
辜老师的C++课堂笔记
不代表全部内容
第一章 C++引论
教材和参考资料
教材:C++程序设计实践教程(新国标微课版)
出版:华中科技大学出版社
编著:马光志
参考文献 : C++ Primer(第五版)
深度探索C++对象模型
C++ 11标准
1.1程序设计语言
- 机器语言: 计算机自身可以识别的语言(CPU指令)
- 汇编语言: 接近于机器语言的符号语言(更便于记忆,如MOV指令)
- 高级语言: 更接近自然语言的程序设计语言,如ADA、C、PASCAL、FORTRAN、BASIC(面向过程,程序基本单元是函数)
- 面向对象的语言:描述对象“特征”及“行为”的程序设计语言,如C++、Java、C#、SMALLTALK等(程序基本单元是类)
1.2程序编译技术
编译过程: 预处理、词法分析、语法分析、代码生成、模块连接。
- 预处理:通过#define宏替换和#include插入文件内容生成纯的不包含#define和#include等的C或C++程序。
- 词法分析:产生一个程序的单词序列(token)。一个token可以是保留字如if和for、标识符如sin、运算符如+、常量如5和 "abcd"等。
- 语法分析:检查程序语法结构,例如if后面是否出现else。
- 代码生成:生成低级语言代码如机器语言或汇编语言。C和C++语言的标识符编译为低级语言标识符时会换名,C和C++的换名策略不一样。代码生成的是中间代码(如.OBJ文件)
- 模块连接:将中间代码和标准库、非标准库连接起来,形成一个可执行的程序。静态连接是编译时由编译程序完成的连接,动态连接是运行时由操作系统完成的连接。
不同厂家对C++标准的支持程度不一样。一定要确认当前使用的编译器是否支持C++11甚至11以上的标准。
在程序编译过程中,函数调用的实现可以通过静态链接和动态链接两种方式来完成。
1. 静态链接
静态链接是在编译时将库的内容与用户程序的目标文件(如 .obj 文件)一起打包,生成最终的可执行文件(如 .exe)。在静态链接中,库文件(如 f.lib)的内容被直接拷贝到可执行文件中。
- 工作过程:
用户程序编译后生成的 .obj 文件会和 f.lib 进行链接。
函数 f 的实现会被直接拷贝到用户程序的最终可执行文件中(如 .exe 文件)。
当用户程序启动时,所有使用到的库函数,包括 f,都会被加载到内存中。
- 内存占用:
如果有多个程序都使用静态链接,并且都调用了函数 f,那么每个程序的内存中都会有一份 f 函数的副本。这意味着每个程序的内存中都会保存一份独立的 f 函数。
- 优点:
不需要在运行时加载库,所有依赖的库函数已经嵌入到可执行文件中,因此不会遇到库缺失的问题。
程序的启动速度较快,因为所有的代码已经在编译时集成。
- 缺点:
由于每个程序都包含了库的副本,多个程序会导致内存的重复使用。
如果库函数需要更新,所有使用静态链接的程序都需要重新编译。
- 例子:
在静态链接的情况下,假设程序 A 和程序 B 都调用了函数 f,它们的 .exe 文件中都会包含 f 的实现。因此,在内存中,程序 A 和程序 B 各自有一个 f 函数的副本。
2. 动态链接
动态链接是在运行时才将库加载到内存中,并为程序提供所需的函数实现。库文件以动态链接库的形式存在(如 .dll 文件),而不是在编译时嵌入到可执行文件中。
- 工作过程:
编译时,用户程序的 .obj 文件和 f.dll 文件进行链接,生成可执行文件。
在这个过程中,目标文件中并不会包含 f 函数的实际代码,而是只包含函数 f 的描述信息。
当程序运行并且调用 f 函数时,系统会动态加载 f.dll,并将 f 函数的实现加载到内存中供程序使用。
- 内存占用:
动态链接的最大好处之一是,多个程序可以共享同一个库的副本。也就是说,如果程序 A 和程序 B 都使用 f.dll,那么 f 函数的实现只会在内存中存在一个副本,所有程序共享这一份库。
- 优点:
节省内存:多个程序可以共享动态链接库的代码,不会重复加载函数 f 的实现。
易于更新:库的实现可以独立更新,无需重新编译所有依赖它的程序。只需要替换动态链接库的文件即可。
- 缺点:
程序启动时可能会稍慢,因为需要在运行时加载库。
运行时依赖动态链接库,若 .dll 文件缺失或损坏,程序将无法正常运行。
- 例子:
假设程序 A 和程序 B 都调用 f 函数,并且都通过 f.dll 动态链接。在内存中,程序 A 和程序 B 都会共享同一个 f 函数的副本,而不会各自有独立的副本。这大大减少了内存的重复使用。
第二章 类型、常量及变量
2.1 C++的单词
单词包括常量、变量名、函数名、参数名、类型名、运算符、关键字等。
关键字也被称为保留字,不能用作变量名。
预定义类型如int等也被当作保留字
char16_t和char32_t是C++11引入的两种新的字符类型,用于表示特定大小的Unicode字符
例如 char16_t x = u'马';
wchar_t表示char16_t ,或char32_t
nullptr表示空指针
需要特别注意的是:char可以显示地声明为带符号的和无符号的。因此C++11标准规定char,signed char和unsigned char是三种不同的类型。
但每个具体的编译器实现中,char会表现为signed char和unsigned char中的一种。
unsigned char ua = ~0;
printf("%d ", ua);//输出255
signed char ub = ~0;
printf("%d ", ub);//输出-1
char uc = ~0;
printf("%d", uc);//输出-1
2.2 预定义类型(内置数据类型)及值域和常量
2.2.1 常见预定义类型
类型的字节数与硬件、操作系统、编译有关。假定VS2019采用X86编译模式。
void:字节数不定,常表示函数无参或无返回值。
void
是一个可以指向任意类型的指针类型。它本质上是一个“无类型”*的指针,这意味着它可以指向任何类型的数据,而不关心具体的数据类型。
int n = 0721;//前置0代表8进制
double pi = 3.14;
void* p = &n;
cout << *(int*)p << endl;//不能直接解引用哦
p = π
cout << *(double*)p << endl;
- bool:单字节布尔类型,取值false和true。
- char:单字节有符号字符类型,取值-128~127。
- short:两字节有符号整数类型,取值-32768~32767。
- int:四字节有符号整数类型,取值-231~231-1 。
- long:四字节有符号整数类型,取值-231~231-1 。
- float:四字节有符号单精度浮点数类型,取值-1038~1038。
- double:八字节有符号双精度浮点数类型,取值-10308~10308。
注意:默认一般整数常量当作为int类型,浮点常量当作double类型。 - char、short、int、long前可加unsigned表示无符号数。
- long int等价于long;long long占用八字节。
- 自动类型转换路径(数值表示范围从小到大):
char→unsigned char→ short→unsigned short→ int→unsigned int→long→unsigned long→float→double→long double。
数值零自动转换为布尔值false,数值非零转换为布尔值true。 - 强制类型转换的格式为:
(类型表达式) 数值表达式 - 字符常量:‘A’,‘a’,‘9’,‘\’’(单引号),‘\’(斜线),‘\n’(换新行),‘\t’(制表符),‘\b’(退格)
- 整型常量:9,04,0xA(int); 9U,04U,0xAU(unsigned int); 9L,04L,0xAL(long); 9UL, 04UL,0xAUL(unsigned long), 9LL,04LL,0xALL(long long);
这里整型常量的类型相信大家看后面的字母也能看出来,例如L代表long,U代表unsigned
2.2.2预定义类型的数值输出格式化
- double常量:0.9, 3., .3, 2E10, 2.E10, .2E10, -2.5E-10
- char: %c; short, int: %d; long:%ld; 其中%开始的输出格式符称为占位符。
- 输出无符号数用u代替d(十进制),八进制数用o代替d,十六进制用x代替d
- 整数表示宽度如printf(“%5c”, ‘A’)打印字符占5格(右对齐)。%-5d表示左对齐。
- float:%f; double:%lf。float, double:%e科学计数。%g自动选宽度小的e或f。
- 可对%f或%lf设定宽度和精度及对齐方式。“%-8.2f”表示左对齐、总宽度8(包括符号位和小数部分),其中精度为2位小数。
- 字符串输出:%s。可设定宽度和对齐:printf(“%5s”,”abc”)。
- 字符串常量的类型:指向只读字符的指针即const char *, 上述”abc“的类型。
- 注意strlen(“abc”)=3,但要4个字节存储,最后存储字符‘\0’,表示串结束。
2.3 变量及其类型解析
2.3.1 变量的声明和定义(C++11标准3.1节)
- 变量说明:描述变量的类型及名称,但没有初始化。可以说明多次。
- 变量定义:描述变量的类型及名称,同时进行初始化。只能定义一次。
- 说明例子:extern int x; extern int x; //变量可以说明多次
- 定义例子:int x=3; extern int y=4; int z; //全局变量z的初始值为0
- 模块静态变量:使用static在函数外部定义的变量,只在当前文件(模块)可用。可通过单目::访问。
- 局部静态变量:使用static在函数内部定义的变量。
static int x, y; //模块静态变量x、y定义,默认初始值均为0
int main( ){
static int y; //局部静态变量y定义, 初始值y=0
return ::y+x+y;//分别访问模块静态变量y,模块静态变量x,局部静态变量
}
为了允许把程序拆分成多个逻辑部分来编写,C++支持分离式编译(separation compilation),即将程序分成多个文件,每个文件独立编译。
为了支持分离式编译,必须将声明(Declaration)和定义(Definition)区分开来。声明是使得名字(Identifier,如变量名)为其它程序所知。而定义则负责创建与名字(Identifier)相关联的实体,如为一个变量分配内存单元。因此只有定义才会申请存储空间。
One definition rule(ODR):只能定义一次,但可以多次声明
如果想要声明一个变量而非定义它,就在前面加关键字extern,而且不要显示地初始化变量:
extern int i; //变量的声明
int i;//变量的定义(虽没有显示初始化,但会有初始值并分配内存单元存储,即使初始值随机)
任何包含显式初始化的声明成为定义。如果对extern的变量显式初始化,则extern的作用被抵消。
extern int i = 0; //变量的定义
声明和定义的区别非常重要,如果要在多个文件中使用同一个变量,就必须将声明和定义分离,变量的定义必须且只能出现在一个文件中,而其他用到该变量的文件必须对其声明,而不能定义。
例如,头文件里不要放定义,因为头文件可能会被到处include,导致定义多次出现。
值得一提的是C++17引入了 inline 变量,这允许在多个翻译单元中定义同一个全局变量而不引发重复定义的链接错误。inline 变量使得变量像 inline 函数一样,在多个文件中共享同一个定义。而在之前的标准中,inline只能用于函数而不能用于变量
- 保留字inline用于定义函数外部变量或函数外部静态变量、类内部的静态数据成员。
- inline函数外部变量的作用域和inline函数外部静态变量一样,都是局限于当前代码文件的,相当于默认加了static。
- 用inline定义的变量可以使用任意表达式初始化
// header.h
inline int globalVar = 42;
关于其作用,可见C++17之 Inline变量
此外, C++20 引入了模块(Modules)机制,用于替代头文件的传统做法。模块减少了编译依赖并提高了编译速度。在模块中,变量声明和定义的规则更为清晰,模块能够很好地管理变量的可见性和作用范围。
如有兴趣,可见C++20 新特性: modules 及实现现状
2.3.2 变量的初始化(C++11标准8.5节)
变量在创建时获得一个值,我们说这个变量被初始化了(initialized)。最常见的形式为:类型 变量名=表达式;//表达式的求值结果为变量的初始值
用=来初始化的形式让人误以为初始化是赋值的一种。
其实完全不同:初始化的含义是创建变量时设定一个初始值;而赋值的含义是将变量的当前值擦除,而以一个新值来替代。
实际上,C++定义了多种初始化的形式:
int a = 0;
int b = { 0 };
int c(0);
int d{ 0 };
其中用{ }来初始化作为C++11的新标准一部分得到了全面应用(而以前只在一些场合使用,例如初始化结构变量)。这种初始化形式称为列表初始化(list initialization)。
只读变量:使用const或constexpr说明或定义的变量,定义时必须同时初始化。当前程序只能读不能修改其值。constexpr变量必须用编译时可计算表达式初始化。
易变变量:使用volatile说明或定义的变量,可以后初始化。当前程序没有修改其值,但是变量的值变了。不排出其它程序修改。
const实例:extern const int x; const int x=3; //定义必须显式初始化x
volatile例: extern volatile int y; volatile int y; //可不显式初始化y,全局y=0
若y=0,语句if(y==2)是有意义的,因为易变变量y可以变为任何值。
- volatile 的作用
编译器通常会进行优化,将变量的值缓存到寄存器中,以提高访问速度。然而,某些情况下,变量的值可能会在程序执行过程中发生外部变化,例如通过硬件、信号、操作系统或多线程访问。因此,需要使用 volatile 关键字告知编译器,每次访问该变量时都要重新读取内存中的值,而不要使用优化的缓存值。
2.3.3 constexpr(c++11)
**constexpr **是 C++11 引入的关键字,主要用于在编译期计算常量。constexpr 声明的变量或函数保证可以在编译时求值,并且在特定条件下也可以在运行时使用。它用于提高编译期计算的能力,从而优化程序的性能。
- 任何被声明为 constexpr 的变量或对象,必须在编译时能求出其值。
- constexpr 变量比 const 更加严格,所有的初始化表达式必须是常量表达式。
字面值类型:对声明constexpr用到的类型必须有限制,这样的类型称为字面值类型(literal type)。
算术类型(字符、布尔值、整型数、浮点数)、引用、指针都是字面值类型
自定义类型(类)都不是字面值类型,因此不能被定义成constexpr
其他的字面值类型包括字面值常量类、枚举
constexpr类型的指针的初始值必须是
- nullptr
- 0
- 指向具有固定地址的对象(全局、局部静态)。
注意局部变量在堆栈里,地址不固定,因此不能被constexpr类型的指针指向
当用constexpr声明或定义一个指针时,constexpr仅对指针有效 ,即指针是const的,
int i=0;
//constexpr指针
const int *p = nullptr; //p是一个指向整型常量的指针
constexpr int *q = nullptr; //q是一个指向整数的constexpr指针
constexpr int *q2 = 0;
constexpr int *q3 = &i; //constexpr指针初始值可以指向全局变量i
int f2() {
static int ii = 0;
int jj = 0;
constexpr int *q4 = ⅈ//constexpr指针初始值可以指向局部静态变量
//constexpr int *q5 = &jj;//错误:constexpr指针初始值不可以指向局部变量,局部变量在堆栈,非固定地址
return ++i;
}
constexpr函数:是指能用于常量表达式的函数,规定:
-
函数返回类型和形参类型都必须是字面值类型
-
函数体有且只有一条return语句(c++11)
C++14之后,constexpr 函数可以包含复杂的控制流语句,如 if、for、while 等,这使得 constexpr 函数更加灵活和强大。 -
constexpr函数被隐式地指定为内联函数,因此函数定义可放头文件
-
constexpr函数体内也可以包括其他非可执行语句,包括空语句,类型别名,using声明
-
在编译时,编译器会将函数调用替换成其结果值,即这种函数在编译时就求值
如果传递给 constexpr 函数的参数是常量表达式(可以在编译时求值),那么编译器将会在编译时对这个函数进行求值。
如果参数不是常量表达式,constexpr 函数将作为普通函数在运行时进行求值。 -
constexpr函数返回的不一定是常量表达式
//constexpr函数
constexpr int new_size() { return 42; }
constexpr int size = new_size() * 2; //函数new_size是constexpr函数,因此size是常量表达式
//允许constexpr返回的是非常量
constexpr int scale(int cnt) { return new_size() * cnt;}
//这时scale是否为constexpr取决于实参
//当实参是常量表达式时, scale返回的也是constexpr
constexpr int rtn1 = scale(sizeof(int)); //实参sizeof(int)是常量表达式,因此rtn1也是
int i = 2;
//constexpr int rtn2 = scale(i); //编译错:实参i不是是常量表达式,因此scale返回的不是常量表达式
2.3.4 复合类型(C++11标准3.9.2)
复合类型(Compound Type)是指基于其他类型定义的类型,例如指针、引用。和内置数据类型变量一样,复合类型也是通过声明语句(declaration)来声明。一条声明语句由基本数据类型和跟在后面的声明符列表(declarator list)组成。每个声明符命名一个变量并指定该变量为与基本数据类型有关的某种类型。
复合类型的声明符基于基本数据类型得到更复杂的类型,如p,&p,分别代表指向基本数据类型变量的指针和指向基本数据类型变量的引用。,&是类型修饰符。
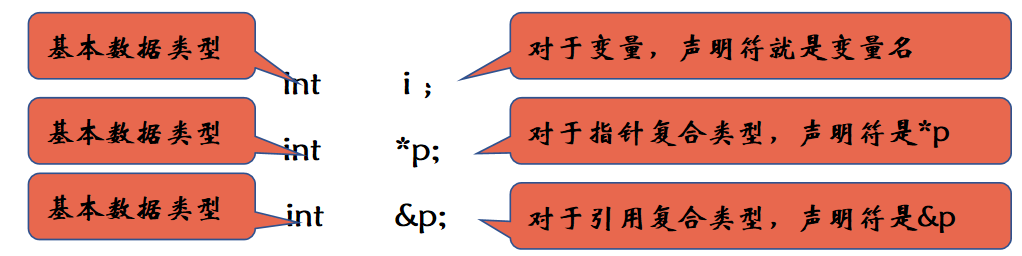
在同一条声明语句中,基本数据类型只有一个,但声明符可以有多个且形式可以不同,即一条声明语句中可以声明不同类型的变量:
int i, *p, &r; //i是int变量,p是int指针,r是int引用
正确理解了上面的定义,就不会对下面的声明语句造成误解:
int * p1,p2; //p1是int指针,p2不是int指针,而是int变量
为了避免类似的误解,一个好的书写习惯是把类型修饰符和变量名放连一起:
int *p1,p2, &r1;
2.3.5 指针及其类型理解
-
const默认与左边结合,左边没有东西则与右边结合
-
指针类型的变量使用*说明和定义,例如:int x=0; int *y=&x;。
-
指针变量y存放的是变量x的地址,&x表示获取x的地址运算,表示y指向x。
-
指针变量y涉及两个实体:变量y本身,y指向的变量x。
-
变量x、y的类型都可以使用const、volatile以及const volatile修饰。
const int x=3; //不可修改x的值
const int *y=&x; //可以修改y的值,但是y指向的const int实体不可修改
const int *const z=&x; //不可修改z的值,且z指向的const int实体也不可改 -
在一个类型表达式中,先解释优先级高的,若优先级相同,则按结合性解释。
如:int *y[10][20];在y的左边是*,右边是[10],据表2.7知[ ]的优先级更高。
解释: (1) y是一个10元素数组;(2)每个数组元素均为20元素数组
(3) 20个元素中的每个元素均为指针int * -
但括号()可提高运算符的优先级,如:
int (*z)[10][20];
(…)、[10]、[20]的运算符优先级相同,按照结合性,应依次从左向右解释。
因此z是一个指针,指向一个int型的二维数组,注意z与y的解释的不同。
指针移动:y[m][n]+1移动到int 指针指向的下一整数,z+1移动到下一1020整数数组。
指针使用注意事项
-
只读单元的指针(地址)不能赋给指向可写单元的指针变量。
例如:
const int x=3; const int *y=&x; //x是只读单元,y是x的地址
int z=y; //错:y是指向只读单元的指针
z=&x; //错:&x是是只读单元的地址
证明:
(1)假设int z=&x正确(应用反正法证明)
(2)由于int z表示z指向的单元可写,故z=5是正确的
(3)而z修改的实际是变量x的值,const int x规定x是不可写的。矛盾。
可写单元的指针(地址)能赋给指向只读单元的指针变量: y=z;
前例的const换成volatile或者const volatile,结论一样。
int可以赋值给const int *,const int 不能赋值给int -
除了二种例外情况,指针类型类型都要与指向(绑定)的对象严格匹配:二种例外是:
- 指向常量的指针(如const int *)可以指向同类型非常量
- 父类指针指向子类对象
2.4 引用
引用(reference)为变量起了一个别名,引用类型变量的声明符用&来修饰变量名:
int i = 10;//i为一个整型变量
int &r = i; //定义一个引用变量r,引用了变量i,r是i的别名
//定义引用变量时必须马上初始化,即马上指明被引用的变量。
int &r2; //编译错误,引用必须初始化,即指定被引用变量
C++11增加了一种新的引用:右值引用(rvalue reference),课本上叫无址引用,用&&定义. 当采用术语引用时,我们约定都是指左值引用(lvalue reference),课本上叫有址引用,用&定义。关于右值引用,会在后续介绍
2.4.1 左值和右值
C++表达式的求值结果要不是左值(lvaue),要不是右值(rvalue)。在C语言里,左值可以出现在赋值语句的左侧(当然也可以在右侧),右值只能出现在赋值语句的右侧。
但是在C++中,情况就不是这样。C++中的左值与右值的区别在于是否可以寻址:可以寻址的对象(变量)是左值,不可以寻址的对象(变量)是右值。这里的可以寻址就是指是否可以用&运算符取对象(变量)的地址。
int i = 1; //i可以取地址,是左值;1不可以取地址,是右值
//3 = 4; //错误:3是右值,不能出现在赋值语句左边
const int j = 10; //j是左值, j可以取地址
const int *p = &j;
// j = 20; //错误:const左值(常量左值)不能出现在赋值语句左边
非常量左值可以出现在赋值运算符的左边,其余的只能出现在右边。右值出现的地方都可以用左值替代。
区分左值和右值的另一个原则就是:左值持久、右值短暂。左值具有持久的状态(取决于对象的生命周期),而右值要么是字面量,要么是在表达式求值过程中创建的临时对象。
//i++等价于用i作为实参调用下列函数
//第一个参数为引用x,引用实参,因此x = x + 1就是将实参+1;第二个int参数只是告诉编译器是后置++
int operator++(int &x, int) {
int tmp= i; //先取i的值赋给temp
x = x + 1;
return tmp;
}
//因此i++ = 1不成立,因为1是要赋值给函数的返回值,而函数返回后,tmp生命周期已经结束,不能赋值给tmp
//i++等价于operator++(i, int),实参i传递给形参x等价于int &x = i;
2.4.2 引用的本质
引用的本质还是指针,考查以下C++代码及其对应的汇编代码
int i = 10;
int &ri = i;
ri = 20;
//从汇编代码可以看到,引用变量ri里存放的就是i的地址
int i = 10;
mov dword ptr [i],0Ah //将文字常量10送入变量i
int &ri = i;
lea eax,[i] //将变量i的地址送入寄存器eax
mov dword ptr [ri],eax //将寄存器的内容(也就是变量i的地址)送入变量ri
ri = 20;
mov eax,dword ptr [ri] //将变量ri的值送入寄存器eax
mov dword ptr [eax],14h //将数值20送入以eax的内容为地址的单元中
引用变量在功能上等于一个常量指针
但是,为了消除指针操作的风险(例如指针可以++,- -),引用变量ri的地址不能由程序员获取,更不允许改变ri的内容。
由于引用本质上是常量指针,因此凡是指针能使用的地方,都可以用引用来替代,而且使用引用比指针更安全。例如Java、C#里面就取消了指针,全部用引用替代。
- 引用与指针的区别是:
- 引用在逻辑上是“幽灵”,是不分配物理内存的,因此无法取得引用的地址,也不能定义引用的引用,也不能定义引用类型的数组。引用定义时必须初始化,一旦绑定到一个变量,绑定关系再也不变(常量指针一样)。
- 指针是分配物理内存的,可以取指针的地址,可以定义指针的指针(多级指针),指针在定义时无需初始化(但很危险)。对于非常量指针,可以被重新赋值(指向不同的对象,改变绑定关系),可以++, --(有越界风险)
- 定义了引用后,对引用进行的所有操作实际上都是作用在与之绑定的对象之上。被引用的实体必须是分配内存的实体(能按字节寻址)
- 寄存器变量可被引用,因其可被编译为分配内存的自动变量。
- 位段成员不能被引用,计算机没有按位编址,而是按字节编址。注意有址引用被编译为指针,存放被引用实体内存地址。
- 引用变量不能被引用。对于int x; int &y=x; int &z=y; 并非表示z引用y, int &z=y表示z引用了y所引用的变量i。
例如
struct A {
int j : 4; //j为位段成员
int k;
} a;
void f() {
int i = 10;
int &ri = i; //引用定义必须初始化,绑定被引用的变量
ri = 20; //实际是对i赋值20
int *p = &ri; //实际是取i的地址,p指向i,注意这不是取引用ri的地址
//int &*p = &ri; //错误:不能声明指向引用的指针
//int & &rri = ri; //错误:不能定义引用的引用
//int &s[4]; //错误:数组元素不能为引用类型,否则数组空间逻辑为0
register int i = 0, &j = i; //正确:i、j都编译为(基于栈的)自动变量
int t[6], (&u)[6] = t; //正确:有址引用u可引用分配内存的数组t
int &v = t[0]; //正确:有址引用变量v可引用分配内存的数组元素
//int &w = a.j; //错误:位段不能被有址引用,按字节编址才算有内存
int &x = a.k; //正确:a.k不是位段有内存
}
2.4.3 引用初始化
引用初始化时,除了二种例外情况,引用类型都要与绑定的对象严格匹配:即必须是用求值结果类型相同的左值表达式来初始化。二种例外是:
- const引用
- 父类引用绑定到子类对象
int j = 0;
const int c = 100;
double d = 3.14;
int &rj1 = j; //用求值结果类型相同的左值表达式来初始化
//int &rj2 = j + 10; //错误:j + 10是右值表达式
//int &rj3 = c; //错误:c是左值,但类型是const int,类型不一致
//int &rj4 = j++; //错误:j++是右值表达式
//int &rd = d; //错误:d是double类型左值,类型不一致
而const引用则是万金油,可以用类型相同(如类型不同,看编译器)的左值表达式和右值表达式来初始化。
int j = 0;
const int c = 100;
double d = 3.14;
const int &cr1 = j; //常量引用可以绑定非const左值
const int &cr2 = c; //常量引用可以绑定const左值
const int &cr3 = j + 10; //常量引用可以绑定右值
const int &cr4 = d; //类型不一致,报**警告**错误 (VS2017)
int &&rr = 1; //rr为右值引用
const int &cr5 = rr; //常量引用可以绑定同类型右值引用
2.4.3.1 为什么非const引用不能用右值或不同类型的对象初始化?
