1-Spark学习笔记1
Spark-core#
Spark概述#
-
Spark是什么
- Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
-
Spark and Hadoop
-

-
-
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间的数据通信是基于内存,而Hadoop的基于磁盘
-
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以Spark并不能完全替代 MR
-
-
Spark核心模块
Spark快速上手#
-
-
增加依赖关系(一次引入后续各个模块的依赖)
-
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.lotuslaw</groupId> <artifactId>spark-core</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.10</version> </dependency> </dependencies> <build> <plugins> <!-- 该插件用于将 Scala 代码编译成 class 文件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <!-- 声明绑定到 maven 的 compile 阶段 --> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
-
-
log4j.properties文件
-
log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/ddHH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to ERROR. When running the spark-shell,the # log level for this class is used to overwrite the root logger's log level, sothat # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
-
-
WordCount
-
package com.lotuslaw.spark.core.wc import org.apache.spark.{SparkConf, SparkContext} /** * @author: lotuslaw * @version: V1.0 * @package: com.lotuslaw.spark.core.wc * @create: 2021-12-02 10:08 * @description: */ object Spark01_WordCount { def main(args: Array[String]): Unit = { // 创建Spark运行配置对象 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount") // 创建Spark上下文环境对象(连接对象) val sc = new SparkContext(sparkConf) // 读取文件数据 val fileRDD = sc.textFile("input/word.txt") // 将文件中的数据进行分词 val wordRDD = fileRDD.flatMap(_.split(" ")) // 转换数据结构 val word2OneRDD = wordRDD.map((_, 1)) // 将转换结构后的数据按照相同的单词进行分组聚合 val word2CountRDD = word2OneRDD.reduceByKey(_ + _) // 将数据聚合结果采集到内存中 val word2Count = word2CountRDD.collect() // 打印结果 word2Count.foreach(println) // 关闭连接 sc.stop() } }
-
-


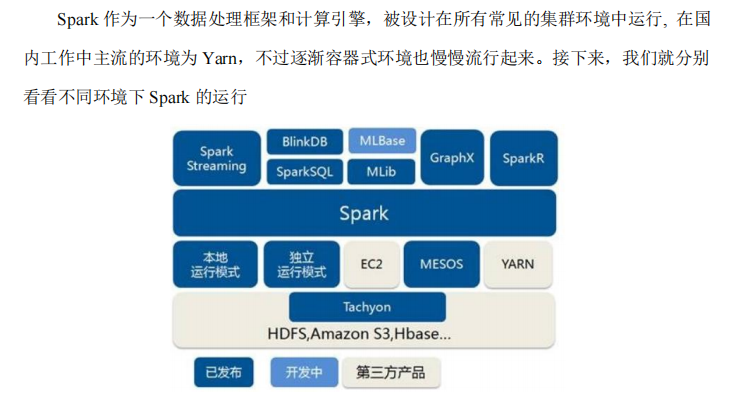
Spark运行环境#
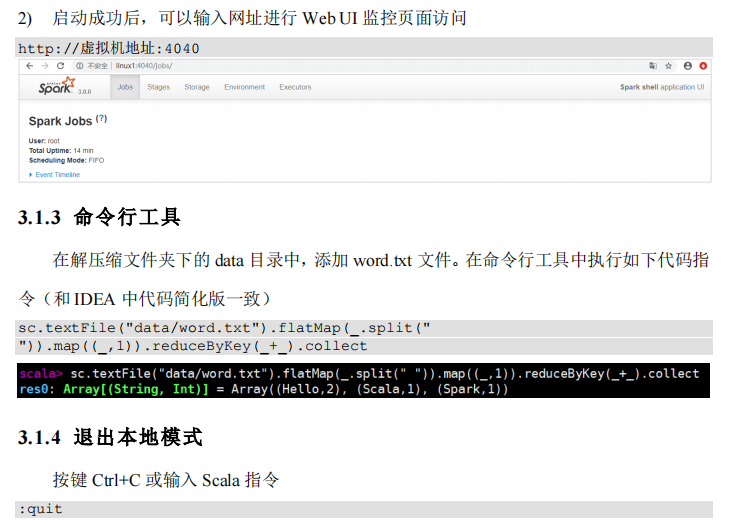
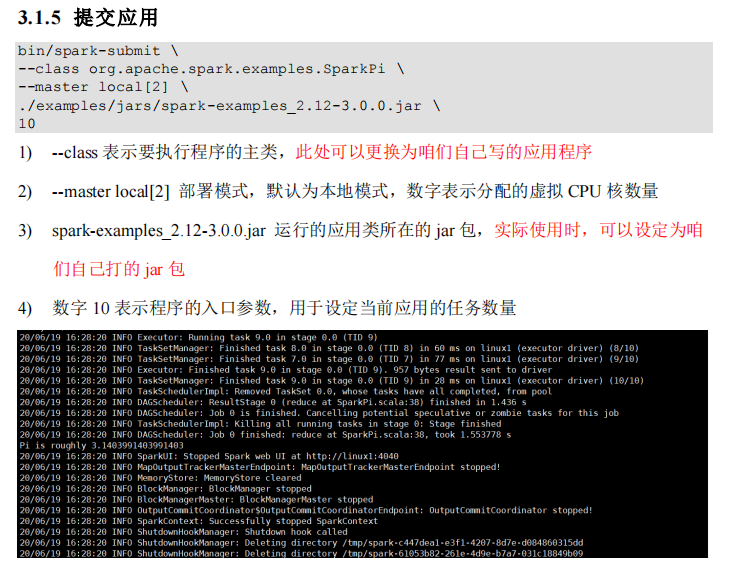


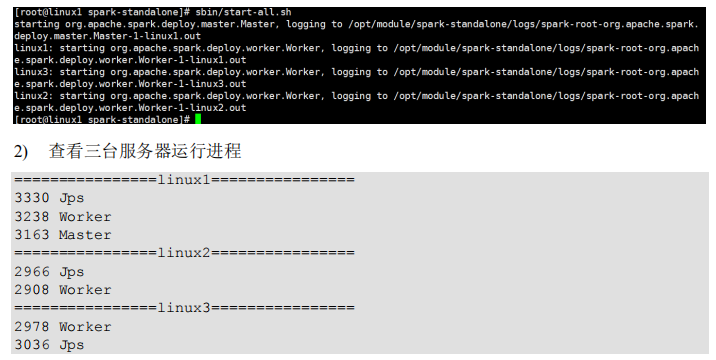
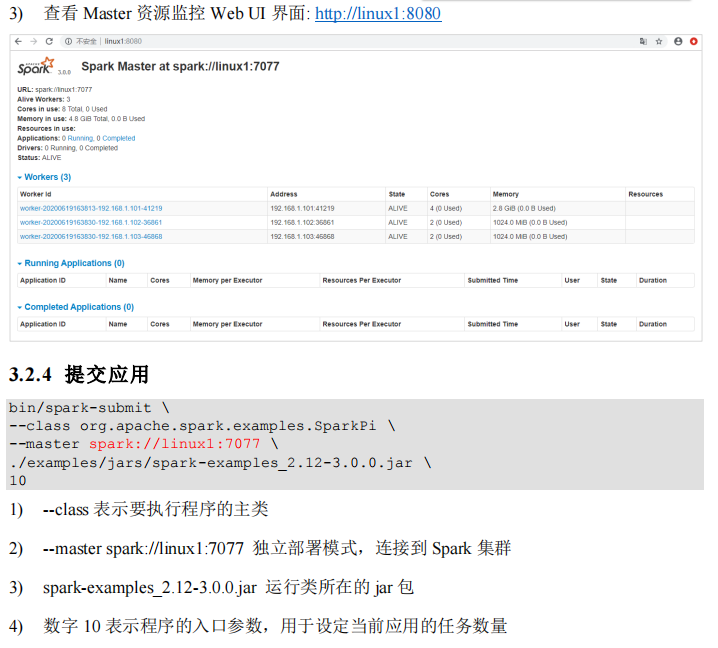
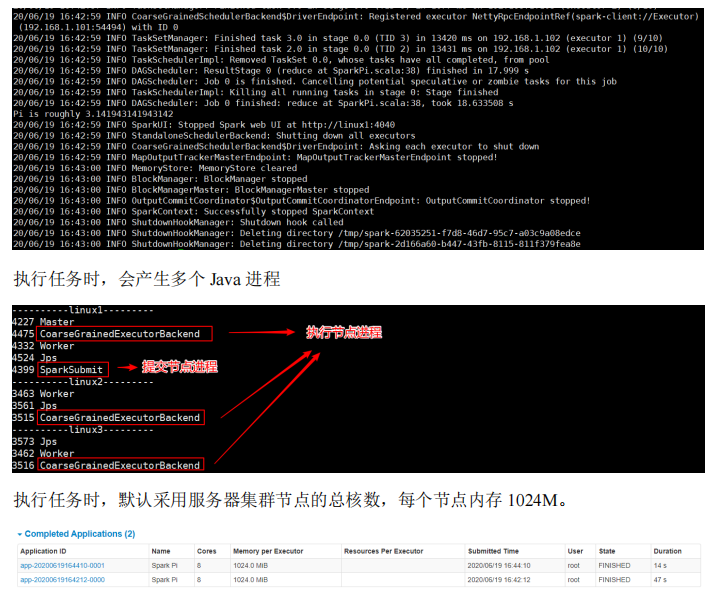
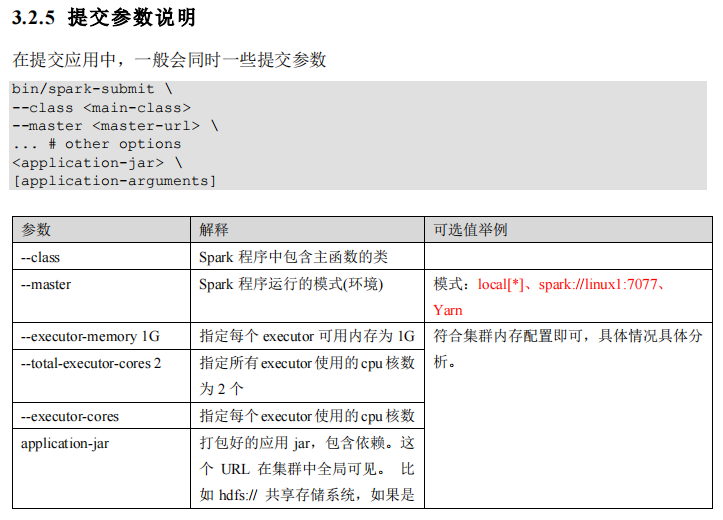

