9-电商项目实战
导包及基础设置
import re
import os
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series, DataFrame
import seaborn as sns
from sklearn.linear_model import LinearRegression
sns.set(font_scale=1.2)
plt.rcParams['font.sans-serif'] = 'simhei'
plt.rcParams['axes.unicode_minus'] =False
驱虫市场潜力分析
# 切换目录
os.chdir(r'C:\Users\86188\Desktop\Data_Analysis\电商文本挖掘\data\驱虫剂市场')
filenames1 = glob.glob('*市场近三年交易额.xlsx')
filenames1
'''
['灭鼠杀虫剂市场近三年交易额.xlsx',
'电蚊香套装市场近三年交易额.xlsx',
'盘香灭蟑香蚊香盘市场近三年交易额.xlsx',
'蚊香加热器市场近三年交易额.xlsx',
'蚊香液市场近三年交易额.xlsx',
'蚊香片市场近三年交易额.xlsx',
'防霉防蛀片市场近三年交易额.xlsx']
'''
# 回顾一下re.search包
re.search(r'.*(?=市场)', '灭鼠杀虫剂市场近三年交易额.xlsx').group()
'''
'灭鼠杀虫剂'
'''
- 定义函数,读取单个excel文件,转换成DataFrame,改变列名, 时间列变为datetime类型,并将时间列变为index
def read_3years(filename):
colname = re.search(r'.*(?=市场)', filename).group() # 提起文件名中市场前面的文字
df = pd.read_excel(filename)
if df['时间'].dtypes == 'int64':
# 讲“时间”列的数据类型转变为datetime类型
df['时间'] = pd.to_datetime(df['时间'], unit='D', origin=pd.Timestamp('1899-12-30'))
df.rename(columns={df.columns[1]:colname}, inplace=True) # 修改第二列的列名
df.set_index('时间', inplace=True)
return df
# 分别读取七个文件,并转换成DataFrame,存入列表中
dfs = [read_3years(filename) for filename in filenames1]
# 将7个DataFrame在axis=1的方向拼接
df = pd.concat(dfs, axis=1).reset_index()
df.head()
- 查看各列的数据缺失情况
df.isna().any()
'''
时间 False
灭鼠杀虫剂 False
电蚊香套装 False
盘香灭蟑香蚊香盘 False
蚊香加热器 False
蚊香液 False
蚊香片 False
防霉防蛀片 False
dtype: bool
'''
- pandas 数据透视表
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
'''
data:dataframe格式数据
values:需要汇总计算的列,可多选
index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
aggfunc:聚合函数或函数列表,默认为平均值
fill_value:设定缺失替换值
margins:是否添加行列的总计
dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
margins_name:汇总行列的名称,默认为All
observed:是否显示观测值
'''
- 抽取df的所有月份,以供后面使用
month = df['时间'].dt.month
month
'''
0 10
1 9
2 8
3 7
4 6
5 5
6 4
7 3
8 2
9 1
10 12
11 11
12 10
13 9
14 8
15 7
16 6
17 5
18 4
19 3
20 2
21 1
22 12
23 11
24 10
25 9
26 8
27 7
28 6
29 5
30 4
31 3
32 2
33 1
34 12
35 11
Name: 时间, dtype: int64
'''
- 循环预测2018年11月、12月的各子类目的销售额
for i in [11, 12]:
dm = df[month==i] # 从df中抽取对应月份的记录
X_train = np.array(dm['时间'].dt.year).reshape(-1, 1)
y_hat = [pd.datetime(2018, i, 1)]
for j in range(1, len(dm.columns)): # 遍历对应月份的每个种类
y_train = np.array(dm.iloc[:, j]) # 获取对应种类的交易金额,作为训练样本集的标签
linear = LinearRegression()
linear.fit(X_train, y_train)
y_predict = linear.predict(np.array([2018]).reshape(-1, 1))
y_hat.append(y_predict)
newrow = DataFrame(dict(zip(df.columns, y_hat)))
df = newrow.append(df) # 将预测的结果加到df中
df.reset_index(inplace=True)
df.head()

df.drop(columns=['index'], inplace=True)
df.head()
- 删除2015年的记录
df = df[df['时间'].dt.year != 2015]
df.tail()
- 添加新列,用来存储每年的交易金额总和
df['colsum'] = df.sum(axis=1)
df.head()

- 插入一个年份列‘year’
df.insert(1, 'year', df['时间'].dt.year)
df.head()

- 根据年份分组并对每一组求和,重置索引
byyear = df.groupby('year').sum().reset_index()
byyear.head()

按照年份查看驱虫市场总体变化趋势
sns.relplot('year', 'colsum', data=byyear, kind='line', marker='o', height=4, palette='Set2')
plt.title('近三年驱虫市场趋势')
plt.xticks(byyear.year, rotation=45) # x轴刻度设置,刻度旋转
plt.xlabel('年份')
plt.ylabel('总交易额')
plt.show()
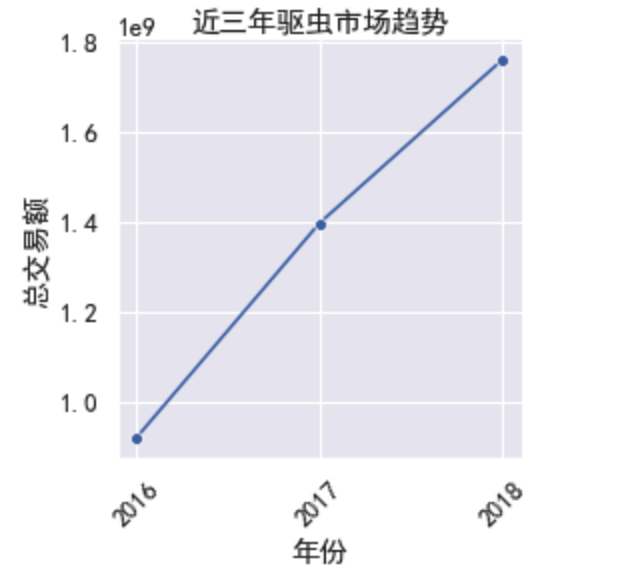
- 可以看出:近三年呈增长趋势,整个市场倾向于成长期和成熟期
查看各类目市场三年内销售额总和的变化趋势
plt.figure(figsize=(10, 6))
# 没有说明X轴与Y轴的数据,则原数据的索引值作为X轴的数据,每一列的值作为Y轴数据
# dashes设为False,因为默认只能显示6种种类,设置dashes为False后,不区分线型
sns.lineplot(data=byyear.set_index('year').iloc[:, :-1], marker='^', dashes=False)
for x,y in zip(byyear['year'], byyear['灭鼠杀虫剂']):
plt.text(x, y+0.4e8, '%.3e'%y, ha='center', va='bottom') # 在图中(x,y)位置加入文本
plt.title('近三年各类目市场销量趋势分析')
plt.xlabel('年份')
plt.ylabel('总交易额')
plt.xticks(byyear.year, rotation=45)
plt.legend(prop={'size':10})
plt.show()
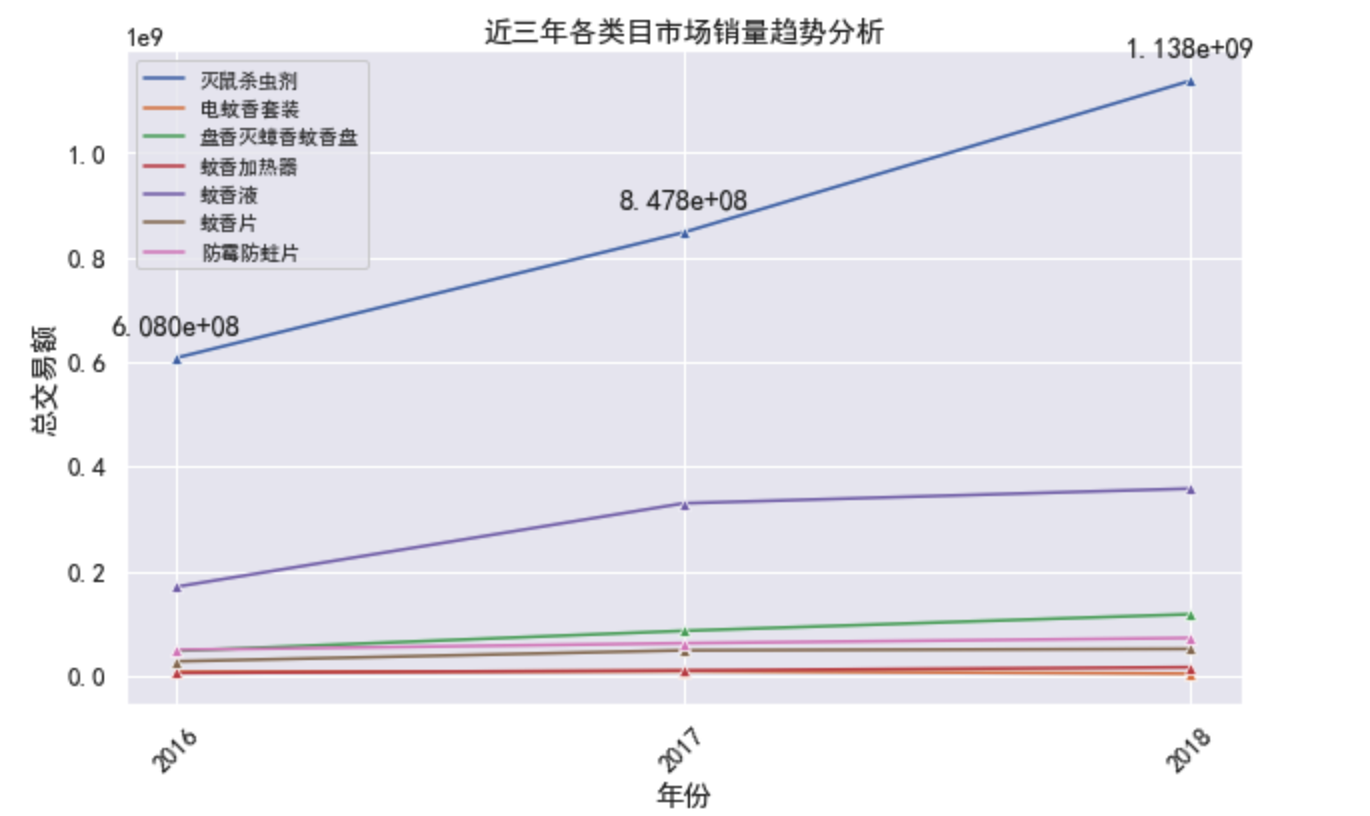
- 直观的看,灭鼠杀虫剂和蚊香液都有较大的机会
import statsmodels.api as sm
model = sm.OLS(np.array(dm.iloc[:,1]), np.array([2015,2016,2017]))
results = model.fit()
results.summary()
'''
OLS Regression Results
Dep. Variable: y R-squared (uncentered): 0.955
Model: OLS Adj. R-squared (uncentered): 0.932
Method: Least Squares F-statistic: 42.20
Date: Thu, 29 Oct 2020 Prob (F-statistic): 0.0229
Time: 08:56:08 Log-Likelihood: -51.741
No. Observations: 3 AIC: 105.5
Df Residuals: 2 BIC: 104.6
Df Model: 1
Covariance Type: nonrobust
coef std err t P>|t| [0.025 0.975]
x1 1.705e+04 2624.373 6.496 0.023 5756.519 2.83e+04
Omnibus: nan Durbin-Watson: 1.021
Prob(Omnibus): nan Jarque-Bera (JB): 0.305
Skew: -0.216 Prob(JB): 0.859
Kurtosis: 1.500 Cond. No. 1.00
'''
查看各类目市场三年销售额综合的占比
byyear

