网络流问题
1. 网络最大流
1.1 容量网络和网络最大流
1.1.1 容量网络
设 G(V, E)是一个有向网络,在 V 中指定了一个顶点,称为源点(记为 Vs),以及另一个顶点,称为汇点(记为 Vt);对于每一条弧<u, v>∈ E,对应有一个权值c(u, v)>0,称为弧的容量(capacity)。通常把这样的有向网络 G 称为容量网络。
1.1.2 弧的流量
通过容量网络 G 中每条弧<u, v>上的实际流量(简称流量), 记为 f(u, v)。
1.1.3 网络流
所有弧上流量的集合 f = { f(u, v) },称为该容量网络 G 的一个网络流。
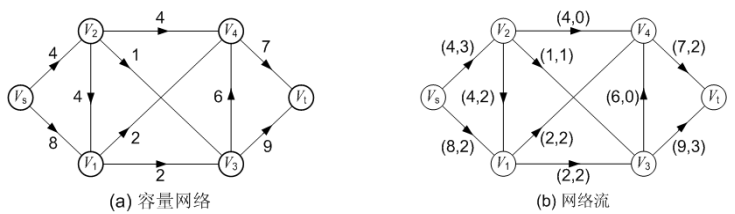
每条弧旁边括号内的两个数值( c(u, v), f(u, v) ),第 1 个数值表示弧容量,第二个数值表示通过该弧的流量。例如,弧<Vs, V1>上的两个数字(8, 2),前者是弧容量,表示通过该弧最大流量为 8,后者表示目前通过该弧的实际流量为 2。
从上图中可见:
-
通过每弧的流量均不超过弧容量;
-
源点 Vs 流出的总量为 3 + 2 = 5,等于流入汇点 Vt 的总量 2 + 3 = 5;
-
其他中间顶点的流出流量等于其流入流量。例如,中间顶 V2 的流入流量为 3,流出流量为: 2 + 1 = 3。
1.1.4 可行流
在容量网络 G(V, E)中,满足以下条件的网络流 f,称为可行流。
-
弧流量限制条件: 0 ≤ f(u, v) ≤ c(u, v), <u, v>∈ E
-
平衡条件:
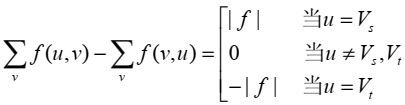
1.1.5 零流
对于任何一个容量网络,可行流总是在存在的,如 f = { 0 },即每条弧上的流量为 0,该网络流称为零流。
1.1.6 伪流
如果一个网络流只满足弧流量限制条件,不满足平衡条件,则这种网络流称为伪流,或称为容量可行流。
1.1.7 可行流
在容量网络 G(V, E)中,满足弧流量限制条件和平衡条件、且具有最大流量的可行流,称为网络最大流,简称最大流。
1.2 链与增广路
在容量网络 G(V, E)中,设有一可行流 f = { f(u, v) },根据每条弧上流量的多少、以及流量和容量的关系,可将弧分四种类型:
-
饱和弧, 即 f(u, v) = c(u, v);
-
非饱和弧,即 f(u, v) < c(u, v);
-
零流弧, 即 f(u, v) =0;
-
非零流弧,即 f(u, v) > 0。
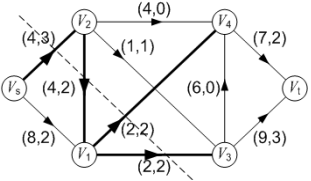
在上图中,弧<V1, V4>、 <V1, V3>是饱和弧;弧<Vs, V2>、 <V2, V1>等是非饱和弧;弧<V2, V4>、 <V3, V4>是零流弧;弧<V1, V4>、 <V3, Vt>等是非零流弧。
1.2.1 链
在容量网络中,称顶点序列(u, u1, u2, …, un, v)为一条链,要求相邻两个顶点之间有一条弧,如< u, u1 >或< u1, u >为容量网络中一条弧。
设 P 是 G 中从 Vs 到 Vt 的一条链,约定从 Vs 指向 Vt 的方向为该链的正方向。注意,链的概念不等同于有向路径的概念,在链中,并不要求所有的弧都与链的正方向同向。
沿着 Vs 到 Vt 的一条链,各弧可分为两类:
-
前向弧(方向与链的正方向一致的弧),其集合记为 P+;
