
CSS3字体模块
介绍
字体提供了包含字符的视觉表现的资源。在最简单的等级中,其包含由字符编码到表示这些字符的形状(被称为字形)的映射信息。根据一组标准字体属性被分入一个字体家族的字体共享一个通用设计风格。在一个家族中,表现指定字符的形状,可以通过笔画粗细、倾斜或相对宽度而彼此改变。一个给定的字体外观是为这些属性的一个唯一组合而设计的。对于文本的给定范围,在渲染这些文本时使用CSS字体属性选择所使用的字体家族及家族中的字体外观。作为一个简单的例子,为了使用Helvetica字体的粗体形式,可以使用:
body { font-family: Helvetica; font-weight: bold; }
字体资源可以是本地、安装于运行用户代理的系统中、或可下载的。对于本地字体资源,描述信息可以直接从字体资源中获得。对于可下载的字体资源(有时为到Web字体的引用),描述信息在对字体资源的引用中。
通常字体的家族不会为字体属性的每个可能变化包含一个独立的外观。CSS字体选择机制描述如何将一个给定的CSS字体属性集匹配到一个给定的字体外观。
排版的背景
本节所包含的内容会被用作其他章节中所描述的问题和情况的背景。它应当仅被认为是参考信息。
全球各地的传统排版存在不同,所以不存在一种唯一的方法对所有字体按照语言和文化进行分类。即使是普通的拉丁字母,也存在多种可能的变种:
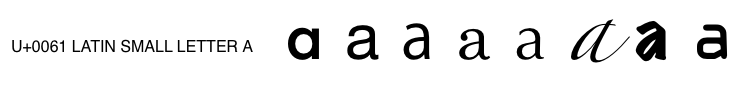
图1:一个字符,多个字形变种。
字形分解的不同是区别字体的一种方法。对于拉丁字体,字符的主要笔划端点处的花边或衬线,可以用于区分字体。类似的区别也存在于非拉丁字体,即锥形笔划和均匀笔划。
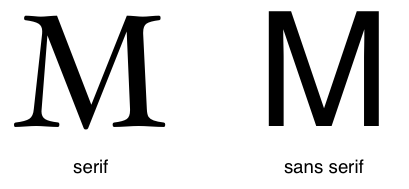
图2:使用衬线和不使用的字形。

图3:日语字形的类似区别。
字体包含字母形态和将字符映射到这些字母形态所需的数据。通常这可能是一个简单的一对一映射,但也可能会是更复杂的映射。与发音符号集合使用可能会产生潜在的字母形态变种:
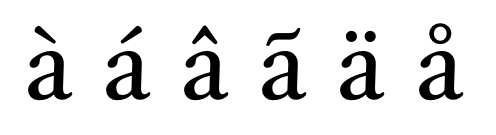
图4:发音符号变种。
一段字符序列可以被表示为一个单独的字形,这边称为连字:

图5:连字示例。
视觉转换基于文本上下,这对于欧洲语言可能是可选的,但在正确选择诸如阿拉伯语这类语言时确实必须的;下面的lam和alef字符在连续出现时必须连接在一起。
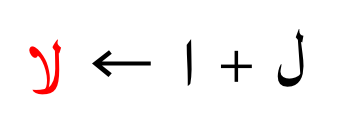
图6:必须的阿拉伯语连字。
这些相对复杂的形状转换需要字体的附加数据。
一系列拥有不同格式变种的字体外观通常会在字体家族中进行分组。在最简单的情况下,一个标准外观会辅以粗体和斜体外观,但也可以拥有更多。这通常包括字母形态笔划的粗细、重量、或字母形态整体的比例、或宽度的变种。在下面的例子中,每个字母使用了Univers字体家族中的一种不同的字体外观。宽度自上至下递增,重量自左至右递增:
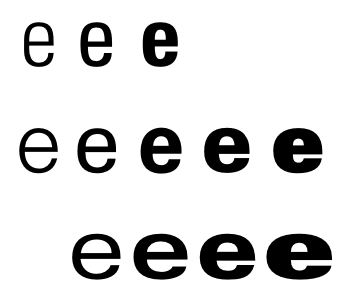
图7:单一字体家族中的粗体和宽度变种。
创建一个支持多种脚本的字体是不同的任务;设计师需要理解使用不同脚本的文化传统,进而了解字母形态将以何种形式公用一个相同的主题。许多语言经常会公用一个通用脚本,这些语言之间可能会拥有显要的格式区别。波斯语、乌尔都语、斯拉夫语公用阿拉伯语脚本,不仅是俄语。
一个字体的字符映射定义了该字体中字符到字形的映射。如果一个文档中包含的字体没有在该字体中明确指定的字符映射,用户代理可能会使用系统字体备用程序来定位适当的字体。如果没有找到适当的字体,用户代理将会选择某种形式的“丢失字形”字符。备用程序可以发生在没有明确指定字体或作者没有明确指出文档的编码时。
虽然一个字体的字符映射将一个给定的字符映射到该字符的字形,诸如OpenType和AAT(Apple Advanced Typography)的现代字体技术提供了一个更丰富的执行映射的规则。这种形式的字体允许将这些特性嵌入到字体本身,并受应用的控制。包括连字、花字、上下文替换、比例及表格数字、和自动小数的通用排版特性仅列出几个。对于OpenType特性的视觉概述,请查阅【OPENTYPE-FONT-GUIDE】。
基本字体属性
显示一个字符的特定字体外观是由字体系列和其他指定在元素上的字体属性所决定的。这种结果允许设置相互独立的改变。
字体:‘font-family’属性
| 名称: | font-family |
| 取值: | [ <家族名称> | <通用家族> ]# |
| 初始: | 由用户代理决定 |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | 不适用 |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
该属性指定了一个优先序列,其中包含字体家族名称或通用家族名称。与其他CSS属性不同,其值的各个组成部分之间以逗号分隔。用户代理迭代穿过家族名称列表,指定匹配一个包含待渲染字符的字形的有效字体。这允许在不同平台拥有的有效字体存在差异,以及单个字体所支持的字符范围有差异。
一个字体家族名称仅指定一个给一个字符外观集合的名称,其比指定个体外观。字体的可用性在下面给出,Futura可以匹配,但Futura Medium不能:

图8:家族及单个外观名称。
考虑下面的例子:
示例:
body {
font-family: Helvetica, Verdana, sans-serif;
}
如果Helvetica有效,则在渲染时使用该字体家族。如果Helvetica和Verdana均不可用,则将使用用户地理定义的无衬线字体(sans serif)字体。
存在两种字体家族名称的类型:
<家族名称>
<通用家族>
serif’、‘sans-serif’、‘cursive’、‘fantasy’和‘monospace’。这些关键字可以被用作编码人员所选择的字体不可用时的通用后备机制。作为关键字,它们禁止使用引号。我们鼓励编码人员为了提高健壮性,将通用字体家族作为最终替代追加在字体列表之中。字体家族名称必须为一个被引号包围的字符串,或者没有被引号包围的一或多个标识符的序列。这意味着在没有被引号包围的字体家族名称中,必须避免在每个标记的起始处出现大部分标点字符和数字。
举例说明,下列声明是无效的:
font-family: Red/Black, sans-serif;
font-family: "Lucida" Grande, sans-serif;
font-family: Ahem!, sans-serif;
font-family: test@foo, sans-serif;
font-family: #POUND, sans-serif;
font-family: Hawaii 5-0, sans-serif;
如果一个标识符序列作为字体家族名称给出,则其计算值是被转换为字符串的名称,在转换时,会将所有标识符通过一个单独的空格连接起来。
为了避免转码错误,我们建议把包含空格、数字或除连字符外标点字符的字体家族名称用引号包围:
body { font-family: "New Century Schoolbook", serif }
<BODY STYLE="font-family: '21st Century', fantasy">
恰好与关键字值(‘inherit’、‘serif’、‘sans-serif’、‘monospace’、‘fantasy’和‘cursive’)相同的字体家族名称必须为了防止与同名关键字混淆而是用引号包围。关键字‘initial’和‘default’为未来使用而保留,且必须在用作字体名称时使用引号包围。用户代理禁止将这些关键字匹配‘<家族名称>’类型。
某些字体格式允许字体包含字体名称的多个本地化形式。用户代理必须识别并正确匹配所有这些名称,这些操作独立于底层平台的本地化、所使用的系统API和文档编码:

图9:本地化家族名称。
通用字体家族
所有五个通用字体家族被定义要求存在于所有CSS实现中(不必为它们映射五个不同的实际字体)。用户代理应当为通用字体家族提供合理的默认选择,该选择在底层技术允许的范围内尽可能的表现每个家族中字体。我们鼓励用户代理允许用户选择通用字体的替代选择。
衬线(serif)
衬线字体的字形,如其在CSS中所使用的术语相同,拥有收笔、向外展开说收紧的端点、或者拥有实际的衬线端点(包括粗衬线)。衬线字体通常是按比例隔开的。通常在显示时,它们比‘无衬线(sans-serif)’通用字体家族在粗/细笔划间拥有更明显的变种。CSS将术语‘衬线(serif)’应用于所有脚本的字体,即使对于某些脚本其他名称可能更加熟悉,例如:Mincho(明朝体,日语)、Sung、Song或Kai(宋体、楷书,中文)、Batang(巴塘,韩语)。所有如此描述的字体都可能会被用于表示通用‘衬线(serif)’家族。

图10:衬线字体示例。
无衬线(sans-serif)
无衬线字体的字形,如其在CSS中所使用的术语相同,其笔划的端点没有格式——没有扩口、交叉笔划、或者其他装饰。无衬线字体通常是按比例隔开的。通常它们比‘衬线(serif)’家族的字体在粗/细笔划间拥有较小的差异。CSS将术语‘衬线(serif)’应用于所有脚本的字体,即使对于某些脚本其他名称可能更加熟悉,例如:Gothic(哥特式,日语)、Hei(黑体,中文)或Gulim(韩语)。所有如此描述的字体都可能会被用于表示通用‘无衬线(sans-serif)’家族。

图11:无衬线字体示例。
手写体(cursive)
手写体字体的字形拥有连接的笔划或其他远超斜体字体字符的手写体特性。这些字形部分或完全的连接在一起,且产生的结果比印刷的字母更像是手写笔、手写刷。对于某些脚本,例如阿拉伯语,其几乎都是手写体。CSS将属于‘手写体(cursive)’应用于所有脚本的字体,即使对于某些脚本其他名称可能更加熟悉,例如: Chancery、Brush、Swing和Script。

图12:手写体字体示例。
幻想(fantasy)
幻想字体主要用于装饰包含幽默地表示字符的字体。它们不包括不表示实际字符的Pi或图片字体。

图13:幻想字体示例。
等宽(monospace)
等宽字体的唯一要求是所有字形都拥有相同的固定宽度。它们经常被用于显示计算机代码示例。

图14:等宽字体示例。
字体粗细:‘font-weight’属性
| 名称: | font-weight |
| 取值: | normal | bold | bolder | lighter | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 详见描述 |
| 动画: | - |
‘font-weight’属性执行字体中字形的重量,这取决于黑度等级或笔划粗细。
其值的意义如下:
100至900
- 100 - Thin
- 200 - Extra Light (Ultra Light)
- 300 - Light
- 400 - Normal
- 500 - Medium
- 600 - Semi Bold (Demi Bold)
- 700 - Bold
- 800 - Extra Bold (Ultra Bold)
- 900 - Black (Heavy)
bold
bolder
lighter
使用并非九阶的缩放比例的字体格式应当将其缩放比例映射到CSS缩放比例,使得400大致符合将会标为Regular、Book、Roman的外观;700大致符合将会标为Bold的外观。或者从样式名推断其重量,使其大致符合上述宽度比例。缩放比例是相对的,所以一个拥有较大重量的外观不可能更轻。如果样式名被用于推断重量,则应当着重处理与本地化信息交叉的样式名称中的变种。
通常一个特定的字体家族仅会包含少数的可用重量。若一个重量所指定的字形不存在,则应当使用相近重量的字形。通常,较重的重量会映射到更重的重量、较轻的重量会映射到更轻的重量(精确定义参见下面的字体匹配章节)。下面的例子展示了不同重量将使用的外观,灰色表示该重量的外观不存在、使用的是相近重量的字形:

