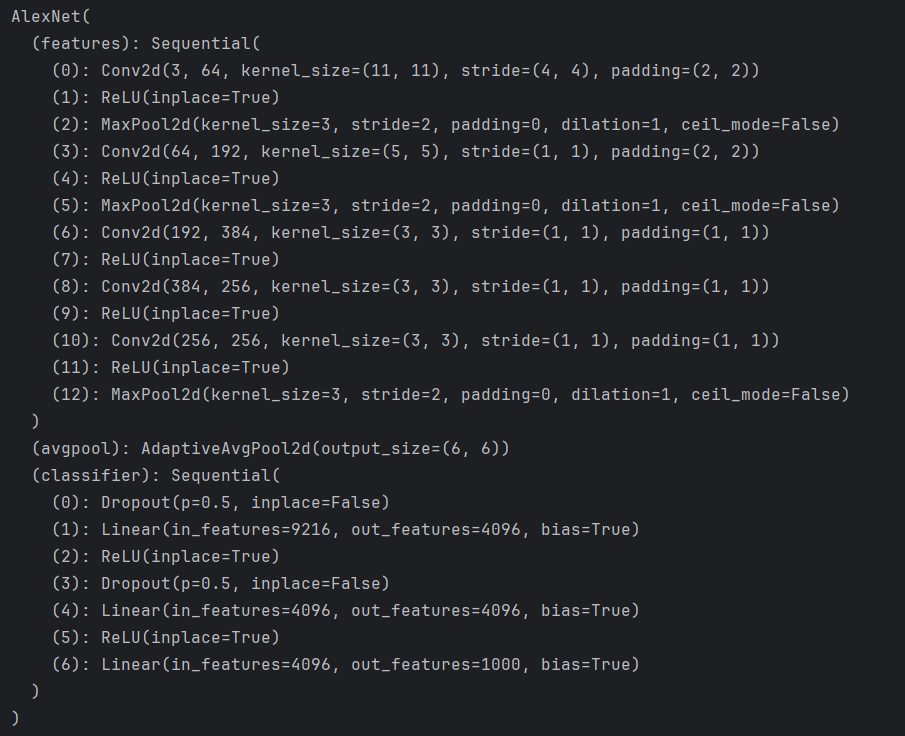
②下载模型,同时加载预训练好权重参数
import torchvision.models as models
resnet50 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
print(resnet50)
打印如下(截图只截取了部分,太长了):
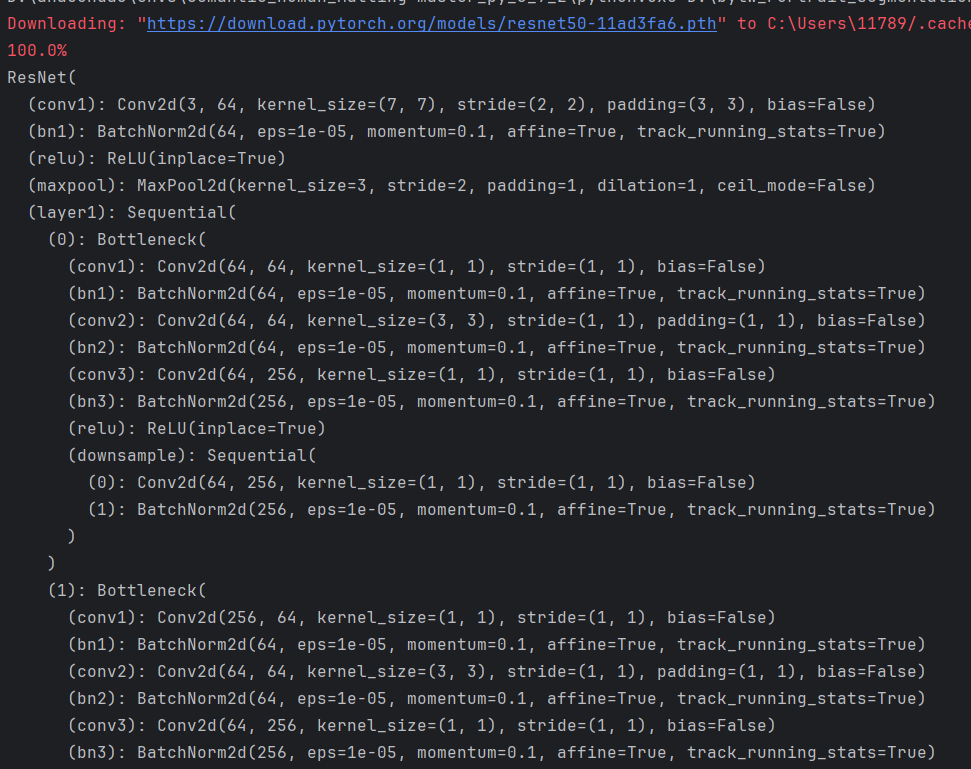
③pretrained=True
#如果pretrained设置为False:模型将使用随机初始化的权重进行训练,这意味着它不会从任何预先存在的知识中受益。
resnet = models.resnet50(pretrained=True)
2)保存模型、加载模型
- 仅保存模型的参数,如: torch.sava(resnet50.state_dict(), 'resnet50_weight.pth')
- 已有模型,加载预训练参数,如:resnet50.load_state_dict(torch.load('resnet50_weight.pth'))
- 保存模型 + 参数,如:torch.save(resnet50, 'resnet50.pth')
- 加载模型 + 参数, 如:net = torch.load('resnet50.pth')
# 仅保存模型参数
torch.sava(resnet50.state_dict(), 'resnet50_weight.pth')
# 已有模型,加载预训练参数
resnet50 = models.resnet50(weights=None)
resnet50.load_state_dict(torch.load('resnet50_weight.pth'))
###########################################################################
