图的遍历-DFS
1. DFS遍历
DFS 算法的思想:对一个无向连通图,在访问图中某一起始顶点 v 后,由 v 出发,访问它的某一邻接顶点 w1;再从 w1 出发,访问与 w1 邻接但还没有访问过的顶点 w2;然后再从 w2 出发,进行类似的访问;…;如此进行下去,直至到达所有邻接顶点都被访问过的顶点 u 为止;接着,回退一步,回退到前一次刚访问过的顶点,看是否还有其它没有被访问过的邻接顶点,如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,就再回退一步进行类似的访问。重复上述过程,直到该连通图中所有顶点都被访问过为止。
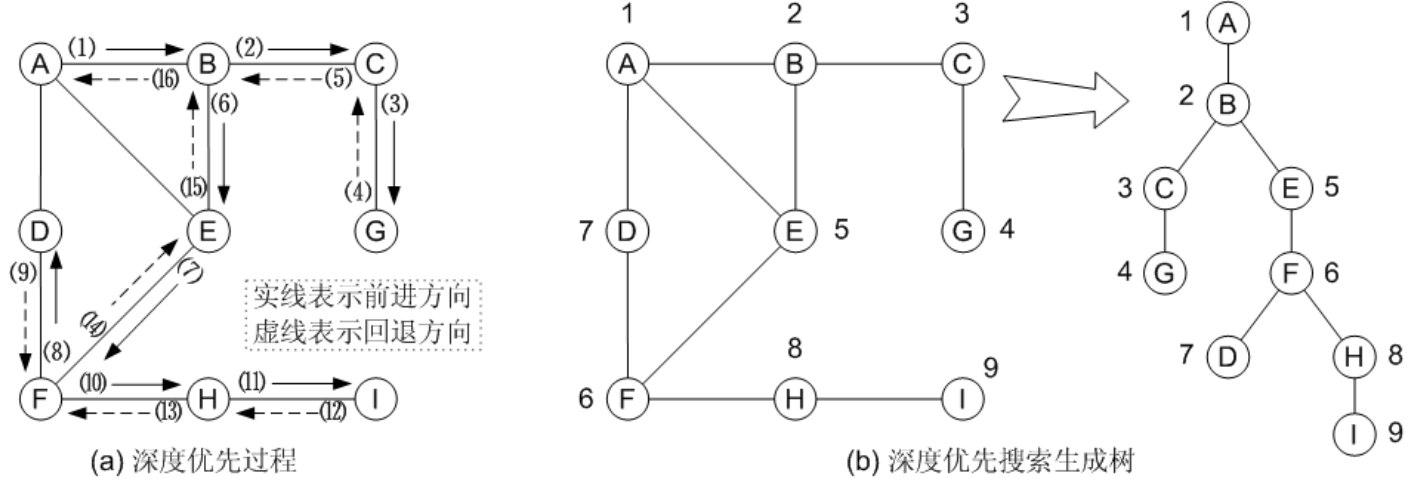
对上图示的无向连通图, 采用 DFS 思想搜索的过程为(在图(a)中,实线表示前进方向,虚线表示回退方向,箭头旁的数字跟下面的序号对应):
- 从顶点 A 出发,访问顶点序号最小的邻接顶点,即顶点 B;
- 然后访问顶点 B 的未访问过的、顶点序号最小的邻接顶点,即顶点 C;
- 接着访问顶点 C 的未访问过的、顶点序号最小的邻接顶点,即顶点 G;
- 此时顶点 G 已经没有未访问过的邻接顶点了,所以回退到顶点 C;
- 回退到顶点 C 后,顶点 C 也没有未访问过的邻接顶点了,所以继续回退到顶点 B;
- 顶点 B 还有一个未访问过的邻接顶点,即顶点 E,所以访问顶点 E;
- 然后访问顶点 E 的未访问过的、顶点序号最小的邻接顶点,即顶点 F;
- 顶点 F 有两个未访问过的邻接顶点,选择顶点序号最小的,即顶点 D,所以访问 D;
- 此时顶点 D 已经没有未访问过的邻接顶点了,所以回退到顶点 F;
- 顶点 F 还有一个未访问过的邻接顶点,即顶点 H,所以访问顶点 H;
- 然后访问顶点 H 的未访问过的、顶点序号最小的邻接顶点,即顶点 I;
- 此时顶点 I 已经没有未访问过的邻接顶点了,所以回退到顶点 H;
- 回退到顶点 H 后,顶点 H 也没有未访问过的邻接顶点了,所以继续回退到顶点 F;
- 回退到顶点 F 后,顶点 F 也没有未访问过的邻接顶点了,所以继续回退到顶点 E;
- 回退到顶点 E 后,顶点 E 也没有未访问过的邻接顶点了,所以继续回退到顶点 B;
- 回退到顶点 B 后,顶点 B 也没有未访问过的邻接顶点了,所以继续回退到顶点 A。
回退到顶点 A 后,顶点 A 也没有未访问过的邻接顶点了,而且顶点 A 是搜索的起始顶点。至此,整个搜索过程全部结束。由此可见, DFS 搜索最终要回退到起始顶点,并且如果起始顶点没有未访问过的邻接顶点了,则算法结束。
2. DFS 算法的实现
假设有函数 DFS(v), 可实现从顶点 v 出发访问它的所有未访问过的邻接顶点。 在 DFS 算法中,必有一数组,设为 visited[n],用来存储各顶点的访问状态。如果 visited[i] = 1,则表示顶点 i 已经访问过;如果 visited[i] = 0,则表示顶点 i 还未访问过。初始时,各顶点的访问状态均为 0。
如果用邻接表存储图,则 DFS 算法实现的伪代码如下:
DFS( 顶点 i ) //从顶点 i 进行深度优先搜索
{
visited[ i ] = 1; //将顶点 i 的访问标志置为 1
p = 顶点 i 的边链表表头指针;
while( p 不为空 )
{
//设指针 p 所指向的边结点所表示的边中,另一个顶点为顶点 j
if( 顶点 j 未访问过 )
{
//递归搜索前的准备工作需要在这里写代码
DFS( 顶点 j );
//以下是 DFS 的回退位置,在很多应用中需要在这里写代码
}
p = p->nextarc; //p 移向下一个边结点
}
}如果用邻接矩阵存储图(设顶点个数为 n),则 DFS 算法实现的伪代码如下:
DFS( 顶点 i ) //从顶点 i 进行深度优先搜索
{
visited[ i ] = 1; //将顶点 i 的访问标志置为 1
for( j=0; j<n; j++ ) //对其他所有顶点 j
{
//j 是 i 的邻接顶点,且顶点 j 没有访问过
if( Edge[i][j]==1 && !visited[j] )
{
//递归搜索前的准备工作需要在这里写代码
DFS( j ) //从顶点 j 出发进行 DFS 搜索
//以下是 DFS 的回退位置,在很多应用中需要在这里写代码
}
}
}在上述伪代码中,在递归调用 DFS 函数前后的两个位置特别重要:
- 如果需要在递归搜索前做一些准备工作,则需要在 DFS 递归调用前的位置写代码;
- 如果需要在搜索的回退后做一些还原工作,或者根据搜索结果做一些统计或计算工作,则需要在 DFS 递归调用后的位置写代码。
3. DFS的算法度分析
现以下图(a)所示的无向图为例分析 DFS 算法的复杂度。设图中有 n 个顶点,有 m 条边。
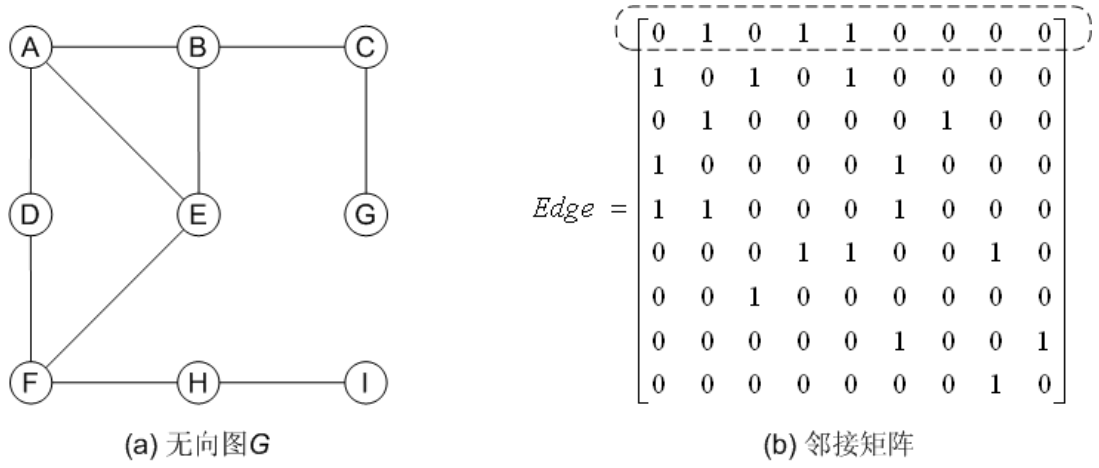
如果用邻接表存储图,如图 (b)所示,从顶点 i 进行深度优先搜索,首先要取得顶点 i 的边链表表头指针,设为 p,然后要通过指针 p 访问它的第 1 个邻接顶点,如果该邻接顶点未访问过,则从这个顶点出发进行递归搜索;如果这个邻接顶点已经访问过,则指针 p 要移向下一个边结点。在这个过程中,对每个顶点递归访问 1 次,即每个顶点的边链表表头指针取出一次,而每个边结点都只访问了一次。由于总共有 2m 个边结点,所以扫描边的时间为 O(2m)。因此采用邻接表存储图时,进行深度优先搜索的时间复杂性为 O(n+2m)。

如果采用邻接矩阵存储图,由于在邻接矩阵中只是间接的存储了边的信息。在对某个顶点进行 DFS 搜索时,要检查其他每个顶点,包括它的邻接顶点和非邻接顶点,所需时间为 O(n)。例如在下图(b)中,执行 DFS(A)时,要在邻接矩阵中的第 0 行检查顶点 A~I 与顶点 A 是否相邻且是否已经访问过。另外,整个 DFS 过程,对每个顶点都要递归进行 DFS 搜索,因此遍历图中所有的顶点所需的时间为 O(n2)。
4. DFS实例解析
4.1 骨头的诱惑
- 题目描述:一只小狗在一个古老的迷宫里找到一根骨头,当它叼起骨头时,迷宫开始颤抖,它感觉到地面开始下沉。它才明白骨头是一个陷阱,它拼命地试着逃出迷宫。
迷宫是一个 N×M 大小的长方形,迷宫有一个门。刚开始门是关着的,并且这个门会在第 T 秒钟开启,门只会开启很短的时间(少于一秒),因此小狗必须恰好在第 T 秒达到门的位置。每秒钟,它可以向上、下、左或右移动一步到相邻的方格中。但一旦它移动到相邻的方格,这个方格开始下沉,而且会在下一秒消失。所以,它不能在一个方格中停留超过一秒,也不能回到经过的方格。
- 输入描述:输入文件包括多个测试数据。每个测试数据的第一行为三个整数: N M T, ( 1<N, M<7; 0<T<50),分别代表迷宫的长和宽,以及迷宫的门会在第 T 秒时刻开启。
- 接下来 N 行信息给出了迷宫的格局,每行有 M 个字符,这些字符可能为如下值之一:
- X :墙壁,小狗不能进入;
- S :迷宫入口;
- D :迷宫大门;
- . :空格;
- 输出描述:对每个测试数据,如果小狗能成功逃离,则输出"YES",否则输出"NO"。
- 输入样例:3 4 5; S . . .; . X . X; . . . D;
- 搜索策略: 以样例输入中的测试数据进行分析,如图所示。图(a)表示测试数据及所描绘的迷宫;在图(b)中,圆圈中的数字表示某个位置的行号和列号,行号和列号均从 0 开始计起,实线箭头表示搜索前进方向,虚线箭头表示回退方向。

