python之编码问题
二进制
------>ASCII:只能存英文和拉丁字符。一个字符占用一个字节,8位
------------>gb2312:智能6700多个中文, 1980年
gbk1.0:存了2万多字符 1995年
gb18030:2w7汉字 2000年
------------>其他国家大量编码
------------------------>统一的万国码 unicode:utf-32 一个字符占4个字节
------------------------>统一的万国码 unicode:utf-16 一个字符占2个字节
为解决内存的问题,开发了utf-16但是一些字找不到
--------------->再次改进unicode:utf-8:
英文用ASCII码占用一个字节,中文3个字节,欧洲2个字节
计算只认识二进制0,1 而在python中,字节类型就非常接近二进制
明文:就是我们可以认识的数据
密文:我们不认识,但是计算机认识的数据
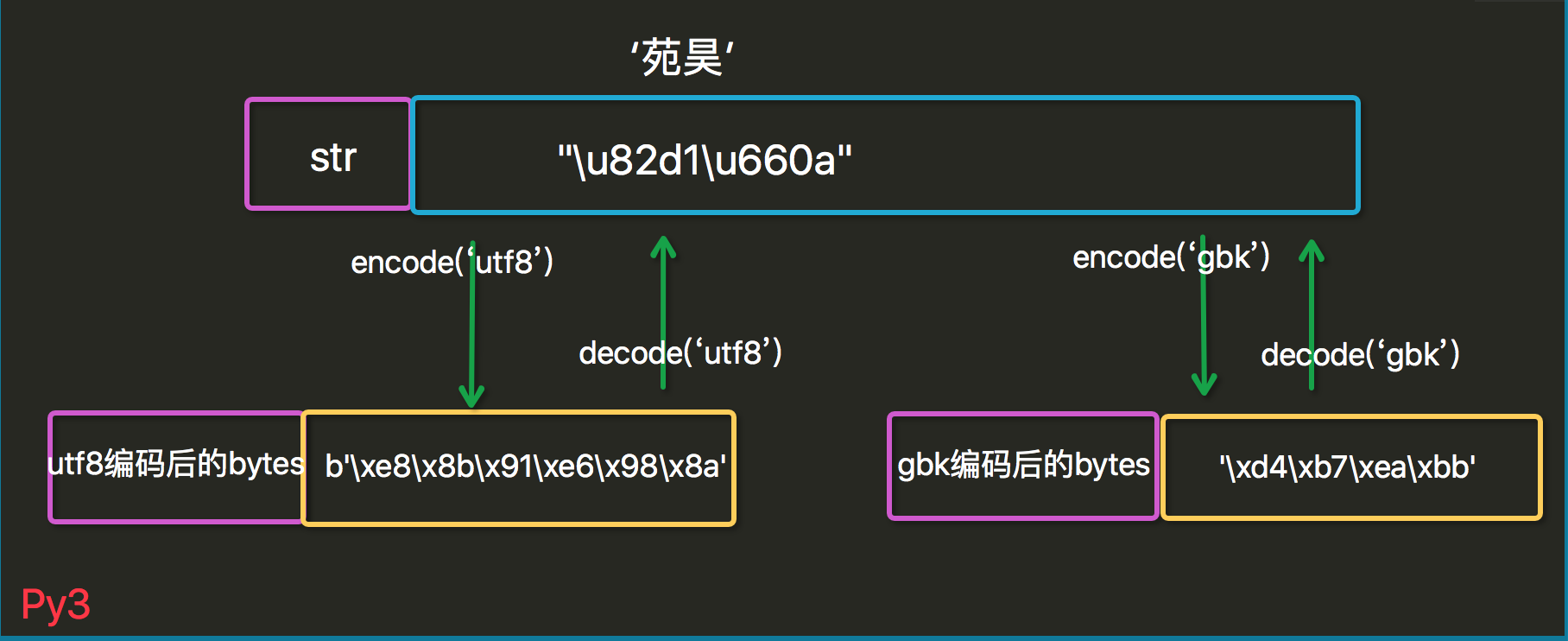
注意:byts类型不会记录编码格式,但是相同的unicode字符串,根据不同的编码格式(utf-8,gbk等)得到的结果是不一致的。
py2中的编码:
py2中存在着两种数据格式:他是都是basestring的子类。
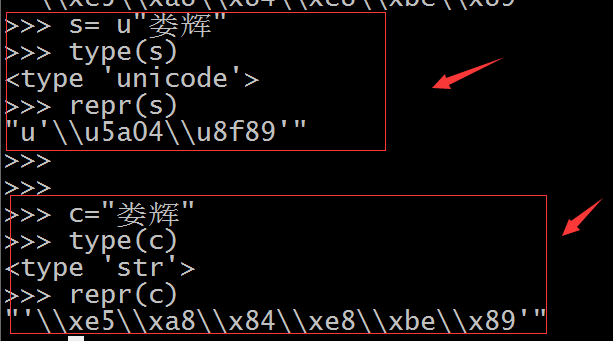
1.str 以bytes字节流存储,更接近计算机,密文,len(一个汉字) 长度是3 因为在utf-8编码的存储,一个汉字长度就是3。(所以在py2中的sock可以直接传递str)
2.unicode 以unicode编码存储,其实就是一个字符串,len(一个汉字)长度是1 就是我们认识的明文
py2的优点:
1.字符串的拼接: s="hellow"+u"yuan" 字节流与unicode 进行拼接,不是应该报错吗?
可以进行拼接 因为,py2中自动帮我们把assic码的字节流转换为了unicode。
但是在非aciic码的字节流就会失效了。比如 s='娄'+u"辉" 因此我们自己去编码

py3编码
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.
1.python3 中把unicode类型 弄成了str(因为我们比较常用),原来的str弄成了bytes类型
2.定义了str 与 bytes类型的清晰界限,解释器不帮我们转换,需要我们去转换
注意:无论py2,还是py3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
#文件开头的encoding:utf-8的作用
在py2中,默认的编码是assic 在使用 s=“汉字” 的时候,acssic码中没有,所以报错,所以使用 coding:utf-8
在py3中,默认的编码是unicode 可以使用 sys.getdefaultencoding()查看
但是 py3中str 和 py2中 str = u”“汉字”的时候,都是unicode的,内存的统一,便于操作!!
同时还需要注意一个点: 文本保存的编码方式与编译器的编码格式要一直
编码cmd下的错误:
hello.py
#coding:utf8
print ('苑昊')
文件保存时的编码也为utf8。
思考:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身就是一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print'苑昊'时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe显示,而在py2里这个内容就是utf8编码的字节数据,而这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,符合ISO统一标准的,所以没问题。(这里也解释了为什么 字符串默认就是unicode的方式更好。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号