浅谈LangChain框架及其在大模型应用开发中的实践
1.LangChain框架介绍
思考:
1)开发一个大模型应用,需要哪些能力?或者说需要解决哪些问题?
2)大模型应用中,大模型承担了什么样的角色?
1.1 LangChain框架发展历程
- 从功能发展上来看:
- LangChain第一个版本在2022年10月发布。
- 提供了基础的提示词(Prompt)管理功能。
- 将工具(Tool)与语言模型结合,支持调用外部 API。
- 支持记忆(Memory)模块,用于对话场景的上下文管理。
- 2023年快速发展,成为LLM应用开发的主流框架之一。
- 推出关键功能模块
- 链
- 记忆
- 工具与代理
- RAG支持
- 流水线功能:支持 Prompt 模板化、参数化以及上下文动态注入,流水线式开发。
- 生态与社区建设。
- 2023年下半年,加强商业化与企业应用。
- 推出关键功能模块
- 2024年
- 技术进一步更新升级、进一步建设社区与生态。
- 发展方向:更广泛的标准化、低代码/无代码、企业专用版
- LangChain第一个版本在2022年10月发布。
- 从版本上来看:
- 0.1版本之前
- 框架迭代比较快,各功能模块的代码并没有做很好的区分,以支撑功能为主。
- 0.1版本
- 框架被分拆为过个包,为LangChain生态系统创建良好的基础架构。
- langchain-core:包含涉及 LangChain Runnables 的核心抽象、可观察性工具以及重要抽象(例如聊天模型)的基本实现。
- langchain:包含使用 中定义的接口构建的通用代码langchain-core。此包适用于在特定接口的不同实现之间具有良好通用性的代码。例如,create_tool_calling_agent适用于支持工具调用功能的聊天模型。
- langchain-community:社区维护的第三方集成。包含基于langchain-core中定义的接口的集成。由 LangChain 社区维护。
- 合作伙伴包,专用包通常具有更好的可靠性和支持:
- langchain-openai
- langchain-anthropic
- langgraph:通过将步骤建模为图中的边和节点,使用 LLM 构建强大且有状态的多参与者应用程序。
- langserve:将 LangChain 链部署为 REST API。
- 0.2版本
- langchain软件包不再需要langchain-community。相反langchain-community,现在将依赖于langchain-core和langchain。将更多集成移至langchain-community其自己的langchain-x包中。这是一项非重大更改,因为旧实现保留并标记为已弃用。
- 其他改进:
- 简化工具定义和使用。点击此处了解更多。
- 增加了与聊天模型交互的实用程序:通用模型构造函数、速率限制器、消息实用程序。
- 增加了调度自定义事件的能力。
- 修订了集成文档和 API 参考。
- 0.3版本
- 所有软件包都已从 Pydantic 1 内部升级到 Pydantic 2。所有软件包都完全支持在用户代码中使用 Pydantic 2,无需使用langchain_core.pydantic_v1或pydantic.v1之类的桥接器。
- 其他改进。
- 0.1版本之前
1.2 LangChain框架的核心概念介绍
- 聊天模型(Chat models):通过聊天 API 公开的 LLM,将消息序列处理为输入并输出消息。
- 消息(Messages):聊天模型中的通信单位,用于表示模型的输入和输出。
- 聊天记录(Chat history):以一系列消息表示的对话,在用户消息和模型响应之间交替。
- 工具(Tools):具有关联模式的函数,定义函数的名称、描述和它接受的参数。
- 工具调用(Tool calling):一种聊天模型 API,它接受工具模式以及消息作为输入,并将这些工具的调用作为输出消息的一部分返回。