# 每个种类在当年的销售额占比
byyear_per = byyear.iloc[:,1:-1].div(byyear.colsum, axis=0)
byyear_per

byyear_per.index = byyear.year # 将byyear_per的索引值设置为byyear的year列对应的值
byyear_per
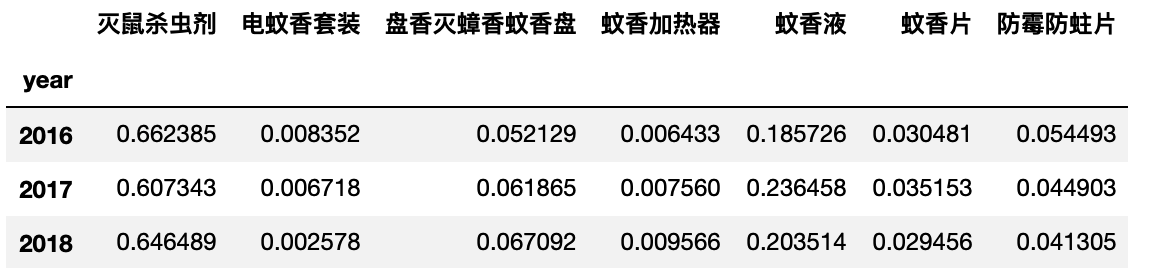
- 直接使用byyear_per这个DataFrame画图
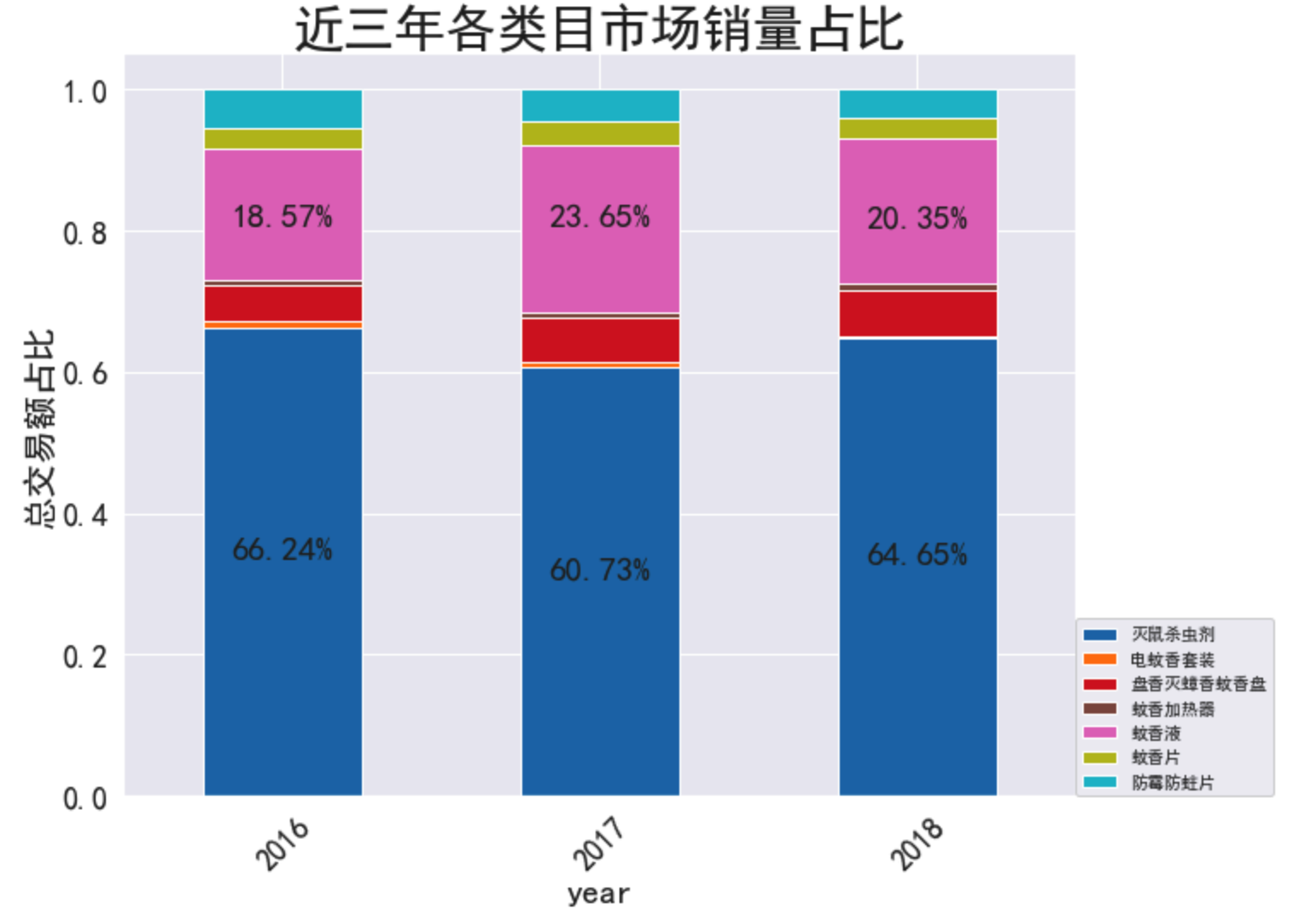
byyear_per.plot(kind='bar', stacked=True, figsize=(10, 8), colormap='tab10')
plt.legend(loc=(1,0), prop={'size':10})
plt.title('近三年各类目市场销量占比', fontdict=dict(fontsize=30))
plt.xlabel('year', fontdict=dict(fontsize=20))
plt.ylabel('总交易额占比', fontdict=dict(fontsize=20))
plt.xticks(rotation=45)
plt.tick_params(labelsize=18)
# 对于条形图,X轴位置从0开始
for x,y in zip(range(len(byyear_per)), byyear_per['灭鼠杀虫剂']):
plt.text(x, y/2, str(round(y*100,2))+'%', ha='center', va='bottom', size=20)
for m,n in zip(range(len(byyear_per)), byyear_per['蚊香液']):
plt.text(m, 0.8, str(round(n*100,2))+'%', ha='center', va='bottom', size=20)
plt.show()
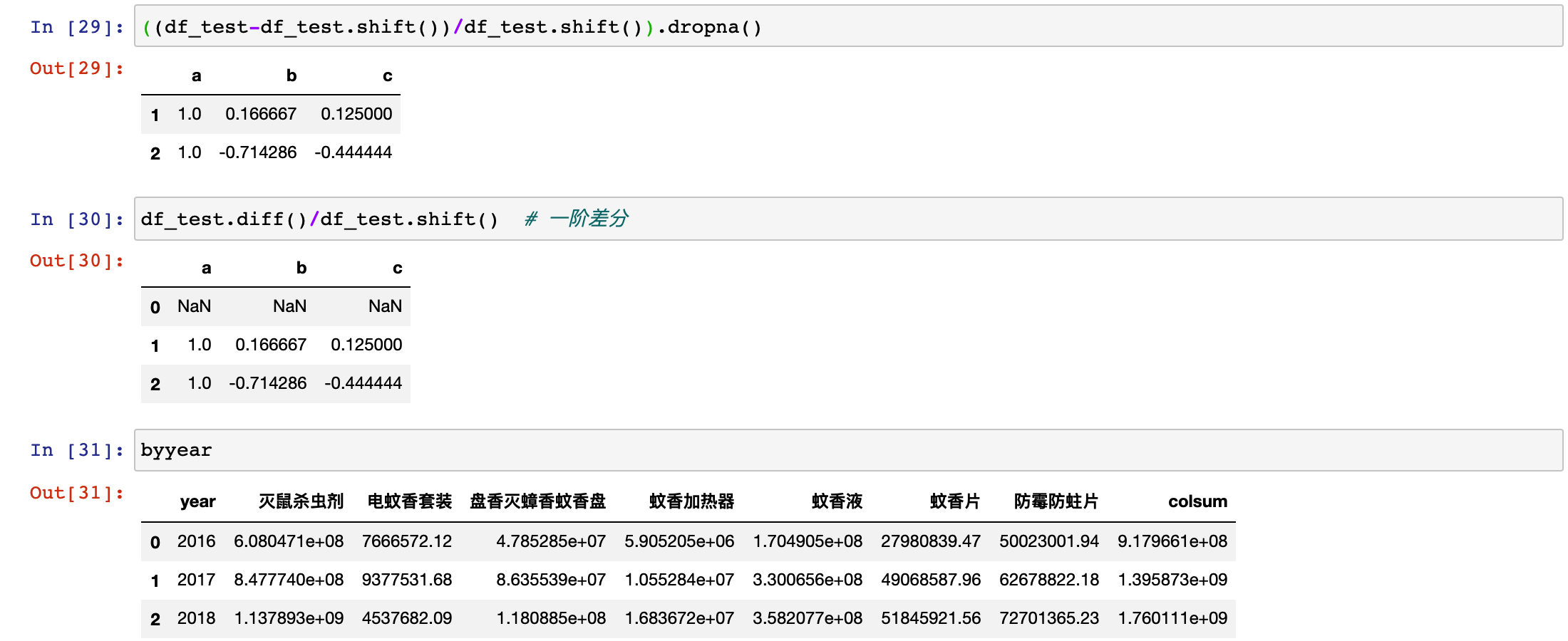
# 分别计算各产品在16-17,17-18年间的增长率
byyear_growth = (byyear.iloc[:,1:-1].diff().iloc[1:,:] / byyear.iloc[:,1:-1].shift()).dropna().reset_index(drop=True)
byyear_growth.index = ['16-17', '17-18']
byyear_growth

plt.figure(figsize=(10, 8))
sns.lineplot(data=byyear_growth, dashes=False) # 不区分线型
plt.title('近三年各类目市场年增幅')
plt.xlabel('年份')
plt.ylabel('总交易额年增幅')
plt.show()
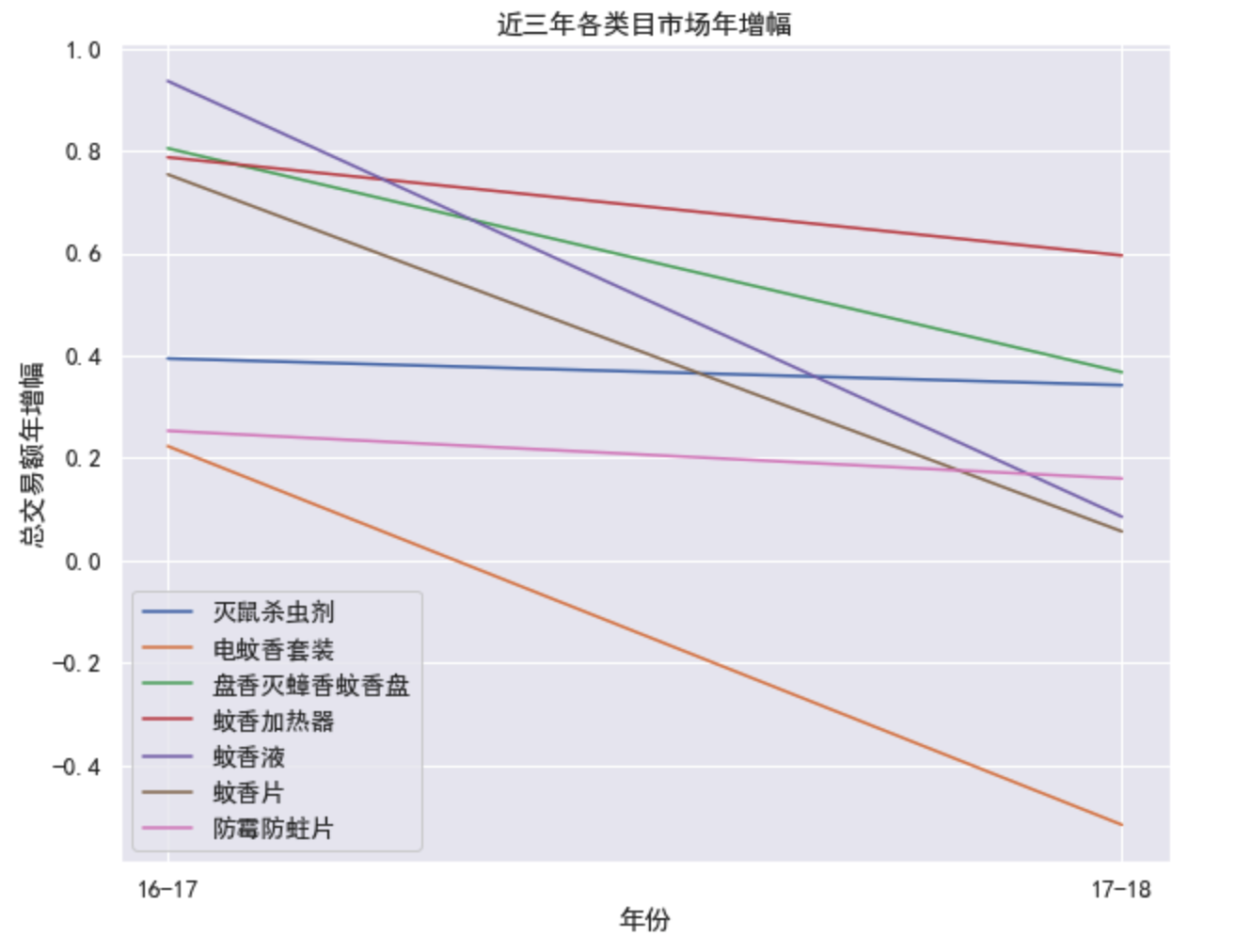
- 可见除了灭鼠杀虫剂和蚊香液增幅比较稳定,其它都有下降甚至变负
计算驱虫市场HHI
df_top100 = pd.read_excel('./top100品牌数据.xlsx')
df_top100.head()
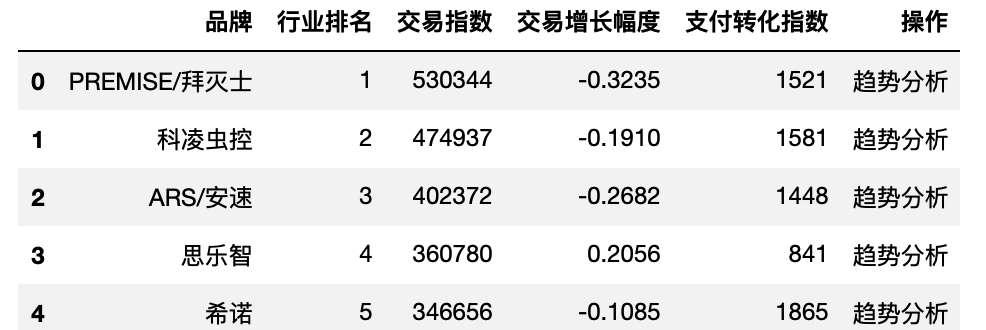
- 添加“交易指数占比”列(因为交易指数反应销售额),代表市场占有率
df_top100['交易指数占比'] = df_top100['交易指数'] / df_top100['交易指数'].sum()
df_top100.head()
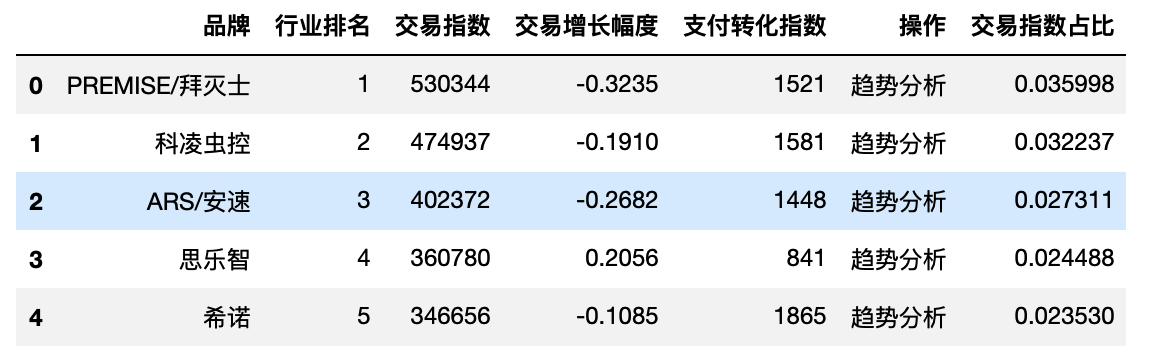
df_top100.plot(x='品牌', y='交易指数占比', kind='bar', figsize=(20,6))
plt.tick_params(labelsize=10)
plt.show()
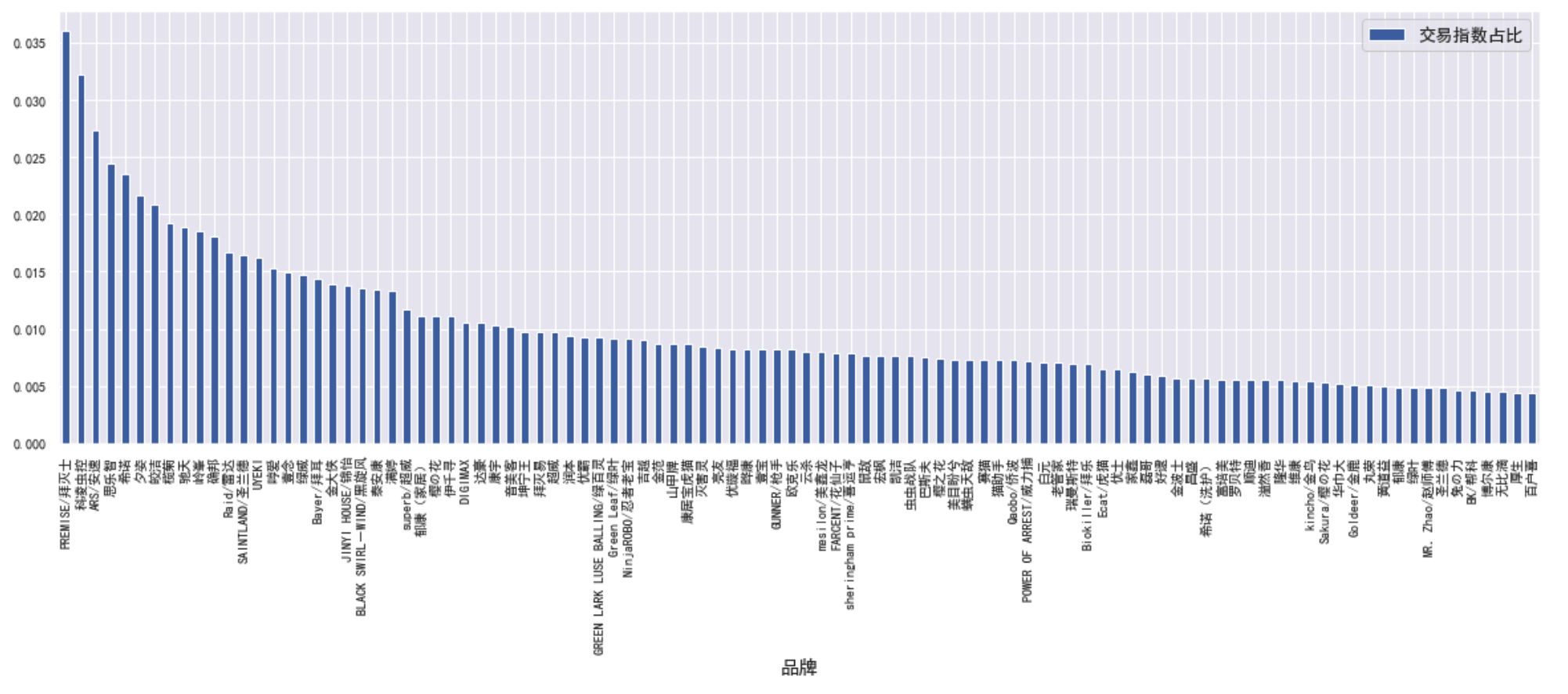
HHI = sum(df_top100['交易指数占比']**2)
print('HHI是:', str(round(HHI*100, 2))+'%')
print('等效公司数:', round(1/HHI,2))
'''
HHI是: 1.35%
等效公司数: 73.82
'''
灭鼠杀虫剂市场机会点
产品类别
os.chdir(r'../灭鼠杀虫剂细分市场/') # 切换目录
filenames2 = glob.glob('*.xlsx')
filenames2
'''
['杀虫.xlsx', '灭鼠.xlsx', '虱子.xlsx', '螨.xlsx', '蟑螂.xlsx']
'''
dfs2 = [pd.read_excel(filename) for filename in filenames2]
df2 = pd.concat(dfs2, sort=False) # sort=False关闭警告,合并列表中的5个DataFrame
df2.isna().sum()
类别 0
时间 0
页码 0
排名 0
链接 0
...
宝贝成份 6556
规格: 6556
樟脑 6556
包装 6556
产品名 6556
Length: 229, dtype: int64
col_index = df2.isna().mean() > 0.98 # 查看每一列的缺失值是否超过98%
df21 = df2.loc[:,~col_index] # 删除缺失值占比超过98%的特征
ser = Series([4,5,3,3,7,8,8,9])
ser.unique()
'''
array([4, 5, 3, 7, 8, 9], dtype=int64)
'''
ser.nunique()
'''
6
'''
col_index2 = np.array([df21[colname].nunique()==1 for colname in df21.columns])
df22 = df21.loc[:,~col_index2] # 删除特征值完全一致的特征
len(df22.columns)
'''
37
'''
col_index3 = df22.columns.get_loc('药品登记号') # 获取“药品登记号”列的索引位置
df23 = df22.iloc[:,:col_index3]
len(df23.columns)
'''
24
'''
useless = ['时间','链接','主图链接','主图视频链接','页码','排名','宝贝标题','运费','下架时间','旺旺']
df24 = df23.drop(columns=useless)
len(df24.columns)
'''
14
'''
df24.dtypes
'''
类别 object
宝贝ID int64
销量(人数) int64
售价 float64
预估销售额 float64
评价人数 float64
收藏人数 int64
地域 object
店铺类型 object
品牌 object
型号 object
净含量 object
适用对象 object
物理形态 object
dtype: object
'''
df25 = df24.astype({'宝贝ID':'object'})
df25.reset_index(drop=True, inplace=True)
df25.dtypes
'''
类别 object
宝贝ID object
销量(人数) int64
售价 float64
预估销售额 float64
评价人数 float64
收藏人数 int64
地域 object
店铺类型 object
品牌 object
型号 object
净含量 object
适用对象 object
物理形态 object
dtype: object
'''
df25.describe()
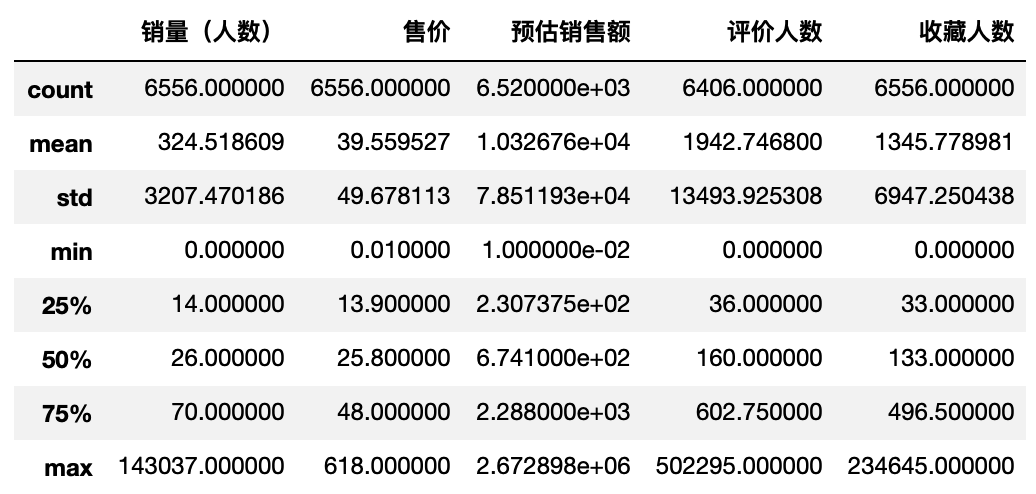
df25.head()
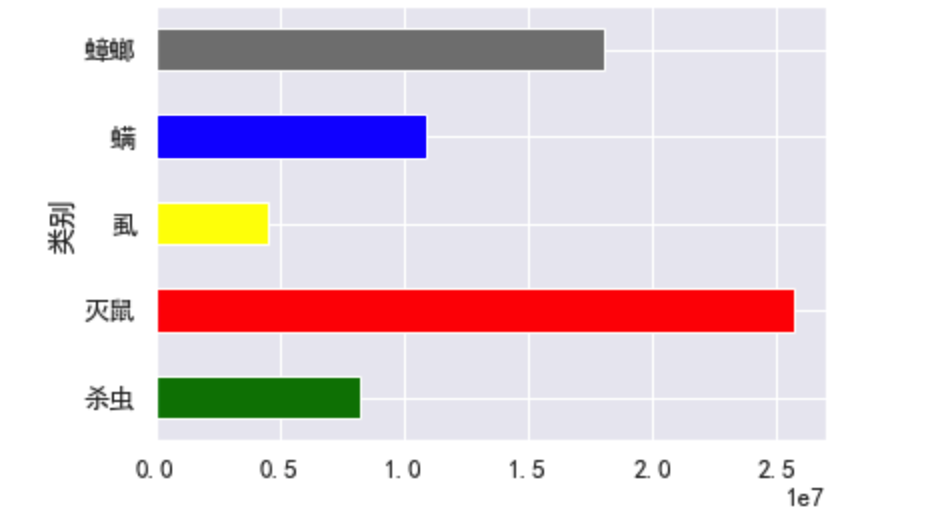
byclass = df25['预估销售额'].groupby(df25['类别']).sum()
byclass.plot.barh(color=['green', 'red', 'yellow', 'blue', 'grey'])
plt.show()
byclass.plot.pie(autopct='%.2f%%') # 使用Series对象绘制饼图
plt.show()

