一、分布式数据库存储
在前面的章节;GreenPlum数据库是分布式架构数据库;表的数据分布在segment节点。那么表的数据根据什么策略来分布的?
GreenPlum数据库性能依赖于跨数据节点均匀分布
- GreenPlum数据库查询响应时间由所有数据节点完成时间来度量。系统只能跟最慢数据节点完成时间来决定。如果数据存储倾斜。一个数据节点比其他节点需要花更多的时间来处理数据,数据存储倾斜只会存在哈希分布的情况。
- 在GreenPlum数据库中;表关联查询最常见。若两个或者多个表关联的字段非分布键或者采用随机分布。在其他分布式架构这表之间的关系不是亲和表。要执行连接,匹配的行必须位于同一节点上。 如果数据未在同一连接列上分发,则其中一个表所需的行将动态重新分发到其他节点。 有些情况下,执行广播动作,每个节点将其各个行发送到所有其他节点上,而不是每个节点重新哈希数据并根据哈希值将行发送到适当的节点的重新分配。
- 是不是还有一种复制表?在GreenPlum6.0以上的版本支持复制表。正好避免2中的广播或者重分布动作。
二、分布策略
在GreenPlum数据库在创建表时可以指定分布策略:哈希分布(DISTRIBUTED BY)、随机分布(DISTRIBUTED RANDOMLY)、复制分布(DISTRIBUTED REPLICATED)。
- 哈希分布:需要指定分布键。会根据分布键的哈希值分配到对应的segment数据节点。相近的值会分配到同一个数据节点。
- 随机分布:随机分布无需指定分布键。这样无法保证表中字段的唯一性。因为同个值可能会分布在不同的数据节点。
- 复制分布:在GreenPlum6.0以上的版本支持复制表;Greenplum数据库会将每个表行分发到每个节点实例。 复制表的数据均匀分布,因为每个节点具有相同的行。
如何选择分布策略呢?我们现在来分析
2.1、单表查询情况
结果验证:好像没区别

2.2、表关联查询
现在我们创建一个表t_lottu;也插入10000条记录
lottu=# truncate table t_lottu;
TRUNCATE TABLE
lottu=# insert into t_lottu select generate_series(1,10000),'lottu';
INSERT 0 10000
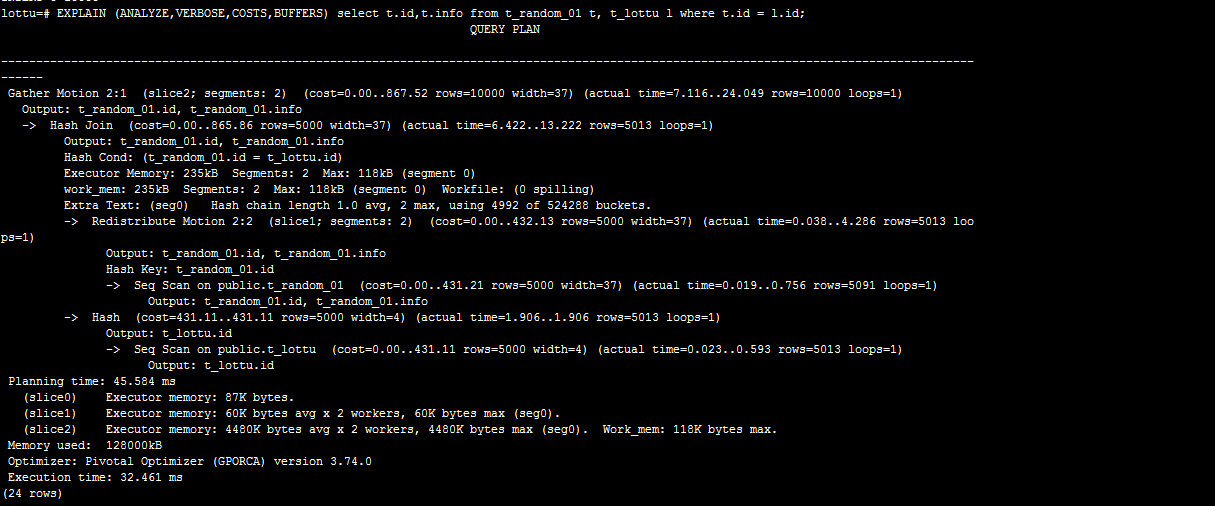
随机策略:通过t_random_01与表t_lottu关联
哈希策略:
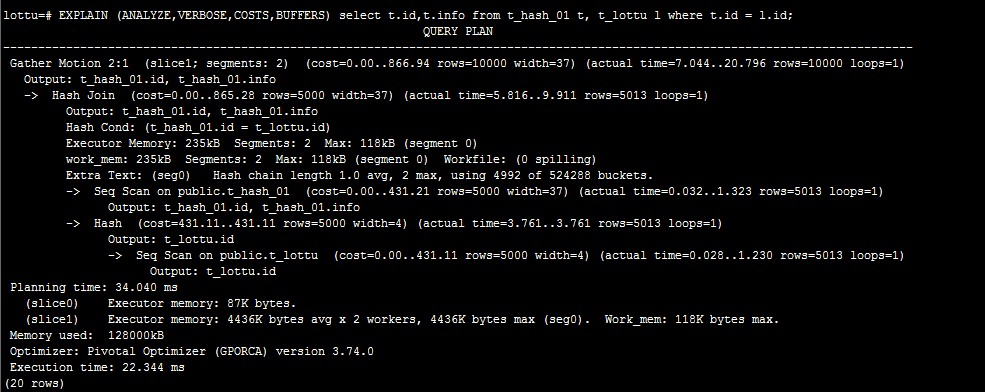
通过上两图比较:可以判断哈希策略略好;我这环境只有2个segment节点。效果不明显。我们可以明显可以看到在随机策略查询计划里面那有Redistribute Motion。 这个在后面讲解查询计划。这个叫数据重分布。后须讲解。
为什么随机策略会Redistribute Motion?
