
Mysql面试大全
说说MySQL索引的底层数据结构
MySQL索引的底层数据结构是B+树数据结构
详细介绍一下B+树的数据结构是什么样子的
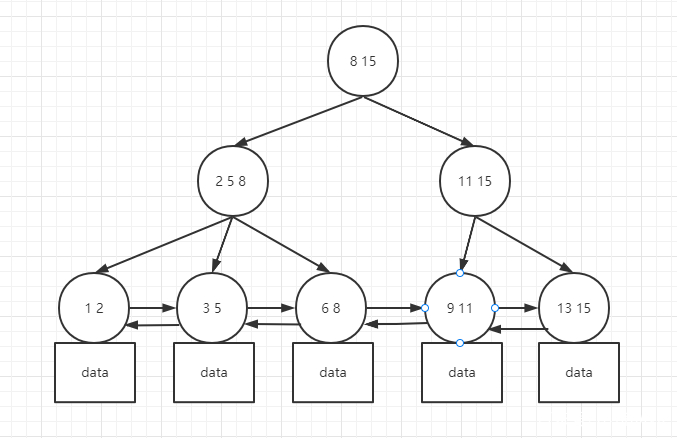
B+树有三个特性
- B+树是一个平衡多叉树,与平衡二叉树的每一个节点下面最多有两个子节点相比B+树每一个节点下面有多个子节点。
- B+树叶子节点(也就是最下面一层的没有子节点的节点)有一个双向链表,左右是为了方便范围查找(假如我找前100条数据,那么我找到第一条叶子节点的数据就可以从叶子节点直接向后取100个数据即可,不用再从根节点向下寻找)
- B+树的叶子节点有data数据(就是数据库中这一条所有的字段数据),非叶子节点只有索引数据。
那你说一下B树和B+树的区别,为什么MySQL底层使用B+树而不使用B树呢
B树与B+树有两个地方不同,一个是叶子节点的双向链表,一个是B树不是只有叶子节点有data数据,而是所有的节点都有data数据。
那为什么不用二叉树作为索引的底层结构而用B+树呢
因为二叉树的特性造成根节点距离叶子节点的路径太长,假如一个7个节点的数据二叉树从根节点到叶子节点的距离为三。
如果用B+树则距离为1就可以搞定(当然B+树一层不止7个节点,节点数量取决于一页数据能存放多少个节点)
每一个节点都有data数据不是更好吗,不需要到达叶子节点就可以获取数据返回了,为什么B+树还要把其他节点的data数据去掉,只留叶子节点的data数据呢
因为这里涉及到计算机中的IO操作,计算机IO一次只能拿一数据页的数据(姑且认为大小为64KB吧),如果每一个节点都有data数据,那么计算机IO一次可能只够拿一个节点出来,这样,可能IO一百次才能找到结果,如果其他节点不存储data数据,那么这个索引占用空间就少,IO一个可以拿出多个节点来,这样IO的次数就大大降低了,IO一次是比较耗费性能的,所以使用B+树就提高了性能。
那你简单说一下聚集索引和非聚集索引是什么意思
聚集索引:首先所谓聚集的含义是索引与data数据是否相邻,就是我找到索引以后在它附近就可以找到想要的data数据这就是聚集索引。
非聚集索引:非聚集索引就是我找到索引后,在它的附近找不到data数据。
这里我们根据之前的图想一下,之前的图叶子节点下面紧挨着就是data数据,这里肯定是聚集索引啊,那么什么情况下是非聚集索引呢。
在索引的字段是非主键的时候就是非聚集索引。
这里我来举个例子,如果一个student表中有主键id,姓名name,年龄age,住址add。这个时候我们给name字段建立一个索引,给add字段建立了一个索引,那么这个时候是不是有两个B+树的索引结构,那么意味着这两个索引结构的叶子节点都需要有data数据,那岂不是需要将name索引中的data数据复制一份出来给add索引。
那假如有100个字段都建立了索引,岂不是data要复制100遍。能不能只让一个索引的子节点有data数据,其他索引的子节点没有data数据而是放有data数据的索引的地址呢。
这个时候就让哪个索引作为唯一拥有data数据的索引呢,这里很明显可以用主键嘛,因为主键正好是唯一的,其他字段都可以为多个,所以主键所建立的索引就是拥有data数据的聚集索引,而其他非主键字段建立的索引就是非聚集索引。
MySQL语句怎么写可以提高性能呢
当然是建立索引啦,建立了索引犹如给书加上了目录,如鱼得水、如虎添翼
那索引是不是建立的越多越好呢
因为每一个索引就是给索引字段建立一个索引结构,假如现在插入一条数据,那么这条数据也需要将字段建立到索引结构当中,就需要调整索引结构了,如果建立了100个索引,那么插入1条数据需要调整100个索引结构,那么性能就可想而知了。
但是不建立索引又不行,必须还得建立,那么应该怎么建立呢,就是把经常要用到的查询条件的字段建立一个联合索引,这样用一个索引树可以将多个字段建立了索引。
说到了联合索引,如果我建立的联合索引是A、B、C这三个字段,那么我查询的时候条件是A、B那么这个索引还有效果吗?为什么呢?
