
AI小记-K近邻算法
K近邻算法和其他机器学习模型比,有个特点:即非参数化的局部模型。
其他机器学习模型一般都是基于训练数据,得出一般性知识,这些知识的表现是一个全局性模型的结构和参数。模型你和好了后,不再依赖训练数据,直接用参数去预测新的未知数据。
K近邻算法并不是预先计算出参数,而且对于特定的预测实例,K近邻预测只是基于关联到的局部数据,不需要依赖全部数据。
K近邻是基于实例的学习,学习的不是明确的泛化模型,而是样本之间的关系。通过样本之间的关系,来确定新样本的输出。
K近邻原理:简单说就是“近朱者赤近墨者黑”。对于新样本,它会寻找离新样本最近的K个训练样本,从K个样本里推算出新样本的输出,比如多数样本所属的类别即为新样本的预测类别。K属于算法超参数,需要预先指定。K的不同对于预测结果影响较大。如下图K=3和K=5对预测结果有不一样的输出。
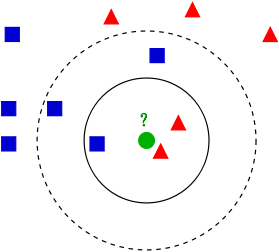
从KNN原理上,我们可以知道,KNN无需训练,但是预测时需要计算出离新样本最近的k个点。
如何寻找离新样本最近的K个点,这是一个问题。我们在另一篇文章里解决这个问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号