1-3文本数据建模流程范例
0.配置
import os
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
# os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
!pip install torchmetrics
import torch
import torchvision
import torchkeras
import torchmetrics
import gensim
print('torch', torch.__version__)
print('torchvision', torchvision.__version__)
print('torchkeras', torchkeras.__version__)
print('torchmetrics', torchmetrics.__version__)
print(gensim.__version__)
"""
torch 2.1.1+cu118
torchvision 0.16.1+cu118
torchkeras 3.9.4
torchmetrics 1.2.1
4.3.2
"""
1.准备数据
imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签。
训练集有20000条电影评论文本,测试集有5000条电影评论文本,其中正面评论和负面评论都各占一半。
文本数据预处理较为繁琐,包括文本切词,构建词典,编码转换,序列填充,构建数据管道等等。
此处使用gensim中的词典工具并自定义Dataset。
下面进行演示。

import numpy as np
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
MAX_LEN = 200
BATCH_SIZE = 20
df = pd.read_csv('./dataset/imdb/IMDB Dataset.csv')
df.columns = ['text', 'label']
df['label'] = df['label'].apply(lambda x: 1 if x == 'positive' else 0)
dftrain, dfval = train_test_split(df, test_size=0.2, random_state=42)
from gensim import corpora
import string
# 文本切词
def textsplit(text):
translator = str.maketrans('', '', string.punctuation)
words = text.translate(translator).split(' ')
return words
# 构建词典
vocab = corpora.Dictionary((textsplit(text) for text in dftrain['text']))
vocab.filter_extremes(no_below=5, no_above=5000)
special_tokens = {'<pad>': 0, '<unk>': 1}
vocab.patch_with_special_tokens(special_tokens)
vocab_size = len(vocab.token2id)
print('vocab_size= ', vocab_size)
"""
vocab_size= 43536
"""
# 序列填充
def pad(seq, max_length, pad_value=0):
result = seq + [pad_value] * max_length
return result[: max_length]
# 编码转换
def text_pipeline(text):
tokens = vocab.doc2idx(textsplit(text))
tokens = [x if x > 0 else special_tokens['<unk>'] for x in tokens]
result = pad(tokens, MAX_LEN, special_tokens['<pad>'])
return result
print(text_pipeline('this is an example!'))
"""
[236, 137, 277, 917, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"""
# 构建管道
class ImdbDataset(torch.utils.data.Dataset):
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, index):
text = self.df['text'].iloc[index]
label = torch.tensor([self.df['label'].iloc[index]]).float()
tokens = torch.tensor(text_pipeline(text)).int()
return tokens, label
ds_train = ImdbDataset(dftrain)
ds_val = ImdbDataset(dfval)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=50, shuffle=True)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=50, shuffle=True)
for features, labels in dl_train:
print(features)
print(labels)
break
"""
tensor([[ 23, 104, 137, ..., 793, 52, 5624],
[ 4235, 137, 179, ..., 14696, 176, 139],
[ 2083, 1644, 8, ..., 0, 0, 0],
...,
[ 1281, 601, 229, ..., 0, 0, 0],
[11553, 28, 13202, ..., 86, 1168, 227],
[ 834, 119, 4277, ..., 438, 1121, 580]], dtype=torch.int32)
tensor([[1.],
[0.],
[0.],
[0.],
[1.],
[0.],
[1.],
[0.],
[0.],
[1.],
[0.],
[1.],
[0.],
[0.],
[1.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[1.],
[0.],
[0.],
[1.],
[0.],
[1.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[1.]])