有效果,因为最左前缀原则,假如当我们给姓名、年龄、性别三个字段建立了索引,那么从左边先开始的字段才可以索引有效果。
那如果我查A和C呢?
那么只有A有索引效果,查询的字段从索引的最左边开始向右查找,如果中间断了,那么后面的索引字段就失去效果了。
讲一下MySQL的索引覆盖是怎么回事吧
所谓索引覆盖就是用索引字段来覆盖要查询的字段。
假如我们要查询两个字段,name和age,我们的sql语句为
select name,age from student where name='张三' and age=20
假如我们这个时候只有name建立了索引,这个时候我们需要在索引中找到name等于张三的这些数据,并回表(就是从普通索引中找不全所要查询的所有字段,那么需要回表再去主键聚簇索引中寻找,因为聚簇索引中有全量的data数据)。
这个时候我们可以看到我们需要查询的字段只有name,age两个字段,这个时候我们可以将name,age这两个字段做一个联合索引,这个时候我们直接通过联合索引就可以找到所要查询出的字段了。
请注意如果是
select name,age,add from student where name=‘张三’ and age=20;
这个时候由于刚刚的联合索引只有name,age两个字段,没有add字段,所以这种情况又要回表查询,这种情况就没有索引覆盖了。
所以我们sql语句要尽可能的查询出少量的字段,就是用哪个字段就查询哪个字段,更要避免select * 的这种情况。
那你再说一下什么是索引下推吧
首先索引下推是MySQL5.6版本引入的一种优化手段,说白了就是优化了一下,具体优化后有了哪些效果呢。关键点:
-
第一个字段为非等值字段。
-
查询的字段建立了联合索引
前提:
name和age建立了联合索引
例如:
select name,age from student where name like ‘%李*%’ and age=20;
这个时候如果在5.6之前,我们会在联合索引中先找到所有name为李开头的数据id(主键),然后再去主键索引(聚集索引)中找age为20的数据的id拿回来,然后将最后合并的数据根据id再去聚集索引中找,这样其实是两次回表查询。
而在5.6之后,我们在联合索引中就直接将name为李开头的和age等于20的数据id筛选出来了,然后再去聚集索引中查询,这样就只进行了一次回表查询。
总结:5.6之前如果查询字段为非等值字段,那么后面的查询条件就回去聚集索引中进行判断,5.6之后非等值字段后面的查询条件在当前非聚集索引中也可以进行判断。
那你能说一下索引在什么情况下会失效吗?
1、在使用不等于!= 或者<> 这样的会失效。
2、在使用不包含 not in , 不存在 not exists 这样的会失效。
3、在使用空 is null,不为空 is not null 这样的会失效。
4、在使用小于 <、大于 >、<=、 >= 这些的时候,mysql优化器会根据索引比例、表的数据量大小等因素来决定走不走索引。
那我写了一条sql,我怎么知道这条sql有没有走索引呢
使用explain解释器来查看,在sql语句前面加上explain就可以来查看。
explain中有多列,我们直接看type这一列,这一列表示访问类型,即MySQL决定以哪种形式来查找表中的行,是根据索引还是全表扫描,表示查找数据行记录的大概范围。
type中的数据类型从优到差依次为:
system > const > eq_ref > ref > range > index >ALL
当我们写了一条sql语句发现他的type是ALL的时候我们就要考虑一下怎么优化一下了,因为ALL是最差的,我们就需要琢磨一下怎么优化,当然优化到system是最好的。
数据库有哪些事务隔离级别,MySQL使用了哪种级别呢?
数据库有四种事务隔离级别
读未提交
读已提交
可重复读
可串行化
MySQL默认是可重复读事务隔离级别
那MySQL有哪些锁呢?
从颗粒度来分,MySQL有表锁和行锁。
表锁:每次操作锁住整张表,开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突的概率最低。
行锁:每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。
那你知道MVCC机制吗,他的原理是什么?
MVCC(Multi-Version Concurrency Control)是多版本并发控制,是在多个事务情况下可以保证每个事物之间相互隔离,MVCC机制适用于读已提交和可重复读这两个事务隔离级别。
MVCC机制中有最重要的两部分:
undo日志版本链:在一行数据被多个事务依次修改过后,每次的修改记录都会保存到undo日志版本链中,用于回滚操作。
一致性视图:read-view:每一个事务开启后,执行任何查询sql时就会生成当前事务的一致性视图。这个视图是由查询的时候所有未提交的事务id数组和已创建的最大事务id组成。
总结:MySQL隔离级别是可重复读的,所以当一个事务执行第一个查询语句的时候就生成了一个一致性视图,当第二个事务修改了这条数据够,第一个事务查询的还是原来的数据,因为第一个事务当时查询的时候生成了一致性视图,这个一致性视图对于第一个事务来说没有变化,所以查询出来的数据也没有变化。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具