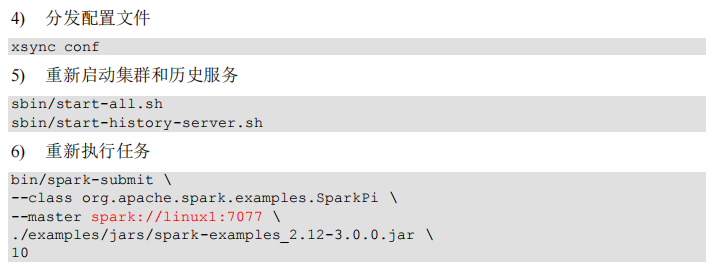
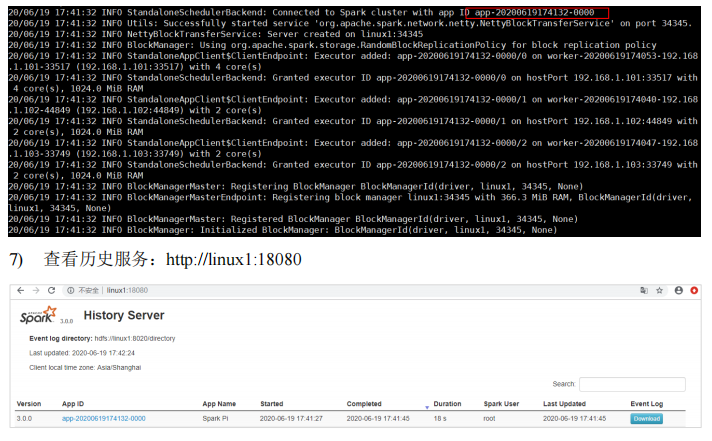
注释如下内容:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自
定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark"

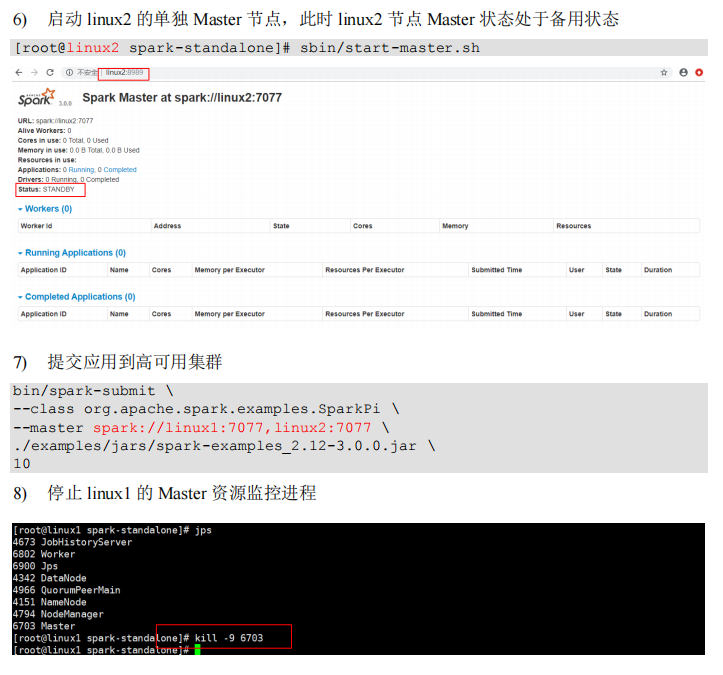
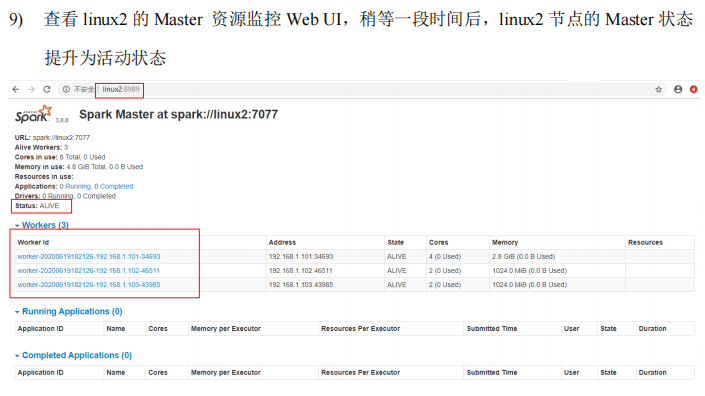

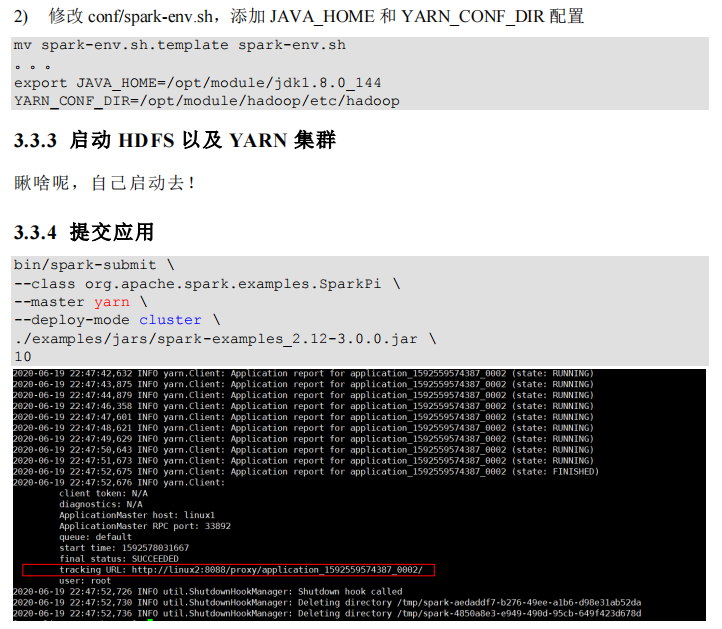
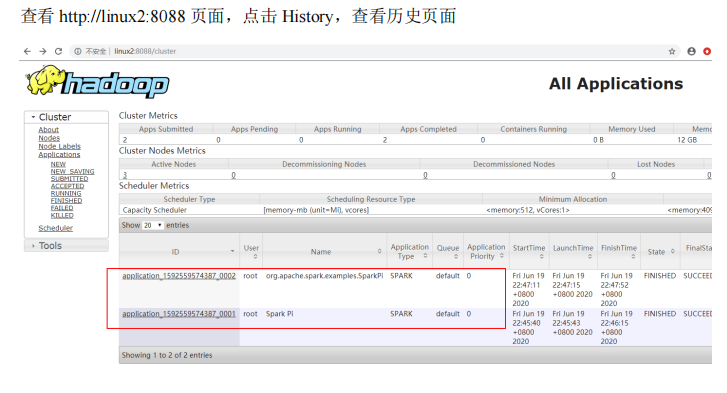
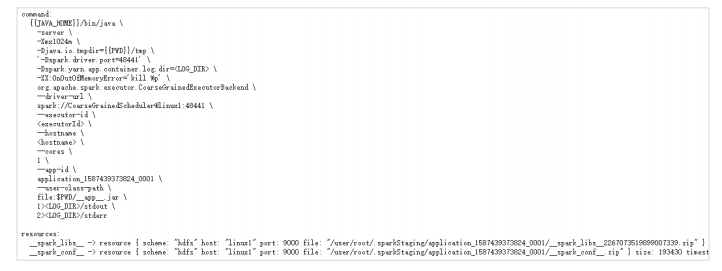

