
华科python与人工智能实践(公选)教程
python基础
软件下载
1.python下载安装
点击此链接进入官网windows下载地址
点击箭头处链接下载最新版本,进入页面后下拉

根据你的机器下载对应版本,一般人使用的是X86架构windos系统,下载箭头所指即可
若是不知道CPU架构,可见查看cpu架构,x86还是arm
下载后根据指引进行安装即可
2.环境变量配置
3.IDE下载安装(Pycharm)
4.Conda下载安装 包管理和环境管理系统
5.jupyter notebook 交互计算应用程序
一、基础语法
1.行与缩进
Python 与 C/C++、Java 这些 C 类语言不同,Python 使用缩进来表示代码块,而不是花括号,缩进的空格数量可以由个人习惯决定,但同一个代码块的缩进空格数必须相同。
if True:
print("true")
print("true")
else:
print("false")
print("false");
上面程序的 if 部分和 else 部分缩进不相同,但是在各自的代码块内缩进是相同的,所以是正确的程序。
if True:
print("true")
print("true")
这个程序的 if 部分缩进不相同,所以是错误的程序。
多行语句
Python 的代码一般是一行一条语句,语句之后的分号 ; 可加可不加。但如果要在一行中写多条语句,则需要用分号 ; 隔开每条语句。
print("hello")
print("world");
print("hello");print("world")
以上三行(四条语句)都是正确的。
2.标识符与保留字
(1)标识符
标识符就是程序中,使用的各种名称,例如:变量名、常量名、类名等等。
在 Python 中,对标识符格式的要求与 C/C++、Java 等差不多:
- 第一个字符必须是字母表中的字母或下划线 _ ;
- 标识符的其他的部分,由字母、数字和下划线组成;
- 标识符对大小写敏感;
- 标识符不能与保留字相同。
比如:
num1 = 1
float1 = 0.5
true = True #这个 true 虽然字面上的意思与值“True”相同,但 python 对大小写敏感,所以也是正确的
str1 = "hello"
这些都是正确的标识符。
而:
1value = 1 #开头不能是数字
value0.1 = 0.1 #标识符中间只能是数字,字母,下划线
if = True #与保留字if重名
都是不正确的标识符。
(2)保留字
保留字即关键字,是 Python 语言中内部使用的单词,代表一定语义。例如:and、class、if、else 等。保留字不能作为标识符,用在变量名、常量名、类名等地方。
Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
import keyword
print(keyword.kwlist)
输出:['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del','elif',
'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in','is', 'lambda', 'nonlocal'
, 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
3.注释
注释是对程序代码的说明,一般是给程序员理解代码使用,不作为程序一部分。
Python 中单行注释以 # 开头:
#这是一个注释1
print("python")
#这是一个注释2
#print("python2")
多行注释可以使用多个#,也可以用一对'''(三个单引号)或者"""(三个双引号)包裹要注释的内容:
#使用多个#
#作注释
'''
用三个单引号
作注释
'''
"""
用三个双引号
作注释
"""
4.输出输出
(1)输出
print的函数的基本使用,在之前的关卡中,已经出现过多次,将要输出的内容放在print()的括号内,就可以输出:
print("hello world")
得到的结果是:hello world
print函数可以同时输出多个内容,只需要将它一起放在print的括号内,并用逗号隔开:
print("hello","world")
得到的结果:hello world
值得注意的是,同时输出的多个内容之间,会有空格隔开。
类似于 C/C++ 的printf,Python 的print也能实现格式化输出,方法是使用%操作符,它会将左边的字符串当做格式字符串,将右边的参数代入格式字符串:
print("100 + 200 = %d" % 300) #左边的%d被替换成右边的300
print("A的小写是%s" % "a") #左边的%s被替换成右边的a
得到的结果是:
100 + 200 = 300
A的小写是a
如果要带入多个参数,则需要用()包裹代入的多个参数,参数与参数之间用逗号隔开,参数的顺序应该对应格式字符串中的顺序:
print("%d + %d = %d" % (100,200,300))
print("%s %s" % ("world","hello"))
得到的结果是:
100 + 200 = 300
world hello
格式字符串中,不同占位符的含义:
| 占位符 | 含义 |
|---|---|
%s |
作为字符串 |
%d |
作为有符号十进制整数 |
%u |
作为无符号十进制整数 |
%o |
作为无符号八进制整数 |
%x |
作为无符号十六进制整数,a~f 采用小写形式 |
%X |
作为无符号十六进制整数,A~F 采用大写形式 |
%f |
作为浮点数 |
%e/%E |
作为浮点数,使用科学计数法 |
%g/%G |
作为浮点数,使用最低有效数位 |
注意: print函数输出数据后会换行,如果不想换行,需要指定end="":
print("hello" , end="")
print("world" , end="")
得到的结果:helloworld
(2)输入
Iinput
使用input函数可以获得用户输入,在控制台窗口上,输入的一行的字符串,使用变量 = input()的形式将其赋值给一个变量:
str1 = input()
print("输入的是%s" % str1)
如果输入hello然后回车,则输出:输入的是hello。
还可以在input()的括号内,加入一些提示信息:
str1=input("请输入:")
print("输入的是%s" % str1)
运行之后,会先显示请输入:,输入数据hello之后回车,则会得到输出:输入的是hello,控制台上显示的全部内容为:
请输入:hello
输入的是hello
II 字符串转换
input函数接收的是用户输入的字符串,此时还不能作为整数或者小数进行数学运算,需要使用函数将字符串转换成想要的类型。
转换成整数,使用int()函数:num1 = int(str)
转换成小数,使用float()函数:f1 = float(str)
str = input()
num1 = int(str)
f1 = float(str)
print("整数%d,小数%f" % (num1,f1))```
如果输入10,得到的输出是:整数10,小数10.000000。
III f-string格式化字符串
f-string是 Python 3.6 引入的一种格式化字符串的方式,它比 % 操作符和 str.format() 更加简洁和高效。f-string 允许直接在字符串内嵌入表达式或变量。基本使用语法如下:
在字符串前加上 f 或 F,并在字符串内部使用 {} 包裹变量或表达式,例如:
name = "Alice"
age = 30
message = f"My name is {name} and I am {age} years old."
print(message)
#输出
#My name is Alice and I am 30 years old.