对不可寻址的右值或不同类型对象,编译器为了实现引用,必须生成一个临时(如常量)或不同类型的值,对象,引用实际上指向该临时对象,但用户不能通过引用访问。如当我们写
double dval = 3.14;
int &ri = dval;
编译器将其转换成
int temp = dval; //注意将dval转换成int类型
int &ri = temp;
如果我们给ri赋给新值,改变的是temp而不是dval。对用户来说,感觉赋值没有生效(这不是好事)。
const引用不会暴露这个问题,因为它本来就是只读的。
干脆禁止用右值或不同类型的变量来初始化非const引用比“允许这样做,但实际上不会生效”的方案好得多。
2.4.3.2 &定义的有址引用(左值引用)
const和volatile有关指针的用法可推广至&定义的(左值)引用变量
例如:“只读单元的指针(地址)不能赋给指向可写单元值的指针变量”推广至引用为“只读单元的引用不能初始化引用可写单元的引用变量”。如前所述,反之是成立的。
int &可以赋值给const int &,const int &不能赋值给int &
-
const int &u=3; //u是只读单元的引用 -
int &v=u; //错:u不能初始化引用可写单元的引用变量v -
int x=3; int &y=x;//对:可进行y=4,则x=4。 -
const int &z=y; //对:不可进行z=4。但若y=5,则x=5, z=5。 -
volatile int &m=y;//对,m引用x。
左值引用的主要作用:
- 为对象创建别名
左值引用允许为一个对象创建别名,方便代码编写和对象操作。 - 作为函数参数传递
左值引用可以用于函数参数的传递,尤其是在函数需要修改参数时。相比值传递,引用传递可以避免复制对象,节省内存和提高性能。 - 避免不必要的拷贝
左值引用避免了传值带来的对象拷贝开销,尤其在传递大型对象时,引用可以显著提高效率。
void print(const std::string& str) {
std::cout << str << std::endl;
}
std::string largeString = "This is a very large string.";
print(largeString); // 通过引用传递,避免拷贝
- 允许修改引用的对象
通过左值引用,可以直接修改所引用对象的内容。这种特性使得它适用于修改对象的场景,例如更新数据或改变状态。 - 在返回值中使用左值引用
函数可以返回左值引用,允许调用者直接操作函数返回的对象。注意,返回的对象必须有较长的生命周期,不能返回局部变量的引用。
int& getX(int& x) {
return x; // 返回 x 的引用
}
int main() {
int a = 5;
getX(a) = 100; // 可以通过函数返回的引用修改 a
std::cout << a << std::endl; // 输出 100
}
- 支持左值对象的传递
左值引用可以绑定到左值对象,而左值是指那些在内存中具有明确地址、生命周期较长的对象。左值引用允许对这些左值进行操作。
int x = 10;
int& ref = x; // 左值引用绑定到 x
ref = 20; // 修改 x 的值
2.4.3.3 &&定义的无址引用(右值引用)
右值引用:就是必须绑定到右值的引用。
右值引用的重要性质:只能绑定到即将销毁的对象,包括字面量,表达式求值过程中创建的临时对象。
返回非引用类型的函数、算术运算、布尔运算、位运算、后置++,后置--都生成右值,右值引用和const左值引用可以绑定到这些运算的结果上。
c++ 11中的右值引用使用的修饰符是&&,如:
int &&aa = 1; //实质上就是将不具名(匿名)变量取了个别名
aa = 2; //可以。匿名变量1的生命周期本来应该在语句结束后马上结束,但是由于被右值引用变量引用,其生命期将与右值引用类型变量aa的生命期一样。这里aa的类型是右值引用类型(int &&),但是如果从左值和右值的角度区分它,它实际上是个左值
- &&定义右值引用变量,必须引用右值。如int &&x=2;
- 注意,以上x是右值引用(引用了右值),但它本身是左值,即可进行赋值:x=3;
- 但:const int &&y=2;//不可赋值: y=3;
- 同理:“右值引用共享被引用对象的“缓存”,本身不分配内存。”
int && *p; //错:p不能指向没有内存的无址引用
int && &q; //错:int &&没有内存,不能被q引用
int & &&r; //错:int &没有内存,不能被r引用。
int && &&s; //错:int &&没有内存,不能被s引用
int &&t[4]; //错:数组的元素不能为int &&:数组内存空间为0。
const int a[3]={1,2,3}; int(&& t)[3]=a; //错:a是有址的, 有名的均是有址的。&&不能引用有址的
int(&& u)[3]= {1,2,3}; //正确,{1,2,3}是无址右值
右值引用的主要作用:
-
移动语义:允许临时对象的资源(如内存、文件句柄等)被“移动”到另一个对象中,而不是进行拷贝。这可以避免不必要的资源复制,提高程序效率。
-
完美转发:在模板编程中,能够将函数的参数以左值或右值的形式完美转发给另一个函数。
int b = 1;
//int && c = b; //编译错误! 右值引用不能引用左值
A getTemp() { return A( ); }
A o = getTemp(); // o是左值 getTemp()的返回值是右值(临时变量),被拷贝给o,会引起对象的拷贝
// getTemp()返回的右值本来在表达式语句结束后,其生命也就该终结了,而通过右值引用,该右值又重获新生,其生命期将与右值引用类型变量refO的生命期一样,只要refO还活着,该右值临时变量将会一直存活下去。
A && refO = getTemp(); //getTemp()的返回值是右值(临时变量),可以用右值引用,但不会引起对象的拷贝
//注意:这里refO的类型是右值引用类型(A &&),但是如果从左值和右值的角度区分它,它实际上是个左值(其生命周期取决于refO)。因为可以对它取地址,而且它还有名字,是一个已经命名的左值。因此
A *p = &refO;
//不能将一个右值引用绑定到一个右值引用类型的变量上
//A &&refOther = refO; //编译错误,refO是左值
- 若函数不返回(左值)引用类型,则该函数调用的返回值是无址(右值)的
int &&x=printf(“abcdefg”); //对:printf( )返回无址右值
int &&a=2; //对:引用无址右值
int &&b=a; //错:a是有名有址的,a是左值
int&& f( ) { return 2; }
int &&c=f( ); //对:f返回的是无址引用,是无址的
- 位段成员是无址的。
struct A { int a; /*普通成员:有址*/ int b : 3; /*位段成员:无址*/ }p = { 1,2 };
int &&q=p.a; //错:不能引用有址的变量,p.a是左值
int &&r=p.b; //对:引用无址左值
2.5 枚举、数组
2.5.1 枚举
- 枚举一般被编译为整型,而枚举元素有相应的整型常量值;
- 第一个枚举元素的值默认为0,后一个元素的值默认在前一个基础上加1
enum WEEKDAY {Sun, Mon, Tue, Wed, Thu, Fri, Sat}; //Sun=0, mon=1
WEEKDAY w1=Sun, w2(Mon); //可用限定名WEEKDAY::Sun, - 也可以为枚举元素指定值,哪怕是重复的整数值。
enum E{e=1, s, w= –1, n, p}; //正确, s=2, p= 1和e相等 - 如果使用“enum class”(C++11 引入)或者“enum struct”定义枚举类型,则其元素必须使用类型名限定元素名
enum struct RND{e=2, f=0, g, h}; //正确:e=2,f=0,g=1,h= 2
RND m= RND::h; //必须用限定名RND::h
int n=sizeof(RND::h); //n=4, 枚举元素实现为整数
2.5.2 元素、下标及数组
-
数组元素按行存储, 对于“int a[2][3]={{1,2,3},{4,5,6}};”,先存第1行再存第2行
a: 1, 2, 3, 4, 5, 6 //第1个元素为a[0][0], 第2个为a[0][1],第4个为a[1][0]``` -
若上述a为全局变量,则a在数据段分配内存,1,2…6等初始值存放于该内存。
-
若上述a为静态变量,则a的内存分配及初始化值存放情况同上。
-
若上述a函数内定义的局部非静态变量,则a的内存在栈段分配
-
C++数组并不存放每维的长度信息,因此也没有办法自动实现下标越界判断。每维下标的起始值默认为0。
-
数组名a代表数组的首地址,其代表的类型为int [2][3]或int(*)[3]。
-
一维数组可看作单重指针,反之也成立。例如:
int b[3]; //*(b+1)等价于访问b[1]
int p=&b[0]; //(p+2)等价访问p[2],也即访问b[2] -
字符串常量可看做以’\0’结束存储的字符数组。例如“abc”的存储为
| ‘a’ | ‘b’ | ‘c’ | ‘\0’ | //字符串长度即strlen(“abc”)=3,但需要4个字节存储。
char c[6]=“abc”;//sizeof(c)=6,strlen(c)=3, “abc”可看作字符数组
char d[ ]=“abc”;//sizeof(d)=4,编译自动计算数组的大小, strlen(d)=3
const char*p=“abc”;//sieof(p)=4, p[0]=‘a’,“abc”看作const char指针,注意必须加const -
故可以写:
cout << “abc”[1];//输出b
2.6 运算符及表达式
C++运算符、优先级、结合性见表。优先级高的先计算,相同时按结合性规定的计算顺序计算。可分如下几类:
- 位运算:按位与&、按位或|、按位异或^、左移、右移。左移1位相当于乘于2,右移1位相当于除于2。
- 算数运算:加+、减-、乘*、除/、模%。
- 关系运算:大于、大等于、等于、小于、小等于
- 逻辑运算:逻辑与&&、逻辑或||
| 优先级 | 运算符 | 描述 | 结合性 | 运算类型 |
|---|---|---|---|---|
| 1 | :: |
作用域解析运算符 | 无 | 其他 |
| 2 | ++ -- |
后缀自增、自减 | 从左到右 | 算数运算 |
| 2 | () |
函数调用 | 从左到右 | 其他 |
| 2 | [] |
下标 | 从左到右 | 其他 |
| 2 | . -> |
成员访问 | 从左到右 | 其他 |
| 2 | typeid |
类型信息 | 从左到右 | 其他 |
| 2 | const_cast dynamic_cast reinterpret_cast static_cast |
类型转换 | 从右到左 | 其他 |
| 3 | ++ -- |
前缀自增、自减 | 从右到左 | 算数运算 |
| 3 | + - |
正负号 | 从右到左 | 算数运算 |
| 3 | ! ~ |
逻辑非、按位取反 | 从右到左 | 逻辑运算、位运算 |
| 3 | * & |
指针解引用、取地址 | 从右到左 | 指针运算 |
| 3 | sizeof |
取大小 | 从右到左 | 其他 |
| 3 | new new[] |
动态内存分配 | 从右到左 | 其他 |
| 3 | delete delete[] |
动态内存释放 | 从右到左 | 其他 |
| 3 | typeid |
类型信息 | 从右到左 | 其他 |
| 3 | decltype |
推导类型 | 无 | 其他 |
| 4 | .* ->* |
成员指针运算符 | 从左到右 | 指针运算 |
| 5 | * / % |
乘法、除法、取余 | 从左到右 | 算数运算 |
| 6 | + - |
加法、减法 | 从左到右 | 算数运算 |
| 7 | << >> |
位移 | 从左到右 | 位运算 |
| 8 | < <= > >= |
比较运算符 | 从左到右 | 关系运算 |
| 9 | == != |
等于、不等于 | 从左到右 | 关系运算 |
| 10 | & |
按位与 | 从左到右 | 位运算 |
| 11 | ^ |
按位异或 | 从左到右 | 位运算 |
| 12 | ` | ` | 按位或 | 从左到右 |
| 13 | && |
逻辑与 | 从左到右 | 逻辑运算 |
| 14 | ` | ` | 逻辑或 | |
| 15 | ?: |
条件运算符 | 从右到左 | 三元运算符 |
| 16 | = |
赋值 | 从右到左 | 赋值运算 |
| 16 | += -= *= /= %= <<= >>= &= ^= ` |
=` | 复合赋值 | 从右到左 |
| 16 | throw |
异常抛出 | 从右到左 | 其他 |
| 17 | , |
逗号运算符 | 从左到右 | 其他 |
-
由于C++逻辑值可以自动转换为整数0或1,因此,数学表达式的关系运算在转换为C++表达式容易混淆整数值和逻辑值。假如x=3,则数学表达式 “1<x<2”的结果为假,但若C++计算则1<x<2⇔1<3<2⇔1<2⇔真,
-
数学表达式实际上是两个关系运算的逻辑与,相当于C++的“1<x&&x<2”。
-
赋值表达式也是C++一种表达式。对于int x(2); x=x+3; 赋值语句中的表达式:
x+3是加法运算表达式,其计算结果为传统右值5。
x=5是赋值运算表达式,其计算结果为传统左值x(x的值为5) 。
由于计算结果为传统左值x,故还可对x赋值7,相当于运算:(x=x+3)=7;结果为左值x -
选择运算使用”?:”构成, 例如:y=(x>0)?1:0; 翻译成等价的C++语句如下。
if(x>0) y=1;
else y=0; -
前置运算“++c”、后置运算“c ++”为自增运算;相当于c=c+1,前置运算“—c”、后置运算“c –”为自减运算,相当于c=c-1。前置运算先运算后取值,结果为传统左值;后置运算先取值后运算,结果为传统右值。
第三章 语句、函数及程序设计
3.1 C++的语句
- 语句是用于完成函数功能的基本命令。
- 语句包括空语句、值表达式语句、复合语句、if语句、switch语句、for语句、while语句、do语句、break语句、continue语句、标号语句、goto语句等。
- 空语句:仅由分号“;”构成的语句。
- 值表达式语句:由数值表达式(求值结果为数值)加上分号“;”构成的语句。例如:x=1; y=2;
- 复合语句:复合语句是由 “{ }“括起的若干语句。例如:
- if语句:也称分支语句,根据满足的条件转向不同的分支。两种形式:
- if(x>1) y=3; //单分支:当x>1时,使y=3
- if(x>1) y=3; else y=4; //双分支:当x>1时,使y=3,否则使y=4
上述if语句红色部分可以是任何语句,包括新的if语句:称之为嵌套的if语句。
- switch语句:也称多路分支语句,可提供比if更多的分支。
- 括号中的expression只能是
- 小于等于int的类型包括枚举。
- 进入swtich的“{ }”, 可以定义新的类型和局部变量
- bool, char, short, int等值均可。
- “default”可出现在任何位置。
- 未在case中的值均匹配“default”。
- 若当前case的语句没有break,则继续执行下一个case直到遇到break或结束。
- switch的”( )”及“{ }”中均可定义变量,但必须先初始化再被访问。
3.2 C++的函数
3.2.1 函数
- 函数用于分而治之的软件设计,以将大的程序分解为小的模块或任务。
- 函数说明(声明)不定义函数体,函数定义必须定义函数体。说明可多次,定义仅能实施一次。
- 函数可说明或定义为四种作用域:(1)全局函数(默认);(2)内联即inline函数;(3)外部即extern函数;(4)静态即static函数
- 全局函数可被任何程序文件(.cpp)的程序用,只有全局main函数不可被调用(新标准)。故它是全局作用域的。
- 内联函数可在程序文件内或类内说明或定义,只能被当前程序文件的程序调用。它是局部文件作用域的,可被编译优化(掉)。
- 静态函数可在程序文件内或类内说明或定义。类内的静态函数不是局部文件作用域的,程序文件内的静态函数是局部文件作用域的。
- 函数说明(声明)可以进行多次,但定义只能在某个程序文件(.cpp)进行一次
int d( ) { return 0; } //默认定义全局函数d:有函数体
extern int e(int x); //说明函数e:无函数体。可以先说明再定义,且可以说明多次
extern int e(int x) { return x; } //定义全局函数e:有函数体
inline void f( ) { } //定义程序文件局部作用域函数f:有函数体,可优化,内联。仅当前程序文件可调用
void g( ) { } //定义全局函数g:有函数体,无优化。
static void h( ){ } //定义程序文件局部作用域函数h:有函数体,无优化,静态。仅当前程序文件可调用
void main(void) {
extern int d( ), e(int); //说明要使用外部函数:d, e均来自于全局函数。可以说明多次。
extern void f( ), g( ); //说明要使用外部函数:f来自于局部函数(inline), g来自于全局函数
extern void h( ); //说明要使用外部函数:h来自于局部函数(static)
}
3.2.2 main函数
- 主函数main是程序入口,它接受来自操作系统的参数(命令行参数)。
- main可以返回0给操作系统,表示程序正常执行,返回其它值表示异常。
- main的定义格式为int main(int argc, char*argv[ ]),argc表示参数个数,argv存储若干个参数。
- 函数必须先说明或定义才能调用,如果有标准库函数则可以通过#include说明要使用的库函数的参数。
- 例如在stdio.h中声明了scanf和printf函数,分别返回成功输入的变量个数以及成功打印的字符个数:int printf(const char*, ...);
- 例如在string.h中声明了strlen函数,返回字符串s的长度(不包括字符串借宿标志字符‘\0’):int strlen(const char *s);
- 注意在#include <string.h>之前,必须使用
#define _CRT_SECURE_NO_WARNINGS
3.2.3 函数缺省参数
省略参数...表示可以接受0至任意个任意类型的参数。通常须提供一个参数表示省略了多少个实参。
long sum(int n, ...) {
long s = 0; int* p = &n + 1; //p指向第1个省略参数
for (int k = 0; k < n; k++) s += p[k];
return s;
}
void main()
{
int a = 4; long s = sum(3, a, 2, 3); //执行完后s=9
}
注意:参数n和省略参数连续存放,故可通过&n+1得到第1个省略参数的地址;若省略参数为double类型,则应进行强制类型转换。且必须在x86下运行,x64会优先使用寄存器而不是栈导致无法寻址
double *p=(double *)(&n+1);
C++ 提供了标准的机制来安全、正确地处理可变参数。这是通过使用 stdarg.h 或 cstdarg 中的相关宏来实现的。以下是使用标准宏处理可变参数的正确方式:
#include <cstdarg>
#include <iostream>
long sum(int n, ...) {
long s = 0;
va_list args; // 声明可变参数列表
va_start(args, n); // 初始化列表,args 指向第一个可变参数
for (int k = 0; k < n; k++) {
s += va_arg(args, int); // 逐个读取可变参数,指定类型为 int
}
va_end(args); // 清理可变参数列表
return s;
}
int main() {
int a = 4;
long s = sum(3, a, 2, 3); // 执行后 s = 9
std::cout << s << std::endl;
return 0;
}
3.3 作用域
3.3.1 作用域的种类
- 程序可由若干代码文件(.cpp)构成,整个程序为全局作用域:全局变量和函数属于此作用域。
- 稍小的作用域是代码当前文件作用域:函数外的static变量和函数属此作用域。
- 更小的作用域是函数体:函数局部变量和函数参数属于此作用域。
- 在函数体内又有更小的复合语句块作用域。
- 最小的作用域是数值表达式:常量在此作用域。
- 除全局作用域外,同层不同作用域可以定义同名的常量、变量、函数。但他们为不同的实体。
- 如果变量和常量是对象,则进入面向对象的作用域。
- 同名变量、函数的作用域越小、被访问的优先级越高。
3.3.2 名字的作用域
每个名字(标识符:由程序员命名的名字)都会指向一个实体:变量、函数、类型等。
但同一个名字处于不同的位置,也可能指向不同的实体,这是由名字的作用域(scope)决定的。C++绝大多数作用域用{ }分割。
- 定义于所有花括号之外名字具有全局作用域,在整个程序范围内可见;
- 定义于{ }之内的名字,其作用域始于名字的声明语句,结束于所在的{}的最后一条语句;这样的名字的作用域是块作用域(block scope);
- 作用域可以嵌套。作用域一旦申明了一个名字,它所嵌套的所有作用域都能访问该名字,同时允许在内部嵌套作用域内定义同名名字。
- 作用域越小,访问优先级越高;因此内部嵌套作用域内的名字会隐藏外层作用域里同名名字;
- 函数的形参相当于函数里定义的局部变量,其作用域是函数体;
#include <iostream>
int gi = 1; //i具有全局作用域
void func(){
//具有全局作用域的变量gi到处可以访问,输出0
std::cout << gi << std::endl;
int j = 10; //j的作用域是函数f
{
int j = 100; //嵌套作用域,可以定义同名变量j
//嵌套作用域里的j隐藏了外面作用域里的j,输出100
std::cout << j << std::endl;
}
std::cout << j << std::endl; //这时访问的是外层作用域里的j,输出10
}
3.4 生命期
- 作用域是变量等可使用的空间,生命期是变量等存在的时间。
- 变量的生命期从其被运行到的位置开始,直到其生命结束(如被析构或函数返回等)为止。
- 常量的生命期即其所在表达式。
- 函数参数或自动变量的生命期当退出其作用域时结束。
- 静态变量的生命期从其被运行到的位置开始,直到整个程序结束。
- 全局变量的生命期从其初始化位置开始,直到整个程序结束。
- 通过new产生的对象如果不delete,则永远生存(内存泄漏)。
- d(包括函数参数),否则导致变量的值不确定:因为内存变量的生命已经结束(内存已做他用)。
#include <iostream>
//返回内层作用域的自动变量
int & g() {
int x = 10;
return x;
}
int main()
{
int & r = g(); //外层作用域引用变量r引用了g里面的自动变量
std::cout << r << std::endl; //g返回后,自动变量弹出堆栈,生命周期已经结束
//打印的是不确定的值
}
【例3.24】试分析常量、变量和函数的生命期和作用域。代码文件“A.cpp”:
int x=2; //全局变量:生命期和作用域为整个程序
static int y=3; //模块静态变量:生命期自第一次访问开始至整个程序结束
int f( ) //全局函数f():其作用域为整个程序,生命期从调用时开始
{
int u=4; //函数自动变量:生命期和作用域为当前函数
static int v=5; //函数静态变量:生命期自第一次调用开始至整个程序结束
v++;
return u+v+x+y;
}
static int g( ) { return x; } //静态函数g():其作用域为“A.cpp”文件
第四章 C++的类
4.1 类的声明和定义
类保留字:class、struct或union可用来声明和定义类。
class 类型名;//前向声明
class 类型名{//类的定义
private:
私有成员声明或定义;
protected:
保护成员声明或定义;
public:
公有成员声明或定义;
};
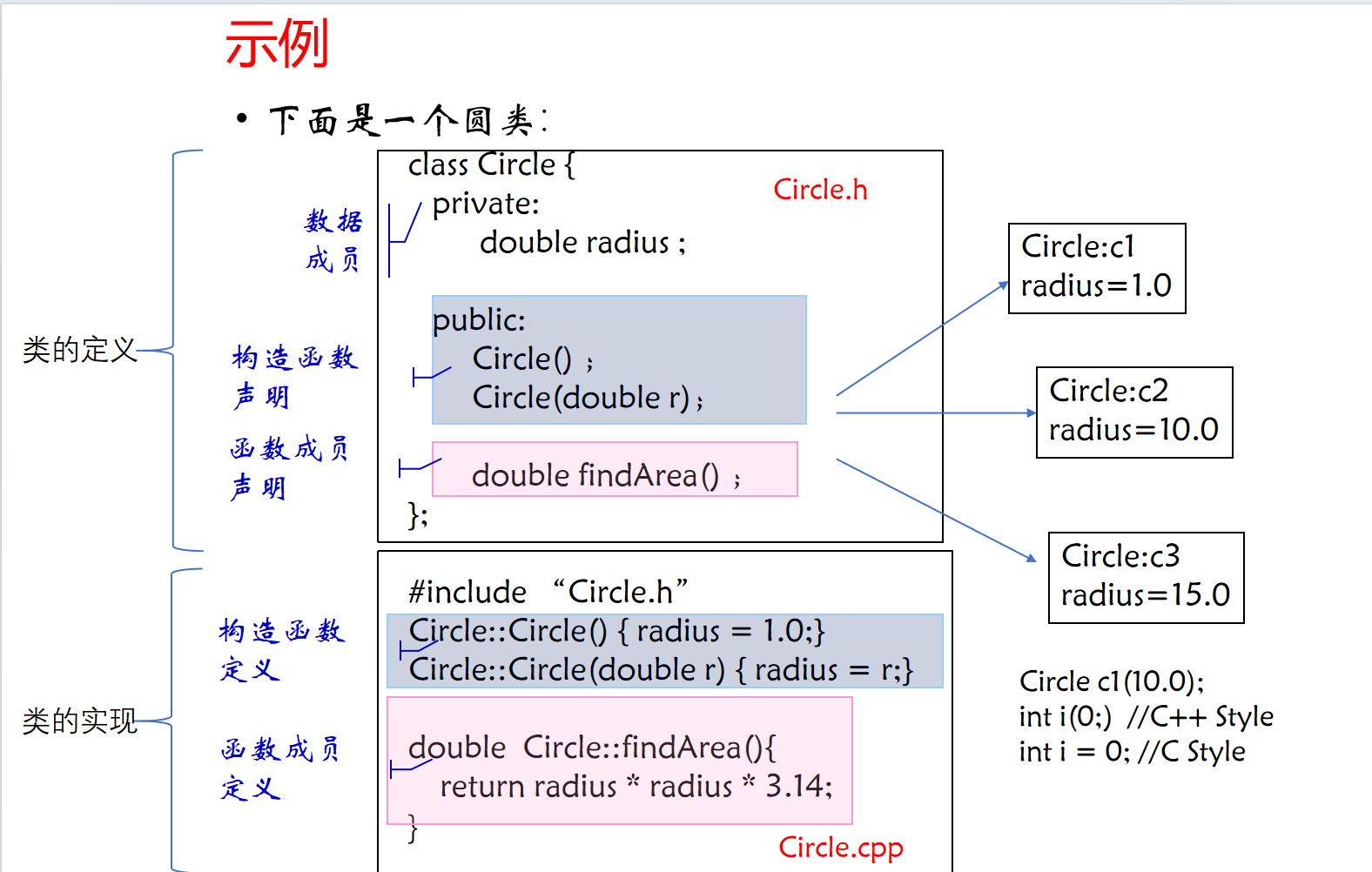
4.1.1 定义类时应注意的问题:
- 使用private、protected和public保留字标识主体中每一区间的访问权限,同一保留字可以多次出现;
- 同一区间内可以有数据成员、函数成员和类型成员,习惯上按类型成员、数据成员和函数成员分开;
- 成员在类定义体中出现的顺序可以任意,函数成员的实现既可以放在类的外面,也可以内嵌在类定义体中(此时会自动成为内联函数);但是数据成员的声明/定义顺序与初始化顺序有关(先声明/定义的先初始化)。
- 若函数成员在类定义体外实现,则在函数返回类型和函数名之间,应使用类名和作用域运算符“::”来指明该函数成员所属的类。
- 类的定义体花括号后要有分号作为定义体结束标志。
- 在类定义体中允许对数据成员定义默认值,若在构造函数的参数列表后面的“:”和函数体的“{”之间对其进行了初始化(在成员初始化列表进行初始化),则默认值无效,否则用默认值初始化;
4.1.2 构造函数和析构函数
- 构造函数和析构函数:是类封装的两个特殊函数成员,都有固定类型的隐含参数this(对类A,this指针为A* const this) 。
- 构造函数:函数名和类名相同的函数成员。可在参数表显式定义参数,通过参数变化实现重载。
- 析构函数:函数名和类名相同且带波浪线的参数表无参函数成员。故无法通过参数变化重载析构函数。
- 定义变量或其生命期开始时自动调用构造函数,生命期结束时自动调用析构函数。
- 同一个对象仅自动构造一次。构造函数是唯一不能被显式(人工,非自动)调用的函数成员
- 构造函数和析构函数都不能定义返回类型。
- 如果类没有自定义的构造函数和析构函数,则C++为类生成默认的构造函数(不用给实参的构造函数)和析构函数。
- 构造函数的参数表可以出现参数,因此可以重载。
- 构造函数用来为对象申请各种资源,并初始化对象的数据成员。构造函数有隐含参数this,可以在参数表定义若干参数,用于初始化数据成员。
- 析构函数是用来毁灭对象的,析构过程是构造过程的逆过程。析构函数释放对象申请的所有资源。
- 析构函数既能被显式调用,也能被隐式(自动)调用。由于只有一个固定类型的this,故不可能重载,只能有一个析构函数。
- 若实例数据成员有指针指向malloc/new的内存,应当防止反复析构(用指针是否为空做标志)。
- 联合也是类,可定义构造、析构以及其它函数成员。
4.1.3 不同对象的构造和析构
构造函数在自动变量 (对象)被实例化或通过new产生对象时被自动调用一次,是唯一不能被显式调用的函数成员。
析构函数在变量 (对象)的生命期结束时被自动调用一次,通过new产生的对象需要用delete手动释放(自动调用析构)。由于析构函数可被显式反复调用,而有些资源是不能反复析构的,例如不能反复关闭文件,因此,必要时要防止对象反复释放资源。
- 全局变量 (对象) :main执行之前由开工函数调用构造函数,main执行之后由收工函数调用析构函数。
- 局部自动对象 (非static变量) :在当前函数内对象实例化时自动调用构造函数, 在当前函数正常返回时自动调用析构函数。
- 局部静态对象 (static变量) :定义时自动调用构造函数, main执行之后由收工函数调用析构函数。
- 常量对象:在当前表达式语句定义时自动调用构造函数,语句结束时自动调用析构函数
/全局对象,mian函数之前被开工函数构造,由收工函数自动析构,全局对象在数据段里
MYSTRING gs(“Global String”);
void f(){
//局部自动变量,函数返回后自动析构,局部对象在堆栈里
MYSTRING x(“Auto local variable”);
//静态局部变量,由收工函数自动析构,静态局部对象在数据段里
static MYSTRING y(“Static local variable”);
//new出来的对象在堆里(Heap)
MYSTRING *p = new MYSTRING(“ABC”);
delete(p); //delete new出来的对象的析构是程序员的责任,delete会自动调用析构函数
}
C++11新标准中出现了智能指针的概念,就是要减轻程序员的必须承担的手动delete动态分配的内存(new出来的东西)的负担,后面会介绍。
析构函数要防止反复释放资源
#include <iostream>
#include <cstring> // 使用 C++ 中的字符串库
#include <string.h>
#include <stdlib.h>
using namespace std;
struct MYSTRING {
char* s;
MYSTRING(const char*);
~MYSTRING();
};
MYSTRING::MYSTRING(const char* t) {
s = (char*)malloc(strlen(t) + 1);
strcpy(s, t);
cout << "Construct: " << s;
}
MYSTRING ::~MYSTRING() {
cout << "Deconstruct:" << s;
free(s);
}
int main(void) {
MYSTRING s1("String 1\n");
s1.~MYSTRING(); //显式析构s1,会free(s)
return 0;
}//自动析构s1,会导致s1的s指针指向内存又释放,会出现运行时错误
//构造s1时,传进去的是字符串字面量“String 1\n”,类型被编译器解释为const char * ,const char * 是不能传给构造函数的参数char * 的
// (课堂上讲过,int * = const int * 是不成立的,换成char类型是一样的)
//因此构造函数参数必须是const char*
程序不同结束形式对对象的影响:
- exit退出:局部自动对象不能自动执行析构函数,故此类对象资源不能被释放。静态和全局对象在exit退出main时自动执行收工函数析构。
- abort退出:所有对象自动调用的析构函数都不能执行。局部和全局对象的资源都不能被释放,即abort退出main后不执行收工函数。
- return返回:隐式调用的析构函数得以执行。局部和全局对象的资源被释放。
int main( ){ …; if (error) return 1; …;}
提倡使用return。如果用abort和exit,则要显式调用析构函数。另外,使用异常处理时,自动调用的析构函数都会执行。
//例4.2本例说明exit和abort的正确使用方法。
#include <process.h>
#include “string.cpp” //不提倡这样include:因为string.cpp内有函数定义
STRING x("global"); //自动调用构造函数初始化x
void main(void){
short error=0;
STRING y("local"); //自动调用构造函数初始化y
switch(error) {
case 0: return; //正常返回时自动析构x、y
case 1: y.~STRING( ); //为防内存泄漏,exit退出前必须显式析构y
exit(1);
default: x.~STRING( ); //为防内存泄漏,abort退出前须显式析构x、y
y.~STRING( );
abort( );
}
}
接受与删除编译自动生成的函数:default接受, delete:删除。
//例4.4使用delete禁止构造函数以及default接受构造函数。
struct A {
int x=0;
A( ) = delete; //删除由编译器产生构造函数A( )
A(int m): x(m) { }
A(const A&a) = default; //接受编译生成的拷贝构造函数A(const A&)
};
void main(void) {
A x(2); //调用程序员自定义的单参构造函数A(int)
A y(x); //调用编译生成的拷贝构造函数A(const A&)
//A u; //错误:u要调用构造函数A( ),但A( )被删除
A v( ); //正确:声明外部无参非成员函数v,且返回类型为A
}//“A v( );”等价于“extern A v( );”
4.2 成员访问权限及其访问
- 封装机制规定了数据成员、函数成员和类型成员的访问权限。包括三类:
private:私有成员,本类函数成员可以访问;派生类函数成员、其他类函数成员和普通函数都不能访问。
protected:保护成员,本类和派生类的函数成员可以访问,其他类函数成员和普通函数都不能访问。
public:公有成员,任何函数均可访问。 - 类的友元不受这些限制,可以访问类的所有成员。可以在private、protected和public等任意位置说明,友元可以像类自己的函数成员一样访问类的所有成员。另外,通过强制类型转换可突破访问权限的限制。
- 构造函数和析构函数可以定义为任何访问权限。不能访问构造函数则无法用其初始化对象。
- 进入class定义的类时,缺省访问权限为private;进入struct和union定义的类时,缺省访问权限为public
【例4.5】为女性定义FEMALE类。
class FEMALE { //缺省访问权限为private
int age; //私有的,自己的成员和友员可访问
public: //访问权限改为public
typedef char* NAME; //公有的,都能访问
protected: //访问权限改为protected
NAME nickname; //自己的和派生类成员、友员可访问
NAME getnickname();
public: //访问权限改为public
NAME name; //公有的,都能访问
};
FEMALE::NAME FEMALE::getnickname( ){//类型成员FEMALE::NAME 是公有的,可以到处访问(使用)
return nickname; //自己的函数成员访问自己的成员