- 可以看出重点需要研究的市场是灭鼠和蟑螂,这里我们选择灭鼠
灭鼠类别分析
# 选择灭鼠数据
df26 = df25[df25['类别']=='灭鼠']
df26.head()
bins = [0,50,100,150,200,250,300,500] # 售价划分刻度
lables = ['0_50','50_100','100_150','150_200','200_250','250_300','300以上']
# 划分价格区间并将其作为一列添加到原始的DATa Frame中
df26['价格区间'] = pd.cut(df26['售价'],bins=bins,labels=lables,include_lowest=True)
df26.head()

- 编写函数,根据指定字段分组,组装新的DataFrame
def by_function(df,by,sort='单宝贝平均销售额'):
bytype = df.groupby(by).sum().loc[:,['预估销售额']] # 特别注意,抽取的列名加中括号保证是DataFrame
bytype['销售额占比'] = bytype['预估销售额'] / bytype['预估销售额'].sum()
bytype['宝贝数'] = df.groupby(by).nunique()['宝贝ID']
bytype['宝贝数占比'] = bytype['宝贝数'] / bytype['宝贝数'].sum()
bytype['单宝贝平均销售额'] = bytype['预估销售额'] / bytype['宝贝数']
bytype['相对竞争度'] = 1 - (bytype['单宝贝平均销售额']-bytype['单宝贝平均销售额'].min())/(bytype['单宝贝平均销售额'].max()-bytype['单宝贝平均销售额'].min())
if sort:
bytype.sort_values(sort, ascending=False, inplace=True)
return bytype
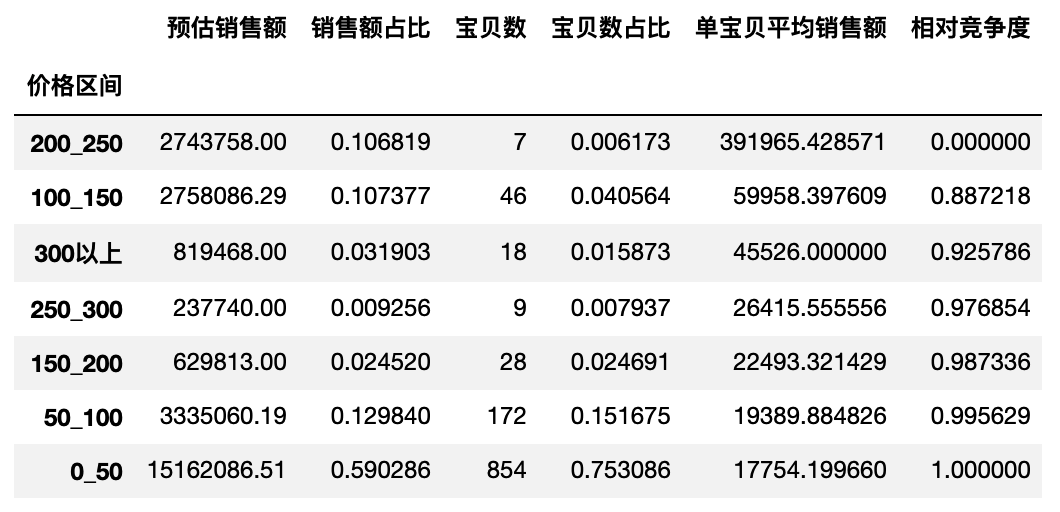
by_price = by_function(df26,'价格区间')
by_price
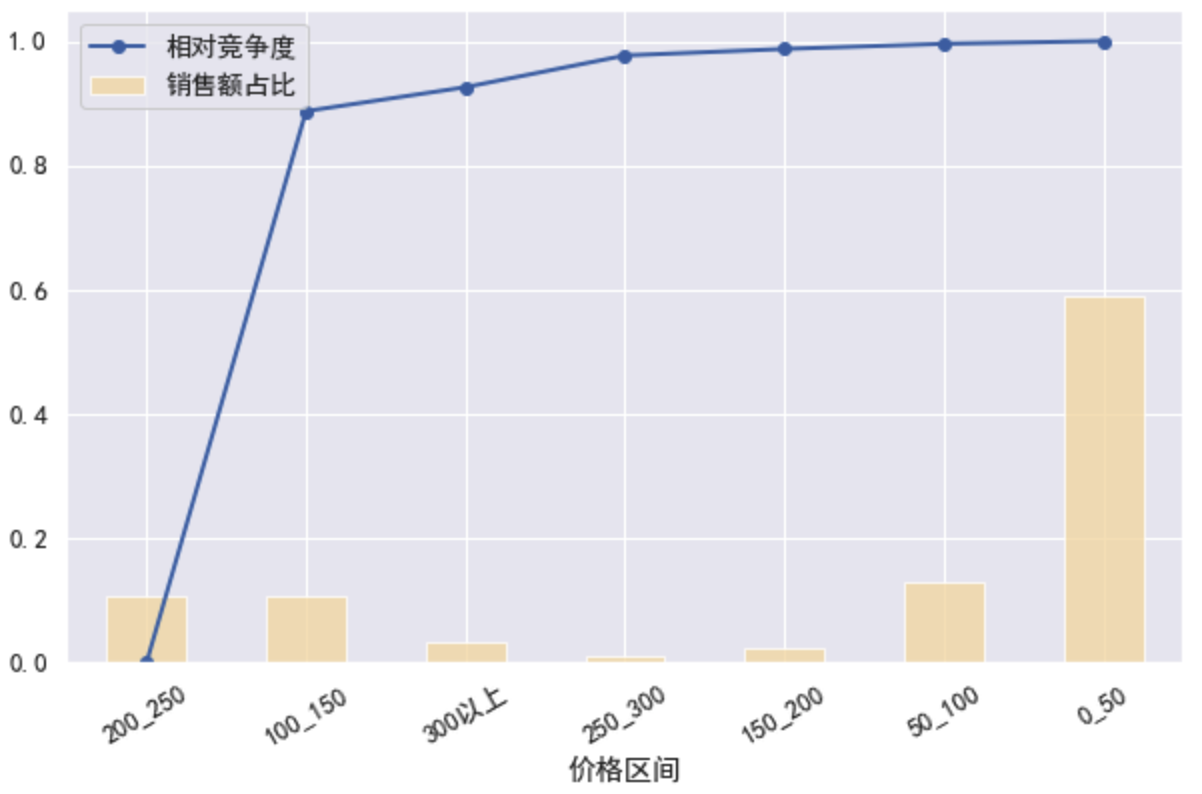
- 编写绘图函数绘制“相对竞争度”和“销售额占比”
def draw_plot(df,figsize=(10,6),rotation=30):
ax = df.plot(y='相对竞争度', marker='o',figsize=figsize, c='b',lw=2)
df.plot(y='销售额占比',kind='bar',color='wheat',alpha=0.8,ax=ax)
plt.legend(loc=2)
plt.xticks(rotation=rotation)
plt.show()
draw_plot(by_price)
-
结果依单宝贝销售额降序,即依竞争度升序,这里销售额占比可以理解为市场份额
-
可见0-50容量大,竞争大,大容量市场(对比的是50-100,容量小,竞争稍小)
-
200-250,竞争小,做高价市场的优先选择,属于机会点
-
可见我们喜欢的类目是:市场份额高(表示更适合大众),相对竞争度低(没人抢).也就是找到闷声发大财的那些个分类去分蛋糕
灭鼠类别0_50细分价格市场
df26.head()