图15:只包含400、700和900重量字形的字体家族的重量映射。

图15:只包含300和600重量字形的字体家族的重量映射。
尽管该实践对于印刷业来说并不完善,但是在缺少实际较重重量的字形的情况下,通常由用户代理合成较重重量的字形。为了符合样式匹配的要求,这些字形必须被当做其存在于家族之中。
值“bolder”和“lighter”表示其值相对于其父元素的重量。基于继承的重量值,其重量通常是使用下表计算而得的。子元素将继承计算后的宽度,而不是值“bolder”或“lighter”。
| 继承到的值 | bolder | lighter |
|---|---|---|
| 100 | 400 | 100 |
| 200 | 400 | 100 |
| 300 | 400 | 100 |
| 400 | 700 | 100 |
| 500 | 700 | 100 |
| 600 | 900 | 400 |
| 700 | 900 | 400 |
| 800 | 900 | 700 |
| 900 | 900 | 700 |
上面的表格等价于选择下一个相关的更重或更轻字形,给出一个包含normal和bold外观的字体家族外加一个thin和heavy外观。需要在指定元素上使用精确重量值的编码人员应当使用数字值,而不是相对重量。
字体宽度:‘font-stretch’属性
| 名称: | font-stretch |
| 取值: | normal | ultra-condensed | extra-condensed | condensed | semi-condensed | semi-expanded | expanded | extra-expanded | ultra-expanded |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
‘font-stretch’属性从字体家族中选择一个normal、condensed或expanded的外观。绝对的关键字值其从窄至宽拥有下列顺序:
- Ultra Condensed
- Extra Condensed
- Condensed
- Semi Condensed
- Normal
- Semi Expanded
- Expanded
- Extra Expanded
- Ultra Expanded
缩放比例是相对的,所以拥有在上面列表中更靠上的‘font-stretch’值的字形必应当更宽。如果不存在给定宽度的外观,则normal或condensed值将会映射至较窄的外观、其他的值将会映射到较宽的外观。相反的,expanded值将会映射到较宽的外观、其他的值将会映射到较窄的外观。下图展示了九个‘font-stretch’属性将如何影响包含多种宽度的字体家族的字体选择,灰色表示该宽度对应的字形不存在,将使用其他的宽度替代:

图17:包含condensed、normal和expanded宽度外观的字体家族的宽度映射。
字体样式:‘font-style’属性
| 名称: | font-style |
| 取值: | normal | italic | oblique |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
‘font-style’属性允许选择斜体或倾斜的外观。斜体形式通常是自然的手写体,而倾斜外观是规则外观的倾斜版本。倾斜外观通过人工的倾斜规则外观的字形而模拟形成。比较处于灰色的人工倾斜而产生的Palatino“a”和Baskerville“N”与实际的斜体版本:
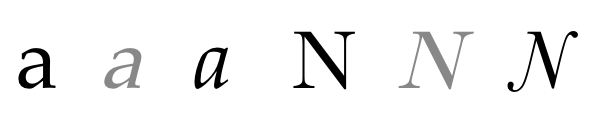
图18:人工倾斜与实际的斜体。
值‘normal’选择被分类为“normal”的外观,而‘oblique’选择被标为‘oblique’的字体。值‘italic’选择被标为‘italic’的字体,或者如果其不可用,则选择被标为‘oblique’的字体。如果斜体和倾斜的外观均不可用,则可以通过在normal外观上应用倾斜变换而合成一个倾斜的外观。
许多脚本没有在显示文本时与normal外观混用草书形式的传统。中文、日语和韩语字体几乎没有斜体或倾斜的外观。支持多种脚本的字体有时会在支持斜体的外观中忽略某些诸如阿拉伯语的脚本的字形集。用户代理应当小心地跨外观进行字符映射。
字体大小:‘font-size’属性
| 名称: | font-size |
| 取值: | <绝对字号> | <相对字号> | <长度> | <百分比> |
| 初始: | medium |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | 相对于父元素的字号 |
| 媒介: | 视觉 |
| 计算值: | 绝对长度 |
| 动画: | - |
此属性表示来自于字体的期望高度。对于可缩放的字体,font-size是一个以EM为单位应用于字体的缩放因子。(注意某些字形可能会超出它们的EM盒子。)对于不可缩放的字体,font-size被转换为绝对单位并匹配字体所声明的font-size,对所有匹配的值使用相同的绝对坐标空间。其值拥有如下意义:
<绝对字号>
[ xx-small | x-small | small | medium | large | x-large | xx-large ]
<相对字号>
[ larger | smaller ]
举例说明,如果父元素的字号是‘medium’,该属性的值为‘larger’,则当前元素的字号将会是‘large’。如果父元素的字号不是表中的实体,则用户代理可以自由的在表中插入或者取近似值。如果数值型的值超过了关键字,则用户代理可能不得不自行推断表格的值。<长度>
<百分比>
em’的值,导致更强大和联级样式表。下表提供了<绝对字号>的缩放因子、对应的XHTML标题和绝对字号对用户代理的指导方针。‘medium’值用于引用中间值。用户代理可能会针对不同字体或显示设备的不同类型对这些值进行微调。
| CSS <绝对字号>值 | xx-small | x-small | small | medium | large | x-large | xx-large | |
|---|---|---|---|---|---|---|---|---|
| 缩放因子 | 3/5 | 3/4 | 8/9 | 1 | 6/5 | 3/2 | 2/1 | 3/1 |
| XHTML标题 | h6 | h5 | h4 | h3 | h2 | h1 | ||
| XHTML字号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
基于可读性原因,用户代理在应用这些指导方针的时候,应当避免产生的字号造成在计算机上显示时每EM单位少于9像素。
在CSS1中,每个相邻索引之间的缩放因子是1.5,使用体验显示其过大。在CSS2中,对于计算机屏幕每个相邻索引之间的缩放因子是1.2,这仍然会在小字号上产生问题。对每个索引之间新的缩放因子的改变会提供更好的可读性。
由于‘font-size-adjust’的数值型值和某些字号的不可用,此属性的实际值[链接到联级模块]可能会与计算值不同。
子元素继承‘font-size’属性的计算值(否则,将会包含‘font-size-adjust’的影响)。
示例:
p { font-size: 12pt; }
blockquote { font-size: larger }
em { font-size: 150% }
em { font-size: 1.5em }
相对大小:‘font-size-adjust’属性
| 名称: | font-size-adjust |
| 取值: | <数值> | none |
| 初始: | none |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
对于给出的字号,显式的字号和方便阅读的文本使用不同的字体。对于诸如拉丁或斯拉夫的区分大、小写字母的脚本,小写字母与和其对应的大写字母的相对高度取决于易读性因素。这通常被称为纵横值。精确定义是,其等于字体的x轴高度除以字号。
在使用后备字体的情况下,后备字体可能不会与期望的字体家族共享相同的纵横比,因此也会造成可读性降低。‘font-size-adjust’属性是一种在使用后备字体时保持文本可读性的方法。其使用的方法时调整字号,来使得无论使用何种字体都使其拥有相同的x轴高度。
示例:
下面的样式定义Verdana为期望的字体,但如果Verdana不可用,则使用Futura或Times。
p {
font-family: Verdana, Futura, Times;
}
<p>Lorem ipsum dolor sit amet, ...</p>
Verdana具有较高的纵横比,小写字母与大写字母的比例相对较高,所以较小字号的字体能够清晰的显示。Times具有较低的纵横比,所以如果使用后备字体,较小字号的字体较Verdana会具有较低的清晰度。
这些字体将如何显示的比较如下,各列分别展示用Verdana、Futura和Times显示的文本。每行中的各单元格使用相同的‘font-size’值,其中的红线展示在x轴高度上的差异。在上半部分中各行使用相同的‘font-size’值显示。‘font-size’值的相同同样适用于下半部分,但在下半部分中,同时设置了‘font-size-adjust’属性,这使得实际的字号被调整为保持各行的x轴高度。注意在下半部分中较小的文本仍然能够清晰的显示。

此属性允许编码人员为一个元素指定一个纵横值,这能够有效的保持首选字体的x轴高度,而不考虑首选字体是否被替代。其值的意义如下:
none
<数值>
c = ( a / a' ) s
其中:
s= font-size值a= font-size-adjust属性指定的纵横值a'= 实际字体的纵横值c= 调整后的font-size
(a/a')对于第一个字体直接为1,且不需要进行调整。如果进行了不精确指定,使用家族列表中第一个字体显示的文本将与在不支持font-size-adjust的旧用户代理上的显示不同。编码人员可以通过比较font-size-adjust不同的相同内容的跨度来计算给定字体的纵横值。如果使用了相同的font-size,若精确指定font-size-adjust到给定字体,则跨度应当相匹配。
示例:
两个拥有边框的跨度被i用来确定字体的纵横值。两个跨度均使用相同的font-size,但仅在左侧跨度上指定了font-size-adjust属性。从0.5开始调整纵横值,直到包围两个字母的边框相对齐。
p {
font-family: Futura;
font-size: 500px;
}
span {
border: solid 1px red;
}
.adjust {
font-size-adjust: 0.5;
}
<p><span>b</span><span class="adjust">b</span></p>

