

Fast RCNN 训练自己数据集 (2修改数据读取接口)
Fast RCNN训练自己的数据集 (2修改读写接口)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/
https://github.com/YihangLou/fast-rcnn-train-another-dataset 这是我在github上修改的几个文件的链接,求星星啊,求星星啊(原谅我那么不要脸~~)
这里楼主讲解了如何修改Fast RCNN训练自己的数据集,首先请确保你已经安装好了Fast RCNN的环境,具体的编配编制操作请参考我的上一篇文章。首先可以看到fast rcnn的工程目录下有个Lib目录
这里下面存在3个目录分别是:
- datasets
- fast_rcnn
- roi_data_layer
- utils
在这里修改读写数据的接口主要是datasets目录下,fast_rcnn下面主要存放的是python的训练和测试脚本,以及训练的配置文件,roi_data_layer下面存放的主要是一些ROI处理操作,utils下面存放的是一些通用操作比如非极大值nms,以及计算bounding box的重叠率等常用功能
1.构建自己的IMDB子类
1.1文件概述
可有看到datasets目录下主要有三个文件,分别是
- factory.py
- imdb.py
- pascal_voc.py
factory.py 学过设计模式的应该知道这是个工厂类,用类生成imdb类并且返回数据库共网络训练和测试使用
imdb.py 这里是数据库读写类的基类,分装了许多db的操作,但是具体的一些文件读写需要继承继续读写
pascal_voc.py Ross在这里用pascal_voc.py这个类来操作
1.2 读取文件函数分析
接下来我来介绍一下pasca_voc.py这个文件,我们主要是基于这个文件进行修改,里面有几个重要的函数需要修改
- def init(self, image_set, year, devkit_path=None)
这个是初始化函数,它对应着的是pascal_voc的数据集访问格式,其实我们将其接口修改的更简单一点 - def image_path_at(self, i)
根据第i个图像样本返回其对应的path,其调用了image_path_from_index(self, index)作为其具体实现 - def image_path_from_index(self, index)
实现了 image_path的具体功能 - def _load_image_set_index(self)
加载了样本的list文件 - def _get_default_path(self)
获得数据集地址 - def gt_roidb(self)
读取并返回ground_truth的db - def selective_search_roidb
读取并返回ROI的db - def _load_selective_search_roidb(self, gt_roidb)
加载预选框的文件 - def selective_search_IJCV_roidb(self)
在这里调用读取Ground_truth和ROI db并将db合并 - def _load_selective_search_IJCV_roidb(self, gt_roidb)
这里是专门读取作者在IJCV上用的dataset - def _load_pascal_annotation(self, index)
这个函数是读取gt的具体实现 - def _write_voc_results_file(self, all_boxes)
voc的检测结果写入到文件 - def _do_matlab_eval(self, comp_id, output_dir='output')
根据matlab的evluation接口来做结果的分析 - def evaluate_detections
其调用了_do_matlab_eval - def competition_mode
设置competitoin_mode,加了一些噪点
1.3训练数据集格式
在我的检测任务里,我主要是从道路卡口数据中检测车,因此我这里只有background 和car两类物体,为了操作方便,我不像pascal_voc数据集里面一样每个图像用一个xml来标注多类,先说一下我的数据格式
这里是所有样本的图像列表
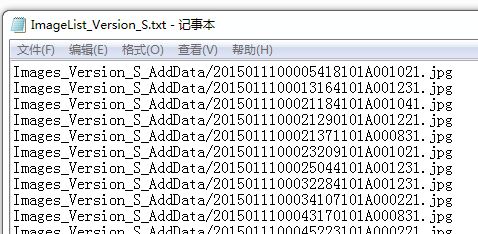
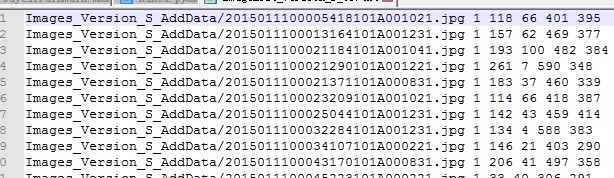
我的GroundTruth数据的格式,第一个为图像路径,之后1代表目标物的个数, 后面的坐标代表左上右下的坐标,坐标的位置从1开始
这里我要特别提醒一下大家,一定要注意坐标格式,一定要注意坐标格式,一定要注意坐标格式,重要的事情说三遍!!!,要不然你会范很多错误都会是因为坐标不一致引起的报错
1.4修改读取接口
这里是原始的pascal_voc的init函数,在这里,由于我们自己的数据集往往比voc的数据集要更简单的一些,在作者额代码里面用了很多的路径拼接,我们不用去迎合他的格式,将这些操作简单化即可,在这里我会一一列举每个我修改过的函数。这里按照文件中的顺序排列。
原始初始化函数:
def __init__(self, image_set, year, devkit_path=None):
datasets.imdb.__init__(self, 'voc_' + year + '_' + image_set)
self._year = year
self._image_set = image_set
self._devkit_path = self._get_default_path() if devkit_path is None \
else devkit_path
self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
self._class_to_ind = dict(zip(self.classes, xrange(self.num_classes)))
self._image_ext = '.jpg'
self._image_index = self._load_image_set_index()
# Default to roidb handler
self._roidb_handler = self.selective_search_roidb
# PASCAL specific config options
self.config = {'cleanup' : True,
'use_salt' : True,
'top_k' : 2000}
assert os.path.exists(self._devkit_path), \
'VOCdevkit path does not exist: {}'.format(self._devkit_path)
assert os.path.exists(self._data_path), \
'Path does not exist: {}'.format(self._data_path)
修改后的初始化函数:
def __init__(self, image_set, devkit_path=None):
datasets.imdb.__init__(self, image_set)#imageset 为train test
self._image_set = image_set
self._devkit_path = devkit_path
self._data_path = os.path.join(self._devkit_path)
self._classes = ('__background__','car')#包含的类