# 选择灭鼠种类,价格区间在“0-50”的数据作为DataFrame
df50 = df26[df26['价格区间']=='0_50']
df50.head()

bins2 = [0,10,20,30,40,50] # 售价划分刻度
lables2 = ['0_10','10_20','20_30','30_40','40_50']
# 划分价格区间并将其作为一列添加到原始的DataFrame中
df50['价格子区间'] = pd.cut(df50['售价'],bins=bins2,labels=lables2,include_lowest=True)
df50.head()
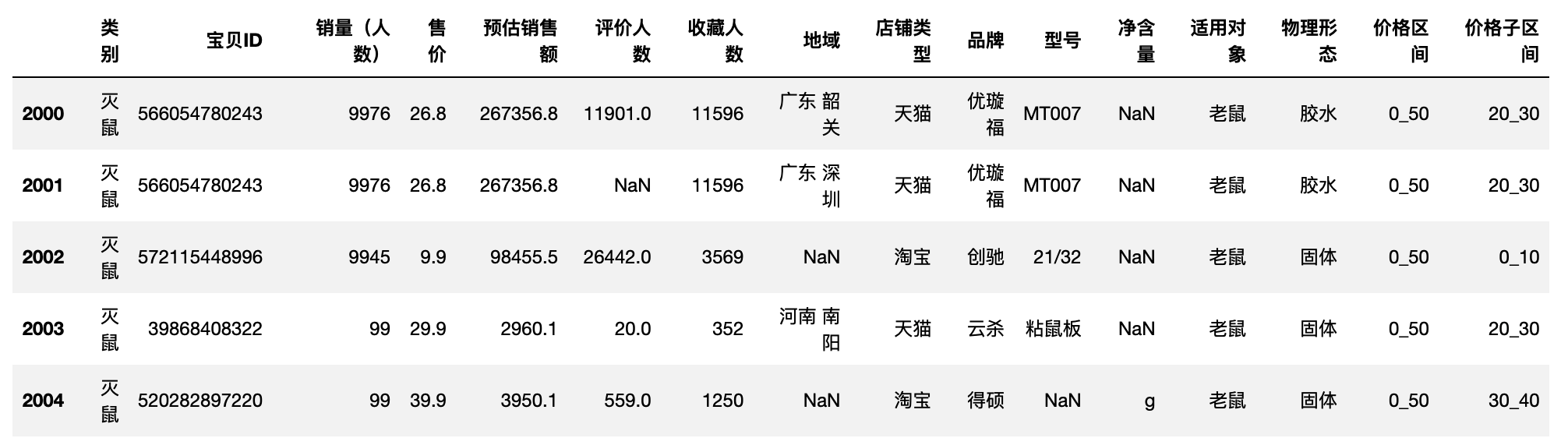
byprice_sub = by_function(df50,'价格子区间')
draw_plot(byprice_sub)
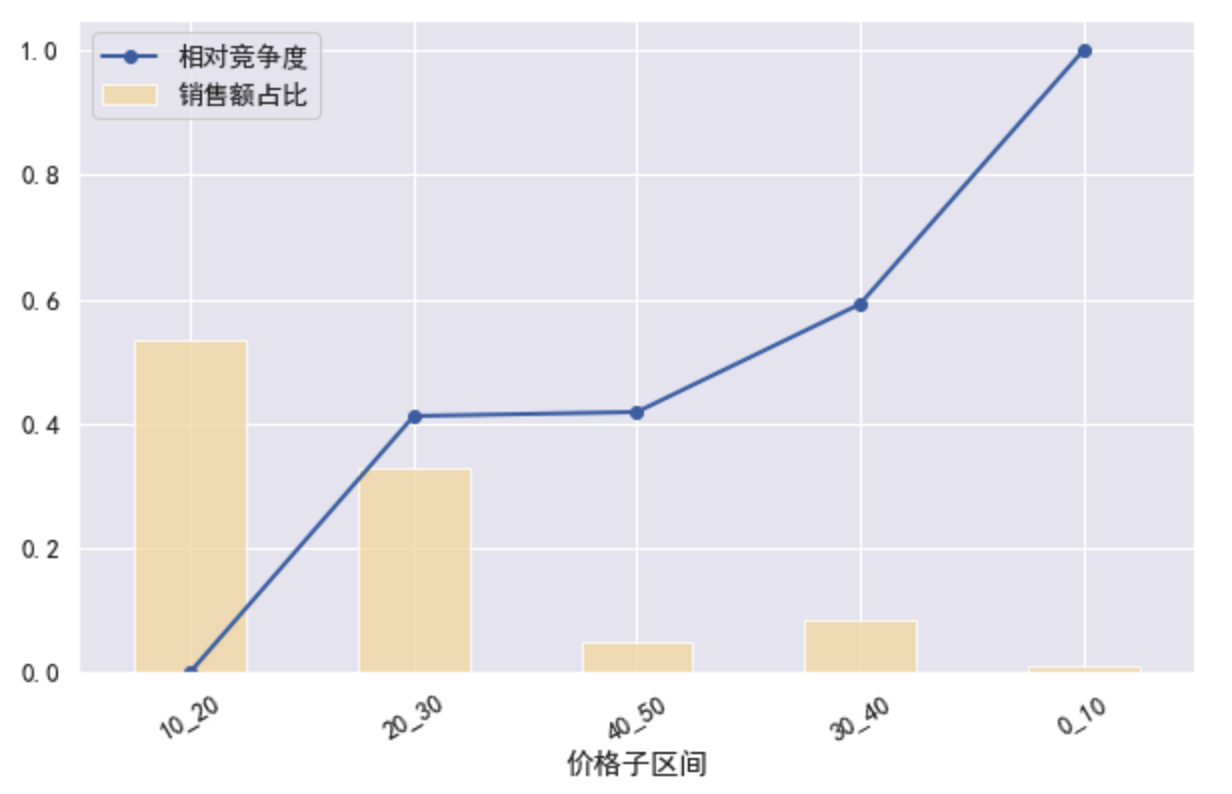
- 可见10-20竞争度低,容量大,优选,20-30也不错
- 200-250细分市场也是同样的分析思路
# 选择灭鼠种类,价格区间在“0-50”的数据作为DataFrame
df200_250 = df26[df26['价格区间']=='200_250']
df200_250.head()
bins3 = [200,210,220,230,240,250] # 售价划分刻度
lables3 = ['200_210','210_220','220_230','230_240','240_250']
# 划分价格区间并将其作为一列添加到原始的DataFrame中
df200_250['价格子区间'] = pd.cut(df200_250['售价'],bins=bins3,labels=lables3,include_lowest=True)
df200_250.head()
byprice_sub2 = by_function(df200_250,'价格子区间')
figsize=(10,6)
ax = byprice_sub2.plot(y='相对竞争度', marker='o',figsize=figsize, c='b',lw=2)
byprice_sub2.plot(y='销售额占比',kind='bar',color='wheat',alpha=0.8,ax=ax)
plt.legend(loc=4)
plt.xticks(rotation=45)
plt.show()

-
可见210-220竞争度低,容量大,优选
-
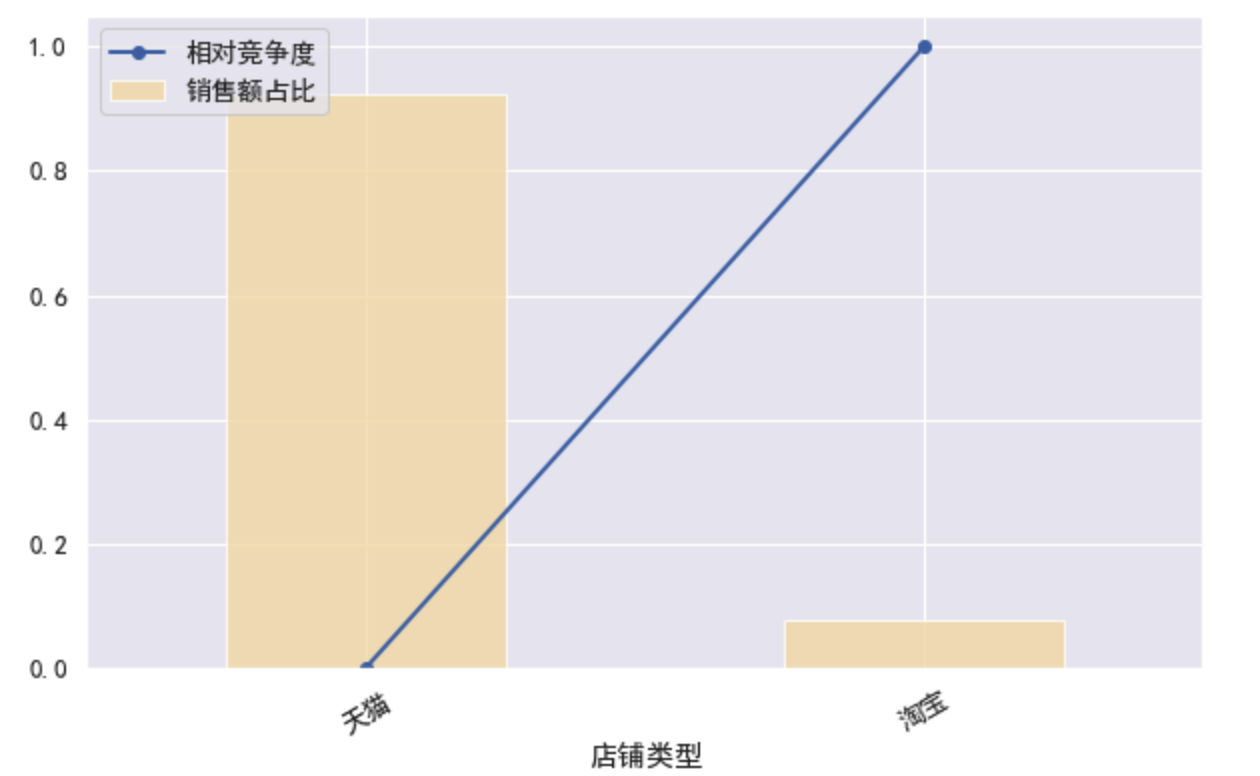
根据店铺类型分组并绘图
byshop = by_function(df50,'店铺类型')
draw_plot(byshop)
- 选取预估销售额排名前5%的商品,按照型号分组,并按照预估销售额排序并绘图
byshape = by_function(df50,'型号', sort='预估销售额')
df95 = byshape[byshape['预估销售额']>byshape['预估销售额'].quantile(0.95)] # 分位数
draw_plot(df95,rotation=90)
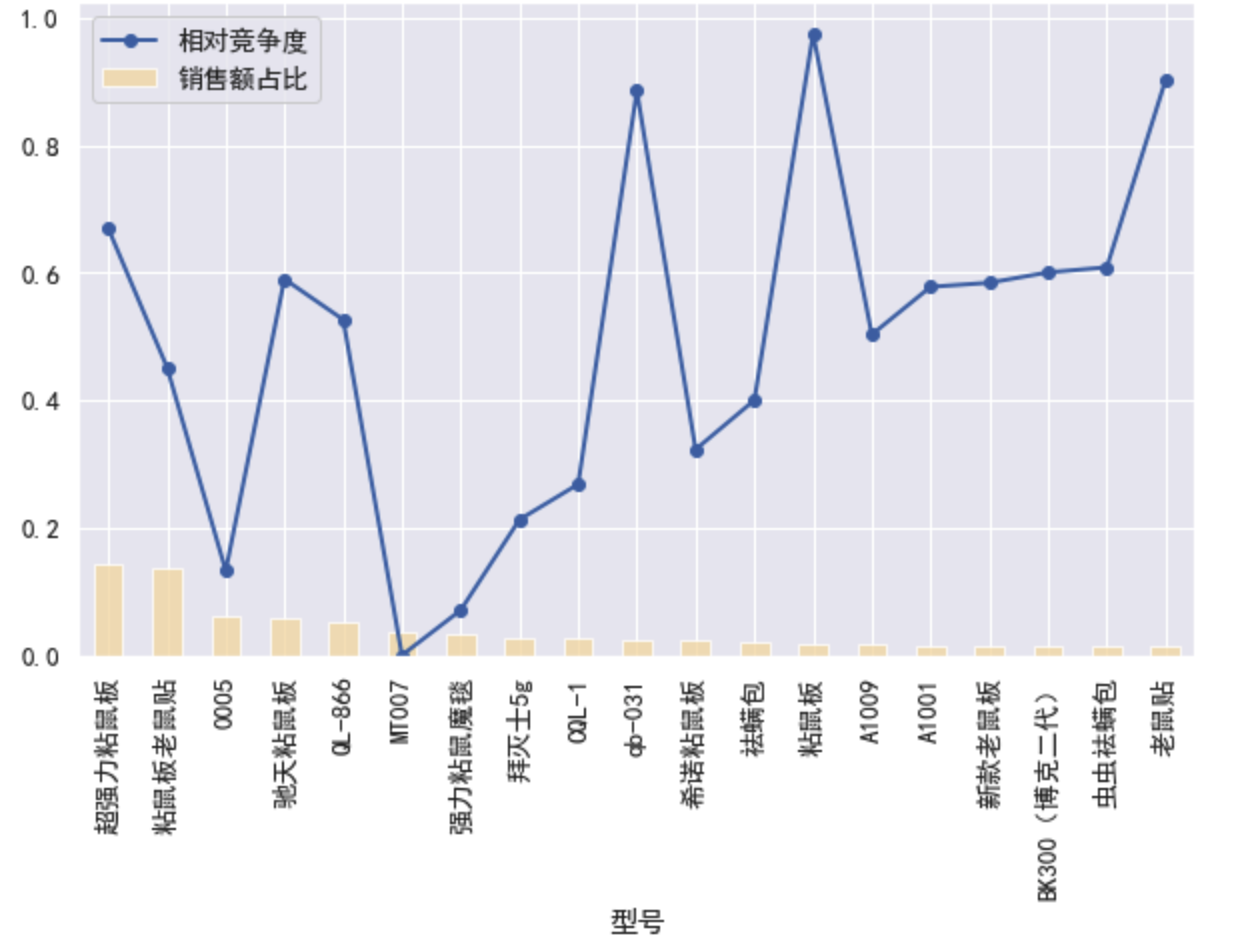
- 可见虽然粘鼠板市场份额普遍较高,但是0005,MT007在竞争度上有明显的优势
by_wuli = by_function(df50, '物理形态')
draw_plot(by_wuli)
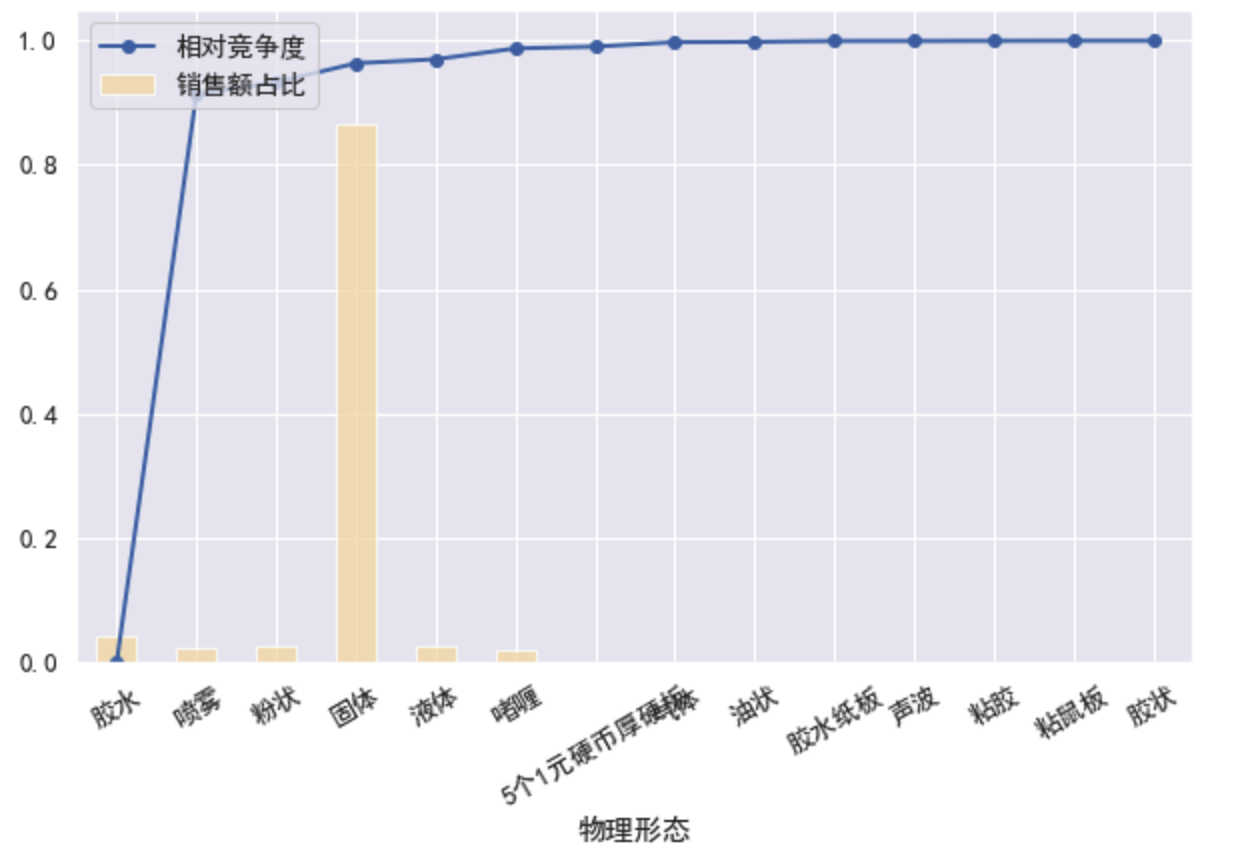
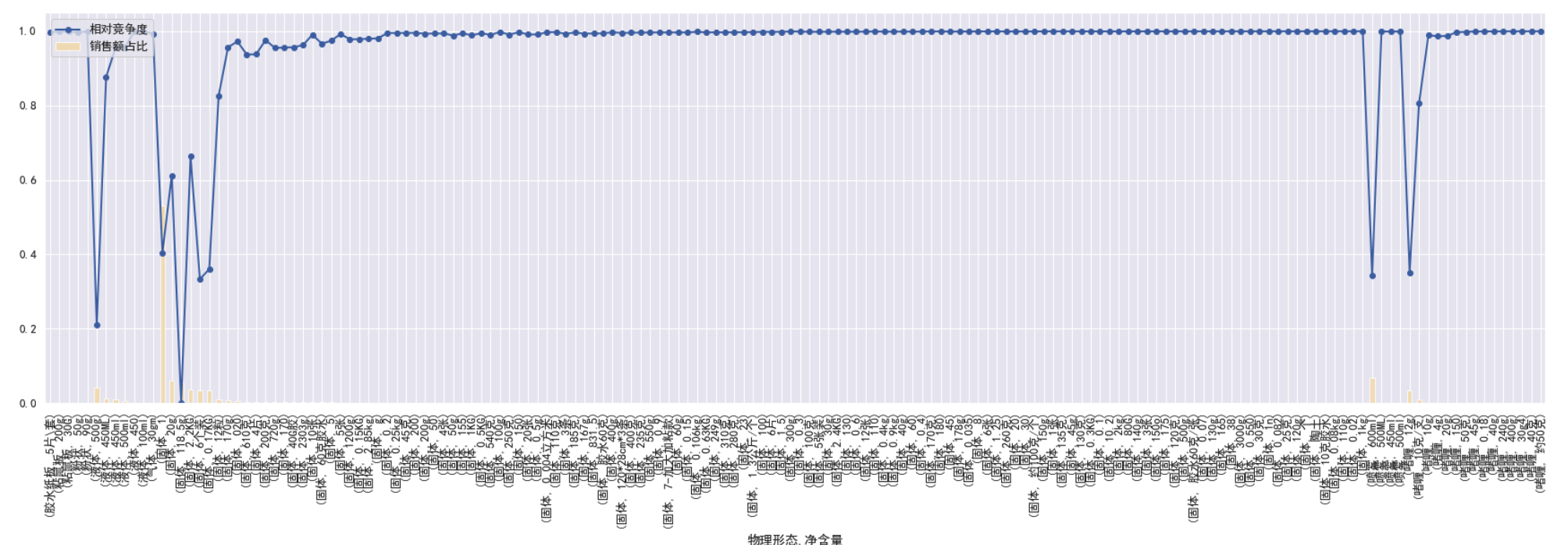
- 通过['物理形态','净含量']分组,通过['物理形态','预估销售额']排序;并制图
by_common = by_function(df50,['物理形态','净含量'],sort=['物理形态','预估销售额'])
draw_plot(by_common,figsize=(30,8),rotation=90)
竞争分析——产品类目,适用对象
os.chdir(r'../竞争数据/商品销售数据/') # 切换目录
filenames3 = glob.glob('*.xlsx')
filenames3
'''
['安速家居近30天销售数据.xlsx', '拜耳近30天销售数据.xlsx', '科凌虫控旗舰店近30天销售数据.xlsx']
'''
def read_sales(filename):
df = pd.read_excel(filename)
useless = ['序号','店铺名称','商品名称','主图链接','商品链接']
df.drop(columns=useless, inplace=True)
return df
dfs3 = [read_sales(filename) for filename in filenames3]
df_bai = dfs3[1] # 拜耳的DataFrame
df_an = dfs3[0]
df_ke = dfs3[2]
- 通过类目分组,对各个公司30天销售记录分组,并画饼图
df_bai_category = df_bai.groupby('类目').sum() # 通过类目分组并求和
df_an_category = df_an.groupby('类目').sum()
df_ke_category = df_ke.groupby('类目').sum()
df_bai_category

