1-4时间序列数据建模流程范例——eat_tensorflow2_in_30_days
1-4时间序列数据建模流程范例#
本篇文章将利用TensorFlow2.0建立时间序列RNN模型,对国内的新冠肺炎疫情结束时间进行预测。
准备数据#
本文的数据集取自tushare,获取该数据集的方法参考了以下文章。
https://zhuanlan.zhihu.com/p/109556102
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models, layers, losses, metrics, callbacks
%matplotlib inline
%config InlineBackend.figure_format='svg'
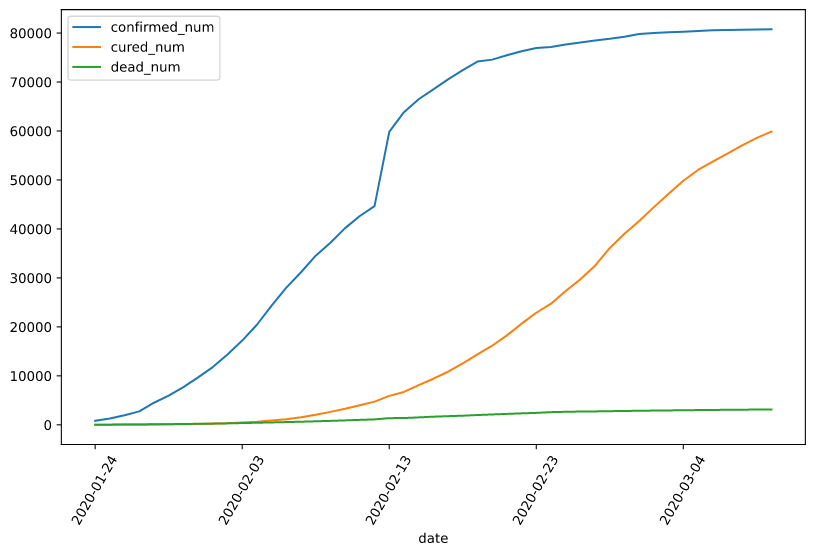
df = pd.read_csv('./data/covid-19.csv', sep='\t')
df.plot(x='date', y=['confirmed_num', 'cured_num', 'dead_num'], figsize=(10, 6))
plt.xticks(rotation=60)
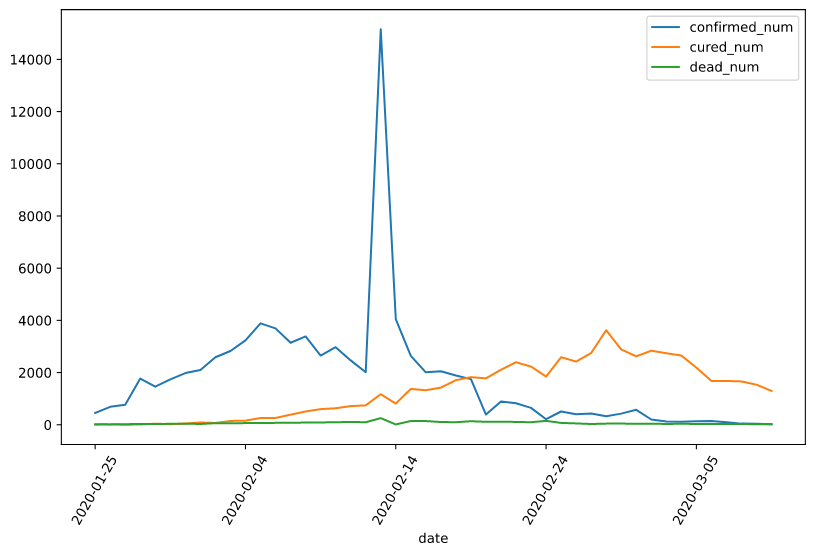
dfdata = df.set_index('date')
dfdiff = dfdata.diff(periods=1).dropna()
dfdiff = dfdiff.reset_index('date')
dfdiff.plot(x='date', y=["confirmed_num","cured_num","dead_num"], figsize=(10,6))
plt.xticks(rotation=60)
dfdiff = dfdiff.drop('date', axis=1).astype('float32')
# 用某日前8天窗口数据作为输入预测改日数据
WINDOW_SIZE = 8
def batch_dataset(dataset):
dataset_batched = dataset.batch(WINDOW_SIZE, drop_remainder=True) # 去掉不足一个batch的多余数据
return dataset_batched
ds_data = tf.data.Dataset.from_tensor_slices(tf.constant(dfdiff.values, dtype=tf.float32)) \
.window(WINDOW_SIZE, shift=1).flat_map(batch_dataset)
ds_label = tf.data.Dataset.from_tensor_slices(tf.constant(dfdiff.values[WINDOW_SIZE:], dtype=tf.float32))
# 数据较小,可以将全部数据放入到一个batch中,提升性能
ds_train = tf.data.Dataset.zip((ds_data, ds_label)).batch(38).cache()
定义模型#
使用Keras接口有以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。
此处选择使用函数式API构建任意结构模型。
# 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构
class Block(layers.Layer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def call(self, x_input, x):
x_out = tf.maximum((1+x)*x_input[:, -1, :], 0.0)
return x_out
def get_config(self):
config = super().get_config()
return config
tf.keras.backend.clear_session()
x_input = layers.Input(shape=(None, 3), dtype=tf.float32)
x = layers.LSTM(3, return_sequences=True, input_shape=(None, 3))(x_input)
x = layers.LSTM(3, return_sequences=True, input_shape=(None, 3))(x)
x = layers.LSTM(3, return_sequences=True, input_shape=(None, 3))(x)
x = layers.LSTM(3, input_shape=(None, 3))(x)
x = layers.Dense(3)(x)
# 考虑到新增确诊,新增治愈,新增死亡人数数据不可能小于0,设计如下结构
# x = tf.maximum((1+x)*x_input[:,-1,:],0.0
x = Block()(x_input, x)
model = models.Model(inputs=[x_input], outputs=[x])
model.summary()
"""
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, 3)] 0 []
lstm (LSTM) (None, None, 3) 84 ['input_1[0][0]']
lstm_1 (LSTM) (None, None, 3) 84 ['lstm[0][0]']
lstm_2 (LSTM) (None, None, 3) 84 ['lstm_1[0][0]']
lstm_3 (LSTM) (None, 3) 84 ['lstm_2[0][0]']
dense (Dense) (None, 3) 12 ['lstm_3[0][0]']
block (Block) (None, 3) 0 ['input_1[0][0]',
'dense[0][0]']