f-string的特点和用法包括:
- 直接嵌入变量: 可以在 {} 中放置任何变量,它会直接替换为该变量的值。
- 支持表达式: 不仅可以放入变量,还可以放入任意表达式,Python 会计算表达式的值并插入。
- 调用函数: 你可以直接在 {} 中调用函数并输出结果。
- 格式化数字: 可以在 {} 中使用格式化指令,比如浮点数保留小数位、百分比格式等,例如:
pi = 3.1415926535
print(f"Pi to 3 decimal places: {pi:.3f}")
二、字符串处理
字符串是 Python 中的一种基本数据类型,用于表示文本数据。字符串由字符组成,可以包含字母、数字、符号和空格等。字符串是不可变的,意味着一旦创建,字符串的内容就不能被改变。
1.字符串拼接
Python 中使用+来合并两个字符串,这种合并字符串的方法叫做拼接。其基本语法如下:
result_string = source_string1 + source_string2
其中:
- source_string1:待合并的第一个字符串;
- source_string2:待合并的第二个字符串;
- result_string:合并后的字符串。
注意:如果需要,在两个字符串之间可以增加相应的空格,具体见下面的例子。例如,将姓氏和名字拼接成全名:
# coding=utf-8
# 将姓氏和名字分别保存在两个变量中
first_name = 'Zhang'
last_name = 'san'
# 将姓氏和名字拼接,将结果存储在full_name变量中
full_name = first_name + " " + last_name
print(full_name)
#输出结果:
#Zhang san
2.字符转换
3.字符串查找与替换
(1)字符串查找
Python 提供了内置的字符串查找方法find(),利用该方法可以在一个较长的字符串中查找子字符串。如果该字符串中,有一个或者多个子字符串,则该方法返回第一个子串所在位置的最左端索引,若没有找到符合条件的子串,则返回-1。find()方法的基本使用语法如下:
source_string.find(sub_string)
其中:
- source_string:源字符串;
- sub_string:待查的目标子字符串;
- find:字符串查找方法的语法关键字。
例如,在一个字符串中,查找两个单词的位置:
# coding=utf-8
# 创建一个字符串
source_string = 'The past is gone and static'
# 查看"past"在source_string字符串中的位置
print(source_string.find('past'))
# 查看"love"在source_string字符串中的位置
print(source_string.find('love'))
#输出结果:
#4
#-1
(2)字符串替换
Python 提供了replace()方法,用以替换给定字符串中的子串。其基本使用语法如下:
source_string.replace(old_string, new_string)
其中:
- source_string:待处理的源字符串;
- old_string:被替换的旧字符串;
- new_string:替换的新字符串;
- replace:字符串替换方法的语法关键词。
该操作返回值为转换后的新串,若要直接对原串修改,应写source_string=source_string.replace(old_string, new_string)
例如,在如下字符串中,用small子串替换big子串:
# coding = utf-8
# 创建一个字符串circle
source_string = 'The world is big'
# 利用replace()方法用子串"small"代替子串"big"
print(source_string.replace('big','small'))
#输出结果:
#The world is small
(3)字符串分割
Python 提供了split()()方法实现字符串分割。该方法根据提供的分隔符,将一个字符串分割为字符列表,如果不提供分隔符,则程序会默认把空格(制表、换行等)作为分隔符。其基本使用语法如下:
source_string.split(separator)
其中:
- source_string:待处理的源字符串;
- parator:分隔符;
- split:字符串分割方法的关键词。
例如,用+、/还有空格作为分隔符,分割字符串:
# coding = utf-8
# 待处理字符串source_string
source_string = '1+2+3+4+5'
# 利用split()方法,按照`+`和`/`对source_string字符串进行分割
print(source_string.split('+'))
print(source_string.split('/'))
#输出结果:
#['1', '2', '3', '4', '5']
#['1+2+3+4+5']
三、玩转列表
列表是 Python 中一种内置的数据结构,用于存储多个元素。它是一个有序的可变集合,可以包含不同类型的数据,例如数字、字符串、甚至其他列表。列表中的元素可以通过索引访问,并且支持多种操作,如增、删、改、查。
特点:
- 有序性:列表中的元素按插入顺序存储,每个元素都有一个对应的索引(从 0 开始)
- 可变性:列表是可变的,可以动态地添加、修改或删除元素。
- 多样性:列表可以存储不同类型的元素,包括整数、浮点数、字符串、对象等。
1.列表元素的增删改
(1)添加列表元素
Python 提供了append()和insert()等函数,实现向一个列表增加新元素的功能。
(1)在列表尾部添加元素
在 Python 中,可以使用append()方法向一个列表的尾部追加一个元素,其基本语法如下:
source_list.append(obj)
其中:
- source_list:待修改的列表;
- obj:待插入的元素。
例如,要向guests列表尾部增加客人Hu qi,相应的语句为:
# 初始化guests列表
guests=['Zhang san','Li si','Wang wu','Zhao liu']
# 向guests列表尾部追加一个名为Hu qi的客人
guests.append('Hu qi')
# 输出新的guests列表
print(guests)
#输出结果为:
['Zhang san','Li si','Wang wu','Zhao liu','Hu qi']
(2)在列表指定位置添加元素
Python 也提供了insert()方法,可以在列表任意指定位置插入元素,其基本语法为:
source_list.insert(index,obj)
其中:
- source_list:待修改的列表;
- index:待插入的位置索引;
- obj:待插入的元素。
注意:在 Python 中,列表起始元素的位置索引为0。
例如,要向guests列表中Zhang san的后面增加客人Hu qi,则相应的语句为:
# 创建并初始化guests列表
guests=['Zhang san','Li si','Wang wu','Zhao liu']
# 向guests列表Zhang san后面增加一个名为Hu qi的客人
guests.insert(1,'Hu qi')
# 输出新的guests列表
print(guests)
#输出结果为:
['Zhang san','Hu qi','Li si','Wang wu','Zhao liu']
(2)修改列表元素
Python 中修改列表元素的方法为:直接将列表中要修改的元素索引指出,然后为其指定新值。其基本语法如下:
source_list[index] = obj
其中:
- source_list:待修改的列表;
- index:待修改元素的位置索引;
- obj:待元素的新值。
例如,将请客名单guests列表中的Wang wu改为Wang shi,则相应的语句为:
# 初始化guests列表
guests=['Zhang san','Li si','Wang wu','Zhao liu']
# 将列表中的`Wang wu`改为`Wang shi`
guests[2] = 'Wang shi'
# 输出新的guests列表
print(guests)
#输出结果为:
['Zhang san','Li si','Wang shi','Zhao liu']
(3)删除列表元素
2.列表的排序、查找、翻转
(1)列表排序
Python 针对列表数据结构内置提供了sort()方法,实现对列表元素的排序功能。其基本语法如下:
source_list.sort(reverse=True)
其中:
- source_list:待排序的列表;
- sort:列表排序函数的语法关键词;
- reverse:sort函数的可选参数。如果设置其值为True,则进行反向从大到小排序,如果设置为False或者不填写该参数,则默认进行正向从小到大排序。
例如,给定一个客人列表guests,我们对其按照字母排序如下:
guests = ['zhang san','li si','wang wu','sun qi','qian ba']
guests.sort()
print(guests)
guests.sort(reverse=True)
#print(guests)
程序输出结果:
['li si','qian ba','sun qi','wang wu','zhang san']
['zhang san','wang wu','sun qi','qian ba','li si']
注意:sort函数会直接作用于待排序的列表并修改其排序。
(2) 列表查找
Python 提供了index() 和 count() 方法用于查找列表中的元素。index() 方法用于返回指定元素的索引,count() 方法用于返回指定元素在列表中出现的次数。其基本语法如下:
index_value = source_list.index(value)
count_value = source_list.count(value)
其中:
- source_list:待查找的列表;
- index:查找元素的语法关键词,返回该元素的第一个索引;