self._class_to_ind = dict(zip(self.classes, xrange(self.num_classes)))#构成字典{'__background__':'0','car':'1'}
self._image_index = self._load_image_set_index('ImageList_Version_S_AddData.txt')#添加文件列表
# Default to roidb handler
self._roidb_handler = self.selective_search_roidb
# PASCAL specific config options
self.config = {'cleanup' : True,
'use_salt' : True,
'top_k' : 2000}
assert os.path.exists(self._devkit_path), \
'VOCdevkit path does not exist: {}'.format(self._devkit_path)
assert os.path.exists(self._data_path), \
'Path does not exist: {}'.format(self._data_path)
原始的image_path_from_index:
def image_path_from_index(self, index):
"""
Construct an image path from the image's "index" identifier.
"""
image_path = os.path.join(self._data_path, 'JPEGImages',
index + self._image_ext)
assert os.path.exists(image_path), \
'Path does not exist: {}'.format(image_path)
return image_path
修改后的image_path_from_index:
def image_path_from_index(self, index):#根据_image_index获取图像路径
"""
Construct an image path from the image's "index" identifier.
"""
image_path = os.path.join(self._data_path, index)
assert os.path.exists(image_path), \
'Path does not exist: {}'.format(image_path)
return image_path
原始的 _load_image_set_index:
def _load_image_set_index(self):
"""
Load the indexes listed in this dataset's image set file.
"""
# Example path to image set file:
# self._devkit_path + /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt
image_set_file = os.path.join(self._data_path, 'ImageSets', 'Main',
self._image_set + '.txt')
assert os.path.exists(image_set_file), \
'Path does not exist: {}'.format(image_set_file)
with open(image_set_file) as f:
image_index = [x.strip() for x in f.readlines()]
return image_index
修改后的 _load_image_set_index:
def _load_image_set_index(self, imagelist):#已经修改
"""
Load the indexes listed in this dataset's image set file.
"""
# Example path to image set file:
# self._devkit_path + /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt
#/home/chenjie/KakouTrainForFRCNN_1/DataSet/KakouTrainFRCNN_ImageList.txt
image_set_file = os.path.join(self._data_path, imagelist)# load ImageList that only contain ImageFileName
assert os.path.exists(image_set_file), \
'Path does not exist: {}'.format(image_set_file)
with open(image_set_file) as f:
image_index = [x.strip() for x in f.readlines()]
return image_index
函数 _get_default_path,我直接删除了
原始的gt_roidb:
def gt_roidb(self):
"""
Return the database of ground-truth regions of interest.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} gt roidb loaded from {}'.format(self.name, cache_file)
return roidb
gt_roidb = [self._load_pascal_annotation(index)
for index in self.image_index]
with open(cache_file, 'wb') as fid:
cPickle.dump(gt_roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote gt roidb to {}'.format(cache_file)
return gt_roidb
修改后的gt_roidb:
def gt_roidb(self):
"""
Return the database of ground-truth regions of interest.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')
if os.path.exists(cache_file):#若存在cache file则直接从cache file中读取
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} gt roidb loaded from {}'.format(self.name, cache_file)
return roidb
gt_roidb = self._load_annotation() #已经修改,直接读入整个GT文件
with open(cache_file, 'wb') as fid:
cPickle.dump(gt_roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote gt roidb to {}'.format(cache_file)
return gt_roidb
原始的selective_search_roidb(self):
def selective_search_roidb(self):
"""
Return the database of selective search regions of interest.