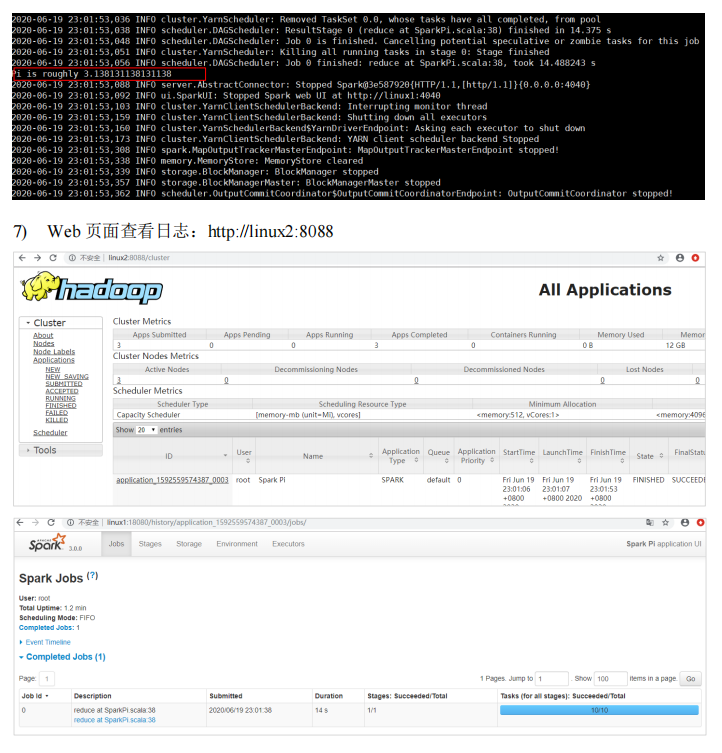

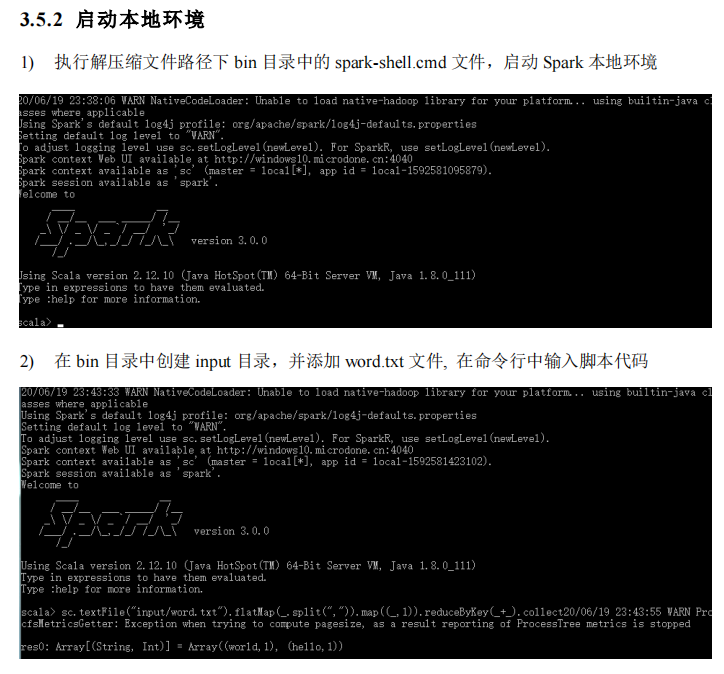

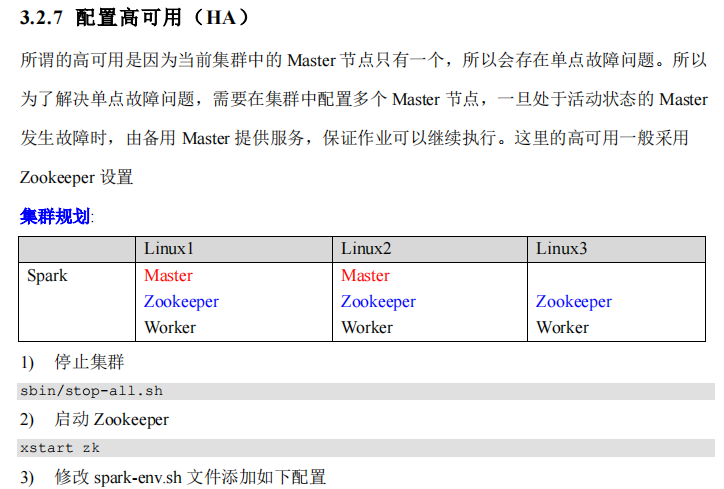
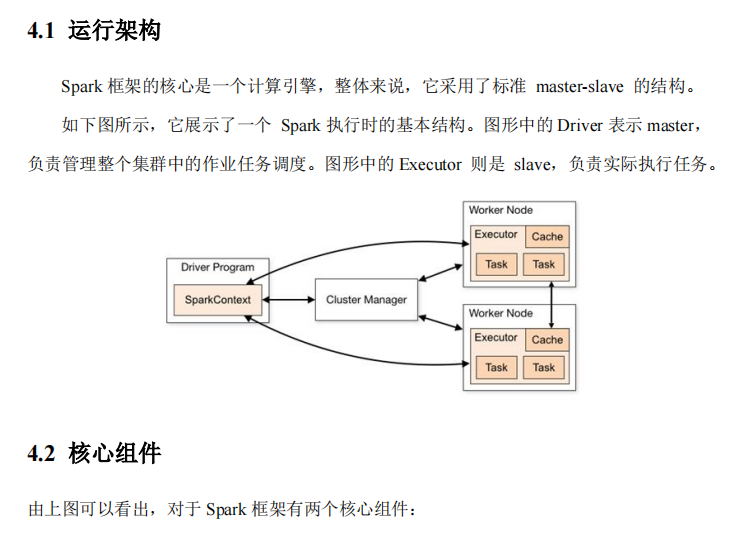
Spark运行架构#



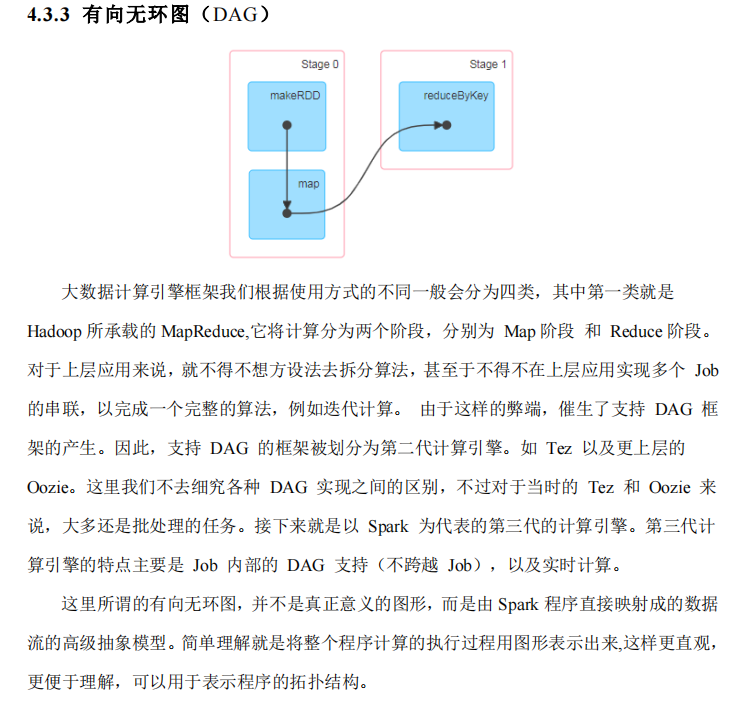
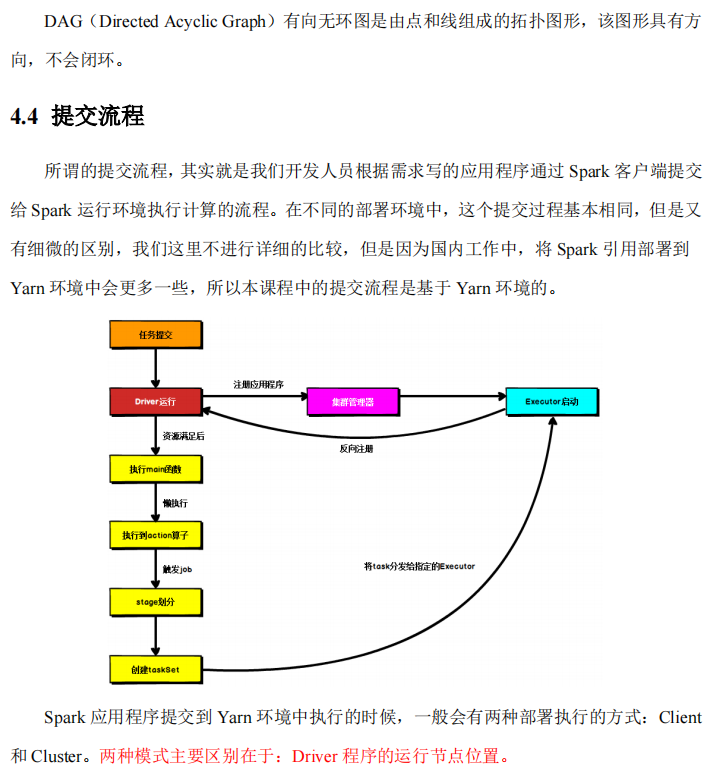