}
void main(void){ //main没有定义为类FEMALE的友员
FEMALE w;
FEMALE::NAME(FEMALE::*f)( ); //实例成员函数指针f
FEMALE::NAME n;
n=w.name; //任何函数都能访问公有name
n=w.nickname; //错误,main不得访问保护成员
n=w.getnickname( ); //错误,main不得调用保护成员
int d=w.age; //错误,main不得访问私有age
f=&FEMALE::getnickname; //错误,不得取保护成员地址
}
4.3 内联、匿名类及位段
- 函数成员的内联说明:
i.在类体内定义的任何函数成员都会自动内联。
ii.如果在类外实现函数,在类内或类外使用inline保留字说明函数成员。 - 内联失败:有分支类语句、定义在使用后,取函数地址,定义(纯)虚函数。
- 内联函数成员的作用域局限于当前代码文件。
- 匿名类函数成员只能在类体内定义(内联)。
- 函数局部类的函数成员只能在类体内定义(内联),某些编译器不支持局部类。
class COMP {
double r, v;
public:
COMP(double rp, double vp) { r = rp; v = vp; } //自动内联
inline double getr(); //inline保留字可以省略, 后面又定义
double getv();
};
inline double COMP::getv() { return v; } //定义内联
void main(void) {
COMP c(3, 4);
double r = c.getr(); //此时getr的函数体未定义, 内联失败
double v = c.getv(); //函数定义在调用之前, 内联成功
}
inline double COMP::getr() { return r; } //定义内联
4.4 new和delete
- 内存管理的区别:
- C:函数malloc、free;C++:运算符new、delete。
- 内存分配:malloc为函数,参数为值表达式,分配后内存初始化为0;new为运算符,操作数为类型表达式,先底层调用malloc,然后调用构造函数;
- 用“new 类型表达式 {}”可使分配的内存清零,若“{}”中有数值可用于初始化。
- 内存释放:free为函数,参数为指针类型值表达式,直接释放内存;delete为运算符,操作数为指针类型值表达式,先调用析构函数,然后底层调用free。
- 如为简单类型(没有构造、析构函数)分配和释放内存,则new和malloc、 delete和free没有区别,可混合使用:比如new分配的内存用free释放。
- 无法用malloc代替new初始化
- 注意delete的形参类型应为const void*,因为它可接受任意指针实参。
- new <类型表达式> //后接()或{ }用于初始化或构造。{}可用于数组元素
- 类型表达式:
int *p=new int; //等价int *p=new int(0); - 数组形式仅第一维下标可为任意表达式,其它维为常量表达式:int (*q)[6][8]=new int[x+20][6][8];
- 为对象数组分配内存时,必须调用默认构造函数,如Circle *p =new Circle[10],如Circle无默认构造 函数如何?编译器报错。因此保证一个类有默认构造函数非常重要
- 注意int *p=new int (10)分配一个 int 变量并初始化为 10
和int *p=new int [10] 的区别
- 类型表达式:
- delete <指针>
- 指针指向非数组的单个实体:delete p; 可能调析构函数。
- delete [ ]<数组指针>
- 指针指向任意维的数组时:delete [ ]q;
- 如为对象数组,对所有对象(元素)调用析构函数,然后释放对象数组占有的内存。
- 若数组元素为简单类型,则可用delete <指针>代替。
【例4.13】定义二维整型动态数组的类。
#include <alloc.h>
class ARRAY{ //class体的缺省访问权限为private
int *a, r, c;
public: //访问权限改为public
ARRAY(int x, int y);
~ARRAY( );
};
ARRAY::ARRAY(int x, int y){
a=new int[(r=x)*(c=y)]; //可用malloc:int为简单类型
}
ARRAY::~ARRAY( ){ //在析构函数里释放指针a指向的内存
if(a){ delete [ ]a; a=0;} //可用free(a), 也可用delete a
}
ARRAY x(3, 5); //开工函数构造,收工函数析构x
void main(void){
ARRAY y(3, 5), *p; //退出main时析构y
p=new ARRAY(5, 7); //不能用malloc,ARRAY有构造函数
delete p; //不能用free,否则未调用析构函数
} //退出main时,y被自动析构
//程序结束时,收工函数析构全局对象x
- new还可以对已经析构的变量重新构造。可以减少对象的说明个数,提高内存的使用效率。(不是所有C++编译器都支持)
STRING x ("Hello!"), *p=&x;
x. ~STRING ( );
new (&x) STRING ("The World");
new (p) STRING ("The World");
- 这种用法可以节省内存或栈的空间。
4.5 隐含参数this
- this指针是一个特殊的指针,它是非静态函数成员(包括构造和析构)隐含的第一个参数,其类型是指向要调用该函数成员的对象的const指针。(A * const this)
- 当通过对象调用函数成员时,对象的地址作为函数的第一个实参首先压栈,通过这种方式将对象地址传递给隐含参数this。
- 构造函数和析构函数的this参数类型固定。例如A::~A()的this参数类型为
A*const this; //析构函数的this指向可写对象,但this本身是只读的 - 注意:可用*this来引用或访问调用该函数成员的普通、const或volatile对象;类的静态函数成员没有隐含的this指针;this指针不允许移动。
class A{
int age;
public:
void setAge( int age){
this->age = age; //this类型:A*const this
}
}
A a;
a.setAge(30);
//函数setAge通过对象a被调用时,setAge函数的第一个参数是
//A*const this指针,指向调用对象a。this->age = a.age = 30
//*this就是对象a
【例4.16】在二叉树中查找节点。
class TREE {
int value;
TREE* left, * right;
public:
TREE(int); //this类型: TREE * const this
~TREE(); //this类型: TREE * const this,析构函数不能重载
const TREE* find(int) const; //这个const是修饰this指针,this类型: const TREE * const this
};
TREE::TREE(int value) { //隐含参数this指向要构造的对象
this->value = value; //等价于TREE::value=value
left = right = 0; //C++提倡空指针NULL用0表示
}
TREE::~TREE() { //this指向要析构的对象
if (left) { delete left; left = 0; }
if (right) { delete right; right = 0; }
}
const TREE* TREE::find(int v) const { //this指向调用对象
if (v == value) return this; //this指向找到的节点
if (v < value) //小于时查左子树,即下次递归进入时新this=left
return left != 0 ? left->find(v) : 0;
return right != 0 ? right->find(v) : 0; //否则查右子树
} //注意find函数返回类型必须是const TREE *
TREE root(5); //收工函数将析构对象root
void main(void) {
if (root.find(4)) cout << "Found\n";
}
//find函数最后加了const有什么区别?在find函数里,*this是不能出现在=左边的
4.6 对象的构造与析构
4.6.1 非静态数据成员初始化
- 类的非静态数据成员可以在如下位置初始化:
- 类体中进行就地初始化(称为就地初始化)(=或{}都可以),但成员初始化列表的效果优于就地初始化。
成员初始化列表初始化 - 可以同时就地初始化和在成员初始化列表里初始化,当二者同时使用时,并不冲突,初始化列表发生在就地初始化之后,即最终的初始化结果以初始化列表为准。
- 在构造函数体内严格来说不叫初始化,叫赋值
- 类体中进行就地初始化(称为就地初始化)(=或{}都可以),但成员初始化列表的效果优于就地初始化。
【例4.17】非静态数据成员初始化
#include <iostream>
#include <climits>
#include <algorithm>
#include <vector>
using namespace std;
class Person {
private:
int id;
public:
Person(int id) { this->id = id; }
};
class A {
public:
int i = 10; //可以用=号初始化
double d{ 3.14 }; //可以用{}初始化
int j = { 0 }; //可以用 = {}来初始化
Person p{ 100 }; //没有默认构造函数的类成员也可以就地初始化而不用出现在成员初始化列表里
//int k(0); //不能用()来初始化
//Person p(100); //不能用()初始化
} a;
//可以同时就地初始化和在成员初始化列表里初始化,当二者同时使用时,即最终的初始化结果以初始化列表为准(即使是引用和const成员)。
class B {
public:
int i = 0; //就地初始化
int& r = i; //引用也可以就地初始化而不用出现在成员初始化列表里
int j;
const double PI = 3.14; //const成员也可以就地初始化而不用出现在成员初始化列表里
public:
B() :i(10), j(100), r(j), PI(6.28) { }// 成员初始化列表初始化,这时
} b;
void testB() {
cout << b.i << " " << b.r << " " << b.PI << endl;
//输出:10 100 6.28 ,说明r绑定到j,const常量PI的值为6.28
}
//为什么不能用()进行类内初始化
//不同类型(指变量类型、类类型、函数类型)的标识符可以同名
int C = 7; //定义整型变量C
struct C { //定义classC
C(int i) {}
};
//但是同类型(指变量类型、类类型、函数类型)的标识符不能同名
//int C = 9; //不能定义二个变量都叫C
//当要使用类型C时,必须加class来修饰,让编译器知道是用class C
class C o { C }; //定义一个C类型的对象o,构造函数的实参是变量C
struct D {
//定义一个C类型的数据成员x,并用变量C作为构造函数实参。若可用()来就地初始化,如下
//class C x(C); //这时编译器很难区分这是不是一个成员函数声明:函数名x,形参和返回为C类型
};
//顺便说明,如果要声明一个函数成员:函数名x,形参类型和返回为类C类型,应该写成
class C x(class C);
class A {
int i;
int j;
public:
A() :j(0), i(0) { //还是先初始化i, 后初始化j。初始化按定义顺序
i = 1; j = 1; //在函数体内不应看做初始化,而是赋值
//最终构造后i=j=1
}
};
成员按照在类体内定义的先后次序初始化,与出现在初始化位置列表的次序无关
-
类可能会定义只读(const)和引用类型的非静态(static)数据成员,在使用它们之前必须初始化;若这二种成员没有类内就地初始化,该类必须定义构造函数,在成员初始化列表初始化这类成员。在构造函数里是赋值,因此这二种成员没法在构造函数里初始化
-
类A还可能定义类B类型的非静态对象成员,若B类型对象成员必须用带参数的构造函数构造,且该成员没有类内就地初始化,则A必须自定义初始化构造函数,在成员初始化列表初始化这类成员(自定义的类A的构造函数,传递实参初始化类B的非静态对象成员:缺省的无参的A( )自动只调用无参的B( ))。
在下面的例子中,必须自己定义构造函数,没有自定义构造函数何来成员初始化列表。构造函数是否带参数取决于程序员的选择。关键是需要一个成员初始化列表
【例4.18】含只读或引用类型成员的类的构造
class WithReferenceAndConstMembers {
public:
int i = 0; //就地初始化
int &r; //引用成员,没有就地初始化
const double PI; //const成员,没有就地初始化
} ws;
class WithReferenceAndConstMembers {
public:
int i = 0; //就地初始化
int &r; //引用成员,没有就地初始化
const double PI; //没有就地初始化
WithReferenceAndConstMembers() :r(i), PI(3.14) {} //这时r和PI必须在成员初始化列表初始化
} ws;
【例4.19】含其他类(有参构造函数)的类的构造
class Person {
private:
int id;
public:
Person(int id){ this->id = id; } // 注意Person没有默认构造函数,实例化对象必须带参数
};
class WithPersonObject {
public:
Person p; //没有就地初始化,如Person p{1};
} wpo;
class WithPersonObject {
public:
Person p;
//这时p必须在成员初始化列表初始化
WithPersonObject() :p(10) {}
} wpo;
-
构造函数的成员初始化列表在参数表的“:”后,{}之前.所有数据成员建议在此初始化,未在成员初始化列表初始化的成员也可类内就地初始化,既未在成员初始化列表初始化,也未类内就地初始化的非只读、非引用、非对象成员的值根据被构造对象的存储位置可取随机值(对象是局部变量,栈段)或0及nullptr值(对象是全局变量或静态变量,数据段)。
-
按定义顺序初始化或构造数据成员(大部分编译支持)。
- 如未定义或生成构造函数,且类的成员都是公有的,则可以用”{ }”的形式初始化(和C的结构初始化一样)。联合仅需初始化第一个成员。
- 对象数组的每个元素都必须初始化,默认采用无参构造函数初始化。
- 单个参数的构造函数能自动转换单个实参值成为对象
- 若类未自定义构造函数,编译器会尝试自动生成构造函数。
- 一旦自定义构造函数,将不能接受编译生成的构造函数,除非用=default接受。
- 用常量对象做实参,总是优先调用参数为&&类型的构造函数;用变量等做实参,总是优先调用参数为&类型的构造函数。
4.6.2 合成的默认构造函数
-
合成的默认构造函数:当没有自定义类的构造函数时,编译器会提供一个默认构造函数,称为合成的默认构造函数。合成的默认构造函数会按如下规则工作:
- 如果为数据成员提供了类内初始值,则按类内初始值进行初始化
- 否则,执行默认初始化
但是有些场合下默认初始化失败,导致合成的默认构造函数工作失败。
-
合成的默认构造函数会工作是否成功,分以下情况
1)如果为数据成员提供了类内初始值,则工作成功;
2)如果没有为数据成员提供类内初始值,则:- A:如果只包含非const、非引用内置类型数据成员,如果类的对象是全局的或局部静态的,则这些成员被默认初始化为0,如果类的对象是局部的,如果程序要访问这些成员,则编译器报错;合成的默认构造函数工作失败;如果对象是new出来的(在堆里),访问这些成员编译器不报错,但值为随机值;
- B:如果包含了const、引用数据成员,一旦实例化对象,编译器会报错;合成的默认构造函数工作失败;
- C: 如果包含了其他class类型成员且这个类型没有默认构造函数,那么编译器无法默认初始化该成员;编译器会报错;合成的默认构造函数工作失败;
【例4.20】 合成的默认构造函数
#include <iostream>
#include <vector>
#include <map>
using namespace std;
//如果非引用,非const的内置数据成员没有进行任何形式的初始化
class A {
public:
int i;
} e; //全局对象,在数据段
void testA() {
static A se; //局部静态对象,在数据段
A o; //局部对象,在堆栈段,只要不访问对象成员,编译器不报错
cout << e.i << endl; //对e.i执行了默认初始化,为0
cout << se.i << endl; //对se.i执行了默认初始化,为0
//cout << o.i << endl; //一旦访问局部对象的未初始化数据成员,编译器就报错:使用了未初始化的局部变量“o”。因为o.i初始化失败
A* p = new A; //p指向堆里new出来的对象
cout << p->i << endl;//编译器不报错,但i的值是一个随机值-842150451
delete p;
}
class B {
public:
int i = 0;
int& ri;
const int c;
}; //只要不实例化对象,编译器不报错
//B ob; //只要实例化对象,编译器立刻报错
//Person自定义构造函数,因此编译器不再提供合成的构造函数
//更糟糕的是Person自定义的构造函数是带参数的,这就意味着Person类无法默认初始化,即该类对象没有默认值
class Person {
public:
int i;
public:
Person(int i) { this->i = i; }
};
class C {
public:
Person p; //包含一个Person类型成员,且这个类没有默认构造函数
};
//C oc; //只要实例化对象,编译器立刻报错,报错信息如下(VS2017)
int main() {
testA();
return 0;
}
- 任何情况下,只要合成的默认构造函数工作失败,编译器会报错。工作失败的原因就是有成员没有初始值,而且也不能默认初始化该成员。因此,我们一定要保证类的所有数据成员或者有初始值,或者能默认初始化。
- 对于const、引用成员,没有默认构造函数的对象成员,只能就地初始化和在成员初始化列表里初始化,不能在构造函数体内被赋值。
- 当没有自定义类的构造函数时,编译器会提供一个合成的默认构造函数。但自定义了构造函数后,能否要求编译器仍然提供合成的默认构造函数呢?可以,使用=default
【例4.21】default提供默认构造函数
class PersonWithoutDefaultConstructor {
public:
int i = 100; //就地初始化
public:
//自定义带参数构造函数,因此没有默认构造函数
PersonWithoutDefaultConstructor(int i) { this->i = i; }
};
//PersonWithoutDefaultConstructor p; //编译报错:没有合适的默认构造函数可用
class PersonWithDefaultConstructor {
public:
int i = 100;//就地初始化
public:
//自定义带参数构造函数
PersonWithDefaultConstructor(int i) { this->i = i; }
//要求编译器提供合成的默认构造函数
PersonWithDefaultConstructor() = default; //=default出现在类内部,这时默认构造函数是内联的
};
PersonWithDefaultConstructor p; //这时p可以执行默认构造了
class PersonWithDefaultConstructor {
public:
int i = 100; //就地初始化
public:
//自定义带参数构造函数
PersonWithDefaultConstructor(int i) { this->i = i; }
PersonWithDefaultConstructor();
};
PersonWithDefaultConstructor::PersonWithDefaultConstructor() = default;
//=default也可以作为实现出现在类外部,这时默认构造函数不是内联的
4.6.3 隐式的类型转换和显式构造函数
- 如果构造函数只接受一个实参时,实际上它定义了转换为此类类型的转换机制,这种构造函数称为转换构造函数。如果想抑制这种隐式转换,必须将转换构造函数声明为explicit。
- explicit只对接受一个实参的构造函数有效,需要多个实参的构造函数不能用于执行隐式转换。
- 只能在类内声明构造函数时使用explicit关键字
class Integer {
public:
int value;
public:
//隐式地提供了从int到Integer的转换功能
Integer(int value) : value(value) {}
};
class Age {
public:
Integer age{ 0 };
public:
//隐式地提供了从Integer到Age的转换功能
Age(Integer i) :age(i) {}
};
void test() {
// 隐式地将int转换成Integer
Integer integer = 25; // 对于转换构造函数(单参数),可以用=初始化;也可以Integer b(35)
Age age = integer; //隐式地将Integer转换成Age
//但编译器只能自动进行一次转换
//Age a = 100; //编译报错:不存在int到Age的转换构造函数。如果成立,就有二次隐式转换:int->Integer->Age
//只能这样
Age a = Integer(100); //先显式地int->Integer,再隐式地Integer->Age
}
//有时想抑制这种隐式转换,这时必须把构造函数声明为explicit
class ExplicitInteger {
public:
int value;
public:
explicit ExplicitInteger(int value) : value(value) {}
};
class ExplicitAge {
public:
Integer age{ 0 };
public:
ExplicitAge(Integer i) :age(i) {}
ExplicitAge() = default;
};
void test_explicit() {
//编译报错:不存在从int到ExplicitInteger的构造函数, 这种用=来初始化的形式不再支持
//ExplicitInteger i = 10;
//编译也报错:标记为explicit的构造函数也不支持={}形式
//ExplicitInteger j = { 10 };
ExplicitInteger k(0); //只能以这种形式
ExplicitInteger l{ 0 }; //或以这种形式
class A {
public:
int i;
int j;
public:
A(int i, int j = 0) {} // 同样是转换构造函数
};
A a = 0; //这样初始化也成立
class A {
public:
int i;
int j;
public:
explicit A(int i, int j = 0) {} // 不是转换构造函数
};
//A a = 0; //这样就不成立
}
【例4.17】包含只读、引用及对象成员的类。
class A{
int a;
public:
A(int x) { a=x;} //重载构造函数,自动内联
A( ){ a=0; } //重载构造函数,自动内联
};
class B{
const int b; //b没有就地初始化
int c, &d, e, f; //b,d,g,h都没有就地初始化,故只能在构造函数体前初始化
A g, h; //数据成员按定义顺序b, c, d, e, f, g, h初始化
public: //类B构造函数体前未出现h,故h用A( )初始化
B(int y): d(c), c(y), g(y) , b(y) , e(y){//自动内联
c+=y; f=y;
}//f被赋值为y
};
void main(void){
int x(5); //int x=5等价于int x(5)
A a(x), y=5; //A y=5等价于A y(5),请和上一行比较
A *p=new A[3]{ 1, A(2)}; //初始化的元素为A(1), A(2), A(0)
B b(7), z=(7,8); //B z=(7,8)等价于B z(8),等号右边必单值
delete [ ]p; //防止内存泄漏:new产生的所有对象必须用delete
} //故(7,8)为C的扩号表达式,(7,8)=8
4.6.4 拷贝构造函数
如果class A的构造函数的第一个参数是自身类型引用(const A &或A &), 且其它参数都有默认值(或没有其它参数),则此构造函数是拷贝构造函数。
class ACopyable{ public: ACopyable() = default; ACopyable(const ACopyable &o); //拷贝构造函数 };
如果没有为类定义拷贝构造函数,编译器会为我们定义一个合成的默认拷贝构造函数,编译器提供的合成的默认拷贝构造函数原型是ACopyable(const ACopyable &o);
用一个已经构造好对象去构造另外一个对象时会调用拷贝构造函数
class A{
public:
A( ) = default;
};
const A o1;
A o2(o1);
//编译通过,说明A o2(o1)调用的合成的默认拷贝构造函数A(const A & )。因为:若合成的默认拷贝构造函数是A(A &),实参o1是无法传给A &形参的,因A &是无法引用const A的
class A{
public:
A( ) = default;
A(A &o) { cout << "A copied" << endl;} //自己定义的拷贝构造函数
};
const A o1;
A o2(o1); // 编译报错,A &o = o1;错误。因为自定义了拷贝构造函数,编译器不再提供合成的默认构造函数
什么时候会调用拷贝构造函数?
1.用一个已经存在的对象去构造另外一个对象,包括如下形式:
A o1; A o2(o1); A o3 = o1; A o4{o1}; A o5 = {o1};
2.拷贝构造函数更多的用在函数传递值参和返回值参时,包括:
i. 把对象作为实参传递给非引用形参
ii. 返回类型为非引用类型的函数返回一个对象
为什么传入const引用?
const引用可以接受const对象,临时对象,适用面更广
为什么是传引用而不是值
如果拷贝构造函数按值传递参数(即传递对象的副本),那么在调用拷贝构造函数时,C++ 需要对传递的对象参数进行复制,这会再次调用拷贝构造函数,导致递归调用,最终导致无限递归,并引发栈溢出。
(1)对象构造的编译器优化
例1:
class ACopyable{
public:
ACopyable() = default;
ACopyable(const ACopyable &o){//拷贝构造函数
cout << "ACopyable is copied" << endl;
}
};
ACopyable FuncReturnRvalue(){ return ACopyable(); } //函数返回非引用类型
void FuncAcceptValue(ACopyable o){ } //函数接受值参
void FuncAcceptReference(const ACopyable &o){ } //函数接受引用
int main(){
cout << "pass by value: " << endl;
FuncAcceptValue(FuncReturnRvalue()); // 应该调用两次拷贝构造函数
cout << "pass by reference: " << endl;
FuncAcceptReference(FuncReturnRvalue()); //应该只调用一次拷贝构造函数
return 0;
}
c++11禁用RVO优化输出:
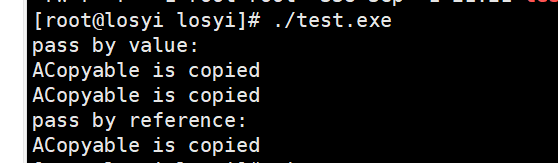
Visual studio(c++17)输出:
pass by value:
pass by reference:
RVO(Return Value Optimization) 是 C++ 编译器的一种优化技术,它优化了通过返回值构造对象的场景,减少了不必要的临时对象创建和拷贝操作。RVO 主要是在函数返回对象时进行优化,通过省略临时对象的构造和拷贝,直接将返回的对象构造在调用者期望的内存位置上,从而提高性能。
关闭方法: g++ -std=c++11 -O0 -fno-elide-constructors main main.cpp
例2:
class A{
public:
A() { cout<<"Construct"<<endl; }
A(const A &a) { cout<<"Copy Construct"<<endl; }
};
A getA() { return A(); }
int main(){
A a = getA();
return 0;
}
/*
A a = getA();会调用调用三次构造
1)A(); 产生临时对象,记为tmp1
2) 函数return,调用拷贝构造由tmp1构造另外一个tmp2返回
3)用tmp2拷贝构造a
但是如果关闭优化,则只会调用一次构造函数,编译器会将A a = getA() 优化为:A a;
*/
理论输出
Construct
Copy Construct
Copy Construct
实际上经过优化只输出了Construct
(2)深拷贝与浅拷贝
- 编译器提供的合成的默认拷贝构造函数其行为是:按成员依次拷贝。如果用类型A的对象o1拷贝构造对象o2,则依次将对象o1的每个非静态数据成员拷贝给对象o2的对应的非静态数据成员,其中
- 如果数据成员是内置类型、指针、引用,则直接拷贝
- 如果数据成员是类类型,执行该数据成员类型的拷贝构造函数
- 如果是数组(不是指针指向的),则逐元素拷贝;如果元素类型是类类型,逐元素拷贝时会调用元素类型的拷贝构造函数
- 按成员依次拷贝也被称为浅拷贝。当函数的参数为值参(非引用)时,实参传递给值参(非引用)会调用拷贝构造函数,如果拷贝构造函数的实现为浅拷贝(如编译器提供的合成的默认拷贝构造函数),就存在如下问题:
- 若实参对象包含指针类型(或引用)的实例数据成员,则只复制指针值而未复制指针所指的单元内容,实参和形参两变量的指针成员指向同一块内存。
- 当被调函数返回,形参对象就要析构,释放其指针成员所指的存储单元。若释放的内存被操作系统分配给其他程序,返回后若实参继续访问该存储单元,就会造成当前程序非法访问其他程序页面,导致操作系统报告一般性保护错误。
- 若释放的内存分配给当前程序,则变量之间共享内存将产生副作用。
- 深拷贝:在传递参数时先为形参对象的指针成员分配新的存储单元,而后将实参对象的指针成员所指向的单元内容复制到新分配的存储单元中。必须进行深拷贝才能避免出现内存保护错误或副作用
为了在传递参数时能进行深拷贝,必须自定义参数类型为类的引用的拷贝构造函数,即定义A (A &)、A (const A&) 等形式的构造函数。建议使用A (const A&) 。
拷贝构造函数参数必须为引用(为什么)。
struct A {
int *p;
int size;
A (int s):size(s), p(new int[size]){ }
A( ):size(0),p(0){ }
A (const A &r) ; //A (const A&r) 自定义拷贝构造函数
~A( ) { if(p) {delete p; p=0;}}
};
A::A (const A &r) { //实现时不是浅拷贝,而是深拷贝
p=new int[size=r.size]; //构造时p指向新分配内存
for (int i =0; i<size; i++) p[i]=r.p[i] ;
}
void f(A a) {}; //函数参数为值参
A o1(20);
f(o1); //调用自定义的拷贝构造函数,不用浅拷贝使o.p=a.p,
//而是o.p!=a.p 但是二块内存的内容一样
(3)赋值运算符重载函数
与拷贝构造函数一样,如果类未定义自己的赋值运算符函数,编译器会提供合成的赋值运算符函数。
编译器提供的合成的赋值运算符函数是浅拷贝赋值。因此和拷贝构造函数一样,在必要的时候需要自己定义赋值运算符函数,且实现为深拷贝赋值。
class A{
public:
//赋值运算符返回非const &,参数是const 引用
A & operator=(const A &){ …}
}
class MyString {
private:
char *s;
public:
MyString(const char *t = “”){ …}
~MyString() { … }
MyString & operator=(const MyString &rhs); //重载=
};
MyString& MyString::operator=(const MyString &rhs) { //实现为深拷贝赋值
char *t = static_cast<char *>(malloc(rhs.len));
strcpy(t,rhs.s);
//把右边对象的内容复制到新的内存后,再释放this->s,这样做最安全
if(this->s) { delete[] this->s; } //这里为什么需要判断?