- count:返回该元素在列表中出现的次数。
例如,给定一个列表 numbers,我们可以查找某个数字的索引和计数:
numbers = [1, 2, 3, 2, 4, 2]
index_of_two = numbers.index(2)
count_of_twos = numbers.count(2)
print(index_of_two) # 输出: 1
print(count_of_twos) # 输出: 3
注意:如果要查找的元素不在列表中,index() 方法会引发 ValueError。
(3) 列表翻转
Python 提供了reverse() 方法来翻转列表中的元素顺序,其基本语法如下:
source_list.reverse()
其中:
- source_list:待翻转的列表;
- reverse:翻转列表的语法关键词。
例如,给定一个列表 items,我们可以翻转其顺序:
items = [1, 2, 3, 4, 5]
items.reverse()
print(items)
#程序输出结果:
csharp
[5, 4, 3, 2, 1]
3.数值列表:用数字说话
(1)range()函数
Python 提供了range()函数,能够用来生成一系列连续增加的数字。其基本使用语法有如下三种:
range(lower_limit,upper_limit,step)
其中:
- lower_limit: 生成系列整数的下限整数,不填该参数则默认为从0开始,生成的整数从此数开始,包括该数;
- upper_limit:生成系列整数的上限整数,必填参数,生成的整数要小于该上限;
- step:在下限和上限之间生成系列整数之间的间隔步长,不填该参数则默认步长为1。
注意:range()函数的三个参数都只能为整数。如果range()函数中仅一个参数,则该参数表示upper_limit,如果仅两个参数,则分别表示lower_limit和upper_limit。
例如,要生成1~6之间步长为2的系列整数:
for i in range(1,6,2):
print(i)
输出结果:
1
3
5
(2)基于range()函数创建数字列表
我们可以通过range()函数,利用 Python 列表提供的append()插入功能创建一个列表。例如,我们要创建一个包含10个0~9整数的平方的列表:
# 声明一个列表变量
numbers = []
# 利用append()函数和range()函数向列表插入目标元素
for i in range(10):
number = i**2
numbers.append(number)
print(numbers)
#输出结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
(3)使用list()函数和range()函数创建数字列表
我们可以利用list()函数将range()生成的系列数字直接转为列表,这时range()函数的返回值将会作为list()函数的参数,输出为一个数字列表。其基本使用语法如下:
data_list = list(range(lower_limit,upper_limit,step))
其中:
- list:列表函数的语法关键词;
- range:函数语法关键词;
- data_list:最终生成的列表变量。
例如,我们要生成并输出1~5的数字列表:
data_list = list(range(1,6))
print(data_list)
输出结果:
[1,2,3,4,5]
(4)对数字列表进行简单的统计运算
Python 中有一些专门处理数字列表简单的统计运算的函数,利用这些函数可以轻松找到数字列表的最小值、最大值及进行总和等一系列统计运算。其基本语法如下:
min_value = min(data_list)
max_value = max(data_list)
sum_value = sum(data_list)
其中:
- min:数字列表求最小值的语法关键字;
- max:数字列表求最大值的语法关键字;
- sum:数字列表求和的语法关键字。
具体使用示例如下:
numbers = [2,4,11,1,21,32,5,8]
print('The min number is',min(numbers))
print('The max number is',max(numbers))
print('The sum is',sum(numbers))
# 输出结果:
The min number is 1
The max number is 32
The sum is 84
注意:reverse() 方法会直接作用于待翻转的列表并修改其顺序。
四、元组与字典
4.1 元组的使用
(1)元组与列表
元组与列表很相似,两者之间的差别在于:
- 列表在初始化后其中的元素还可以进行增删改等操作,但是元组在初始化后其中的元素不能进行更改;
- 列表在赋值时使用方括号[],而元组在赋值时使用小括号()。
- 因为元组具有不可变的特性,所以在能用元组替代列表的地方最好都使用元组,这样代码更安全。
(2)创建元组
元组创建很简单,只需要在括号()中添加元素,元素之间用逗号隔开。元组中只包含单个元素时,需要在该元素后面添加逗号。例如:
menu1 = ('meat','fish','chicken')
menu2 = ('meat',)
(3)访问元组
元组和列表一样,可以使用下标索引来访问元组中的值。例如:
menu = ('meat','fish','chicken','carrot')
print(menu[0])
print(menu[1:3])
输出结果:
meat
('fish', 'chicken')
同样也可以像列表一样负索引访问,切片访问
I.切片访问
切片的基本语法是:
sequence[start:stop:step]
- start:切片的起始索引,包含该位置的元素。省略时默认为 0。
- stop:切片的结束索引,不包含该位置的元素。省略时默认为序列的长度。
- step:切片的步长,表示每次跳过多少元素。默认为 1。
常见示例
假设有一个元组:
my_tuple = (10, 20, 30, 40, 50, 60)
通过切片操作,可以获取元组中的某些部分:
slice_tuple = my_tuple[1:4]
print(slice_tuple) # 输出: (20, 30, 40)
#这里 [1:4] 意味着从索引 1 开始(即元素 20),一直到索引 4,但不包括索引 4 的元素(即 50)。
省略起始位置或结束位置
如果省略 start 或 stop,Python 会使用默认值。
print(my_tuple[:3]) # 输出: (10, 20, 30) # 从索引 0 开始,直到索引 3
print(my_tuple[3:]) # 输出: (40, 50, 60) # 从索引 3 开始,一直到最后一个元素
使用负索引
负索引从序列的末尾开始计数。-1 表示最后一个元素,-2 表示倒数第二个元素。
print(my_tuple[-3:]) # 输出: (40, 50, 60) # 从倒数第三个元素开始到结尾
print(my_tuple[:-2]) # 输出: (10, 20, 30, 40) # 从头开始,直到倒数第二个元素(不包括)
使用步长
步长控制切片时的步进。如果没有指定,默认步长为 1。步长可以为负数,这样可以反向切片。
print(my_tuple[::2]) # 输出: (10, 30, 50) # 每隔一个元素获取
print(my_tuple[::-1]) # 输出: (60, 50, 40, 30, 20, 10) # 反转元组
步长为负数的切片
当步长为负数时,start 和 stop 也应该相应调整。反向切片时,start 要大于 stop,否则将返回空序列。
print(my_tuple[4:1:-1]) # 输出: (50, 40, 30)
注意事项
切片不会修改原序列,而是返回一个新序列。
start、stop 和 step 参数都可以被省略,Python 会使用默认值。start 默认是 0,stop 默认是序列的长度,step 默认是 1。
如果 step 为负数,切片会反向进行。
切片的常用操作
- 反转序列: sequence[::-1]
- 每隔一个元素获取: sequence[::2]
- 获取某一范围的元素: sequence[start:stop]
II.嵌套元组的访问
如果元组内包含嵌套元组,可以通过多层索引来访问嵌套元组中的元素。
nested_tuple = (10, (20, 30), 40)
print(nested_tuple[1]) # 输出: (20, 30)
print(nested_tuple[1][0]) # 输出: 20
III.使用 index() 查找元素索引
可以使用元组的 index() 方法查找某个元素的索引。如果元素不在元组中,会抛出 ValueError 异常。
print(my_tuple.index(30)) # 输出: 2
IV.使用 count() 统计元素出现次数
count() 方法可以统计元组中某个元素出现的次数。
print(my_tuple.count(20)) # 输出: 1
(4)修改元组
元组中的元素值是不可以修改的,如果强行修改会报错。例如我们想修改元组menu中的某个值:
menu = ('meat','fish','chicken','carrot')
menu[0] = 'pizza'
print(menu[0])
#输出结果:
TypeError: 'tuple' object does not support item assignment
#系统会自动报错,元组中的元素值不支持修改。
(5)元组内置函数
元组和列表一样,都有一些内置函数方便编程。例如:
len(tuple):计算元组中元素个数;
max(tuple):返回元组中元素的最大值;
min(tuple):返回元组中元素的最小值;
tuple(seq):将列表转换为元组。
元组中的元素是不能改变的,它也没有append()、insert()这样的方法,但其他获取元素的方法和列表是一样的。
4.2 字典的使用
字典是 Python 最强大的数据类型之一,通过键-值对的方式建立数据对象之间的映射关系。字典的每个键-值对用冒号:分割,每个键-值对间用逗号,分隔开,字典则包含在{}中。列表格式如下:
