3-2中阶API示范
- 下面的范例使用Pytorch的低阶API实现线性回归和DNN二分类
- Pytorch的中阶API主要包括各种模型层,损失函数,优化器,数据管道等。
import os
import datetime
# 打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('\n' + '========='*8 + '%s' % nowtime)
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
# os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
print('torch.__version__=' + torch.__version__)
"""
torch.__version__=2.1.1+cu118
"""
1.线性回归模型
# 准备数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader, TensorDataset
#样本数量
n = 400
# 生成测试用数据集
X = 10*torch.rand([n,2])-5.0 #torch.rand是均匀分布
w0 = torch.tensor([[2.0],[-3.0]])
b0 = torch.tensor([[10.0]])
Y = X@w0 + b0 + torch.normal( 0.0,2.0,size = [n,1]) # @表示矩阵乘法,增加正态扰动
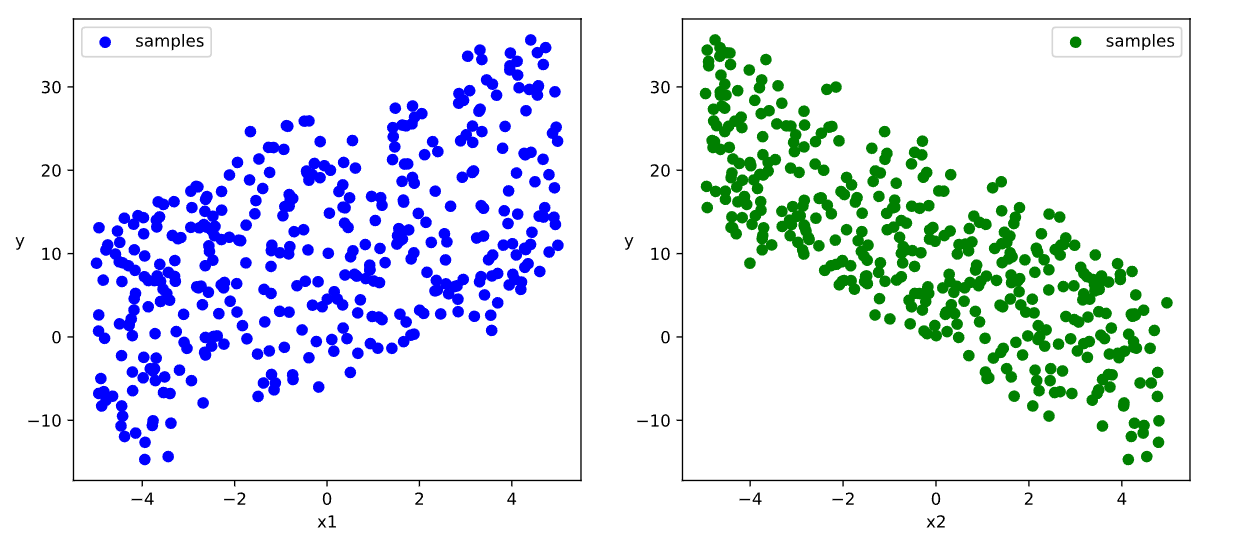
# 数据可视化
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
plt.figure(figsize = (12,5))
ax1 = plt.subplot(121)
ax1.scatter(X[:,0],Y[:,0], c = "b",label = "samples")
ax1.legend()
plt.xlabel("x1")
plt.ylabel("y",rotation = 0)
ax2 = plt.subplot(122)
ax2.scatter(X[:,1],Y[:,0], c = "g",label = "samples")
ax2.legend()
plt.xlabel("x2")
plt.ylabel("y",rotation = 0)
plt.show()
# 构建输入数据管道
ds = TensorDataset(X, Y)
dl = DataLoader(ds, batch_size=10, shuffle=True, num_workers=2)
# 定义模型
model = nn.Linear(2, 1)
model.loss_fn = nn.MSELoss()
model.optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
def train_step(model, features, labels):
predictions = model(features)
loss = model.loss_fn(predictions, labels)
loss.backward()
model.optimizer.step()
model.optimizer.zero_grad()
return loss.item()
# 测试train_step效果
features, labels = next(iter(dl))
train_step(model, features, labels)
def train_model(model, epochs):
for epoch in range(1, epochs+1):
for features, labels in dl:
loss = train_step(model, features, labels)
if epoch % 10 == 0:
printbar()
w = model.state_dict()['weight']
b = model.state_dict()['bias']
print("epoch =",epoch,"loss = ",loss)
print("w =",w)
print("b =",b)
train_model(model,epochs = 50)
