K-临近算法(KNN)
K-临近算法(KNN)
K nearest neighbour
1、k-近邻算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
欧几里得距离(Euclidean Distance)
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。公式如下:
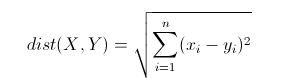
2、在scikit-learn库中使用k-近邻算法
-
分类问题:from sklearn.neighbors import KNeighborsClassifier
-
回归问题:from sklearn.neighbors import KNeighborsRegressor
1)用于分类(用鸢尾花作为示例)
导包,机器学习的算法KNN、数据鸢尾花
# scikit-learning 提供数据样本,可以供我们研究机器学习模型 # 可以使用load方法加载datasets中的各种数据 from sklearn import datasets import matplotlib.pyplot as plt
iris = datasets.load_iris() # load是获取本地的数据集 iris就是鸢尾花数据集 data = iris.data # 特征值 target = iris.target # 目标值 target_names = iris.target_names # 目标的名字 feature_names = iris.feature_names # 特征的名字 df = DataFrame(data,columns=feature_names) df.plot()

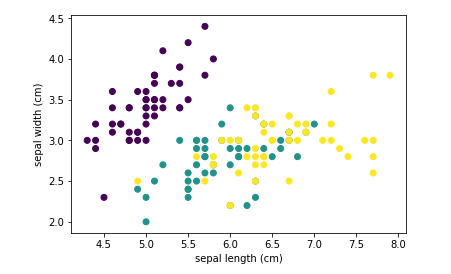
画图研究前两个特征和分类之间的关系(二维散点图只能展示两个维度)
# 取出 前两个特征 特征0 作为横轴 特征1作为纵轴 X_train = data[:,:2] y_train = target plt.scatter(X_train[:,0],X_train[:,1],c=target) # 特征0作为点的横坐标 特征1作为点的纵坐标 target值作为点的颜色映射 plt.xlabel(feature_names[0]) plt.ylabel(feature_names[1])
定义KNN分类器
真正判断分类的时候 肯定是用所有的4个特征 效果更好
这里只用两个特征来判断分类 也可以 但是效果肯定不如4个的好
这里之所以用两个 是为了画图 给大家展示效果
# 获取模型 from sklearn.neighbors import KNeighborsClassifier # 使用两个特征来训练模型 # n_neighbors可以自己根据经验给定 一般给的是奇数(偶数容易造成 两种分类一样多的情况) knn = KNeighborsClassifier(n_neighbors=7)
第一步,训练数据
knn.fit(X_train,y_train)
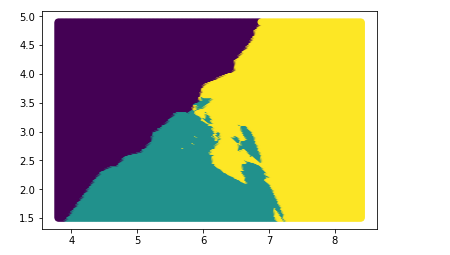
第二步预测数据:所预测的数据,自己创造,就是上面所显示图片的背景点
生成预测数据
# 要 取遍 平面 上 所有点 # 首先 x的范围内要取遍 y的范围内也要取遍 x = np.arange(X_train[:,0].min()-0.5,X_train[:,0].max()+0.5,0.02) # 取遍x轴 y = np.arange(X_train[:,1].min()-0.5,X_train[:,1].max()+0.5,0.02) # 取遍y轴 # 交叉 取遍 整个平面 X,Y = np.meshgrid(x,y) # 返回两个 ndarray 第一个是 平面上所有点的x座标 第二个是平面上所有点的y座标 # c_函数 可以使行 变列 (我们使用这个函数 就可以 把X,Y里面的值 组合成座标点) X_test = np.c_[X.flatten(),Y.flatten()] # 使用reshape去变形也可以 plt.scatter(X_test[:,0],X_test[:,1])# 查看是否确定是取遍平面中的所有点 # 模型预测出来的结果 一般叫y_ y_ = knn.predict(X_test) y_
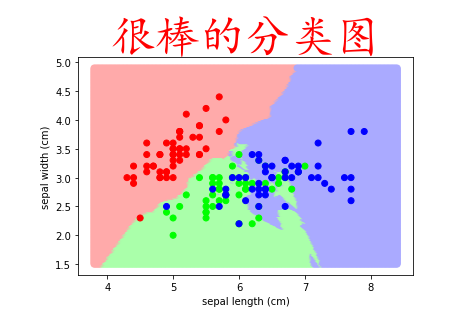
以图形化的效果展示结果
plt.scatter(X_test[:,0],X_test[:,1],c=y_)
from matplotlib.colors import ListedColormap # ListedColormap([]) # 创建颜色映射对象 cm1 = ListedColormap( ['#FFAAAA','#AAFFAA','#AAAAFF'] ) cm2 = ListedColormap( ['#FF0000','#00FF00','#0000FF'] ) plt.scatter(X_test[:,0],X_test[:,1],c=y_,cmap=cm1) # c是color 会根据 传入的不同数值 去填充不同的颜色 plt.scatter(X_train[:,0],X_train[:,1],c=target,cmap=cm2) plt.xlabel(feature_names[0]) plt.ylabel(feature_names[1]) plt.title('很棒的分类图',fontproperties='KaiTi',fontsize=45,color='r')