图20:纵横值为0.5的Futura字体
右侧的盒子稍大于左侧的,所以改字体的纵横值稍小于0.5。
速记属性:‘font’属性
| 名称: | font |
| 取值: | [ [ <‘font-style’> | | <font-variant-css21> | | <‘font-weight’> ]? <‘font-size’> [ / <‘line-height’> ]? <‘font-family’> ] | caption | icon | menu | message-box |small-caption | status-bar |
| 初始: | 查看独立属性 |
| 适用于: | 所以元素 |
| 继承: | 是 |
| 百分比: | 查看独立属性 |
| 媒介: | 视觉 |
| 计算值: | 查看独立属性 |
| 动画: | - |
‘font’属性,除了下面描述的,是在样式表中同一位置设置‘font-style’、‘font-variant’、‘font-weight’、‘font-size’、‘line-height’、‘font-family’的速记属性。可以‘font-variant’属性的值,但仅能包含被CSS 2.1支持的值,本规范新增的‘font-variant’值不能被用于‘font’速记:
<font-variant-css21> = [ normal | small-caps ]
此属性的语法基于可以设置多个与字体相关的属性的传统排版速记符号。
所有与字体相关的属性都会首先被重置为它们的初始值,包括在之前段落列出的、以及‘font-stretch’、‘font-size-adjust’、‘font-kerning’和所有字体特性属性。之后,设置那些在‘font’速记属性中明确设置的值。对于允许的定义和初始值,可以查看之前定义的属性。基于向后兼容的原因,不能使用‘font’速记属性将‘font-stretch’和‘font-size-adjust’设为其初始值之外的值;作为替代,请设置独立属性。
示例:
p { font: 12pt/14pt sans-serif }
p { font: 80% sans-serif }
p { font: x-large/110% "new century schoolbook", serif }
p { font: bold italic large Palatino, serif }
p { font: normal small-caps 120%/120% fantasy }
p { font: oblique 12pt "Helvetica Neue", serif; font-stretch: condensed }
在第二个规则中,字号百分比值(‘80%’)涉及其父元素的字号。在第三个规则中,行高百分比(‘110%’)涉及该元素自身的字号。
前三个规则没有明确的指定‘font-variant’和‘font-weight’,所以这些属性取得他们的初始值(‘normal’)。注意字体家族名称“new century schoolbook”(其包含空格)是被引号包围的。第四个规则设置了‘font-weight’为‘bold’、‘font-style’为‘italic’、以及隐含的‘font-variant’为‘normal’。
第五个规则设置了‘font-variant’(‘small-caps’)、‘font-size’(其父亲字号的120%)、‘line-height’(字号的120%)以及‘font-family’(‘fantasy’)。于是,余下的两个属性‘font-style’和‘font-weight’应用了‘normal’。
第六个规则设置了‘font-style’、‘font-size’和‘font-family’,其他字体属性被设为它们的初始值。之后设置了‘font-stretch’为‘condensed’,这是因为‘font’速记属性不能将该属性设置为该值。
下列各值引用系统字体:
caption
icon
menu
message-box
small-caption
系统字体可能仅被设置为一个整体,即字体家族、字号、重量、样式等,它们同时被设置。如果需要,之后可以个别的修改这些值。如果包含特定特征的字体不存在于给定的平台上,则用户代理应当智能替代(例如一个较小版本的‘caption’字体可能被用于‘smallcaption’字体)、或替换为用户代理默认字体。对于一个规则字体, 如果(对于系统字体)任何独立属性不是操作系统可用的用户首选项中的一部分,则这些属性应当被设为它们的初始值。
这就是为什么该属性“几乎”是一个速记属性:系统字体仅可以使用该属性指定,而不是‘font-family’本身,所以‘font’允许编码人员将其用作较其子属性总和更多的用途。然而,诸如‘font-weight’的独立属性仍然会给出从系统字体获得的可以独立改变的值。
示例:
button { font: 300 italic 1.3em/1.7em "FB Armada", sans-serif }
button p { font: menu }
button p em { font-weight: bolder }
如果在特定系统上用于下拉菜单的字体恰好是,例如,9-point的Charcoal,其重量为600,则作为BUTTON后裔的P元素的显示将与下列规则产生的效果相似:
button p { font: 600 9pt Charcoal }
由于‘font’速记属性将没有明确给定值的属性重置为其初始值,则其与下面的声明拥有相同的效果:
button p {
font-style: normal;
font-variant: normal;
font-weight: 600;
font-size: 9pt;
line-height: normal;
font-family: Charcoal
}
控制合成:‘font-synthesis’属性
| 名称: | font-synthesis |
| 取值: | nont | [ weight | | style ] |
| 初始: | weight style |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
该属性控制是否允许用户代理在字体家族缺少粗体或斜体外观是字形合成粗体或倾斜的字体外观。如果没有指定‘weight’,则用户代理禁止合成粗体外观;如果没有指定‘style’,则用户代理禁止合成斜体外观。值‘none’禁止所有合成外观。
示例:
下面的样式规则不能使用合成的倾斜阿拉伯语:
*:lang(ar) { font-synthesis: none; }
字体资源
@font-face规则
@font-face规则允许到字体的链接,该字体在需要的时候会自动激活。这允许编码人员选择更接近该页面设计目标的字体,而不必在选择字体的时候被全平台可用字体集所限制。一个字体描述符集定义了一个字体资源的位置(既可以是本地位置也可以是远程位置)以及个体外观的样式特征。多个@font-face规则可以用于产生拥有不同外观的字体家族。使用CSS字体匹配规则,用户代理可以有选择的仅仅下载这些外观中指定的部分文本。
@font-face @规则的一般格式是:
@font-face { <字体描述> }
其中<字体描述>的格式是:
descriptor: value;
descriptor: value;
[...]
descriptor: value;
每个@font-face规则指定为所有字体描述符指定一个值,这可以是隐含的也可以是明确的。对于那些规则中没有给出明确值的情况,将使用本规范中为每个描述符列出的初始值。这些描述符仅在定义它们的@font-face的上下文中适用,不会被应用于文档语言元素。没有关于描述符适用于的元素或子元素是否会继承这些值的概念。如果一个描述符在给定的@font-face规则中出现了多次,则指使用最后指定的值,忽略所有该描述符之前的值。
示例:
为了使用一个名为Gentium的可下载字体:
@font-face {
font-family: Gentium;
src: url(http://example.com/fonts/Gentium.ttf);
}
p { font-family: Gentium, serif; }
用户代理将下载Gentium,并在渲染段落元素中的文本时使用。如果由于某些原因服务器上的字体不可用,则使用默认的serif字体。
一个给定的@font-face规则集定义了一组对包含文档可用的字体。可以使用多个规则定义额一个拥有大外观集合的家族。如果使用这些规则定义的字体能够通过字体匹配,则这些字体的优先级高于其他系统可用字体。
已下载的字体仅在引用它们的文档中可用,激活这些字体的过程不应该使它们对于其他应用或没有直接链接到相同字体的文档可用。用户代理实践可能会在渲染其他不存在可用字体的文档中的字符时方便的使用已下载的字体作为系统字体后备程度一部分的。这可能会造成安全漏洞,因为一个页面中的内容可以影响另一个页面,有时可被攻击者用作攻击媒介。这些限制不会影响缓存行为,字体的缓存与其他资源的缓存方式相同。
不支持@font-face规则的用户代理将忽略从开花括号到毕花括号之间的内容。此@规则符合CSS的向前兼容解析要求,解析器可以没有错误的忽略这些规则。所有没有被特定用户代理认可或实现的描述符都必须被忽略。@font-face规则需要一个font-family和src描述符,如果缺少它们之一则必须忽略该@font-face规则。
在用户代理拥有被限制的平台资源或实现能够禁用可下载字体资源的情况下,@font-face规则必须直接被忽略;本规范中定义的个体描述符的行为不应被改变。
字体家族:‘font-family’描述符
| 名称: | font-family |
| 取值: | <家族名称> |
| 初始: | (不适用) |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
此描述符定义了将用于所有CSS字体家族名称匹配的字体架子名称,其重新定义了隐含字体数据中包含的字体家族名称。如果该字体家族名称与用户环境中可用的字体家族相同,则其有效的在使用该样式表的文档中隐藏了这个底层的字体。这允许web编码任意自由的选择字体家族的名称,而不必担心其会与给定的用户环境中现场的字体家族名称冲突。加载字体的错误不会影响字体名称的匹配行为。如果一个用户代理将平台字体别名规则应用到由@font-face规则所定义的字体家族名称上,则这个用户代理是不符合规范的。
字体引用:‘src’描述符
| 名称: | src |
| 取值: | [ <uri> [format(<string>#)]? | < font-face-name > ]# |
| 初始: | (不适用) |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
该描述符指定包含字体数据的资源。这是必需的,不论字体是可下载的或是本地安装的。其值是有序的、逗号分隔的外部引用或本地已安装字体外观名称的列表。若字体需要用户代理迭代遍历引用列表集合,则使用第一个能够成功激活的。包含无效数据的字体或没有找到的本地字体外观将会被忽略,且用户代理将会载入列表中的下一个字体(禁止平台替换给定的字体)。
与CSS中的其他URI相似,此URI可以是局部的,在这种情况下其相对于包含该@font-face规则的样式表的位置。对于SVG字体,该URL指向一个包含SVG字体定义的文档中的元素。如果元素引用被省略,则意味着引用到第一个定义的字体。类似地,对于能够包含超过一个字体的字体容器格式,一个给定的@font-face规则必须载入并仅能载入一个字体。片段标识符用于表示要载入哪个字体。如果一个容器格式没有定义片段标识符方案,实践应当从1开始索引这些方案(即“font-collection#1”为第一个字体、“font-collection#2”为第二个字体)
src: url(fonts/simple.ttf); /* 相对于样式表位置加载simple.ttf */
src: url(/fonts/simple.ttf); /* 从绝对位置加载simple.ttf */
src: url(fonts.svg#simple); /* 加载id为‘simple’的SVG字体 */
外部引用由一个URI、以及一个紧跟的可选的用于描述该URI所引用的字体资源的格式的提示。这个格式提示包含一个逗号分隔的列表,列表中的元素是表示众所周知的字体格式的格式字符串。如果格式提示都是不支持或未知的字体格式,则符合规范的用户代理必须跳过对这些字体资源的下载。如果没有提供格式提示,则用户代理应当下载这些字体资源。
/* 如果WOFF自己可用则进行载入,否则使用OpenType字体 */
@font-face {
font-family: bodytext;
src: url(ideal-sans-serif.woff) format("woff"),
url(basic-sans-serif.ttf) format("opentype");
}
格式字符串由本规范定义:
| 字符串 | 字体格式 | 常见后缀名 |
|---|---|---|
| “woff” | WOFF(Web Open Font Format) | .woff |
| “truetype” | TrueType | .ttf |
| “opentype” | OpenType | .ttf、.otf |
| “embedded-opentype” | Embedded OpenType | .eot |
| “svg” | SVG字体 | .svg、.svgz |
由于TrueType和OpenType的常见用法相互重叠,所以格式提示“truetype”和“opentype”必须被认为拥有相同意义;一个“opentype”格式提示并不意味着改字体包含Postscript CFF样式的字形数据或者其包含OpenType布局信息(更多背景信息参见附录A)。
如果编码人员希望使用给定字体的本地可用副本,并且在其不存在的时候下载该字体,则可以使用local()。本地已安装的<font-face-name>是一个格式特定的字符串,其唯一标识一个大的家族中的一个单独的字体外观。一个<font-face-name>的语法是由“local(”和“)”包围的一个唯一的字体外观名称。
/* Gentium的规则外观 */
@font-face {
font-family: MyGentium;
src: local(Gentium), /* 使用本地可用的Gentium */
url(Gentium.ttf); /* 否则进行下载 */
}
名称可以可选的使用引号包围。对于OpenType和TrueType字体,其字符串用于在本地可用字条的名称表中仅匹配Postscript名称或完整的字体名称。使用哪一个会因平台或字体而变,所以用户代理应当同时包含这些名称,以保持其能够跨平台匹配。
/* Gentium的粗体外观 */
@font-face {
font-family: MyGentium;
src: local(Gentium Bold), /* 完整字体名称 */
local(Gentium-Bold), /* Postscript名称 */
url(GentiumBold.ttf); /* 否则进行下载 */
font-weight: bold;
}
与@font-face规则指定一个家族中一个单独字体的特征类似,使用local()的唯一名称指定一个单独字体,而不是一个字体家族项目。OpenType字体数据的术语中定义,Postscript名称应在字体的名称表]中查找,其名称记录的nameID = 6(详细内容参见【OPENTYPE】)。Postscript名称是所有OSX和Windows下Postscript CFF字体的通用键。完整字体名称(nameID=4)被用作Windows下拥有TrueType字形的字体的唯一键。
对于拥有多个本地化完整字体名称的OpenType字体,将使用美国英语版本(对于Windows语言ID=0x409,对于Macintosh语言ID=0)或者如果美国英语的完整字体名称不可用则使用首选本地名称(OpenType规则推荐所有字体最低限度的包含美国英语名称)。同时还会匹配其他完整字体名称的用户代理,即如果当前系统位置被设为荷兰时匹配荷兰语名称,被认为是不符合规范的。这不是因为偏好英语,这是为了避免跨字体版本和OS本地化时的匹配不一致。这是由于字体样式名称(例如“Bold”)经常在被本地化为多种语言,而且跨字体版本和本地化OS的可用本地化变种集合非常广泛。匹配将家族名称(nameID=1)和样式名称(nameID=2)串联后字符串的用户代理被认为是不符合规范的。
这也允许引用那个属于不能被引用的大家族中的外观。
示例:
使用本地字体或引用一个其他文档中的SVG字体:
@font-face {
font-family: Headline;
src: local(Futura-Medium),
url(fonts.svg#MyGeometricModern) format("svg");
}
为在不同平台上的本地日文字体创建一个别名:
@font-face {
font-family: jpgothic;
src: local(HiraKakuPro-W3), local(Meiryo), local(IPAPGothic);
}
引用一个不能被匹配的大家族中的字体外观:
@font-face {
font-family: Hoefler Text Ornaments;
/* 与Hoefler Text Regular拥有相同的字体属性 */
src: local(HoeflerText-Ornaments);
}
由于不能匹配本地化的完整名称,一个拥有如下标题样式规则的文档将总是使用默认serif字体进行显示,而无论特定系统的位置参数是否被设为芬兰:
@font-face {
font-family: SectionHeader;
src: local("Arial Lihavoitu"); /* Arial Bold的芬兰语完整名称,匹配应当失败 */
font-weight: bold;
}
h2 { font-family: SectionHeader, serif; }
一个符合规范的用户代理不会在下面的例子中载入字体“gentium.eot”,因为其被包含在第一个“src”描述符中,而其被同一个@font-face规则中的第二个描述符所重写:
@font-face {
font-family: MainText;
src: url(gentium.eot); /* 为了兼容较旧的不符合规范的用户代理 */
src: local("Gentium"), url(gentium.ttf); /* 重写src描述符 */
}
字体属性描述:‘font-style’、‘font-weight’、‘font-stretch’描述
| 名称: | font-style |
| 取值: | normal | italic | oblique |
| 初始: | normal |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
| 名称: | font-weight |
| 取值: | normal | bold | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| 初始: | normal |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
| 名称: | font-stretch |
| 取值: | normal | ultra-condensed | extra-condensed | condensed | semi-condensed | semi-expanded | expanded | extra-expanded | ultra-expanded |
| 初始: | normal |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
该描述符定义了字符外观的特征,其被用于匹配样式到指定外观的过程中。对于被定义拥有多个@font-face规则的字体家族,用户代理可以下载所有家族中的外观,也可以使用这些描述符有选择地下载匹配文档中使用的实际样式的字体外观。这些描述符的值与相应的字体属性相同,但不允许使用相对关键字(‘bolder’和‘lighter’)。如果忽略了这些描述符,则假定为默认值。
这些字体外观样式属性的值被用于替代底层字体数据所隐含的样式。这允许编码人员灵活的组合外观,即使是在源字体数据拥有不同安排的情况下。实现了合成粗体和倾斜的用户代理必须在字体描述符暗示其需要的情况下仅应用合成样式,而不是基于字体数据所暗示的样式属性。
字符范围:‘unicode-range’描述
| 名称: | unicode-range |
| 取值: | <urange># |
| 初始: | U+0-10FFFF |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
此描述符定义给定字体所支持的Unicode字符的范围。其值<urange>使用十六进制数表示,其前缀“U+”,与Unicode字符码位相对应。Unicode范围描述符被用作用户代理决定是否下载一个字体资源时的提示。
Unicode范围值使用十六进制值编写且不区分大小写。每个都由“U+”作为前缀并重复,不连续的范围以逗号分隔。逗号之前或之后的空格将被忽略。有效的字符码在0至10FFFF之间(包含)变化。一个单独的范围有三种基本形式:
- 一个单独的码位(如:U+416)
- 一个区间值范围(如:U+400-4ff)
- 一个尾随表示“任意数字值”的“?”字符的范围(如:U+4??)
任何不符合上述三种形式的范围都被认为会解析出错并忽略该描述符。有一个单独码位组成的区间范围是有效的。使用“?”且没有起始数字的范围(如:U+???)也是有效的,其被认为是在问号之前有一个单独的0(因此,“U+???”=“U+0???”=“U+0000-0FFF”)。“U+??????”不是一个语法错误,但“U+0??????”是。范围是可以重叠的,但向下的区间范围(如:U+400-32f)是无效的且会被忽略但不会出现解析错误;它们不会影响在同一个范围列表中的其他范围。范围会被剪裁到Unicode码位的范围(当前包括0-10FFFF);完全超出集合的范围会被忽略。没有有效范围的描述符将被忽略。用户代理可能会将这些范围列表标准版的列入一个不同但表示相同字母码位集合的列表。
字符范围可以是底层字体完整字符映射的子集。映射字符到字体上时所使用的有效Unicode范围是Unicode范围指定的和底层字体字符映射的交集。这意味着编码人员不需要精确的定义一个字体的Unicode范围,可以使用字符中所定义的码位的稀疏集的广泛范围。超出Unicode范围的码位将被忽略,而不论该字体是否包含该码位的字形。下载了超出Unicode范围所定义码位的用户代理被认为是不符合规范的。相同的,在显示某个字符时使用了Unicode范围定义没有包含该字符的字体的用户代理也被认为是不符合规范的。
特定语言或字符范围的例子:
Unicode范围:U+A5;
Unicode范围:U+0-7F;
Unicode范围:U+590-5ff;
Unicode范围:U+A5, U+4E00-9FFF, U+30??, U+FF00-FF9F;
示例:
BBC提供多语言新闻服务,其中许多语言没有被所有平台很好地支持。使用@font-face规则,BBC可以为这些语言提供字体,如同这些字体已经通过手动下载。
@font-face {
font-family: BBCBengali;
src: url(fonts/BBCBengali.ttf) format("opentype");
unicode-range: U+00-FF, U+980-9FF;
}
示例:
科技文档通常需要更广泛的符号。STIX字体项目旨在通过标准方式提供一个支持广泛科技排版的字体。下面的例子展示了如何使用提供了许多Unicode中数学和技术范围内字形的字体:
@font-face {
font-family: STIXGeneral;
src: local(STIXGeneral), url(/stixfonts/STIXGeneral.otf);
unicode-range: U+000-49F, U+2000-27FF, U+2900-2BFF, U+1D400-1D7FF;
}
多个拥有相同家族和样式描述符但Unicode范围不同的@font-face规则可以被用于为不同脚本创建混合多个字体中字形的混合字体。这可以用于结合只包含单一脚本字形的字体(如拉丁语、希腊语、斯拉夫语)或者可以被编码任意用来将一个字体分割为常用字符和稀有字符。由于用户代理只会下载需要的字体,所以这可以帮助缩减页面贷款。
如果Unicode范围与一个拥有相同家族和样式描述符的@font-face集合重叠,则这些规则的顺序是它们被定义顺序的逆序;即首先在最后定义的规则中检查给定的字符。
示例:
下面的例子展示了编码人员如何使用其他字体中的字形覆盖日语中的拉丁字符所使用的字形。第一个规则没有指定范围,所以其默认的为全部范围。第二个规则指定了范围,由于其为后定义的,所以其覆盖了原有范围。
@font-face {
font-family: JapaneseWithGentium;
src: local(MSMincho);
/* 没有指定范围,所以其默认的为全部范围。 */
}
@font-face {
font-family: JapaneseWithGentium;
src: url(../fonts/Gentium.ttf);
unicode-range: U+0-2FF;
}
示例:
通过分隔拉丁语、日语和其他字符到不同的字体文件,最优化一个家族的贷款:
/* 备用字体 - 大小: 4.5MB */
@font-face {
font-family: DroidSans;
src: url(DroidSansFallback.ttf);
/* 没有指定范围,所以其默认的为全部范围。 */
}
/* 日语字形 - 大小: 1.2MB */
@font-face {
font-family: DroidSans;
src: url(DroidSansJapanese.ttf);
unicode-range: U+3000-9FFF, U+ff??;
}
/* 拉丁语、希腊语、斯拉夫语以及一些标点符号 - 大小: 190KB */
@font-face {
font-family: DroidSans;
src: url(DroidSans.ttf);
unicode-range: U+000-5FF, U+1e00-1fff, U+2000-2300;
}
对于简单的拉丁语文本,则只会下载拉丁语字符的字体:
body { font-family: DroidSans; }
<p>This is that</p>
在这种情况下,用户代理首先检查包含拉丁语字符的字体(DroidSans.ttf)的Unicode范围。因为所有上述字符都在U+0-5FF范围内,则用户代理下载该字体并使用该字体显示这些文本。
随后,考虑被用作简体字符的文本(⇨):
<p>This ⇨ that<p>
用户代理在此首先检查只包含拉丁语字符的字体的Unicode范围。由于U+2000-2300包含箭头码位(U+21E8),则用户代理下载该字体。对于那些拉丁语字体不能匹配字形的字符,该字体所用于的Unicode范围不能有效匹配该码位。所含用户代理评估日语字体。日语字体的Unicode范围U+3000-9FFF和U+FF??,不包含U+21E8,所以用户代理不会下载日语字体。随后考虑备用字体。备用字体的@font-face规则没有定义Unicode范围,所以其值为默认的全部Unicode码位范围。下载备用字体并使用该字体显示箭头字符。
字体特性:‘font-variant’和‘font-feature-settings’描述
| 名称: | font-variant |
| 取值: | normal | [ <common-lig-values> | | <discretionary-lig-values> | | <historical-lig-values> | | <contextual-alt-values> | | stylistic(<feature-value-name>) | | historical-forms | | styleset(<feature-value-name>#) | | character-variant(<feature-value-name>#) | | swash(<feature-value-name>) | | ornaments(<feature-value-name>) | | annotation(<feature-value-name>) | | [ small-caps | all-small-caps | petite-caps | all-petite-caps | titling-caps | unicase ] | | <numeric-figure-values> | | <numeric-spacing-values> | | <numeric-fraction-values> | | ordinal | | slashed-zero | | <east-asian-variant-values> | | <east-asian-width-values> | | ruby ] |
| 初始: | normal |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
| 名称: | font-feature-settings |
| 取值: | normal | <feature-tag-value># |
| 初始: | normal |
| 适用于: | - |
| 继承: | - |
| 百分比: | - |
| 媒介: | - |
| 计算值: | - |
| 动画: | - |
此描述符定义了在由@font-face所定义的字体被显示时所应用的设置。它们不会影响字体选择。它们的值与随后定义的‘font-variant’和‘font-feature-settings’属性完全一致,但它们忽略了‘inherit’。所使用了多个字体特性描述符或属性,在文本显示上的积累效应将在下面描述。
对于字体载入的指导方针
@font-face规则的设计,是为了允许对字体的延迟加载。字体将仅会在被文档需要时才会下载。一个样式表可以包含@font-face规则并将其作为一个只有一个选择集被使用的字体库;用户代理只能下载适用于给定页面的样式规则中引用的字体。那些下载@font-face规则中所定义的所有字体而不考虑这些字体实际上是否会在页面中使用的用户代理被认为是不符合规范的。在某些情况下,可能会因为字体后备的要求而下载字体,在这种情况下,如果字体被列在字体列表中,但不会在给定文本中实际使用,用户代理也可以下载该字体。
@font-face {
font-family: GeometricModern;
src: url(font.ttf);
}
p {
/* 页面包含p元素是将下载该字体 */
font-family: GeometricModern, sans-serif;
}
h2 {
/* 页面包含h2元素时可能会下载该字体,即使Futura在本地可用 */
font-family: Futura, GeometricModern, sans-serif;
}
如果文本内容在可下载字体可用前加载完成,则用户代理在显示文本时可以像可下载字体资源不可用时那样,或者也可以透明地使用备用字体显示文本以避免使用备用字体的文本闪烁。如果字体下载失败,用户代理必须显示文本,只留下透明文本被认为是不符合规范的行为。我们建议编码人员在其字体列表中使用与可下载字体垂直度量上相近的备用字体,以尽可能地避免出现大的页面回流。
字体的同源限制
默认的同源约束
用户代理必须实现一个在通过@font-face机制载入字体时的同源约束。该约束限制给定文档的字体载入为从相同源下载到的字体。字体只能使用【HTML5】规范中描述的源匹配算法通过相同的主机、端口和方法组成的包含文档加载。在确定字体是否同源的时候不会使用包含@font-face规则的样式表的源,而是使用包含文档的源。该约束适用于所有字体类型。
给出一个位于http://example.com/page.html的文档,禁止家族使用‘src’定义的被认为是跨域的字体:
/* 同源(即域名、协议、端口与文档匹配) */
src: url(fonts/simple.ttf);
src: url(//fonts/simple.ttf);
/* 跨源,协议不同 */
src: url(https://example.com/fonts/simple.ttf);
/* 跨源,域名不同 */
src: url(http://another.example.com/fonts/simple.ttf);
允许跨源载入字体
用户代理还必须实现使用跨站源控制(cross-site origin controls,【CORS】)放松该约束的能力。站点可以使用Access-Control-Allow-OriginHTTP头明确的允许跨站下载字体数据。
字体匹配算法
下面的算法描述了字体将如何与个体文本相关联。被选中的字体家族以及被选择的特定字体外观中的每个字符都包含一个该字符的字形。
匹配字体样式
选择字体的程度包括迭代由font-family属性所确定的字体家族、基于其他属性选择适当的字体外观以及确定指定字符对于的字形是否存在。
- 使用指定元素上字体属性计算后的值,用户代理从由‘
font-family’属性所指定的字体列表中的第一个自己家族名开始。 - 如果家族名称没有被引号括起,且它是一个通用家族名称,则用户代理查找将要使用的恰当的字体家族名。用户代理可以基于包含元素的语言或字符的Unicode范围选择通用字体家族。
- 对于其他家族名称,用户代理尝试在@font-face规则中查找该家族名称,之后继续在可用系统字体中查找。名称匹配不区分大小写。在字体包含多种本地化字体家族名称的系统中,用户代理必须在匹配这些名称时独立于底层系统的语言或所使用的平台API。如果一个由@font-face规则定义的字体家族仅包含无效的字体数据,则它应当被认为是一个存在的但包含空的字符映射的字体;在此情况下,拥有相同名称的平台字体不能匹配。
- 如果一个字体家族成功匹配,用户代理组合包含字符的字形的家族中的字体外观集。之后逐步的根据下面给出的顺序使用其他字体属性匹配一个外观:
- 首先尝试‘
font-stretch’。如果匹配集中包含宽度指匹配‘font-stretch’值的外观,则从匹配集中删除拥有其他宽度值的字形。如果没有精确匹配该宽度值的外观,则使用相近的宽度。如果‘font-stretch’为‘normal’或收缩比例值之一,则首先检查较窄的宽度值,之后检查较宽的宽度值。如果‘font-stretch’的值是扩大比例值之一,则首先检查较宽的宽度值,之后检查较窄的宽度值。一旦通过此过程确定了最近匹配的宽度,则从匹配集中删除其他宽度的外观。 - 之后尝试‘
font-style’。如果‘font-style’的值是‘italic’,则首先检查斜体外观,之后检查倾斜,然后检查正常外观。如果值为‘oblique’,则首先检查倾斜外观,之后检查斜体外观,然后检查正常外观。如果值为‘normal’,则首先检查正常外观,之后检查倾斜外观,然后检查斜体外观。从匹配集中删除拥有其他样式值的外观。我们允许用户代理在平台字体家族中区分斜体和倾斜外观,但这不是必须的,用户代理可以将斜体或倾斜外观都视为斜体外观。但是,在由@font-face规则定义的字体家族中,斜体和倾斜外观必须使用‘font-style’描述符进行区分。 - 之后匹配‘
font-weight’,它总能将匹配集缩小为一个字体外观。如果使用了更大/更小相对重量,则基于继承的重量值计算有效重量,相关信息在‘font-weight’属性的定义中描述。给定需要的重量和经过之前各步之后匹配集中外观的宽度,如果需要的重量可用,则匹配该外观。否则,使用下面的规则选择一个重量:- 如果需要的重量小于400,则首先降序检查小于所需重量的各重量,之后升序检查大于所需重量的各重量,直到找到匹配的重量。
- 如果需要的重量大于500,则首先升序检查大于所需重量的各重量,之后降序检查小于所需重量的各重量,直到找到匹配的重量。
- 如果所需的重量是400,则首先检查500,之后执行所需重量小于400的规则。
- 如果所需的重量是500,则首先检查400,之后执行所需重量大于500的规则。
- ‘
font-size’必须在用户代理决定的容差边距中匹配。(典型的,可缩放字体被四舍五入到最近的整数像素,而点阵字体的容差可以到20%。)进一步的计算(如其他属性中的“em”值)是基于使用的‘font-size’值,而不是指定的值。
- 首先尝试‘
- 如果没有匹配的外观,或者匹配的外观不包含需要显示的字符的字形,则选择下一个家族名称,并重复前面两步。如果匹配的字体是使用@font-face规则定义的,则下载字体资源。如果匹配的字体是使用@font-face规则定义的且需要下载,则用户代理可以等待字体下载也可以先使用替代字体显示然后在字体下载之后再一次显示。
- 如果没有可考虑的字体家族,而且没有找到匹配的外观,则用户代理执行系统备用字体过程来查找用于显示的最佳匹配字符。这个过程的结果可能会因用户代理而不同。
- 如果个别字符不能使用任何字体显示,则用户代理应当使用某些方法表示该字体不能显示,可以显示一个表示缺少字形的符号(例如使用Last Resort Font)或者使用默认字体中的缺失字符字形。
字符处理问题
上面的程序总会在处理包含Unicode字符在内的文本是执行,使用传统编码的文档被假定为在匹配字体之前已被转换。对于同时包含传统编码和Unicode字符映射的字体,传统编码字符映射的内容在进行字体匹配过程中不得起到任何作用。
字体匹配过程不会将文本假定为标准或非标准形式(详细内容参见【CHARMOD-NORM】)。布局引擎经常会基于字符和组合字符序列而成的预作字符(如果存在)。字体可以一般地支持匹配字符的两种方式,也可以有所不同。编码任意应当在选择字体时为它们的内容量身定制,这包括判断这些内容是否包含标准或非标准的字符流。
如果文本包含Unicode变种选择器,则需要特殊处理。对于每个字符+变种选择器配对,如果第一个包含基础字符字形的字体也包含变种选择器指定的变种的字形,则用户代理必须显示变种字形而不是默认的。如果第一个包含基础字符字形的字体不包含变种选择器对的字形,则显示默认字形。
如果给出的字符是一个私有使用区的Unicode码位且字体列表中的字体均不包含该码位的字形,则用户代理必须显示某种形式的缺失字形符号而不是尝试显示该码位的备用系统字体。在匹配替换字符U+FFFD时,用户代理可以跳过字体匹配过程而直接显示某种形式的缺失字符符号,它们不需要显示从字体匹配过程中选择的字体中获得的字形。
通常,一个家族中的字体都拥有相同或相似的字符映射。此过程被设计用来处理那些包含字符映射差异很大的外观的字体家族。但是,编码人员应当警惕使用这些字体可能会导致意外的结果。一个仅在家族中收缩比例斜体外观中可用的特殊字符可能会在字体属性暗示应当显示粗体扩张比例字形时仍被使用。
此过程的最佳情况是允许提供一个严格重视此算法的实现行为。匹配发生在一个定义良好的顺序下,以保证其结果尽可能的跨用户代理保持一致,给出一个完全一致的可用字体和显示技术集。
问题: 如何匹配字形簇需要明确指定。
字体匹配与CSS2.1的差别
上面的算法与CSS2.1的差异在几个关机位置。这些修改能够更好的反映实际字体匹配行为的跨浏览器实现。
与CSS2.1字体匹配算法的差异:
- 算法包括font-stretch匹配。
- 确定了font-style匹配中所有可能的情况。
- 小型大写字母字体不作为字体匹配过程的一部分进行匹配,它们现在通过字体特性进行处理。
- 需要Unicode变种选择器匹配。
示例:
注意CSS选择器语法可以有助于创建语言敏感的排版。举例说明,某些中文和日文字符统一地具备相同的Unicode码位,即使两种语言的抽象字形并不相同。
*:lang(ja-jp) { font: 900 14pt/16pt "Heisei Mincho W9", serif; }
*:lang(zh-tw) { font: 800 14pt/16.5pt "Li Sung", serif; }
这选择拥有指定语言(日语或繁体中文)的任意元素使用适当的字体。
字体特性属性
现代字体技术支持各种先进的排版和语言特定的字体特性。使用这些特性,一个独立的字体可以为针对指定语言的连字、上下文和格式的替代、表格式和旧式的数字、小型大写字母、自动分数、花饰以及替代提供字形。为了允许编码人员控制这些字体功能,我们在CSS3中扩展了font-variant属性,现在,它的功能更像是一系列能够控制文本字体特性的属性的速记形式。
字形选择与定位
用于显示拉丁文本的简单字体使用一个非常基础的处理模型,字体包含一个将给定字符映射到该字符的字形上的字符映射。后续字符的字形定位在文本中的下一个位置。诸如OpenType和AAT的字体格式使用更丰富的处理模型,可以选择给定字符的字形,其定义也不仅仅依靠一个单独的字符,其还会参考周围的字符以及语言、脚本和文本激活的特性。字符特性可能是特定脚本需要的,或者是推荐默认启动的,或者它们可能是编码人员控制下使用的文本特性。
对这些特性的一个不错的可视化描述,可以查看【OPENTYPE-FONT-GUIDE】。对OpenType字体字形处理的详细描述,可以查看【WINDOWS-GLYPH-PROC】。
文本字体特性可以广义的被分为两类,一类会影响字形模型与周围上下文的协调,这包括字符间距和连字特性;以及类似于小型大写字母、下标/上标以及替换特性等影响模型选择的。
下面列出的font-variant的子属性用于控制这些文本字体特性;它们不会控制显示某一脚本所需的特性,这包括显示阿拉伯语或印度语文本时使用的OpenType特性。它们影响字形选择和定位,它们不影响字体匹配章节中描述的字体选择(除非为了与CSS2.1兼容的情况)。
为了保证跨用户代理的行为一致,为某些属性列出了等价的OpenType属性并且必须被认为是符合规范的。在使用其他字体格式时,这些应当作为将CSS字体特性属性的值映射到指定字体特性上的指导。
问题: OpenType文档没有指定完整的默认特性集合。应当把它们列入规范的附录?
语言特定的显示
OpenType还支持语音特定的字形选择和定位,这使得文本可以在语言规定了特殊显示行为的情况下正确的进行显示。语言通常会公用一个通用脚本,但某些字母的模型可能会在不同语言之间存在差异,例如俄语和保加利亚语文本中的某些斯拉夫字母变种。在拉丁文本中,通常在显示“fi”时会使用去掉“i”上的点的明确的fi连字。但是,在诸如会同时使用拥有点的i和没有点的i的土耳其语的语言中,不使用该连字或者使用在i上方包含点的特殊版本,是非常重要的。下面的例子中展示了西班牙语、意大利语和法语正字法中基于文本惯例的语言特定变种。