- 结构化输出(Structured output):一种使聊天模型以结构化格式响应的技术,例如与给定模式匹配的 JSON。
- 内存(Memory):有关对话的信息将被保存,以便在将来的对话中使用。
- 多模态(Multimodality):处理不同形式的数据的能力,例如文本、音频、图像和视频。
- Runnable 接口(Runnable interface):许多 LangChain 组件和 LangChain 表达语言所构建的基础抽象。
- 流式传输(Streaming):LangChain 流式传输 API,用于在结果生成时显示它们。
- LangChain 表达语言 (LCEL)(LangChain Expression Language (LCEL)):用于编排 LangChain 组件的语法。最适合用于较简单的应用程序。
- 文档加载器(Document loaders):将源加载为文档列表。
- 检索(Retrieval):信息检索系统可以根据查询从数据源检索结构化或非结构化数据。
- 文本分割器(Text splitters):将长文本分割成较小的块,这些块可以单独索引,以实现细粒度的检索。
- 嵌入模型(Embedding models):在向量空间中表示文本或图像等数据的模型。
- 向量存储(Vector stores):向量和相关元数据的存储和有效搜索。
- 检索器(Retriever):响应查询而从知识库返回相关文档的组件。
- 检索增强生成 (RAG,Retrieval Augmented Generation):一种通过将语言模型与外部知识库相结合来增强语言模型的技术。
- 代理(Agents):使用语言模型来选择要采取的一系列动作。代理可以通过工具与外部资源进行交互。
- 提示模板(Prompt templates):用于分解模型“提示”的静态部分(通常是一系列消息)的组件。可用于序列化、版本控制和重用这些静态部分。
- 输出解析器(Output parsers):负责获取模型的输出并将其转换为更适合下游任务的格式。输出解析器主要在工具调用和结构化输出普遍可用之前有用。
- 少量提示(Few-shot prompting):通过提供提示中要执行的任务的几个示例来提高模型性能的一项技术。
- 示例选择器(Example selectors):用于根据给定的输入从数据集中选择最相关的示例。示例选择器用于在少样本提示中为提示选择示例。
- 异步编程(Async programming):在异步环境中使用 LangChain 应该了解的基础知识。
- 回调(Callbacks):回调允许在内置组件中执行自定义辅助代码。回调用于从 LangChain 中的 LLM 流式传输输出、跟踪应用程序的中间步骤等。
- 跟踪(Tracing):记录应用程序从输入到输出所采取的步骤的过程。跟踪对于调试和诊断复杂应用程序中的问题至关重要。
- 评估(Evaluation):评估 AI 应用程序的性能和有效性的过程。这涉及根据一组预定义的标准或基准测试模型的响应,以确保其符合所需的质量标准并实现预期目的。此过程对于构建可靠的应用程序至关重要。
- 测试(Testing):验证集成或应用程序的组件是否按预期运行的过程。测试对于确保应用程序正常运行以及代码库更改不会引入新错误至关重要。
1.3 大模型应用开发概述
- 开发一个大模型应用产品,应该考虑哪些内容?
- 确定应用场景:内容生成、信息提取、知识问答、任务自动化、个性化服务。
- 模型选择:通用大语言模型、垂直领域模型
- 如何构建提示词:设计原则、提示词优化
- 数据增强:RAG
- 集成:工具、记忆
- 多步骤任务:Chains、Agents
- 应用部署
- 测试与优化
- 监控与反馈
- 安全性与合规性
- 思考
假设现在需要构建一个AI伴侣应用,假设该应用提供两个基本的功能:
1)随时随地的陪伴式聊天(情绪价值);
2)设置指定任务(假设可以设置指定时间提醒喝水)。
以你当前对大模型的认知,你觉得对你而言,当前最应该解决的问题是什么?