-
后向弧(方向与链的正方向相反的弧),其集合记为 P–。
注意,前向弧和后向弧是相对的,即相对于指定链的正方向。同一条弧可能在某条链中是前向弧,而在另外一条链中是后向弧。
例如在图下中,指定的链为: P = { Vs , V1 , V2 , V4 , Vt },这条链在图(a)中用粗线标明。则P+和 P–分别为:
-
P+ = { <Vs , V1>, <V2 , V4>, <V4, Vt> }。
-
P– = { <V2, V1> }。
1.2.1 增广路
设 f 是一个容量网络 G 中的一个可行流, P 是从 Vs 到 Vt 的一条链,若 P 满足下列条件:
-
在 P 的所有前向弧<u, v>上, 0 ≤ f(u, v) < c(u, v),即 P+中每一条弧都是非饱和弧;
-
在 P 的所有后向弧<u, v>上, 0 < f(u, v) ≤ c(u, v),即 P–中每一条弧是非零流弧。
则称 P 为关于可行流 f 的一条增广路,简称为增广路(或称为增广链、 可改进路)。
那么,为什么将具有上述特征的链 P 称为增广路呢?原因是可以通过修正 P 上所有弧的流量f(u, v)来把现有的可行流 f 改进成一个值更大的流 f1。 沿着增广路改进可行流的操作称为增广。
下面具体地给出一种方法,利用这种方法就可以把 f 改进成一个值更大的流 f1。这种方法是:
不属于增广路 P 的弧<u, v>上的流量一概不变,即 f1(u, v) = f(u, v);
增广路 P 上的所有弧<u, v>上的流量按下述规则变化: (始终满足可行流的 2 个条件)
-
在前向弧<u, v>上, f1(u, v) = f(u, v) +α ;
-
在后向弧<u, v>上, f1(u, v) = f(u, v) -α 。
称 α 为可改进量,它应该按照下述原则确定: α 既要取得尽量大, 又要使变化后 f1 仍满足可行流的两个条件 - 容量限制条件和平衡条件。
不难看出,按照这个原则, α 既不能超过每条前向弧的 c(u, v)– f(u, v),也不能超过每条后向弧的 f(u, v)。 因此 α 应该等于每条前向弧上的 c(u, v)– f(u, v)与每条后向弧上的 f(u, v)的最小值。 即:
![]()
1.3 残留容量与残留网络
1.3.1 残留容量
给定容量网络 G(V, E)及可行流 f,弧<u, v>上的残留容量记为c'(u, v)= c(u, v)– f(u, v)。每条弧的残留容量表示该弧上可以增加的流量。
1.3.2 残留网络
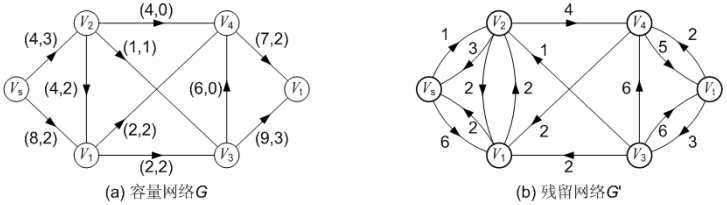
设有容量网络 G(V, E)及其上的网络流 f, G 关于 f 的残留网络(简称残留网络)记为 G'(V', E'), 其中 G'的顶点集 V'和 G 的顶点集 V 相同,即 V'=V,对于 G 中的任何一条弧<u, v>,如果 f(u, v) < c(u, v),那么在 G'中有一条弧<u, v>∈ E',其容量为 c'(u, v) = c(u, v)– f(u, v),如果 f(u, v) > 0,则在 G'中有一条弧<v, u>∈ E',其容量为 c'(v, u) = f(u, v)。 从残留网络的定义可以看出,原容量网络中的每条弧在残留网络中都化为一条或两条弧(如果G中弧<u, v>有残留容量,则在G'中将化为两条弧,一条<u, v>,容量为c(u, v) - f(u, v),一条<v, u>,容量为f(u, v))。