我们要求用户代理从‘lang’属性的值中推断OpenType语言系统,并在选择和定位OpenType字体的字形时使用推断的值。如果没有定义‘lang’属性,则必须使用默认OpenType语言系统。
在某些情况下,需要明确地声明所使用的OpenType语言。例如在使用其他语言的排版惯例来显示某一语言的文本时,或者在选择的字体没有明确地支持给定的语言但其支持共用排版惯例的语言时。‘font-language-override’属性被用于此目的。
问题: 应当允许用户代理推断OpenType语言还是仅仅直接使用默认语言系统?
字距:‘font-kerning’属性
| 名称: | font-kerning |
| 取值: | auto | normal | none |
| 初始: | auto |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
字距是字形之间空间的上下文调整。该属性控制公制的字距,利用包含在字体中的调节数据的字距。其值‘normal’意味着在显示文本时应用字距,而值‘none’则意味着不应用。如果值为‘auto’,则用户代理将自由选择是否默认启用字距,并基于底层文本脚本更改默认值。
对于没有包含字距数据的字体,此属性没有可见的效果。在显示OpenType字体时,该【OPENTYPE】标准建议默认启用字距。如果启用的字距,即启用了OpenType Kern特性(对于垂直文本则启用了vkrn特性)。用户代理必须同时支持那些仅支持通过包含在‘kern’字体表中的数据进行字距调整的字体,详细描述在OpenType规范之中。编码人员可能会更愿意在性能较精致表现更为重要的情况下禁用字距调整。如果定义了‘letter-spacing’属性,则字距调整被认为是默认间距的一部分,字母间距调整则会在应用了字距调整之后再进行。
连字:‘font-variant-ligatures’属性
| 名称: | font-variant-ligatures |
| 取值: | normal | none | [ <common-lig-values> | | <discretionary-lig-values> | | <historical-lig-values> | | <contextual-alt-values> ] |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
连字和上下文形式是一种结合字形以产生更协调的形式。值‘normal’意味着启用通用默认特性,这将在之后的章节进行描述。对于OpenType字体,默认启用通用的连字和上下文形式,而不会启用酌情和历史连字。值‘none’意味着本属性所涵盖的所有类型的连字和上下文形式都将被禁用。在连字被认为不必要的情况下,这可以提供显示文本的速度。
<common-lig-values>
<discretionary-lig-values>
<historical-lig-values>
<contextual-alt-values>
独立值的意义如下:
common-ligatures
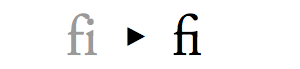
no-common-ligatures
discretionary-ligatures
no-discretionary-ligatures
historical-ligatures
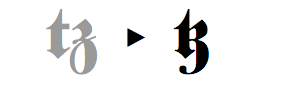
no-historical-ligatures
contextual