this->s = t;
return *this; //最后必须返回*this
};
MyString s1(“s1”),s2(“s2”); s1 = s2;
第五章 成员及成员指针
5.1 实例成员指针
成员指针:指向类的成员(普通和静态成员)的指针,分为实例成员指针和静态成员指针****。变量、数据成员、函数参数和返回类型都可定义为成员指针类型, 即普通指针能用的地方成员指针都能用
实例成员指针声明:
int A::*p;//A类的成员指针,指向A类的int类型实例数据成员
实例成员指针使用:
struct A{
int m, n;
}a={1, 2}, b={3, 4};
p = &A::m; //实例成员指针p指向A类的实例数据成员m
int x = a.*p //x = a.m; 利用实例成员指针访问成员 对象名.*指针名或对象指针->*指针名
- 运算符.和->均为双目运算符,优先级均为第14级,结合性自左向右
- .*的左操作数为类的实例(对象),右操作数为指向实例成员的指针
- ->*的左操作数为对象指针,右操作数为指向该对象实例成员的指针。
- 实例成员指针是指向实例成员的指针,可分为实例数据成员指针和实例函数成员指针。
- 实例成员指针必须直接或间接同.或->左边的实例(对象)结合,以便访问该对象的实例数据成员或函数成员。
- 构造函数不能被显式调用,故不能有指向构造函数的实例成员指针。
声明语法
数据类型 类名::*指针名 = &类名::实例成员名 - 实例数据成员指针是数据成员相对于对象首地址的偏移,不是真正的代表地址的指针。
- 实例数据成员指针不能移动:
i. 数据成员的大小及类型不一定相同,移动后指向的内存可能是某个成员的一部分,或者跨越两个(或以上)成员的内存;
ii. 即使移动前后指向的成员的类型正好相同,这两个成员的访问权限也有可能不同,移动后可能出现越权访问问题。 - 实例成员指针不能转换类型:
否则便可以通过类型转换,间接实现实例成员指针移动
【例5.1】:
struct A{ //实例数据成员指针是偏移量
int m, n;
}a={1, 2}, b={3, 4}; //假设int类型2个字节
void main (void) {//以下p=0表示偏移, 实现时实际<>0
int x;
int A::*p=&A::m; //p是A的实例数据成员指针,指向整型成员m
//设p=0:m相对结构体首址的偏移。编译后,偏移实际<>0
x=a.*p; //x=* (a的地址+p) =* (2000+0) =1 = m
//a.*p指向相对对象a首地址偏移为p的成员,即m
x=b.*p; //x=* (b的地址+p) =* (2004+0) =3
p=&A::n; //p=2:n相对结构体首址偏移, 实际<>2
x=a.*p; //x=* (a的地址+p) =* (2000+2) =2
x=b.*p; //x=* (b的地址+p) =* (2004+2) =4
}
【例5.2】本例说明实例成员指针不能移动。
#include <iostream.h>
struct A {
int i; //公有的成员i
private:
long j;
public:
int f() { cout << "F\n"; return 1; }
private:
void g() { cout << "Function g\n"; }
}a;
void main(void) {
int A::* pi = &A::i; //实例数据成员指针pi指向public成员A::i
int (A:: * pf)() = &A::f; //实例函数成员指针pf指向函数成员A::f
long x = a.*pi; //等价于x=a.*(&A::i)=a.A::i=a.i
x = (a.*pf)(); //.*的优先级低,故用(a.*pf)
pi++; //错误, pi不能移动,否则指向私有成员j
pf += 1; //错误, pf不能移动
x = (long)pi; //错误,pi不能转换为长整型
x = x + sizeof(int) //间接移动指针
pi = (int A::*)x; //错误,x不能转换为成员指针
}
5.2 const、volatile和mutable
- const只读,volatile易变,mutable机动:
- const和volatile可以定义变量、类的数据成员、函数成员及普通函数的参数和返回类型。
- mutable只能用来定义类的数据成员。
- 含const数据成员的类必须定义构造函数(如果没有类内就地初始),且数据成员必须在构造函数参数表之后,函数体之前初始化。
- 含volatile、mutable数据成员的类则不一定需要定义构造函数。
【例5. 3】定义导师类,允许改名但不允许改性别。
#include <string.h>
#include <iostream>
class TUTOR
{
char name[20];
const char sex; // 性别为只读成员
int salary;
public:
TUTOR(const char *name, const TUTOR *t);
TUTOR(const char *name, char gender, int salary);
const char *getname() { return name; }
char *setname(const char *name);
};
TUTOR::TUTOR(const char *n, const TUTOR *t) : sex(t->sex)
{
strcpy(name, n);
salary = t->salary;
} // 只读成员sex必须在构造函数体之前初始化
TUTOR::TUTOR(const char *n, char g, int s) : sex(g), salary(s)
{
strcpy(name, n);
} // 非只读成员sarlary可在函数体前初始化,也可在构造函数体内再次赋值
char *TUTOR::setname(const char *n)
{
return strcpy(name, n); // 注意:strcpy的返回值为name
}
void main(void)
{
TUTOR wang("wang", 'F', 2000);
TUTOR yang("yang", &wang);
*wang.getname() ='w'; // 错误:不能改wang.getname( )返回的指针指向的字符(const char *)
*yang.setname("Zang") ='Y'; // 可改wang.setname( )返回的指针指向的字符(char *)
}
- 普通函数成员参数表后出现const或volatile,修饰隐含参数this指向的对象。出现const表示this指向的对象(其非静态数据成员)不能被函数修改,但可以修改this指向对象的非只读类型的静态数据成员。
- 构造或析构函数的this不能被说明为const或volatile的(即要构造或析构的对象应该能被修改,且状态要稳定不易变)。
- 对隐含参数的修饰还会会影响函数成员的重载:
- 普通对象应调用参数表后不带const和volatile的函数成员;
- const和volatile对象应分别调用参数表后出现const和volatile的函数成员,否则编译程序会对函数调用发出警告。
【例5.4】参数表后出现const和volatile。
#include <iostream>
using namespace std;
class A
{
int a;
const int b; // b为const成员或y引用时,只能在构造函数后的成员初始化列表初始化
volatile int c=1;
public:
int f()
{
a++; // this类型为A * const this, 指向的
return a; // 对象可修改(故其普通成员a可修改),只读成员b不可改
}
int f() const
{ // a++; //this类型为const A * const this,指向的对象
return a; // 不可改,其普通成员a不可改。同上, b不可改
}
int f() volatile
{ // this类型为volatile A * const this,指向的对象可修
a++; // 改,其普通成员a可修改。同上,只读成员b不可改
return a;
}
int f() const volatile
{ // this类型为const volatile A* const this,
// a++; //不能修改普通成员a。同上,只读成员b不可改
return a;
}
A(int x) :b(x) { a = x; }
} x(3); // 等价于A x(3), x可修改,
const A y(6); // y、z不可改
const volatile A z(8); // x、y、z由开工函数构造、收工函数析构
void main(void)
{
x.f(); // 普通对象x调用int f( ): 指向的对象可修改
y.f(); // 只读对象y调用int f( )const:指向的对象不可修改
z.f(); // 只读易变对象z调用int f( )const volatile
}
**const、volatile和mutable **
#include <string.h>
class TUTOR{
char name[20];
const char gender; //性别为只读成员
int wage;
mutable int querytimes;
public:
TUTOR (const char *n, char g, int w) : gender (g), wage (w) { strcpy (name, n); }
//函数体不能修改当前对象,this指针类型变成const TUTOR * const this;
const char *getname ( ) const { return name; }
char *setname (const char *n) volatile // this指针类型变成volatile TUTOR * const this;
//由于this指针被volatile修饰,导致name类型为 voliatile char [20]
{return strcpy ( (char *) name, n) ; } //必须强制将volatile char * 转换为char *
void query (char* &n, char &s, int &w) const
//函数体不能修改当前对象, 但修改机动成员。&name[0]类型为const char *
{ n= (char*) &name[0]; s=gender; w=wage;
wage ++; //错误,不能修改const对象的成员
querytimes++; //ok,querytimes是mutable成员
}
};
- 函数成员参数表后出现volatile,常表示调用该函数成员的对象是挥发对象,这通常意味着存在并发执行的进程。
- 函数成员参数表后出现const时,不能修改调用对象的非静态数据成员,但如果该数据成员的存储类为mutable,则该数据成员就可以被修改。
- mutable说明数据成员为机动数据成员,该成员不能用const、volatile或static修饰。
- 有址(左值)引用变量(&)只是被引用对象的别名,被引用对象自己负责构造和析构,该引用变量(逻辑上不分配内存的实体)不必构造和析构。
- 无址(右值)引用变量(&&)常用来引用常量对象或者生命周期即将结束的对象,该引用变量(逻辑上不分配缓存的实体)不必构造和析构。无址引用变量为左值,但若同时用const定义则不能出现在=左边。
- 如果A类型的有址(左值)引用变量r引用了new生成的(一定有址的)对象x,则应使用delete &r析构x,同时释放其所占内存。
- 引用变量必须在定义的同时初始化,函数的引用参数则在调用函数时初始化。非const左值引用变量和参数必须用同类型的左值表达式初始化。
左值引用对象
class A{
int i;
public:
A(int i){ A::i= i; cout<<"A:i = "<<i<<"\n";}
~A(){if(i) cout<<"~A:i = "<<i<<"\n";i=0;}
};
void g(A &a){cout<<"g is running\n";}
void main(int argc, char* argv[]){
A a(1),b(2);
A &p = a; //p引用a,没有构造新对象
A &q = *new A(3);
A &r = p; //r引用a,没有构造新对象
cout<<"call g(b)\n";
g(b); // 实参传递给形参,A &a = b; 没有构造新对象
cout<<"main return\n";
delete &q; //必须delete
}
- mutable仅用于说明实例数据成员为机动成员,不能用于静态数据成员的。
- 所谓机动是指在整个对象为只读状态时,其每个成员理论上都是不可写的,但若某个成员是mutable成员,则该成员在此状态是可写的。
- 例如,产品对象的信息在查询时应处于只读状态,但是其成员“查询次数”应在此状态可写,故可以定义为“机动”成员。
- 保留字mutable还可用于定义Lambda表达式的参数列表是否允许在Lambda的表达式内修改捕获的外部的参数列表的值。
class PRODUCT {
char* name; //产品名称
int price; //产品价格
int quantity; //产品数量
mutable int count; //产品查询次数
public:
PRODUCT(const char* n, int m, int p);
int buy(int money);
void get(int& p, int& q)const;
~PRODUCT(void);
};
void PRODUCT::get(int &p, int &q)const{//const PRODUCT *const this
p=price; q=quantity; //当前对象为const对象,故其成员不能被修改
count++; //但count为mutable成员,可以修改
}
5.3 静态数据成员
- 静态成员用static声明, 包括静态数据成员和静态函数成员,static声明只能出现在类内。
- 非const、非inline静态数据成员在类体内声明、类体外定义并初始化。
- 类的静态数据成员在类还没有实例化对象前就已存在,相当于Java的类变量,用于描述类的总体信息,如对象总数、连接所有对象的链表表头等。访问权限同普通成员。
- 逻辑上,所有对象共享静态数据成员内存,任何对象修改静态数据成员的值,都会同时影响其他对象关于该成员的值。物理上,静态数据成员相当于独立分配内存的变量,不属于任何对象内存的一部分。
- 静态数据成员相当于有类名限定、带访问权限的全局变量
静态数据成员的初始化-非const、非inline成员
class A {
public:
//非常量静态成员必须在类里声明,类外定义和初始化 ,静态成员的static声明只能出现在类里
static int i = 0; //错误
};
// error C2864: A::i: 带有类内初始化表达式的静态 数据成员 必须具有不可变的常量整型类型,或必须被指定为“内联”
class A {
public:
//非常量静态成员必须在类里声明,类外定义和初始化 ,静态成员的static声明只能出现在类里
static int i; //类里声明
};
int A::i = 10; //类体外初始化,注意不能加static
静态数据成员的初始化-const成员
class B {
public:
//const静态整型常量可以在类里初始化
const static int i = 0; //正确
const static int j{ 1 }; //正确
//错误。error C2864: B::d: 带有类内初始化表达式的静态数据成员必须具有不可变的常量整型类型,或必须被指定为“内联”
//const static double d = 3.14 ;
// constexpr类型的字面值类型可以在类体里初始化
static constexpr double dd = 3.14; //static constexpr double
};
静态数据成员的初始化-inline成员(17 标准)
class C {
public:
//内联的静态数据成员可以在类里初始化
inline static int i = 0;
inline static double d = { 3.14 };
//inline和const可以一起使用
inline static const int j = 1;
};
【例5.9】函数局部类不能定义静态数据成员
int x=3;
union S { //定义全局类T
const static int b=0; //全局类中可用const定义同时初始化静态整型成员,必须用常量
inline static int c = x; //全局类可用inline定义同时初始化静态成员,可用任意表达式
inline const static int d = x; //可用任意表达式
};
void f(void){
class T{ //定义函数中的局部类T
int c;
//static int d; //错误:函数中的局部类不能定义静态数据成员
};
T a; //局部自动变量a
static T s; //局部静态变量s
}
void main( ){ f( ); f( ); } //第一个函数调用f( )返回后a.d⇔s.d⇔T::d产生静态成员声明周期矛盾
5.4 静态函数成员
- 静态函数成员通常在类里以static说明或定义,它没有this参数。
- 有this的构造和析构函数、虚函数及纯虚函数都不能定义为静态函数成员。
- 静态函数成员一般用来访问类的总体信息,例如对象总个数。
- 静态函数成员可以重载、内联、定义默认值参数。
- 静态函数成员同实例成员的继承、访问规则没有区别。
- 静态函数成员的参数表后不能出现const、volatile、const volatile等修饰符。
- 静态函数成员的返回类型可以同时使用inline、const、volatile等修饰。
class A{
double i;
const static int j=3;
public:
static A& inc(A &); //说明静态函数成员
static A& dec(A &a){ //在内体内定义静态函数成员:自动inline
a.i=a.i-A::j;
return a;
}
};
A& A::inc(A&a){ //不能定义static A& A::inc(A&a)
a.i+=A::j; //静态函数可访问静态数据成员,但不能访问实例成员this->i,但可以访问a.i(另外一个已构造好的对象)
return a;
}
5.5 静态成员指针
- 静态成员指针是指向类的静态成员的指针,包括静态数据成员指针和静态函数成员指针。
- 静态数据成员的存储单元为该类所有的对象共享,因此,通过该指针修改成员的值时会影响到所有对象该成员的值。
- 静态数据成员和静态函数成员除了具有访问权限外,同普通变量/普通函数没有本质区别;静态成员指针则和普通指针没有任何区别。
- 变量、数据成员、普通函数和函数成员的参数和返回值都可以定义成静态成员指针。
【例5.15】定义群众类,使每个群众共享人数信息。
#include <iostream>
using namespace std;
class CROWD {
int age;
char name[20];
public:
static int number;
static int getn() { return number; }
CROWD(char* n, int a) {
strcpy(name, n);
age = a; number++;
}
~CROWD() { number – –; }
};
int CROWD::number = 0;
void main(void) {
int* d = &CROWD::number; //普通指针指向静态数据成员
int (*f)() = &CROWD::getn; //普通函数指针指向静态函数成员
//类CROWD无对象时访问静态成员
cout << “\nCrowd number = ” << *d; //输出0
CROWD zan("zan", 20);
//d=&zan.number; 等价于如下
//d=&CROWD::number;
cout << “\nCrowd number = ” << *d; //输出1
CROWD tan("tan", 21);
cout << “\nCrowd number = ” << (*f)(); //输出2
}
静态函数成员指针与普通函数成员指针的区别
-
对于一个全局函数,我们可以声明一个指向该函数的指针(普通函数指针),如
int Sum( int x, int y) { return x + y;}
int (pf)(int, int) = & Sum; //&可省略
int s = pf(2,3); //通过普通函数指针调用函数,或int s = (pf)(2,3) -
对于类的静态函数,静态函数成员指针就是普通函数指针,如:
class A { public: static int sum(int x, int y);};
int A::sum(int x, int y) { return x + y;}
int (pf_A)(int,int) = &A::sum //普通函数指针, &可省略
int s = pf_A(2,3); //或 (pf_A)(2,3); -
但指向类的普通函数成员的指针该怎么声明呢?如果用普通函数指针来声明会怎样?
class A { public: int sum(int x, int y); };
int A::sum(int x, int y) { return x + y;}
int (*pf_A)(int,int) = &A::sum //这样可以吗?错误 -
因为类的普通函数成员除了函数返回类型及参数列表这两个重要特性外,还有第三个重要特性:所属的类类型。类的普通成员函数必通过一个对象来调用(this指针就是指向这个对象)。
-
而普通函数指针无法匹配类的普通函数成员第三个特征:类类型
-
所以类的普通函数成员必须用成员指针来指向。
int (A::*pf_A)(int,int) = &A::sum; -
静态成员指针与普通成员指针有很大区别。静态成员指针存放成员地址,普通成员指针存放成员偏移;静态成员指针可以移动,普通成员指针不能移动;静态成员指针可以强制转换类型,普通成员指针不能强制转换类型。
第六章 继承与构造
6.1 单继承类
- 继承是C++类型演化的重要机制,在保留原有类的属性和行为的基础上,派生出的新类可以有某种程度的变异。
- 通过继承,新类自动具有了原有类的属性和行为,因而只需定义原有类型没有的新的数据成员和函数成员。实现了软件重用,使得类之间具备了层次性。
- 派生类与基类:接受成员的新类称为派生类,提供成员的原有类型称为基类。
- C++既支持单继承又支持多继承。单继承只能获取一个基类的属性和行为。多继承可获取多个基类的属性和行为。
- 单继承是只有一个基类的继承方式。
单继承的定义格式:
class <派生类名>:<继承方式><基类名>
{
<派生类新定义成员>
<派生类重定义基类同名的数据和函数成员>
<派生类声明修改基类成员访问权限>
};
<继承方式>指明派生类采用什么继承方式从基类获得成员,分为三种:private表示私有继承基类;protected表示保护继承基类;public表示公有继承基类。
注意区别继承方式(派生控制)和访问权限。派生控制和类的成员访问控制符的区别:派生控制作用于基类成员,类的成员访问控制符作用于当前类自定义的成员。
#include <iostream>
#include <graphics.h>
using namespace std;
class LOCATION { //定义定位坐标类
int x, y;
public:
int getx(); int gety(); //gety( )获得当前坐标y
void moveto(int x, int y); //定义移动坐标函数成员
LOCATION(int x, int y);
~LOCATION();
};
void LOCATION::moveto(int x, int y) {
LOCATION::x = x;
LOCATION::y = y;
}
int LOCATION::getx() { return x; }
int LOCATION::gety() { return y; }
LOCATION::LOCATION(int x, int y) {
LOCATION::x = x; LOCATION::y = y;
}
LOCATION::~LOCATION() { }
class POINT :public LOCATION {
//定义点类,从LOCATION类继承,继承方式为public
int visible; //新增可见属性
public:
int isvisible() { return visible; } //新增函数成员
void show(), hide();
void moveto(int x, int y); //重新定义与基类同名函数
POINT(int x, int y) :LOCATION(x, y) { visible = 0; } //在构造派生类对象前先构造基类对象
~POINT() { hide(); }
};
void POINT::show() {
visible = 1;
putpixel(getx(), gety());
}
void POINT::hide() {
visible = 0;
putpixel(getx(), gety());
}
void POINT::moveto(int x, int y) {
int v = isvisible();
if (v) hide();
LOCATION::moveto(x, y); //不能去掉LOCATION::,会自递归
if (v) show();
}
void main(void) {
POINT p(3, 6);
p.LOCATION::moveto(7, 8); //调用基类moveto函数
p.moveto(9, 18); //调用派生类moveto函数
}
- 多继承的派生类有多于一个的基类,派生类将是所有基类行为的组合。
- 派生类与基类:接受成员的新类称为派生类,如例中的Point类;提供成员的类称为基类,如例中的Location类。
- 基类是对派生类的抽象,提取了派生类的公共特征;而派生类是基类的具体化,通过增加属性或行为变为更有用的类型。
- 派生类可以看作基类定义的延续,先定义一个抽象程度较高的基类,该基类中有些操作并未实现(称为抽象方法,相应的基类为抽象类);然后定义更为具体的派生类,实现抽象基类中未实现的操作。
- C++通过多种控制派生的方法获得新的派生类,可在定义派生类时:
- 添加新的数据成员和函数成员;
- 改变继承来的基类成员的访问权限;
- 重新定义同名的数据和函数成员(特别是实例函数成员,称为Override)。
- 关于class、struct、union说明:
- 用class声明的类的继承方式缺省为private,因此,声明class POINT: private LOCATION等价于声明class POINT: LOCATION。
- 派生类也可以用struct声明,不同之处在于:用struct声明的继承方式和访问权限缺省为public。
- 用union声明的类既不能作派生类的基类,也不能作任何基类的派生类。
- 当基类成员被继承到派生类时,该成员在派生类中的访问权限由继承方式决定。必须慎重的选择继承方式,它是面向对象程序设计的一个非常重要的环节
6.2 继承方式
- 派生类可以有三种继承方式:公有继承public、保护继承protected、私有继承private。基类私有成员对派生类函数是不可见的。
- 公有继承:基类的公有成员和保护成员派生到派生类时,都保持原有的权限;
- 保护继承:基类的公有成员和保护成员派生后都成为派生类的保护成员;
- 私有继承:基类的公有成员和保护成员派生后都作为派生类的私有成员。
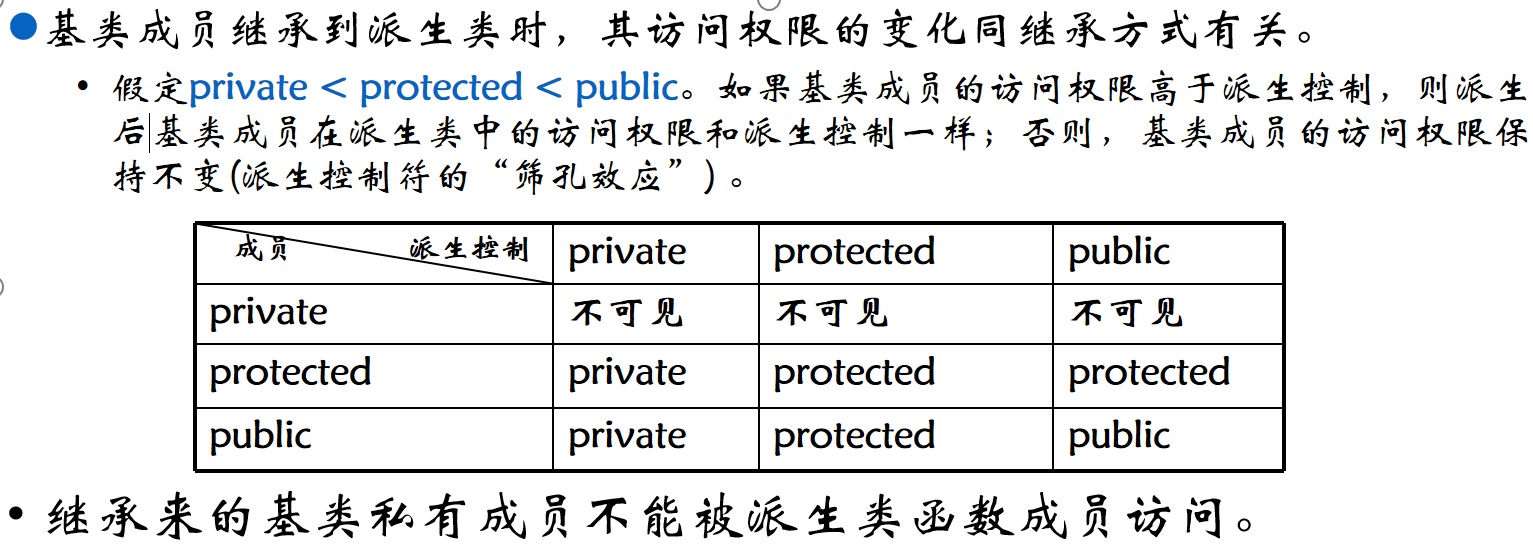
2.基类的私有成员同样也被继承到派生类中,构成派生类的一部分(sizeof会计算基类私有实例数据成员),但对派生类函数成员不可见,不能被派生类函数成员访问。
- 若派生类函数成员要访问基类的私有成员,则必须将其声明为基类的成员友元。
-
在派生类外部,对其成员访问的权限:
- 对于新定义成员,按定义时的访问权限访问;
- 对于继承来的基类成员,取决于这些成员在派生类中的访问权限,与其在基类中定义的访问权限无关。
-
若类POINT的继承方式为public,基类函数getx、gety派生后的访问权限仍为public,对类POINT来说这是合理的,因为,对类POINT来说则类需要这样的函数成员;
-
同上,若类POINT的继承方式为public,基类函数成员moveto派生后的访问权限为public,对类POINT来说则是不合理的,因为类POINT自己定义了public函数成员moveto。在第6页中,主函数还能调用基类函数LOCATION::moveto。
-
继承方式为private时,基类公有成员在派生类中的访问权限变为private。不合理时可以使用“基类名::成员”或“using 基类名::成员”修改某些成员的访问权限, 派生类不能再定义同名的成员。
class POINT:private LOCATION{ //private可省略
int visible;
public:
LOCATION::getx; //修改权限成public,或者using LOCATION::getx;
LOCATION::gety; //修改权限成public
int isvisible( ){ return visible; }
void show( ), hide( );
void moveto(int x,int y);
POINT(int x,int y):LOCATION(x,y){ visible=0; }
~POINT( ){ hide( ); }
};
- 需要指出的是,选用private作继承方式通常不是最好的选择。如果派生类POINT选用private作继承方式,却又未修改LOCATION::getx的访问权限,则getx在POINT类中的访问权限将变为private,从而使其它非派生类成员的函数无法访问private的POINT::getx。
- C++恢复访问权限是将派生类继承的基类成员的访问权限复原成和该成员在基类定义时的访问权限一样。派生类不仅可以恢复基类成员的访问权限,还可以改变访问权限(但不可改变基类私有成员访问权限)。
- 基类成员经过继承方式被继承到派生类后,要注意访问权限的变化。
- 按面向对象的作用域,和基类同名的派生类成员被优先访问。
- 派生类中改写基类同名函数时,要注意区分这些同名函数,否则可能造成自递归调用。
- 标识符的作用范围可分为从小到大四种级别:①作用于函数成员内;②作用于类或者派生类内;③作用于基类内;④作用于虚基类内。
- 标识符的作用范围越小,被访问到的优先级越高。如果希望访问作用范围更大的标识符,则可以用类名和作用域运算符进行限定。
【例6.3】以链表LIST类为基类定义集合类SET。
class LIST{
struct NODE{ //定义节点类
int val; NODE *next;
NODE(int v, NODE *p){ val=v; next=p; }
~NODE( ){if(next) {delete next; next=0;}}
}*head; //定义数据成员
public:
int insert(int), contains(int);
LIST( ){ head=0; } //0表示空指针
~LIST( ){ if(head){ delete head; head=0; //0表示空指针} }
};
int LIST::contains(int v){ //搜索链表,查询是否存在该节点
NODE *h=head;
while((h!=0)&&(h->val!=v)) h=h->next;
return h!=0; //0表示空指针
}
int LIST::insert(int v){ //在链表中插入新增节点(在链表首部插入)
head=new NODE(v,head); //head指向新的节点,第一个节点插入时head->next=0
return 1;
}
class SET:protected LIST{ //采用保护继承方式
int used; //集合元素的个数
public:
LIST::contains; //修改contains函数访问权限
int insert(int); //改写insert函数(Override)
SET( ){ }; //等价于SET( ):LIST( ){ };
};
int SET::insert(int v){ //LIST::insert中的LIST不能省略:否则自递归
if(!contains(v)&&LIST::insert(v)) return ++used;
return 0;
}
void main(void) { SET s; s.insert(3); s.contains(3); }
- 派生类不能访问基类私有成员,除非将派生类的声明为基类的友元类,或者将要访问基类私有成员的派生类函数成员声明为基类的友元。
class B; //前向声明类B
class A{
int a, b;
public:
A(int x){a=x;}
friend B; //声明B为A的友元类,B类成员可以访问A任何成员
};
class B:A{ //缺省为private继承,等价于class B: private A{
int b;
public:
B(int x):A(x){ b=x; A::b=x; a+=3; } //可访问私有成员A::a,A::b
};
void main(void){ B x(7); }
6.4 构造与析构
- 单继承派生类的构造顺序比较容易确定:
- 调用虚基类的构造函数;
- 调用基类的构造函数;
- 按照派生类中数据成员的声明顺序,依次调用数据成员的构造函数或初始化数据成员;
- 最后执行派生类的构造函数构造派生类。
- 析构是构造的逆序
- 以下情况派生类必须定义自己的构造函数:
- 虚基类或基类只定义了带参数的构造函数;
- 派生类自身定义了引用成员或只读成员,且这些成员没有类内就地初始化;
- 派生类定义了需要使用带参数构造函数初始化的其它类对象成员,且这些成员没有类内就地初始化。
class A{
int a;
public:
A(int x):a(x){cout<<a;}//非const成员a也可在构造函数体内再次对a赋值
~A( ){cout<<a;}
};
class B:A{ //私有继承,等价于class B: private A{
int b,c;
const int d;//B中定义有只读成员且没有就地初始化,故必须定义构造函数初始化
A x,y; //x、y的构造必须带参数,且没有就地初始化,故必须定义构造函数初始化
public:
B(int v):b(v),y(b+2),x(b+1),d(b),A(v){//注意构造次序与成员初始化列表的出现顺序无关
c=v; cout<<b<<c<<d; cout<<“C”; //c=v不是初始化,是重新赋值
}
~B( ){cout<<“D”;} //派生类数据成员实际构造顺序为b,c, d,x,y
};
void main(void){ B z(1); } //输出结果:123111CD321
- 如果虚基类和基类的构造函数是无参的,则构造派生类对象时,派生类构造函数可以不用显式调用基类/虚基类的构造函数,编译程序会自动调用虚基类或基类的无参构造函数。
- 如果被引用的对象是用new生成的,则引用变量r必须用delete &r析构对象,否则被引用的对象将因无法完全释放空间(为对象申请的空间)而产生内存泄漏。
- 若被p(指针)指向的对象是用new生成的,则指针变量p必须用delete p析构对象, 不能使用不调用析构函数的free(p),否则将产生内存泄漏。
【例6.6】被引用的对象的析构。
class A {
int i; int* s;
public:
A(int x) {
s = new int[i = x];
cout << "(C): " << i << "\n";
}
~A() {
delete s;
cout << "(D): " << i << "\n";
}
};
void sub1(void) {
A& p = *new A(1);
}//内存泄露
void sub2(void) {
A* q = new A(2);
} //内存泄露
void sub3(void) {
A& p = *new A(3);
delete& p;
}
void sub4(void) {
A* q = new A(4);
delete q;
}
void main(void) {
sub1(); sub2();
sub3(); sub4();
}
输出:
(C): 1
(C): 2
(C): 3
(D): 3
(C): 4
(D): 4
6.5 父类和子类
- 如果派生类的继承方式为public,则这样的派生类称为基类的子类,而相应的基类则称为派生类的父类。
- C++允许父类指针直接指向子类对象,也允许父类引用直接引用子类对象。无须通过强制类型转换保持类型相容。编译时按父类说明的成员权限访问成员(编译程序只能根据类型定义静态检查语义,因此编译时把父类指针指向的对象都当作父类对象)。
- 通过父类指针调用虚函数时晚期绑定,根据对象的实际类型绑定到合适的成员函数。
- 父类指针实际指向的对象的类型不同,虚函数绑定的函数的行为就不同,从而产生多态。
- 编译程序只能根据类型定义静态地检查语义。由于父类指针可以直接指向子类对象,而到底是指向父类对象还是子类对象只能在运行时确定。
- 编译时,只能把父类指针指向的对象都当作父类对象。因此编译时:
- 父类指针访问对象的数据成员或函数成员时,不能超越父类为相应对象成员规定的访问权限;
- 也不能通过父类指针访问子类新增的成员,因为这些成员在父类中不存在,编译程序无法识别。
例:
class POINT
{
int x, y;
public:
int getx() { return x; }
int gety() { return y; }
void show() { cout <<"Show a point\n"; }
POINT(int x, int y)
{
POINT::x = x;
POINT::y = y;
}
};
class CIRCLE : public POINT
{ // 公有继承
int r; // 私有成员
public:
int getr() { return r; }
void show() { cout <<"Show a circle\n"; }
CIRCLE(int x, int y, int r) : POINT(x, y) { CIRCLE::r = r; }
};
int main()
{
CIRCLE c(3, 7, 8);
POINT *p = &c; // 父类对象指针p可以直接指向子类对象,不用类型转换
cout <<"The circle with radius "<< c.getr();
// cout << p->getr(); //错误,因为getr( )函数不是父类的函数成员编译程序无法通过检查
cout <<"is at("<< p->getx() <<","<< p->gety() <<")\n";
p->show();
// p虽然指向子类对象,但调用的是父类的show函数(show函数不是虚函数,没有多态性)
return 0;
}
- C++允许父类指针指向子类对象而不用强制转换
class Person { public: void f() { cout << “P\n”;}};
class Teacher: public Person()
{ public: void f(){ cout << “T\n”;}};
Person *p = new Teacher();//左边父类,右边子类
p->f(); //输出的是P,为什么不输出T?
- 为什么父类指针可以直接指向子类对象?