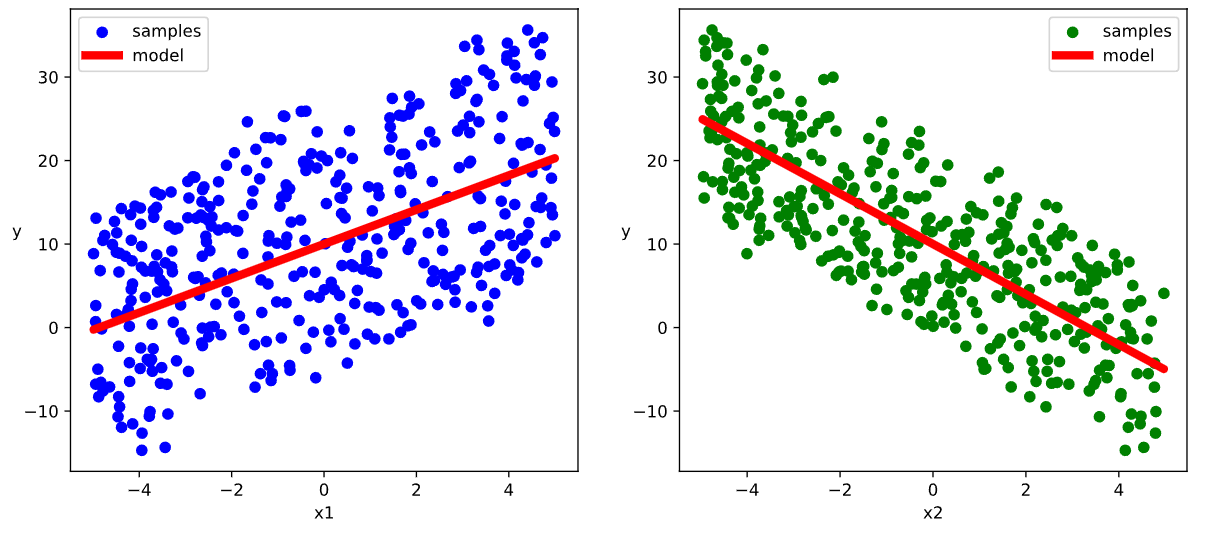
# 结果可视化
%matplotlib inline
%config InlineBackend.figure_format='svg'
plt.figure(figsize = (12,5))
ax1 = plt.subplot(121)
ax1.scatter(X[:,0].numpy(),Y[:,0].numpy(), c = "b",label = "samples")
ax1.plot(X[:,0].numpy(),(model.w[0].data*X[:,0]+model.b[0].data).numpy(),"-r",linewidth = 5.0,label = "model")
ax1.legend()
plt.xlabel("x1")
plt.ylabel("y",rotation = 0)
ax2 = plt.subplot(122)
ax2.scatter(X[:,1].numpy(),Y[:,0].numpy(), c = "g",label = "samples")
ax2.plot(X[:,1].numpy(),(model.w[1].data*X[:,1]+model.b[0].data).numpy(),"-r",linewidth = 5.0,label = "model")
ax2.legend()
plt.xlabel("x2")
plt.ylabel("y",rotation = 0)
plt.show()
2.DNN二分类模型
# 准备数据
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader,TensorDataset
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
#正负样本数量
n_positive,n_negative = 2000,2000
#生成正样本, 小圆环分布
r_p = 5.0 + torch.normal(0.0,1.0,size = [n_positive,1])
theta_p = 2*np.pi*torch.rand([n_positive,1])
Xp = torch.cat([r_p*torch.cos(theta_p),r_p*torch.sin(theta_p)],axis = 1)
Yp = torch.ones_like(r_p)
#生成负样本, 大圆环分布
r_n = 8.0 + torch.normal(0.0,1.0,size = [n_negative,1])
theta_n = 2*np.pi*torch.rand([n_negative,1])
Xn = torch.cat([r_n*torch.cos(theta_n),r_n*torch.sin(theta_n)],axis = 1)
Yn = torch.zeros_like(r_n)
#汇总样本
X = torch.cat([Xp,Xn],axis = 0)
Y = torch.cat([Yp,Yn],axis = 0)
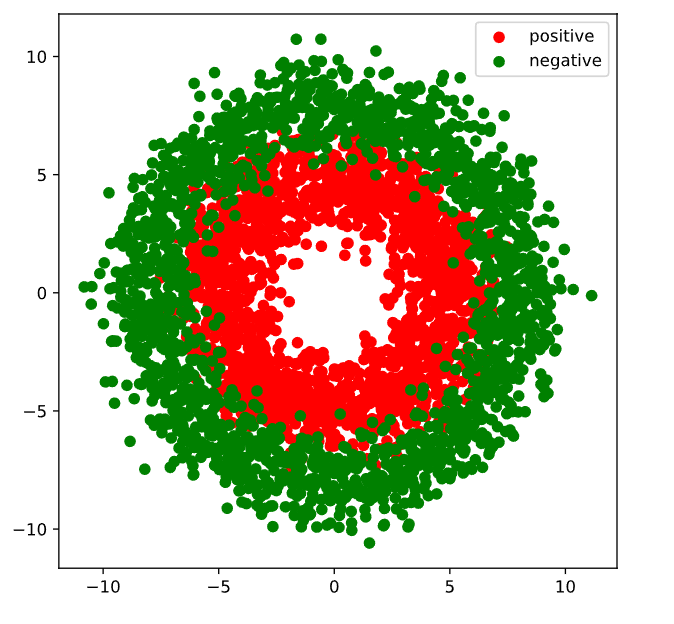
#可视化
plt.figure(figsize = (6,6))
plt.scatter(Xp[:,0],Xp[:,1],c = "r")
plt.scatter(Xn[:,0],Xn[:,1],c = "g")
plt.legend(["positive","negative"]);
# 构建输入数据管道
ds = TensorDataset(X, Y)
dl = DataLoader(ds, batch_size=10, shuffle=True, num_workers=2)
# 定义模型
class DNNModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(2, 4)
self.fc2 = nn.Linear(4, 8)
self.fc3 = nn.Linear(8, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
y = nn.Sigmoid()(self.fc3(x))
return y
def loss_fn(self, y_pred, y_true):
return nn.BCELoss()(y_pred, y_true)
def metric_fn(self, y_pred, y_true):