no-contextual
在显示复杂脚本是所需的必要的连字不受上面所提到的设置所影响,包括‘none’(OpenType特性:rlig)。
下标和上标形式:‘font-variant-position’属性
| 名称: | font-variant-position |
| 取值: | normal | sub | super |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
此属性用于启动上标和下标字形的排版。这将替换在相同EM盒子中作为默认字形而设计的字形,并将其布局在与默认字形相同的基线上而不会调整基线的大小或位置。它们的设计是为了在不影响行高的情况下与周围的文本更协调、更具可读性。
图21:下标字形(上)VS典型的合成下标(下)
值‘sub’和‘super’意味着如果字体中对应的变种字形存在则显示变种字形(OpenType特性:subs、sups)。值‘normal’意味着这两种替代字形均不会被替换。
因为上标和下标的语义性质,如果给定的一段文本的值是‘sub’或‘super’而且变种字形对于这段文本中的字符并不全部可用,则模拟字形是使用默认字型的缩小形式的所有字符合成而得的。这是为了避免在同一段文本中混合使用变种字形和合成字形,这两种字形不能保证能够正确地相互对齐。
对于OpenType字体缺少指定字符上标或下标字形的情况,用户代理必须使用选中字体OS/2表【OPENTYPE】中指定的对应的上标和下标度量计算合成的替代字形的大小和偏移量。
在过去,用户代理使用font-size和vertical-align来模拟sub和sup元素中的上标和下标。为了允许向后兼容上标和下标的定义,我们推荐编码人员使用条件规则【CSS3-CONDITIONAL】以便老的用户代理可以通过老的机制显示上标和下标。
编码人员应当注意字体通常只为其所支持字符的子集提供上标和下标字形。通常拉丁数字的上标和下标字形是可用,而符号和字母字符的字形较少提供。如果所使用的字体没有体会上标或下标中所包含的所有字符对应的替换字形,此属性定义的合成备用规则保证了总是能够显示上标和下标,但这并不保证其能符合编码人员的预期。
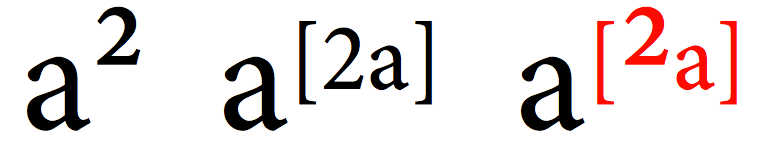
图22:上标替换字符(左)、合成上标字符(中)以及错误的两者混合(右)
此属性不能累加,将其应用于上标或下标中的子元素不会进一步飞定位上标或下标字形。此属性的值为‘sub’或‘super’的一段文本中包含的图片在绘制时与值为‘normal’时相同。相似的,诸如下划线或着重符号的文本装饰在显示时也与在默认字形上相同,这是由于此属性不会影响基线位置。
基于这些限制,我们不推荐在用户代理样式表中使用font-variant-position。编码人员应当在指定字体值支持少量字符的上标或下标的情况下使用此属性。
示例:
典型用户代理sub元素的默认样式:
sub {
vertical-align: sub;
font-size: smaller;
line-height: normal;
}
使用font-variant-position指定上标排版并同时能够在老的用户代理上显示上标:
@supports ( font-variant-position: sub ) {
sub {
vertical-align: inherit;
font-size: 100%;
line-height: inherit;
font-variant-position: sub;
}
}
支持‘font-variant-position’属性的用户代理将会选择上标变种字形并在显示时不会调整基线或font-size。老的用户代理将忽略‘font-variant-position’属性的定义同时使用标准的默认上标。
大小写:‘font-variant-caps’属性
| 名称: | font-variant-caps |
| 取值: | normal | small-caps | all-small-caps | petite-caps | all-petite-caps | unicase | titling-caps |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
指定控制大写形式。
各值的意义如下:
normal
small-caps
all-small-caps
petite-caps
all-petite-caps
unicase
titling-caps
此属性允许选择替换用于小型或细小大写字母或标题的字形。这些字形的设计是为了能够更好的与周围的默认字形混合,为了保持重量和可读性这些文本简单的被调整大小以适应这一目的。
这些字形的可用性基于字体特性列表中是否定义了给定的特性。用户代理可以有选择地针对每个脚本进行判断,但不能针对每个字符进行判断。
某些字体可能会只支持此属性中的一部分特性或者完全不支持。为了向后兼容CSS2.1,如果指定了‘small-caps’或‘all-small-caps’但指定字体的small-caps字形不可用,则用户代理应当模拟一个small-caps字体,例如获取默认字体并将小写字母的字形替换为大写字符字形的缩小版本(在‘all-small-caps’的情况下同时替换大写和小写字母)。
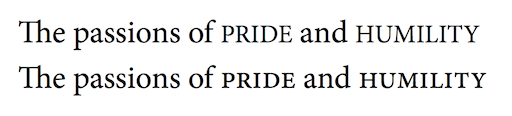
图23:合成与实际的small-caps
为了与周围的文本相协调,在启用了这些特性而不是由用户代理模拟小型大写字母时,字体可能会为不区分大小写的字符替换替代字形,禁止为不区分大小写的码位模拟替代字形。