# 保存模型 + 参数
torch.save(resnet50, 'resnet50.pth')
# 加载模型 + 参数
net = torch.load('resnet50.pth')
print(net)
3)完整代码
import torchvision.models as models
from torchsummary import summary
import torch
# pytorch官网提供好的预训练模型:https://pytorch.org/vision/stable/models.html#classification
'''
下载模型
'''
# alexnet = models.alexnet(weights=None) # 只下载模型,权重参数需要自己训练(不是没有权重参数,而是都是初始的参数,需要自己训练)
# print(alexnet)
resnet50 = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
print(resnet50)
'''
保存模型 / 保存模型参数
'''
# 仅保存模型参数
torch.sava(resnet50.state_dict(), 'resnet50_weight.pth')
# 保存模型 + 参数
torch.save(resnet50, 'resnet50.pth')
'''
加载模型
'''
# 加载模型 + 参数
net = torch.load('resnet50.pth')
print(net)
# 已有模型,加载预训练参数
resnet50 = models.resnet50(weights=None)
resnet50.load_state_dict(torch.load('resnet50_weight.pth'))
3、模型修改
- 删除层
- 修改层
- 添加层
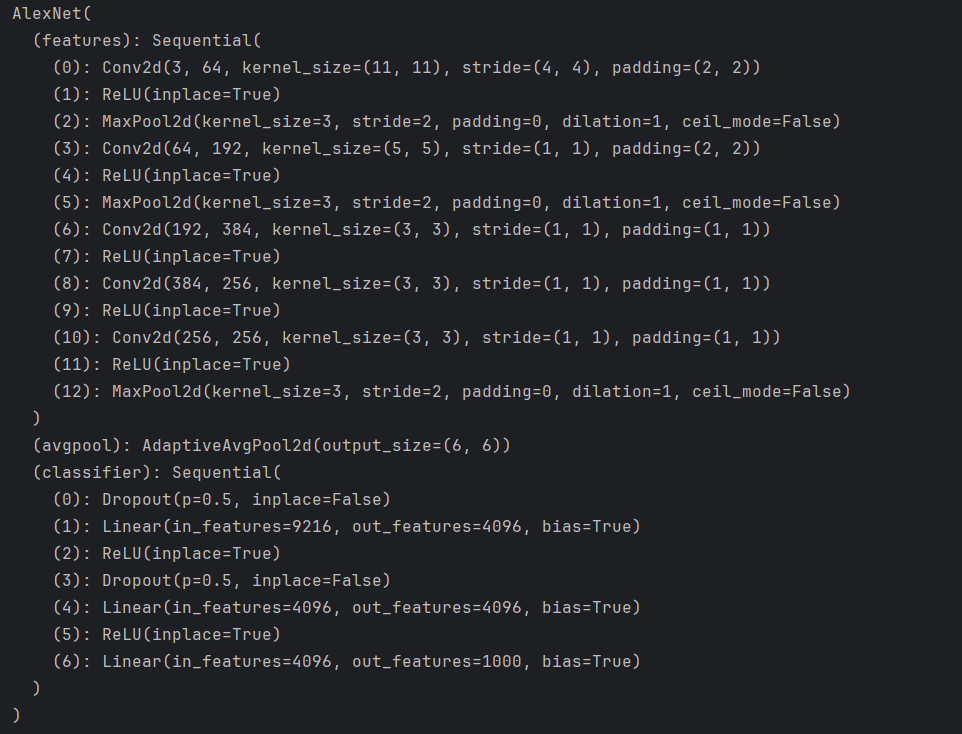
在操作之前先打印一下原始网络,如下:
import torchvision.models as models
alexnet = models.alexnet(weights=None)
print(alexnet)
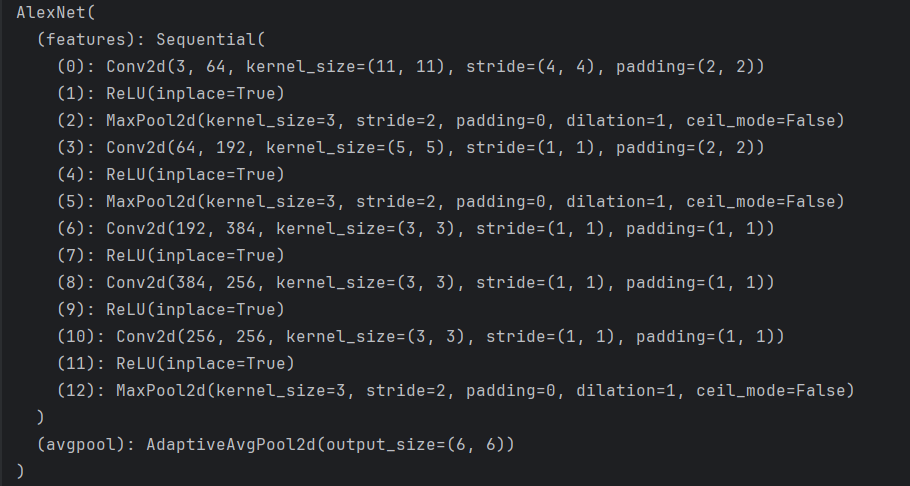
1)删除层
① 删除网络的最后一层
# 1、删除网络的最后一层
del alexnet.classifier
print(alexnet)
如下:
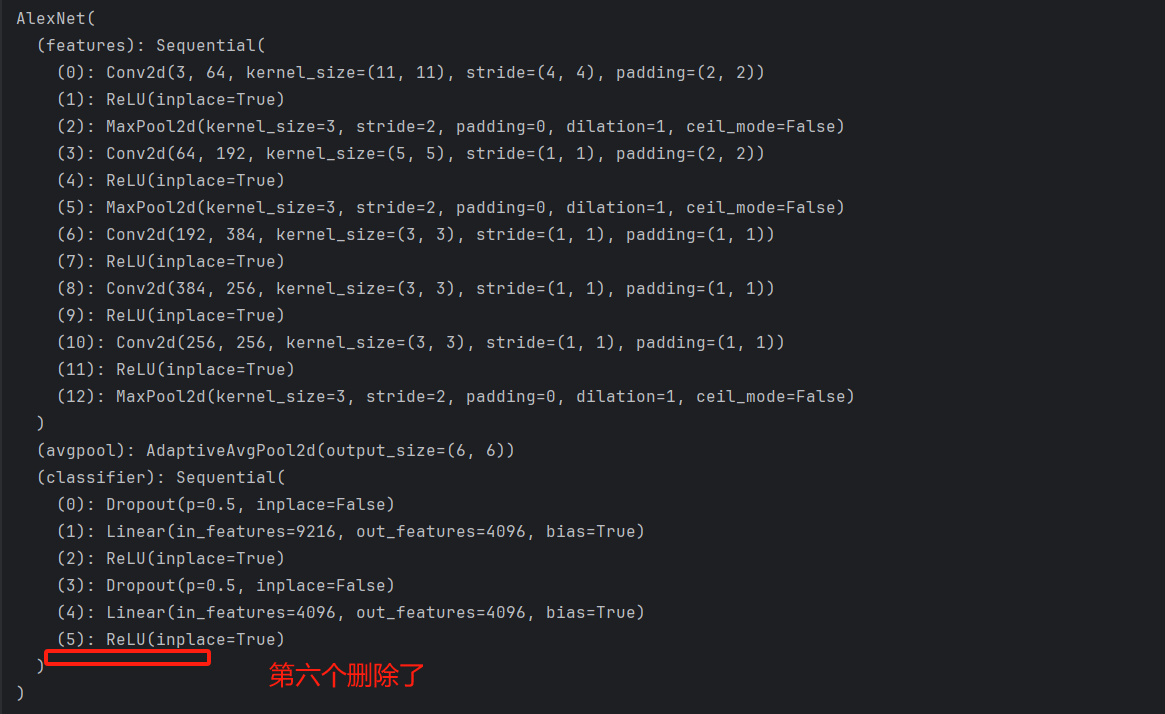
②删除具体某一层的第几个网络
# 删除网络某一层的第几个网络
del alexnet.classifier[6]
print(alexnet)
打印如下:
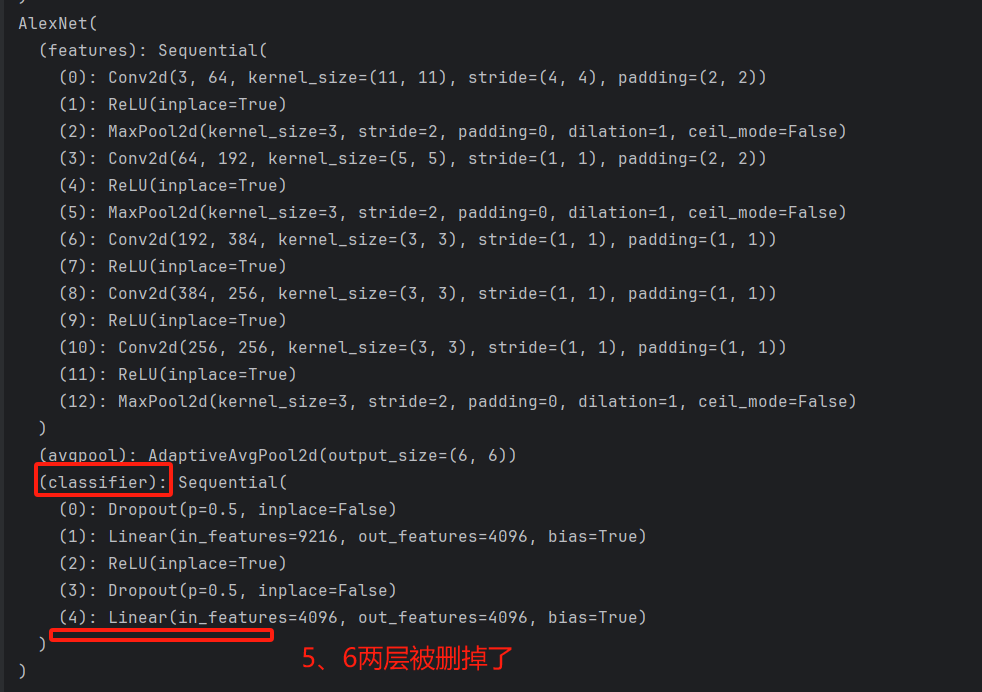
③切片操作删除某层网络最后几层
# 删除classifier网的最后2层
alexnet.classifier = alexnet.classifier[:-2]
print(alexnet)
打印如下:
2)修改层
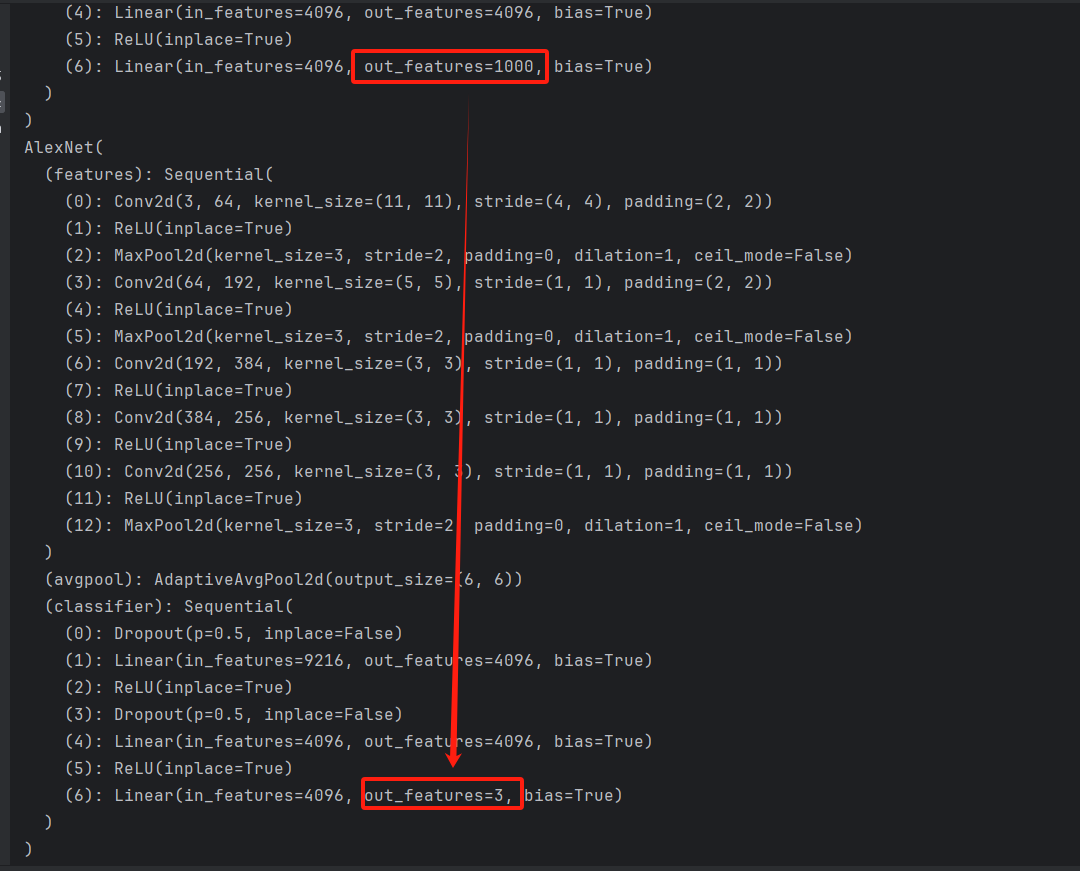
# 之前是1000分类,现在改成3分类
alexnet.classifier[6] = nn.Linear(in_features=4096, out_features=3)
print(alexnet)
打印如下:
3)增加层
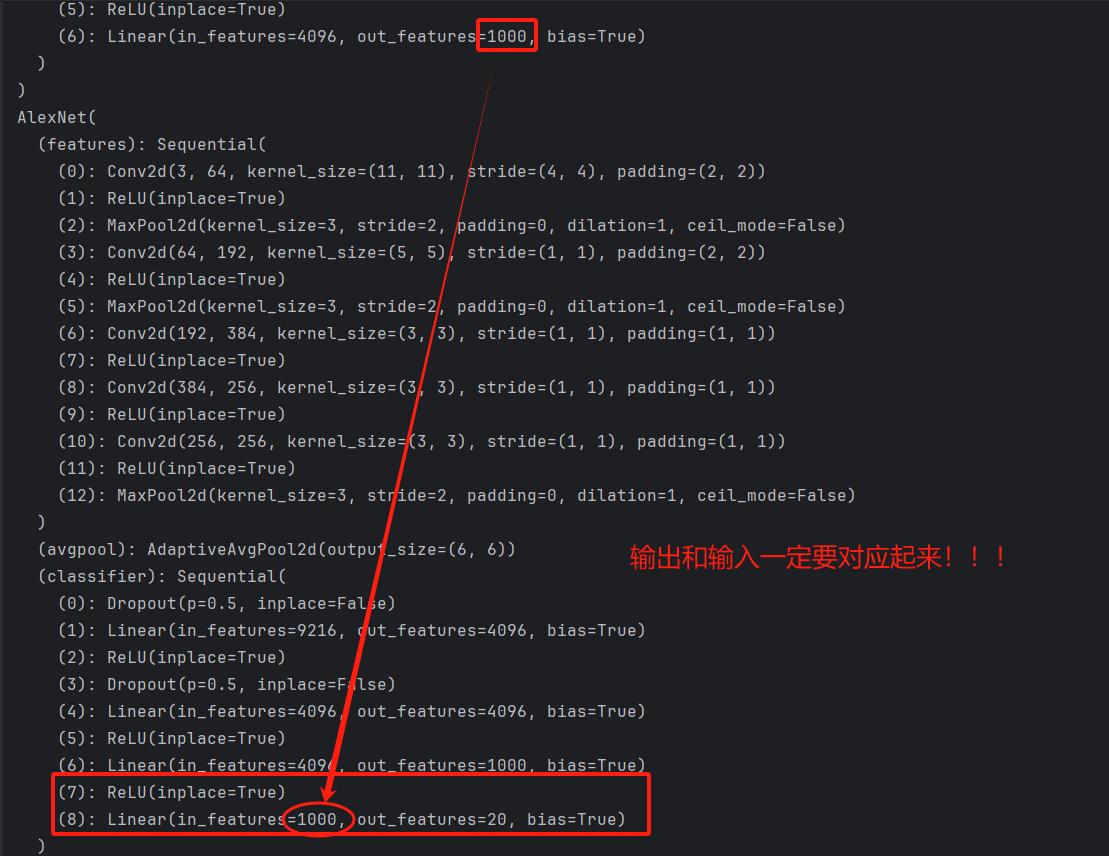
①某一层增加几层
# 增加两层,名称分别是7和8 这里相当于多了一层全连接,输出20个类别
alexnet.classifier.add_module('7', nn.ReLU(inplace=True))
alexnet.classifier.add_module('8', nn.Linear(in_features=1000, out_features=20))
print(alexnet)