d = { key1 : value1, key2 : value2 }
每个键都与一个值相关联,我们可以使用键来访问与之相关联的值。与键相关联的值可以是数字、字符串、列表乃至字典。事实上,可将任何 Python 对象用作字典中的值。
(1)访问字典中的值
要获取与键相关联的值,可依次指定字典名和放在方括号内的键,如下所示:
# 创建并初始化menu字典
menu = {'fish':40, 'pork':30, 'potato':15, 'noodles':10}
# 获取并返回menu字典中键'fish'键对应的值
print(menu['fish'])
#输出结果:
40
(2)添加键-值对
字典是一种动态数据结构,可随时在字典中添加键-值对。要添加键-值对时,可依次指定字典名、键和键对应的值。下面在字典menu中添加两道菜的菜名和价格:
# 创建并初始化menu字典
menu = {'fish':40, 'pork':30, 'potato':15, 'noodles':10}
# 向menu字典中添加菜名和价格
menu['juice'] = 12
menu['egg'] = 5
# 输出新的menu
print(menu)
#输出结果:
{'fish': 40,'pork': 30,'potato': 15,'noodles': 10, 'juice': 12,'egg': 5}
新的menu字典包含6个键-值对,新增加的两个键-值对(菜名和对应价格)添加在了原有键-值对的后面。
注意:字典中键-值对的排列顺序和添加顺序没有必然联系。Python 不关心字典中键-值对的排列顺序,而只关心键与值的对应关系。
同理,字典和列表一样,可以先创建一个空字典,然后可以不断向里面添加新的键-值对。
两个字典合并使用dict1.update(dict2),如此即将dict2中所有元素追加到了dict1中。
>>>a={1:"a",2:"b","c":3}
>>>a[3] = 5 #增加元素
>>>a
{1: 'a', 2: 'b', 'c': 3, 3: 5}
>>>b={1:"d",4:"b"}
>>>a.update(b)
>>>a
{1: 'd', 2: 'b', 'c': 3, 3: 5, 4: 'b'}
(3)修改字典中的值
字典和列表一样,里面的值都是可以修改的。要修改字典中的值,可直接指定字典中的键所对应的新值。例如,将menu中的fish价格改为50:
# 创建并初始化menu字典
menu = {'fish':40, 'pork':30, 'potato':15, 'noodles':10}
# 修改menu字典中菜fish的价格
menu['fish'] = 50
# 打印输出新的menu
print(menu)
#输出结果:
{'fish': 50, 'pork': 30, 'potato': 15, 'noodles': 10}
(4)删除键-值对
I.del
我们可以通过del方法删除字典中不需要的键-值对。使用del方法时,要指定字典名和要删除的键。例如,在menu菜单中删除键noodles和它的值:
# 创建并初始化menu字典
menu = {'fish':40, 'pork':30, 'potato':15, 'noodles':10}
# 删除noodles键值对
del menu['noodles']
# 打印输出新的menu
print(menu)
#输出结果:
{'fish': 40, 'pork': 30, 'potato': 15}
II. pop()
pop() 方法会删除指定键,并返回该键对应的值。
my_dict = {"a": 1, "b": 2, "c": 3}
value = my_dict.pop("b")
print(value) # 输出: 2
print(my_dict) # 输出: {'a': 1, 'c': 3}
- 如果键不存在,可以指定一个默认值,如果不指定默认值而键不存在,则会抛出 KeyError。
value = my_dict.pop("d", None) # 如果 "d" 不存在,返回 None,而不会抛出异常
III.使用 popitem() 方法
popitem() 方法会删除并返回字典中的最后一个键值对。返回的是一个 (key, value) 元组。
my_dict = {"a": 1, "b": 2, "c": 3}
item = my_dict.popitem()
print(item) # 输出: ('c', 3)
print(my_dict) # 输出: {'a': 1, 'b': 2}
如果字典为空,会抛出 KeyError 异常。
IV.使用 clear() 方法
clear() 方法会清空字典,删除所有的键值对。
my_dict = {"a": 1, "b": 2, "c": 3}
my_dict.clear()
print(my_dict) # 输出: {}
4.3 字典的遍历
(1)遍历字典的键
直接遍历字典,默认会遍历字典的键。
my_dict = {'a': 1, 'b': 2, 'c': 3}
for key in my_dict:
print(key)
#输出
a
b
c
(2) 遍历字典的值
使用 values() 方法可以直接遍历字典中的值。
for value in my_dict.values():
print(value)
#输出:
1
2
3
(3)遍历字典的键值对
使用 items() 方法可以同时遍历字典的键和值,返回的是一个 (key, value) 元组。
for key, value in my_dict.items():
print(f"Key: {key}, Value: {value}")
输出:
Key: a, Value: 1
Key: b, Value: 2
Key: c, Value: 3
(4) 遍历字典的键值对元组
如果你不需要解包 (key, value),可以直接遍历 items() 返回的元组。
for item in my_dict.items():
print(item)
#输出:
('a', 1)
('b', 2)
('c', 3)
(5)通过条件遍历
你可以根据条件在遍历时对键值对进行筛选:
for key, value in my_dict.items():
if value > 1:
print(f"Key: {key}, Value: {value}")
输出:
Key: b, Value: 2
Key: c, Value: 3
五、python函数与流程控制
python 中的函数是通过 def 关键字来定义的,结构如下:
def function_name(parameters):
"""
函数的文档字符串(可选)
"""
# 函数体
return result
- def:函数定义的关键字。
- function_name:函数名称,遵循标识符的命名规则(不能以数字开头,不能使用保留字等)。
- parameters:函数的参数,可以没有参数,也可以有多个。
- return:用于返回函数的结果(可选)。如果没有 return,函数会默认返回 None。
示例:
def greet(name):
"""接收名字参数并打印问候语"""
return f"Hello, {name}!"
print(greet("Alice")) # 输出: Hello, Alice!
5.1 函数参数
Python 函数可以通过参数接收输入,参数可以有多种形式:
(1)位置参数
位置参数是最常见的形式,函数调用时按位置传递实参。
def add(a, b):
return a + b
print(add(3, 5)) # 输出: 8
(2)默认参数
函数可以为某些参数提供默认值。如果调用时未传递这些参数,则会使用默认值。
def greet(name, message="Hello"):
return f"{message}, {name}!"
print(greet("Alice")) # 输出: Hello, Alice!
print(greet("Bob", "Hi")) # 输出: Hi, Bob!
(3)关键字参数
使用关键字参数时,调用函数时可以显式指定参数名称,参数顺序可以不同。
def introduce(name, age):
return f"My name is {name} and I am {age} years old."
print(introduce(age=25, name="Alice")) # 输出: My name is Alice and I am 25 years old.
(4)可变参数(*args 和 **kwargs)
- *args:接受任意数量的参数,参数以元组形式传递。
- **kwargs:接受任意数量的关键字参数,参数以字典形式传递。
def print_args(*args):
for arg in args:
print(arg)
print_args(1, 2, 3) # 输出: 1 2 3
def print_kwargs(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
print_kwargs(name="Alice", age=25)
# 输出:
name: Alice
age: 25
5.2 函数返回值
return语句将值返回到调用函数的出口,函数中一定要有return返回值才是完整的函数。如果我们没有在函数中定义函数返回值,那么程序会自动让函数返回一个结果,该结果是None对象,而None对象表示没有任何值。
(1)将值作为返回值
函数的返回值只有一个,但有时我们会发现有的函数好像有多个返回值,其实这里的“多个”并不是指多个返回值。比如函数返回一列表,里面包含很多个元素值。这就类似于,只能从超市带走一个箱子,但是允许我们把一些东西都装到箱子里面看做一个东西带走。例如:
def f():
return 1,'abc','1234'
print(f())
输出结果:
(1, 'abc', '1234')
调用f()函数,程序输出为一个元组,所以函数返回值表面上是3个值,其实是返回一个元组,元组里面有三个不同元素(元组语法上不需要一定带上圆括号)。
(2)将函数作为返回值