图24:启用了small-caps、all-small-caps的不区分大小写字符
如果为一个不支持‘petite-caps’和‘all-petite-caps’特性的字体指定了这些特性,则此属性的行为与指定了对应的‘small-caps’或‘all-small-caps’相同。如果为一个不支持‘unicase’特性的字体指定了该特性,则此属性的行为与仅在小写大写字母上应用‘small-caps’相同。如果在一个不支持‘titling-caps’特性的字体上指定了该特性,则此属性的行为没有可见的效果。如果使用了模拟的小型大写字形,对于确实大写和小写字母的脚本,‘small-caps’、‘all-small-caps’、‘petite-caps’、‘all-petite-caps’和‘unicase’没有可见的效果。
如果使用大小写转换来模拟小型大写字母,则大小写转换应当与‘text-transform’属性所使用的相匹配。
作为最后的手段,缩小默认字体中的大写字母字形可能会替换small-caps字体中的字形,这使得文本以全大写字母形式出现。

图25:在首字母满载的文本中使用小型大写字母以改善可读性
示例:
斜体显示引用,其中第一行使用samall-caps:
blockquote { font-style: italic; }
blockquote:first-line { font-variant: small-caps; }
<blockquote>I'll be honor-bound to slap them like a haddock.</blockquote>
数字格式:‘font-variant-numeric’属性
| 名称: | font-variant-numeric |
| 取值: | normal | [ <numeric-figure-values> | | <numeric-spacing-values> | | <numeric-fraction-values> | | ordinal | | slashed-zero ] |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
指定控制数组形式。
<numeric-figure-values>
<numeric-spacing-values>
<numeric-fraction-values>
独立值的意义如下:
normal
lining-nums
oldstyle-nums
proportional-nums
tabular-nums
下面的例子展示了这些不同的属性将如何结合起来影响支持这些特性的字体的表格数据的显示。

图26:使用数字样式
diagonal-fractions

stacked-fractions

ordinal
slashed-zero

示例:
一个用自动分数和就是数值显示的简单的牛排腌制配方:
.amount { font-variant-numeric: oldstyle-nums diagonal-fractions; }
<h4>牛排腌制:</h4>
<ul>
<li><span class="amount">2</span>汤匙橄榄油</li>
<li><span class="amount">1</span>汤匙柠檬汁</li>
<li><span class="amount">1</span>汤匙酱油</li>
<li><span class="amount">1 1/2</span>汤匙干燥的碎洋葱</li>
<li><span class="amount">2 1/2</span>茶匙意大利调味料</li>
<li>盐 & 胡椒</li>
</ul>
<p>将肉与腌料混合是其完全覆盖,在冰箱中放置几个小时或一整夜。</p>
替换和花饰:‘font-variant-alternates’属性
| 名称: | font-variant-alternates |
| 取值: | normal | [ stylistic(<feature-value-name>) | | historical-forms | | styleset(<feature-value-name>#) | | character-variant(<feature-value-name>#) | | swash(<feature-value-name>) | | ornaments(<feature-value-name>) | | annotation(<feature-value-name>) ] |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
对于任意给定的字符,除了该字符的默认字形外,字体还可以提供各种额外的替代字形。此属性提供了对这些替换字形选择的控制。
对于存在多种可用替代品的情况,编码人员使用下面描述的@font-feature-values规则定义一个<feature-value-name>来明确的指定需要使用的替代品。这些替代品的种类是字体特定的,所以该规则为特定字体家族或家族集合定义值。如果一个特定的值没有在给定的家族中定义,则这个已命名的值被当做从样式规则中忽略该特性。如果给定的值超出给定字体所支持的范围,则忽略该值。这些值不会被应用于通用字体家族和被选为系统备用字体一部分的家族。这样的值被标记为字体特定。
独立值的意义如下:
normal
stylistic(<feature-value-name>)

historical-forms

styleset(<feature-value-name>#)

character-variant(<feature-value-name>#)
swash(<feature-value-name>)
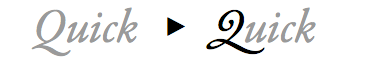
ornaments(<feature-value-name>)

annotation(<feature-value-name>)

定义字体特定的替换:@font-feature-values规则
上面列出的几种‘font-variant-alternates’可能的值被标记为“字体特定”。对于这些特性,字体可能不会只定义一个字形,而是定义一组使用索引进行选择的替代字形。因为这些事字体家族特定的,所以使用@font-feature-values规则定义给定家族中各索引的名值对。
下面的例子中展示了花饰Q的情况,花饰可以使用这些样式规则指定:
@font-feature-values Jupiter Sans {
@swash {
delicate: 1;
flowing: 2;
}
}
h2 { font-family: Jupiter Sans, sans-serif; }
/* 在h2标题中显示第二种花饰变种 */
h2:first-letter { font-variant-alternates: swash(flowing); }
<h2>Quick</h2>
如果存在Jupiter Sans,则显示第二种花饰替代品。如果不存在,因为名值对“flowing”仅为Jupiter Sans家族定义,则不会显示花饰字符。@符号声明可以使用名值对的属性值的名称。名称“flowing”由编码人员决定。
@font-feature-values规则的语法定义如下:
@font-feature-values <font-family># {
@<feature-type> {
<feature-ident> : <feature-index>+;
<feature-ident> : <feature-index>+;
...
}
...
}
其中:
<font-family>
<feature-type>
<feature-ident>
<feature-index>
@font-feature-values规则可以出现在样式表中的任何位置,并且可以跨@import边界双方向暴露。在每个字体特性值声明中,诸如未知属性值名称的语法错误、无效标识符或值将被移除,这类似于对样式声明中语法错误的处理相似。
如果为一个家族定义了多个@font-feature-values规则,其结果是联合这些规则。这允许为一个字体家族在整站范围定义一组名值对,并在各个页面进行追加。如果为一个font-variant值定义了多次相同的<feature-value-name>,则使用最后定义的值。
@font-feature-values Mercury Serif {
@styleset {
stacked-g: 3; /* "two-storey" versions of g, a */
stacked-a: 4;
}
} @font-feature-values Mercury Serif {
@styleset {
geometric-m: 7; /* alternate version of m */
}
}
body {
font-family: Mercury Serif, serif;
/* enable both the use of stacked g and alternate m */
font-variant-alternates: styleset(stacked-g, geometric-m);
}<font-family>只允许使用已命名字体家族,在字体家族名称的列表中包含通用或系统字体的规则被认为是语法错误,该规则中的内容将被忽略。但是,如果用户代理将通用字体定义为一个已命名的字体(如Helvetica),则可以使用与该家族名称有关的设置。
对于<font-variant-property-value>,只有被‘font-variant’属性支持的字体特定属性值名称才会被认可,其他值名称的定义将会被认为是语法错误并被忽略。每个字体特定的属性值都被清楚的标出。特征值名称遵循CSS标识符的规则且不区分大小写。它们针对给定的字体家族集合与font-variant属性值而唯一;在不同font-variant属性值中使用的相同标识符会被认为是独特且不同的值。
使用通用的已命名值,可以让编码人员使用一个样式规则覆盖一系列底层选择器不同的字体。如果下面例子中能够找到任一字体,则将会使用一个圆圈数字字形:
@font-feature-values Taisho Gothic {
@annotation { boxed: 1; circled: 4; }
}
@font-feature-values Otaru Kisa {
@annotation { circled: 1; black-boxed: 3; }
}
h3.title {
/* 圆圈来自于定义的两个字体 */
font-family: Taisho Gothic, Otaru Kisa;
font-variant: annotation(circled);
}
大多数字体为font-variant属性值指定一个单独的值(例如swash)。character-variant属性值允许两个值,styleset不限数目。如果一个给定的名称与过多的值相关联,将会出现语法错误,并会忽略整个<font-feature-values-declaration>。
对于styleset属性值,多个值表示启用样式集。值1至99表示启用OpenType特性ss01至ss99。但是,OpenType标准只正式定义了ss01至ss20。大于99或等于0的值将被忽略,但在解析时不会产生语法错误。
@font-feature-values Mars Serif {
@styleset {
alt-g: 1; /* 意味着 ss01 = 1 */
curly-quotes: 3; /* 意味着 ss03 = 1 */
code: 4 5; /* 意味着 ss04 = 1, ss05 = 1 */
}
@styleset {
dumb: 125; /* >99,忽略 */
}
@swash {
swishy: 3 5; /* swash超过一个值,语法错误 */
}
}
p.codeblock {
/* 意味着 ss03 = 1, ss04 = 1, ss05 = 1 */
font-variant-alternates: styleset(curly-quotes, code);
}
对于character-variant,一个单独的1至99的值表示启用OpenType特性cv01至cv99。对于OpenType字体,大于99或等于0的值将被忽略,但解析时不会产生语法错误。如果列出的两个值,则第一个值表示使用的特性,第二个值传递给该特性。如果两个值名称表示相同底层特性的不同设置,则使用最后设置的。
@font-feature-values MM Greek {
@character-variant { alpha-2: 1 2; } /* 意味着 cv01 = 2 */
@character-variant { beta-3: 2 3; } /* 意味着 cv02 = 3 */
@character-variant { epsilon: 5 3 6; } /* 超过两个值,语法错误,忽略 */
@character-variant { gamma: 12; } /* 意味着 cv12 = 1 */
@character-variant { zeta: 20 3; } /* 意味着 cv20 = 3 */
@character-variant { zeta-2: 20 2; } /* 意味着 cv20 = 2 */
@character-variant { silly: 105; } /* >99,忽略 */
@character-variant { dumb: 323 3; } /* >99,忽略 */
}
#title {
/* 使用第三个替代beta、第一个替换gamma */
font-variant-alternates: character-variant(beta-3, gamma);
}
p {
/* zeta-2在zeta之后,意味着 cv20 = 2 */
font-variant-alternates: character-variant(zeta, zeta-2);
}
.special {
/* zeta在zeta-2之后,意味着 cv20 = 3 */
font-variant-alternates: character-variant(zeta-2, zeta);
}
查看对象模型,描述通过CSS对象模型修改这些规则的接口。