设 f 是容量网络 G(V, E)的可行流, f'是残留网络 G'的可行流,则 f + f'仍是容量网络 G 的一个可行流。 (f + f'表示对应弧上的流量相加)。
1.4 割与最小割
1.4.1 割
在容量网络 G(V, E)中,设 E'⊆ E,如果在 G 的基图中删去 E'后不再连通,则称 E'是 G 的割。割将 G 的顶点集 V 划分成两个子集 S 和 T( V - S)。将割记为(S, T)。
1.4.2 s - t 割
更进一步,如果割所划分的两个顶点子集满足源点 Vs∈ S,汇点 Vt∈ T,则称该割为s-t 割。 s-t 割(S, T)中的弧<u, v>(u∈ S, v∈ T)称为割的前向弧, 弧<u, v>( u∈ T, v∈ S)称为割的反向弧。
1.4.3 割的容量
设(S, T)为容量网络 G(V, E)的一个割, 其容量定义为所有前向弧的容量总和, 用 c(S, T)表示。即:
- c(S, T)=∑ c(u, v) u∈ S, v∈ T, <u, v>∈ E
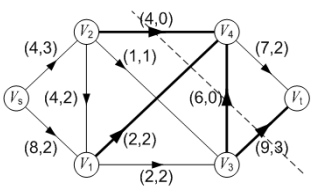
例如在下图中,如果选定 S = { Vs, V1, V2, V3 },则 T = { V4, Vt }, (S, T)就是一个 s-t 割。其容量 c(S, T)为图中粗线边<V2, V4>, <V1, V4>, <V3, V4>, <V3, Vt>的容量总和,即:
- c(S, T) = C24 + C14 + C34 + C3t = 4 + 2 + 6 + 9 = 21
1.4.4 最小割
容量网络 G(V, E)的最小割是指容量最小的割。
1.4.5 割的净流量
设 f 是容量网络 G(V, E)的一个可行流, (S, T)是 G 的一个割, 定义割的净流量 f(S, T)为:
- f(S, T)=∑f(u, v) u∈ S, v∈ T, <u, v>∈ E 或<v, u>∈ E。
注意:
-
在统计割的净流量时:反向弧的流量为负值,即如果<v, u>∈ E,那么在统计割的净流量时 f(u, v)是一个负值。
-
在统计割的容量时:不统计反向弧的容量。
例如,在下图中, S = { Vs, V1 },则 T = { V2, V3, V4, Vt }。
-
割(S, T)的容量 c(S, T)为: c(S, T) = Cs2 + C14 + C13 = 4 + 2 + 2 = 8
-
割(S, T)的净流量为: f(S, T) = fs2 + f21 + f14 + f13 = 3 + (-2) + 2 + 2 = 5
2. 最大流最小割定理
如何判定一个网络流是否是最大流?有以下两个定理。
2.1 增广路定理
设容量网络G(V, E)的一个可行流为 f, f 为最大流的充要条件是在容量网络中不存在增广路。
2.2 最大流最小割定理
对容量网络 G(V, E),其最大流的流量等于最小割的容量。
3. 网络最大流的求解
网络最大流的求解主要有两大类算法: 增广路算法和预流推进算法。
3.1 增广路算法
根据增广路定理,为了得到最大流,可以从任何一个可行流开始,沿着增广路对网络流进行增广,直到网络中不存在增广路为止,这样的算法称为增广路算法。
增广路算法的基本流程是:
-
取一个可行流 f 作为初始流(如果没有给定初始流,则取零流 f= {0} 作为初始流);
-