2.开发实践
开发环境配置
1)Windows系统(Linux及Mac自己对应解决),VSCode,Python3.10
2)安装Docker
3)新建服务docker容器
新建并运行容器
docker run -p 8022:22 -p 5000:5000 -t -d mirekphd/python3.10-ubuntu20.04:latest4)新建redis容器
新建并运行容器
docker run -p 6379:6379 -t -d redis进入容器
docker exec -it 容器id /bin/bash启动Redis-Server
nohup redis-server &拿到Redis容器的内网ip。172.17.0.X
5)Python环境配置
安装virtualenv
pip install virtualenv新建虚拟环境
cd /home,virtualenv venv_test新建项目目录
cd /home,mkdir test_code6)VSCode配置
启动VSCode。
安装Docker插件,找到你刚建立的服务docker容器,右键,选择Attach Visual Studio Code,进入容器。
安装Python插件。
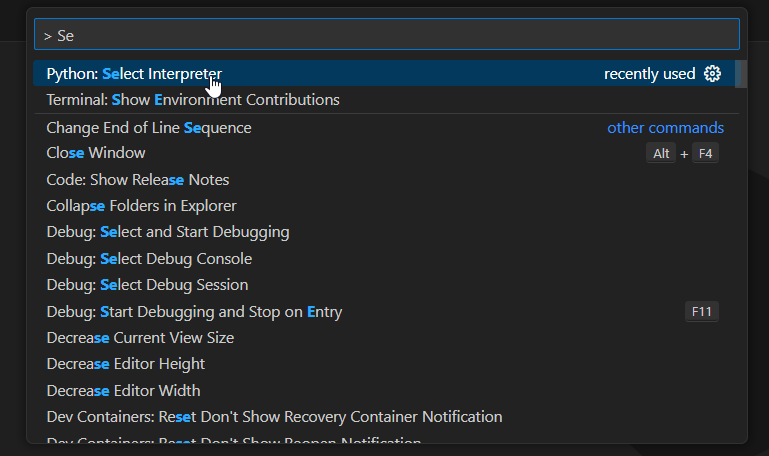
选择Python解释器,在命令输入框输入:
> Se,找到Python: Select Interpreter,选择venv_test虚拟环境。
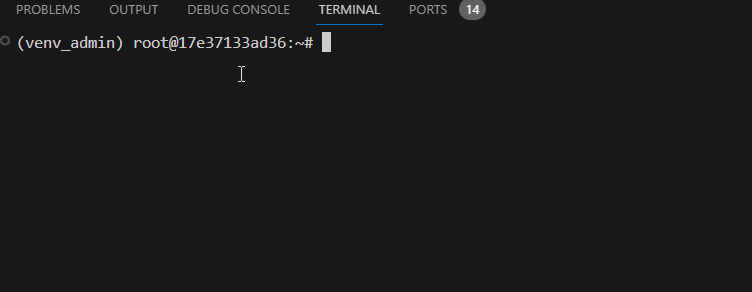
新建终端,确认默认进入
venv_test虚拟环境,说明环境搭建完毕。
2.1 核心组件功能说明(结合代码)
- 安装LangChain包
pip install langchain
pip install langchain_openai
- 配置Openai Key
import os
os.environ['OPENAI_API_KEY'] = ''
当前演示全部依赖如下:
langchain==0.3.12
langchain-community==0.3.12
langchain-core==0.3.25
langchain-openai==0.2.12
langgraph==0.2.59
langsmith==0.2.3
- 从Chat models开始

from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
messages = [
SystemMessage("将如下的文本内容翻译为英文。"),
HumanMessage("你好,世界。"),
]
print(model.invoke(messages).content)

为什么工具调用如此重要?思考如下示例:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
messages = [
SystemMessage("比较如下两个数字的大小。"),
HumanMessage("9.9和9.11"),
]
print(model.invoke(messages).content)

数值计算曾经是大模型的一大弱点,基本各大模型都在此问题翻车,但目前各家大模型都针对此问题做了优化。不过能力偏弱的模型,目前仍然会出错。那么应该如何解决?假设你使用了该模型,但又不得不面对这个场景?
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
class CompareInput(BaseModel):
num_1: float = Field(description="待比较的第一个数字")
num_2: float = Field(description="待比较的第二个数字")
@tool("compare", args_schema=CompareInput, return_direct=False)
def compare(num_1: float, num_2: float) -> str:
"""
比较两个数字的大小,num_1为第一个数字,num_2为第二个数字。
"""
print('调用compare工具')
return f'最大的数字是:{max(num_1, num_2)}'
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
model_with_tools = model.bind_tools([compare])
messages = [
SystemMessage("比较如下两个数字的大小。"),
HumanMessage("9.9和9.11"),
]
result = model_with_tools.invoke(messages)
for item in result.tool_calls:
print(item)
if item['name'] == 'compare':
print('二者最大的数字是:', max(item['args']['num_1'], item['args']['num_2']))

LLM绑定了工具后,经过推理,只是拿到了元数据,每次推理都要自己再解析元数据执行一遍逻辑吗?