在哈希策略中;同样的分布键的值肯定会分布到同一个segment节点。所以上面表t_hash_01和表t_lottu的分布键都是id字段。所就可以在每个Segment节点关联后,Segment节点把结果发送到Master节点,再由Master节点汇总,将最终的结果返还客户端。而随机分布则不能保证同样分布键的数据分布在同一个Segment节点上,这样在表关联的时候,就需要将数据发送到所有Segment节点去做运算,这样网络传输和大量数据运算都需要较长的时间,性能非常低下。所以在关联的时候不建议使用随机策略。
这里有一个问题了;是不是哈希策略查询计划就不会出现Redistribute Motion/Broadcast Motion(广播)。答案是错误的。若分布键跟关联的字段不一致的情况。就会出现。分布键跟关联的字段是否一致?在其它分布式架构叫表的亲和度。
2.3、数据分布倾斜的问题
既然不建议使用随机策略;那我们都是用哈希策略不就好了吗?
哈希策略是同样的分布键的值肯定会分布到同一个segment节点。有可能造成数据分布倾斜的问题。在随机策略不会出现这种情况。
数据分布倾斜的问题;待定。
-- 重新分布表数据
2.4、数据复制分布
在GreenPlum6.0版本中支持复制表。作用消除多表关联中Redistribute Motion/Broadcast Motion带来的性能消耗。也可用于单表的负载均衡。
在用于单表查询;可以看出只需查询一个节点即可。
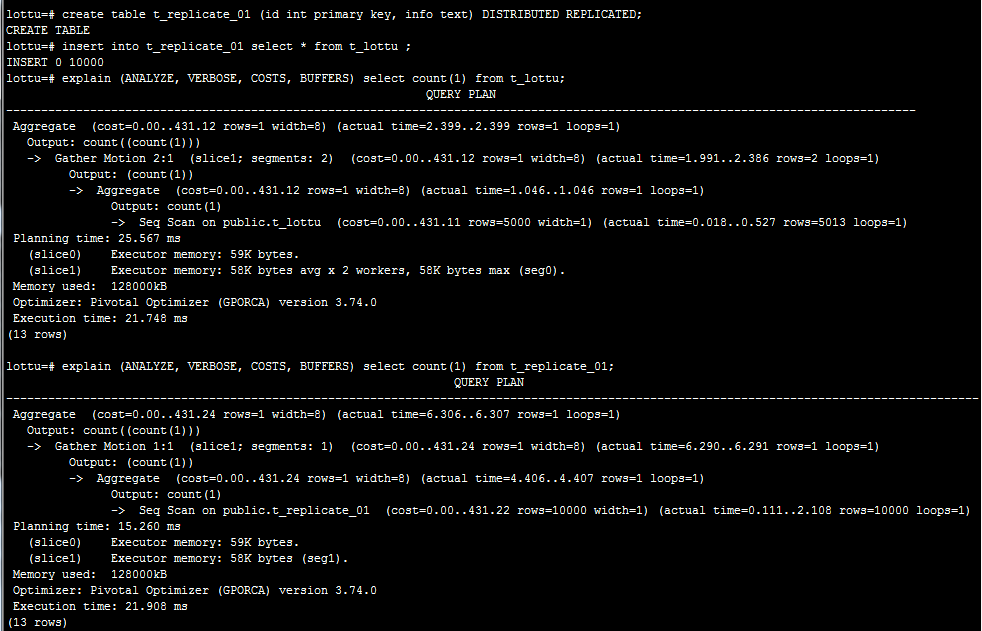
用于多表关联消除多表关联中Redistribute Motion/Broadcast Motion带来的性能消耗

三、数据是如何存储
创建表的DDL语句还可以通过with子句来定义表的存储类型
where storage_parameter is:
APPENDONLY={TRUE|FALSE}
BLOCKSIZE={8192-2097152}
ORIENTATION={COLUMN|ROW}
COMPRESSTYPE={ZLIB|QUICKLZ|RLE_TYPE|NONE}
COMPRESSLEVEL={0-9}
CHECKSUM={TRUE|FALSE}
FILLFACTOR={10-100}
OIDS[=TRUE|FALSE]
where column_constraint is:
在前面有说到
参考:https://github.com/digoal/blog/blob/master/201708/20170818_02.md
Greenplum数据库可以使用追加优化(append-optimized,AO)的存储个事来批量装载和读取数据,并且能提供HEAP表上的性能优势。 追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
在创建表指定 APPENDONLY = TRUE为AO表。若不指定或者APPENDONLY = FALSE为堆表。