图27:使用字符变种显示拜占庭印章文本
示例:
在上图中,红色文本是使用包含字符变种的字体显示的,该字符变种模仿从公园8世纪的拜占庭印章上发现的字符形式。之后的两行则是使用不含变种的字体显示的相同文本。请注意印章上所使用的U和N的两个变种。
@font-feature-values Athena Ruby {
@character-variant {
leo-B: 2 1;
leo-M: 13 3;
leo-alt-N: 14 1;
leo-N: 14 2;
leo-T: 20 1;
leo-U: 21 2;
leo-alt-U: 21 4;
}
}
p {
font-variant: discretionary-ligatures,
character-variant(leo-B, leo-M, leo-N, leo-T, leo-U);
}
span.alt-N {
font-variant-alternates: character-variant(leo-alt-N);
}
span.alt-U {
font-variant-alternates: character-variant(leo-alt-U);
}
<p>ENO....UP͞RSTU<span class="alt-U">U</span>͞<span class="alt-U">U</span>ΚΑΙTỤẠG̣IUPNS</p>
<p>LEON|ΚΑΙCONSTA|NTI<span class="alt-N">N</span>OS..|STOIBAṢ.|LIṢROM|AIO<span class="alt-N">N</span></p>
东亚文本渲染:‘font-variant-east-asian’属性
| 名称: | font-variant-east-asian |
| 取值: | normal | [ <east-asian-variant-values> | | <east-asian-width-values> | | ruby ] |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
允许控制东亚文本的替代和大小。
<east-asian-variant-values>
<east-asian-width-values>
独立值的意义如下:
normal
jis78

jis83
jis90
jis04
simplified
simplified’和‘traditional’允许控制那些已经随时间而被简化但较旧的传统形式仍在某些上下文中使用的字符的字形形式。对于一个进过设计的字体,确切的字符集合字形形式在一定程度上会存在差异。traditional