想直接调用绑定的工具获取最终结果的方式:Agent。
如果我的需求不需要调用工具,只是需要复杂的逻辑推理及转换,应该使用什么:Chain。
- Chain
一个示例:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.documents import Document
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
documents = [
Document(page_content="Apples are red", metadata={"title": "apple_book"}),
Document(page_content="Blueberries are blue", metadata={"title": "blueberry_book"}),
Document(page_content="Bananas are yelow", metadata={"title": "banana_book"}),
]
prompt = ChatPromptTemplate.from_template("Summarize this content: {context}")
chain = create_stuff_documents_chain(model, prompt)
result = chain.invoke({"context": documents})
print(result)

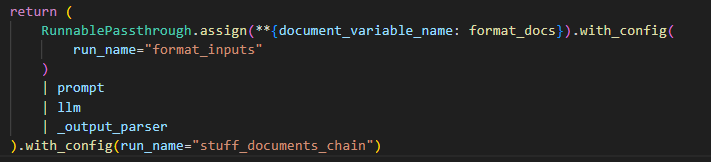
Chain的底层实现是什么?
- LCEL
LangChain的核心是Chain,即对多个组件的一系列调用。LCEL是LangChain 定义的表达式语言,是一种更加高效简洁的调用一系列组件的方式。LCEL使用方式就是:以一堆管道符("|")串联所有实现了Runnable接口的组件。
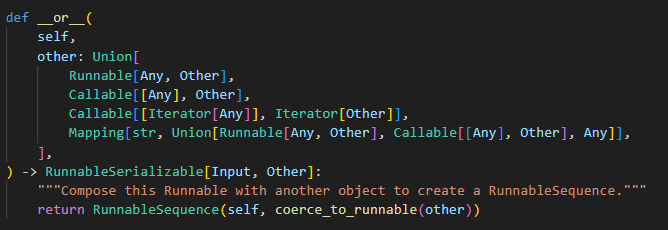
LangChain为了让组件能以LCEL的方式快速简洁的被调用,将所有组件都实现Runnable接口。比如我们常用的PromptTemplate 、LLMChain 、StructuredOutputParser 等等。
LangChain通过or将所有的Runnable串联起来,在通过invoke去一个个执行,上一个组件的输出,作为下一个组件的输入。
LCEL中有哪些重要的组成?RunnablePassthrough、RunnableParallel、RunnableBranch、RunnableLambda。
RunnablePassthrough 主要用在链中传递数据。RunnablePassthrough一般用在链的第一个位置,用于接收用户的输入。如果处在中间位置,则用于接收上一步的输出。
RunnableParallel看名字里的Parallel就猜到一二,用于并行执行多个组件。通过RunnableParallel,可以实现部分组件或所有组件并发执行的需求。
RunnableBranch主要用于多分支子链的场景,为链的调用提供了路由功能,这个有点类似于LangChain的路由链。我们可以创建多个子链,然后根据条件选择执行某一个子链。
RunnableLambda,它可以将Python 函数转换为 Runnable对象。这种转换使得任何函数都可以被看作 LCEL 链的一部分,我们把自己需要的功能通过自定义函数 + RunnableLambda的方式包装一下,集成到 LCEL 链中,这样算是可以跟任何外部系统打通了。
这里演示一下RunnableParallel的用法,其余的大家自行探索:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
from langchain_core.output_parsers import CommaSeparatedListOutputParser
import time
prompt_1 = ChatPromptTemplate.from_messages({
("system", "你是一个中国的高考志愿填报助手。"),
("human", "请你为一个高考600分的广东考生推荐三所大学,报考对应的计算机专业。")
})
prompt_2 = ChatPromptTemplate.from_messages({
("system", "你是水果糖分计算助手。"),
("human", "请你分别输出一个苹果和一个橙子的糖分。")
})
output_parser = CommaSeparatedListOutputParser()
parser_instructions = output_parser.get_format_instructions()
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
chain_1 = prompt_1 | model | output_parser
chain_2 = prompt_2 | model | output_parser
chain_parallel = RunnableParallel(exam=chain_1, fruit=chain_2)
print('------------------------------并行:')
start = time.time()