3.1、堆表
堆表是PostgreSQL数据库原生存储格式,GreenPlum默认的存储格式。堆表存储在OLTP类型负载下表现最好,这种环境中数据会在初始载入后被频繁地修改。 UPDATE和DELETE操作要求存储行级版本信息来确保可靠的数据库事务处理。 堆表最适合于较小的表,例如维度表,它们在初始载入数据后会经常被更新。
多适合用于OLTP系统。但GreenPlum常定位是用于OLAP系统。为了更适合OLAP系统。GreenPlum提供来AO表
应用场景:
堆表是万油金;只是有些场景其他存储方式更加适合。更能提升性能。
3.2、AO表
AO表在4.3版本之前取意为(APPEND-ONLY,AO)。根据其意义只能追加,在4.3版本之后取意为(append-optimized,AO)追加优化。支持update/delete。跟堆表一样。但实现原理不一样。删除更新数据时,通过另一个BITMAP文件来标记被删除的行,通过bit以及偏移对齐来判定AO表上的某一行是否被删除。
追加优化表存储在数据仓库环境中的非规范表表现最好。 非规范表通常是系统中最大的表。 事实表通常成批地被载入并且被只读查询访问。 将大型的事实表改为追加优化存储模型可以消除每行中的更新可见性信息负担,这可以为每一行节约大概20字节。 这可以得到一种更加简洁并且更容易优化的页面结构。 追加优化表的存储模型是为批量数据装载优化的,因此不推荐单行的INSERT语句
AO支持压缩以及列存
应用场景:
- 使用列存、压缩数据使用AO表。
- 数据批量写入使用AO表
3.3、行存和列存
ORIENTATION=COLUMN可以指定创建列存的AO表。列存的表只能是AO表。
- 行存:以行形式存储表中。一行数据存在一个数据文件中。适用于具有许多迭代事务的OLTP类型的工作负载以及一次需要多列的单行,因此检索是高效的
- 列存:以列为形式组织存储,每列对应一个或一批文件。而且压缩比例比较高。适合于在少量列上计算数据聚集的数据仓库负载,或者是用于需要对单列定期更新但不修改其他列数据的情况
若一个宽表。在读取某一个列数据;行存需要把匹配的列的所在的行数据块都要扫描一遍。整好列存可以避免。但是带来的问题是一个表对应多个数据文件。
行存与列存的选择以及转换方法
|
类型
|
创建选项
|
适用场景
|
|
堆表
|
默认/APPENDONLY = FALSE
|
适合OLTP系统,适合单条记录插入,适合小表
|
|
AO表
|
APPENDONLY = TRUE
|
适合OLAP系统,同时支持压缩。适合批量记录插入
|
|
行存
|
ORIENTATION=ROW
|
适合小量数据、多列查询
|
|
列存
|
ORIENTATION=COLUMN
|
适合OLAP系统、宽表
|
备注:以上为本人理解;若有不对的地方;烦请指出。谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号