"""
2.定义模型
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器
(nn.Sequential,nn.ModuleList,nn.ModuleDict)进行封装。
此处选择使用第三种方式构建
import torch
from torch import nn
torch.manual_seed(42)
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# 设置padding_idx参数后,将在训练过程中将填充的token始终赋值为0向量
self.embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=3, padding_idx=0)
self.conv = torch.nn.Sequential()
self.conv.add_module('conv_1', torch.nn.Conv1d(in_channels=3, out_channels=16, kernel_size=5))
self.conv.add_module('pool_1', torch.nn.MaxPool1d(kernel_size=2))
self.conv.add_module('relu_1', torch.nn.ReLU())
self.conv.add_module('conv_2', torch.nn.Conv1d(in_channels=16, out_channels=128, kernel_size=2))
self.conv.add_module('pool_2', torch.nn.MaxPool1d(kernel_size=2))
self.conv.add_module('relu_2', torch.nn.ReLU())
self.dense = torch.nn.Sequential()
self.dense.add_module('flatten', torch.nn.Flatten())
self.dense.add_module('linear', torch.nn.Linear(6144, 1)) # 3*16*128
def forward(self, x):
x = self.embedding(x).transpose(1, 2)
x = self.conv(x)
y = self.dense(x)
return y
net = Net()
print(net)
"""
Net(
(embedding): Embedding(43536, 3, padding_idx=0)
(conv): Sequential(
(conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
(pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_1): ReLU()
(conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
(pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_2): ReLU()
)
(dense): Sequential(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear): Linear(in_features=6144, out_features=1, bias=True)
)
)
"""
from torchkeras import summary
print(summary(net, input_data=features))
"""
--------------------------------------------------------------------------
Layer (type) Output Shape Param #
==========================================================================
Embedding-1 [-1, 200, 3] 130,608
Conv1d-2 [-1, 16, 196] 256
MaxPool1d-3 [-1, 16, 98] 0
ReLU-4 [-1, 16, 98] 0
Conv1d-5 [-1, 128, 97] 4,224
MaxPool1d-6 [-1, 128, 48] 0
ReLU-7 [-1, 128, 48] 0
Flatten-8 [-1, 6144] 0
Linear-9 [-1, 1] 6,145
==========================================================================
Total params: 141,233
Trainable params: 141,233
Non-trainable params: 0
--------------------------------------------------------------------------
Input size (MB): 0.000076
Forward/backward pass size (MB): 0.287788
Params size (MB): 0.538761
Estimated Total Size (MB): 0.826626
--------------------------------------------------------------------------
"""
3.训练模型
Pytorch通常需要用户编写自定义的训练循环,训练循环的代码风格因人而异。
有三种典型的训练循环代码风格:脚本形式训练循环,函数形式训练循环,类形式训练循环。
此处介绍一种较为通用的仿照Keras风格的函数形式的训练循环。
import os
import sys
import time
import numpy as np
import pandas as pd
import datetime
from tqdm import tqdm
import torch
from copy import deepcopy
def printlog(info):
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n" + "===========" * 8 + "%s" % nowtime)
print(str(info) + "\n")
class StepRunner:
def __init__(self, net, loss_fn, stage='train', metrics_dict=None, optimizer=None, lr_scheduler=None):
self.net, self.loss_fn, self.metrics_dict, self.stage = net, loss_fn,metrics_dict, stage
self.optimizer, self.lr_scheduler = optimizer, lr_scheduler
def __call__(self, features, labels):
# loss
preds = self.net(features)
loss = self.loss_fn(preds, labels)
# backward
if self.optimizer is not None and self.stage == 'train':
loss.backward()
self.optimizer.step()
if self.lr_scheduler is not None:
self.lr_scheduler.step()
self.optimizer.zero_grad()
# metrics
step_metrics = {self.stage + "_" + name: metric_fn(preds, labels).item() for name, metric_fn in self.metrics_dict.items()}
return loss.item(), step_metrics
class EpochRunner:
def __init__(self, steprunner):
self.steprunner = steprunner
self.stage = steprunner.stage
self.steprunner.net.train() if self.stage == 'train' else self.steprunner.net.eval()
def __call__(self, dataloader):
total_loss, step = 0, 0
loop = tqdm(enumerate(dataloader), total=len(dataloader))
for i, batch in loop:
if self.stage == 'train':
loss, step_metrics = self.steprunner(*batch)
else:
with torch.no_grad():
loss, step_metrics = self.steprunner(*batch)
step_log = dict({self.stage + "_loss": loss}, **step_metrics)
total_loss += loss
step += 1
if i != len(dataloader) - 1:
loop.set_postfix(**step_log)
else:
epoch_loss = total_loss / step
epoch_metrics = {self.stage + "_" + name: metric_fn.compute().item() for name, metric_fn in self.steprunner.metrics_dict.items()}
epoch_log = dict({self.stage + "_loss": epoch_loss}, **epoch_metrics)
loop.set_postfix(**epoch_log)
for name, metric_fn in self.steprunner.metrics_dict.items():
metric_fn.reset()
return epoch_log
class KerasModel(torch.nn.Module):
def __init__(self, net, loss_fn, metrics_dict=None, optimizer=None, lr_scheduler=None):
super().__init__()
self.history = {}
self.net = net
self.loss_fn = loss_fn
self.metrics_dict = torch.nn.ModuleDict(metrics_dict)
self.optimizer = optimizer if optimizer is not None else torch.optim.Adam(self.parameters(), lr=1e-2)
self.lr_scheduler = lr_scheduler
def forward(self, x):
if self.net:
return self.net.forward(x)
else:
raise NotImplementedError
def fit(self, train_data, val_data=None, epochs=10, ckpt_path='checkpoint.pt', patience=5, monitor='val_loss', mode='min'):
for epoch in range(1, epochs+1):
printlog('Epoch {0} / {1}'.format(epoch, epochs))
# train
train_step_runner = StepRunner(net=self.net, stage='train', loss_fn=self.loss_fn,
metrics_dict=deepcopy(self.metrics_dict), optimizer=self.optimizer, lr_scheduler=self.lr_scheduler)
train_epoch_runner = EpochRunner(train_step_runner)
train_metrics = train_epoch_runner(train_data)
for name, metric in train_metrics.items():
self.history[name] = self.history.get(name, []) + [metric]
# validate
if val_data:
val_step_runner = StepRunner(net=self.net, stage='val', loss_fn=self.loss_fn, metrics_dict=deepcopy(self.metrics_dict))
val_epoch_runner = EpochRunner(val_step_runner)
with torch.no_grad():
val_metrics = val_epoch_runner(val_data)
val_metrics['epoch'] = epoch
for name, metric in val_metrics.items():
self.history[name] = self.history.get(name, []) + [metric]
# early-stopping
if not val_data:
continue
arr_scores = self.history[monitor]
best_score_idx = np.argmax(arr_scores) if mode == 'max' else np.argmin(arr_scores)
if best_score_idx == len(arr_scores) - 1:
torch.save(self.net.state_dict(), ckpt_path)
print('<<<<<< reach best {0} : {1} >>>>>>>'.format(monitor, arr_scores[best_score_idx]), file=sys.stderr)
if len(arr_scores) - best_score_idx > patience:
print("<<<<<< {} without improvement in {} epoch, early stopping >>>>>>".format(
monitor,patience),file=sys.stderr)
break
self.net.load_state_dict(torch.load(ckpt_path))
return pd.DataFrame(self.history)
@torch.no_grad()
def evaluate(self, val_data):
val_setp_runner = StepRunner(net=self.net, stage='val', loss_fn=self.loss_fn, metrics_dict=deepcopy(self.metrics_dict))
val_epoch_runner = EpochRunner(val_setp_runner)
val_metrics = val_epoch_runner(val_data)
return val_metrics
@torch.no_grad()
def predict(self, dataloader):
self.net.eval()
result = torch.cat([self.forward(t[0]) for t in dataloader])
return result.data
from torchmetrics import Accuracy
net = Net()
model = KerasModel(net, loss_fn=torch.nn.BCEWithLogitsLoss(), optimizer=torch.optim.Adam(net.parameters(), lr=0.001),
metrics_dict={'acc': Accuracy(task='binary')})
model.fit(dl_train, val_data=dl_val, epochs=10, ckpt_path='checkpoint.pt', patience=3, monitor='val_acc', mode='max')
"""
========================================================================================2023-12-19 22:49:05
Epoch 1 / 10
100%|██████████████████████████████████████████████| 800/800 [00:11<00:00, 72.25it/s, train_acc=0.561, train_loss=0.68]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 109.23it/s, val_acc=0.654, val_loss=0.626]
<<<<<< reach best val_acc : 0.65420001745224 >>>>>>>
========================================================================================2023-12-19 22:49:18
Epoch 2 / 10
100%|█████████████████████████████████████████████| 800/800 [00:11<00:00, 72.31it/s, train_acc=0.709, train_loss=0.562]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 111.48it/s, val_acc=0.736, val_loss=0.528]
<<<<<< reach best val_acc : 0.7360000014305115 >>>>>>>
========================================================================================2023-12-19 22:49:31
Epoch 3 / 10
100%|███████████████████████████████████████████████| 800/800 [00:10<00:00, 72.78it/s, train_acc=0.79, train_loss=0.45]