Spark核心编程#


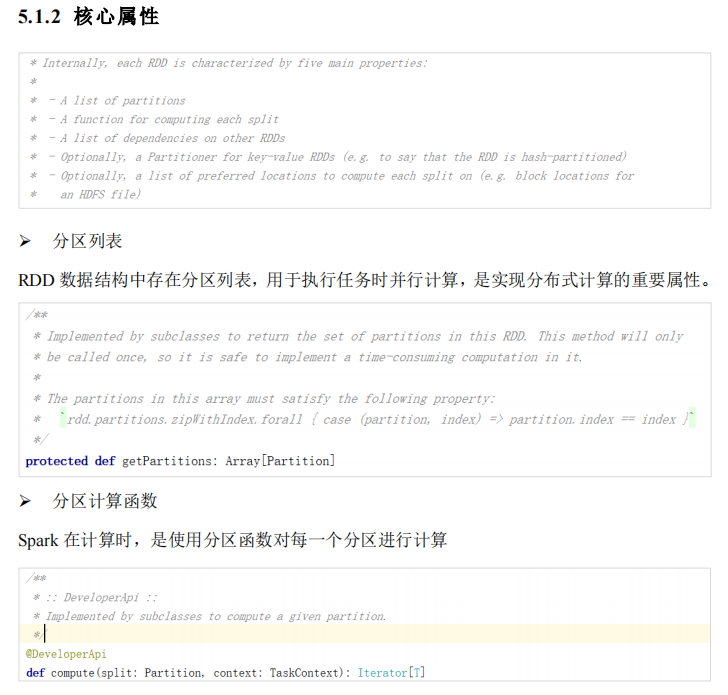
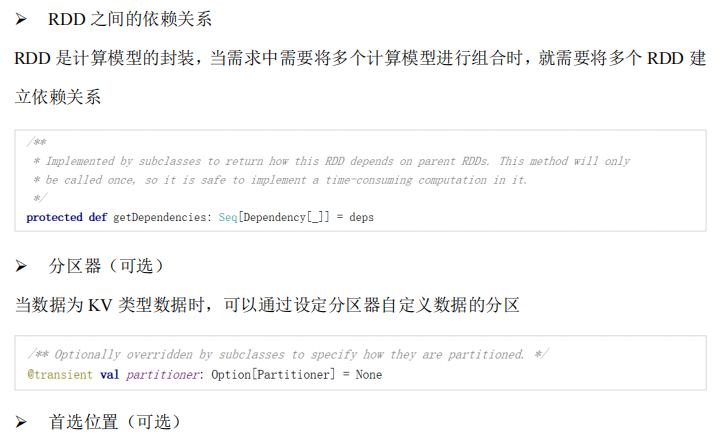
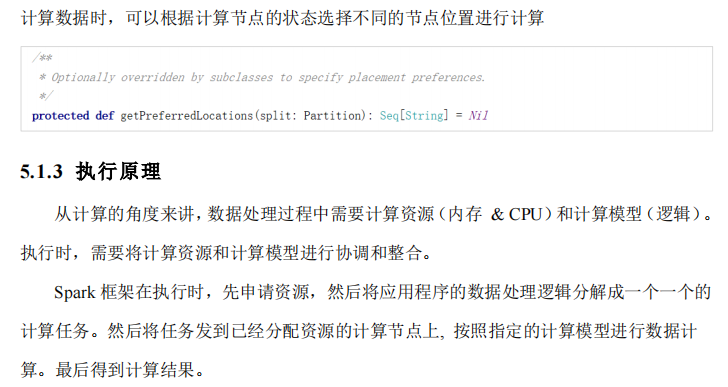
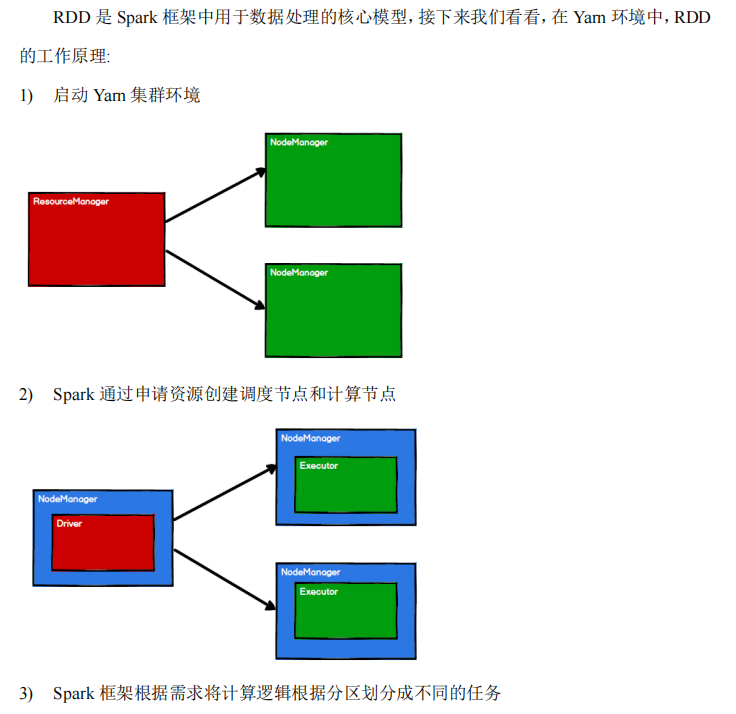
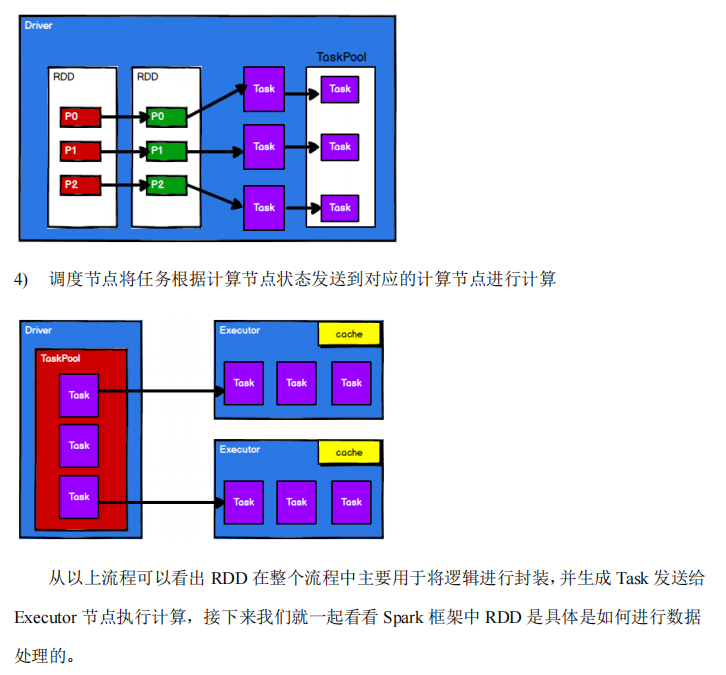
-
RDD创建
-
从集合(内存)中创建
-
package com.lotuslaw.spark.core.rdd.builder import org.apache.spark.{SparkConf, SparkContext} /** * @author: lotuslaw * @version: V1.0 * @package: com.lotuslaw.spark.core.rdd * @create: 2021-12-02 11:26 * @description: */ object Spark01_RDD_Memory { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sparkContext = new SparkContext(sparkConf) val rdd = sparkContext.makeRDD(List(1, 2, 3, 4)) rdd.collect().foreach(println) sparkContext.stop() } }
-
-
从外部存储(文件)创建RDD
-
package com.lotuslaw.spark.core.rdd.builder import org.apache.spark.{SparkConf, SparkContext} /** * @author: lotuslaw * @version: V1.0 * @package: com.lotuslaw.spark.core.rdd * @create: 2021-12-02 11:26 * @description: */ object Spark01_RDD_File { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sparkContext = new SparkContext(sparkConf) val rdd = sparkContext.textFile("input") rdd.collect().foreach(println) sparkContext.stop() } }
-
-
从其他RDD创建
-
直接创建RDD(new)
-
-
RDD并行度与分区
-

-
package com.lotuslaw.spark.core.rdd.builder import org.apache.spark.{SparkConf, SparkContext} /** * @author: lotuslaw * @version: V1.0 * @package: com.lotuslaw.spark.core.rdd * @create: 2021-12-02 11:26 * @description: */ object Spark01_RDD_Memory2 { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") sparkConf.set("spark.default.parallelism", "5") val sc = new SparkContext(sparkConf) // RDD的并行度&分区 /* makeRDD方法可以传递第二个参数,这个参数表示分区的数量 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度) scheduler.conf.getInt("spark.default.parallelism", totalCores) spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数 */ val rdd = sc.makeRDD(List(1, 2, 3, 4), 2) rdd.saveAsTextFile("output") sc.stop() } } -
package com.lotuslaw.spark.core.rdd.builder import org.apache.spark.{SparkConf, SparkContext} /** * @author: lotuslaw * @version: V1.0 * @package: com.lotuslaw.spark.core.rdd * @create: 2021-12-02 11:40 * @description: */ object Spark01_RDD_Memory_File { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark") val sc = new SparkContext(sparkConf) val dataRDD = sc.makeRDD(List(1, 2, 3, 4), 4) val fileRDD = sc.textFile("input", 2) fileRDD.collect().foreach(println) sc.stop() } }
-
-
RDD转换算子