response = chain_parallel.invoke({"parser_instructions": parser_instructions})
print(response)
print(f'耗时:{time.time() - start}')
print('------------------------------非并行:')
start = time.time()
_ = chain_1.invoke({"parser_instructions": parser_instructions})
_ = chain_2.invoke({"parser_instructions": parser_instructions})
print(f'耗时:{time.time() - start}')

- Agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个数值比较助手,你需要比较用户指定的数字大小。"),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
@tool("compare", args_schema=CompareInput, return_direct=False)
def compare(num_1: float, num_2: float) -> str:
"""
比较两个数字的大小,num_1为第一个数字,num_2为第二个数字。
"""
print('调用compare工具')
return f'最大的数字是: {max(num_1, num_2)}'
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = create_openai_tools_agent(model, [compare], prompt)
executor = AgentExecutor(agent=agent, tools=[compare], return_intermediate_steps=False, max_iterations=2)
result = executor.invoke({"messages": [HumanMessage(content="比较如下两个数字的大小:9.9和9.11。")]})
print(result['output'])

如果我想显示的解析出第一个数字大还是第二个数字大该怎么处理?
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from pydantic import BaseModel, Field
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
class Maxnum(BaseModel):
"""最大的数字"""
max_num: float = Field(default=False, description="最大的数字")
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个数值比较助手,你需要比较用户指定的数字大小。"),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
@tool("compare", args_schema=CompareInput, return_direct=False)
def compare(num_1: float, num_2: float) -> str:
"""
比较两个数字的大小,num_1为第一个数字,num_2为第二个数字。
"""
print('调用compare工具')
return f'最大的数字是: {max(num_1, num_2)}'
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = create_openai_tools_agent(model, [compare], prompt)
executor = AgentExecutor(agent=agent, tools=[compare], return_intermediate_steps=False, max_iterations=2)
prompt_parse = """
System: 你是一个数字检测助手。
Human:请识别最大数字: {output}。
{format_instructions}
"""
output_parser = PydanticOutputParser(pydantic_object=Maxnum)
format_instructions = output_parser.get_format_instructions()
parse_prompt = PromptTemplate.from_template(prompt_parse).partial(format_instructions=format_instructions)
parse_chain = parse_prompt | model | output_parser
executor_chain = executor | parse_chain
result = executor_chain.invoke({"messages": [HumanMessage(content="比较如下两个数字的大小:9.9和9.11。请问最大的数字是?")]})
print(result.max_num)

Agent的优缺点分别是什么?如何改进?