打印如下:
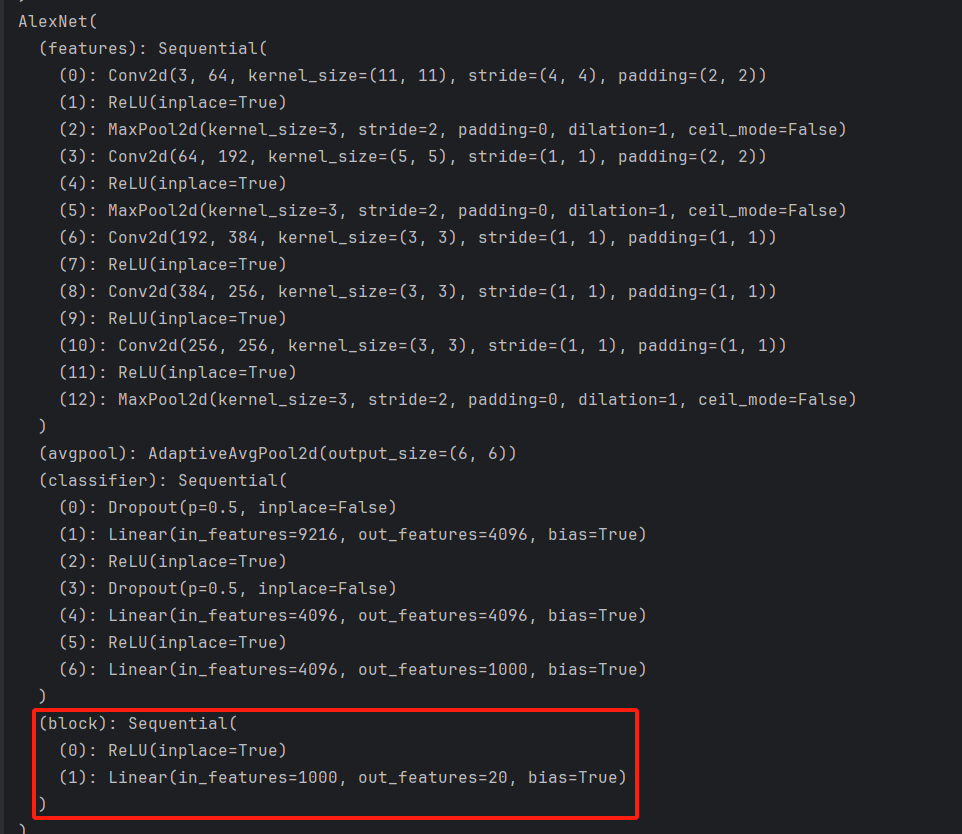
②整个网络增加几层
# 整个网络增加几层
block = nn.Sequential(
nn.ReLU(inplace=True),
nn.Linear(in_features=1000, out_features=20)
)
alexnet.add_module('block', block)
print(alexnet)
打印如下:
4、参数冻结、解冻
在迁移学习中,参数冻结(freezing)是指保持网络中的某些层(通常是预训练网络的底层)的参数不变,而解冻(unfreezing)并进行微调(fine-tuning)则是指在这些层上继续进行训练以更好地适应新的任务。
以下是进行参数冻结和解冻微调的一般步骤:
参数冻结
-
加载预训练模型:首先,你需要加载一个预训练的模型,例如ResNet50。
-
冻结模型参数:确定你想要冻结的层,并设置它们的
requires_grad属性为False。这表示在训练过程中,这些层的参数将不会被更新。
# 假设model是你的预训练模型
for param in model.parameters():
param.requires_grad = False # 冻结所有参数
# 或者,如果你只想冻结特定层,可以这样做:
for layer in model.children():
if isinstance(layer, torch.nn.Conv2d): # 例如,只冻结卷积层
for param in layer.parameters():
param.requires_grad = False
解冻并进行微调
- 解冻特定层:确定你想要解冻并进行微调的层,并将这些层的
requires_grad属性设置为True。
# 假设你想解冻模型的最后几层(例如,这里只解冻FC全连接层)
for layer in model.fc.parameters(): # fc是模型的全连接层