y_pred = torch.where(y_pred > 0.5, torch.ones_like(y_pred, dtype=torch.float32),
torch.zeros_like(y_pred, dtype=torch.float32))
acc = torch.mean(1 - torch.abs(y_true - y_pred))
return acc
@property
def optimizer(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
model = DNNModel()
# 测试模型结构
features, labels = next(iter(dl))
predictions = model(features)
loss = model.loss_fn(predictions, labels)
metric = model.metric_fn(predictions, labels)
print('init loss:', loss.item())
print('init metric:', metric.item())
"""
init loss: 0.7185380458831787
init metric: 0.6000000238418579
"""
# 训练模型
def train_step(model, features, labels):
# 正向传播求损失
predictions = model(features)
loss = model.loss_fn(predictions,labels)
metric = model.metric_fn(predictions,labels)
# 反向传播求梯度
loss.backward()
# 更新模型参数
model.optimizer.step()
model.optimizer.zero_grad()
return loss.item(),metric.item()
def train_model(model,epochs):
for epoch in range(1,epochs+1):
loss_list,metric_list = [],[]
for features, labels in dl:
lossi,metrici = train_step(model,features,labels)
loss_list.append(lossi)
metric_list.append(metrici)
loss = np.mean(loss_list)
metric = np.mean(metric_list)
if epoch % 10 == 0:
printbar()
print("epoch =",epoch,"loss = ",loss,"metric = ",metric)
train_model(model,epochs = 50)
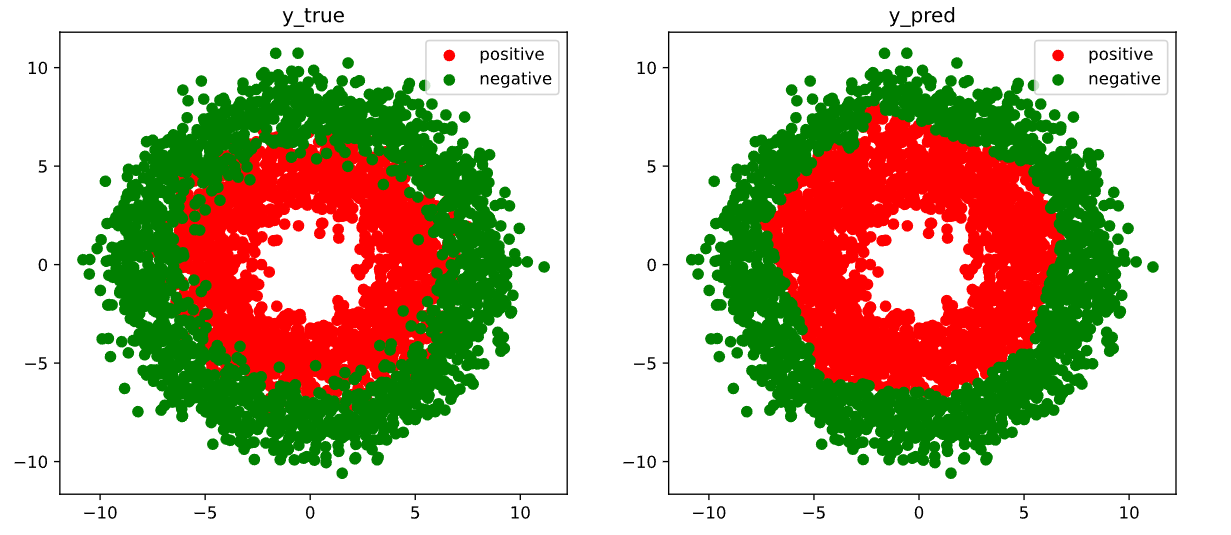
# 结果可视化
fig, (ax1,ax2) = plt.subplots(nrows=1,ncols=2,figsize = (12,5))
ax1.scatter(Xp[:,0],Xp[:,1], c="r")
ax1.scatter(Xn[:,0],Xn[:,1],c = "g")
ax1.legend(["positive","negative"]);
ax1.set_title("y_true");
Xp_pred = X[torch.squeeze(model.forward(X)>=0.5)]
Xn_pred = X[torch.squeeze(model.forward(X)<0.5)]
ax2.scatter(Xp_pred[:,0],Xp_pred[:,1],c = "r")
ax2.scatter(Xn_pred[:,0],Xn_pred[:,1],c = "g")
ax2.legend(["positive","negative"]);
ax2.set_title("y_pred");
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/18055379
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
标签:
Pytorch




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