- 因为子类对象有多个类型,子类本身及父类、父类的父类…。(Teacher是Person)
- 编译器认为子类指针赋给父类指针类型是匹配的

- 子类指针不能指向父类对象(子类=父类)必须强制转换
Person *p = new Teacher();
Teacher *t = (Teacher *)p; // Teacher *t = p会出错
或者 Teahcer *t = (Teacher *)new Person(); //必须强制类型转换 - 首先编译时编译器认为p的类型是Person*,t的类型是Teacher *(按声明类型检查)
- 因为父类型不一定是子类型(Person不一定是Teacher)所以当编译器检查到Teacher *t = p时,认为一个Person类型的指针要赋值给Teacher类型的指针,类型是不匹配的
- 强制转换Teacher *t = (Teacher *)p的意思是告诉编译器,请不要再做类型检查,风险我自己承担。
- 强制类型转换的风险是:运行时如果p指向的对象不是Teacher的实例时程序会出错(Run Time Error)
- 因此在赋值前必须利用RTTI(运行时类型标识)来检查p是不是指向Teacher的实例
if(!strcmp(typeid(*p).name(),”Teacher”))
Teacher *t = (Teacher *)p;
- 若基类和派生类没有构成父子关系,则:
- 普通函数里,定义的基类指针不能直接指向派生类对象,而必须通过强制类型转换才能指向派生类对象。
- 普通函数里定义的基类引用也不能直接引用派生类对象,而必须通过强制类型转换才能引用派生类对象。
例:引用父类对象的引用变量引用子类对象。
#include <iostream>
#include "../include/MyArray.h"
using namespace std;
class A
{
int a;
public:
int getv() { return a; }
A() { a = 0; }
A(int x) { a = x; }
~A() { cout << "~A\n"; }
};
class B : A
{ // 非父子:private
int b;
public:
int getv()
{
return b + A::getv();
}
B() { b = 0; } // 等于B( ):A( )
B(int x) : A(x) { b = x; }
~B() { cout << "~B\n"; }
};
class C : public A
{ // 父子关系
int c; // 私有成员c
public:
int getv() { return c + A::getv(); }
C() { c = 0; } // 等价于C( ):A( ) { c=0; }
C(int x) : A(x) { c = x; }
~C() { cout << "~C\n"; }
};
int main(void)
{
A &p = *new C(3); // 直接引用C类对象:A和C父子
A &q = *(A *)new B(5); // 强制转换引用B类对象:A和B非父子
cout << "p.getv() =" << p.getv() << endl; // 执行的是哪个getv?
cout << "q.getv( )=" << q.getv() << endl; // 执行的是哪个getv?
delete &p; // 析构C(3)的父类A而非子类C(为什么?析构函数不是虚函数)
delete &q;
return 0; // 析构B(5)的父类A 而非子类B
}
- 在派生类函数成员内部,定义的基类指针可以直接指向该派生类对象,即对派生类函数成员而言,基类被等同地当作父类。
- 如果函数声明为派生类的友元,则该友元定义的基类指针也可以直接指向该基类的派生类对象,也不必通过强制类型转换。
例:定义机车类VEHICLE,并派生出汽车类CAR。
class VEHICLE
{
int speed, weight, wheels;
public:
VEHICLE(int spd, int wgt, int whl);
};
VEHICLE::VEHICLE(int spd, int wgt, int whl)
{
speed = spd;
weight = wgt;
wheels = whl;
}
class CAR : private VEHICLE
{ // 非父子关系: private
int seats;
public:
VEHICLE *who();
CAR(int sd, int wt, int st);
friend void main();
};
CAR::CAR(int sd, int wt, int st) : VEHICLE(sd, wt, 4) { seats = st; }
VEHICLE *CAR::who()
{
VEHICLE *p = this; // 派生类内的基类指针直接指向派生类对象
VEHICLE &q = *this; // 派生类内的基类引用直接引用派生类对象
return p;
}
// 在派生类的友元main中,基类和派生类构成父子关系
void main(void)
{
CAR c(1, 2, 3);
VEHICLE *p = &c;
}
dynamic_cast的使用:
- dynamic_cast 是一个用于安全地将基类指针转换为派生类指针的机制,前提是基类有虚函数,表明它是多态类型。
- 在多态类型下,dynamic_cast 可以检查 p3 指针所指的对象是否是 C 类型,如果是,则转换成功;否则,返回 nullptr(对于指针)或者抛出异常(对于引用)。
例:dynamic_cast
class A
{
};
class B : protected A
{
public:
// 以下代码点可以同时访问基类和派生类的公有接口(函数)
void f() { A *p = this; }
static void g() { A *p = new B(); }
friend void h() { A *p = new B(); }
};
void test()
{
// 判断基类指针是否可以直接指向派生类,就要看当前代码点是否可以同时访问基类和派生类的公有接口(函数)。对于非父子关系,当前代码点不能访问基类的公有接口,因此基类指针不能直接指向派生类而必须强制转换
A *p1 = (A *)(new B); // 对于非父子关系,可以用C style casting
delete p1;
}
class A
{
// virtual void f() {};
};
class C : public A
{
public:
C() = default;
};
void test()
{
A *p3 = new C;
// 错误. 运行时dynamic_cast的操作数p3必须是多态类型。
// 因为A没有虚函数,也就没有虚函数表,因此A不是多态类型.
// 若在A里加上虚函数,这个语句就可以
C *p4 = dynamic_cast<C *>(p3); // 父类向子类转换,必须具有多态性
}
上例中,类 A 没有虚函数,因此它不是多态类型。在C++中,如果一个类没有虚函数,它就没有虚函数表(VTable),这意味着它不能用于运行时类型识别(RTTI)。dynamic_cast 在运行时会检查类型,只有具有多态性的类(即具有虚函数的类)才可以使用 dynamic_cast 进行安全的类型转换。
第七章 可访问性
第八章 虚函数与多态
8.1 虚函数
- 虚函数:即用virtual定义的实例成员函数。Java所有实例函数都默认为虚函数。当基类对象指针(引用)指向(引用)不同类型派生类对象时,通过虚函数到基类或派生类中同名函数的映射实现(动态)多态。
- 重载函数是静态多态函数,通过静态绑定调用重载函数(编译时确定了调哪个函数);虚函数是动态多态函数,通过动态绑定调用函数(在运行时重新计算函数入口地址)。动态绑定是程序运行时自己完成的,静态绑定是编译或操作系统完成的。
- 虚函数的动态绑定通过存储在对象中的一个指针完成,该指针指向虚函数入口地址表VFT。虚函数一定有this指针(因为虚函数是实例成员函数)
例1:多态
class A {
public:
virtual void info() { cout << "A\n"; }
//首先将info定义为虚函数
};
class B : public A {
virtual void info() { cout << "B\n"; }
};
class C : public B {
virtual void info() { cout << "C\n"; }
};
//假设从C派生出子类D
class D : public C {
virtual void info() { cout << "D\n"; }
};
void PrintInfo(A* p) { //形参定义为顶级父类指针
p->info();//程序运行时,当顶级父类指针指向p继承链中不同子类对象时,会自动地调用相应子类的info函数
}
int main()
{
//同一条语句p->info( )在运行时表现出动态的行为。运行时行为取决于new后面的类型
//面向对象的程序设计语言的这种特性称为多态
A* a = new A(); B* b = new B(); C* c = new C(); D* d = new D();
PrintInfo(a); //调用A的info,显示A。A * p = a;
PrintInfo(b); //调用B的info,显示B。 A *p = b;
PrintInfo(c); //调用C的info,显示C。 A *p = c;
PrintInfo(d);//只要是从A类开始沿着继承链任意级的派生类对象,PrintInfo都可以打印出其信息。
//即使这些派生类是在PrintInfo函数被编译好以后(假设PrintInfo函数被单独编译为一个动态链接库)才定义。
//PrintInfo甚至都不需要重新编译都可以很好地工作。
}
例2:
#include <iostream>
#include <stdlib.h>
using namespace std;
class POINT2D {
int x, y;
public:
int getx() { return x; }
int gety() { return y; }
virtual POINT2D* show() { cout << "Show a point\n"; return this; } //定义虚函数
POINT2D(int x, int y) { POINT2D::x = x; POINT2D::y = y; }
};
class CIRCLE : public POINT2D { //POINT2D和CIRCE满足父子关系
int r;
public:
int getr() { return r; }
CIRCLE* show() {
cout << "Show a circle\n";
return this;
}//原型“一样”,自动成为虚函数
//C++ 允许虚函数在子类中覆盖时有不同的返回类型,但是这种返回类型必须是 协变类型(covariant types),
//也就是派生类的返回类型必须是基类返回类型的派生类型。
//在代码中,CIRCLE* 是 POINT2D* 的派生类型,所以这部分是合法的。
CIRCLE(int x, int y, int r) :POINT2D(x, y) { CIRCLE::r = r; }
};
int main()
{
CIRCLE c(1, 2, 3);
POINT2D* p = &c; //父类指针p可以直接指向子类对象c
cout << "The circle with radius " << c.getr();
cout << " is at (" << p->getx() << ", " << p->gety() << ")\n";
p->show(); // Show a circle,如果把Circle里的show函数定义为私有的会如何?请思考
//运行时仍然会调用 CIRCLE 中的 show() 函数,即使它是 private 的,这是因为虚函数的调用是在运行时通过动态绑定决定的。
}
- 虚函数必须是类的实例成员函数,非类的成员函数不能说明为虚函数,普通函数如main不能说明为虚函数。
- 虚函数一般在基类的public或protected部分(为什么?)。在派生类中重新定义成员函数时,函数原型必须完全相同;
- 虚函数只有在具有继承关系的类层次结构中定义才有意义(即使不是父子关系),否则引起额外开销 (需要通过VFT访问);
- 必须用父类指针(或引用)访问虚函数才有多态性。根据父类指针所指对象类型的不同,动态绑定相应对象的虚函数;(虚函数的动态多态性)
- 虚函数有隐含的this参数,参数表后可出现const和volatile,静态函数成员没有this参数,不能定义为虚函数:即不能有virtual static之类的说明;
- 构造函数构造对象的类型是确定的,不需根据类型表现出多态性,故不能定义为虚函数;析构函数可通过父类指针(引用)或delete调用,父类指针指向的对象类型可能是不确定的,因此析构函数可定义为虚函数(强烈建议)。
- 一旦父类(基类)定义了虚函数,所有派生类中原型相同的非静态成员函数自动成为虚函数(即使没有“virtual”声明);(虚函数特性的无限传递性)
- 虚函数同普通函数成员一样,可声明为或自动成为inline函数(但内联肯定失败),也可重载、缺省和省略参数。
- 虚函数能根据对象类型适当地绑定函数成员,且绑定函数成员的效率非常之高,因此,最好将实例函数成员全部定义为虚函数。
- 注意:虚函数主要通过基类和派生类表现出多态特性,由于union既不能定义基类又不能定义派生类,故不能在union中定义虚函数。
#include <iostream>
#include <stdlib.h>
using namespace std;
struct A {
virtual void f1() { cout << "A:f1()\n"; } virtual void f2() { cout << "A:f2()\n"; }
virtual void f3() { cout << "A:f3()\n"; } virtual void f4() { cout << "A:f4()\n"; }
};
class B :A { //私有派生
virtual void f1() { cout << "B:f1()\n"; } //virtual可省略
void f2() { cout << "B:f2()\n"; }
};
class C :B { //私有派生
void f4() { cout << "C:f4()\n"; }
};
void test(void)
{
//非父子关系,多态性质还是存在
C c; A* p = (A*)&c;
p->f1(); //B::f1();
p->f2(); //B::f2();
p->f3(); //A::f3()
p->f4(); //C::f4()
//c.f1(), c.f2(), c.f3(), c.f4(); //编译会出错
}
int main(void)
{
test();
system("pause");
return 0;
}
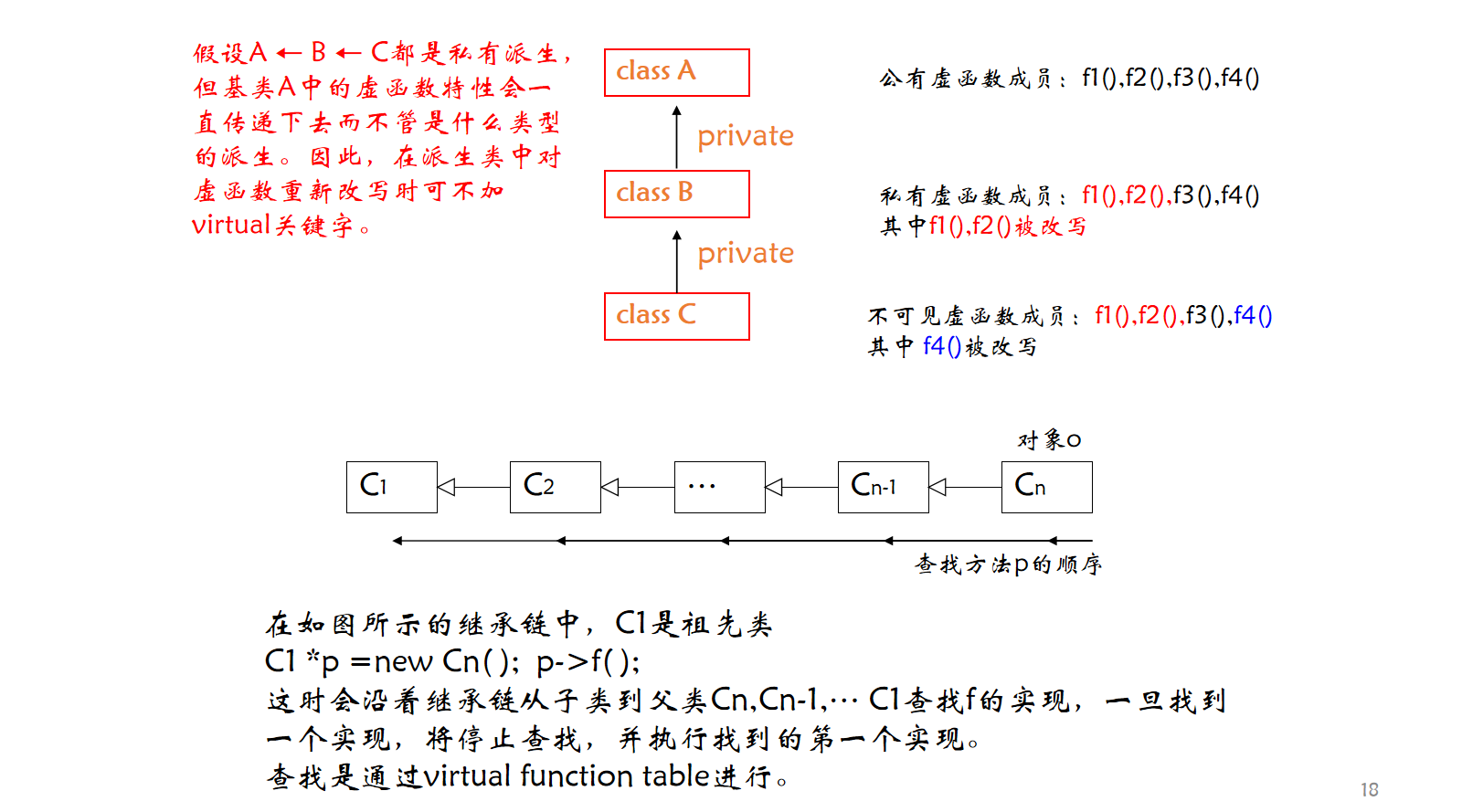
- 重载函数使用静态联编(早期绑定)机制;虚函数采用动态联编(晚期绑定)机制;
- 早期绑定:在程序运行之前的绑定;晚期绑定:在程序运行中,由程序自己完成的绑定。
- 对于父类A中声明的虚函数f( ),若在子类B中重定义f( ),必须确保子类B::f( )与父类A::f( )具有完全相同的函数原型,才能覆盖原虚函数f( )而产生虚特性,执行动态联编机制。否则,只要有一个参数不同,编译系统就认为它是一个全新的(函数名相同时重载)函数,而不实现动态联编。
- 关于子类B::f( )与父类A::f( )具有完全相同的函数原型,有个地方需要补充说明:就是函数返回类型不一定完全一样,只要相容就行(例如A::f( )函数返回A类型(或A),B::f( )函数返回B类型(或B)就是相容)
8.2 虚析构函数
- 如果基类的析构函数定义为虚析构函数,则派生类的析构函数就会自动成为虚析构函数(即使原型不同,即函数名不一样)。
- 说明虚析构函数的目的在于在使用delete运算符释放一个对象时,能够保证所执行的析构函数就是该对象的析构函数;最好将所有的析构函数都定义为虚析构函数。注意,对象数组指针p应用delete []p释放。
- 注意:如果为基类和派生类的对象分配了动态内存,或者为派生类的对象成员分配了动态内存,则一定要将基类和派生类的析构函数定义为虚析构函数,否则便可能造成内存泄漏,导致系统出现内存保护错误。
例1:虚析构函数的使用
class A {
int* p;
int size;
public:
A(int s) : p(new int[size = s]) {}
//A的析构函数是虚函数,它所有的后代的析构函数就都是虚函数
virtual ~A() { if (p) { delete[]p; p = 0; } }
};
class B : public A {
private:
int* q;
int length;
public:
B(int s, int l) :A(s), q(new int[length = l]) {}
//B的析构会自动调用A的析构,所以不用操心p的释放
~B() { if (q) { delete[]q; q = 0; } }
};
void test() {
A* p = new B(10, 10);
//由于多态,会调用B的析构函数。但如果析构函数不是虚函数,由于p的声明类型为
//A *,因此编译时delete P被绑定到A的析构函数,只会执行A的析构,
//导致对象里q指针指向的内存没有被释放
delete p;
}
8.3 类的引用
-
用父类引用实现动态多态性时需要注意, new产生的被引用对象必须用delete &析构:
STRING &z=*new CLERK("zang","982021",23);
delete &z; //析构对象z并释放对象z占用的内存 -
上述delete &z完成了两个任务:①调用该对象析构函数~CLERK( ),释放其基类和对象成员各自为字符指针str分配的空间;②释放CLERK对象自身占用的存储空间。
-
如将delete &z改为z.~STRING( ),则只完成任务①而没完成②;如果改为free(&z),则只完成任务②而没完成①。造成内存泄露。为什么z.~STRING( ) 执行~CLERK( )? (z是引用,实现为指针,同样具有多态性)
-
当类的内部包含指针成员时,为了防止内存泄漏,不应使用编译自动生成的构造函数、赋值运算符函数和析构函数。
-
对于类型为A且内部有指针的类,应自定义A()、A(A&&) noexcept 、A(const A&)、A& operator=(const A&)、 A& operator=(A&&) noexcept以及~A( )函数。
A(A&&)、 A& operator=(A&&)通常应按移动语义实现,构造和赋值分别是浅拷贝移动构造和浅拷贝移动赋值。“移动”即将一个对象(通常是常量)内部的(分配内存的) 指针成员浅拷贝赋给新对象的内部指针成员,而前者的内部指针成员设置为空指针(即内存被移走了)。
例1:
#include <iostream>
#include <stdlib.h>
using namespace std;
class A {
int* p;
int m;
public:
A() : p(nullptr), m(0) {}
A(int m) : p(new int[m]), m(p ? m : 0) { }
A(const A& a) : p(new int[a.m]), m(p ? a.m : 0) {//深拷贝构造必须为p重新分配内存
for (int x = 0; x < m; x++) p[x] = a.p[x];
}
A(A&& a) noexcept : p(a.p), m(a.m) {//深拷贝构造必须为p重新分配内存
a.p = nullptr; a.m = 0;
}
//等号重载
A& operator=(const A& a) {
if (this != &a) {
if (p) delete p;
p = new int[a.m];
m = p ? a.m : 0;
for (int x = 0; x < m; x++) p[x] = a.p[x];
}
return *this;
}
int getm() { return m; }
~A() {
if (p) { delete p; p = nullptr; m = 0; }
};
};
A& f(A&& x) {
//A &&a = x; //报错,无法把右值绑定到左值,x是左值
A&& a = static_cast<A&&>(x); //a引用x所引用的对象;
//或者用std::move,但是可以看std::move的实现,就是用的static_cast<A &&>
// A&& a = std::move(x); //a引用x所引用的对象;
return a; //返回A &:参数有名有址,类型&&自动转换为&。x和a都不负责析构
//return x; //结果同上述两条语句
}
int main()
{
A c(20);
c = f(A(30)); //A(30)是右值,f(A(30))返回的是右值,所以调用移动构造函数
cout << c.getm() << endl;//30
return 0;
}
8.4 抽象类
- 纯虚函数:不必定义函数体的虚函数,也可以重载、缺省参数、省略参数、内联等,相当于Java的interface。
- 定义格式:virtual 函数原型=0。 (0即函数体为空)
- 纯虚函数有this,不能同时用static定义(表示无this)。
- 构造函数不能定义为虚函数,同样也不能定义为纯虚函数。
- 析构函数可以定义为虚函数,也可定义为纯虚函数。
- 函数体定义应在派生类中实现,成为非纯虚函数。
- 抽象类:含有纯虚函数的类。
- 抽象类常用作派生类的基类,不应该有对象或类实例(相当于Java的interface)。
- 如果派生类继承了抽象类的纯虚函数,却没有在派生类中重新定义该原型虚函数,或者派生类定义了基类所没有的纯虚函数,则派生类就会自动成为抽象类。
- 在多级派生的过程中,如果到某个派生类为止,所有纯虚函数都已在派生类中全部重新定义,则该派生类就会成为非抽象类(具体类)。
struct A { virtual void f1() = 0, f2() = 0; }; //A为抽象类, 不能定义A a; A f ( )
//但还是可以给出纯虚函数的函数体,尽管如此,f1,f2还是纯虚函数,A还是抽象类
void A::f2() { cout << "A2"; }
void A::f1() { cout << "A1"; }
class B :public A { //取代型定义f2, 未定义f1, B为抽象类
void f2() { A::f2(); cout << "B2"; } //自动成虚函数, 导致内联失败
}; //B为抽象类, 不能定义f (B b), 不能定义B *s=new B
class C :public B { // f1和f2均取代型定义, 具体类C可定义变量、常量等
void f1() { cout << "C1"; } //自动成虚函数, 虚函数导致内联失败
}c;
void test(void) {
A* p = &c; //A、C满足父子关系
//虽然抽象类没有可供引用或指向的对象,但是抽象类仍然可以作为父类定义指针或引用,指向或引用子对象
p->f1();//调用C::f1 ( )
p->f2(); //调用B::f2 ( )
} //C1A2B2
int main() {
test();
return 0;
}
-
抽象类不能定义或产生任何对象,包括用new创建的对象,故不能用作函数参数的值类型和函数的返回值类型(调用前后要产生该类型的对象)。
-
虽然抽象类没有可供引用或指向的对象,但是抽象类仍然可以作为父类定义指针或引用,指向或引用子对象
-
抽象类指针或引用可以作为函数参数或返回类型,而且强烈建议这样做
-
通过抽象类指针或引用可调用抽象类的纯虚函数,根据多态性,实际调用的应是该类的非抽象派生类的虚函数。
-
抽象类作为抽象级别最高的类,主要用于定义派生类共有的数据和函数成员。抽象类的纯虚函数没有函数体,意味目前尚无法描述该函数的功能。例如,如果图形是点、线和圆等类的抽象类,那么抽象类的绘图函数就无法绘出具体的图形。
-
纯虚函数和虚函数都能定义成另一个类的成员友元。由于纯虚函数一般不会定义函数体,故纯虚函数一般不要定义为其他类的成员友元。
-
如果类A的函数成员f定义为类B的友元,那么f就可以访问类B的所有成员,但是,f并不能访问从类B派生的类C的所有成员,除非f也定义为类C的友元或者类A就是类C。(即友元对派生不具备传递性)
#include<iostream>
using namespace std;
class C;
struct A {
virtual void f1(C& c) = 0;
virtual void f2(C& c);
};
class B : A {
public:
void f1(C& c); //f1自动成虚函数
};
class C {
char c;
//允许但无意义,A::f1无函数体
friend void A::f1(C& c);
friend void A::f2(C& c);
public:
C(char c) { C::c = c; }
};
void A::f1(C& c)
{
cout << "B outputs " << c.c << "\n";
}
void A::f2(C& c) { cout << "A outputs " << c.c << "\n"; }
void B::f1(C& c) { cout << c.c; } //×,B::f1不是C的友元,不能访问
void main(void) {
B b; C c('C');
A* p = (A*) new B;
p->f1(c); //调用B::f1( )
p->f2(c); //调用A::f2( )
}
8.5 虚函数友元与晚期绑定
- 虚函数动态绑定:
i. C++使用虚函数地址表(VFT)来实现虚函数的动态绑定。VFT是一个函数指针列表,存放对象的所有虚函数的入口地址。
ii. 编译程序为有虚函数的类创建一个VFT,其首地址通常存放在对象的起始单元中。调用虚函数的对象通过起始单元找到VFT,从而动态绑定相应的函数成员,从而使虚函数随调用对象的不同而表现多态特性。 - 动态绑定比静态绑定多一次地址访问,在一定程度上降低了程序的执行效率,但同虚函数的多态特性带来的优点相比,效率降低所产生的影响是微不足道的。
- 多态性涉及二个问题
1:程序在运行时怎么知道p指向的是B类的对象
2:怎么找到B::f1() 函数的入口地址 - 第一个问题:利用RTTI (Runtime Type Identification)
- 第二个问题:建立一个VFT,在VFT中,包含每个虚函数的入口地址, 同时用一个索引号来关联函数名。同时将指向VFT的指针vptr加到对象内存中。
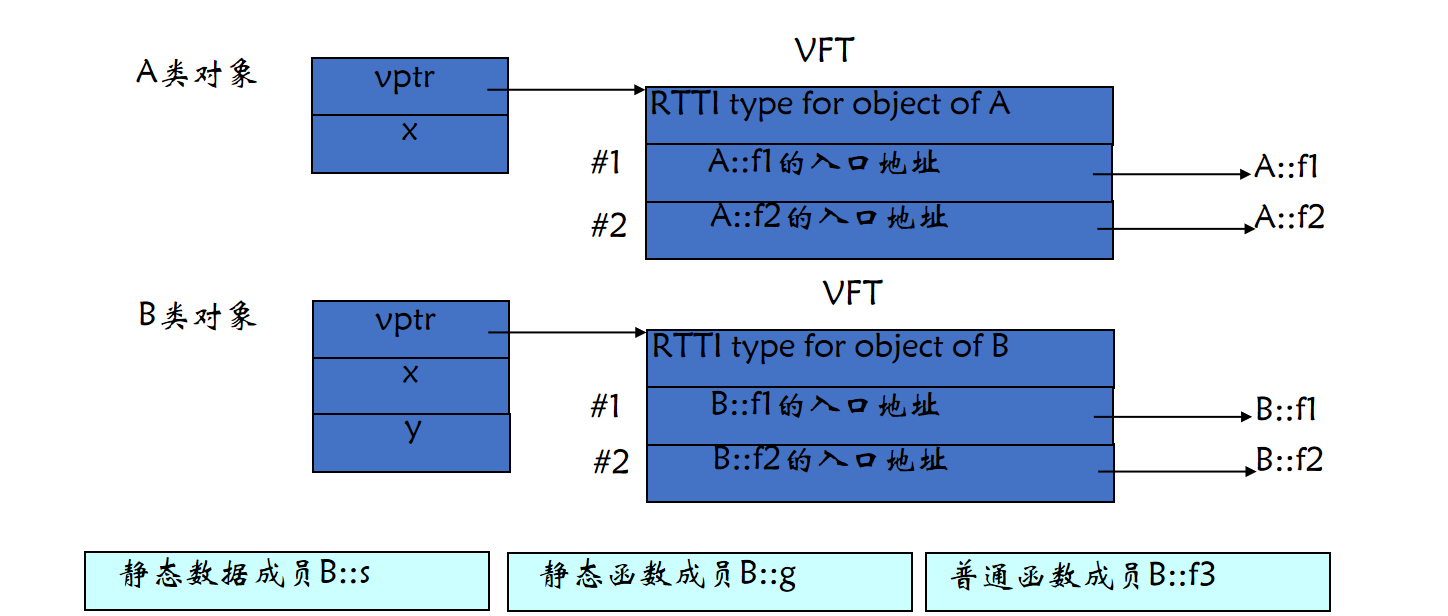
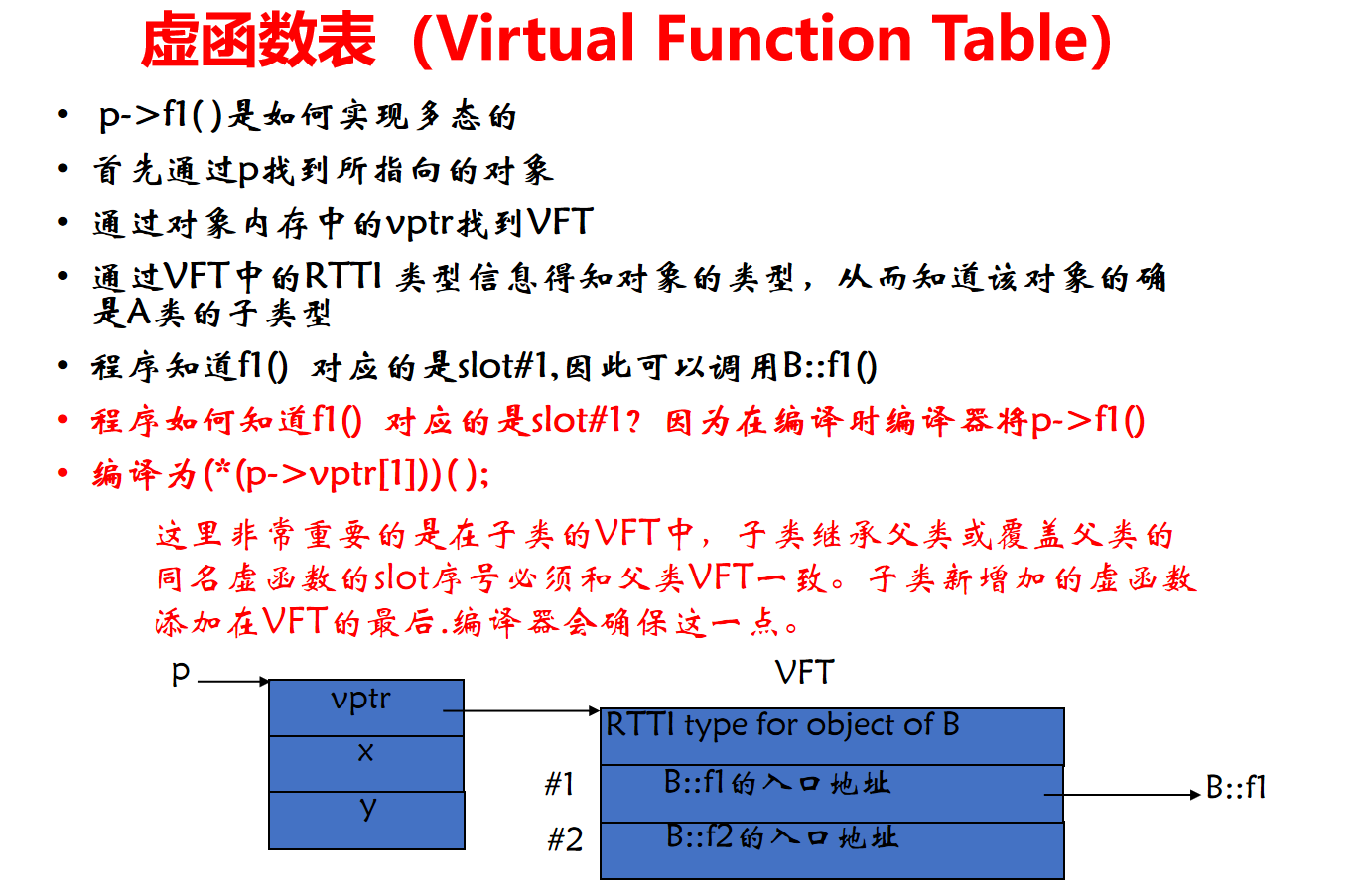
- 设基类A和派生类B都有虚函数, 对应的虚函数入口地址表分别为VFTA和VFTB。派生类对象b在生命期各阶段:
- 构造阶段:先将VFTA的首地址存放到b的起始单元,在基类A构造函数的函数体执行时,如果构造函数函数体调用了虚函数,则与VFTA绑定,执行的虚函数将是类A的函数; 在类B构造函数的函数体执行前,将VFTB的首地址存放到b的起始单元,如果构造函数函数体调用了虚函数,则与VFTB绑定,执行的虚函数将是类B的函数。如果类B没有定义这样的函数,根据面向对象的作用域,将调用基类A的相同原型的函数。
- 生存阶段:b的起始单元指向VFTB,若调用了虚函数,则绑定和执行的将是类B的函数。如果类B没有定义这样的函数,根据面向对象的作用域,将调用基类A的相同原型的函数。
- 析构阶段:b的起始单元指向VFTB,若析构函数里调用了虚函数,则绑定和执行的将是类B的函数; 在b的析构函数执行完后、基类的析构函数执行前, 将VFTA首地址存放到b的起始单元,此后绑定和执行的将是基类A的函数。
例:
#include<iostream>
using namespace std;
class A {
int x;
virtual void c()
{
cout << "Construct A\n";
}
virtual void d()
{
cout << "Deconstruct A\n";
}
public:
A() { c(); } //this->c( )
virtual ~A() { d(); } //this->d( )
};
class B:A {
virtual void c()
{
cout << "Construct B\n";
}
virtual void d()
{
cout << "Deconstruct B\n";
}
public:
B() { c(); }//等于B ( ): A( ){c ( ); }
virtual ~B() { d(); }//virtual可省
};
输出结果:
Construct A
Construct B
Deconstruct B
Deconstruct A
第九章 异常与断言
9.1 异常处理
-
异常:一种意外破坏程序正常处理流程的事件、由硬件或者软件触发的事件。
-
异常处理可以将错误处理流程同正常业务处理流程分离,从而使程序的正常业务处理流程更加清晰顺畅。
-
异常发生后自动析构调用链中的所有对象,这也使程序降低了内存泄漏的风险。
-
由软件引发的异常用throw语句抛出,会在抛出点建立一个描述异常的对象,由catch捕获相应1. 类型的异常。
