

初识数据库索引结构
建立索引的优点在于:能够提高某列数据的检索效率,不需要进行顺序扫描。同时,缺点在于:索引结构需要单独维护,占据磁盘/内存空间,而且降低了增删改的效率。
索引结构可以使用什么数据结构来实现?
-
二叉树。有序,但是存在缺点:顺序插入时会退化成单向链表,查询性能大大降低,数据量大时,树会很深,检索速度变慢。
-
红黑树。一种自平衡的二叉树,因此解决退化成链表的问题,但是其二叉树的本质仍然存在,数据量很大时树的深度仍然很大。
由此引出B树这种数据结构。
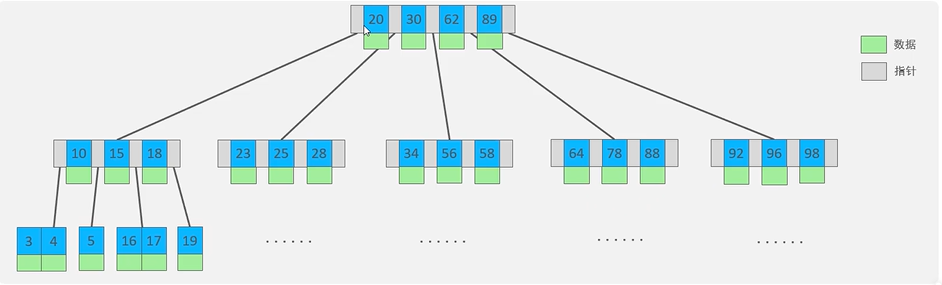
上图是一个最大度数为5的B树,每个节点最多存储4个key和5个指针。5个指针分别指向5个子节点。不管是非叶子节点还是叶子节点,key值都对应存储其数据entry。B树的插入和分裂过程需要重点理解。
B+树是B树的变种。
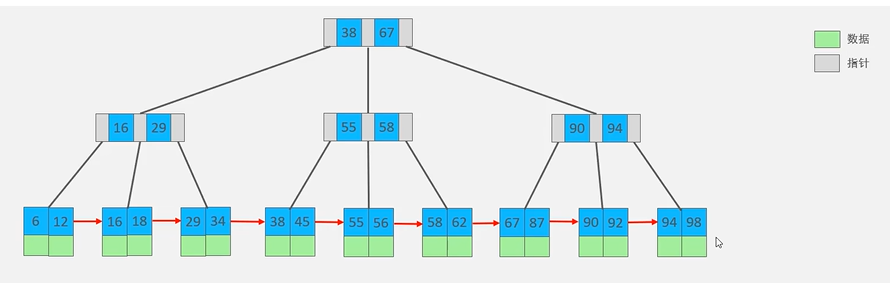
上图以一个最大度数为4的B+树为例。与B树不同的是,B+树中,所有元素都会出现在叶子节点中,叶子节点用于存放数据,而非叶子节点只是起到索引的作用。此外,B+树中,所有的叶子节点形成一个单向链表。
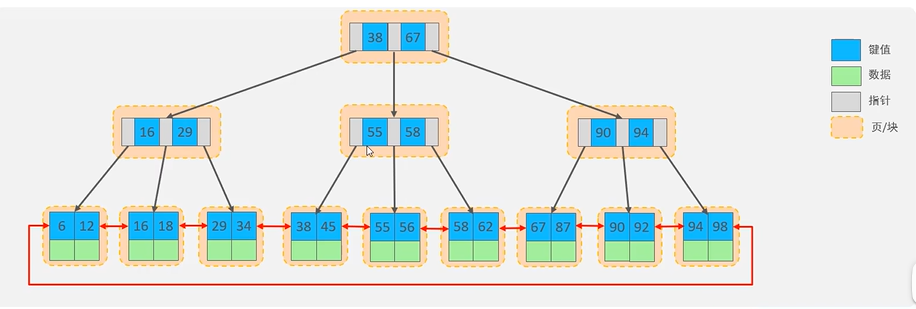
MySQL中,对普通的B+树结构进行改进。对叶子节点增加了一个指针变成双向链表,能够提高区间查询的性能。每个节点(非叶子节点和叶子节点)都存储在一个页中。
另一个常用的索引结构是hash索引结构。这种索引利用hash算法,特点在于:只能用于相等/不等比较,不能进行范围查询;无法利用索引进行排序操作;查询效率通常比B+树索引高,因为只需要进行hash值进行一次查询。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)