我们除了可以将各种类型的值作为返回值外,也可以将函数作为返回值。例如,我们要定义一个函数来求列表中数值元素的和,一般情况下我们是这样定义的:
def plus(*args):
s = 0
for n in args:
s = s + n
return s
但是,如果我们不需要立刻求和,而是在后面的程序中,根据需求再计算,这种情况怎么办呢?这时我们定义的函数可以不返回求和的结果,而是返回计算求和的函数。所以我们还可以用如下方法定义函数:
def lazy_plus(*args):
def plus():
s = 0
for n in args:
s = s + n
return s
return plus
当我们调用lazy_plus()时,返回的并不是求和结果,而是计算求和的函数:
# 定义求和函数,返回的并不是求和结果,而是计算求和的函数
def lazy_plus(*args):
def plus():
s = 0
for n in args:
s = s + n
return s
return plus
# 调用lazy_plus()时,返回的并不是求和结果,而是求和函数
f = lazy_plus(1,2,3,4,5)
print(f)
输出结果:
<function lazy_plus.<locals>.plus at 0x000001DAC97F9950>
调用函数f时,才真正计算求和的结果:
# 定义求和函数,返回的并不是求和结果,而是计算求和的函数
def lazy_plus(*args):
def plus():
s = 0
for n in args:
s = s + n
return s
return plus
# 调用函数f时,得到真正求和的结果
f = lazy_plus(1,2,3,4,5)
print(f())
输出结果:
15
在上述例子中,我们在函数lazy_plus中又定义了函数plus,而且内部函数plus是可以引用外部函数lazy_plus的参数和局部变量的。当函数lazy_plus返回函数plus时,相关参数和变量也将会保存在返回的函数中,这种方式也称为“闭包”(Closure)。
小结
我们除了可以将函数计算的值作为返回值外,也可以将函数作为返回值。
5.3 函数的使用范围:Python 作用域
在 Python 中,正常的函数和变量名是公开的(public),是可以被直接引用的。比如abs()、abc、dir()等。
-
类似__xxx__这种格式的变量是特殊变量,允许被直接引用,但是会被用作特殊用途。比如__author__、__name__就是属于特殊变量。hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己编程定义的变量一般不会用这种变量名。
-
类似_xxx和__xxx这种格式的函数和变量就是非公开的(private),不应该被直接引用。
-
补充:_xxx的函数和变量是protected,我们直接从外部访问不会产生异常。__xxx的函数和变量是private,我们直接从外部访问会报异常,我们要注意前缀符号的区别。
我们要注意用词的区别,我们说的private函数和变量是“不应该”被直接引用,而不是“不能”被直接引用。这是因为在 Python 中并没有一种方法可以真正完全限制访问private函数或变量。但是我们为了养成良好的编程习惯,是不应该引用private函数或变量的。private函数的作用是隐藏函数的内部逻辑,让函数有更好的封装性。例如:
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
我们在上述程序块里公开了greeting()函数,greeting()函数需要使用_private_1()和_private_2()函数。学习者并不需要知道greeting()函数中的内部实现细节,所以我们可以将内部逻辑用private函数隐藏起来,这是一种十分常用的代码封装的方法。
六、循环结构
6.1 while循环与break语句
(1)while语句
while语句的基本形式为:
while 判断条件1:
循环语句
当判断条件1为true时,执行循环语句,直到判断条件1为假。例如:
count = 0
while(count <= 10):
print("现在计数为:",count)
count += 1
(2)break语句
break语句的基本形式为:
while 判断条件1:
循环语句
判断条件2:
break
当判断条件1为true时执行循环语句。若此时判断条件2为true,执行break跳出while循环,若判断条件2一直为false,则执行while循环,一直到判断条件1为false。
例如:
count = 0
while(count <= 10):
print("现在计数为:",count)
count += 1
if(count > 5):
break
6.2 for循环与continue语句
(1)for语句
for语句的基本形式为:
for iteration_var in sequence:
循环语句
依次遍历序列中的成员,执行循环语句。例如:
list = ['python','java','c','c++']
for book in list:
print("当前书籍为:",book)
(2)continue语句
continue语句的基本形式为:
for iteration_var in sequence:
循环语句
if 判断语句1:
continue
当遍历序列时,如果判断语句1为真,则执行continue语句,跳出当前循环,直接进入下一次循环。例如:
list = ['python','java','c','c++']
count = 0
for book in list:
count += 1
if count == 3:
continue
print("当前书籍为:",book)
6.3 循环嵌套
(1)for循环嵌套
for循环嵌套的基本形式为:
for iteration_var in sequence:
for iteration_var in sequence:
循环语句
例如:
for x in range(1,10):
for y in range(0,x):
result = x + y
print(result)
(2)while循环嵌套
while循环嵌套的基本形式为:
while 判断条件:
while 判断条件:
循环语句
例如:
x = 1
y = 0
while x < 10:
while y < x:
result = x + y
print(result)
y += 1
x += 1
y = 0
6.4 迭代器
(1)迭代器的优点
- for 循环遍历列表、元组等数据结构时,可以根据元素的位置(索引)来访问每个元素。例如,列表 list[0] 直接访问第一个元素。
- 迭代器 访问时,不用关心索引,而是按顺序一个个拿到元素。对于像列表和元组这样的结构,迭代器并没有特别的优势,因为我们可以直接通过索引访问。但是对于那些无法通过索引直接访问的数据结构,比如集合(set),迭代器是唯一可以访问其元素的方式。
迭代器访问元素的独特之处:
- 迭代器只在需要的时候才生成元素,这与我们平时使用的列表、元组不同。列表中的元素在创建时就已经存在,但迭代器可以动态生成数据,比如当你需要处理一个非常大的数据集合时(例如一百万条数据),用迭代器可以节省内存,因为它不会一次性创建所有元素,而是按需生成。
统一的访问接口:
- 迭代器提供了统一的访问方式,只要对象实现了 iter() 方法,它就可以使用迭代器来遍历。这样我们就可以在不同的数据结构(比如列表、集合、字典等)中都使用同样的方式遍历它们,而不用关心它们具体的内部实现。
(2)理解迭代器
可迭代对象:
在 Python 中,像列表(list)、元组(tuple)、字典(dict)这样的数据结构可以直接用于 for 循环,统称为可迭代对象(Iterable)。我们可以使用 isinstance() 来判断一个对象是否是可迭代对象。
from collections import Iterable
result = isinstance([],Iterable)
print(result)
result = isinstance((),Iterable)
print(result)
result = isinstance('python',Iterable)
print(result)
result = isinstance(213,Iterable)
print(result)
#结果为:
True
True
True
False
迭代器对象:
- 迭代器(Iterator)是一种可以被 next() 函数调用,并且能够逐个返回下一个值的对象。迭代器的好处是,它不会一次性加载所有数据,而是按需获取。
- 当所有元素访问完毕时,next() 会抛出一个 StopIteration 异常,表示迭代结束。
from collections import Iterator
result = isinstance([],Iterator)
print(result)
result = isinstance((),Iterator)
print(result)
result = isinstance((x for x in range(10)),Iterator)
print(result)
#结果为:
False
False
True
所有的Iterable都可以通过iter()函数转化为Iterator。
虽然列表、元组本身不是迭代器,但你可以使用 iter() 函数将它们转化为迭代器。这样就可以一个一个按顺序访问它们的元素。
(3)定义迭代器
当我们想自定义一个迭代器时,需要创建一个类,并在类中定义 iter() 和 next() 方法:
- iter():返回自身或迭代器对象。
- next():返回下一个元素,当没有更多元素时抛出 StopIteration。
class MyIterable:
def __iter__(self):
return MyIterator()
class MyIterator:
def __init__(self):
self.num = 0
def __next__(self):
self.num += 1
if self.num >= 10:
raise StopIteration
return self.num