-
异常对象:描述异常事件的对象
-
try:程序的正常流程部分,可引发异常,由异常捕获部分处理。
-
thow:用于引发异常、继续传播异常
-
catch:异常捕获部分。处理时,根据要捕获的异常对象类型处理相应异常事件,可以继续传播或引发新的异常。
-
一旦异常被某个catch处理过程捕获,则其它所有处理过程都会被忽略。
-
C++不支持finally处理过程

-
可以抛出任何类型的异常,抛出异常的throw语句一定要间接或直接在try语句块中
-
如果抛出的异常不在任何一个try语句块中,这种没有异常处理过程捕获的异常将引起程序终止执行
-
在try中抛出的异常如果没有合适的catch捕获,也将引起程序终止执行
-
一个try中可以抛出多种异常。
throw 1;
throw ‘c’;
throw new int(3);
throw new int[3]{1,2,3}
throw “abcdef”;
throw CExecption();
throw new CExecption();
9.1.1 异常(Exception)处理流程
try语句块中的语句可能抛出各种异常。但只要抛出第一个异常,try语句块马上结束,转到catch子句。如果try语句块执行成功,则跳过catch,执行try{}catch{}的后续statements;
可定义多个catch子句截获可能抛出的各种异常。但最多只会执行其中一个异常处理过程。在相应异常被处理后,其他异常处理过程都将被忽略。如果异常处理成功,则执行后续statements。如果异常处理过程中又抛出新的异常,则后续statements不会被执行
try {
// statements throw E1
// statements throw E2
…
}
catch(E1){
//handle the exception E1
}
catch(E2){
//handle the exception E2
}
statements;
9.1.2 异常处理的结构
异常的抛出都是由throw语句直接或间接抛出:
1:程序运行时的逻辑错误导致异常间接抛出,例如数组指针++导致越界时由运行库throw出异常
2:程序在满足某条件时,用throw语句直接抛出异常,如
if(满足某条件){
throw “A exception occurred”;
抛出异常使用throw:
throw CExecption( );
抛出的异常可以是任意类型:
throw 1;
throw ‘c’;
throw CExecption( );
throw new int[4];
捕获异常:根据异常类型由catch子句捕获
catch (异常类型 变量)
{
//异常处理
}
可以是指针等任何类型:
catch(int e){...}
catch(char ch){…;}
catch(CExecption e){…}
catch子句必须定义且只能定义一个参数,该参数不能是void,可以是值类型,指针、左值引用,不能是右值引用。
catch必须出现try语句块后面
try{ …
if(rr==0) throw -1;
}
catch(int t){
cout<<t<<endl;
}
不能有单独的try语句块或者单独的catch语句块
throw语句要求直接或者间接出现在try语句块中,异常必须被某个try的catch捕获。如果没有被任何catch捕获,则程序将被终止执行。
异常捕获的过程:栈展开
- 当一个try语句块有异常抛出时,首先检查与该try块相关的catch子句,如果找到了匹配的catch子句,则由该catch子句处理异常
- 如果该try块没找到匹配的catch子句,且该try块嵌套在外层try块里,则检查外层try块的catch子句,这个过程递归进行
- 如果到最外层try块还没找到,则退出当前函数,在调用当前函数的外层函数继续寻找,这个过程递归进行
- 如果到main函数还没找到匹配的catch子句,程序退出,将异常交给OS处理
- 上述过程称为栈展开过程,这里的栈指函数调用链形成的调用栈。
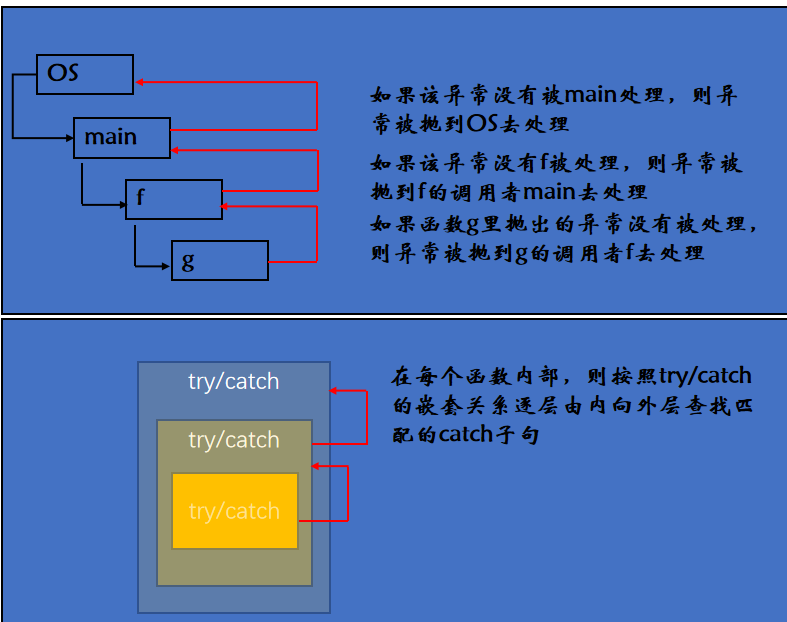
重新抛出异常和捕获所有异常
-
throw语句通常后面跟一个表达式,表达式求值结果就是抛出的异常对象
-
但有时catch子句在捕获异常并作了一些处理后,需要由嵌套的外层try/catch或调用链更上一层的函数继续处理异常,这时可以用不带表达式的throw语句重新抛出异常,如:
catch(MyException &ex){
//do something
throw; //重新抛出异常
} -
有时希望能捕获所有异常,或者不知道可能抛出的异常对象类型,这时可以用catch(…)来捕获所有异常。但要注意如果有其他catch子句,那么catch(…)应该在最后位置。
-
异常处理过程必须定义且只能定义一个参数,该参数必须是省略参数或者是类型确定的参数 ,因此,异常处理过程不能定义void类型的参数。
-
如果是通过new产生的指针类型的异常,在catch处理过程捕获后,通常应使用合适的delete释放内存,否则可能造成内存泄漏。
-
如果继续传播指针类型的异常,则可以不使用delete。
-
抛出字符串常量如“abc”的异常需要用catch(const char *p)捕获,处理异常完毕可以不用delete p释放,因为字符串常量通常存储在数据段。
【例9.1】
#include <iostream>
using namespace std;
class VECTOR
{
int *data; // 用于存储向量元素
int size; // 向量的最大元素个数
public:
VECTOR(int n); // 构造最多存储n个元素的向量
int &getData(int i); // 取下标所在位置的向量元素
~VECTOR()
{
if (data)
{
delete[] data;
data = nullptr;
}
};
};
class INDEX
{ // 定义异常的类型
int index; // 异常发生时的下标值
public:
INDEX(int i) { index = i; }
int getIndex() const { return index; }
};
VECTOR::VECTOR(int n)
{
if (!(data = new int[size = n])) // 分配内存失败则抛出异常
throw(INDEX(0)); // 抛出一个异常对象
};
int &VECTOR::getData(int i)
{
if (i < 0 || i >= size) // 下标越界则抛出异常
throw INDEX(i);
return data[i];
};
void main(void)
{
VECTOR v(100); // 定义向量最多存放100个元素
try
{
v.getData(101) = 30; // 调用int &operator[ ](int i)发生下标越界异常
}
catch (const INDEX &r)
{ // 捕获INDEX及其子类类型的异常
int i = r.getIndex();
switch (i)
{
case 0:
cout << "Insufficient memory!\n";
break;
default:
cout << "Bad index is " << i << "\n";
}
} // C++的异常处理没有finally部分,但是不同的编译器可能由不同的支持方法
cout << "I will return\n";
}
- 没有任何实参的throw用于传播已经捕获的异常。
- 任何throw后面的语句都会被忽略,直接进入异常捕获处理过程catch。
- 如果是通过new产生的指针类型的异常,并且该异常不再传播,则一定要使用delete释放,以免造成内存泄漏。
try{……
throw 1; //正确
//或throw //本try语句出现在某个catch中,或间接被某个catch包含
}
catch(int e){
throw; //正确
}
9.2 捕获顺序
- 先声明的异常处理过程将先得到执行机会,因此,可将需要先执行的异常处理过程放在前面。
- 异常的类型只要和catch参数的类型相同或相容即可匹配成功。即派生异常对象(及对象指针或引用)可以被带基类型对象、指针及引用参数的catch子句捕获。
i.如果A的子类为B,B类异常也能被catch(A)、catch(const A)、 catch(volatile A)、 catch(const volatile A) 等捕获,以及将上述A改为A&等的捕获
ii.如果A的子类为B,指向可写B类对象的指针异常也能被catch(A)、 catch(const A)、 catch(volatile A)、 catch(const volatile A)等捕获。 - 如果产生了B类异常,且catch(const A &)在catch(const B &)之前,则catch(const A &)会捕获异常,从而使catch(const B &)没有捕获的机会。因此,在排列catch时通常将catch父类参数的catch放在后面,否则子类(还包含指针或引用)参数的catch永远没有机会捕获异常。
- 注意catch(const volatile void *)能捕获任意指针类型的异常,catch(…)能捕获任意类型的异常。
【例9.2】
struct A
{
}; // 没有定义任何构造函数,可用编译器提供的A( )
struct B : A
{
}; // 异常类需要描述异常的原因、发生现场、错误信息等
void main(int argc, char *argv[])
{
try
{
throw new B;
}// 注意这里抛出了异常对象的指针 }
catch (A *x) // 参数类型为指针
{
printf("I will catch the exception"); // 捕获异常
}
catch (B *x) // 参数类型为指针
{
} // 无法捕获异常;
catch (...) // 表示可捕获任何异常
{
} // 无法捕获异常;
// 正确的顺序应该为catch(B *x) { } catch(A *x) { } catch(…){ }
// 问题:假定throw (const B*) new B,哪一个catch将捕获异常?
}
【例9.3】
#include <iostream>
class VECTOR
{
int *data;
int size;
public:
VECTOR(int n);
int &getData(int i); // 取下标所在位置的向量元素
~VECTOR() { delete[] data; };
};
class INDEX
{
int index;
public:
INDEX(int i) { index = i; }
int getIndex() const { return index; }
};
struct SHORTAGE : INDEX
{ // INDEX是父类,SHORTAGE为子类
SHORTAGE(int i) : INDEX(i) {}
using INDEX::getIndex;
};
VECTOR::VECTOR(int n)
{
if (!(data = new int[size = n]))
throw SHORTAGE(0);
};
int &VECTOR::getData(int i)
{
if ((i < 0) || (i >= size))
throw INDEX(i);
return data[i];
};
void main(void)
{
VECTOR v(100);
try
{
v.getData(101) = 30;
}
catch (const SHORTAGE &)
{
printf("SHORTAGE: Shortage of memory!\n");
}
catch (const INDEX &r)
{
printf("INDEX: Bad index is %d\n", r.getIndex());
}
catch (...)
{
printf("ANY: any error caught!\n");
}
}
9.3 函数的异常接口
- 通过异常接口声明的异常都是由该函数引发的、而其自身又不想捕获或处理的异常。
- 异常接口定义的异常出现在函数的参数表后面,用throw列出要引发的异常类型
void func(void) throw(A, B, C);
void func(void) const throw(A, B, C); (成员函数)
void anycept(void); //可引发任何异常
void nonexcept (void) throw( ); //不引发任何异常
void no_except (void) throw(void);//不引发任何异常
void notanyexcept (void) noexcep;//不引发任何异常
异常接口声明
- 可以定义异常接口声明来说明函数可能会抛出什么类型异常或不会抛出异常,这个异常可交给函数的调用者处理。
- 异常接口通常用throw(类型表达式列表)形式定义上述类型表达式可以是任何类型,但不得使用省略参数形式。函数可以抛出同接口类型表达式相同和相容的类型如子类型。
- 可用throw( )表示函数不引发任何异常。
(C++11将上述异常接口声明定义为过时的)。 - 如果参数表后面不出现异常接口,表示该函数可能引发任何类型的异常。
- C++11标准中,在函数参数列表后面加noexcept用于标识该函数不会抛出异常
异常接口声明必须在函数声明和函数定义时都出现。
【例9.4】
#include <iostream>
#include <string>
using namespace std;
struct A
{
string msg = "Exception A";
};
struct B
{
string msg = "Exception B";
};
void f1(); // 可能会抛出异常
void f2() throw(A); // 可能会抛出异常类型A , 过时的,警告错误
void f3() throw(A, B); // 可能会抛出异常类型A,B,过时的,警告错误
void f4() throw(); // 不会抛出异常,过时的, 警告错误
void f5() noexcept; // 不会抛出异常,C++11新标准
void f1()
{
throw A(); // 抛出A类型异常
}
void f2() throw(A)
{
throw B(); // 抛出非A类型异常
}
void f3() throw(A, B)
{
int i;
cin >> i;
if (i > 0)
throw A();
else
throw B();
}
void f4() throw()
{
throw B(); // 声明不抛出异常,但抛出A类型异常
}
void f5() noexcept
{
throw B(); // 声明不抛出异常,抛出A类型异常
}
void g()
{
try
{
// f1(); //没有声明异常接口的(即可能会抛出任何异常),异常会被截获
// f2(); //抛出了和异常接口声明类型不一致的异常,异常不会被截获
// f3(); //异常会被截获
// f4(); //声明不会抛出异常,但实际抛出了异常,异常不会被截获
f5(); // 声明不会抛出异常,但实际抛出了异常,异常不会被截获
}
catch (A &ex)
{
cout << ex.msg;
}
catch (B &ex)
{
cout << ex.msg;
}
}
int main()
{
g();
}
凡是引发了和函数异常声明接口异常不一致的异常,称为不可预料的异常。不可预料的异常不会被捕获,即使catch子句的异常类型与实际出现的异常类型一致。
任何没有被捕获的异常最终由标准库函数terminate来处理。
- 异常接口不是函数原型的一部分,不能通过异常接口来定义和区分重载函数,故其不影响函数内联、重载、缺省和省略参数
- 不引发任何异常的函数引发的异常、引发了未说明的异常称为不可意料的异常。
- 通过set_unexpected过程,可以将不可意料的异常处理过程设置为程序自定义的不可意料的异常处理过程,其设置方法和通过set_terminate过程设置终止处理函数类似,设置后也返回一个指原先的不可意料的异常处理过程的指针。不同的编译提供的设置函数可能不同。
- 函数模板可定义异常接口,类模板及模板类的函数成员定义异常接口(构造函数和析构函数都可以定义异常接口 )
terminate函数
对于未经处理的异常或传播后未经处理的异常,C++的监控系统将调用void terminate( )处理。缺省情况下terminate函数调用abort函数来终止程序。
可以调用set_terminate( )函数,设置自定义的terminate处理函数( terminate handler)。
set_terminate的原型为
void (*set_terminate(void (*)( )) )( ),
返回一个指向原来的terminate处理函数的指针。
void (*set_terminate(void (*)( )) )( )声明了一个函数set_terminate,其参数为函数指针,该指针指向原型为void ( )的函数。 set_terminate也返回一个函数指针,该指针指向原型为void ( )的函数。
【例9.5】
#include <exception>
#include <iostream>
#include <string>
using namespace std;
struct A
{
string msg = "Exception A";
};
struct B
{
string msg = "Exception B";
};
void f5() noexcept
{
throw B(); // 声明不抛出异常,抛出A类型异常
}
void (*old_terminate)();
void new_terminate()
{
cout << "Custom terminate" << endl;
abort();
}
void g()
{
try
{
f5(); // 声明不会抛出异常,但实际抛出了异常,异常不会被截获
}
catch (A &ex)
{
cout << ex.msg;
}
catch (B &ex)
{
cout << ex.msg;
}
}
int main()
{
old_terminate = set_terminate(new_terminate);
g();
// 如果程序运行到这里,说明没有异常
// 恢复终止处理函数set_terminate (old_terminate);
set_terminate(old_terminate);
}
// 输出Custom terminate
对于和旧的函数异常接口声明不一致的异常,实际上先由void unexpected()函数处理,再由void terminate( )来处理。
同样地,可以调用set_unexpected函数来设置自己的unexpected函数。
【例9.6】
#include <exception>
#include <iostream>
#include <string>
using namespace std;
struct A
{
string msg = "Exception A";
};
struct B
{
string msg = "Exception B";
};
void f2() throw(A)
{
throw B(); // 抛出非A类型异常
}
void f5() noexcept
{
throw B(); // 声明不抛出异常,抛出A类型异常
}
void (*old_terminate)();
void (*old_unexpected_handler)();
void new_terminate()
{
cout << "Custom terminate" << endl;
abort();
}
void new_unexpected_handler()
{
cout << "Custom unexpected handler" << endl;
// abort();
}
void g()
{
try
{
f2();
} // 抛出了和异常接口声明类型不一致的异常,异常不会被截获
catch (A &ex)
{
cout << ex.msg;
}
catch (B &ex)
{
cout << ex.msg;
}
}
int main()
{
// g();terminate called after throwing an instance of 'B'
old_unexpected_handler = set_unexpected(new_unexpected_handler);
old_terminate = set_terminate(new_terminate);
g();
// 如果程序运行到这里,说明没有异常
set_unexpected(old_unexpected_handler);
set_terminate(old_terminate);
}
// 输出Custom unexpected handler
//Custom terminate
可以看到,用旧式异常接口声明的函数如果抛出了与声明不一致的异常,不会被捕获,而是先由先由void unexpected()函数处理,再由void terminate( )来处理
对于C++11定义的noexcept函数,如果抛出了异常,只会由terminate处理。
【例9.7】对数组a的若干相邻元素进行累加
#include <iostream>
using namespace std;
// 以下函数sum()可不处理它发出的const char *类型的异常
int sum(int a[], int t, int s, int c) throw (const char *) // 参数t指明数组大小
{ // 以下语句若发出const char *类型的异常,此后的语句不执行
if (s < 0 || s >= t || s + c < 0 || s + c > t)
throw "subscription overflow";
int r = 0, x = 0;
for (x = 0; x < c; x++)
r += a[s + x];
return r;
}
void main()
{
int m[6] = {1, 2, 3, 4, 5, 6};
int r = 0;
try
{
r = sum(m, 6, 3, 4); // 发出异常后try中所有语句都不执行,直接到其catch
r = sum(m, 6, 1, 3); // 不发出异常
}
// 以下const去掉则不能捕获const char *类型的异常,只读指针实参不能传递给可写指针形参e
catch (char *p)
{
cout << p;
} // 不能捕获throw "subscription overflow";
catch (const char *e)
{ // 还能捕获char *类型的异常,可写指针实参可以传递给只读指针形参e
cout << e;
} // 由于throw时未分配内存,故在catch中无须使用delete e
}
- noexcept可以表示throw()或throw(void)。
- noexcept一般用在移动构造函数,析构函数、移动赋值运算符函数等函数后面。
- 如果移动构造函数和移动赋值运算符还要申请资源,则难免发生异常,此时不应将noexcept放在这些函数的参数后面。
- 保留字noexcept和throw( )可以出现在任何函数的后面,包括constexpr函数和Lambda表达式的参数表后面。但 throw(除void外的类型参数)不应出现在constexpr函数的参数表后面,并且constexpr函数也不能抛出异常,否则不能优化生成常量表达式。
9. 4 异常类型
- C++提供了一个标准的异常类型exception,以作为标准类库引发的异常类型的基类,exception等异常由标准名字空间std提供。
- exception的函数成员不再引发任何异常。
- 函数成员what( )返回一个只读字符串,该字符串的值没有被构造函数初始化,因此必须在派生类中重新定义函数成员what( )。
- 异常类exception提供了处理异常的标准框架,应用程序自定义的异常对象应当自exception继承。
- 在catch有父子关系的多个异常对象时,应注意catch顺序。
- 如果是通过new产生的指针类型的异常,在catch处理过程捕获后,通常应使用合适的delete释放内存,否则可能造成内存泄漏。
- 如果继续传播指针类型的异常,则可以不使用delete。
- 从最内层被调函数抛出异常到外层调用函数的catch处理过程捕获异常,由此形成的函数调用链所有局部对象都会被自动析构,因此使用异常处理机制能在一定程度上防止内存泄漏。但是,调用链中的指针通过new创建的异常对象不会自动释放。
【例9.8】局部对象的析构过程
#include <exception>
#include <iostream>
using namespace std;
class EPISTLE : exception
{ // 定义异常对象的类型
public:
EPISTLE(const char *s) : exception(s) { cout << "Construct: " << s; }
~EPISTLE() noexcept { cout << "Destruct: " << exception::what(); };
const char *what() const throw() { return exception::what(); };
};
void h()
{
EPISTLE h("I am in h( )\n");
throw new EPISTLE("I have throw an exception\n");
}
void g()
{
EPISTLE g("I am in g( )\n");
h();
}
void f()
{
EPISTLE f("I am in f( )\n");
g();
}
void main(void)
{
try
{
f();
}
catch (const EPISTLE *m)
{
cout << m->what();
delete m;
}
}
main()->f()->g()->h()->h抛出异常(指针)->局部对象h、g、f依次析构->main捕获异常并delete
9.6 断言
- 函数assert(int)在assert.h中定义。
- 断言(assert)是一个带有整型参数的用于调试程序的函数,如果实参的值为真则程序继续执行。
- 否则,将输出断言表达式、断言所在代码文件名称以及断言所在程序的行号,然后调用abort()终止程序的执行。
- 断言输出的代码文件名称包含路径(编译时值),运行时程序拷到其它目录也还是按原有路径输出代码文件名称。assert()在运行时检查断言。
5.** 保留字static_assert定义的断言在编译时检查,为真时不终止编译运行**。
【例9.9】断言的用法
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
class SET
{
int *elem, used, card;
public:
SET(int card);
virtual int has(int) const;
virtual SET &push(int); // 插入一个元素
virtual ~SET() noexcept
{
if (elem)
{
delete elem;
elem = 0;
}
};
};
SET::SET(int c)
{
card = c;
elem = new int[c];
assert(elem); // 当elem非空时继续执行
used = 0;
}
int SET::has(int v) const
{
for (int k = 0; k < used; k++)
if (elem[k] == v)
return 1;
return 0;
}
SET &SET::push(int v)
{
assert(!has(v)); // 当集合中无元素v时继续执行
assert(used < card); // 当集合还能增加元素时继续执行
elem[used++] = v;
return *this;
}
int main(void)
{
static_assert(sizeof(int) == 4); // VS2019采用x86编译模式时为真,不终止编译运行
SET s(2); // 定义集合只能存放两个元素
s.push(1).push(2);// 存放第1,2个元素
s.push(3); // 因不能存放元素3,断言为假,程序被终止
printf("OK\n"); // SET s(3);
}
// 输出Expression: used < card
第十章 多继承类和虚基类
10.1 多继承
- 单继承是多继承的一种特例,多继承具有更强的类型表达能力。
- 多继承派生类有多个基类或虚基类。同一个类不能多次作为某个派生类的直接基类,但可多次作为一个派生类的间接基类(同编译程序相关)。
class QUEUE: STACK, STACK{ }; //错误, 出现两次 - 多继承派生类继承所有基类的数据成员和函数成员。
- 多继承派生类在继承基类时,各基类可采用不同的派生控制符。
- 基类之间的成员可能同名,基类与派生类的成员也可能同名。在出现同名时,如面向对象的作用域不能解析,可使用基类类名加作用域运算符::来指明要访问基类的成员。
- Java、C#、SmallTalk等单继承语言在描述多继承的对象时,常常通过对象成员委托(代理)实现多继承。
class A{ public: void f( ) {}};
class B{ public: void g( ) {}};
//如果需要实现一个类,同时具有类A和类B的行为,但又不能
//多继承怎么办(如JAVA)?