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Map {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4))
val dataRDD1 = dataRDD.map(
num => {
num * 2
}
)
val dataRDD2 = dataRDD1.map(", " + _)
dataRDD2.collect().foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Map_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("input/apache.log")
val mapRDD = rdd.map(
line => {
val datas = line.split(" ")
datas(6)
}
)
mapRDD.collect().foreach(println)
sc.stop()
}
}


package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_MapPartitions {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4))
val data1RDD = dataRDD.mapPartitions(
datas => {
datas.filter(_ == 2)
}
)
data1RDD.collect().foreach(println)
sc.stop()
}
}
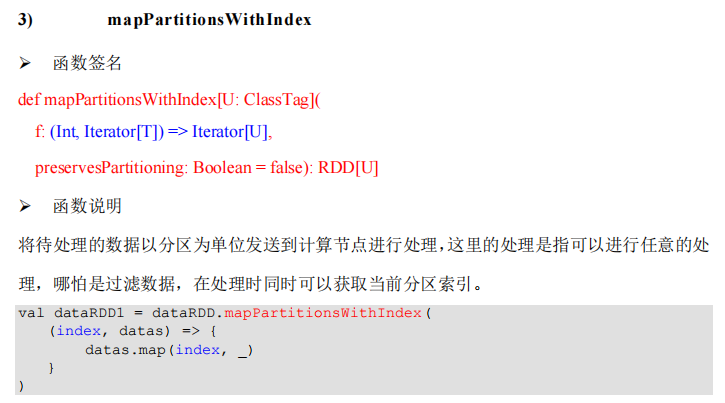
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_MapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4), 2)
val dataRDD1 = dataRDD.mapPartitionsWithIndex(
(index, iter) => {
if (index == 1) {
iter
} else {
Nil.iterator
}
}
)
dataRDD1.collect().foreach(println)
sc.stop()
}
}
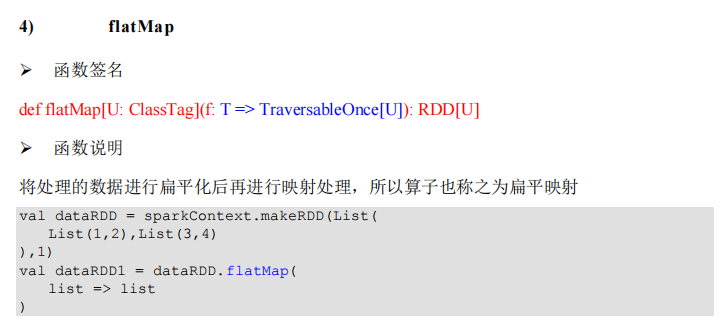
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_FlatMap {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(
List(1, 2), 3, List(3, 4)
))
/*
val dataRDD1 = dataRDD.flatMap(
data => {
data match {
case list: List[_] => list
case data_tmp => List(data_tmp)
}
}
)
*/
val dataRDD1 = dataRDD.flatMap {
case list: List[_] => list
case data_tmp => List(data_tmp)
}
println(dataRDD1.collect().toList.mkString(", "))
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Glom {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD = rdd.glom()
glomRDD.collect().foreach(data => println(data.mkString(", ")))
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Glom_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD = rdd.glom()
val maxRDD = glomRDD.map(
array => {
array.max
}
)
println(maxRDD.collect().sum)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_GroupBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val groupRDD = rdd.groupBy(_ % 2)
groupRDD.collect().foreach(println)
sc.stop()
}
}
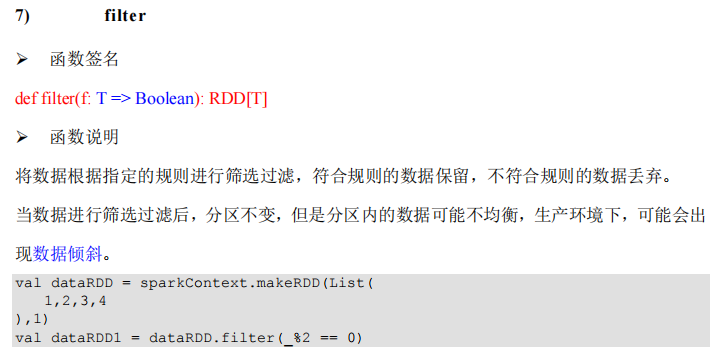
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import java.text.SimpleDateFormat
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Filter {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.makeRDD(List(1, 2, 3, 4), 1)
val dataRDD1 = dataRDD.filter(_ % 2 == 0)
dataRDD1.collect().foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import java.text.SimpleDateFormat
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Filter_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("input/apache.log")
rdd.filter(
line => {
val datas = line.split(" ")
val time = datas(3)
time.startsWith("17/05/2015")
}
).collect().foreach(println)
sc.stop()
}
}
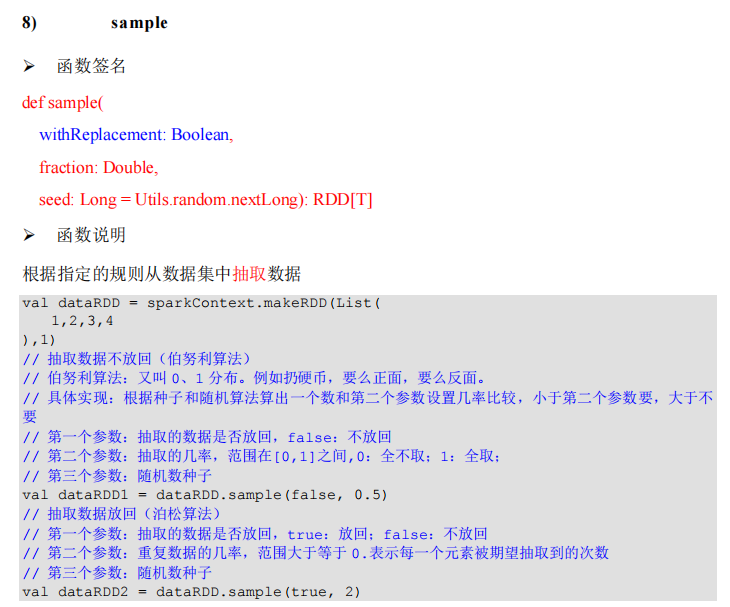
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Sample {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
rdd.sample(false, 0.4, 42).collect().foreach(println)
rdd.sample(true, 2, 42).collect().foreach(println)
sc.stop()
}
}
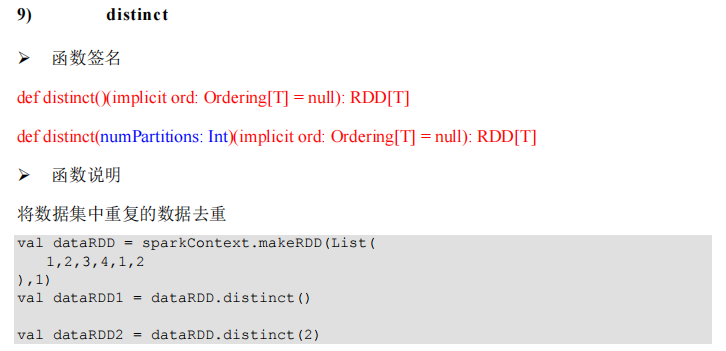
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Distinct {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))
val rdd1 = rdd.distinct()
rdd1.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Coalesce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// coalesce方法默认情况下不会将分区的数据打乱重新组合
// 这种情况下的缩减分区可能会导致数据不均衡,出现数据倾斜
// 如果想要让数据均衡,可以进行shuffle处理
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
// val newRDD = rdd.coalesce(2)
val newRDD = rdd.coalesce(2, true)
newRDD.saveAsTextFile("output")
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Repartition {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// 缩减分区:coalesce,如果想要数据均衡,可以采用shuffle
// 扩大分区:repartition, 底层代码调用的就是coalesce,而且肯定采用shuffle
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
val newRDD = rdd.repartition(3)
newRDD.saveAsTextFile("output")
sc.stop()
}
}

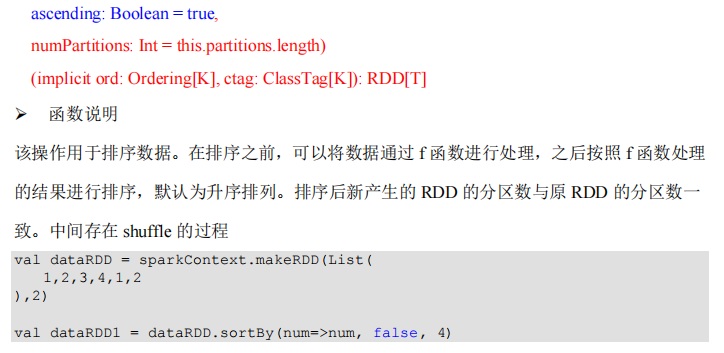
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_SortBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(6, 3, 4, 2, 5, 1), 2)
val newRDD = rdd.sortBy(num => num)
newRDD.saveAsTextFile("output")
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_SortBy2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// sortBy方法可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式
// sortBy默认情况下,不会改变分区。但是中间存在shuffle操作
val rdd = sc.makeRDD(List(("1", 1), ("11", 2), ("2", 3)), 2)
val newRDD = rdd.sortBy(t => t._1.toInt, false)
newRDD.collect().foreach(println)
sc.stop()
}
}




package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Intersection_And {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// 交集,并集和差集要求两个数据源数据类型保持一致
// 拉链操作两个数据源的类型可以不一致
val rdd1 = sc.makeRDD(List(1, 2, 3, 4))
val rdd2 = sc.makeRDD(List(3, 4, 5, 6))
val rdd3 = sc.makeRDD(List("1", "2", "3", "4"))
val rdd4 = rdd1.intersection(rdd2)
println(rdd4.collect().mkString(", "))
val rdd5 = rdd1.union(rdd2)
println(rdd5.collect().mkString(", "))
val rdd6 = rdd1.subtract(rdd2)
println(rdd6.collect().mkString(", "))
val rdd7 = rdd1.zip(rdd3)
println(rdd7.collect().mkString(", "))
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_PartitionBy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val mapRDD = rdd.map((_, 1))
// RDD => PairRDDFunctions
// 隐式转换(二次编译)
val newRDD = mapRDD.partitionBy(new HashPartitioner(2))
newRDD.saveAsTextFile("output")
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_ReduceByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// reduceByKey : 相同的key的数据进行value数据的聚合操作
// scala语言中一般的聚合操作都是两两聚合,spark基于scala开发的,所以它的聚合也是两两聚合
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
val reduceRDD = rdd.reduceByKey((x, y) => {
println(s"s = ${x}, y = ${y}")
x + y
})
reduceRDD.collect().foreach(println)
sc.stop()
}
}
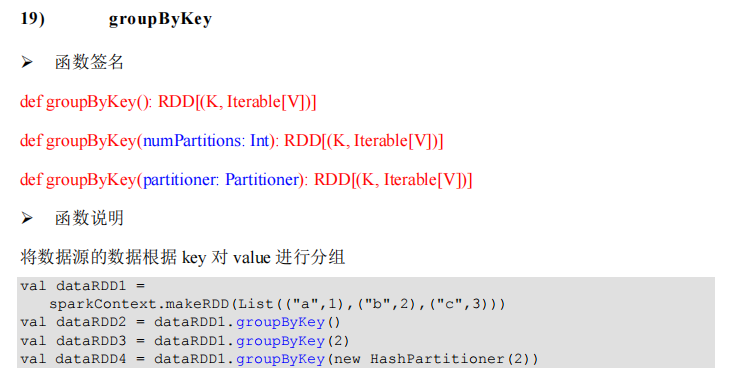