(4)复制迭代器
迭代器当一次迭代完毕后就结束了,在此调用便会引发StopIteration异常。如果想要将迭代器保存起来,可以使用复制的方法:copy.deepcopy():x = copy.deepcopy(y),不可使用赋值的方法,这样是不起作用的。
七、顺序与选择结构
7.1. 顺序结构
顺序结构是程序最基本的执行方式,按照代码编写的顺序从上到下逐行执行,不存在任何跳转或条件判断。
print("第二步")
print("第三步")
#输出结果是:
复制代码
第一步
第二步
第三步
在顺序结构中,代码会按照书写顺序依次执行,没有任何条件或分支。
7.2 选择结构
选择结构允许程序根据条件判断,执行不同的代码块。Python 的选择结构主要通过 if、elif 和 else 来实现。
(1)if 语句
if 语句根据条件表达式的真假,决定是否执行对应的代码块。如果条件为真,则执行代码块;否则跳过。
x = 10
if x > 5:
print("x 大于 5")
#输出结果:
x 大于 5
(2)if-else 语句
if-else 语句用于在条件不满足时执行另一段代码。当条件为假时,执行 else 代码块。
x = 3
if x > 5:
print("x 大于 5")
else:
print("x 小于或等于 5")
输出结果:
x 小于或等于 5
(3)if-elif-else 语句
if-elif-else 结构允许在多个条件之间进行选择。每个条件依次判断,直到某个条件为真时,执行对应的代码块。
x = 7
if x > 10:
print("x 大于 10")
elif x > 5:
print("x 大于 5 小于等于 10")
else:
print("x 小于或等于 5")
#输出结果:
x 大于 5 小于等于 10
7.3 三三目运算符
在 Python 中,三目运算符(也叫条件表达式或三元运算符)是一种简洁的条件判断方式,可以根据某个条件的真假,选择执行不同的表达式。它的语法与其他编程语言中的三目运算符略有不同。
Python 中的三目运算符语法
result = true_value if condition else false_value
- condition:需要判断的条件。如果条件为 True,则执行 true_value;否则执行 false_value。
- true_value:条件为 True 时返回的值。
- false_value:条件为 False 时返回的值。
示例 1:基本使用
x = 10
y = 20
# 如果 x 大于 y,result 赋值为 'x 大于 y',否则赋值为 'x 小于等于 y'
result = "x 大于 y" if x > y else "x 小于等于 y"
print(result) # 输出: x 小于等于 y
在这个例子中,x > y 条件为 False,因此返回 false_value,即 x 小于等于 y。
示例 2:根据条件返回不同的值
num = 5
# 检查 num 是奇数还是偶数
result = "奇数" if num % 2 != 0 else "偶数"
print(result) # 输出: 奇数
在这个例子中,num % 2 != 0 检查 num 是否是奇数,如果是,则返回 "奇数",否则返回 "偶数"。
三目运算符的优点
简洁:它可以将 if-else 语句压缩到一行代码中,使代码更加简短和易读。
适合简单判断:当条件判断和返回值都比较简单时,使用三目运算符会让代码更简明。
注意:
虽然三目运算符可以使代码简短,但当条件或操作变得复杂时,应该优先考虑使用标准的 if-else 语句来提高代码的可读性。
八、模块
8.1 模块的定义
在 Python 中,模块(Module)是组织和管理代码的一种方式,它是包含 Python 代码的文件,通常用于将相关功能封装在一起。模块可以包含函数、类、变量,甚至是可执行代码。通过模块化代码,能够提高代码的复用性、可维护性和结构化程度。
(1) 定义模块
一个模块其实就是一个包含 Python 代码的 .py 文件。文件名就是模块名。例如,如果你有一个名为 my_module.py 的文件,它就是一个模块,里面可以定义函数、变量、类等。
# 文件: my_module.py
# 定义一个函数
def greet(name):
return f"Hello, {name}!"
# 定义一个变量
pi = 3.14159
(2) 导入模块
在使用模块中的内容之前,需要通过 import 语句将模块导入到当前程序中。
import my_module
# 调用模块中的函数
print(my_module.greet("Alice")) # 输出: Hello, Alice!
# 使用模块中的变量
print(my_module.pi) # 输出: 3.14159
(3) 从模块中导入特定内容
可以只导入模块中的某个函数或变量,而不导入整个模块,使用 from 语句:
from my_module import greet, pi
print(greet("Bob")) # 输出: Hello, Bob!
print(pi) # 输出: 3.14159
(4)模块的命名空间
每个模块都有自己独立的命名空间,这意味着同名的变量或函数在不同模块中不会冲突。例如,你可以在 my_module.py 和另一个模块中定义同名函数,但它们在各自的模块中互不影响。
(5) 内置和第三方模块
除了自己定义的模块,Python 还自带了大量的标准库模块(例如 math、os、random),你可以直接导入这些模块使用。此外,还有许多第三方模块,可以通过 pip 安装并导入使用。
使用标准库模块:
import math
# 使用 math 模块中的函数
print(math.sqrt(16)) # 输出: 4.0
(6)模块的组织:包
多个模块可以组织成一个包(Package),包是一个包含 init.py 文件的文件夹,用于管理多个相关的模块。
8.2 内置模块中的内置函数
在 Python 中,内置模块是 Python 自带的模块,它们不需要额外安装,直接可以使用。内置模块提供了丰富的功能,帮助开发者简化各种常见的编程任务,例如数学运算、文件处理、系统操作等。下面列出一些常见的内置模块
(1)math:提供了数学运算的函数和常量。
功能:平方根、对数、三角函数、常数如 π 和 e 等。
示例:
python
复制代码
import math
print(math.sqrt(16)) # 输出: 4.0
print(math.pi) # 输出: 3.141592653589793
(2)os:与操作系统交互的模块,提供了文件和目录操作等功能。
功能:创建、删除文件和目录,获取环境变量,执行系统命令等。
示例:
import os
print(os.getcwd()) # 输出当前工作目录
os.mkdir('new_folder') # 创建新目录
(3)sys:提供与 Python 解释器交互的功能。
功能:处理命令行参数、获取 Python 版本、退出程序等。
示例:
import sys
print(sys.version) # 输出 Python 版本
sys.exit() # 退出程序
(4)datetime:用于处理日期和时间的模块。
功能:获取当前日期、时间差计算、格式化日期等。
示例:
import datetime
now = datetime.datetime.now()
print(now) # 输出当前日期和时间
(5)random:生成随机数和随机选择的模块。
功能:生成随机数、打乱列表顺序、随机选择等。
示例:
import random
print(random.randint(1, 10)) # 输出 1 到 10 之间的随机整数
(6)json:用于处理 JSON 数据的模块。
功能:将 Python 对象转换为 JSON,或将 JSON 字符串解析为 Python 对象。
示例:
import json
data = {'name': 'Alice', 'age': 25}
json_data = json.dumps(data) # 转换为 JSON 字符串
print(json_data)
(7)re:正则表达式处理模块。
功能:用于模式匹配、替换、分割字符串等。
示例:
import re
pattern = r'\d+'
text = 'There are 123 apples'
result = re.findall(pattern, text) # 找到所有数字
print(result) # 输出: ['123']
(8)使用内置模块
要使用内置模块,只需要在代码中通过 import 语句导入模块:
import math
print(math.factorial(5)) # 输出: 120
内置模块的优点
无需安装:Python 内置的模块可以直接使用,不需要通过 pip 安装。
功能丰富:涵盖了数学、系统操作、日期时间、随机数生成等常见需求。
性能高:内置模块是 Python 官方提供的,经过优化,通常具有很高的性能。
总结
内置模块是 Python 自带的功能模块,直接可以导入使用。
常见内置模块包括
- os模块:文件和目录,用于提供系统级别的操作;
- sys模块:用于提供对解释器相关的操作;
- json模块:处理JSON字符串;
- logging: 用于便捷记录日志且线程安全的模块;
- time&datetime模块:时间相关的操作,时间有三种表示方式;
- hashlib模块:用于加密相关操作,代替了md5模块,主要是提供SHA1、SHA224、SHA256、SHA384、SHA512和MD5算法;
- random模块:提供随机数。
内置模块帮助简化了开发中的很多常见任务,提高了开发效率。
九、经典函数实例
9.1 递归函数 - 汉诺塔的魅力
在 Python 函数内部,我们可以去调用其他函数。所以如果一个函数在内部调用自身,这个函数我们就称为递归函数。本关我们将以汉诺塔的例子来感受递归函数的方法与应用。
汉诺塔问题源于印度一个古老传说。相传大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上并规定,任何时候,在小圆盘上都不能放大圆盘,且在三根柱子之间一次只能移动一个圆盘。如下图1所示,请问应该如何操作?