//采用代理模式,继承一个类,将另外一个类的对象作为数据成员
class C: public A{
B b; //B类行为的代理
public:
void g( ) { b.g( ): } //定义一个同名的g函数,但其功能
//委托对象b完成(通过调用b.g()),因此 //C::g的行为与B::g完全一致
//A::f被C继承
};
//这样C就具有A的行为f和B的行为g,达到了多重继承的效果
8.委托代理在多数情况下能够满足需要,但当对象成员和基类物理上是同一个基类时(存在一个共同的基类),就可能对同一个物理对象重复初始化 (可能是危险的和不必要的) 。
9. 两栖机车AmphibiousVehicle继承基类陆用机车LandVehicle,委托对象成员水上机车WaterVehicle完成水上功能。两栖机车可能对同一个物理对象Engine初始化(启动)两次。
class Engine{ /*...*/};
class LandVehicle: Engine{/*...*/};
class WaterVehicle: Engine{/*...*/};
class AmphibiousVehicle: LandVehicle{WaterVehicle wv; };
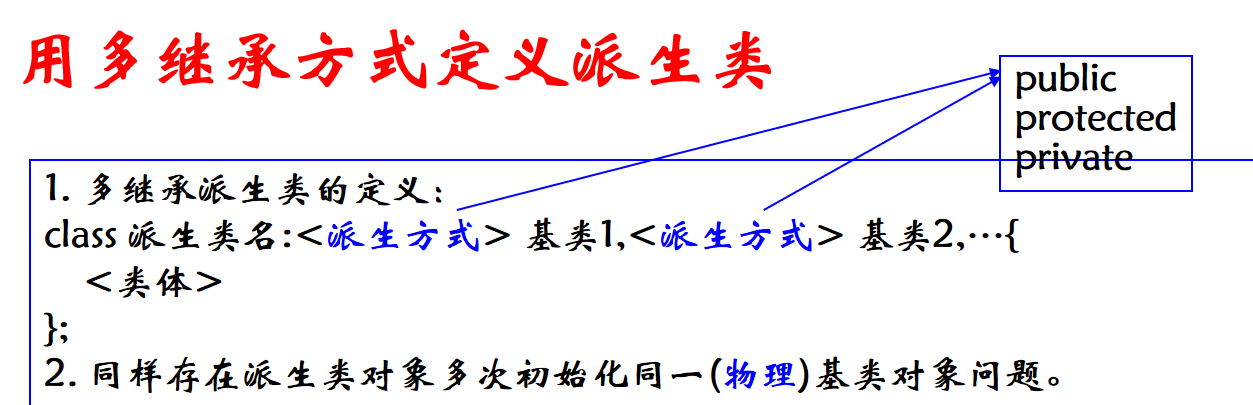
-
C++提供多继承机制描述两栖机车AmphibiousVehicle:
class AmphibiousVehicle:LandVehicle, WaterVehicle { }; -
仅靠多继承仍然不能解决同一个物理对象初始化两次的问题。
-
可以采用全局变量、静态数据成员做标记,解决同一个物理对象初始化两次的问题;此外,还需要解决同一物理对象两次析构问题,这样会使程序的逻辑变得复杂化。
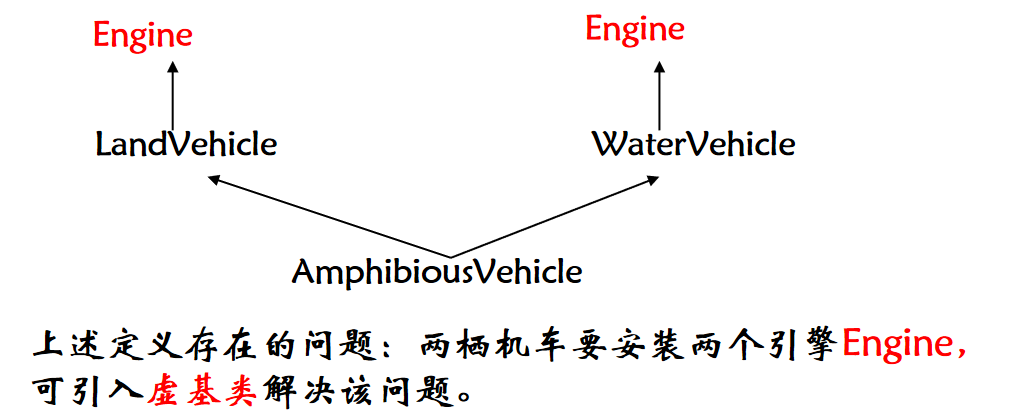
-
虚基类用virtual声明,可把多个逻辑虚基类对象映射成同一个物理虚基类对象。
-
映射成的这个物理虚基类对象尽可能早的构造、尽可能晚的析构,且构造和析构都只进行一次。
-
若虚基类的构造函数都有参数,必须在派生类构造函数的初始化列表中列出虚基类的构造实参的值。
class Engine{ /*...*/ };
class LandVehicle: virtual public Engine{ /*...*/ };
class WaterVehicle: public virtual Engine{ /*...*/ };
class AmphibiousVehicle: LandVehicle, WaterVehicle{ };
- 同一棵派生树中的同名虚基类,共享同一个存储空间;其构造和析构仅执行1次,且构造尽可能最早执行,而析构尽可能最晚执行。由派生类(根) 、基类和虚基类构成一个派生树的节点,而对象成员将成为一棵新派生树的根。
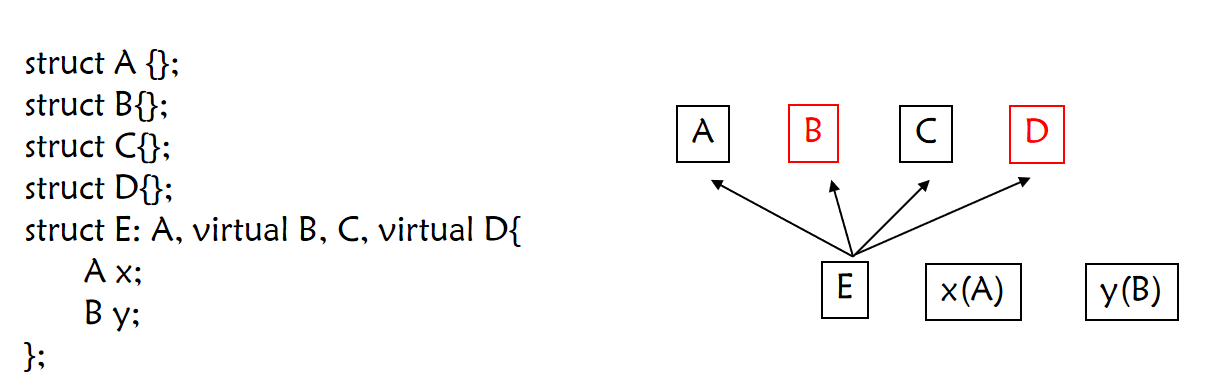
【例10.1】
#include <iostream>
#include <climits>
#include <algorithm>
#include <vector>
using namespace std;
class Engine {
int power;
public:
Engine(int p) : power(p) { }
};
class LandVehicle : virtual public Engine {
int speed;
public:
// 如从AmphibiousVehicle调LandVehicle, 则此处不会调用Engine(p)
LandVehicle(int s, int p) : Engine(p), speed(s) { } // 必须调用Engine(p)
};
class WaterVehicle : public virtual Engine {
int speed;
public:
// 如从AmphibiousVehicle调WaterVehicle, 则此处不会调用Engine(p)
WaterVehicle(int s, int p) : Engine(p), speed(s) { } // 必须调用Engine(p)
};
struct AmphibiousVehicle : LandVehicle, WaterVehicle {
AmphibiousVehicle(int s1, int s2, int p) :
// 先构造虚基类再基类
WaterVehicle(s2, p), LandVehicle(s1, p), Engine(p) { } // 必须调用Engine(p)
// 在整个AmphibiousVehicle派生树中,Engine(p) 只执行1次
}; // 初始化顺序:Engine(p), LandVehicle(s1, p), WaterVehicle(s2, p)
10.2 虚基类
- 虚拟基类特殊的初始化语义
- 在非虚拟派生中,派生类只能显式初始化其直接基类
- 而虚拟基类的初始化则成了每一级派生类的责任
【例10.2】
#include <iostream>
#include <climits>
#include <algorithm>
#include <vector>
using namespace std;
class A {
string msg;
public:
A(string s) :msg(s) { cout << "Constructor:" << msg << endl; }
};
class B :virtual public A {
int b;
public:
B(string s, int i) :A(s), b(i) {}
};
class C :virtual public A {
int c;
public:
C(string s, int j) :A(s), c(j) {}
};
class D :public B, public C {
int d;
public:
D(string s, int x, int y, int z) :A(s), B(s, x), C(s, y), d(z) {}
};
void main(int argc, char* argv[])
{
B b("B", 1); //B为最终派生类,由它调用虚基类A的构造函数
C c("C", 2); //C为最终派生类,由它调用虚基类A的构造函数
D d("D", 1, 2, 3); //D为最终派生类,由它调用虚基类A的构造函数,
//B和C的构造函数不再调虚基类A的构造函数
}
-
虚基类和基类同名必然会导致二义性访问,编译程序会对这种二义性访问报错。当出现这种情况时,可用作用域运算符限定要访问的成员。
-
有虚基类的派生类构造函数不能使用constexpr定义
-
当派生类有多个基类或虚基类时,不同基类或虚基类的成员之间可能出现同名;派生类和基类或虚基类的成员之间也可能出现同名。
-
出现上述同名问题时,必须通过面向对象的作用域解析,或者用类名加作用域运算符::指定要访问的成员,否则就会引起二义性问题。
-
当派生类成员和基类成员同名时,优先访问作用域小的成员,即优先访问派生类的成员。当派生类数据成员和派生类函数成员的参数同名时,在函数成员内优先访问函数参数。
-
虚基类和基类同名必然会导致二义性访问,编译程序会对这种二义性访问报错。当出现这种情况时,可用作用域运算符限定要访问的成员。
-
有虚基类的派生类构造函数不能使用constexpr定义
【例10.3】
#include <iostream>
#include <climits>
#include <algorithm>
#include <vector>
using namespace std;
struct A {
int a, b, c, d;
};
struct B {
int b, c;
protected:
int e;
};
class C : public A, public B {
int a;
public:
int b; int f(int c);
} x;
int C::f(int c) {
int i = a; //访问C::a
i = A::a;
i = b + c + d; //访问C::b和参数c
i = A::b + B::b; //访问基类成员
return A::c;
}
void main(void) {
int i = x.A::a;
i = x.a; //错,私有的
i = x.b; //访问C::b
i = x.A::b + x.B::b;
i = x.A::c;
}
C的成员有:
private:
int C::a;
protected:
int B::e;
public:
int A::a, A::b,A::c,A::d;
int B::b,B::c;
int C::b, C::f()
【例10.4】
struct A {
void f() { cout << "A\n"; }
};
struct B :virtual A {
void f() { cout << "B\n"; }
};
struct C :B {};
struct D :C, virtual A {};
void main(int argc, char* argv[])
{
D d;
B* pb = &d; //B和D之间为父子关系
D* pd = &d;
pb->f(); //调用B::f(). B::f()被优先访问
pd->f(); //调用B::f().pb为D类型指针,D分别从A和B继承了函数成员f,但优先访问基类B的f(基类比虚基类作用域小)
}
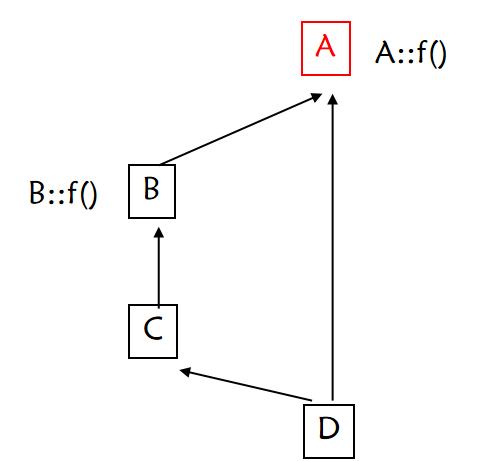
struct A{
void f() { cout << "A\n"; }
};
struct B:A{
void f() { cout << "B\n"; }
};
struct C:B{};
struct D:C,virtual A {};
void main(int argc, char* argv[])
{
D d;
B *pb = &d; //B和D之间为父子关系
D *pd = &d;
pb->f(); //OK,优先访问B::f()
pd->f(); //有二义性,f可能是基类A的,可能是基类B的,从
//这里可以看出,对于D而言,A和B作用域大小一样,
//都是基类作用域(左边分支)
//改成pd->A::f();或pd->B::f();
}

多重继承的内存布局(Memory Layout)
- 一个类不能多次成为一个派生类的直接基类(即使是虚基类)
- 否则会报编译错误
- 一个类可以多次成为一个派生类的间接基类(即使不是虚基类)
- 一个类(A)可以同时成为一个派生类的直接基类和间接基类,但该类(A)作为直接基类时必须是虚基类。
- 否则会报警告错误
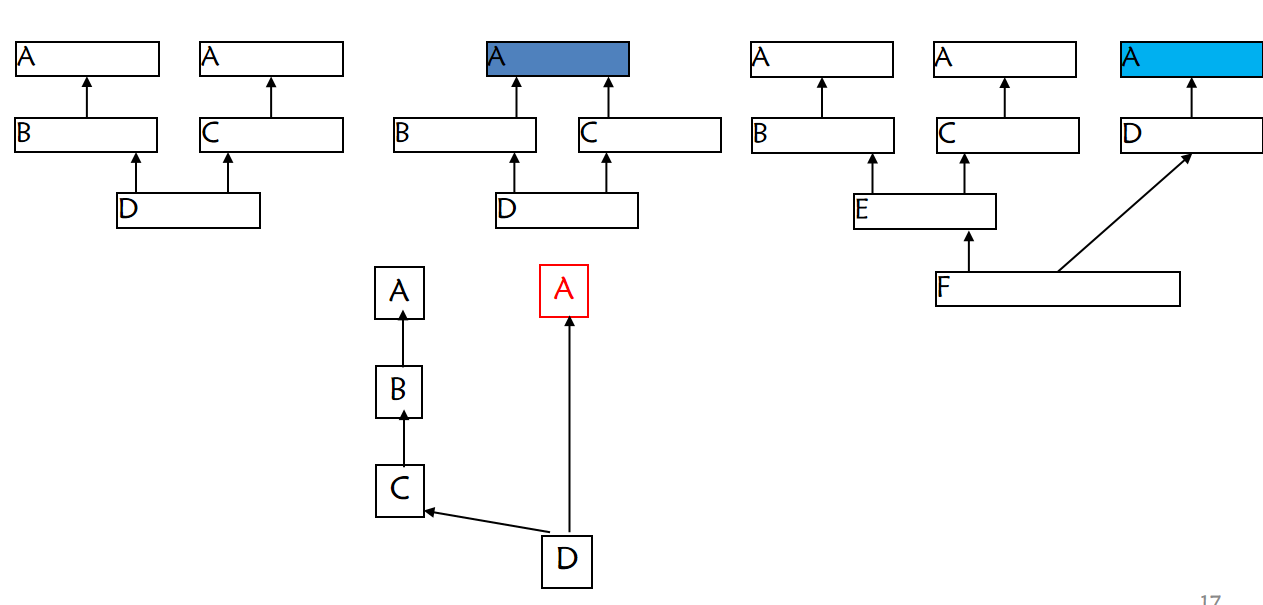
10.4 构造与析构
- 析构和构造的顺序相反,派生类对象的构造顺序:
(1)按定义顺序构造倒派生树中所有虚基类;
(2)按定义顺序构造派生类的所有直接基类;
(3)按定义顺序构造 (初始化)派生类的所有数据成员,包括对象成员、const成员和引用成员;
(4)执行派生类自身的构造函数体*。 - 如果构造中虚基类、基类、对象成员、const及引用成员又是派生类,则派生类对象重复上述构造过程,但同名虚基类对象在同一棵派生树中仅构造一次。
由派生类 (根)、基类和虚基类构成一个派生树的节点,而对象成员将成为一棵新派生树的根。
多继承派生类的构造过程
【例10.5】
struct A {
A() { cout << 'A'; }
};
struct B {
B() { cout << 'B'; }
};
struct C {
int a; int& b;
const int c;
C(char d) : c(d), a(d), b(a) { cout << d; }
};
struct D {
D() { cout << 'D'; }
};
struct E : A, virtual B, C, virtual D {
A x, y;
B z;
E() :z(), y(), C('C')
{
cout << 'E';
}
};
int main(void)
{
E e;
}
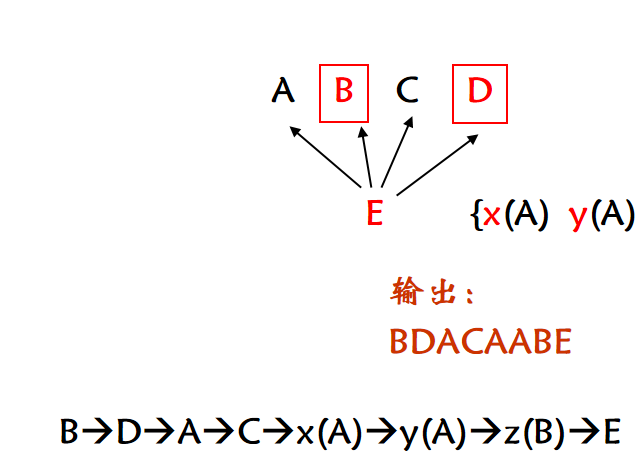
【例10.6】复杂派生类构造过程
struct A { A() { cout << 'A'; } };
struct B { const A a; B() { cout << 'B'; } }; //a作为新根 B():a(){}
struct C : virtual A { C() { cout << 'C'; } };
struct D { D() { cout << 'D'; } };
struct E : A { E() { cout << 'E'; } }; //等价E():A(){}
struct F : B, virtual C { F() { cout << 'F'; } };
struct G : B { G() : B() { cout << 'G'; } };
struct H : virtual C, virtual D { H() { cout << 'H'; } };
struct I : E, F, virtual G, H {
E e; F f; //对象成员e、f作为新根
I() { cout << 'I'; }
};
int main(void) { I i; }
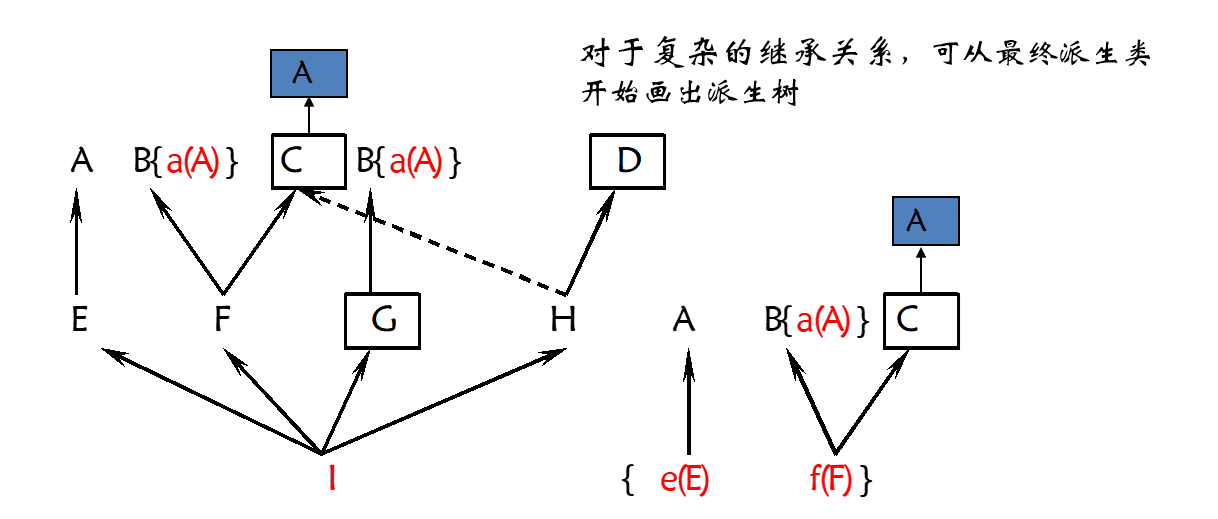
首先确定四个虚基类的构造顺序。从派生类I倒推:
要构造I,必须按定义顺序依次构造E、F、G、H。
1:E没有虚基类不予考虑;
2:构造F:按派生顺序依次构造虚基类A、C,对应输出为AC;
3:构造虚基类G:先构造G的基类B。构造类B必须先构造A类成员a,再调用B的构造函数体。因此对应输出为ABG;
4:构造H,必须先构造虚基类D,对应输出为D。
因此,四个虚基类构造完毕后,输出为ACABGD
按定义顺序自左至右、自下而上地构造倒派生树中所有虚基类
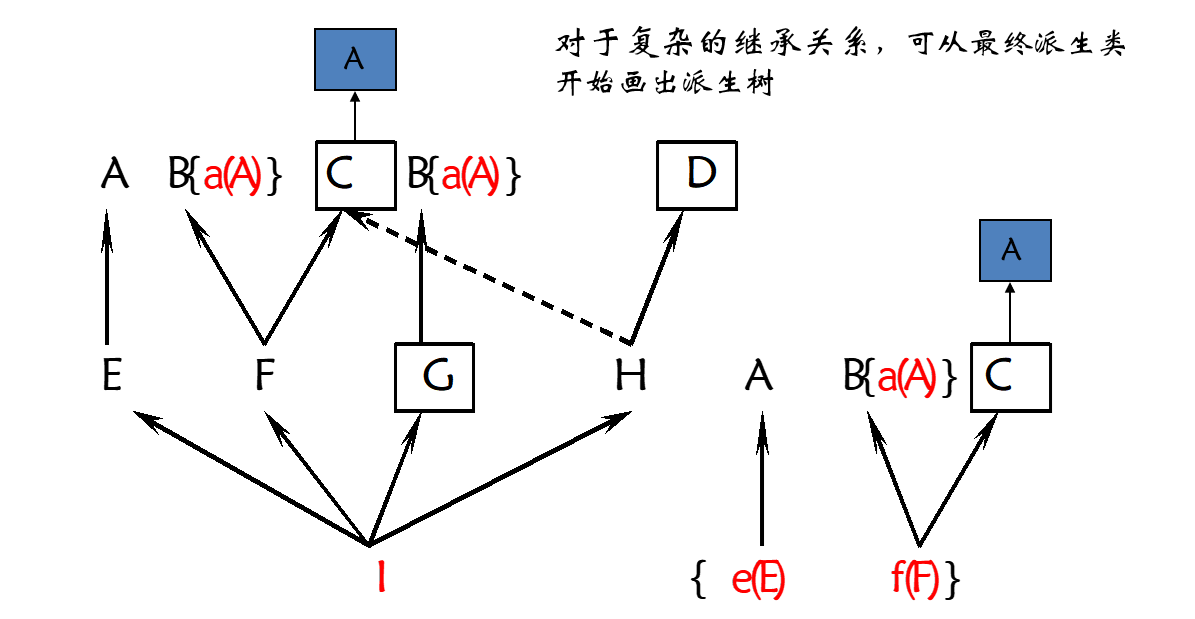
接着构造I的对象成员
1:构造e (E): 必须先构造A,因此对应输出为AE
2:构造f (F):首先按派生顺序依次构造虚基类A、C;再构造B(先构造B的对象成员a,再调用B的构造函数体);最后构造F。因此对应输出为ACABF
因此当I的对象成员构造完毕,输出为AE ACABF。
最后调用I自己的构造函数,输出I
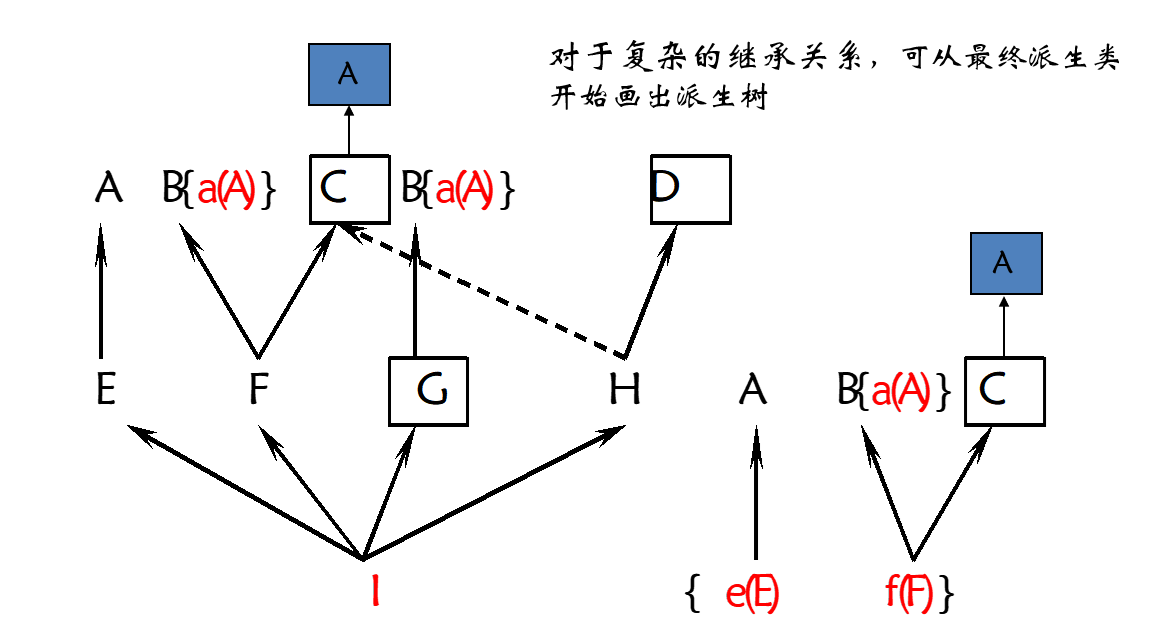

第十一章 运算符重载
11.1 运算符概述
- 纯单目运算符,只能有一个操作数,包括:!、~、sizeof、new、delete 等
- 纯双目运算符,只能有两个操作数,包括:[ ]、->、%、= 等
- 三目运算符,有三个操作数,如“? :”
- 既是单目又是双目的运算符,包括:+、-、&、* 等
- 多目运算符,如函数参数表 “( )”。
- 左值运算符是运算结果为左值的运算符,其表达式可出现在等号左边,如前置++、--以及赋值运算=、+=、*=和&=等。右值运算符是运算结果为右值的运算符,如+、-、>>、 %、后置++、--等。
- 某些运算符要求第一个操作数为左值,如 ++、-- 、=、+=、&=等。
例1:传统左值运算符的用法
#include <stdio.h>
void main(int argc, char *argv[ ])
{ int x=0;
++x; //++x的结果为左值(可出现在等号左边)
++ ++x; //++x仍为左值,故可连续运算(作为第二个++的操作数),x=3
--x=10; //--x仍为左值,故可再次赋值,x=10
(x=5)=12; //x=5仍为左值,故可再次赋值,x=12
(x+=5)=7; //x+=5仍为左值,故可再次赋值,x=7
printf("%d %d", x, x++); //( )可看作任意目运算符
}//(x--)++是错的:x--的结果为右值,而++要求一个左值
运算符重载工作机制
运算符重载就是函数重载,编译器在编译时确定调用哪个运算符重载函数
class A {
public:
int i;
A (int x): i(x) {}
//重载双目运算符+,使”+”能支持二个A类型对象相加
//二个A类型对象相加的语义由operator+函数负责实现
//由于双目运算符+要求2个操作数,因此operator+也要求2个操作数
//如果用A的普通成员函数(实例函数)实现,则只需要一个显式参数(因为隐含的//this指针指//向了第一个操作数,即出现在+左边的操作数)
int operator+( A a) { return this->i + a.i;}
};
//用全局函数重载双目“-”,这时要显式指定二个参数(a1为第一个操作数)
int operator-(A a1, A a2) { return a1.i – a2.i;}
- C++预定义了简单类型的运算符重载,如3+5、3.2+5.3分别表示整数和浮点加法。故C++规定运算符重载必须针对类的对象(复杂类型),即重载时至少有一个参数代表对象(类型如A、const A、A&、const A&、volatile A等) 。(注意A*,A[]不是复杂类型,是简单类型:指针)
- C++用operator加运算符进行运算符重载。如果用类的普通成员函数重载运算符,this隐含参数代表第一个操作数对象。
运算符分类:
- 不能重载的:sizeof . .* :: ?:
- 只能重载为类的普通成员函数的:=、–>、 ( ) 、[ ]
- 不能重载为类的普通成员函数的:new、delete
- 其他运算符:不能重载为类的静态成员函数,但可以重载为类的普通成员函数和全局函数。
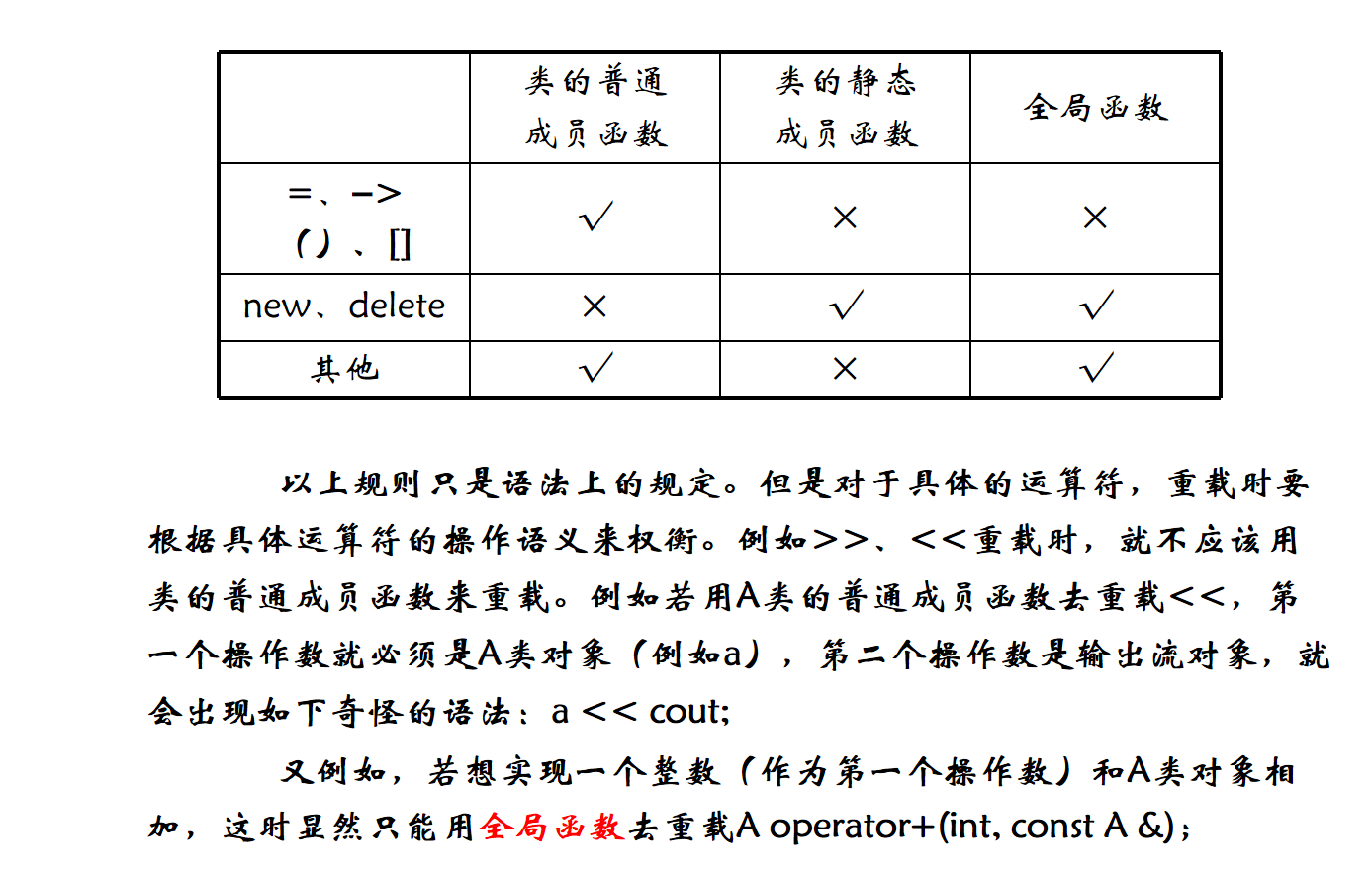
例2:
class A;
int operator= (int, A&); //错误,=不能重载为全局函数
A& operator += (A&s, A&r) //注意,+= 可以重载为全局函数,
{ return s; }
//注意这时参数不能写A s,因此时不知A的字节数。而A *r可以。
int operator+(A[6],int); //不允许,A[6]和A *为普通类型
int operator+(A *, int); //不允许,A[6]和A *为普通类型
class A{
friend int operator=(int, A&); //错误, 不能为全局函数友元
static int operator ( ) (A&, int); //错误, 不能为静态成员重载函数调用()
static int operator+ (A&, int); //错误, 不能为静态成员
friend A& operator+=(A&, A&); //正确,+=可以用全局函数重载
A& operator ++( ); //隐含参数this代表一个对象
};
//注意重载左值运算符如=、+=、…时最好返回非const左值引用,凡是左值参数最好都用引用(非const),否则改变了运算符的性质
- 若运算符为左值运算符,则重载后运算符函数最好返回非只读左值引用类型(左值)。当运算符要求第一个参数为左值时,不能使用const说明第一个参数(含this),例如++、--、=、+=等的第一个参数。
- 重载运算符函数可以声明为类的友元;重载运算符的普通成员函数也可定义为虚函数;重载运算符的非成员函数被视为普通函数。
- 重载运算符函数一般不能缺省参数,只有任意目的运算符( )省略参数才有意义。
- 重载不改变运算符的优先级和结合性。
- 重载一般也不改变运算符的操作数个数。特殊的运算符->、++、-- (区分前置和后置)除外。
例3:
#include<iostream>
using namespace std;
class A {
int x;
public:
int getx()const { return x; } //隐含参数this的类型为const A*const this,可代表对象
A(int x) { A::x = x; } //隐含参数this的类型为A*const this
};
int operator+(const A& x, int y) //定义非成员函数(全局函数重载+):参数const A&x代表一个对象
{
return x.getx() + y;
}
int operator+(int y, const A& x) //定义非成员函数(全局函数重载+) :参数const A&x代表一个对象
{
return x.getx() + y;
}
//不能声明int operator+(A[6],int);//A[6]不是单个对象
//不能声明int operator+(A*, int);//A*是对象指针,属于简单类型,不能用于代表对象
int main()
{
A a(6); //调用A(int)时,实参&a传递给隐含形参this
cout << "a+7=" << a + 7 << "\n"; //调用int operator+(const A&, int)
cout << "a+7=" << operator+(a, 7) << "\n"; //调用int operator+(const A&, int)
cout << "8+a=" << operator+(8, a) << "\n"; //调用int operator+(int, const A& )
cout << "8+a=" << 8 + a << "\n"; //调用int operator+(int, const A&,)
return 0;
}
例4:
#include<iostream>
using namespace std;
class A {
int x, y;
public:
A(int x, int y) { A::x = x; A::y = y; }
A& operator=(const A& m) //取m送给this指向的可修改对象
{
x = m.x; y = m.y; return *this;
} //返回非const引用,赋值后还可赋值
friend A operator-(const A&); //全局函数重载, 返回右值,单目-
friend A operator+(const A&, const A&); //const不能修改两个加数
void printA()
{
cout << x << " " << y << endl;
}
} a(2, 3), b(4, 5), c(1, 9);
A operator-(const A& a) //重载为单目运算符
{
return A(-a.x, -a.y);
} //返回右值(临时变量)
A operator+(const A& x, const A& y) { //返回右值
return A(x.x + y.x, x.y + y.y); //A(x.x+y.x, x.y+y.y)为类A的常量
}
void main(void)
{
(c = a + b) = b + b; /*等价于c=a+b, c=b+b, (c=a+b)返回的是c的引用*/
c.printA();//8 10
c = -b;
c.printA();// -4 - 5
}
11.2 运算符参数
-
重载函数种类不同,参数表列出的参数个数也不同。
i. 重载为普通函数(全局函数):参数个数=运算符目数
ii. 重载为类的普通成员函数(实例函数):参数个数=运算符目数 - 1 (即this指针)
iii. 重载为类的静态成员函数:参数个数 = 运算符目数(没有this指针) -
注意有的运算符既为单目又为双目,如*, +, -等。
-
特殊运算符不满足上述关系:->双目重载为单目,前置++和--重载为单目,后置++和--重载为双目(实际上这个参数不会被使用,但是它可以区分前置和后置重载版本)、函数( )可重载为任意目。
-
( )表示强制类型转换时为单参数;表示函数时可为任意个参数。
-
运算符++和--都会改变当前对象的值,重载时最好将参数定义为非const左值引用类型(左值),左值形参在函数返回时能使实参带出执行结果,非const保证可以改变操作数。前置运算是先运算再取值,后置运算是先取值再运算。
-
后置运算应重载为返回右值(返回类型为值类型)的双目运算符函数:
i. 如果重载为类的普通函数成员,则该函数只需定义一个int类型的参数(已包含一个不用const修饰的this参数);
ii. 如果重载为全局函数,则最好声明非const左值引用类型(原因同上)和int类型的两个参数(无this参数)。 -
前置运算应重载为返回非const左值引用的单目运算符函数:
i. 前置运算结果应为非const左值,其返回类型应该定义为非只读类型的左值引用类型;左值运算结果可继续++或--运算。
ii. 如果重载为全局函数,则最好声明非const左值引用类型一个参数 (无this参数)。
注:
- 前置++,--要返回非const左值引用,否则不能出现在=号左边,改变了运算符的性质
- 前置++,--和后置++,--参数要为非const左值引用,否则无法将结果带回,也改变了运算符的性质。因为++,--(不管是前置还是后置)都要求改变操作数自身的值。如果参数为值参,会导致传值调用,函数里改变的是形参,实参不会改变。
- 上述二个规则不是语法规定,而是语义上的规定。
例1:后置++重载
struct A{
static int x;
int y;
public:
const A operator ++(int){
return A(x++, y++);
}
A(int i, int j){ x=i; y=j;}
};
int A::x = 23;
int main(){
A a(4,3);
A b = a++; //b.x, b.y ,a.x, a.y=?