current_palette = sns.color_palette('bright')
sns.set_palette(current_palette)
fig, axes = plt.subplots(1,3,figsize=(16, 5)) # 规划绘图区域,返回图像和绘图区域数组
ax = axes[0] # 选择第一个绘图区域
df_bai_category['销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=30, title='拜尔')
ax.set_ylabel('')
ax = axes[1]
df_an_category['30天销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=60, title='安速')
ax.set_ylabel('')
ax = axes[2]
df_ke_category['30天销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=90, title='科凌')
ax.set_ylabel('')
plt.show()
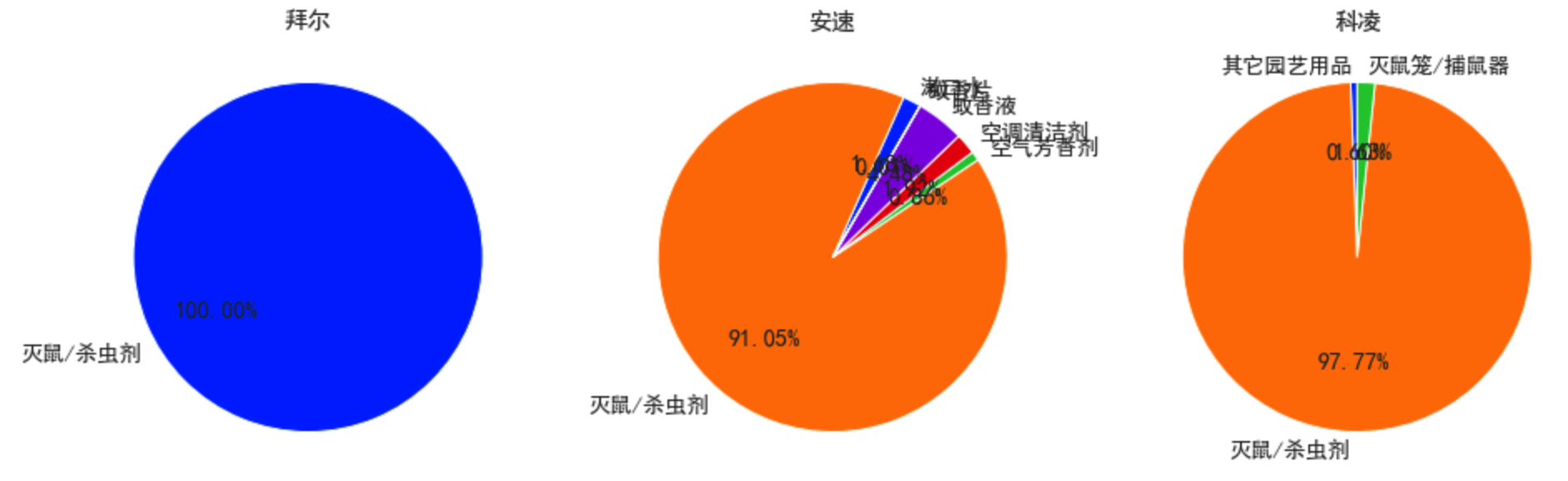
- 可见拜耳只有一个市场,其他的有不同市场,但主要市场都是灭鼠杀虫剂
# 看不清可以画复合饼图
current_palette = sns.color_palette('bright')
sns.set_palette(current_palette)
plt.figure(figsize=(16,5))
axes1 = plt.subplot(1,3,1)
axes1.pie(df_bai_category['销售额'],labels=df_bai_category.index, autopct='%.2f%%',startangle=30,shadow=True)
axes1.set_title('拜耳')
axes2 = plt.subplot(1,3,2)
axes2.pie(df_an_category['30天销售额'],labels=df_an_category.index, autopct='%.2f%%',startangle=30,shadow=True, explode=[0.4]*6)
axes2.set_title('安速')
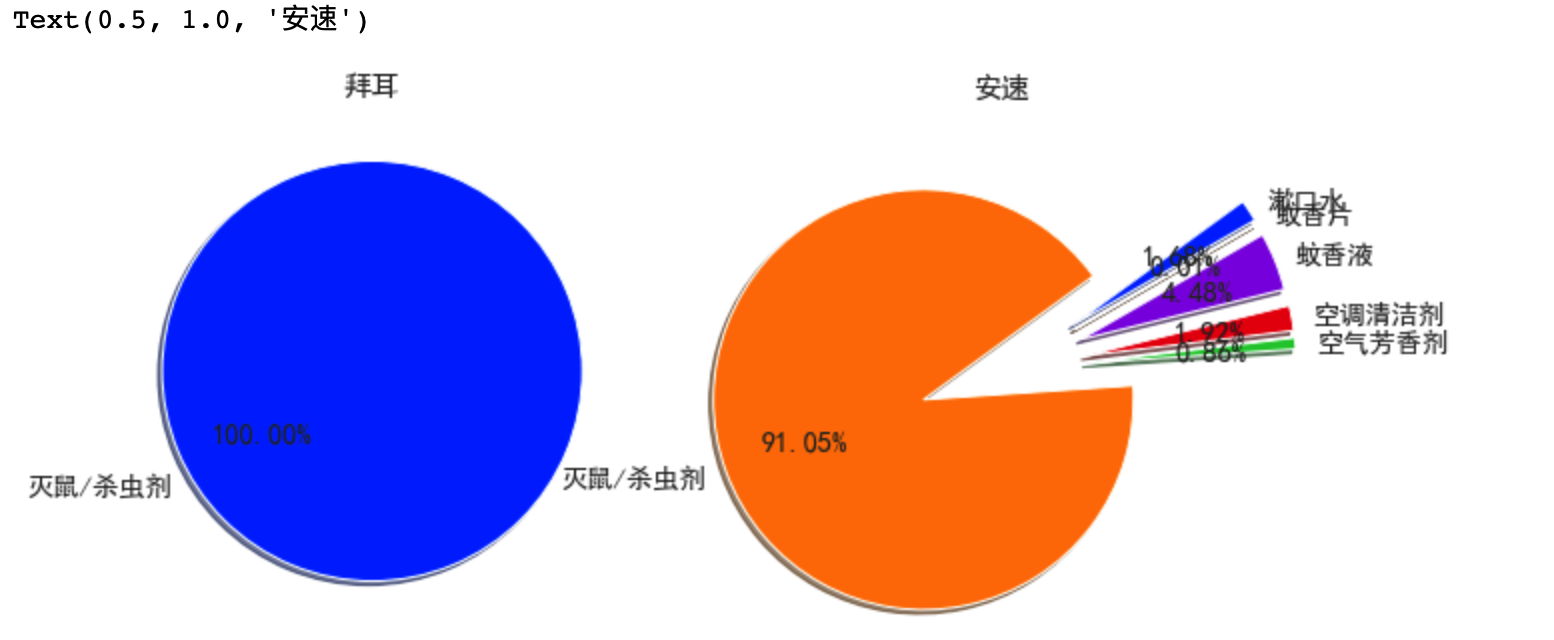
- 通过适用对象分组,对各个公司30天销售记录分组,并画饼图
df_bai_use = df_bai.groupby('使用对象').sum() # 通过类目分组并求和
df_an_use = df_an.groupby('适用对象').sum()
df_ke_use = df_ke.groupby('适用对象').sum()
current_palette = sns.color_palette('bright')
sns.set_palette(current_palette)
fig, axes = plt.subplots(1,3,figsize=(16, 5)) # 规划绘图区域,返回图像和绘图区域数组
ax = axes[0] # 选择第一个绘图区域
df_bai_use['销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=30, title='拜尔')
ax.set_ylabel('')
ax = axes[1]
df_an_use['30天销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=60, title='安速')
ax.set_ylabel('')
ax = axes[2]
df_ke_use['30天销售额'].plot.pie(autopct='%.2f%%', ax=ax, startangle=90, title='科凌')
ax.set_ylabel('')
plt.show()
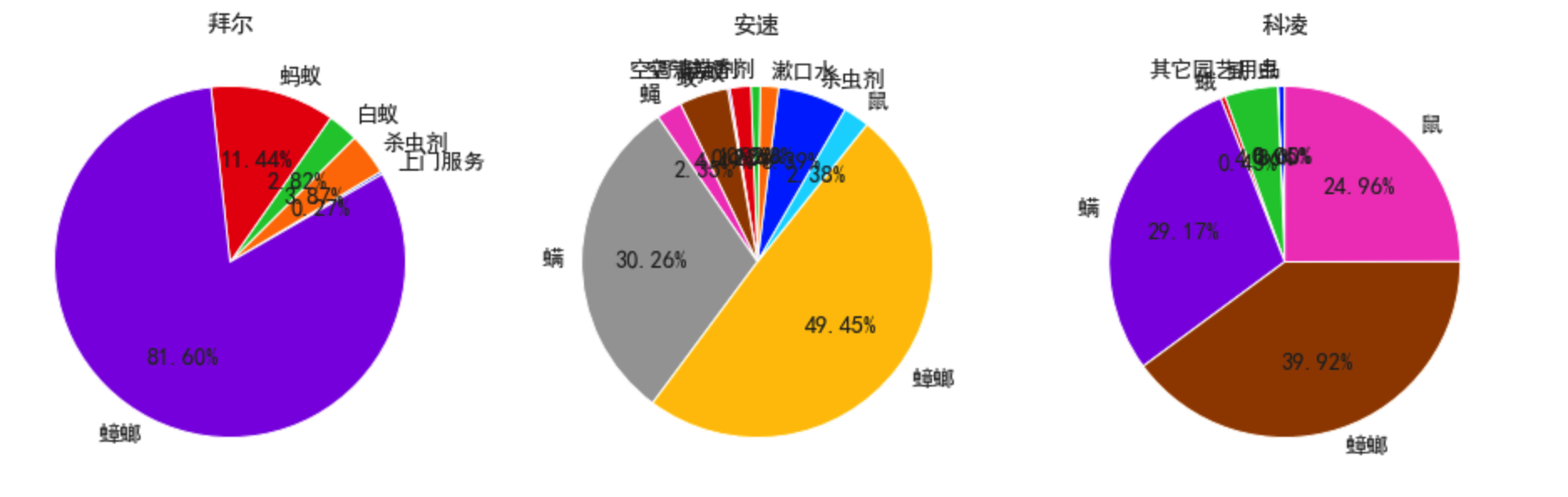
- 拜耳的主要对象是蟑螂,而另外两家除此之外还有螨,鼠
- 而从之前的分析看灭鼠和蟑螂的整体市场份额都大
- 应该开拓新市场,尤其是灭鼠,也考察其他两家都开拓的螨市场
竞争分析-产品结构
拜耳公司产品结构分析
os.chdir(r'../商品交易数据/')
filenames4 = glob.glob('*.xlsx')
filenames4
'''
['安速全店商品交易数据.xlsx', '拜耳全店商品交易数据.xlsx', '科凌虫控全店商品交易数据.xlsx']
'''
df_bai_trade = pd.read_excel(filenames4[1])
df_bai_trade.head()