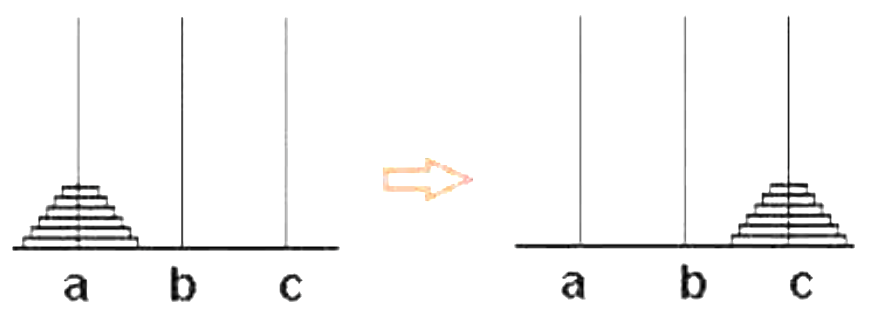
在编程语言中,如果一种计算过程的其中每一步都会用到前一步或前几步的结果,这个计算过程就可以称为递归的。而用递归计算过程定义的函数,则被称为递归函数。递归函数的应用很广泛,例如连加、连乘及阶乘等问题都可以利用递归思想来解决。而汉诺塔问题也是递归函数的经典应用。
汉诺塔问题的解决思路是:如果我们要思考每一步怎么移可能会非常复杂,但是可以将问题简化。我们可以先假设除a柱最下面的盘子之外,已经成功地将a柱上面的63个盘子移到了b柱,这时我们只要再将最下面的盘子由a柱移动到c柱即可。如下图2所示:
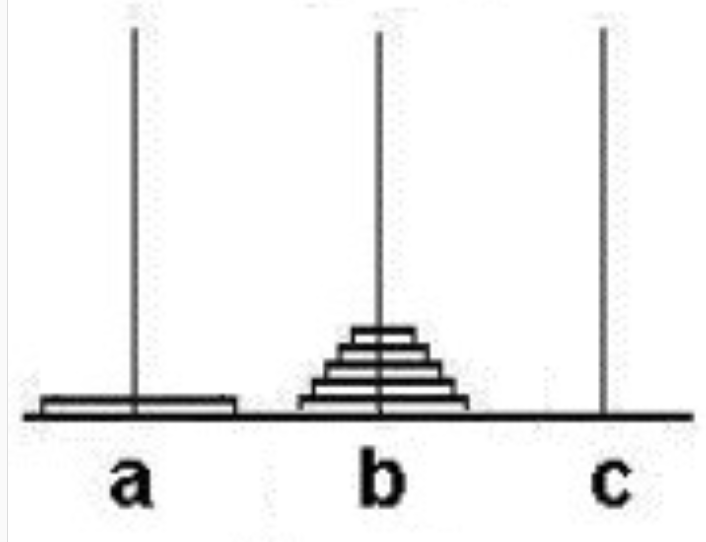
当我们将最大的盘子由a柱移到c柱后,b柱上便是余下的63个盘子,a柱为空。因此现在的目标就变成了将这63个盘子由b柱移到c柱。这个问题和原来的问题完全一样,只是由a柱换为了b柱,规模由64变为了63。因此可以采用相同的方法,先将上面的62个盘子由b柱移到a柱,再将最下面的盘子移到c柱。
以此类推,再以b柱为辅助,将a柱上面的62个圆盘最上面的61个圆盘移动到b柱,并将最后一块圆盘移到c柱。我们已经发现规律,我们每次都是以a或b中一根柱子为辅助,然后先将除了最下面的圆盘之外的其他圆盘移动到辅助柱子上,再将最底下的圆盘移到c柱子上,不断重复此过程。
这个反复移动圆盘的过程就是递归。例如我们每次想解决n个圆盘的移动问题,就要先解决(n-1)个盘子进行同样操作的问题。我们先假设a柱上只有3个圆盘,利用 Python 进行编程实现圆盘的移动,代码如下:
def move(n, a, b, c):
if(n == 1):
print(a,"->",c)
return
move(n-1, a, c, b)
move(1, a, b, c)
move(n-1, b, a, c)
move(3, "a", "b", "c")
函数运行结果:
a -> c
a -> b
c -> b
a -> c
b -> a
b -> c
a -> c
程序分析:
首先我们定义了一个函数move(n,a,b,c),参数n代表a柱上的圆盘个数,a,b,c三个柱子的顺序代表要将a柱上的圆盘最终移动到c柱上,然后b柱作为中间柱。
我们在递归函数中肯定会有终止递归的条件。第2到4行的代码就是表示,当a柱上的圆盘个数为1时,就中止递归并返回。因为此时a柱上面只有一个圆盘,肯定就是直接把圆盘从a柱移动到c柱了。
第5行的代码move(n-1, a, c, b)表示,先得把a柱上的n-1个圆盘从a柱移动到b柱,这时c柱是中间辅助柱。第6行的代码move(1, a, b, c)表示,当条件n=1的时候,把a柱上剩下的1个最大圆盘从a柱移动到c柱。
第7行的代码move(n-1, b, a, c)表示,现在n-1个圆盘已经转移到b柱上了,还是递归调用move函数,将n-1个圆盘从b柱移动到c柱,这时a柱是中间辅助柱。
最后我们调用move函数将3个圆盘从a柱移动到到c柱。当移动64个圆盘时,只需要将调用函数move(n,a,b,c)中的n变为64即可。这个计算量是十分巨大的,也只能交给计算机去解决。
小结
我们通过汉诺塔的例子感受了递归函数的基本思路,并尝试解决了一个具体问题。递归函数的优点是定义清晰、思路简洁,能够极大简化编程过程。理论上,所有的递归函数都可以用循环的方法代替,但循环方法的编程过程要比递归函数复杂很多。
9.2 lambda 函数 - 匿名函数的使用
在 Python 中,lambda 函数(也叫匿名函数)是一种简洁的方式来定义简单的函数。lambda 函数没有名字,通常用于需要快速定义一个简单函数的场景。
(1)lambda 函数的语法
lambda 函数的语法非常简单:
lambda 参数1, 参数2, ... : 表达式
- lambda 是关键字,表示定义一个匿名函数。
- 参数:可以有一个或多个参数,多个参数用逗号隔开。
- 表达式:lambda 函数的主体,表达式的计算结果会作为函数的返回值。
(2) lambda 函数的特点
lambda 函数只能包含一个表达式,不能包含多条语句。
它是匿名的,因为它没有名称。
常用于简单的、一次性的函数操作,特别是在像 map()、filter() 和 sorted() 等高阶函数中使用。
(3) lambda 函数的使用场景
I.替代简单的函数定义
你可以使用 lambda 函数替代普通函数的定义,适合非常简单的逻辑操作。
示例:
# 普通函数定义
def add(x, y):
return x + y
# 使用 lambda 函数
add_lambda = lambda x, y: x + y
# 调用 lambda 函数
print(add_lambda(3, 4)) # 输出: 7
II.在 map()、filter() 中使用 lambda
lambda 函数非常适合与 map()、filter() 这样的高阶函数结合使用。
map():对序列中的每个元素应用函数。
示例:
numbers = [1, 2, 3, 4, 5]
# 使用 lambda 函数将每个元素平方
squared_numbers = map(lambda x: x * x, numbers)
print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25]
filter():根据条件过滤序列中的元素。
示例:
numbers = [1, 2, 3, 4, 5, 6]
# 使用 lambda 函数过滤出偶数
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # 输出: [2, 4, 6]
III.在 sorted() 中使用 lambda 进行自定义排序
lambda 函数可以用于 sorted() 函数中的 key 参数,自定义排序规则。
示例:
students = [("Alice", 25), ("Bob", 20), ("Charlie", 23)]
# 按照年龄进行排序,使用 lambda 函数作为 key
sorted_students = sorted(students, key=lambda x: x[1])
print(sorted_students) # 输出: [('Bob', 20), ('Charlie', 23), ('Alice', 25)]
用法:
sorted(iterable, key=None, reverse=False)
iterable:要排序的可迭代对象,如列表、元组等。
key(可选):一个函数,用于从每个元素中提取用于排序的关键字。如果不提供,默认按元素本身排序。
reverse(可选):布尔值,指定排序顺序。默认是 False(升序)。如果为 True,则按降序排序。
IV.在 reduce() 中使用 lambda
lambda 函数还可以与 reduce()函数结合使用,用于累积计算。
示例:
from functools import reduce
numbers = [1, 2, 3, 4, 5]
# 使用 lambda 函数计算所有元素的积
product = reduce(lambda x, y: x * y, numbers)
print(product) # 输出: 120 (1*2*3*4*5)
(4)lambda 函数与普通函数的对比
简单性:lambda 函数适用于非常简单的操作,通常只包含一个表达式。对于复杂的逻辑,建议使用 def 定义的普通函数。
匿名性:lambda 函数没有名字,只是临时使用;而 def 定义的函数有名称,可以重复使用。
(5)lambda 函数的局限性
只能写一行:lambda 函数只能包含一个表达式,不能有多条语句。
可读性较差:大量使用 lambda 函数可能会降低代码的可读性,尤其是当表达式变得复杂时。
总结:
lambda 函数 是一种匿名函数,适用于定义简单的、一次性使用的函数。
它的典型使用场景包括与 map()、filter()、sorted() 和 reduce() 这样的高阶函数结合使用。
lambda 函数结构简单,适合用于非常简单的表达式操作,但对于复杂逻辑,建议使用 def 定义的普通函数。
9.3 Map-Reduce - 映射与归约的思想
(1) map() 函数
map() 函数用于将指定的函数应用于一个或多个可迭代对象中的每一个元素,返回一个迭代器。它可以理解为对可迭代对象中的每个元素“映射”一个操作。
语法:
map(function, iterable, ...)