full-width
proportional-width

ruby

字体渲染的全部速记属性:‘font-variant’属性
| 名称: | font-variant |
| 取值: | normal | none | [ <common-lig-values> | | <discretionary-lig-values> | | <historical-lig-values> | | <contextual-alt-values> | | stylistic(<feature-value-name>) | | historical-forms | | styleset(<feature-value-name>#) | | character-variant(<feature-value-name>#) | | swash(<feature-value-name>) | | ornaments(<feature-value-name>) | | annotation(<feature-value-name>) | [ small-caps | all-small-caps | petite-caps | all-petite-caps | unicase | titling-caps ] | | <numeric-figura-values> | | <numeric-spacing-values> | | <numeric-fraction-values> | | ordinal | | slashed-zero | | <east-asian-variant-values> | | <east-asian-width-values> | | ruby ] |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
值‘normal’表示所有其他字体特性属性均为它们的初始值。值‘none’设置‘font-variant-ligatures’为‘none’并重置所有其他字体特性属性为它们的初始值。与其他速记属性类似,使用‘font-variant’会重置未指定的font-variant子属性为它们的初始值。它不会重置‘font-language-override’或‘font-feature-settings’的值。
低等级字体特性设置控制:‘font-feature-settings’属性
| 名称: | font-feature-settings |
| 取值: | normal | <feature-tag-value># |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
此属性提供对OpenType字体特定的低等级控制。它的目的是提供一种方法来访问那些不被广泛使用但在某些特定情况下需要的字体特性。其值‘normal’意味着不会因此属性而改变字形的选择和定位。
/* 启用小型大写字母和第二种花饰替代 */
font-feature-settings: "smcp", "swsh" 2;
特性标记值的语法如下:
<feature-tag-value>
<string>是区分大小写的OpenType特性标签。按照OpenType规范中的定义,特性标签包含四个ASCII字符。长于或短于四个字符、或者包含U+20-7E码位范围之外字符的标签字符串是无效的。用户代理禁止使用截断或填充到四个字符的字符串创建特性标签。特征标签需要只匹配一个字体中顶一个的特征标签,它们不限于明确注册的OpenType特征。字体定义的自定义特性标签应当遵循OpenType规范中定义的标签名称规则【OPENTYPE-FEATURES】。字体中不存在的特性标记将被忽略;用户代理禁止视图基于这些特性标签合成备用行为。
这意味着明确地禁用kern特性不会影响‘kern’表中字距数据(相反字距数据与‘GPOS’表中的kern特性相关)。由于此属性会同时影响两种字距,编码人员应当使用‘font-kerning’属性来明确地启用或禁用字距。
如果存在,一个值声明一个用于选择字形的索引。一个<integer>值必须大于等于0。值0声明禁用该特性。对于布尔型特性,值1启用该特性。对于非布尔型特性,值1或者大于1的值启用该特性并且声明所选择的索引。值‘on’等价于1,值‘off’等价于0。如果忽略了值,则假定为1。
font-feature-settings: "dlig" 1; /* dlig=1 启用酌情连字 */
font-feature-settings: "smcp" on; /* smcp=1 启用小型大写字母 */
font-feature-settings: 'c2sc'; /* c2sc=1 启用大写及小写字母的小体大写字母 */
font-feature-settings: "liga" off; /* liga=0 禁用通用连字 */
font-feature-settings: "tnum", 'hist'; /* tnum=1, hist=1 启用表格数字和历史形式 */
font-feature-settings: "tnum" "hist"; /* 无效,需要一个逗号分隔的列表 */
font-feature-settings: "palin" off; /* 好主意,但标记名无效 */
font-feature-settings: "PKRN"; /* PKRN=1 启用自定义特性 */
font-feature-settings: dlig; /* 无效,标记必须为一个字符串 */
只要可行,编码人员通用应当使用‘font-variant’及其相关子属性。只有在特殊情况下才能使用此属性,即这是唯一一种访问特定的不经常使用的字体特性的途径。
虽然目前仅为OpenType特性标记进行定义,但其他支持字体特性的现代字体格式也可能会在未来增加。如果可能,为其他字体格式定义的特性应当遵循注册OpenType标签的模式。
示例:
下面的日语文本将使用半角kana字符显示:
body { font-feature-settings: "hwid"; /* 半角OpenType特性 */ }
<p>毎日カレー食べてるのに、飽きない</p>
字体语言覆盖:‘font-language-override’属性
| 名称: | font-language-override |
| 取值: | normal | <string> |
| 初始: | normal |
| 适用于: | 所有元素 |
| 继承: | 是 |
| 百分比: | (不适用) |
| 媒介: | 视觉 |
| 计算值: | 特定值 |
| 动画: | - |
值‘normal’意味着在显示OpenType字体时,使用文档的语言推测OpenType语言系统。而它是在进行显示时用来选择语言特定特性的。其值<string>是一个单独的三个字母的OpenType语言系统标签,其定义于OpenType规范的布局标签注册。
示例:
《世界人权宣言》被翻译为多种语言。在土耳其语中,此文档的第9条可能会如下标记:
<body lang="tr">
<h4>Madde 9</h4>
<p>Hiç kimse keyfi olarak tutuklanamaz, alıkonulanamaz veya sürülemez.</p>
此处用户代理在显示文本时使用‘lang’属性的值,并且适当的不适用‘fi’连字显示这些文本。这里不需要使用‘font-language-override’属性。
但是,一个给定的字体可能会缺乏对特定语言的支持。在这种情况下,编码人员可能会需要使用该字体支持的相关语言的排版惯例:
<body lang="mk"> <!-- 马其顿语言代码 -->
body { font-language-override: "SRB"; /* 塞尔维亚语OpenType语言标签 */ }
<h4>Члeн 9</h4>
<p>Никoj чoвeк нeмa дa бидe пoдлoжeн нa прoизвoлнo aпсeњe, притвoр или прoгoнувaњe.</p>
在显示此处的马其顿文本时,将使用塞尔维亚语排版惯例,假设指定字体支持塞尔维亚语。
字体特性解析
在之前章节的描述中,字体可以可以通过多种途径启用,既可以在样式规则中使用‘font-variant’或‘font-feature-settings’也可以在@font-face规则中设置。联合使用这些设置时的决定顺序在下面描述。通过CSS属性定义的特性应用于布局引擎的默认特性之上。
默认特性
对于OpenType字体,用户代理必须启用OpenType文档中对给定脚本和书写模式定义的默认特性。必要的连字、通用连字以及上下文形式必须默认启用(OpenType特性:rlig、liga、clig、calt),另外还有本地化形式(OpenType特性:locl)和为了正确显示字符和符号所需的特性(OpenType特性:ccmp、mark、mkmk)。即使‘font-variant’和‘font-feature-settings’属性被设为‘normal’,也必须启用这些特性。个体属性只有在被编码人员明确拒绝时才会被禁用,例如设‘font-variant-ligatures’为‘no-common-ligatures’。为了处理诸如阿拉伯语、蒙古语或天城文的符合脚本,需要额外的特性。对于垂直排列的竖排文本,必须启用垂直替代(OpenType特性:vert)。
特性优先级
通用和字体特定的字体特性属性设置按照下面的顺序提升优先级进行处理。此顺序用于生成一个影响给定文本的字体特性列表组合。
- 默认启用的字体特性,包括给定脚本需要的特性。
- 如果字体是通过@font-face规则定义的,@font-face规则中font-variant描述符表示的字体特性。
- 如果字体是通过@font-face规则定义的,@font-face规则中font-feature-settings描述符表示的字体特性。
- 由‘
font-variant’或‘font-feature-settings’之外的属性所确定的字体设置。例如为‘letter-spacing’属性设置一个非默认值禁用连字。 - 由‘
font-variant’属性所确定的字体特性,相关font-variant字属性和其他可能会使用OpenType特性的CSS属性(如‘font-kerning’属性)。 - 由‘
font-feature-settings’属性所确定的字体特性。
此顺序允许编码人员在@font-face规则中为字体建立一个通用的默认集,之后使用特定元素上的属性进行覆盖。通用属性设置覆盖@font-face规则中的设置,低等级字体特性设置覆盖‘font-variant’属性设置。
对于字体特性设置列表组合中包含多个对于相同特性的值的情况,使用最后一个值。若字体缺少对指定底层字体特性的支持,显示字体时则按照没有启用该字体特性处理;不会出现备用字体,并且除非明确为指定属性指出,不会视图合成该特性。
特性优先级实例
示例:
下面的样式中,数字在段落中被显示为比例值,在prices表格中被显示为等宽值。
body {
font-variant-numeric: proportional-nums;
}
table.prices td {
font-variant-numeric: tabular-nums;
}
示例:
如果在@font-face规则中使用了font-variant描述符,其只适用于该规则所定义的字体。
@font-face {
font-family: MainText;
src: url(http://example.com/font.ttf);
font-variant: oldstyle-nums proportional-nums styleset(1,3);
}
body {
font-family: MainText, Helvetica;
}
table.prices td {
font-variant-numeric: tabular-nums;
}
在此情况下,除了使用“MainText”字体的地方,其他地方都将使用旧式数字。和之前的例子一样,因为通用样式规则中设置了‘tabular-nums’且它与‘proportional-nums’相互独立,所以在prices表格中使用了等宽值。格式替换集值适用于使用了MainText的地方。
示例:
@font-face规则还可以通过在其定义中‘src’描述符内使用local()来访问本地可用字体中的字体特性:
@font-face {
font-family: BodyText;
src: local("HiraMaruPro-W4");
font-variant: proportional-width;
font-feature-settings: "ital"; /* 拥有中日韩文本特性的拉丁斜体 */
}
body { font-family: BodyText, serif; }
如果可用,则会使用日语字体“Hiragino Maru Gothic”。在显示文本时,日语假名将会按比例分隔,同时拉丁文本将用斜体字显示。在使用备用的衬线字体显示文本时,将使用默认的显示属性。
示例:
在下面的例子中,只会在可下载字体上启用酌情连字,但是在class为“special”的span元素上禁用:
@font-face {
font-family: main;
src: url(fonts/ffmeta.woff) format("woff");
font-variant: discretionary-ligatures;
}
body { font-family: main, Helvetica; }
span.special { font-variant-ligatures: no-discretionary-ligatures; }
向上面的@font-face追加酌情样式规则:
body { font-family: main, Helvetica; }
span { font-feature-settings: "dlig"; }
span.special { font-variant-ligatures: no-discretionary-ligatures; }
在class为“special”的span中,将显示酌情连字。这是因为‘font-feature-settings’和‘font-variant-ligatures’同时应用于该元素。尽管将‘font-variant-ligatures’设为‘no-discretionary-ligatures’有效的禁用了OpenType dlig特性,但因为‘font-feature-settings’的处理在其之后,其值‘dlig’重新启用了酌情连字。
对象模型
@font-face和@font-feature-values规则的内容可以通过下面到CSS对象模型的扩展来访问。
CSSFontFaceRule接口
CSSFontFaceRule接口表示一个@font-face规则。
interface CSSFontFaceRule : CSSRule {
attribute DOMString family;
attribute DOMString src;
attribute DOMString style;
attribute DOMString weight;
attribute DOMString stretch;
attribute DOMString unicodeRange;
attribute DOMString variant;
attribute DOMString featureSettings;
}
DOM Level 2样式规范【DOM-LEVEL-2-STYLE】为此规则定义了一个不同的变种。这个定义取代了那个。
CSSFontFeatureValuesRule接口
CSSRule接口如下扩展:
partial interface CSSRule {
const unsigned short FONT_FEATURE_VALUES_RULE = 14;
}
CSSFontFeatureValuesRule接口表示一个@font-feature-values规则。
interface CSSFontFeatureValuesRule : CSSRule {
readonly attribute DOMString familyList;
readonly attribute DOMString valueText;
};
familyList,类型DOMString,只读
valueText,类型DOMString,只读
字体加载事件
因为通过@font-face规则定义的字体会在需要时加载,页面可能会在测量文本元素或者显示某种形式的临时用户界面状态时需要知道字体在何时完成下载。
扩展Document接口
为了让字体加载能够被显式地跟踪,需要将下列事件目标加入到页面的Document中:
partial interface Document {
readonly attribute FontLoader fontloader;
};
FontLoader接口
dictionary CSSFontFaceLoadEventInit : EventInit {
CSSFontFaceRule fontface = null;
DOMError error = null;
};
[Constructor(DOMString type, optional CSSFontFaceLoadEventInit eventInitDict)]
interface CSSFontFaceLoadEvent : Event {
readonly attribute CSSFontFaceRule fontface;
readonly attribute DOMError error;
}
callback FontsReadyCallback = void ();
interface FontLoader : EventTarget {
// -- 载入状态变化时的事件
attribute EventHandler onloading;
attribute EventHandler onloadingdone;
// -- 针对个体字体加载的事件
attribute EventHandler onloadstart;
attribute EventHandler onload;
attribute EventHandler onerror;
// 检查字体是否已经加载和可用(如果不可用不会初始化加载)
boolean isFontAvailable(DOMString font, optional DOMString text = " ");
// 检查,如果适当则开始加载
void loadFont(DOMString font, optional DOMString text = " ");
// 完成后进行异步通知,挂起布局变化
void notifyWhenFontsReady(FontsReadyCallback fontsReadyCallback);
// 加载状态,如果正在加载一或多个字体则为真,否则为假
readonly attribute boolean loading;
};
因为@font-face规则定义的字体家族只在其使用时才会家族,内容有时会需要知道字体加载在何时发生。编码人员可以使用这里定义的事件和方法来允许对依赖特定字体可用性的行为进行更多控制。
之后使用的术语字体加载表示对一个给定@font-face规则内容的加载完成的时刻。一个@font-face规则可能会使用‘src’描述符列出多个替代资源,包括到本地字体的引用,但本术语只涉及给定规则最终所选择的资源的载入,而不是对每个个体资源的载入。
事件
下列事件处理函数(及其对应的事件处理函数事件类型)必须被FontLoader对象作为IDL属性所支持。
| 事件处理函数 | 事件处理函数事件类型 |
|---|---|
| onloading | loading |
| onloadingdone | loadingdone |
| onloadstart | loadstart |
| onload | load |
| onerror | error |
在对象target上使用一个给定字体外观规则和一个错误触发一个名为e的字体载入事件,意味着在target上触发一个名为e的事件,该事件使用CSSFontFaceLoadEvent接口,并伴随下列约束:
- 初始化
fontface属性为给定的字体外观规则。 - 初始化
error属性为给定的错误。
如果用户代理确定需要下载通过文档doc中@font-face规则定义的一个或多个字体,则必须执行下列步骤:
- 设字体载入器为doc的
fontloader属性的值。 - 设字体载入器的
loading属性为真。 - 在字体载入器上使用字体外观规则和错误触发一个名为“
loading”的字体载入事件。 - 如果用户代理正在载入给定@font-face规则中的第一个资源,其必须在字体载入器上触发一个名为“
loadstart”的字体载入事件,其中设字体外观为造成此次载入开始的@font-face规则、设错误为????。
问题: 此处应该使用哪种错误类型?
术语“字体载入”覆盖了‘src’描述符中资源列表,其中也包含本地字体。如果列出了多个资源,则“字体载入”是列表中第一个成功载入的资源或者视图载入最后一个资源时产生的错误。
问题: 给出的@font-face规则集可能会同时进行载入,“loading”事件的非空值是否有意义?
用户代理完成文档doc中的每个字体载入时,必须执行下列步骤:
- 设字体载入器为doc的
fontloader属性的值。 - 如果‘
src’描述符中所列出的资源均不包含有效数据,则在字体载入器上触发一个名为“error”的字体载入事件,其中设字体外观为造成此次载入开始的@font-face规则、设错误为[空?]。 - 否则,在字体载入器上触发一个名为“
load”的字体载入事件,其中设字体外观为造成此次载入开始的@font-face规则、设错误为[空?]。
用户代理完成文档doc中最后的字体载入时,必须执行下列步骤:
- 设字体载入器为doc的
fontloader属性的值。 - 设字体载入器的
loading属性为假。 - 在字体载入器上使用被设为最后载入字体的字体外观规则和一个错误触发一个名为“
loadingdone”的字体载入事件。
loading”事件,其后跟随三个“loadstart”事件和三个“load”或“error”事件,其后跟随一个“loadingdone”事件。方法
方法isFontAvailable和loadFont必须确定所有在给定字体列表中的字体是否已经载入和可用。如果所有字体均可用,则isFontAvailable必须返回真,如果一个或多个字体不可用则必须返回假。对于loadFont,如果有字体为可下载字体且尚未被载入,则用户代理必须为每个这样的字体初始化加载。
这两个方法都需要一个指定字体列表的font属性和一个可选的指定将使用这些字体的文本的text属性。font的值必须使用与‘font’属性相同的语法进行解析,使用与CanvasRenderingContext2D的font属性相同的方式进行解释。【HTML5】这将产生一个伴随字体样式属性的字体家族列表。
isFontAvailable(font, text)方法必须执行下列步骤:
- 使用‘font’属性的CSS值语法解析
font属性的值。 - 如果出现语法错误,则返回假。
- 否则,设字体家族列表为家族集合,字体样式为其他字体样式属性。
- 如果字体家族列表中的任意字体不是通过@font-face规则定义的,或是平台没有提供的,则返回假。
- 对于字体家族列表中的每个家族,使用字体匹配规则选择匹配字体样式的字体外观。对于通过@font-face规则定义的字体外观,‘unicode-range’的使用意味着其可能不仅仅是单一的字体外观。
- 从字体外观集中移除那些‘unicode-range’值与
text属性中字符值范围不相交的外观。 - 如果集合中没有字体外观,则返回假。
- 否则,如果集合中余下的所有字体外观均已被载入也可用,则返回真,如果其中任一不可用则返回假。
loadFont(font, text)方法必须执行下列步骤:
- 使用‘font’属性的CSS值语法解析
font属性的值。 - 如果出现语法错误,则返回。
- 否则,设字体家族列表为家族集合,字体样式为其他字体样式属性。
- 对于字体家族列表中的每个家族,使用字体匹配规则选择匹配字体样式的字体外观。对于通过@font-face规则定义的字体外观,‘unicode-range’的使用意味着其可能不仅仅是单一的字体外观。
- 从字体外观集中移除那些‘unicode-range’值与
text属性中字符值范围不相交的外观。 - 对于字体集合中的所有字体外观,载入那些尚未载入的外观。
因为载入字体的数量取决于给定文本中所需使用的字体数,在某些情况下,可能不知道是否需要载入字体。notifyWhenFontsReady方法为编码人员提供一种避免在检查使用某字体的内容前去跟踪字体是否已被载入的方法。
notifyWhenFontsReady(fontsReadyCallback)方法必须执行下列步骤:
- 设字体载入器为doc的
fontloader属性的值。 - 向字体载入器的通知回调列表中添加
fontsReadyCallback属性的值,并返回。 - 一旦所有挂起的布局操作全部完成,确定字体资源是否需要加载。
- 如果没有正在处理的加载,则将通知回调列表中的内容复制到字体载入器的通知挂起列表中同时清空通知列表。之后调用通知挂起列表中的每个回调并清空通知挂起列表。
- 否则,一旦所有字体载入完成,则在触发“
loadingdone”事件之后依照上一步中的机制调用每个回调。
编码人员应当注意此处的回调仅触发一次,此方法需要在可能的进一步字体载入发生时再次调用。此方法与“loadingdone”事件处理函数的回调方法类似,但在此情景下总是会调用回调,即使因为需要字体已经载入而没有发生加载行为。这是一种简单的方法,来同步字体加载代码,而不必跟踪需要的字体和载入时机。
问题: 没有覆盖一个特别复杂的情况,即多个可下载字体可能会在布局操作执行多次之后才会被加载。在同一个字体列表中给出两个字体(字体A、字体B),假定字体A只支持基础拉丁码位而字体B还支持泰国语。如果在所有字体载入之前调用notifyWhenFontsReady(),回调将发生在字体A载入之后,但是之后用户代理会发现字体A不支持泰国语并在之后开始下载字体B。所以回调方法实际上发生与所有字体载入完成之前。
字体加载事件实例
示例:
在所有字体载入完成之后显示文本。
document.fontloader.onloadingdone = function() {
var content = document.getElementById("content");
content.style.visibility = "visible";
}
示例:
在canvas上使用一个可下载字体绘制文本,显式地初始化字体下载并在完成后开始绘制:
function drawStuff() {
var ctx = document.getElementById("c").getContext("2d");
ctx.fillStyle = "red";
ctx.font = "50px MyDownloadableFont";
ctx.fillText("Hello!", 100, 100);
}
window.onload = function() {
document.fontloader.loadFont("50px MyDownloadableFont");
}
document.fontloader.onloadingdone = drawStuff;
示例:
富文本编辑器应用可能会需要在编辑行为发生之后测量文本元素。由于样式变化可能需要也可能不需要追加下载字体,或者字体可能已经下载,所以测量程序需要发生在字体载入完成之后:
function measureTextElements() {
// 此时可以使用可下载字体的度量来测量内容
}
function doEditing() {
// 内容/布局操作可能会造成追加下载字体
document.fontloader.notifyWhenFontsReady(measureTextElements);
}
附录A:映射平台字体属性到CSS属性
本附录包含了其他章节中描述的某些问题或情景的背景。其应当仅作为信息参考。
CSS中的字体属性被设计为独立于底层字体格式而使用;除了常见的TrueType和OpenType字体外,它们还可以用来指定点阵字体、Type1字体和SVG字体。但是TrueType和OpenType格式经常会使编码人员混淆,而且对于在不同平台上的实现提出了挑战。
TrueType最初由Apple开发,被设计为一个同时适用于屏幕和印刷的轮廓字体格式。之后Microsoft加入了TrueType格式的开发,至此两个平台都支持了TrueType字体。TrueType格式中的字体数据由以四个字母的标记名称区别的表格集合组成,其中各自包含了一类特殊的数据。距离说明,命名信息,包含版权和授权信息,被存储在‘name’表。字符映射(‘cmap’)表包含了一个从字符编码到字形的映射。之后Apple又增加了支持增强排版功能的额外的表;此时被称为Apple Advanced Typography或ATT字体。Microsoft和Adboe开发了一组单独的表来增强排版,并称为OpenType【OPENTYPE】。
在许多情况下,在Microsoft Windows或Linux中使用的字体数据与在Apple的Mac OS X下使用的数据存下轻微不同,这是因为TrueType格式允许明确的跨平台变种。这包括字体度量、名称和字符映射数据。
特别的,对于字体家族名称数据的处理不同平台各有不同。对于TrueType和OpenType字体,它们的名称包含在‘name’表之中,其名称记录的ID为1。可以为不同地点存储多个名称,但Microsoft推荐字体总是至少包含美国英语版本的名称。在Windows上,Microsoft决定为了向后兼容,限制家族名称最多四个;对于较大的分组,可以使用“首选家族”(名称ID 16)或“WWS家族”(名称ID 21)。其他诸如OSX的平台没有这个限制,家族名称可以用于定义所有可能的组。
名称表中的其他数据提供用于唯一标识家族中特定外观的名称。完整字体名称(名称ID 4)和Postscript名称(名称ID 6)描述一个独立的唯一外观。Gill Sans家族的粗体外观的完整名称为“Gill Sans Bold”、Postscript名称为“GillSans-Bold”。一个给定外观的完成名称可以有多种本地版本,但Postscript名字总是一个由ASCII字符组成的唯一名称。
对于不同平台,使用不同的名称搜索一个字体。举例说明,使用Windows GDI CreateIndirectFont API,可以使用家族或完整名称查找一个外观,而在Mac OS X上ATSFontFindFromName和ATSFontFindFromPostScriptName API可以使用完整名称和Postscript名称查找指定外观。在Linux下,fontconfig API允许使用所有这些名称查找字体。在平台API自动替代其他字体选择的情况下,可能会需要验证返回的字体与给定名称相匹配。
给定外观的重量可以通过OS/2表的usWeightClass字段确定或者通过样式名称(名称ID 2)推测。类似的,宽度可以通过OS/2表的usWidthClass确定或者通过样式名称推测。由于历史原因,使用Windows GDI API对200或更小重量的加粗合成,字体设计师有时会使用OS/2表中的skewed值禁用这些重量。
在显示诸如泰语、阿拉伯语和梵文等使用上下文形状的复杂脚本时,需要只存在于OpenType或AAT字体中的特性。当前,Windows和Linux使用OpenType字体特性支持复杂脚本的显示,而AAT字体特性被用于Mac OS X。Apple表示其计划在未来支持使用OpenType字体特性显示复杂脚本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号