Ground-truth ROIs are also included.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path,
self.name + '_selective_search_roidb.pkl')
if os.path.exists(cache_file):
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} ss roidb loaded from {}'.format(self.name, cache_file)
return roidb
if int(self._year) == 2007 or self._image_set != 'test':
gt_roidb = self.gt_roidb()
ss_roidb = self._load_selective_search_roidb(gt_roidb)
roidb = datasets.imdb.merge_roidbs(gt_roidb, ss_roidb)
else:
roidb = self._load_selective_search_roidb(None)
with open(cache_file, 'wb') as fid:
cPickle.dump(roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote ss roidb to {}'.format(cache_file)
return roidb
修改后的selective_search_roidb(self):
这里有个pkl文件我需要特别说明一下,如果你再次训练的时候修改了数据库,比如添加或者删除了一些样本,但是你的数据库名字函数原来那个,比如我这里训练的数据库叫KakouTrain,必须要在data/cache/目录下把数据库的缓存文件.pkl给删除掉,否则其不会重新读取相应的数据库,而是直接从之前读入然后缓存的pkl文件中读取进来,这样修改的数据库并没有进入网络,而是加载了老版本的数据。
def selective_search_roidb(self):#已经修改
"""
Return the database of selective search regions of interest.
Ground-truth ROIs are also included.
This function loads/saves from/to a cache file to speed up future calls.
"""
cache_file = os.path.join(self.cache_path,self.name + '_selective_search_roidb.pkl')
if os.path.exists(cache_file): #若存在cache_file则读取相对应的.pkl文件
with open(cache_file, 'rb') as fid:
roidb = cPickle.load(fid)
print '{} ss roidb loaded from {}'.format(self.name, cache_file)
return roidb
if self._image_set !='KakouTest':
gt_roidb = self.gt_roidb()
ss_roidb = self._load_selective_search_roidb(gt_roidb)
roidb = datasets.imdb.merge_roidbs(gt_roidb, ss_roidb)
else:
roidb = self._load_selective_search_roidb(None)
with open(cache_file, 'wb') as fid:
cPickle.dump(roidb, fid, cPickle.HIGHEST_PROTOCOL)
print 'wrote ss roidb to {}'.format(cache_file)
return roidb
原始的_load_selective_search_roidb(self, gt_roidb):
def _load_selective_search_roidb(self, gt_roidb):
filename = os.path.abspath(os.path.join(self.cache_path, '..',
'selective_search_data',
self.name + '.mat'))
assert os.path.exists(filename), \
'Selective search data not found at: {}'.format(filename)
raw_data = sio.loadmat(filename)['boxes'].ravel()
box_list = []
for i in xrange(raw_data.shape[0]):
box_list.append(raw_data[i][:, (1, 0, 3, 2)] - 1)
return self.create_roidb_from_box_list(box_list, gt_roidb)
修改后的_load_selective_search_roidb(self, gt_roidb):
这里原作者用的是Selective_search,但是我用的是EdgeBox的方法来提取Mat,我没有修改函数名,只是把输入的Mat文件给替换了,Edgebox实际的效果比selective_search要好,速度也要更快,具体的EdgeBox代码大家可以在Ross的tutorial中看到地址。
注意,这里非常关键!!!!!,由于Selective_Search中的OP返回的坐标顺序需要调整,并不是左上右下的顺序,可以看到在下面box_list.append()中有一个(1,0,3,2)的操作,不管你用哪种OP方法,输入的坐标都应该是x1 y1 x2 y2,不要弄成w h 那种格式,也不要调换顺序。坐标-1,默认坐标从0开始,楼主提醒各位,一定要非常注意坐标顺序,大小,边界,格式问题,否则你会被错误折腾死的!!!
def _load_selective_search_roidb(self, gt_roidb):#已经修改
#filename = os.path.abspath(os.path.join(self.cache_path, '..','selective_search_data',self.name + '.mat'))
filename = os.path.join(self._data_path, 'EdgeBox_Version_S_AddData.mat')#这里输入相对应的预选框文件路径
assert os.path.exists(filename), \
'Selective search data not found at: {}'.format(filename)
raw_data = sio.loadmat(filename)['boxes'].ravel()
box_list = []
for i in xrange(raw_data.shape[0]):
#box_list.append(raw_data[i][:,(1, 0, 3, 2)] - 1)#原来的Psacalvoc调换了列,我这里box的顺序是x1 ,y1,x2,y2 由EdgeBox格式为x1,y1,w,h经过修改
box_list.append(raw_data[i][:,:] -1)
return self.create_roidb_from_box_list(box_list, gt_roidb)
原始的_load_selective_search_IJCV_roidb,我没用这个数据集,因此不修改这个函数
原始的_load_pascal_annotation(self, index):
def _load_pascal_annotation(self, index):
"""
Load image and bounding boxes info from XML file in the PASCAL VOC
format.
