
redis_列表对象
《Redis设计与实现》中说:redis列表对象有两种底层编码格式:ziplist、linkedlist,其中ziplist用压缩列表实现、linkedlist用双向链表实现
但我在实践中,没有发现linkedlist的使用,而发现了一种叫"quicklist"的type,意为一个由ziplist组成的双向链表
首先了解列表对象的结构
// redis对象内存分配,列出主要相关的属性
redisObject {
// 对于列表对象,type = REDIS_LIST
type
// 列表对象的底层编码格式,有三种:ziplist、linkedlist、quicklist
encoding
// 指向实际保存列表内容的空间
ptr
// 还有其他属性
......
}
上面的redisObject不实际保存列表内容,而是通过ptr指向实际保存列表内容的空间
根据编码格式的不同,ptr所指向的空间的结构会有所区别
ziplist编码
ziplist的实现为压缩列表,这个结构在redis中经常用到,
核心思想:能不用指针就不用指针,尽量依靠"记录各个节点、头尾之间的字节偏移量,来达到指针的效果"
一个基本的压缩列表其空间分配如下:
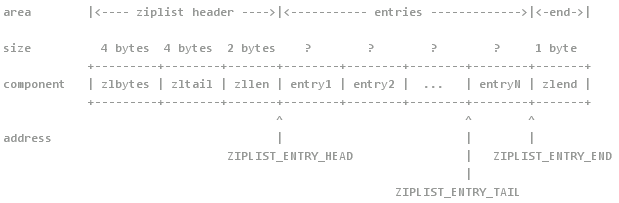
zlbytes:4字节,记录整个压缩列表占用的字节大小
zltail:4字节,记录"tail数据节点的起止地址"距离"整个压缩列表起始地址"的字节偏移量
zllen:2字节,记录节点数量(2直接最大只能存65536,所以当zllen<65536时是准确值,zllen=65536时,需要遍历才能知道准确值)
entryX:实际保存的数据,长度就不固定了
zlend:1字节,内容为0xFF,是压缩列表的结束标志
其中每个entryX,其内部结构由 previous_entry_length 、 encoding 、 content 三个部分组成:

previous_entry_length:保存了前一个entry节点的总长度
- 如果前驱的长度<254字节,那么previous_entry_length采用 1字节
- 如果前驱的长度>=254字节,那么previous_entry_length采用 5字节,其中第一字节内容固定为0xFE(254),后四个字节来保存前驱的长度。(好像没有考虑过前驱超级长,比 2^8 * 5 还长的情况)
encoding:保存content中数据的类型
content:存数据。整数就直接是整数、字符串是字符串对象
ziplist这种结构的好处:
- 数据连续且很紧凑,空间利用效率好
存在的问题:
- 不利于增删数据,需要频繁修改内存
- 存在"连锁更新"问题:
- 有这样一种情况,列表中有一串节点,大小比如都是253字节
- 突然在其中插入了一个大小为600字节的节点,这时其next节点本身只用1字节来保存pre节点的大小,现在不行了,需要改成5字节
- 改成5字节后,next节点大小变成了253-1+5=257字节,next的next也不能再用1字节了,也得扩
- ......
- 当在一串大小临界的节点中插入一个大数据时,会出现连锁更新现象,导致频繁分配内存
- 在一串大小刚刚超过254的节点中删除一个小数据时,也会出现类似的情况,频繁缩小内存
- 问题本身不常遇到
应用场景:
- 列表较短,并且数据都是小整数值、短字符串
- 当一个哈希键只包含少量kv对、且key和value都是小整数值、短字符串时,redis也会使用压缩列表来做
-
127.0.0.1:6379> hmset profile "name" "jack" "age" 28 OK 127.0.0.1:6379> object encoding profile "ziplist"
linkedlist编码
没有很特别,ptr指向一个双端链表
quicklist编码
《Redis设计与实现》中没有具体写。其结构为 A doubly linked list of ziplists,一个由ziplist组成的双向链表
其本身还是一个双向链表,但链表的每个节点不只保存一个数据,而是保存着一个ziplist
我理解是ziplist和linkedlist的一种结合:从整体上看整个list是不连续的,每个节点之间依靠指针访问。从局部上看数据是连续的,每个节点内依靠压缩列表实现,提高空间利用效率
micheal.li > mikeve@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号