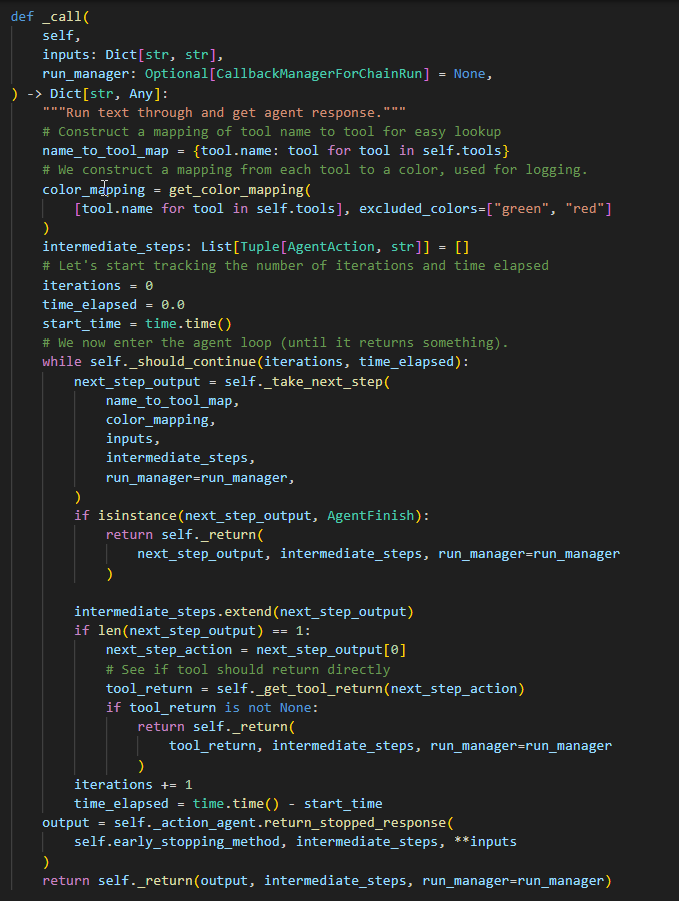
想象一个极端的案例,如果一个需求,需要支撑100个不同的场景,如果使用单一的Agent,Agent的提示词将会是怎样的?实际处理下来,它的准确率会是怎样的?
如果将场景分拆,不同的Agent之间如何串联?这些都是需要考虑的问题。
- LangGraph

from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
import operator
from typing import Annotated, Sequence, TypedDict
from langchain.output_parsers import PydanticOutputParser
from langchain_core.messages import BaseMessage, AIMessage
from pydantic import BaseModel, Field
from langgraph.graph import END, StateGraph
import functools
import warnings
warnings.filterwarnings("ignore")
# 准备测试文档
docs_list = [
Document(page_content="小红同学喜欢蓝色。"),
Document(page_content="小蓝同学喜欢黄色。"),
Document(page_content="小黄同学喜欢红色。")
]
# 构建检索器
knowledge_base_vec_store = FAISS.from_documents(docs_list, OpenAIEmbeddings(model="text-embedding-3-small"))
retriever = knowledge_base_vec_store.as_retriever(search_kwargs={"k": 3})
@tool
def search_from_faiss_info(query: str):
"""
这个工具用来查询指定同学喜欢的颜色。
"""
search_result = retriever.invoke(query)
print('调用search工具')
return search_result
tools = [search_from_faiss_info]
class CompareInput(BaseModel):
num_1: float = Field(description="待比较的第一个数字")
num_2: float = Field(description="待比较的第二个数字")
@tool("compare", args_schema=CompareInput, return_direct=False)
def compare(num_1: float, num_2: float) -> str:
"""
比较两个数字的大小,num_1为第一个数字,num_2为第二个数字。
"""
print('调用compare工具')
return f'最大的数字是: {max(num_1, num_2)}'
tools_2 = [compare]
# 公共的创建agent函数
def create_agent(llm, tools, system_prompt):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_prompt,
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_tools_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools, return_intermediate_steps=True, max_iterations=5)
return executor
# 创建监督者
def create_supervisor_chain(members):
system_prompt = (
"你是一个问答助手,可用的代理如下:{members}。"
" search_agent擅长查找同学喜欢的颜色,compare_agent擅长比较数值大小。"
" 你需要根据用户的问题,来选择适当的代理。"
" 比如用户的问题是查找某个同学喜欢的颜色,如果代理找到对应信息,则你应该结束当前对话。"
" 不可以针对同一个问题重复调用代理。"
" 当你判断答案合理,可以结束对话, 返回 FINISH."
)
options = ["FINISH"] + members
function_def = {
"name": "route",
"description": "Select the next role.",
"parameters": {
"title": "routeSchema",
"type": "object",
"properties": {
"next": {
"title": "Next",
"anyOf": [
{"enum": options},
],
}
},
"required": ["next"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"给定上面的对话,我们接下来应该选择哪个动作?或者结束对话?"