"""
filename = os.path.join(self._data_path, 'Annotations', index + '.xml')
# print 'Loading: {}'.format(filename)
def get_data_from_tag(node, tag):
return node.getElementsByTagName(tag)[0].childNodes[0].data
with open(filename) as f:
data = minidom.parseString(f.read())
objs = data.getElementsByTagName('object')
num_objs = len(objs)
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
# Load object bounding boxes into a data frame.
for ix, obj in enumerate(objs):
# Make pixel indexes 0-based
x1 = float(get_data_from_tag(obj, 'xmin')) - 1
y1 = float(get_data_from_tag(obj, 'ymin')) - 1
x2 = float(get_data_from_tag(obj, 'xmax')) - 1
y2 = float(get_data_from_tag(obj, 'ymax')) - 1
cls = self._class_to_ind[
str(get_data_from_tag(obj, "name")).lower().strip()]
boxes[ix, :] = [x1, y1, x2, y2]
gt_classes[ix] = cls
overlaps[ix, cls] = 1.0
overlaps = scipy.sparse.csr_matrix(overlaps)
return {'boxes' : boxes,
'gt_classes': gt_classes,
'gt_overlaps' : overlaps,
'flipped' : False}
修改后的_load_pascal_annotation(self, index):
def _load_annotation(self):
"""
Load image and bounding boxes info from annotation
format.
"""
#,此函数作用读入GT文件,我的文件的格式 CarTrainingDataForFRCNN_1\Images\2015011100035366101A000131.jpg 1 147 65 443 361
gt_roidb = []
annotationfile = os.path.join(self._data_path, 'ImageList_Version_S_GT_AddData.txt')
f = open(annotationfile)
split_line = f.readline().strip().split()
num = 1
while(split_line):
num_objs = int(split_line[1])
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
gt_classes = np.zeros((num_objs), dtype=np.int32)
overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)
for i in range(num_objs):
x1 = float( split_line[2 + i * 4])
y1 = float (split_line[3 + i * 4])
x2 = float (split_line[4 + i * 4])
y2 = float (split_line[5 + i * 4])
cls = self._class_to_ind['car']
boxes[i,:] = [x1, y1, x2, y2]
gt_classes[i] = cls
overlaps[i,cls] = 1.0
overlaps = scipy.sparse.csr_matrix(overlaps)
gt_roidb.append({'boxes' : boxes, 'gt_classes': gt_classes, 'gt_overlaps' : overlaps, 'flipped' : False})
split_line = f.readline().strip().split()
f.close()
return gt_roidb
之后的这几个函数我都没有修改,检测结果,我是修改了demo.py这个文件,直接生成txt文件,然后用python opencv直接可视化,没有用着里面的接口,感觉太麻烦了,先怎么方便怎么来
- _write_voc_results_file(self, all_boxes)
- _do_matlab_eval(self, comp_id, output_dir='output')
- evaluate_detections(self, all_boxes, output_dir)
- competition_mode(self, on)
记得在最后的__main__下面也修改相应的路径
d = datasets.pascal_voc('trainval', '2007')
改成
d = datasets.kakou('KakouTrain', '/home/chenjie/KakouTrainForFRCNN_1')
并且同时在文件的开头import 里面也做修改
import datasets.pascal_voc
改成
import datasets.kakou
OK,在这里我们已经完成了整个的读取接口的改写,主要是将GT和预选框Mat文件读取并返回
2.修改factory.py
当网络训练时会调用factory里面的get方法获得相应的imdb,
首先在文件头import 把pascal_voc改成kakou
在这个文件作者生成了多个数据库的路径,我们自己数据库只要给定根路径即可,修改主要有以下4个
- 因此将里面的def _selective_search_IJCV_top_k函数整个注释掉
- 函数之后有两个多级的for循环,也将其注释
- 直接定义imageset和devkit
- 修改get_imdb函数
原始的factory.py:
__sets = {}
import datasets.pascal_voc
import numpy as np
def _selective_search_IJCV_top_k(split, year, top_k):
"""Return an imdb that uses the top k proposals from the selective search
IJCV code.
