1-香皂销售预测
import pandas as pd
from sklearn.metrics import mean_squared_error
import math
import matplotlib.pyplot as plt
import datetime
# 加载数据
def parser(x):
return datetime.datetime.strptime(x, '%Y/%m/%d')
ser = pd.read_csv('../LSTM系列/LSTM单变量1/data_set/shampoo-sales.csv',
header=0, parse_dates=[0], index_col=0, date_parser=parser).squeeze('columns')
# 分成训练集和测试集合,前24行给训练集,后12行给测试集
X = ser.values
train, test = X[:-12], X[-12:]
history = [x for x in train]
predictions = []
for i in range(len(test)):
predictions.append(history[-1]) # history[-1],就是执行预测,这里我们只是假设predictions数组就是我们预测的结果
history.append(test[i]) # 将新的测试数据加入模型
# 预测效果评估
rmse = math.sqrt(mean_squared_error(test, predictions))
print('RMSE:%.3f' % rmse)
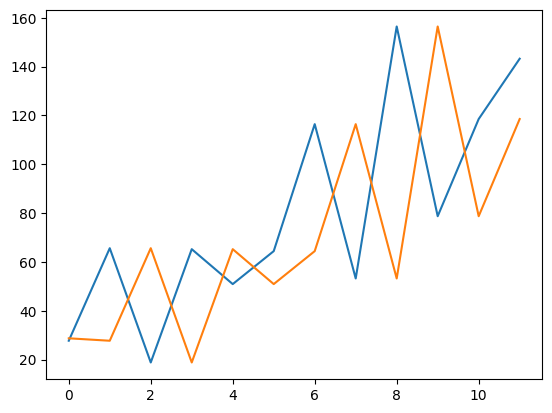
# 画出预测+观测值
plt.plot(test)
plt.plot(predictions)
plt.show()
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/17103759.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