100%|█████████████████████████████████████████████████| 200/200 [00:01<00:00, 111.92it/s, val_acc=0.79, val_loss=0.451]
<<<<<< reach best val_acc : 0.7901999950408936 >>>>>>>
========================================================================================2023-12-19 22:49:44
Epoch 4 / 10
100%|█████████████████████████████████████████████| 800/800 [00:11<00:00, 72.48it/s, train_acc=0.831, train_loss=0.379]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 110.80it/s, val_acc=0.813, val_loss=0.417]
<<<<<< reach best val_acc : 0.8134999871253967 >>>>>>>
========================================================================================2023-12-19 22:49:57
Epoch 5 / 10
100%|██████████████████████████████████████████████| 800/800 [00:10<00:00, 73.79it/s, train_acc=0.858, train_loss=0.33]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 110.44it/s, val_acc=0.826, val_loss=0.395]
<<<<<< reach best val_acc : 0.8259999752044678 >>>>>>>
========================================================================================2023-12-19 22:50:09
Epoch 6 / 10
100%|██████████████████████████████████████████████| 800/800 [00:10<00:00, 72.91it/s, train_acc=0.878, train_loss=0.29]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 109.23it/s, val_acc=0.829, val_loss=0.395]
<<<<<< reach best val_acc : 0.8289999961853027 >>>>>>>
========================================================================================2023-12-19 22:50:22
Epoch 7 / 10
100%|█████████████████████████████████████████████| 800/800 [00:11<00:00, 72.69it/s, train_acc=0.897, train_loss=0.252]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 111.86it/s, val_acc=0.831, val_loss=0.398]
<<<<<< reach best val_acc : 0.8312000036239624 >>>>>>>
========================================================================================2023-12-19 22:50:35
Epoch 8 / 10
100%|█████████████████████████████████████████████| 800/800 [00:10<00:00, 74.63it/s, train_acc=0.912, train_loss=0.221]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 114.48it/s, val_acc=0.834, val_loss=0.408]
<<<<<< reach best val_acc : 0.8337000012397766 >>>>>>>
========================================================================================2023-12-19 22:50:48
Epoch 9 / 10
100%|█████████████████████████████████████████████| 800/800 [00:11<00:00, 72.70it/s, train_acc=0.926, train_loss=0.191]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 110.50it/s, val_acc=0.832, val_loss=0.445]
========================================================================================2023-12-19 22:51:00
Epoch 10 / 10
100%|█████████████████████████████████████████████| 800/800 [00:11<00:00, 72.22it/s, train_acc=0.939, train_loss=0.163]
100%|████████████████████████████████████████████████| 200/200 [00:01<00:00, 110.25it/s, val_acc=0.832, val_loss=0.453]
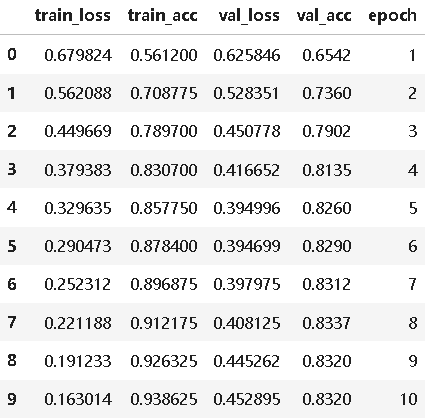
train_loss train_acc val_loss val_acc epoch
0 0.679824 0.561200 0.625846 0.6542 1
1 0.562088 0.708775 0.528351 0.7360 2
2 0.449669 0.789700 0.450778 0.7902 3
3 0.379383 0.830700 0.416652 0.8135 4
4 0.329635 0.857750 0.394996 0.8260 5
5 0.290473 0.878400 0.394699 0.8290 6
6 0.252312 0.896875 0.397975 0.8312 7
7 0.221188 0.912175 0.408125 0.8337 8
8 0.191233 0.926325 0.445262 0.8320 9
9 0.163014 0.938625 0.452895 0.8320 10
"""
4.评估模型
import pandas as pd
history = model.history
dfhistory = pd.DataFrame(history)
dfhistory
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory["train_"+metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory, 'loss')

plot_metric(dfhistory, 'acc')

# 评估
model.evaluate(dl_val)
"""
{'val_loss': 0.40812516428530216, 'val_acc': 0.8337000012397766}
"""
5.使用模型
def predict(net, dl):
net.eval()
with torch.no_grad():
result = torch.nn.Sigmoid()(torch.cat([net.forward(t[0]) for t in dl]))
return result.data
# 预测概率
y_pred_probs = predict(net, dl_val)
y_pred_probs
"""
tensor([[0.0116],
[0.2019],
[0.9939],
...,
[0.9908],
[0.9375],
[0.5256]])
"""
6.保存模型
net_clone = Net()
net_clone.load_state_dict(torch.load('checkpoint.pt'))
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/17915080.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
标签:
Pytorch




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