==================================================================================================
Total params: 348
Trainable params: 348
Non-trainable params: 0
__________________________________________________________________________________________________
"""
训练模型#
训练模型通常有3种方法,内置fit方法,内置train_on_batch方法,以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
注:循环神经网络调试较为困难,需要设置多个不同的学习率多次尝试,以取得较好的效果。
# 自定义损失函数,考虑平方差和预测目标的比值
class MSPE(losses.Loss):
def call(self, y_true, y_pred):
err_percent = (y_true - y_pred) ** 2 / (tf.maximum(y_true**2, 1e-7))
mean_err_percent = tf.reduce_mean(err_percent)
return mean_err_percent
def get_config(self):
config = super().get_config()
return config
import datetime
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=optimizer, loss=MSPE(name='MSPE'))
log_dir = './data/keras_model/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tb_callback = tf.keras.callbacks.TensorBoard(log_dir, histogram_freq=1)
# 如果loss在100个epoch没有提升,学习率减半
lr_callback = tf.keras.callbacks.ReduceLROnPlateau(monitor='loss', factor=0.5, patience=100)
# 当loss在200个 epoch后没有提升,则终止训练
stop_callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=200)
callbacks_list = [tb_callback, lr_callback, stop_callback]
history = model.fit(ds_train, epochs=500, callbacks=callbacks_list)
评估模型#
评估模型一般要设置验证集或者测试集,由于此例数据较少,我们仅仅可视化损失函数在训练集上的迭代情况。
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
def plot_metric(history, metric):
train_metrics = history.history[metric]
epochs = range(1, len(train_metrics)+1)
plt.plot(epochs, train_metrics, 'bo--')
plt.title("Training" + metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_" + metric])
plt.show()
plot_metric(history, 'loss')

使用模型#
此处我们使用模型预测疫情结束时间,即 新增确诊病例为0 的时间。
# 使用dfresult记录现有数据以及此后预测的疫情数据
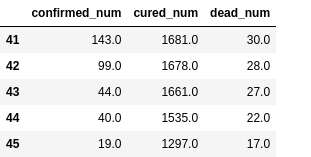
dfresult = dfdiff[["confirmed_num","cured_num","dead_num"]].copy()
dfresult.tail()
# 预测此后100天的新增走势,将其结果添加到dfresult中
for i in range(100):
arr_predict = model.predict(tf.constant(tf.expand_dims(dfresult.values[-38:, :], axis=0)))
dfpredict = pd.DataFrame(tf.cast(tf.floor(arr_predict), tf.float32).numpy(), columns=dfresult.columns)
dfresult = dfresult.append(dfpredict, ignore_index=True)
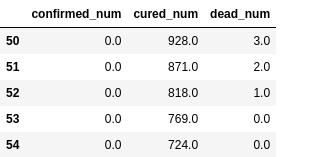
dfresult.query('confirmed_num==0').head()
# 第50天开始新增确诊降为0,第45天对应3月10日,也就是5天后,即预计3月15日新增确诊降为0
# 注:该预测偏乐观
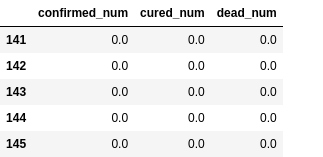
dfresult.query('cured_num==0').head()
# 第112天开始新增治愈降为0,第45天对应3月10日,也就是大概3个月左右全部治愈。
# 注: 该预测偏悲观,并且存在问题,如果将每天新增治愈人数加起来,将超过累计确诊人数。
dfresult.query('dead_num==0').head()
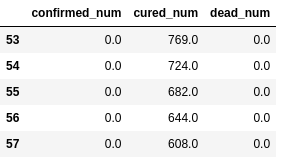
保存模型#
推荐使用TensorFlow原生方式保存模型。
model.save('./data/tf_model_savedmodel/', save_format='tf')
print('export saved model.')