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_GroupByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
val groupRDD = rdd.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_AggregateByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// aggregateByKey存在函数柯里化,有两个参数列表
// 第一个参数列表,需要传递一个参数,表示为初始值
// 主要用于当碰见第一个key的时候,和value进行分区内计算
// 第二个参数列表需要传递2个参数
// 第一个参数表示分区内计算规则
// 第二个参数表示分区间计算规则
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("a", 4)
), 2)
rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect().foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_AggregateByKey_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
val newRDD = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resRDD = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_FoldByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
rdd.foldByKey(0)(_+_).collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_CombineByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// combineByKey : 方法需要三个参数
// 第一个参数表示:将相同key的第一个数据进行结构的转换,实现操作
// 第二个参数表示:分区内的计算规则
// 第三个参数表示:分区间的计算规则
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
),2)
val newRDD = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t2._2 + t2._2)
}
)
newRDD.mapValues{
case (num, cnt) => {
num / cnt
}
}.collect().foreach(println)
sc.stop()
}
}



package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_SortByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 0)))
val sortRDD = rdd.sortByKey(false)
sortRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Join {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// join : 两个不同数据源的数据,相同的key的value会连接在一起,形成元组
// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。
val rdd1 = sc.makeRDD(List(
("a", 1), ("a", 2), ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 5), ("c", 6), ("a", 4)
))
val joinRDD = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_LeftOuterJoin {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// join : 两个不同数据源的数据,相同的key的value会连接在一起,形成元组
// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。
val rdd1 = sc.makeRDD(List(
("a", 1), ("a", 2), //("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 5), ("c", 6), ("a", 4)
))
val lojRDD = rdd1.leftOuterJoin(rdd2)
lojRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_CoGroup {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// cogroup : connect + group (分组,连接)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6), ("c", 7)
))
val cgRDD = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Transform_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val dataRDD = sc.textFile("input/agent.log")
val mapRDD = dataRDD.map(
line => {
val datas = line.split(" ")
((datas(1), datas(4)), 1)
}
)
val reduceRDD = mapRDD.reduceByKey(_ + _)
val newMapRDD = reduceRDD.map {
case ((prv, ad), sum) => {
(prv, (ad, sum))
}
}
val groupRDD = newMapRDD.groupByKey()
val resRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
resRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Reduce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val reduceRes = rdd.reduce(_ + _)
println(reduceRes)
sc.stop()
}
}
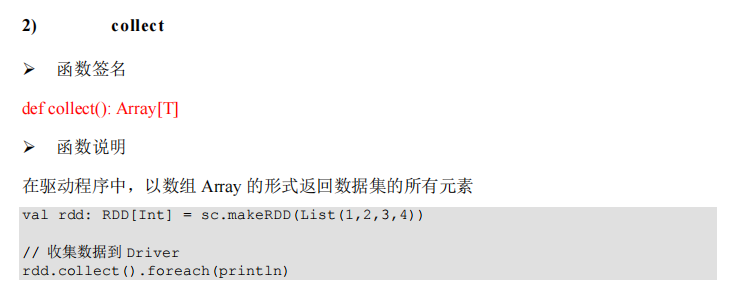
package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Collect {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val collectRes = rdd.collect()
collectRes.foreach(println)
sc.stop()
}
}
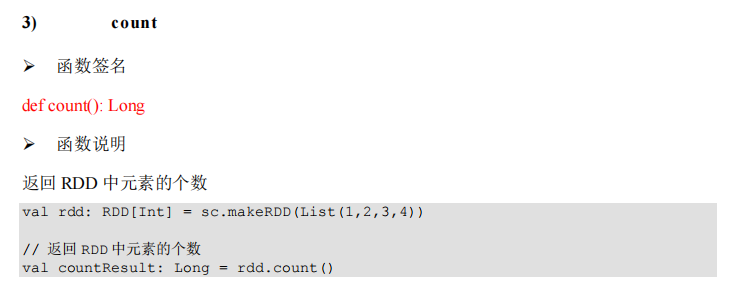
package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Count {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val countRes = rdd.count()
println(countRes)
sc.stop()
}
}


package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_First {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val firstRes = rdd.first()
println(firstRes)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Take {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val takeRes = rdd.take(3)
println(takeRes.mkString(", "))
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_TakeOrdered {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 4, 3))
val takeORes = rdd.takeOrdered(3)
println(takeORes.mkString(", "))
sc.stop()
}
}
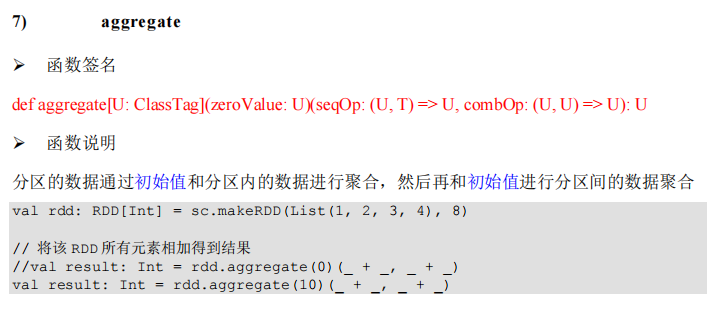
package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Aggregate {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// aggregateByKey : 初始值只会参与分区内计算
// aggregate : 初始值会参与分区内计算,并且和参与分区间计算
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val aggRes = rdd.aggregate(10)(_ + _, _ + _)
println(aggRes)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_fold {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// aggregateByKey : 初始值只会参与分区内计算
// aggregate : 初始值会参与分区内计算,并且和参与分区间计算
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val foldRes = rdd.fold(10)(_ + _)
println(foldRes)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
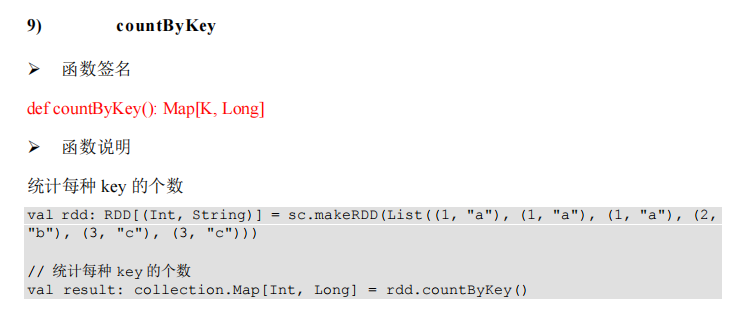
object Spark_RDD_Operator_Action_CountByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
(1, "a"), (1, "a"), (1, "a"),
(2, "b"), (3, "c"), (3, "c")
))
val cbkRes = rdd.countByKey()
println(cbkRes)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
object Spark_RDD_Operator_Action_Save {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
// (1, "a")作为一个value
val rdd = sc.makeRDD(List(
(1, "a"), (1, "a"), (1, "a"),
(2, "b"), (3, "c"), (3, "c")
))
rdd.saveAsTextFile("output")
rdd.saveAsObjectFile("output")
// saveAsSequenceFile方法要求数据的格式必须为K-V类型
rdd.saveAsSequenceFile("output2")
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.operator.actor
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.operator.transform.action.transform
* @create: 2021-12-02 11:46
* @description:
*/
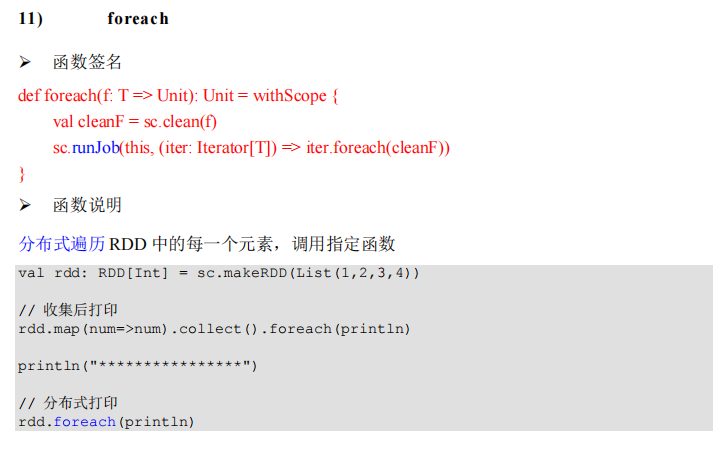
object Spark_RDD_Operator_Action_ForEach {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// foreach 其实是Driver端内存集合的循环遍历方法
rdd.collect().foreach(println)
println("******************************")
// foreach 其实是Executor端内存数据打印
rdd.foreach(println)
sc.stop()
}
}

object serializable02_function {
def main(args: Array[String]): Unit = {
//1.创建 SparkConf 并设置 App 名称
val conf: SparkConf = new
SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建 SparkContext,该对象是提交 Spark App 的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个 RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark",
"hive", "atguigu"))
//3.1 创建一个 Search 对象
val search = new Search("hello")
//3.2 函数传递,打印:ERROR Task not serializable
search.getMatch1(rdd).collect().foreach(println)
//3.3 属性传递,打印:ERROR Task not serializable
search.getMatch2(rdd).collect().foreach(println)
//4.关闭连接
sc.stop()
} }
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
} }

object serializable_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu",
"atguigu", "hahah"), 2)
val searcher = new Searcher("hello")
val result: RDD[String] = searcher.getMatchedRDD1(rdd)
result.collect.foreach(println)
} }
case class Searcher(val query: String) {
def isMatch(s: String) = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]) = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]) = {
val q = query
rdd.filter(_.contains(q))
}
}