搜索时从小狗所在初始位置 S 出发进行搜索。每搜索到一个方格位置,对该位置的 4 个可能方向(要排除边界和墙壁)进行下一步搜索。往前走一步,要将到达的方格设置成墙壁,表示当前搜索过程不能回到经过的方格。一旦前进不了,要回退,要恢复现场(将前面设置的墙壁还原成空的方格),回到上一步时的情形。只要有一个搜索分支到达门的位置并且符合要求,则搜索过程结束。如果所有可能的分支都搜索完毕,还没找到满足题目要求的解,则该迷宫无解。
- 搜索实现: 假设实现搜索的函数为 dfs,它带有 3 个参数。 dfs( si, sj, cnt ):已经到达(si, sj)位置,且已经花费 cnt 秒,如果到达门的位置且时间符合要求,则搜索终止;否则继续从其相邻位置继续进行搜索。继续搜索则要递归调用 dfs 函数,因此 dfs 是一个递归函数。 成功逃离条件: si=di, sj=dj, cnt=t。其中(di,dj)是门的位置,在第 t 秒钟开启。
- 为什么在回退过程中恢复现场:如果当前搜索方向行不通,该搜索过程要结束了,但并不代表其他搜索方向也行不通,所以在回退时必须还原到原来的状态,保证其他搜索过程不受影响。
- 代码实现:
#include <iostream> #include <cstring> using namespace std; char map[9][9]; // 定义地图数组 int n, m, t; // 分别代表地图长、宽、逃离时间 int di, dj; // 代表门的位置 int si, sj; // 代表出发位置 static int escape = 0; // 代表是否能逃脱 int dir[4][2] = { {1, 0}, {-1, 0}, {0, 1}, {0, -1} }; void dfs(int i, int j, int cnt) { // 到达i, j位置花费了cnt秒 if (i <= 0 || j <= 0 || i > n || j > m) { // i == 0 || j == 0 不可以,因为地图数组下标是从1开始的 return; } if (i == di && j == dj && cnt == t) { // 成功逃脱的条件 escape = 1; return; } for (int s = 0; s < 4; s++) { if (map[i + dir[s][0]][j + dir[s][1]] != 'X') { // 说明此路不通 注意:如果map下标从0开始,这个地方会有越界访问 // 说明这个方向可行,将走过的路设置为墙 map[i + dir[s][0]][j + dir[s][1]] = 'X'; dfs(i + dir[s][0], j + dir[s][1], cnt + 1); // 此时走这一步花费了1秒 map[i + dir[s][0]][j + dir[s][1]] = '.'; // 为了不影响其它路径的结果需要复原 } } } int main() { memset(map, '\0', sizeof(map)); while (1) { cin >> n >> m >> t; int wall = 0; // 统计'X'的个数,方便提前剪枝 char temp; //cin >> temp; for (int i = 1; i <= n; i++) { // 这里没有对数组下标进行减1操作 for (int j = 1; j <= m; j++) { cin >> temp; map[i][j] = temp; if (temp == 'X') { wall++; } else if (temp == 'S') { si = i; sj = j; } else if (temp == 