寻找关于 f 的增广路 P,如果找到,则沿着这条增广路 P 将 f 改进成一个更大的流;
-
重复上一步直到 f 不存在增广路为止。
3.1.1 Ford-Fulkerson 算法
在 Ford-Fulkerson 算法中,寻找增广路和改进网络流的方法是标号法。以下两个实例分别从初始流为零流和非零流出发采用标号法求网络最大流。
3.1.1.1 初始流为零流
在下图(a)所示,各条弧上的流量均为 0,初始可行流 f 为零流。在图(b)中,对初始流 f 进行第一次标号。每个顶点的标号包含两个分量:
-
第一个分量指明它的标号从哪个顶点得到,以便找出可改进量;
-
第二个分量是为确定可改进量 α 用的。
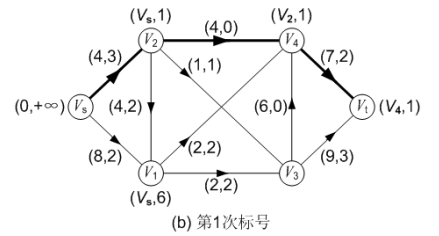
第一次标号:
首先对源点 Vs 进行标号,标号为(0, +∞)。每次标号,源点的标号总是(0, +∞)。其中第一个分量为 0,表示该顶点是源点;第二个分量为+∞,表示 Vs 可以流出任意多的流量(只要从它发出的弧可以接受)。
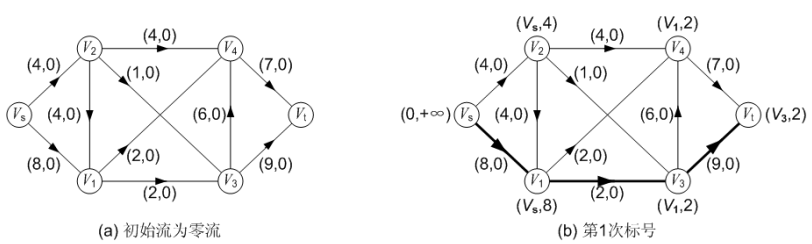
源点 Vs 有标号以后,采用广度优先搜索的思路从源点出发进行遍历,并对遍历到的每个顶点进行标号。例如源点 Vs 有两个邻接顶点: V1 和 V2,则先顶点 V1进行标号。对顶点 V1 的标号为(Vs, 8)。该标号的含义是:第二个分量为 8,表示 Vs 可以流出+∞的流量,但弧<Vs, V1>的容量为 8,所以,顶点 Vs 只能接受 8;第一个分量表示流量改进量“8”来自顶点 Vs。按照同样的思路对顶点 V2 进行标号,标号为(Vs, 4)。
源点 Vs 的邻接顶点检查完毕后,再从顶点 V1出发对它的邻接顶点进行标号:对顶点 V3 的标号为(V1, 2),对顶点 V4的标号为(V1, 2)。注意,顶点 V2也是 V1的“邻接”(通过后向弧“邻接”)顶点,但 V2 已经有标号了,所以不能通过 V1 对 V2 进行标号。
源点 V1 的邻接顶点检查完毕后,再从顶点 V2出发对它的邻接顶点进行标号,此时顶点 V2 的邻接顶点中,都已经有标号了。源点 V2 的邻接顶点检查完毕后,再从顶点 V3 出发对它的邻接顶点进行标号,从而通过 V3 对汇点 Vt 进行标号,标号为(V3, 2)。
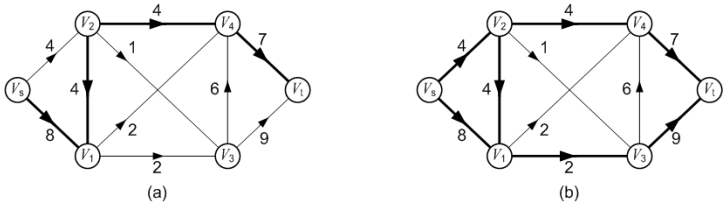
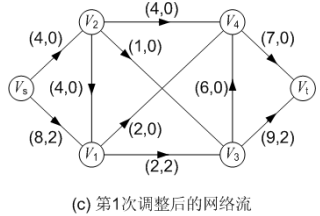
一旦汇点 Vt 有标号,且第二个分量不为 0,则表示找到一条增广路。确定这条增广路的方法是:从汇点 Vt 标号的第一个分量出发,采用“倒向追踪”的方法,一直找到源点 Vs。 例如在图(b)中,汇点 Vt 标号的第一个分量为 V3,表示增广路上汇点 Vt 前面的顶点为 V3;顶点 V3 标号的第一个分量为 V1,表示增广路上顶点 V3 前面的顶点为 V1;顶点 V1 标号的第一个分量为 Vs,表示增广路上顶点 V1前面的顶点为 Vs;因此找到的这条增广路为: P( Vs, V1, V3, Vt ),增广路中的弧用粗线标明。并且这条增广路的可改进量 α 就是汇点 Vt 标号的第二个分量,为 2。沿着这条增广路,可以将流量增加 2,流量变成 2,改进后的流如图(c)所示。
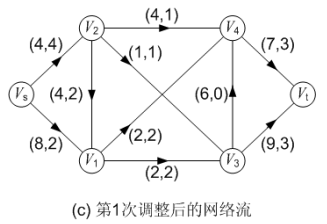
第二次标号:
图(d)对第一次调整后的网络流进行第二次标号,求得的增广路为: P( Vs, V1, V4, Vt ),可改进量α = 2;调整后得到的网络流如图(e)所示,流量为 4。
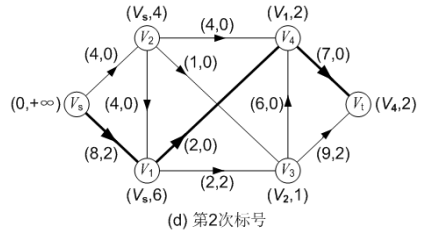
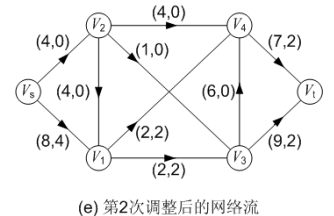
第三次标号:
图(f)对第二次调整后的网络流进行第三次标号,求得的增广路为: P( Vs, V2, V3, Vt ),可改进量α = 1;调整后得到的网络流如图(g)所示,流量为 5。
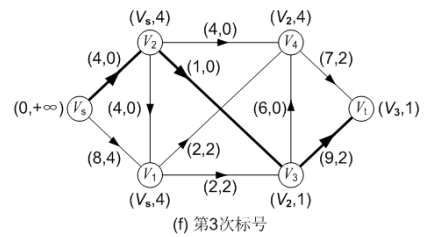
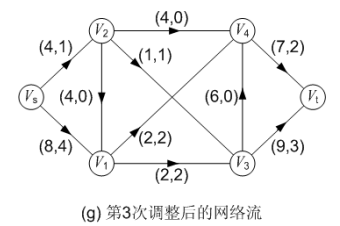
第四次标号:
图(h)对第三次调整后的网络流进行第四次标号,求得的增广路为: P( Vs, V2, V4, Vt ),可改进量α = 3;调整后得到的网络流如图(i)所示,流量为 8。
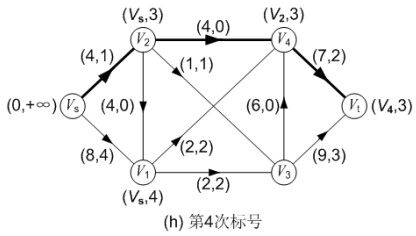
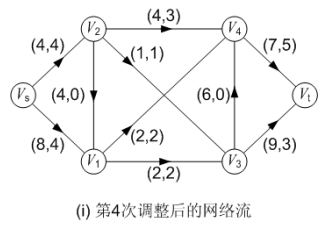
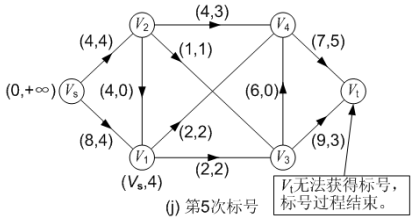
第五次标号:
在图(j)中, 对第四次调整后得到的网络流进行第五次标号: 通过源点 Vs 对顶点 V1的标号为(Vs, 4),源点 Vs 无法对顶点 V2 进行标号,因为弧<Vs, V2>已经饱和了;而顶点 V1 也无法对它的邻接顶点进行标号。此后汇点 Vt 无法获得标号,或者说汇点 Vt 的可改进量α 为 0。至此,标号法结束,求得的最大流流量为 8。
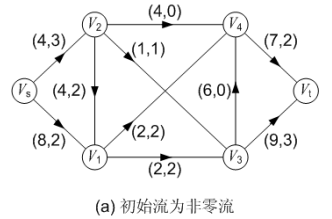
3.1.1.2 初始流为非零流
如下图(a)所示,初始可行流 f 为非零流,其流量为 5。
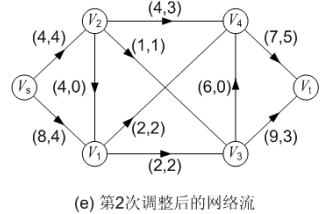
图(b)对初始流进行第一次标号,求得的增广路为: P( Vs, V2, V4, Vt ),可改进量α =1;调整后得到的网络流如图(c)所示,流量为 6。
图(d)所示的第二次标号过程要特别注意:顶点 V2 获得的标号中,第一个分量为-V1。第二次标号过程为:通过源点 Vs 对顶点 V1 的标号为(Vs, 6),源点 Vs无法对顶点 V2进行标号。然后,顶点 V1 的邻接顶点中, V3和 V4都无法从 V1 获得标号,因为对应的弧已经饱和了;但这时要注意,顶点 V1通过后向弧<V2, V1>与顶点 V2“邻接”,且顶点 V2还没有标号。所以给 V2 顶点标号为(-V1, 2),第一个分量前的负号表示在找到的增广路中,弧<V2, V1>是后向弧,在改进当前可行流时它的流量应该减少,相当于这个改进量实际上是由顶点 V2 提供给顶点 V1 的。第二次标号后,求得的增广路为: P( Vs, V1, V2, V4, Vt ),可改进量α = 2;调整后得到的网络流如图(e)所示,流量为 8。
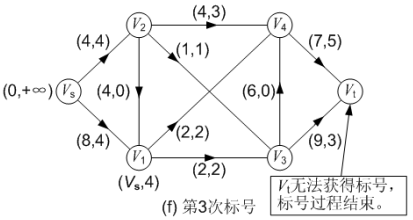
在图(f)中,对得到的网络流进行第三次标号:通过源点 Vs 对顶点 V1 的标号为(Vs, 4),源点 Vs 无法对顶点 V2进行标号, 因为弧<Vs, V2>已经饱和了; 而顶点 V1也无法对它的邻接顶点进行标号。此后汇点 Vt 无法获得标号,或者说汇点 Vt 的可改进量α 为 0。至此,标号法结束,求得的最大流流量为 8。