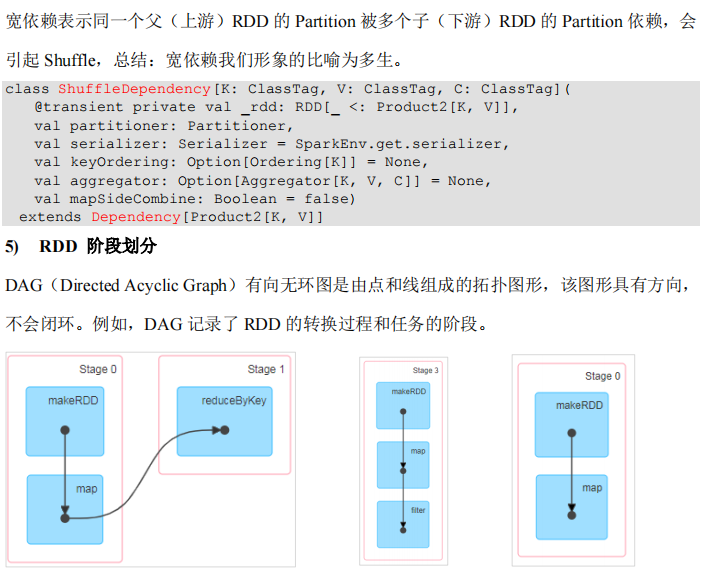
package com.lotuslaw.spark.core.rdd.dep
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.dep
* @create: 2021-12-02 14:35
* @description:
*/
object Spark_RDD_Dependency {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val lines = sc.textFile("input/word.txt")
println(lines.toDebugString)
println("************************")
val words = lines.flatMap(_.split(" "))
println(words.toDebugString)
println("************************")
val wordToOne = words.map((_, 1))
println(wordToOne.toDebugString)
println("************************")
val wordCount = wordToOne.reduceByKey(_ + _)
println(wordCount.toDebugString)
println("************************")
val array = wordCount.collect()
array.foreach(println)
sc.stop()
}
}

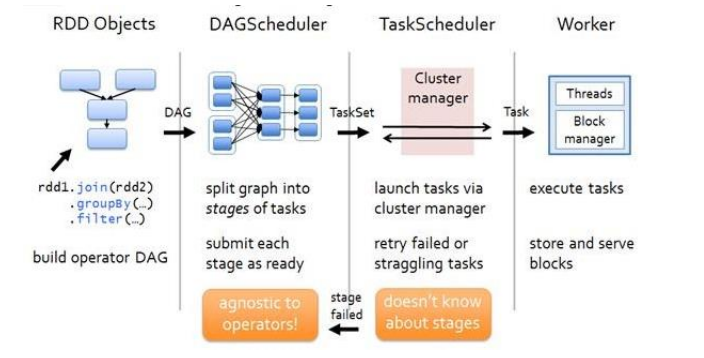
package com.lotuslaw.spark.core.rdd.dep
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.dep
* @create: 2021-12-02 14:35
* @description:
*/
object Spark_RDD_Dependency2 {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val lines = sc.textFile("input/word.txt")
println(lines.dependencies)
println("************************")
val words = lines.flatMap(_.split(" "))
println(words.dependencies)
println("************************")
val wordToOne = words.map((_, 1))
println(wordToOne.dependencies)
println("************************")
val wordCount = wordToOne.reduceByKey(_ + _)
println(wordCount.dependencies)
println("************************")
val array = wordCount.collect()
array.foreach(println)
sc.stop()
}
}





package com.lotuslaw.spark.core.rdd.persist
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.persist
* @create: 2021-12-02 14:50
* @description:
*/
object Spark_RDD_Persist {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Persist")
val sc = new SparkContext(sparConf)
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word => {
println("@@@@@@@@@@@@@@")
(word, 1)
})
// cache默认持久化的操作,只能将数据保存到内存中,如果想要保存到磁盘文件,需要更改存储级别
//mapRDD.cache()
// 持久化操作必须在行动算子执行时完成的。
mapRDD.persist(StorageLevel.DISK_ONLY)
val reduceRDD = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("********************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.persist
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.persist
* @create: 2021-12-02 14:50
* @description:
*/
object Spark_RDD_Persist2 {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Persist")
val sc = new SparkContext(sparConf)
sc.setCheckpointDir("cp")
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word => {
println("@@@@@@@@@@@@@@")
(word, 1)
})
// checkpoint 需要落盘,需要指定检查点保存路径
// 检查点路径保存的文件,当作业执行完毕后,不会被删除
// 一般保存路径都是在分布式存储系统:HDFS
mapRDD.checkpoint()
val reduceRDD = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("********************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.rdd.persist
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.persist
* @create: 2021-12-02 14:50
* @description:
*/
object Spark_RDD_Persist3 {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Persist")
val sc = new SparkContext(sparConf)
sc.setCheckpointDir("cp")
val list = List("Hello Scala", "Hello Spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(word => {
println("@@@@@@@@@@@@@@")
(word, 1)
})
// cache : 将数据临时存储在内存中进行数据重用
// 会在血缘关系中添加新的依赖。一旦,出现问题,可以重头读取数据
// persist : 将数据临时存储在磁盘文件中进行数据重用
// 涉及到磁盘IO,性能较低,但是数据安全
// 如果作业执行完毕,临时保存的数据文件就会丢失
// checkpoint : 将数据长久地保存在磁盘文件中进行数据重用
// 涉及到磁盘IO,性能较低,但是数据安全
// 为了保证数据安全,所以一般情况下,会独立执行作业
// 为了能够提高效率,一般情况下,是需要和cache联合使用
// 执行过程中,会切断血缘关系。重新建立新的血缘关系
// checkpoint等同于改变数据源
mapRDD.cache()
mapRDD.checkpoint()
println(mapRDD.toDebugString)
val reduceRDD = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("********************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}

package com.lotuslaw.spark.core.rdd.partitioner
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.rdd.partitioner
* @create: 2021-12-02 15:01
* @description:
*/
object Spark_RDD_Partitioner {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List(
("nba", "XXXXXXXXXXXXXX"),
("cba", "XXXXXXXXXXXXXX"),
("wnba", "XXXXXXXXXXXXXX"),
("nba", "XXXXXXXXXXXXXX")
), 3)
val partRDD = rdd.partitionBy(new MyPartitioner)
partRDD.saveAsTextFile("output")
sc.stop()
}
/**
* 自定义分区器
* 1. 继承Partitioner
* 2. 重写方法
*/
class MyPartitioner extends Partitioner{
// 分区数量
override def numPartitions: Int = 3
// 根据数据的key值返回数据所在的分区索引,从0开始
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case "wnba" => 1
case _ => 2
}
}
}
}


package com.lotuslaw.spark.core.accbc
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.acc
* @create: 2021-12-02 15:09
* @description:
*/
object Spark_Acc {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Acc")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// 获取系统累加器
// Spark默认就提供了简单数据聚合的累加器
// 转换算子中调用累加器,如果没有行动算子的话,那么不会执行
val sumAcc = sc.longAccumulator("sum")
//sc.doubleAccumulator
//sc.collectionAccumulator
rdd.foreach(
num => {
sumAcc.add(num)
}
)
// 获取累加器的值
println(sumAcc.value)
val mapRDD = rdd.map(
num => {
sumAcc.add(num)
}
)
println(sumAcc.value)
mapRDD.collect()
println(sumAcc.value)
sc.stop()
}
}

package com.lotuslaw.spark.core.accbc
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.acc
* @create: 2021-12-02 15:09
* @description:
*/
object Spark_Acc_DIY {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Acc")
val sc = new SparkContext(sparConf)
val rdd = sc.makeRDD(List("hello", "spark", "hello"))
val wcAcc = new MyAccumulator()
// 向spark注册
sc.register(wcAcc, "wordCountAcc")
rdd.foreach(
word => {
wcAcc.add(word)
}
)
println(wcAcc.value)
sc.stop()
}
/*
自定义数据累加器:WordCount
1. 继承AccumulatorV2, 定义泛型
IN : 累加器输入的数据类型 String
OUT : 累加器返回的数据类型 mutable.Map[String, Long]
2. 重写方法(6)
*/
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
private val wcMap = mutable.Map[String, Long]()
// 判断是否初始状态
override def isZero: Boolean = {
wcMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
override def reset(): Unit = {
wcMap.clear()
}
// 获取累加器需要计算的值
override def add(v: String): Unit = {
val newCnt = wcMap.getOrElse(v, 0L) + 1
wcMap.update(v, newCnt)
}
// Driver合并多个累加器
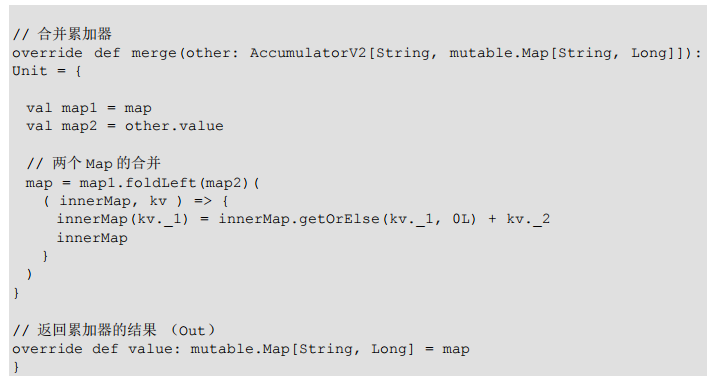
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
map2.foreach{
case (word, count) => {
val newCount = map1.getOrElse(word, 0L) + count
map1.update(word, newCount)
}
}
}
// 累加器结果
override def value: mutable.Map[String, Long] = {
wcMap
}
}
}