'D') { di = i; dj = j; } } //cin >> temp; } if (n * m - wall <= t) { // 如果条件满足,说明不可能逃离 cout << "NO"; continue; // 走向下次循环结束判断的位置,避免进入DFS遍历 } map[si][sj] = 'X'; // 从起始位置开始遍历,先将当前位置设置为墙 dfs(si, sj, 0); if (escape == 1) { cout << "YES" << endl; break; } else if (escape == 0){ cout << "NO" << endl; break; } } }
4.2 油田
- 题目描述:GeoSurvComp 地质探测公司负责探测地下油田。每次 GeoSurvComp 公司都是在一块长方形的土地上来探测油田。在探测时,他们把这块土地用网格分成若干个小方块,然后逐个分析每块土地,用探测设备探测地下是否有油田。方块土地底下有油田则称为 pocket,如果两个 pocket相邻,则认为是同一块油田,油田可能覆盖多个 pocket。你的工作是计算长方形的土地上有多少个不同的油田。
- 输入描述:输入文件中包含多个测试数据,每个测试数据描述了一个网格。每个网格数据的第一行为两个整数: m n,分别表示网格的行和列;如果 m = 0,则表示输入结束,否则 1≤m≤100, 1 ≤n ≤100。接下来有 m 行数据,每行数据有 n 个字符(不包括行结束符)。每个字符代表一个小方块,如果为“*”,则代表没有石油,如果为“@”,则代表有石油,是一个 pocket。
- 输出描述:对输入文件中的每个网格,输出网格中不同的油田数目。如果两块不同的 pocket 在水平、垂直、或者对角线方向上相邻,则被认为属于同一块油田。每块油田所包含的 pocket 数目不会超过100。
- 代码描述:
#include <iostream> #include <cstring> using namespace std; char grid[101][101]; // 定义地图数组 int m, n; // 行,列 int dir[8][2] = { {1, 0}, {-1, 0}, {0, 1}, {0, -1}, {1, 1}, {-1, 1}, {1, -1}, {-1, -1} }; void dfs(int i, int j) { if (i < 0 || j < 0 || i >= m || j >= n) { return; } if (grid[i][j] == '*') { return; } grid[i][j] = '*'; // 将访问过的油田置为 * for (int s = 0; s < 8; s++) { // 合并相邻的油田 dfs(i + dir[s][0], j + dir[s][1]); } } int main() { cin >> m >> n; int count = 0; char temp; memset(grid, '\0', sizeof(grid)); for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { cin >> temp; grid[i][j] = temp; } } for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { if (grid[i][j] == '@') { count++; // 合并完油田之后再次搜索有没有独立的油田 dfs(i, j); } } } cout << count; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端