# 根据“商品”进行分组,组装成一个新的DataFrame并返回
def product_func(df):
df_pro = df.groupby('商品').mean().loc[:,['交易增长幅度']] # 商品分组求均值,获取交易增长幅度列
df_pro['交易金额'] = df.groupby('商品').sum().loc[:,'交易金额']
df_pro['交易金额占比'] = df_pro['交易金额'] / df_pro['交易金额'].sum()
df_pro['商品个数'] = df.groupby('商品').count()['交易金额']
df_pro.reset_index(inplace=True)
return df_pro
# 根据商品分类对拜耳的DataFrame重组
df_bai_product = product_func(df_bai_trade)
df_bai_product.head()
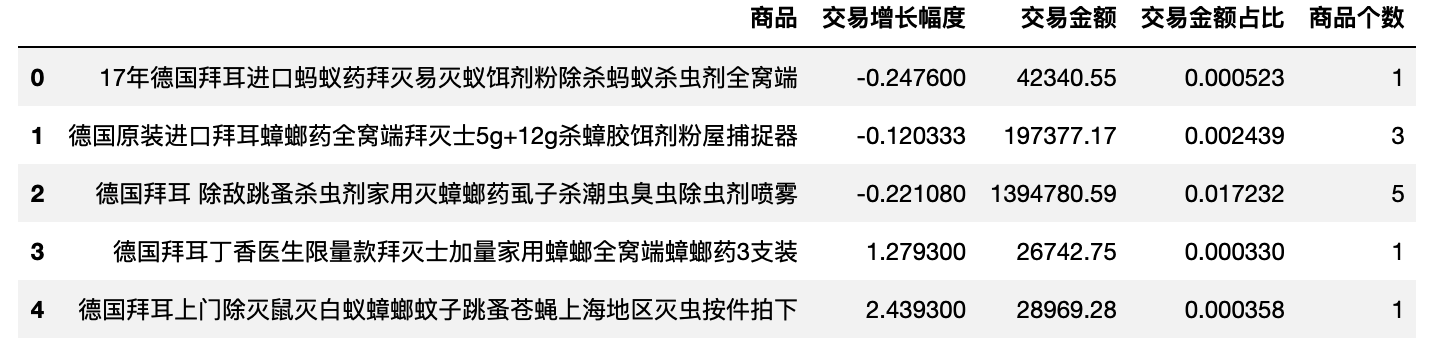
df_bai_product.describe()
- 编写盖帽函数,将0.9分位数以上的数据,都替换为0.9分位数
# 盖帽法
def block(ser):
qu = ser.quantile(0.9) # 获取0.9分位数
result = ser.mask(ser>qu, qu) # 将大于0.9分位数的数据,替换成0.9分位数
return result
def block_product(df):
df_copy = df.copy()
df_copy['交易增长幅度'] = block(df_copy['交易增长幅度'])
df_copy['交易金额占比'] = block(df_copy['交易金额占比'])
return df_copy
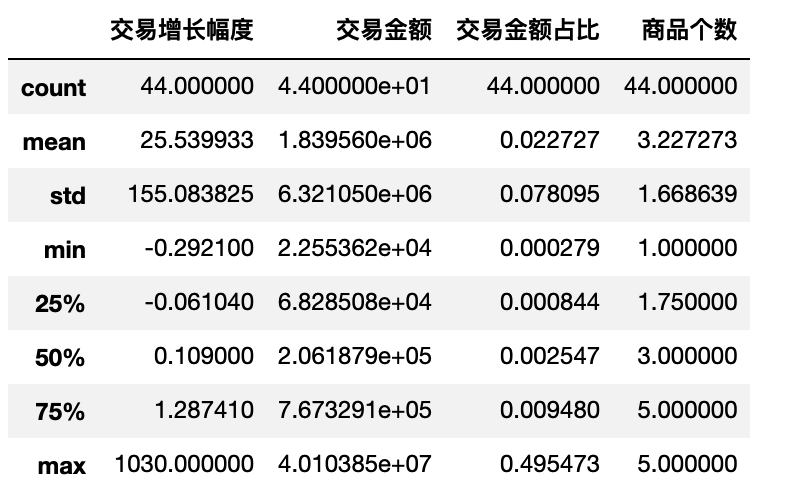
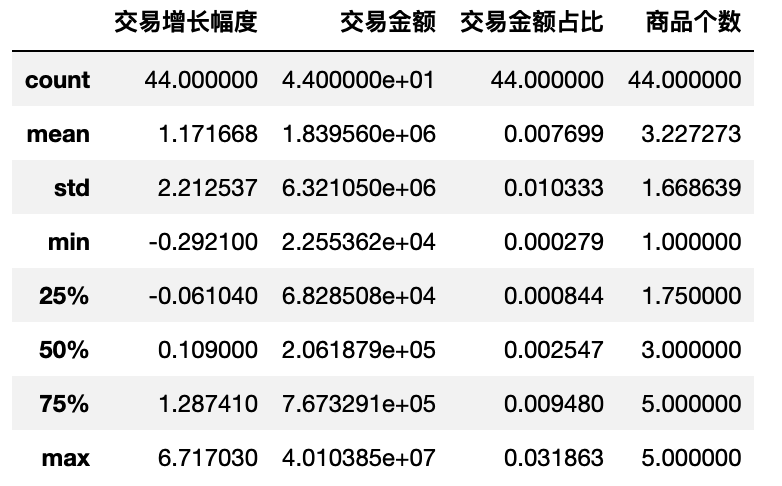
- 调用编写的盖帽函数,将两列“冒尖”的数据进行盖帽
df_bai_block = block_product(df_bai_product)
df_bai_block.describe()
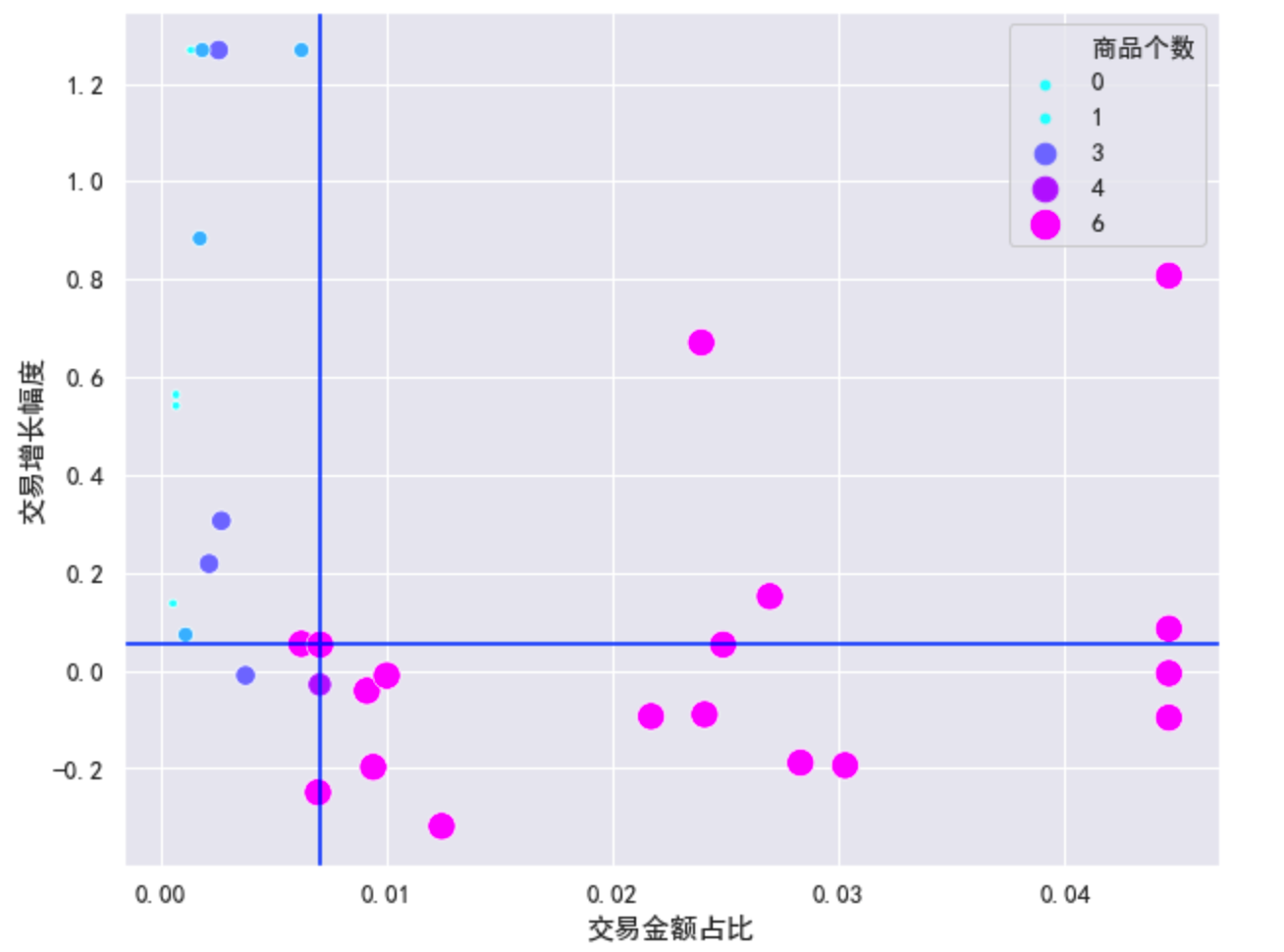
- 绘制波士顿矩阵
def plotBCG(df,mean=False,q1=0.5,q2=0.5):
plt.subplots(figsize=(10,8))
ax = sns.scatterplot('交易金额占比','交易增长幅度',data=df,
hue='商品个数',size='商品个数',sizes=(20,200),
palette='cool') # 绘制散点图
# for i in range(len(df)):
# ax.text(df['交易金额占比'][i],df['交易增长幅度'][i],i)
if mean:
plt.axvline(df['交易金额占比'].mean())
plt.axhline(df['交易增长幅度'].mean())
else:
plt.axvline(df['交易金额占比'].quantile(q1))
plt.axhline(df['交易增长幅度'].quantile(q2))
plt.show()
plotBCG(df_bai_block)

- 自定义区分产品结构的函数
def extractBCG(df,q1=0.5,q2=0.5,sort='交易金额占比'):
star = df.loc[(df['交易金额占比']>=df['交易金额占比'].quantile(q1))&
(df['交易增长幅度']>=df['交易增长幅度'].quantile(q2)),:]
star = star.sort_values(sort, ascending=False)
cow = df.loc[(df['交易金额占比']>=df['交易金额占比'].quantile(q1))&
(df['交易增长幅度']<df['交易增长幅度'].quantile(q2)),:]
cow = cow.sort_values(sort, ascending=False)
question = df.loc[(df['交易金额占比']<df['交易金额占比'].quantile(q1))&
(df['交易增长幅度']>=df['交易增长幅度'].quantile(q2)),:]
qusetion = question.sort_values(sort, ascending=False)
return star, cow, question
star,cow,question = extractBCG(df_bai_product)
star1,cow1,question1 = extractBCG(df_bai_product, sort='交易增长幅度')
star

star1

cow
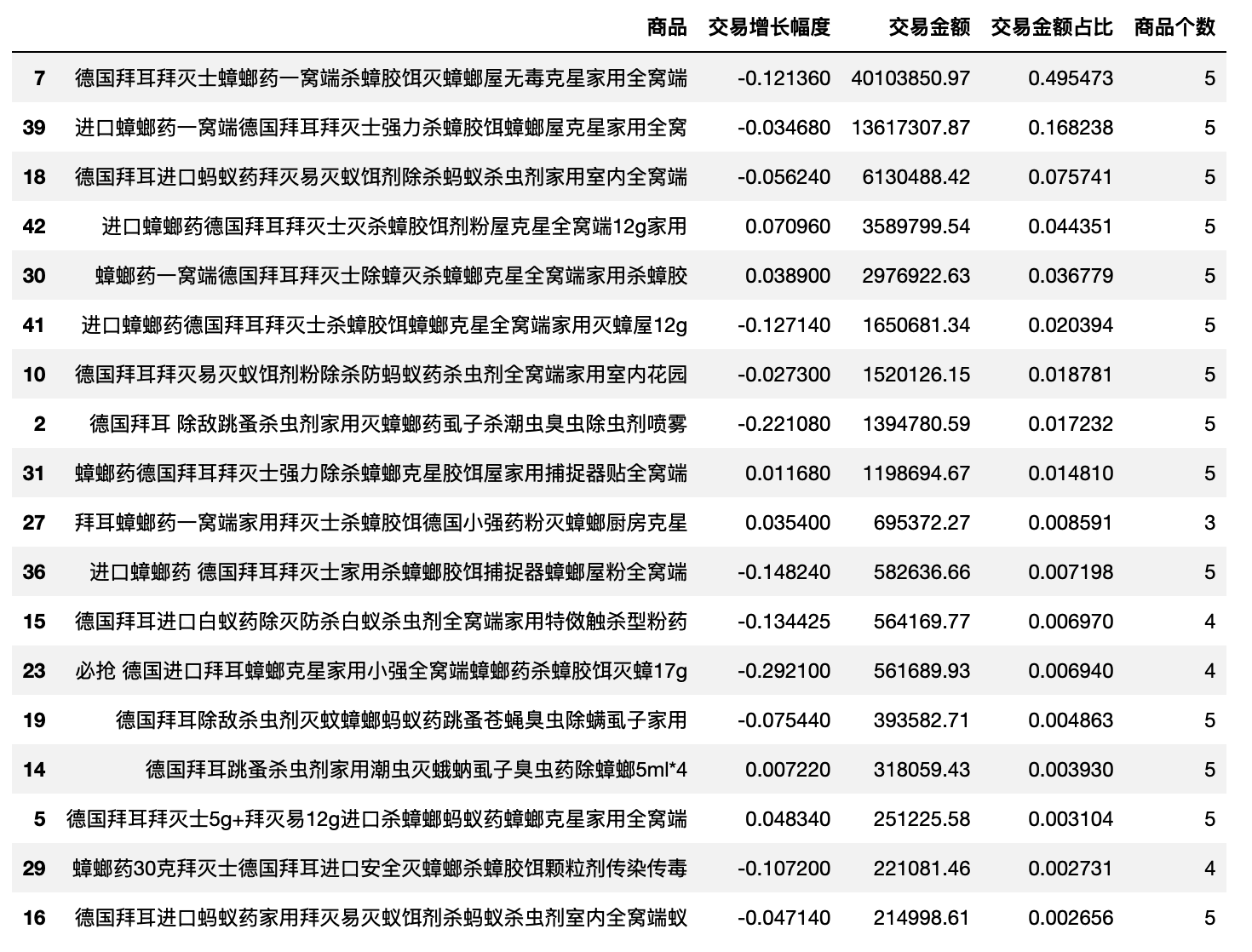
question
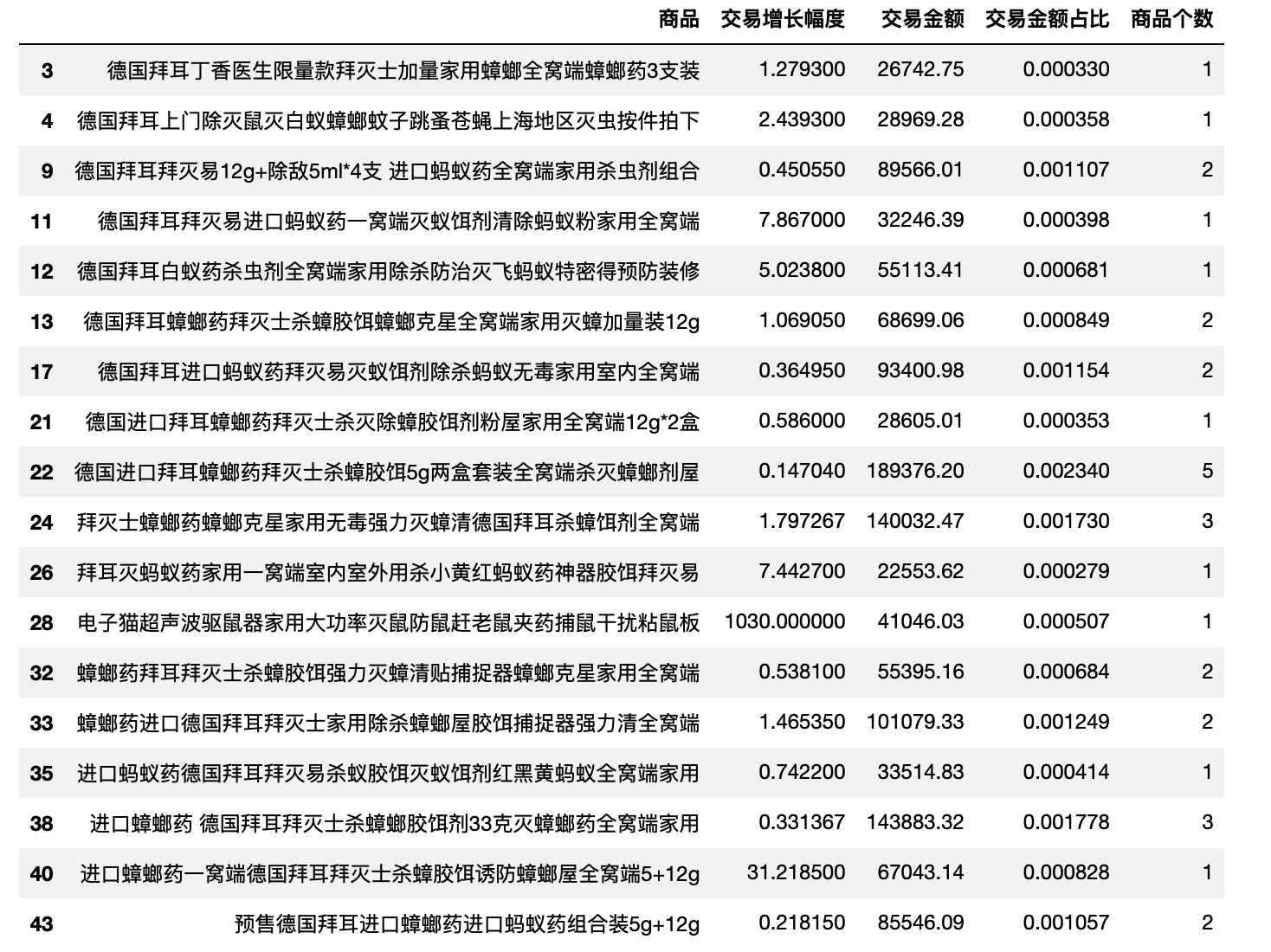
安速产品结构分析
df_an_trade = pd.read_excel(filenames4[0])
df_an_product = product_func(df_an_trade)
df_an_block = block_product(df_an_product) # 盖帽
plotBCG(df_an_block)

