线性回归
线性回归
导包
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression
1. 简单演示
1.1 创建一些有对应关系的散点,使用线性回归推测关系
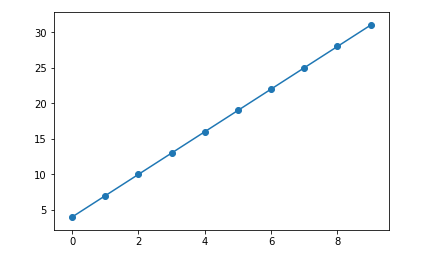
1.1.1 创建一些x,指定w和b,按照这个关系求出y,并绘制散点图展示关系
x = np.arange(0,10,1) y = 3*x+4 plt.scatter(x,y)
1.1.2 获取机器学习模型,对数据进行学习
lr = LinearRegression() # 获取模型 lr.fit(x.reshape(-1,1),y) # 训练模型
1.1.3 获取模型估计出来的斜率和截距,并绘图展示效果
w_ = lr.coef_ # coefficient 系数 也就是 权重的意思. b_ = lr.intercept_ # intercept 截距 也就是 bias y_ = w_*x+b_ # 使用估测出来的w和b 求y_ plt.plot(x,y_) # 估计值 plt.scatter(x,y) # 观测值(真实值)
来一个具体的案例,使用线性回归来做预测
2. 糖尿病严重程度预测
2.1 糖尿病严重程度预测
from sklearn import datasets # 从datasets中获取糖尿病的数据 diabetes = datasets.load_diabetes() # diabetes print(diabetes.DESCR) # 查看数据集的描述信息 data = diabetes.data # 特征值 target = diabetes.target # 目标值 feature_names = diabetes.feature_names # 特征的名字 pd.DataFrame(data,columns=feature_names)
预测结果 展示结果
通过估计各个特征的 权重 来看一下 哪个特征对最终结果的影响更大
之前的案例 只有一个特征(一个x也就是只有一个权重)
这个案例 有很多个特征 (会有各自的权重)
把数据集 分成 训练集 和 测试集(最后40个留着作为测试集)
# 训练集 X_train = data[:-40] y_train = target[:-40] # 测试集 X_test = data[-40:] y_test = target[-40:]. # 使用切分好的数据来训练模型 以后去测试 lr = LinearRegression() lr.fit(X_train,y_train) w_ = lr.coef_ # 有10个特征 所以 这个有10个权重 b_ = lr.intercept_ # y = w1*x1+w2*x2+...+w10*x10+b np.dot(X_test[0],w_) + b_ 或者: y_ = lr.predict(X_test) # 直接调用predict 传入特征值 就可以得到预测结果
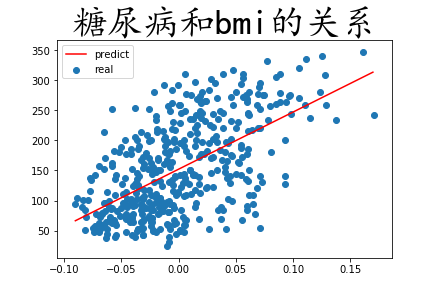
2.2 绘图研究某一特征和糖尿病严重程度的关系
只考察 bmi 和 target 之间的关系
# 只要第二列 X_train = data[:,2] y_train = target plt.scatter(X_train,y_train)
lr = LinearRegression() lr.fit(X_train.reshape(-1,1),y_train) lr.coef_ lr.intercept_ X_train.min() X_train.max() X_test = np.arange(X_train.min(),X_train.max(),0.01).reshape(-1,1) y_ = lr.predict(X_test) plt.plot(X_test,y_,color='r') plt.scatter(X_train,y_train) plt.legend(['predict','real']) plt.title('糖尿病和bmi的关系',fontproperties='KaiTi',fontsize=36)