3.1.1.3 标号法的运算过程
(一)标记过程:
在标号过程,容量网络中的顶点可以分为三类:
-
未标号顶点;
-
已标号,未检查邻接顶点;
-
已标号,且已检查邻接顶点(即已经检查它的所有邻接顶点,看是否能标号)。
每个标号顶点的标号包含两个分量:
-
第一个分量指明它的标号从哪个顶点得到,以便找出增广路;
-
第二个分量是为确定可改进量 α 用的。
标号过程开始时,总是先给 Vs 标上(0, +∞), 0 表示 Vs 是汇点, +∞表示 Vs可以流出任意多的流量(只要从它发出的弧可以接受)。这时 Vs 是已标号而末检查的顶点,其余都是末标号点。然后从源点 Vs 出发,对它的每个邻接顶点进行标号。
一般,取一个已标号而未检查的顶点 u,对一切未标号顶点 v:
-
若 v 与 u“正向”邻接,且在弧<u, v>上 f(u, v)<c(u, v),则给 v 标号(u, L(v)),这里 L(v) = min{ L(u), c(u, v) – f(u, v) }, L(u)是顶点 u 能提供的标号。
-
若 v 与 u“反向”邻接,且在弧< v, u>上 f(v, u)>0,则给 v 标号( -u, L(v)),这里 L(v) =min{ L(u), f(v, u) }。这时顶点 v 成为已标号而未检查的顶点。
当 u 的全部邻接顶点都已检查后, u 成为已标号且已检查过的顶点。
重复上述步骤直至汇点获得标号,一旦汇点 Vt 被标号并且汇点标号的第 2 个分量大于 0,则表明得到一条从 Vs 到 Vt 的增广路 P,转入调整过程;若所有已标号未检查的顶点都检查完毕但标号过程无法继续、从而汇点 Vt 无法获得标号,或者得到的可改进量 α = 0,则算法结束,这时的可行流即为最大流。
(二)调整过程:
采用“倒向追踪”的方法,从 Vt 开始,利用标号顶点的第一个分量逐条弧地找出增广路 P,并以 Vt 的第二个分量 L(Vt)作为改进量 α ,改进 P 路上的流量。
3.1.1.4 标号法的程序实现
#include <iostream>
#include <queue>
#include <cmath>
#define MAX 1000
#define INF 100000
using namespace std;
struct ArcType { // 弧结构
int c, f; // 容量、流量
};
ArcType Edge[MAX][MAX]; // 邻接矩阵(每个元素为ArcType类型)
int n, m;
int Flag[MAX]; // 顶点状态 -1代表未标号,0代表已标号未检查,1代表已标号已检查
int Prev[MAX]; // 标号的第一个分量-指明标号从哪个顶点得到
int Alpha[MAX]; // 标号的第二个分量-指明可改进量a
queue<int> que; // 用于BFS的队列
int v; // 表示从队列中取出的队头元素
int qs, qe; // 表示队列头位置,队列尾位置
bool MIN(int a, int b) {
return a < b ? a : b;
}
void ford() {
while (1) {
memset(Flag, 0xff, sizeof(Flag));
memset(Prev, 0xff, sizeof(Prev));
memset(Alpha, 0xff, sizeof(Alpha));