star_an,cow_an,question_an = extractBCG(df_an_product)
star_an1,cow_an1,question_an1 = extractBCG(df_an_product, sort='交易增长幅度')
star_an
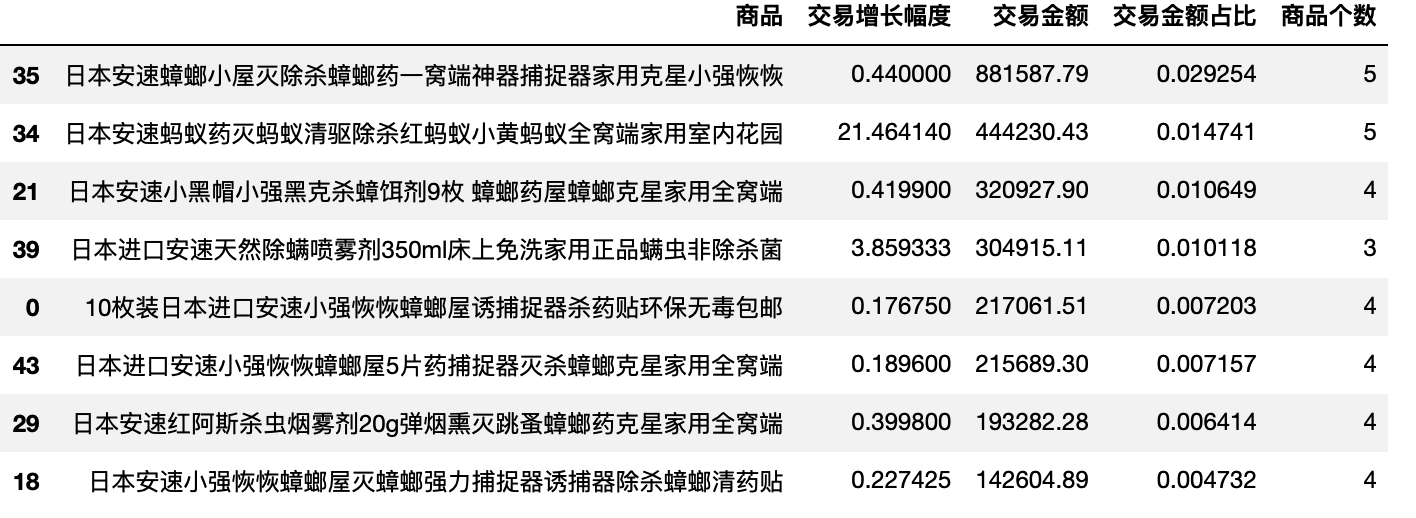
cow_an
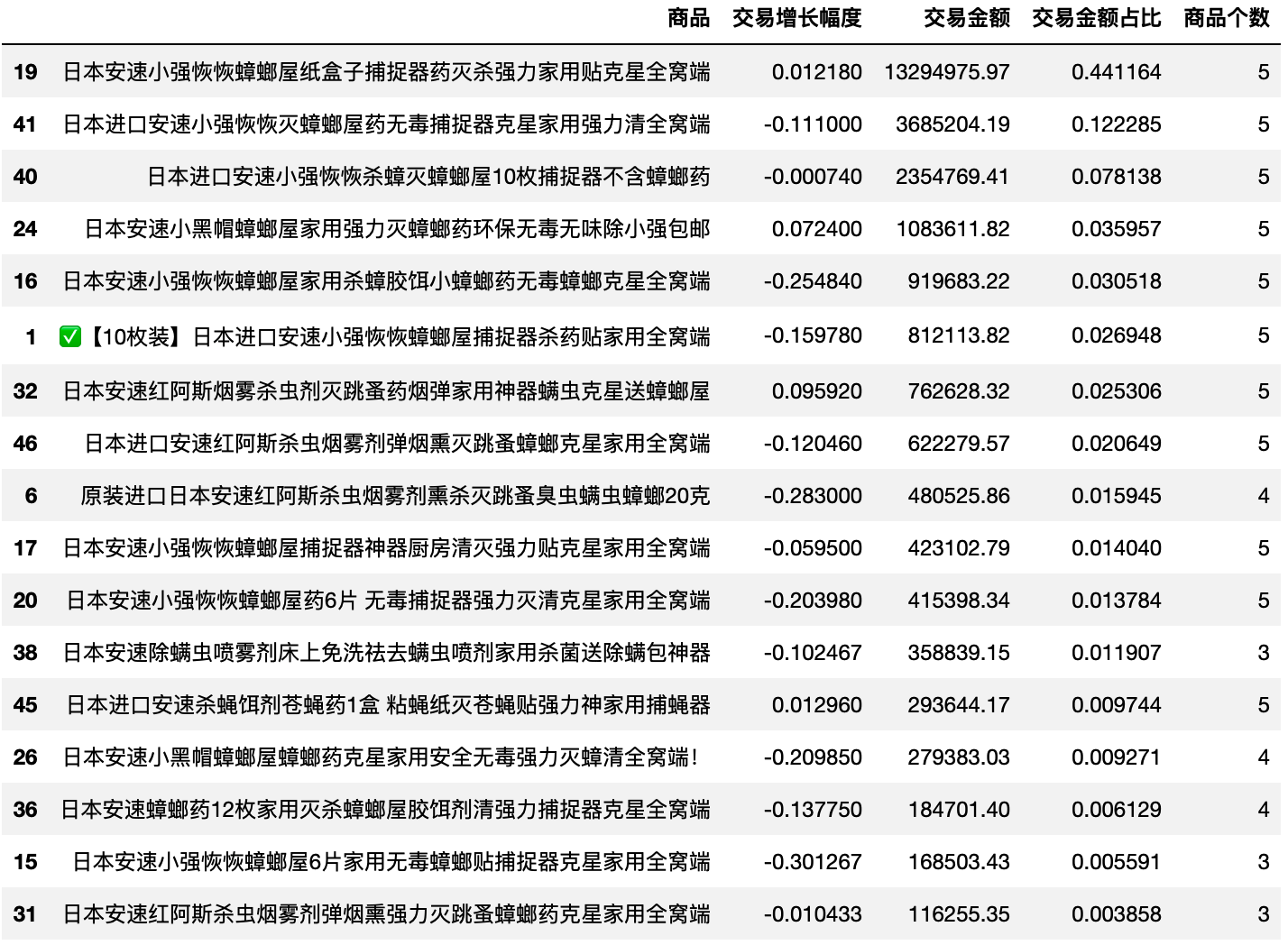
question_an
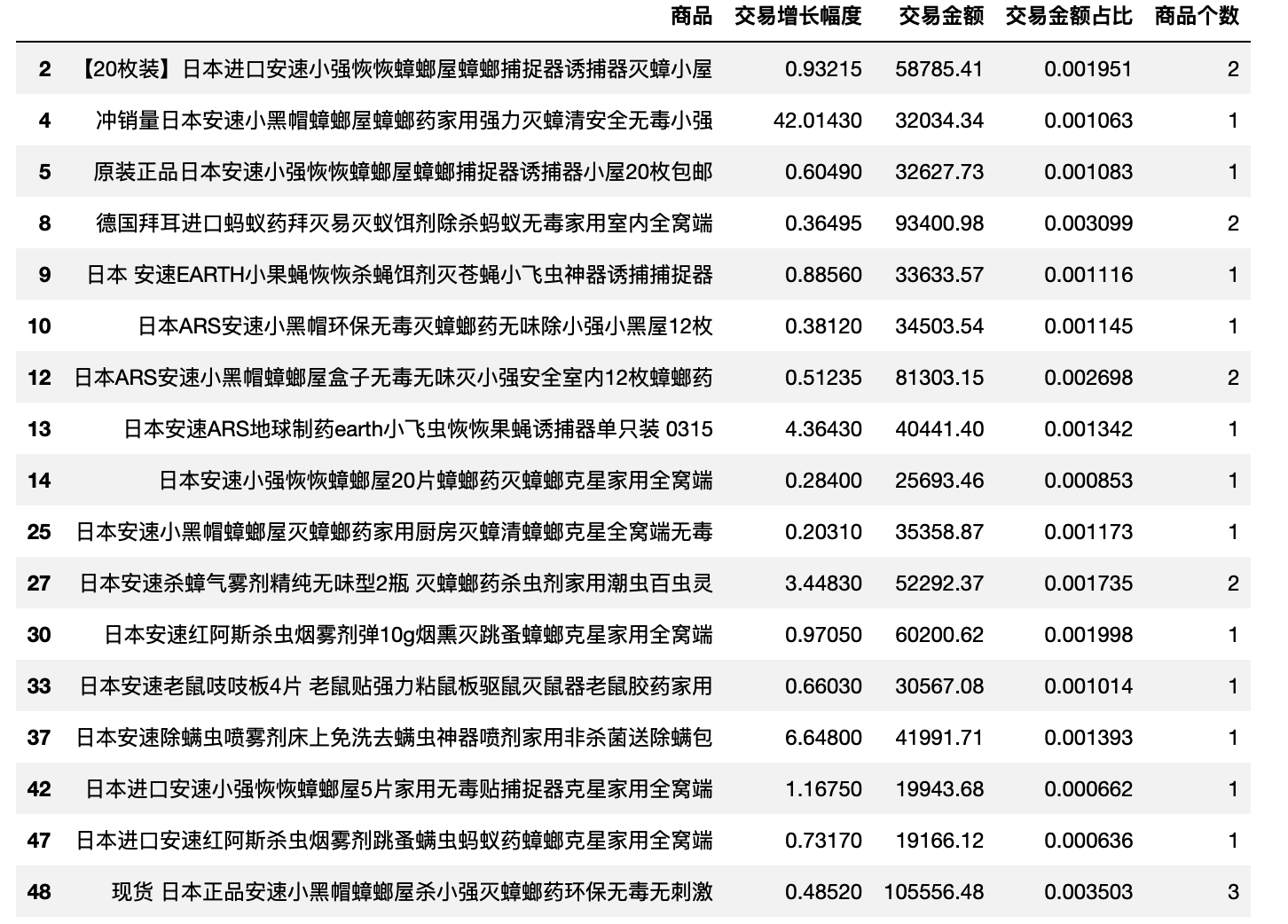
科凌产品结构分析
df_ke_trade = pd.read_excel(filenames4[2])
df_ke_product = product_func(df_ke_trade)
df_ke_block = block_product(df_ke_product) # 盖帽
plotBCG(df_ke_block)
star_ke,cow_ke,question_ke = extractBCG(df_ke_product)
star_ke1,cow_ke1,question_ke1 = extractBCG(df_ke_product, sort='交易增长幅度')
star_ke

竞争分析—流量渠道
os.chdir('../流量渠道数据/') # 切换目录
filenames5 = glob.glob('*.xlsx')
filenames5
'''
['安速家居旗舰店流量渠道.xlsx', '拜耳官方旗舰店流量渠道.xlsx', '科凌虫控旗舰店流量渠道.xlsx']
'''
拜耳流量分析
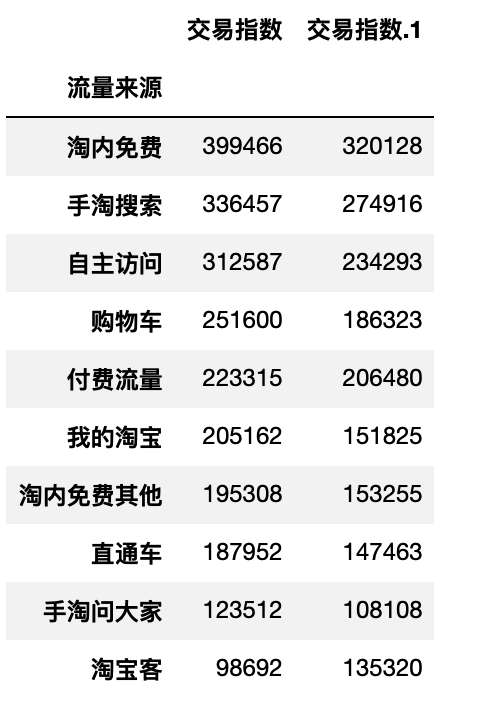
df_bai_flow = pd.read_excel(filenames5[1])
df_bai_flow.head()
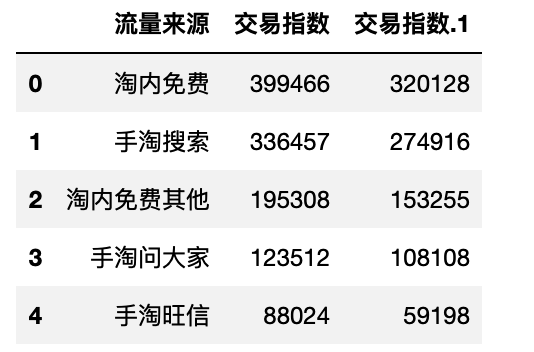
- 编写交易指数排名前10的记录的函数
def flow_top10(df):
df_copy = df.copy()
df_top10 = df_copy.sort_values('交易指数', ascending=False).reset_index(drop=True).iloc[:10,:]
df_top10.set_index('流量来源', inplace=True)
return df_top10
df_bai_top10 = flow_top10(df_bai_flow) # 调用函数,返回交易指数排名前10的记录
df_bai_top10
- 编写绘制交易指数占比的饼图,注意某些流量来源要离圆心一些距离
def draw_flow(df):
paid = ['付费流量', '直通车', '淘宝客', '淘宝联盟'] # 需要付费的流量来源
flow_index = np.array([True if name in paid else False for name in df.index])
explode_value = flow_index * 0.1
ax = df['交易指数'].plot.pie(autopct='%.2f%%', explode=explode_value, figsize=(8,8),colormap='cool')
ax.set_ylabel("")
trade_index_sum = df['交易指数'].sum()
trade_paid_index = df['交易指数'][flow_index].sum()
trade_paid_percent = trade_paid_index / trade_index_sum
plt.xlabel(f'前10流量中:总交易指数:{trade_index_sum};付费流量占比{trade_paid_percent};付费流量带来交易指数:{trade_paid_index}')
draw_flow(df_bai_top10)