package com.lotuslaw.spark.core.accbc
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.acc
* @create: 2021-12-02 15:09
* @description:
*/
object Spark_Bc {
def main(args: Array[String]): Unit = {
val sparConf = new SparkConf().setMaster("local").setAppName("Acc")
val sc = new SparkContext(sparConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 封装广播变量
val bc = sc.broadcast(map)
rdd1.map{
case (w, c) => {
val l = bc.value.getOrElse(w, 0)
(w, (c, l))
}
}.collect().foreach(println)
sc.stop()
}
}
Spark案例实操#

package com.lotuslaw.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req1 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
// 统计品类的点击数量:(品类ID,点击数量)
val clickActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(6) != "-1"
}
)
val clickCountRDD = clickActionRDD.map(
action => {
val datas = action.split("_")
(datas(6), 1)
}
).reduceByKey(_ + _)
// 统计品类的下单数量
val orderActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(8) != "null"
}
)
val orderCountRDD = orderActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(8)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 统计品类的支付数量
val payActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(10) != "null"
}
)
val payCountRDD = payActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(10)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
val cogroupRDD = clickCountRDD.cogroup(orderCountRDD, payCountRDD)
val analysisRDD = cogroupRDD.mapValues {
case (clickIter, orderIter, payIter) => {
var clickCnt = 0
val iter1 = clickIter.iterator
if (iter1.hasNext) {
clickCnt = iter1.next()
}
var orderCnt = 0
val iter2 = orderIter.iterator
if (iter2.hasNext) {
orderCnt = iter2.next()
}
var payCnt = 0
val iter3 = payIter.iterator
if (iter3.hasNext) {
payCnt = iter3.next()
}
(clickCnt, orderCnt, payCnt)
}
}
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
// 将结果采集到控制台打印出来
resultRDD.foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.req
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req2 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// Q:actionRDD重复使用
// Q:cogroup性能可能较低
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
actionRDD.cache()
// 统计品类的点击数量
val clickActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(6) != "-1"
}
)
val clickCountRDD = clickActionRDD.map(
action => {
val datas = action.split("_")
(datas(6), 1)
}
).reduceByKey(_ + _)
// 统计品类的下单数量
val orderActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(8) != "null"
}
)
val orderCountRDD = orderActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(8)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 统计品类的支付数量
val payActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(10) != "null"
}
)
val payCountRDD = payActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(10)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
val rdd1 = clickCountRDD.map {
case (cid, cnt) => {
(cid, (cnt, 0, 0))
}
}
val rdd2 = orderCountRDD.map {
case (cid, cnt) => {
(cid, (0, cnt, 0))
}
}
val rdd3 = payCountRDD.map {
case (cid, cnt) => {
(cid, (0, 0, cnt))
}
}
// 将三个数据源合并在一起,统一进行聚合计算
val sourceRDD = rdd1.union(rdd2).union(rdd3)
val analysisRDD = sourceRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
resultRDD.foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.req
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req3 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// Q:存在大量的shuffle操作(reduceByKey)
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
val flatRDD = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)
// 将相同的品类ID数据进行分组聚合
val analysisRDD = flatRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
// 将统计结果进行降序处理,取前10名
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
resultRDD.foreach(println)
sc.stop()
}
}
package com.lotuslaw.spark.core.req
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req4 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 自定义累加器
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
val acc = new HotCategoryAccumulator
sc.register(acc, "hotCategory")
// 将数据转化结构
actionRDD.foreach(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
acc.add((datas(6), "click"))
} else if (datas(8) != "null"){
// 下单的场合
val ids = datas(8).split(",")
ids.foreach(
id => {
acc.add((id, "order"))
}
)
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.foreach(
id => {
acc.add((id, "pay"))
}
)
}
}
)
val accVal = acc.value
val categories = accVal.values
val sort = categories.toList.sortWith(
(left, right) => {
if (left.clickCnt > right.clickCnt) {
true
} else if (left.clickCnt == right.clickCnt) {
if (left.orderCnt > right.orderCnt) {
true
} else if (left.orderCnt == right.orderCnt) {
left.payCnt > right.payCnt
} else {
false
}
} else {
false
}
}
)
// 将结果采集到控制台打印出来
sort.take(10).foreach(println)
sc.stop()
}
case class HotCategory(cid: String, var clickCnt: Int, var orderCnt: Int, var payCnt: Int)
class HotCategoryAccumulator extends AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] {
private val hcMap = mutable.Map[String, HotCategory]()
override def isZero: Boolean = {
hcMap.isEmpty
}
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = {
new HotCategoryAccumulator()
}
override def reset(): Unit = {
hcMap.clear()
}
override def add(v: (String, String)): Unit = {
val cid = v._1
val actionType = v._2
val category: HotCategory = hcMap.getOrElse(cid, HotCategory(cid, 0, 0, 0))
if (actionType == "click") {
category.clickCnt += 1
} else if (actionType == "order") {
category.orderCnt += 1
} else if (actionType == "pay") {
category.payCnt += 1
}
hcMap.update(cid, category)
}
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
val map1 = this.hcMap
val map2 = other.value
map2.foreach{
case (cid, hc) => {
val category: HotCategory = map1.getOrElse(cid, HotCategory(cid, 0, 0, 0))
category.clickCnt += hc.clickCnt
category.orderCnt += hc.orderCnt
category.payCnt += hc.payCnt
map1.update(cid, category)
}
}
}
override def value: mutable.Map[String, HotCategory] = hcMap
}
}
package com.lotuslaw.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req5 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
actionRDD.cache()
val Top10Ids = top10Category(actionRDD)
// 过滤原始数据,保留点击和前10品类ID
val filterActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
Top10Ids.contains(datas(6))
} else {
false
}
}
)
val reduceRDD = filterActionRDD.map(
action => {
val datas = action.split("_")
((datas(6), datas(2)), 1)
}
).reduceByKey(_ + _)
// 将统计结果进行结构的转换
val mapRDD = reduceRDD.map {
case ((cid, sid), sum) => {
(cid, (sid, sum))
}
}
// 相同的品类进行分组
val groupRDD = mapRDD.groupByKey()
// 将分组后的数据进行点击量的排序,取前10名
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)
}
)
resultRDD.collect().foreach(println)
sc.stop()
}
def top10Category(actionRDD: RDD[String]) = {
val flatRDD = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)
val analysisRDD = flatRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
analysisRDD.sortBy(_._2, false).take(10).map(_._1)
}
}
package com.lotuslaw.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: lotuslaw
* @version: V1.0
* @package: com.lotuslaw.spark.core.req
* @create: 2021-12-02 15:53
* @description:
*/
object Spark_RDD_Req6 {
def main(args: Array[String]): Unit = {
// TODO: Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 读取原始日志数据
val actionRDD = sc.textFile("input/user_visit_action.txt")
val actionDataRDD = actionRDD.map(
action => {
val datas = action.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
actionDataRDD.cache()
// TODO: 对指定的页面连续跳转进行统计
val ids = List[Long](1, 2, 3, 4, 5, 6, 7)
val okflowIds = ids.zip(ids.tail)
// TODO: 计算分母
val pageidToCountMap = actionDataRDD.filter(
action => {
ids.init.contains(action.page_id)
}
).map(
action => {
(action.page_id, 1L)
}
).reduceByKey(_ + _).collect().toMap
// TODO: 计算分子
// 根据session进行分组
val sessionRDD = actionDataRDD.groupBy(_.session_id)
// 分组后,根据访问时间进行排序(升序)
val mvRDD = sessionRDD.mapValues(
iter => {
val sortList = iter.toList.sortBy(_.action_time)
val flowIds = sortList.map(_.page_id)
val pageflowIds = flowIds.zip(flowIds.tail)
pageflowIds.filter(
t => {
okflowIds.contains(t)
}
).map(
t => {
(t, 1)
}
)
}
)
val flatRDD = mvRDD.map(_._2).flatMap(list => list)
val dataRDD = flatRDD.reduceByKey(_ + _)
// TODO:计算单跳转换率
dataRDD.foreach{
case ((pageid1, pageid2), sum) => {
val lon = pageidToCountMap.getOrElse(pageid1, 0L)
println(s"页面${pageid1}跳转页面${pageid2}单跳转换率为:" + (sum.toDouble / lon))
}
}
sc.stop()
}
// 用户访问动作表
case class UserVisitAction(
date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)
}
作者:lotuslaw
出处:https://www.cnblogs.com/lotuslaw/p/15639762.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