" 从如下选项选择一个: {options}."
),
]
).partial(options=str(options), members=", ".join(members))
supervisor_chain = (
prompt
| model.bind_functions(functions=[function_def], function_call="route")
| JsonOutputFunctionsParser()
)
return supervisor_chain
# 状态记事本
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
# 创建agent节点
def agent_node(state, agent):
result = agent.invoke(state)
return {"messages": [AIMessage(content=result["output"])]}
# 创建graph
workflow = StateGraph(AgentState)
supervisor_agent = create_supervisor_chain(["search_agent", "compare_agent"])
def router_forward(state):
if state["next"] == "FINISH":
return "FINISH"
else:
return state["next"]
searc_node = functools.partial(agent_node, agent=create_agent(model, tools, "你是一个信息检索助手,你非常擅长查找指定同学喜欢的颜色,对于用户指定的同学,你需要查找他喜欢的颜色信息。"))
compare_node = functools.partial(agent_node, agent=create_agent(model, tools_2, "你是一个数字比较助手,你非常擅长比较数字的大小,对于用户给出的待比较的两个数字,你需要调用工具来进行大小比较。"))
workflow.add_node("supervisor_agent", supervisor_agent)
workflow.add_node("search_agent", searc_node)
workflow.add_node("compare_agent", compare_node)
map_forward = {"FINISH": END, "search_agent": "search_agent", "compare_agent": "compare_agent"}
workflow.add_conditional_edges("supervisor_agent", router_forward, map_forward)
workflow.add_edge("search_agent", "supervisor_agent")
workflow.set_entry_point("supervisor_agent")
graph = workflow.compile()
print(graph.invoke({"messages": [HumanMessage(content="小红同学喜欢什么颜色?")]})['messages'][-1].content)
print(graph.invoke({"messages": [HumanMessage(content="9.9和9.11哪个大?")]})['messages'][-1].content)

如何debug?当前开发的代码,内部如何执行的,对开发者而言,如果不打印每个过程的日志,基本就是一个黑盒,出问题了难以排查。
- LangSmith

os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = "https://api.smith.langchain.com"
os.environ['LANGCHAIN_API_KEY'] = "你的key"
os.environ['LANGCHAIN_PROJECT'] = "你的项目名"
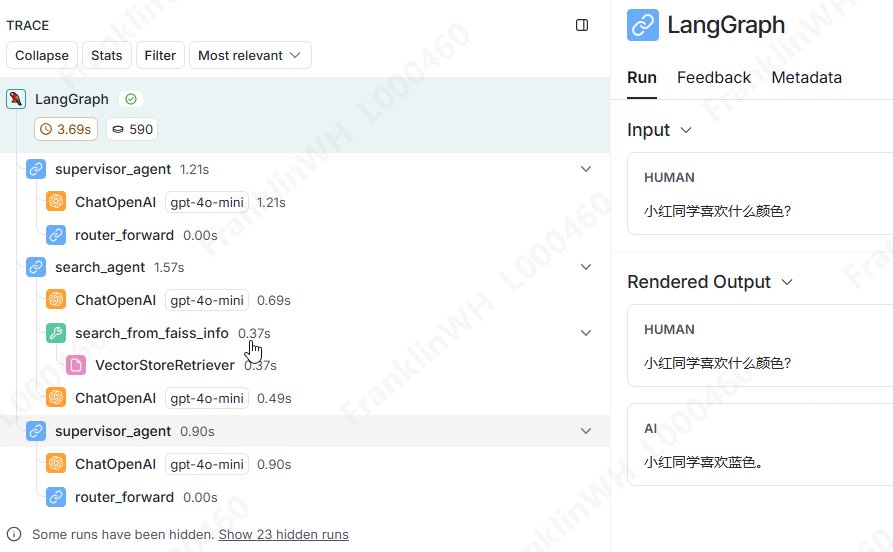
2.2 完成一个你想要完成的简单应用
自行完成。