"""
imdb = datasets.pascal_voc(split, year)
imdb.roidb_handler = imdb.selective_search_IJCV_roidb
imdb.config['top_k'] = top_k
return imdb
# Set up voc_<year>_<split> using selective search "fast" mode
for year in ['2007', '2012']:
for split in ['train', 'val', 'trainval', 'test']:
name = 'voc_{}_{}'.format(year, split)
__sets[name] = (lambda split=split, year=year:
datasets.pascal_voc(split, year))
# Set up voc_<year>_<split>_top_<k> using selective search "quality" mode
# but only returning the first k boxes
for top_k in np.arange(1000, 11000, 1000):
for year in ['2007', '2012']:
for split in ['train', 'val', 'trainval', 'test']:
name = 'voc_{}_{}_top_{:d}'.format(year, split, top_k)
__sets[name] = (lambda split=split, year=year, top_k=top_k:
_selective_search_IJCV_top_k(split, year, top_k))
def get_imdb(name):
"""Get an imdb (image database) by name."""
if not __sets.has_key(name):
raise KeyError('Unknown dataset: {}'.format(name))
return __sets[name]()
def list_imdbs():
"""List all registered imdbs."""
return __sets.keys()
修改后的factory.py
#import datasets.pascal_voc
import datasets.kakou
import numpy as np
__sets = {}
imageset = 'KakouTrain'
devkit = '/home/chenjie/DataSet/CarTrainingDataForFRCNN_1/Images_Version_S_AddData'
#def _selective_search_IJCV_top_k(split, year, top_k):
# """Return an imdb that uses the top k proposals from the selective search
# IJCV code.
# """
# imdb = datasets.pascal_voc(split, year)
# imdb.roidb_handler = imdb.selective_search_IJCV_roidb
# imdb.config['top_k'] = top_k
# return imdb
### Set up voc_<year>_<split> using selective search "fast" mode
##for year in ['2007', '2012']:
## for split in ['train', 'val', 'trainval', 'test']:
## name = 'voc_{}_{}'.format(year, split)
## __sets[name] = (lambda split=split, year=year:
## datasets.pascal_voc(split, year))
# Set up voc_<year>_<split>_top_<k> using selective search "quality" mode
# but only returning the first k boxes
##for top_k in np.arange(1000, 11000, 1000):
## for year in ['2007', '2012']:
## for split in ['train', 'val', 'trainval', 'test']:
## name = 'voc_{}_{}_top_{:d}'.format(year, split, top_k)
## __sets[name] = (lambda split=split, year=year, top_k=top_k:
## _selective_search_IJCV_top_k(split, year, top_k))
def get_imdb(name):
"""Get an imdb (image database) by name."""
__sets['KakouTrain'] = (lambda imageset = imageset, devkit = devkit: datasets.kakou(imageset,devkit))
if not __sets.has_key(name):
raise KeyError('Unknown dataset: {}'.format(name))
return __sets[name]()
def list_imdbs():
"""List all registered imdbs."""
return __sets.keys()
3.修改 __init__.py
在行首添加上 from .kakou import kakou
总结
在这里终于改完了读取接口的所有内容,主要步骤是
- 复制pascal_voc,改名字,修改GroundTruth和OP预选框的读取方式
- 修改factory.py,修改数据库路径和获得方式
- __init__.py添加上改完的py文件
下面列出一些需要注意的地方
- 读取方式怎么方便怎么来,并不一定要按照里面xml的格式,因为大家自己应用到工程中去往往不会是非常多的类别,单个对象的直接用txt就可以
- 坐标的顺序我再说一次,要左上右下,并且x1必须要小于x2,这个是基本,反了会在坐标水平变换的时候会出错,坐标从0开始,如果已经是0,则不需要再-1
- GT的路径最好用相对,别用绝对,然后路径拼接的时候要注意,然后如果是txt是windows下生成的,注意斜杠的方向和编码的格式,中文路径编码必须用UTF-8无BOM格式,不能用windows自带的记事本直接换一种编码存储,相关数据集的编码问题参见我的另一篇文章,linux传输乱码
- 关于Mat文件,在训练时是将所有图像的OP都合在了一起,是一个很大的Mat文件,注意其中图像list的顺序千万不能错,并且坐标格式要修改为x1 y1 x2 y2,每种OP生成的坐标顺序要小心,从0开始还是从1开始也要小心
- 训练图像的大小不要太大,否则生成的OP也会太多,速度太慢,图像样本大小最好调整到500,600左右,然后再提取OP
- 如果读取并生成pkl文件之后,实际数据内容或者顺序还有问题,记得要把data/cache/下面的pkl文件给删掉
关于下部训练和检测网络,我将在下一篇文章中说明