安速流量分析
df_an_flow = pd.read_excel(filenames5[0])
df_an_flow.head()
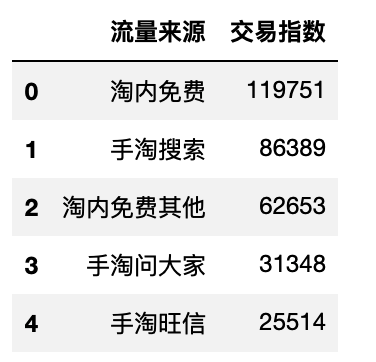
df_an_top10 = flow_top10(df_an_flow) # 调用函数,返回交易指数排名前10的记录
df_an_top10
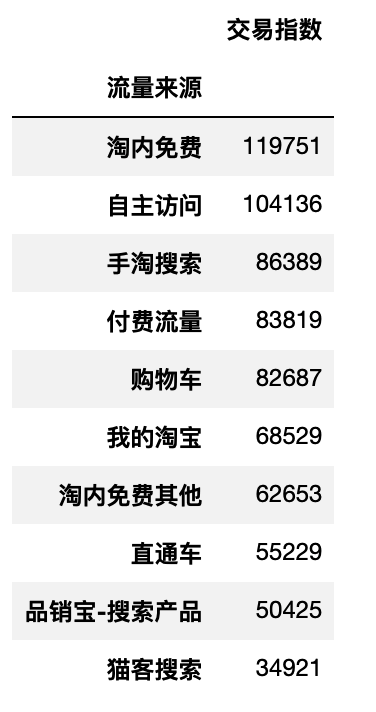
draw_flow(df_an_top10)
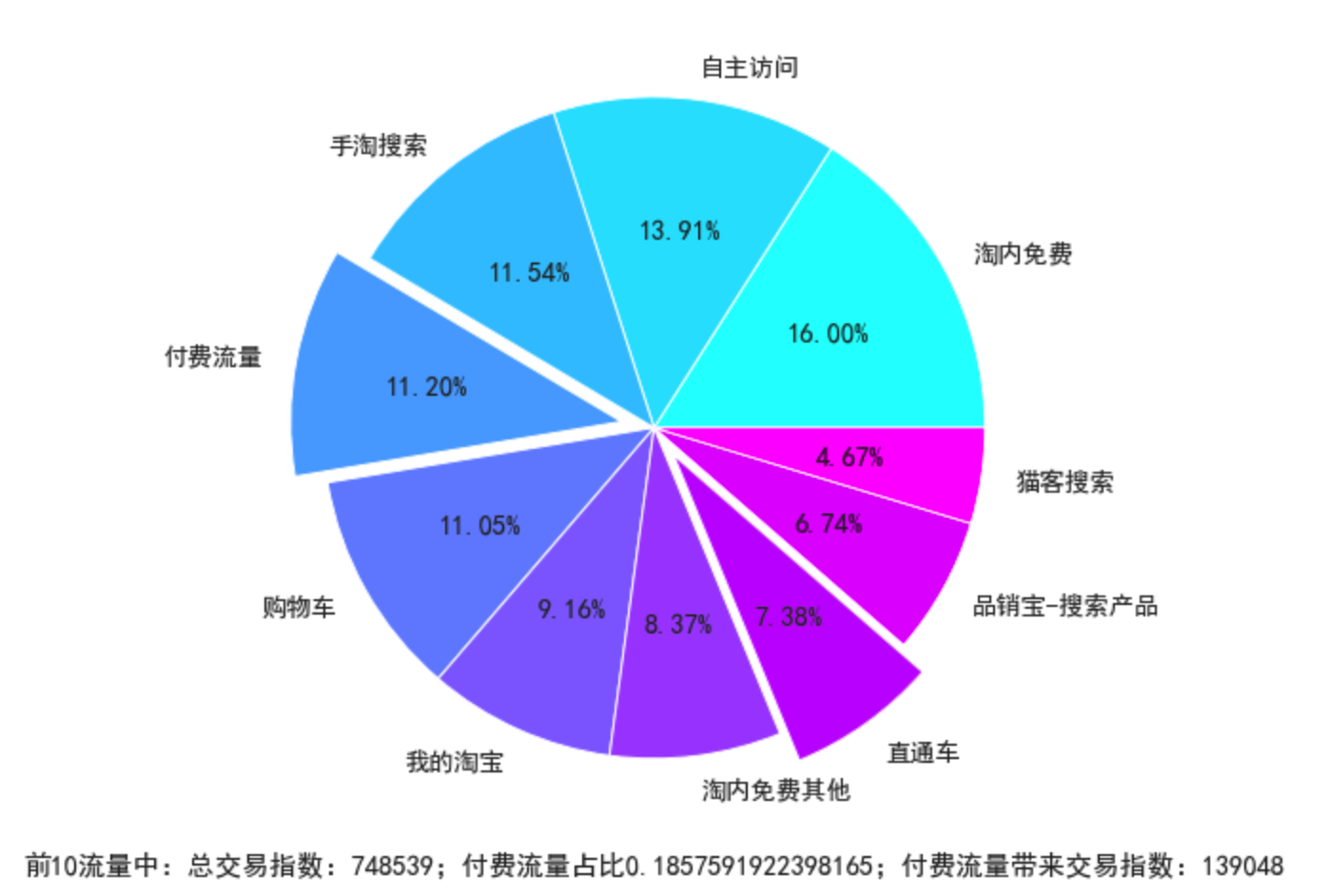
- 可见拜耳和安速的流量配比是差不多的,安速的整体流量小很多,即流量效果拜耳明显 优于安速
科凌流量分析
df_ke_flow = pd.read_excel(filenames5[2])
df_ke_flow.head()
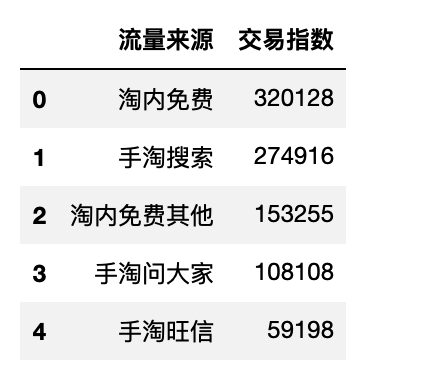
df_ke_top10 = flow_top10(df_ke_flow) # 调用函数,返回交易指数排名前10的记录
draw_flow(df_ke_top10)
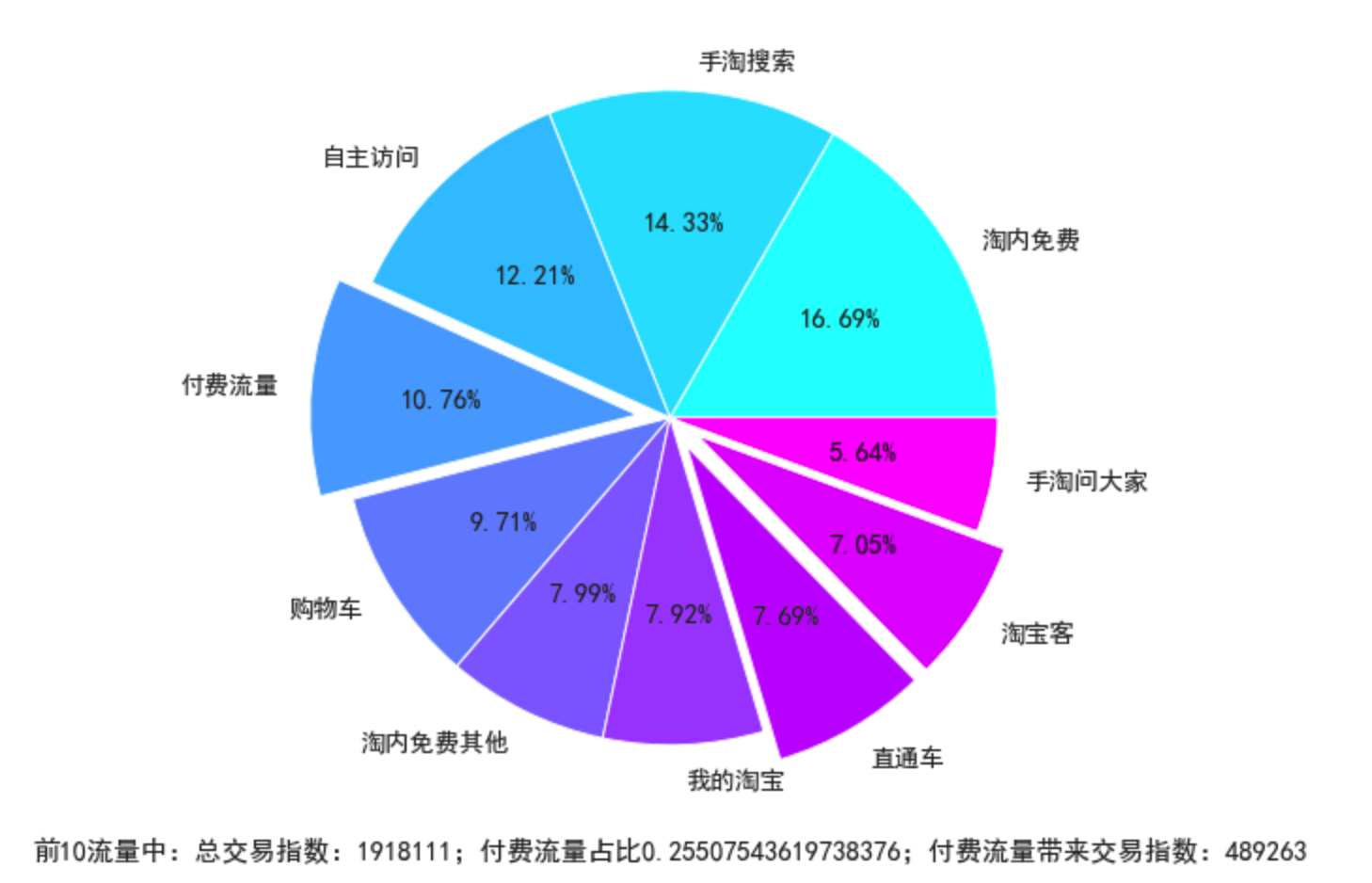
- 和拜耳在流量上差不多,科凌虫控付费占比较高
- 可见拜耳在流量结构上是有优势的,要保持这个优势
舆情分析-文本挖掘
os.chdir('../评论舆情数据/')
filenames6 = glob.glob('*.xlsx')
filenames6
'''
['安速.xlsx', '德国拜耳.xlsx', '科林虫控.xlsx']
'''
df_bai_comment = pd.read_excel(filenames6[1])
df_bai_comment
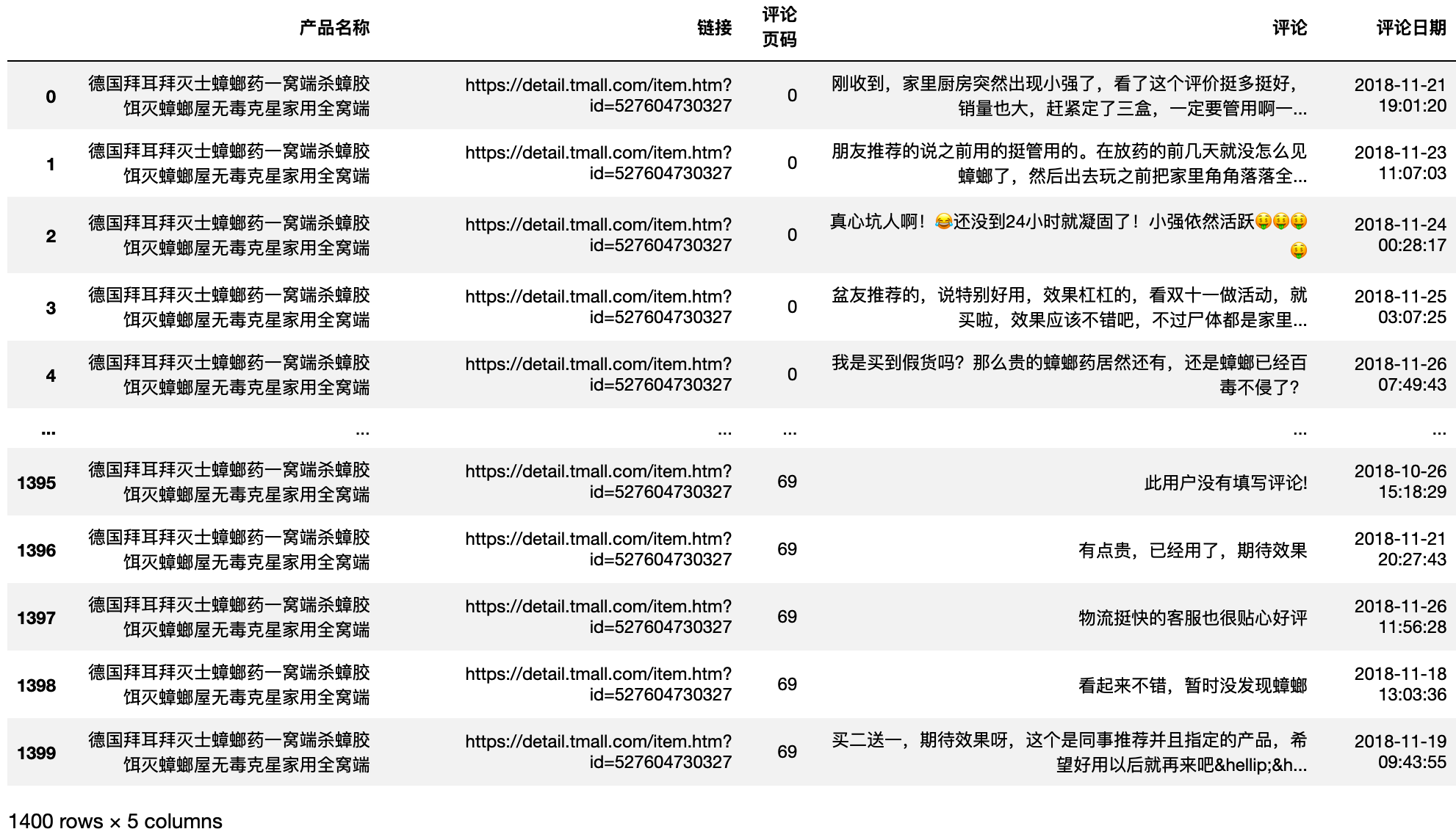
comment_list = list(df_bai_comment['评论']) # 抽出评论列,并转换为list
# 替换非中英文字符为空格
comment_list_2 = [re.sub(r'[^a-zA-Z\u4E00-\u9FA5]+',' ',comment) for comment in comment_list]
# 读取停用词,转换成停用词列表
stopwords = list(pd.read_csv('../../百度停用词表.txt',names=['stopwords'],engine='python')['stopwords'])
import jieba
# jieba.lcut('中华人民共和国万岁') # 精确模式
jieba.lcut('中华人民共和国万岁',cut_all=True) # 全模式
'''
['中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '万岁']
'''
comment_list3 = []
for comment in comment_list_2: # 遍历每一条评论
words = jieba.lcut(comment) # 精确模式,没有冗余,对每一条评论进行结巴分词
index = np.array([len(word)>1 for word in words]) # 判断每个分词的长度是否大于1
ser1 = Series(words)
ser2 = ser1[index] # 筛选分词长度大于1的分词
ser3 = ser2[~ser2.isin(stopwords)].unique() # 筛选出不在停用词表的分词,并去重
if len(ser3) > 0:
comment_list3.append(list(ser3))
# 将所有分词存储到一个列表中
word_list = [word for comlist in comment_list3 for word in comlist]
comment_str = ' '.join(word_list) # 将列表中所有的分词拼接成一个字符串
- 绘制词云图
from wordcloud import WordCloud
import imageio
leaf = imageio.imread('../../leaf.jpg')
wc = WordCloud(background_color='wheat',font_path='../../SimHei.ttf', mask=leaf) # 创建WordCloud对象
wc.generate(comment_str) # 传入拼接好的评论字符串,生成词云
plt.figure(figsize=(6,8))
plt.imshow(wc) # 绘制词云图
plt.axis('off')
plt.show()

wc.to_file('../../拜耳舆情词云.jpg') # 保存词云图到指定位置
- 计算TF-IDF值,提取关键词
import jieba.analyse
jieba.analyse.extract_tags(comment_str,topK=20,withWeight=True)