layer.requires_grad = True
- 创建优化器:创建一个优化器,并将需要微调的层的参数传递给它。
# 只优化解冻的层
optimizer = torch.optim.Adam(
[param for param in model.parameters() if param.requires_grad], lr=0.001
)
# 或者 只优化明确解冻层(如FC全连接层)
optimizer = torch.optim.Adam(resnet.fc.parameters(), lr=0.001)
- 训练模型:使用你的训练数据和解冻的层进行模型训练。在训练过程中,只有那些
requires_grad=True的层会更新其参数。
# 训练循环(伪代码)
for epoch in range(num_epochs):
for inputs, targets in dataloader:
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, targets) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
通过这种方式,你可以在迁移学习中利用预训练模型的强大特征提取能力,并通过微调解冻的层来使模型更好地适应你的特定任务。这通常可以加速训练过程并提高模型在新任务上的性能。
三、使用ResNet50进行迁移学习----猫狗分类
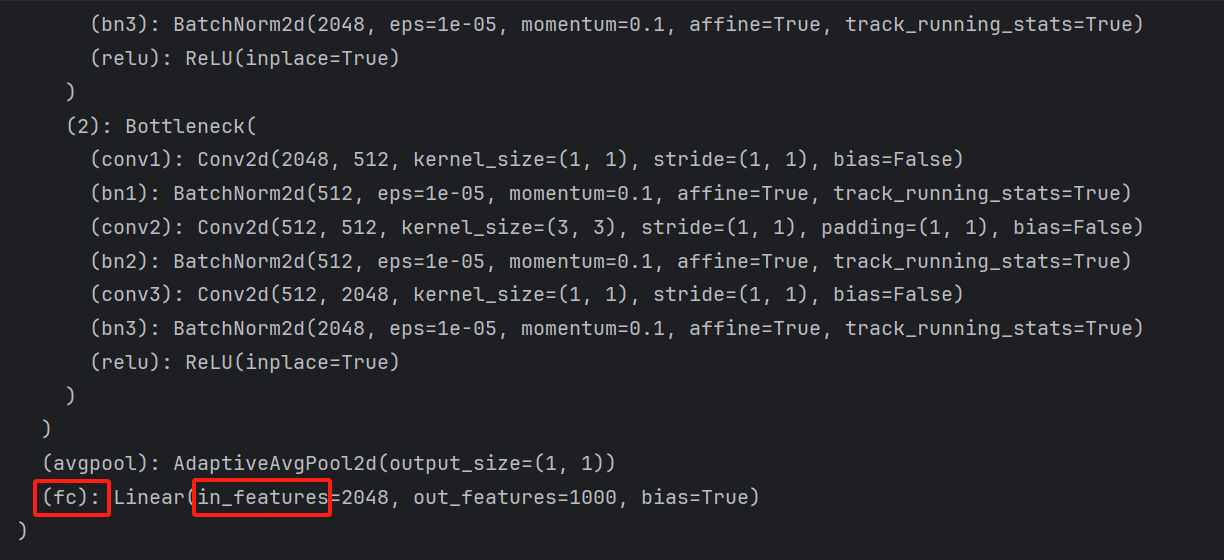
替换最后一层全连接层,将分类类别数替换
# 加载预训练的ResNet50模型
model = models.resnet50(pretrained=True)
# 冻结预训练模型的参数,这样我们在训练时只会更新最后一层的参数
for param in resnet.parameters():
param.requires_grad = False
