12-LSTM多变量-定义&训练模型
import math
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense, LSTM
# 转换成有监督数据
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): # n_in, n_out相当于lag
n_vars = 1 if type(data) is list else data.shape[1] # 变量个数
df = pd.DataFrame(data)
print('待转换数据')
print(df.head())
cols, names = [], []
# 输入序列(t-n, ..., t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
print('shift数据')
print(cols[0][:5])
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
print('names数据')
print(names[:5])
# 预测序列(t, t+1, ..., t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0: # t时刻
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# 拼接
agg = pd.concat(cols, axis=1)
print('拼接')
print(agg[:5])
agg.columns = names
# 将空值NaN行删除
if dropnan:
agg.dropna(inplace=True)
return agg
# 数据预处理
dataset = pd.read_csv('../LSTM系列/LSTM多变量3/data_set/pollution.csv', header=0, index_col=0)
values = dataset.values
# 标签编码
encoder = LabelEncoder()
values[:, 4] = encoder.fit_transform(values[:, 4])
# 转换float
values = values.astype(np.float32)
# 归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(values)
# 转换成有监督数据
reframed = series_to_supervised(scaled, 1, 1)
# 删除不预测的列
reframed.drop(reframed.columns[[9, 10, 11, 12, 13, 14, 15]], axis=1, inplace=True)
print(reframed.head())
# 数据准备
# 把数据分为训练数据和测试数据
values = reframed.values
# 拿一年的时间长度训练
n_train_hours = 365 * 24
# 划分训练数据和测试数据
train = values[:n_train_hours, :]
test = values[n_train_hours:, :]
# 拆分输入输出
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# reshape输入为LSTM的输入格式
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print('train_X.shape, train_y.shape, test_X.shape, test_y.shape')
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
# 模型定义
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
model.compile(loss='mae', optimizer='adam')
print(model.summary())
# 模型训练
history = model.fit(train_X, train_y, epochs=5, batch_size=72, validation_data=(test_X, test_y), verbose=2, shuffle=False)
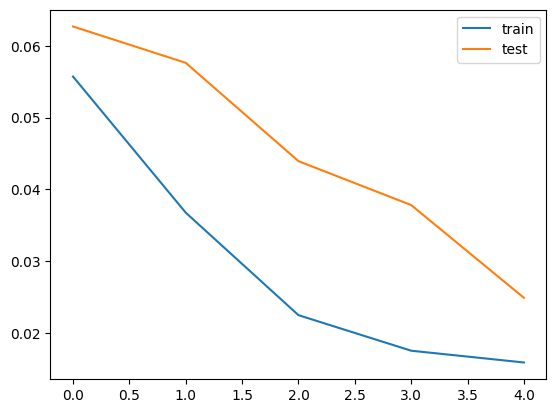
# 输出plot history
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
# 进行预测
yhat = model.predict(test_X)
test_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))
# 预测数据逆缩放
inv_yhat = np.concatenate((yhat, test_X[:, 1:]), axis=1)
inv_yhat = scaler.inverse_transform(inv_yhat)
inv_yhat = inv_yhat[:, 0]
inv_yhat = np.array(inv_yhat)
# 真实数据逆缩放
test_y = test_y.reshape((len(test_y), 1))
inv_y = np.concatenate((test_y, test_X[:, 1:]), axis=1)
inv_y = scaler.inverse_transform(inv_y)
inv_y = inv_y[:, 0]
# 画出真实数据和预测数据
plt.plot(inv_yhat, label='prediction')
plt.plot(inv_y, label='true')
plt.legend()
plt.show()
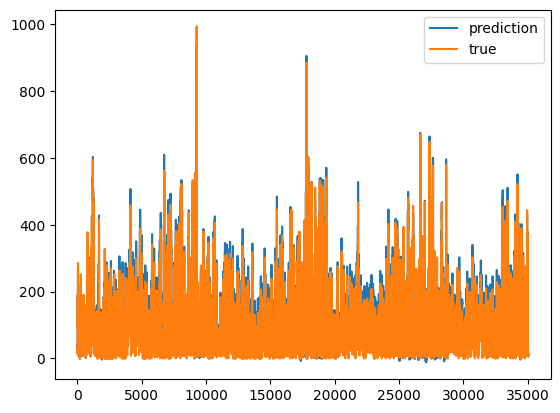
# 计算RMSE
rmse = math.sqrt(mean_squared_error(inv_y, inv_yhat))
print('Test RMSE: %.3f' % rmse)
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/17103804.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