Flag[0] = 0; // 标记源点Vs为已标号未检查
Prev[0] = 0; //
Alpha[0] = INF; //
que.push(0); // 源点Vs入队
// 队列非空且汇点Vt未标号
while (!que.empty() && Flag[n - 1] == -1) {
v = que.front(); // 取出队头顶点
que.pop();
// 检查v的正向和返回“邻接点”
for (int i = 0; i < n; i++) {
if (Edge[v][i].c < INF && Edge[v][i].f < Edge[v][i].c) { // 正向且容量c < 流量f
Flag[i] = 0;
Prev[i] = v;
Alpha[i] = MIN(Alpha[v], Edge[v][i].c - Edge[v][i].f);
que.push(i); // 顶点i入队
}
else if (Edge[i][v].c < INF && Edge[i][v].f > 0) { // 反向且流量f > 0
Flag[i] = 0;
Prev[i] = -v;
Alpha[i] = MIN(Alpha[v], Edge[i][v].f);
que.push(i);
}
}
Flag[v] = 1; // 顶点v已标号已检查
}
if (Flag[n - 1] == -1 || Alpha[n - 1] == 0) {
break; // 当汇点没有获得标号或调整量a为0,退出循环
}
// 当汇点有标号,进行调整
int k1 = n - 1, k2 = abs(Prev[k1]);
int a = Alpha[k1]; // 可改进量
while (1) {
if (Edge[k2][k1].f < INF) { // 正向弧
Edge[k2][k1].f += a;
}
else { // 反向弧
Edge[k1][k2].f -= a;
}
if (k2 == 0) { // 一直调整到源点Vs
break;
}
k1 = k2;
k2 = abs(Prev[k2]);
}
}
}
int main() {
int u, v, c, f;
cin >> n >> m;
// 初始化矩阵各个元素。INF表示没有边连接
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
Edge[i][j].c = Edge[i][j].f = INF;
}
}
// 构造邻接矩阵
for (int i = 0; i < m; i++) {
cin >> u >> v >> c >> f;
Edge[u][v].c = c;
Edge[u][v].f = f;
}
ford();
return 0;
}3.1.1.5 Ford-Fulkerson 算法的复杂度
Ford-Fulkerson算法的时间复杂度为 O(mnU)。因此, Ford-Fulkerson 算法的时间复杂度不仅依赖于容量网络的规模(顶点数和弧数),还和各条弧的容量有关。 (n 和 m 分别为顶点数和边数, U为各条弧的最大容量)
3.1.2 最短增广路算法
3.1.3 Dinic 算法
3.2 预流推进算法
3.2.1 一般预流推进算法
3.2.2 最高标号预流推进算法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端