# 获取最后一层全连接层的输入特征数量
num_ftrs = model.fc.in_features
# 替换最后一层全连接层以适应新的分类任务(猫狗二分类)
model.fc = nn.Linear(num_ftrs, len(class_names))
冻结预训练模型的参数,只优化最后一层,这里只解冻最后一层fc全连接层,如下:
# 假设你想解冻模型的最后几层(例如,这里只解冻FC全连接层的参数)
for layer in model.fc.parameters(): # fc是模型的全连接层
layer.requires_grad = True
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(resnet.fc.parameters(), lr=0.001)
如果想整体微调,则:
# 如果我们想要微调整个网络,可以取消下面这行的注释
for param in resnet.parameters():
param.requires_grad = True
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
# optimizer = torch.optim.Adam(resnet.fc.parameters(), lr=0.001) # 只优化最后一层
# 如果微调整个网络,则使用:
optimizer = torch.optim.Adam(resnet.parameters(), lr=0.001)
完整代码,如下:
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
# 数据预处理:训练集需要数据增强,验证集则不需要
data_transforms = {
'train': transforms.Compose([
# 随机裁剪和翻转用于数据增强
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
# 转换为Tensor并进行归一化
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
# 验证集只需调整大小和中心裁剪
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 设置数据集路径
data_dir = 'path_to_your_dataset' # 请将此路径替换为你的数据集所在路径
# 加载训练和验证数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: DataLoader(image_datasets[x], batch_size=32, shuffle=True, num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes # 获取类别名称
# 加载预训练的ResNet50模型
model = models.resnet50(pretrained=True)
# 冻结预训练模型的参数,这样我们在训练时只会更新最后一层的参数
for param in resnet.parameters():
param.requires_grad = False
# 获取最后一层全连接层的输入特征数量
num_ftrs = model.fc.in_features
# 替换最后一层全连接层以适应新的分类任务(猫狗二分类)
model.fc = nn.Linear(num_ftrs, len(class_names))
# 检测是否有可用的GPU,并将模型转移到该设备上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 如果我们想要微调整个网络,可以取消下面这行的注释
# for param in resnet.parameters():
# param.requires_grad = True
# 假设你想解冻模型的最后几层(例如,这里只解冻FC全连接层的参数)
for layer in model.fc.parameters(): # fc是模型的全连接层
layer.requires_grad = True
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
# 只优化最后一层全连接层的参数
optimizer = optim.SGD(model.fc.parameters(), lr=0.001, momentum=0.9)
# 如果微调整个网络,则使用:
# optimizer = torch.optim.Adam(resnet.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for inputs, labels in dataloaders['train']:
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新权重
# 打印训练损失
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 保存模型权重
torch.save(model.state_dict(), 'resnet50_catdog.pth')
# 在验证集上评估模型性能(可选)
correct = 0
total = 0
# 关闭梯度计算以节省内存和计算资源
with torch.no_grad():
for data in dataloaders['val']:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算并打印验证集上的准确率
print(f'Accuracy of the model on the validation set: {100 * correct / total}%')
posted on 2024-05-02 12:30 loveDoDream_zzt 阅读(1250) 评论(0) 编辑 收藏 举报