model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel', compile=False)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model_loaded.compile(optimizer=optimizer, loss=MSPE(name="MSPE"))
model_loaded.predict(ds_train)
"""
array([[1.29506799e+03, 9.26605377e+01, 2.40224361e+00],
[1.59739441e+03, 7.26542816e+01, 4.88456202e+00],
[1.74300476e+03, 1.54785217e+02, 4.56426287e+00],
[1.99473779e+03, 1.65314819e+02, 5.12478638e+00],
[2.39763403e+03, 2.73769775e+02, 5.20486116e+00],
[2.27917163e+03, 2.74822723e+02, 5.84545946e+00],
[1.93920850e+03, 4.07495758e+02, 5.84545946e+00],
[2.08852075e+03, 5.37009949e+02, 6.88643169e+00],
[1.63626501e+03, 6.30723450e+02, 7.12665606e+00],
[1.83431970e+03, 6.65471130e+02, 7.76725435e+00],
[1.52212134e+03, 7.52866882e+02, 8.64807701e+00],
[1.24324060e+03, 7.83402710e+02, 7.76725435e+00],
[9.34805859e+03, 1.23301685e+03, 2.03389969e+01],
[2.49696997e+03, 8.55004028e+02, 1.04097223e+00],
[1.62947803e+03, 1.44571497e+03, 1.14506950e+01],
[1.26493555e+03, 1.37077380e+03, 6.94930954e+01],
[9.91234863e+02, 1.51438965e+03, 9.29494476e+01],
[6.88026611e+02, 1.89116382e+03, 1.05506691e+02],
[5.46848022e+02, 2.07013770e+03, 1.56961151e+02],
[1.33432922e+02, 1.98183557e+03, 1.28883331e+02],
[4.09158569e+02, 2.13445508e+03, 1.13192642e+02],
[3.88079865e+02, 2.21991479e+03, 7.97306824e+01],
[2.91137482e+02, 2.05084302e+03, 6.49722900e+01],
[1.00071075e+02, 1.70365100e+03, 1.01444641e+02],
[2.51889359e+02, 2.40150195e+03, 4.99933777e+01],
[2.32710464e+02, 2.27377710e+03, 4.03472328e+01],
[2.67352448e+02, 2.59846411e+03, 2.37115974e+01],
[2.01903580e+02, 3.42241357e+03, 3.59762192e+01],
[2.63647797e+02, 2.72602515e+03, 3.84291420e+01],
[3.53794342e+02, 2.47846240e+03, 2.86174469e+01],
[1.24723312e+02, 2.68067017e+03, 3.43409348e+01],
[7.71802673e+01, 2.59090503e+03, 2.53468800e+01],
[7.34756165e+01, 2.50586426e+03, 3.10703697e+01],
[8.58244553e+01, 2.06837744e+03, 2.53468800e+01],
[8.82942276e+01, 1.58837024e+03, 2.45292397e+01],
[6.11267700e+01, 1.58553552e+03, 2.28939571e+01],
[2.71674538e+01, 1.56947229e+03, 2.20763149e+01],
[2.46976852e+01, 1.45041541e+03, 1.79881096e+01]], dtype=float32)
"""
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/16488170.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
分类:
TensorFlow




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2021-07-17 2-Maven