- function:要应用的函数。
- iterable:一个或多个可迭代对象(如列表、元组等)。
- map() 返回一个 map 对象(迭代器),可以使用 list() 函数将其转换为列表。
# 定义一个函数,计算平方
def square(x):
return x * x
# 使用 map 对列表中的每个元素应用 square 函数
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(square, numbers)
# 将结果转换为列表
print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25]
你还可以传递多个可迭代对象:
# 对应位置相加
numbers1 = [1, 2, 3]
numbers2 = [4, 5, 6]
sum_numbers = map(lambda x, y: x + y, numbers1, numbers2)
print(list(sum_numbers)) # 输出: [5, 7, 9]
(2) reduce() 函数
reduce() 函数用于将可迭代对象中的元素进行累计计算,最终返回一个值。与 map() 不同,reduce() 逐步将可迭代对象的元素进行归约(简化),通常用于累加、累乘等操作。
from functools import reduce
reduce(function, iterable[, initializer])
- function:要应用的函数,它需要接收两个参数并返回一个结果。
- iterable:要处理的可迭代对象。
- initializer(可选):初始值,如果提供,它将作为计算的初始值。
reduce() 会对 iterable 中的元素进行两两累计计算,直到生成一个单一的值。
示例:
from functools import reduce
# 定义一个函数,将两个数相乘
def multiply(x, y):
return x * y
numbers = [1, 2, 3, 4, 5]
product = reduce(multiply, numbers)
print(product) # 输出: 120 (1 * 2 * 3 * 4 * 5)
你还可以为 reduce() 提供一个 initializer 参数:
#对所有元素求和,并加上初始值 10
sum_result = reduce(lambda x, y: x + y, [1, 2, 3, 4], 10)
print(sum_result) # 输出: 20 (10 + 1 + 2 + 3 + 4)
map() 和 reduce() 的对比
map():针对每个元素执行一个操作,并返回一个与输入大小相同的结果集合。
reduce():对集合中的元素进行归约,最终返回一个单一值。
注意:
在 Python 3 中,reduce() 不再是内置函数,需要从 functools 模块导入。
对于简单的情况,map() 和 reduce() 可以使用列表推导式或循环来代替,代码更易读。
总结
map():对每个元素应用一个函数,返回包含处理结果的迭代器。
reduce():将可迭代对象的元素进行累积计算,返回单一结果。
使用场景:map() 用于逐元素处理,reduce() 用于累计结果。
9.4 enumerate函数
在 Python 中,enumerate() 是一个内置函数,它用于在遍历可迭代对象时生成一个索引序列,同时返回元素及其对应的索引。这样可以在循环遍历列表、元组或其他可迭代对象时,既获取元素的值,又获取该元素在序列中的索引。
(1)enumerate() 函数的语法
enumerate(iterable, start=0)``
iterable:要遍历的可迭代对象(如列表、元组、字符串等)。
start(可选):用于指定索引的起始值,默认为 0。
(2) enumerate() 的作用
enumerate() 会将可迭代对象组合为一个索引序列,每次迭代返回一个包含索引和元素的元组。
示例:
# 定义一个列表
fruits = ["apple", "banana", "cherry"]
# 使用 enumerate 遍历列表,同时获取索引
for index, fruit in enumerate(fruits):
print(f"索引: {index}, 元素: {fruit}")
输出结果:
索引: 0, 元素: apple
索引: 1, 元素: banana
索引: 2, 元素: cherry
(3)start 参数的使用
enumerate() 的第二个参数 start 用于指定索引的起始值,默认情况下索引从 0 开始。如果你想从其他数字开始,可以设置 start 参数。
示例:
# 从索引 1 开始
for index, fruit in enumerate(fruits, start=1):
print(f"索引: {index}, 元素: {fruit}")
输出结果:
索引: 1, 元素: apple
索引: 2, 元素: banana
索引: 3, 元素: cherry
(4) enumerate() 的返回值
enumerate() 返回的是一个 迭代器,每次迭代生成一个包含索引和值的元组。如果你需要将它转换为列表或其他数据类型,可以使用 list() 函数进行转换。
示例:
# 将 enumerate 的结果转换为列表
enumerate_list = list(enumerate(fruits))
print(enumerate_list)
输出结果:
[(0, 'apple'), (1, 'banana'), (2, 'cherry')]
(5) 应用场景
同时获取元素和索引:enumerate() 常用于需要在循环中同时获取元素和索引的场景,比如需要根据索引对元素进行操作。
简化代码:相比使用 range(len(iterable)) 进行索引操作,enumerate() 可以让代码更加简洁、易读。
示例:修改列表中元素
fruits = ["apple", "banana", "cherry"]
# 修改列表中带有 'a' 的元素,将其转换为大写
for index, fruit in enumerate(fruits):
if 'a' in fruit:
fruits[index] = fruit.upper()
print(fruits) # 输出: ['APPLE', 'BANANA', 'cherry']
总结:
enumerate() 用于同时迭代元素和它们的索引,返回一个包含索引和值的元组。
它的常见使用场景是在循环中同时需要获取索引和元素的情况下。
通过可选的 start 参数,enumerate() 可以从任意索引开始。
使用 enumerate() 可以让代码更加简洁高效,避免手动使用 range(len(iterable)) 来获取索引。
9.4 eval() 函数
eval() 函数是 Python 中的一个内置函数,它的功能是将字符串解析并执行为 Python 表达式。eval() 可以动态地执行传入的字符串内容,并返回表达式的结果。
(1) eval() 函数的语法
eval(expression, globals=None, locals=None)
- expression:一个字符串,表示有效的 Python 表达式。
- globals(可选):用于指定全局变量环境,默认为当前全局环境。
- locals(可选):用于指定局部变量环境,默认为当前局部环境。
(2)eval() 的基本功能
eval() 可以将传入的字符串作为一个合法的 Python 表达式执行,并返回其结果。例如,可以用它执行简单的算术运算、调用函数、访问变量等。
示例:
# 执行简单的算术表达式
result = eval("2 + 3 * 5")
print(result) # 输出: 17
在上面的例子中,eval() 将字符串 "2 + 3 * 5" 作为表达式进行计算,返回的结果是 17。
总结:
eval() 是一个可以动态执行 Python 表达式的函数,它将字符串内容解析为 Python 表达式并执行。
使用场景:可以用于执行简单的数学运算、调用函数、访问变量等。
注意安全:由于 eval() 可以执行任意代码,使用时要确保传入的字符串是安全的,避免执行不受信任的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号