return 0;
}
答案为:a(4,4), b(4,3)
return A(x++,y++)等价于
1:先取x,y的值
temp1 = x; //4
temp2 = y; //3
2: x加1,y加1,对象a变为a(5,4)
3:构造临时对象tempo
tempo = A(temp1,temp2); //A(4,3)
x为静态成员,使得a变为a(4,4)
4:返回tempo给b,b为b(4,3)
例2:重载为单目运算的纯双目运算符->
下面例子说明->运算符重载后左操作数不是对象指针,右操作数也不是对象成员
struct A{ int a; A (int x){ a=x; } };
class B{
A x;
public:
A *operator-> ( ) { return &x; }; //只有this, 故重载为单目
B (int v): x (v) { }
}b (5) ;
void main (void){
int i=b->a; //等价于下一条语句,i=b.x.a=5
i=b.operator -> ( ) ->a; //i=b.x.a=5
}
当返回指针后,则内置的成员访问操作符->的语义被应用在返回值上
例3:
class POINT{
int x,y;
public:
POINT(int x,int y):x(x),y(y){}
POINT operator-() { return POINT(-x,-y); } //单目-
POINT operator-(POINT p) { return POINT(x-p.x,y-p.y);}//双目-
POINT operator+(POINT p) { return POINT(x+p.x,y+p.y); }//双目+
friend POINT operator+(POINT p) { return POINT(p.x,p.y);}//单目+
friend POINT operator+(POINT p1,POINT p2) { //双目+
return POINT(p1.x+p2.x,p1.y+p2.y);
}
};
void main(int argc, char* argv[]){
POINT p1(1,2),p2(3,4);
POINT p3=-p1; //调 POINT operator-()
POINT p4=p1-p2; //调 POINT operator-(POINT p)
POINT p5=p1.operator -(p2); //调 POINT operator-(POINT p)
POINT p6 = +p1; //调 friend POINT operator+(POINT p)
POINT p7=operator+(p1,p2); // friend POINT operator+(POINT p1,POINT p2)
POINT p8 = p1.operator +(p2); //调 POINT operator+(POINT p)
POINT p9 = p1+p2; //错误,无法确定是调用友元还是函数成员
}
重载函数调用操作符()
为多目运算符
int sum(int x, int y) { return x + y;}
int s = sum (1,2); //三个操作数sum, 1, 2
//第一个操作数为函数名,这里把函数名看做函数对象
( )只能通过类的普通成员函数重载,这意味着( )第一个操作数必须是this指针指向的类对象,这样的对象称为函数对象。
class AbsInt{
public:
//语法:returnType operator( ) (参数列表)
//调用:objectofAbsInt(实参),类AbsInt的对象称为函数对象
int operator()( int val) { return val > 0? val:-val; }
} absInt;
int i = absInt(-1); //函数对象可以作为函数的参数, 这意味着我们可以将函数当做对象传递. 在模板编程里广泛使用。在C+11里,还可以用lamda表达式
函数指针也可以作为函数的参数,但函数指针主要的缺点是:被函数指针指向的函数是无法内联的。而函数对象则没这个问题。
11.3 赋值与调用
-
默认情况下,编译器为类A默认生成6个实例成员函数:A( )、A(A&&)、A(const A&) 、~A( ) 、A&operator=(const A&)、A& operator=(A&&)
-
如果类自定义上述函数,则优先调用自定义的函数; 若函数体用=default取代,表示启用上述函数;若用=delete取代表示删除上述函数,且不得再定义同型函数,即禁止使用。
-
默认赋值运算函数实现数据成员的浅拷贝赋值,如果普通数据成员为指针或引用类型且指向了一块动态分配的内存,则不复制指针所指存储单元的内容。若类不包含上述普通数据成员,浅拷贝赋值不存在问题。
-
如果函数参数为值参对象,当实参传值给形参时,若类A没有自定义拷贝构造函数,则值参传递也通过浅拷贝构造实现(调用编译器提供的默认拷贝构造函数)。
例1:赋值与调用
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <vector>
#include<cstring>
using namespace std;
class STRING {
char* s;
public:
virtual char& operator[ ] (int x) { return s[x]; } //[]重载要返回非const引用
STRING(const char* c) { strcpy(s = new char[strlen(c) + 1], c); }
STRING(const STRING& c) //拷贝构造函数
{
strcpy(s = new char[strlen(c.s) + 1], c.s);
}
virtual STRING operator+(const STRING&)const; //不改参数
virtual STRING& operator= (const STRING&);
//<<必须用全局函数重载,声明为友元是为了方便访问私有成员
friend ostream& operator<<(ostream& os, const STRING& s);
virtual STRING& operator+=(const STRING& s)
{
return *this = *this + s;
} //调用重载的operator+, =
virtual ~STRING() { if (s) { delete[]s; s = 0; } }
} s1("S1"), s2 = "S2", s3("S3");
STRING STRING::operator+(const STRING& c)const {
char* t = new char[strlen(s) + strlen(c.s) + 1];
STRING r(strcat(strcpy(t, s), c.s)); //strncpy、strcat返回t
delete []t;
return r;
}
STRING& STRING::operator=(const STRING& rhs) {
char* t = new char[strlen(rhs.s) + 1]; strcpy(t, rhs.s);
delete [] this->s; //一定要在char *t指向的内存分配成功后再delete[] this->s
this->s = t;
return *this;
}
ostream& operator<<(ostream& os, const STRING& s) {
os << s.s; return os;
}
void main(void) {
s1 = s1 + s2;
s1 += s3;
s3[0] = 'T'; //调用char &operator[ ] (int x)
cout << s1 << s2 << s3 << endl;
}
- 对于类T,防止内存泄露要注意以下几点:
(1)应定义“T(const T &)”形式的深拷贝构造函数;
(2)应定义“T(T &&) noexcept”形式的移动构造函数;
(3)应定义“virtual T &operator=(const T &)”形式的深拷贝赋值运算符;
(4)应定义“virtual T &operator=(T &&) noexcept”形式的移动赋值运算符;
(5)应定义“virtual ~T( )”形式的虚析构函数;
(6)在定义引用“T &p=*new T( )”后,要用“delete &p”删除对象;
(7)在定义指针“T *p=new T( )”后,要用“delete p”删除对象;
(8)对于形如“T a; T&&f( );”的定义,不要使用“T &&b=f( );”之类的声明和“a=f( );”
(9)不要随便使用exit和abort退出程序。
(10)最好使用异常处理机制。
(11)注意delete p和delete [ ]p
例2:对于形如“T a; T&&f( );”的定义,不要使用“T &&b=f( );和“a=f( );”之类的声明
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <vector>
#include<cstring>
using namespace std;
class A {
private:
int size; int* p;
public:
A() :size(1), p(new int[size]) { cout << "Default Constructor, size = " << size << endl; }
A(int s) :size(s > 0 ? s : 1), p(new int[size]) { cout << "Constructor,size = " << size << endl; }
virtual ~A() {
cout << "Deconstructor,size = " << size << endl; if (p) { delete[] p; p = 0; size = 0; }
}
int get_size() { return size; };
A(const A& old) :size(old.size), p(new int[size]) { //拷贝构造
for (int i = 0; i < size; i++) { p[i] = old.p[i]; } cout << "Copy constructor,size = " << size << endl;
}
A(A&& old) :size(old.size), p(old.p) { //移动构造
old.p = 0; cout << "Move constructor,size = " << size << endl;
}
A& operator=(A&& rhs) {
if (this == &rhs) return *this;
int* t = this->p; this->p = rhs.p; this->size = rhs.size; rhs.p = 0; rhs.size = 0;
if (t) delete t;
cout << "Move =,size = " << size << endl;
}
};
//返回右值引用的函数要非常小心,特别是引用了即将出栈的临时对象
A&& f() { return A(100); }
A&& g() { return A(200); }
int main() {
A a;
// A && rr1 = f(); //右值引用引用了一个已经出栈的对象
// cout << rr1.get_size() << endl; //会输出不确定值,因为局部对象出栈
// A && rr2 = g();
// cout << rr2.get_size() << endl; //会输出不确定值,因为局部对象出栈
cout << "-------------------" << endl;
A c = A(100); //在C++11下,调用移动构造;但是在C++17下,被编译器优化为调用构造函数A(int), 等价于A c(100);
A d = a; //调用拷贝构造
cout << "-------------------" << endl;
//f()返回右值引用,然后用该右值引用引用的对象去构造对象b
// 应该调用移动构造,但是该右值引用引用的对象已经在f()返回后出栈,因此出错
// A b = f();
//A &r = f(); //编译错误,f()返回的右值
//和A b = f();存在同样的问题: f()返回右值引用,然后将该右值引用引用的对象移动赋值给a
//应该调用移动赋值,但是但是该右值引用引用的对象已经在f()返回后出栈,因此出错
a = f();
cout << "-------------------" << endl;
return 0;
}
11.4 强制类型转换
- C++是强类型的语言,运算时要求类型相容或匹配。隐含参数this匹配调用当前函数的对象,若用const、volatile说明this指向的对象,则匹配的是const、volatile对象。
- 如定义了合适的类型转换函数重载,就可以完成操作数的类型转换;如定义了合适的构造函数,就可以构造符合类型要求的对象,构造函数也可以起到类型转换的作用。
- 对象与不同类型的数据进行运算,可能出现在双目运算符的左边和右边,为此,可能需要定义多种运算符重载函数。
- 只定义几种运算符重载函数是可能的,即限定操作数的类型为少数几种乃至一种。如果运算时对象类型不符合操作数的类型,则可以通过类型转换函数转换对象类型,或者通过构造函数构造出符合类型要求的对象。
例:强制类型转换运算符重载
struct A {
int i;
A(int v) { i = v; }
//C style casting: double d; int i = (int) d;
//C++ style casting: double d; int i = int(d);
//重载类型强制转换函数:operator targetType(),不需要定义返回类型
//( ) 只能用普通成员函数重载
virtual operator int() const { return i; } //类型转换返回右值(int)
}a(5);
struct B {
int i, j; B(int x, int y) { i = x; j = y; }
operator int() const { return i + j; } //类型转换返回右值
operator A() const { return A(i + j); } //类型转换返回右值
}b(7, 9), c(a, b); //a强制转换int,b强制转换int,再调B的构造函数
void main(void) {
int i = 1 + int(a); //强制转换, 调用A::operator int ( )转换a, i=6
i = b + 3; //自动转换, 调用B::operator int ( )转换b, i=19
i = a = b; //调用1:B::operator A ( );2:调用默认=重载,3:A::operator int ( ), i=16
cout << i << endl;
}
- 单参数的构造函数相当于类型转换函数,单参数的T::T(const A) T::T(A&&) 、T::T(const A&)等相当于A类到T类的强制转换函数。
- 也可以用operator定义强制类型转换函数。由于转换后的类型就是函数的返回类型,所以强制类型转换函数不需要定义返回类型。
- 不应该同时定义T::operator A( )和A::A (const T&),否则容易出现二义性错误。
- 按照C++约定,类型转换的结果通常为右值,故最好不要将类型转换函数的返回值定义为左值,也不应该修改当前被转换的对象 (参数表后用const说明this)。
- 转换的目标类型只要是能作为函数的返回类型即可。函数不能返回数组和函数。因此C++规定转换的类型表达式不能是数组和函数,但可以是指向数组和函数的指针
11.5 重载new和delete
- 运算符函数new和delete定义在头文件new.h中,new的参数就是要分配的内存的字节数。其函数原型为:
extern void * operator new(unsigned bytes);
extern void operator delete(void *ptr); - 在使用运算符new分配内存时,使用类型表达式而不是值表达式作为实参,编译程序会根据类型表达式计算内存大小并调用上述new函数。例如:new long[20] 。
- 按上述函数原型重载,new和delete可重载为普通函数,也可重载为静态函数成员。
Lambda表达式
1 Lambda表达式概念
- lambda表达式本质上是一个匿名、自动内联的函数
- 与任何函数类似,一个lambda表达式具有返回类型、参数列表、函数体{}
- 和普通函数不一样的是:lambda表达式有捕获列表,可以定义在一个函数内部(C++是不允许在一个函数里定义另外一个函数的)
- 一个lambda表达式具有如下形式
[捕获列表](形参列表) mutable 异常说明 -> 返回类型 {函数体}
其中:
捕获列表是必须有的(即使列表为空也必须有[]); 函数体{}是必须有的
mutable和异常说明是可选的
当不需要任何参数时,(形参列表)可以没有
当函数返回类型可以推断时,->返回类型 可以没有
注意:
形参列表指传递给lambda表达式参数(和函数形参列表一样),函数参数称为绑定变量,它在函数上下文有明确的定义
捕获列表指lambda表达式要使用的、定义在lambda表达式外面的变量,称为自由变量。
lambda表达式可以赋值给一个变量, 变量的类型用auto
例1:
//定义了一个lambda表达式,捕获列表为空,不需要任何参数,返回类型省略(可以从函数 体推断出//返回类型为int)
auto f1 = [] {return 42;}; //等价于 auto f1 = []()->int {return 42;};
//将一个lambda表达式赋值给变量f1后,f1就可以看成函数名,可以通过f1进行调用
int rtn_f1 = f1();
cout << "rtn_f1 = " << rtn_f1 << endl;
//这里定义了一个lambda表达式,捕获列表为空,形参int x(默认值为1),返回类型为int
auto f2 = [ ](int x=1)->int { return x; };
int rtn_f2 = f2(10);
cout << "rtn_f2 = " << rtn_f2 << endl;
auto f3 = [](int i) { return i < 0?-i:i;}; //功能:返回整数i的绝对值
int rtn_f3 = f3(-20);
cout << "rtn_f3 = " << rtn_f3 << endl;
//如果有兴趣,可以用typeid函数看看f3被自动推断出什么类型
//如果用gcc
cout << "type of f1:" << abi::__cxa_demangle(typeid(f1).name(), nullptr, nullptr, nullptr);
//如果在VisualStudio cout << "type of f1:" << typeid(f1).name() << endl;
lambda捕获变量
- lambda可以使用它所在函数的局部变量(包括它所在函数的形参),这个过程叫捕获。捕获只限于局部非static变量。
- lambda可以直接使用它所在函数的局部static变量,以及在它所在函数之外声明的名字(例如全局的名字、所在文件的静态的名字),但这种情况不是捕获。
例2:捕获变量
void test_lambda_demo_2(){
//函数test_lambda_demo_2定义了局部变量 x,y
int x = 10, y = 10;
//现在在test_lambda_demo_2里定义lambda表达式
//问题:lambda表达式除了自己的形参外,是否可以使用lambda表达式所位于的test_lambda_demo_2函数的
//局部变量x、y呢?可以!lambda表达式使用所在函数中的局部变量叫做捕获变量,可以在[捕获列表]里指明要
//捕获那些局部变量
//lambda表达式要使用(捕获)所在函数test_lambda_demo_2的局部变量x,是值捕获
auto f1 = [x] (int i) ->int {return x * i;}; //调用lambda表达式
cout << "f1() = " << f1(2) << endl; //输出20
++x; //函数test_lambda_demo_2定义了局部变量 x变了
cout << "f1() = " << f1(2) << endl; //还是输出20,而不是22
}
为什么会这样?
lambda表达式捕获发生在lambda表达式被创建的时候(即定义lambda表达式的代码执行时),这个例子里是语句
auto f1 = [x] (int i) ->int {return x * i;};
这个时刻捕获x的值是10,而且是值捕获,因此x(值为10)被复制到lambda表达式的上下文里(更准确的说应该是闭包)。
因此++x没有改变已经创建好的lambda表达式闭包里的x,所以调用f1(2)时,函数体{ return x * i; }里的x还是10
顺便说一下,当lambda表达式被创建好以后,可以多次执行,例如f1(2),f1(3), ...
例3:引用捕获
void test_lambda_demo_2(){
int x = 10, y = 10;
/* 如果是引用捕获呢?
lambda表达式捕获发生在lambda表达式被创建的时候(即定义lambda表达式的代码执行时),下面例子
auto f2 = [&y] (int i) ->int {return y * i;};
这个捕获是引用捕获,即y的引用复制到lambda表达式的上下文里(更准确的说应该是闭包)。因此++y以后再调用f2(2)时,函数体{ return y * i; }里的y变成了11
*/
auto f2 = [&y] (int i) ->int {return y * i;}; //调用lambda表达式
cout << "f2() = " << f2(2) << endl; //输出20
++y;
cout << "f2() = " << f2(2) << endl; //输出22
/* 可以捕获多个局部变量,这时在[捕获列表]里面多个名字用逗号分割例如 */
auto f3 = [x, y] (int i)->int { return i * (x + y);}; //同时值捕获x和y
auto f4 = [&x, &y] (int i)->int { return i * (x + y);}; //同时引用捕获x和y
auto f5 = [x, &y] (int i)->int { return i * (x + y);}; //值捕获x,引用捕获y
}
3 隐式捕获
除了在[捕获列表]显式列出lambda需要捕获的变量外,也可以让编译器根据lambda表达式函数体代码来推断要捕获哪些变量 .但为了指示编译器如何推断捕获列表,应该在[]里写=或&,来告诉编译器是值捕获还是引用捕获
例4:隐式捕获
void test_lambda_demo_3(){
int x = 10, y = 10, z = 10;
auto f1 = [=]()-> int{ return x + y + z;}; //隐式值捕获,根据代码可以推断出:值捕获了x , y, z三个变量
cout << "f1() = " << f1() << endl; //输出30
auto f2 = [&]()-> int{ return x + y + z;}; //隐式引用捕获,根据代码可以推断出:引用捕获了x ,y ,z三个变量
cout << "f2() = " << f2() << endl; //输出30
++x;++y;++z;
cout << "f1() = " << f1() << endl; //还是输出30
cout << "f2() = " << f2() << endl; //输出33
}
可以混合使用隐式捕获和显式捕获
当混合使用隐式捕获和显示捕获时,捕获列表的第一个元素必须是一个=或者&,指定隐式捕获方式;后面是显 式捕获变量名列表,而且显式捕获的方式必须和隐式捕获不一样
即:如果隐式捕获是引用捕获,则显式捕获必须用值捕获;如果隐式捕获是值捕获,则显式捕获必须用引用捕获;
auto f3 = [=,&z]()-> int{ return x + y + z;}; //隐式值捕获x , y,显式引用捕获变量z
auto f4 = [&,x]()-> int{ return x + y + z;}; //隐式引用捕获y , z,显式值捕获变量x}
4 Lambda表达式作为返回值
既然lambda表达式可以赋值给一个变量,那么lambda表达式可以作为函数的返回值
我们希望有这样一个函数:natural_number_generator(自然数产生器),每次调用natural_number_generator会自动产生下一个自然数,
我们还希望有一个函数能帮我们产生这样的自然数产生器,这个函数比如叫natural_number_generator_factory(自然数发生器的制造工厂)
即:我们希望函数natural_number_generator_factory能返回另外一个函数natural_number_generator(自然数产生器)。我们可以也只能用lambda表达式
例5:自然数产生器
void test_lambda_demo_4(){
//调用natural_number_generator_factory()得到一个自然数产生器generator1
auto generator1 = natural_number_generator_factory();
cout << "generator1 generates ..." << endl;
int n1 = generator1(); //调用generator1,得到下一个自然数,n1 = 1;
cout << "n1 = " << n1 << endl;
int n2 = generator1(); //调用generator1,得到下一个自然数,n2 = 2;
cout << "n2 = " << n2 << endl;
//可以一直这样产生下一个自然数
//调用natural_number_generator_factory()得到另一个一个自然数产生器generator2
auto generator2 = natural_number_generator_factory();
cout << "generator2 generates ..." << endl;
int m1 = generator2(); //调用generator2,得到下一个自然数,m1 = ?;
cout << "m1 = " << m1 << endl;
int m2 = generator2(); //调用generator2,得到下一个自然数,m2 = ?;
cout << "m2 = " << m2 << endl;
//可以一直这样产生下一个自然数
}
5闭包
闭包是指带有捕获的lambda表达式对象。简单来说,lambda表达式会返回一个可调用对象,这个对象本身携带了它捕获的外部变量的信息,形成了一个闭包。闭包可以在不同的上下文中使用,甚至在原来作用域之外使用捕获的变量值,这种特性在异步编程或回调中非常有用。
Lambda表达式+捕获的自由变量i叫闭包。闭包(Closure)并不是一个新鲜的概念,很多函数式语言中都使用了闭包。例如在JavaScript中,当你在内嵌函数中使用外部函数作用域内的变量时,就是使用了闭包。用一个常用的类比来解释闭包和类(Class)的关系:类是带函数的数据,闭包是带数据的函数。
闭包的本质:代码块+上下文
闭包中使用的自由变量有一个特性,就是它们不在父函数返回时释放,而是随着闭包生命周期的结束而结束。 generator1和generator2就是二个不同的闭包,它们分别使用了相互独立的变量i(在generator2的i自增1的时候, generator2的i并不受影响,反之亦然),只要generator2或generator2这两个变量没有被回收,他们各自的自由变量i就不会被释放。
- Lambda表达式是C++引入的一种匿名函数。存储Lambda表达式的变量被编译为临时类的对象。
- 该临时类变量的对象被构造时,此时Lambda表达式被计算。
- 若未定义存储该临时类对象的变量,则称该Lambda表达式没被计算。
- 临时类重载operator( ) (…) ;当调用f(3)时,等价于f.operator( )(3)
- Lambda表达式被编译成函数对象,函数对象名为f
例6:捕获的哪些值可改?
当捕获列表以值的方式传递后,lambda表达式不能修改这个变量的值,只能使用,除非加mutable
void main() {
int m = 1, p = 3;
const int n = 2, q = 4;
auto g = [m, n, &p, &q](int x) ->int { p++; /*错:m++; n++; q++;*/; return m+n+x; };
int z = g(0); //m=1,p=4,z=3, 等价于g.operator()(0)
z = g(0); //m=1,p=5,z=3
}
//auto g = lambda表达式这条语句,被编译为匿名类对象g,生成的匿名类及其函数如下
class 匿名类{
const int m, n; //Lambda表达式无mutable时,非&捕获的可写外部变量m为const成员
int &p; //&捕获的外部变量保持其原有类型int+&
const int &q; //&捕获的外部变量保持其原有类型const int+&
public:
构造函数(int m, const int n, int &p, const int &q) : m(m), n(n), p(p), q(q){ }
int operator()(int x) { p++; return m + n + x; }
}g(m, n, p, q); //调用构造函数初始化匿名类对象g
6 捕获列表的参数
- Lambda表达式的外部变量不能是全局变量或static定义的变量。
- Lambda表达式的外部变量不能是类的成员。
- Lambda表达式的外部变量可以是函数参数或函数定义的局部自动变量。
- 出现“&变量名”表示引用捕获外部变量,[&]表示引用捕获所有函数参数或函数定义的局部自动变量。其可写特性同被捕获的外部变量一致。
- 出现“=变量名”表示值捕获外部变量的值(值参传递), [=]表示捕获所有函数参数或函数定义的局部自动变量的值。
- 参数表后有mutable表示在Lambda表达式中可以修改“值参传递的可写变量的值”,但调用后不影响Lambda表达式捕获的对应该可写外部变量的值(值捕获)。
例7:指针与类型
//例12.21
int main( ) {
int a = 0;
auto f = [](int x = 1)->int { return x; }; //捕获列表为空,对象f当准函数用
auto g = [](int x)throw(int) ->int { return x; }; //g同上:匿名函数可能抛出异常, throw(int) 是异常声明
int(*h)(int) = [](int x)->int { return x * x; }; //捕获列表为空,可以用函数指针h指向“准函数”
h = f; //正确:f的Lambda表达式捕获列表为空,f当准函数使用
auto m = [a, f](int x)->int { return x * f(x); }; //m是函数对象:捕获a初始化函数对象实例成员
//int(*k)(int)=[a](int x)->int{return x;}; //函数指针k不能指向函数对象(捕获列表非空,函数对象包含其他成员)
//h = m; //错误:m的Lambda表达式捕获列表非空,m是函数对象
//printf(typeid([ ](int x)->int{return x;}).name( )); //错:临时Lambda表达式未计算,无类型
printf("%s\n", typeid(f).name()); //输出class <lambda_...>
printf("%s\n", typeid(f(3)).name()); //输出int,使用实参值调用x=3
printf(“%s\n”, typeid(f.operator( )()).name()); //输出int,使用默认值调用x=1,f是函数对象,显式调用operator()()
printf("%s\n", typeid(f.operator( )).name()); //输出int __cdecl(int)
printf("%s\n", typeid(g.operator( )).name()); //输出int __cdecl(int)
printf("%s\n", typeid(h).name()); //输出int (__cdecl*)(int)
printf("%s\n", typeid(m).name()); //输出class <lambda_...>
return f(3) + g(3) + (*h)(3); //用对象f、g调用Lambda表达式
}
- 捕获列表的参数可以出现this,但实例函数成员中的Lambda表达式默认捕获this,而静态函数成员中的Lambda表达式不能捕获this。
- 由于this不是变量名或参数名,故不能使用“&this”或者“=this” 。
- Lambda表达式的捕获列表非空,倾向于用作“准对象”,否则倾向于用作“准函数”。
- 早期编译器实例函数成员中的Lambda表达式默认捕获this,故它是一个准对象。但vs2019必须明确捕获this才能访问实例数据成员。
- 只有作为“准函数”才能获得其函数入口地址。
【例8】:默认捕获this
int m = 7; //全局变量m不用被捕获即可被Lambda表达式使用
static int n = 8; //模块变量n不用被捕获即可被Lambda表达式使用
class A {
int x; //由于this默认被捕获,故可访问实例数据成员A::x
static int y; //静态数据成员A::y不用捕获即可被Lambda表达式使用
public:
A(int m): x(m) { }
void f(int &a) { //实例函数成员f()有隐含参数this
int b = 0;
static int c=0; //静态变量c不用被捕获即可被Lambda表达式使用
auto h = [&, a, b](int u)mutable->int{ //this默认被捕获,创建对象h,a, b值捕获,其它引用捕获
a++; //f()的参数a被值捕获并传给h的实例成员a:a++不改变f()的参数a的值
b++; //f()的局部变量b被捕获并传给h实例成员b:b++不改局部变量b的值
c++; //f()的静态变量c可直接使用,c++改变f()的静态变量c的值
y=x+m+n+u+c; //this默认被捕获:可访问实例数据成员x
return a;
};
h(a + 2); //实参a+2值参传递给形参u,调用h.operator( )(a+2)
}
static void g(int &a){ //静态函数成员g()没有this
int b = 0;
static int c = 0; //静态变量c不用被捕获即可被Lambda表达式使用
auto h = [&a, b](int u)mutable->int{ //没有this被捕获,创建函数对象h
a++; //g()的参数a被捕获并传给h的引用实例成员a:a++改变参数a的值,a是引用捕获
b++; //g()的局部变量b被捕获传给h实例成员b:b++不改局部变量b的值,b是值捕获
c++; //g()的静态变量c可直接使用,c++改变g()的静态变量c的值
y=m+n+u+c; //没有捕获this,不可访问实例数据成员A::x
return a;
};
auto k = [ ](int u) ->int { return u; }; //静态成员函数g没有this,没有this被捕获,创建对象k
auto p = k; //p的类型为class<lambda…>
int (*q)(int) = k; //问题:若将红色部分放入void f(int &a)中,如何? int (*q)(int) = k;就不成立
h(a + 2); //实参a+2值参传递给h形参u
}
}a(10);
int A::y = 0; //静态数据成员必须初始化
void main( ) {
int p = 2;
a.f(p); //p=2,a.x=10,A::y=30 x(10)+m(7)+n(8)+u(4)+c(1)
a.f(p); //p=2,a.x=10,A::y=31
A::g(p); //p=3,a.x=10,A::y=20
A::g(p); //p=4,a.x=10,A::y=22
}
8 std::function
std::function是C++标准库中的一个通用的函数包装器,位于
8.1 基本使用
std::function是一个模板类,通常形式为:
std::function<ReturnType(ArgTypes...)>
例如,要创建一个接受int参数并返回int的std::function对象,可以这样定义:
#include <functional>
#include <iostream>
int add(int a, int b) {
return a + b;
}
int main() {
// 创建std::function对象,能够接受两个int参数并返回int
std::function<int(int, int)> func = add;
// 调用
std::cout << func(3, 4) << std::endl; // 输出:7
return 0;
}
8.2 2. 支持的可调用对象
std::function可以存储多种类型的可调用对象,包括:
1)普通函数
2)Lambda表达式
可以将lambda表达式赋值给std::function。有无捕获的lambda都可以:
std::function<int(int, int)> func = [](int a, int b) { return a + b; };
3)函数指针
可以使用函数指针来初始化std::function对象:
int (*funcPtr)(int, int) = add;
std::function<int(int, int)> func = funcPtr;
4)std::bind
std::bind用于绑定函数的参数或部分参数。绑定后的对象也可以赋值给std::function:
#include <functional>
int add(int a, int b) {
return a + b;
}
int main() {
// 使用std::bind绑定第一个参数为2
std::function<int(int)> func = std::bind(add, 2, std::placeholders::_1);
std::cout << func(3) << std::endl; // 输出5
return 0;
}
5)成员函数指针
使用std::function时可以包装成员函数指针,不过需要同时指定对象实例:
#include <functional>
#include <iostream>
class MyClass {
public:
int multiply(int a) const { return a * 2; }
};
int main() {
MyClass obj;
// 使用std::function包装成员函数指针
std::function<int(const MyClass&, int)> func = &MyClass::multiply;
std::cout << func(obj, 5) << std::endl; // 输出10
return 0;
}
第十三章 模板与内存回收
13.1 变量模板及其实例
- C++提供了3种类型的模板,即变量模板、函数模板和类模板。
- 变量模板使用类型形参定义变量的类型,可根据类型实参生成变量模板的实例变量。
- 生成实例变量的途径有三种:一种是从变量模板隐式地或显式地生成模板实例变量;另一种是通过函数模板(见13.2节)和类模板(见13.4节)生成。
- 在定义变量模板、函数模板和类模板时,类型形参的名称可以使用关键字class或者typename定义,即可以使用“template
”或者“template ”。 - 生成模板实例变量时,将使用实际类型名代替T。实际类型名可以是内置类型名、 类名或类模板实例(类模板实例就是具体的class,是类型)
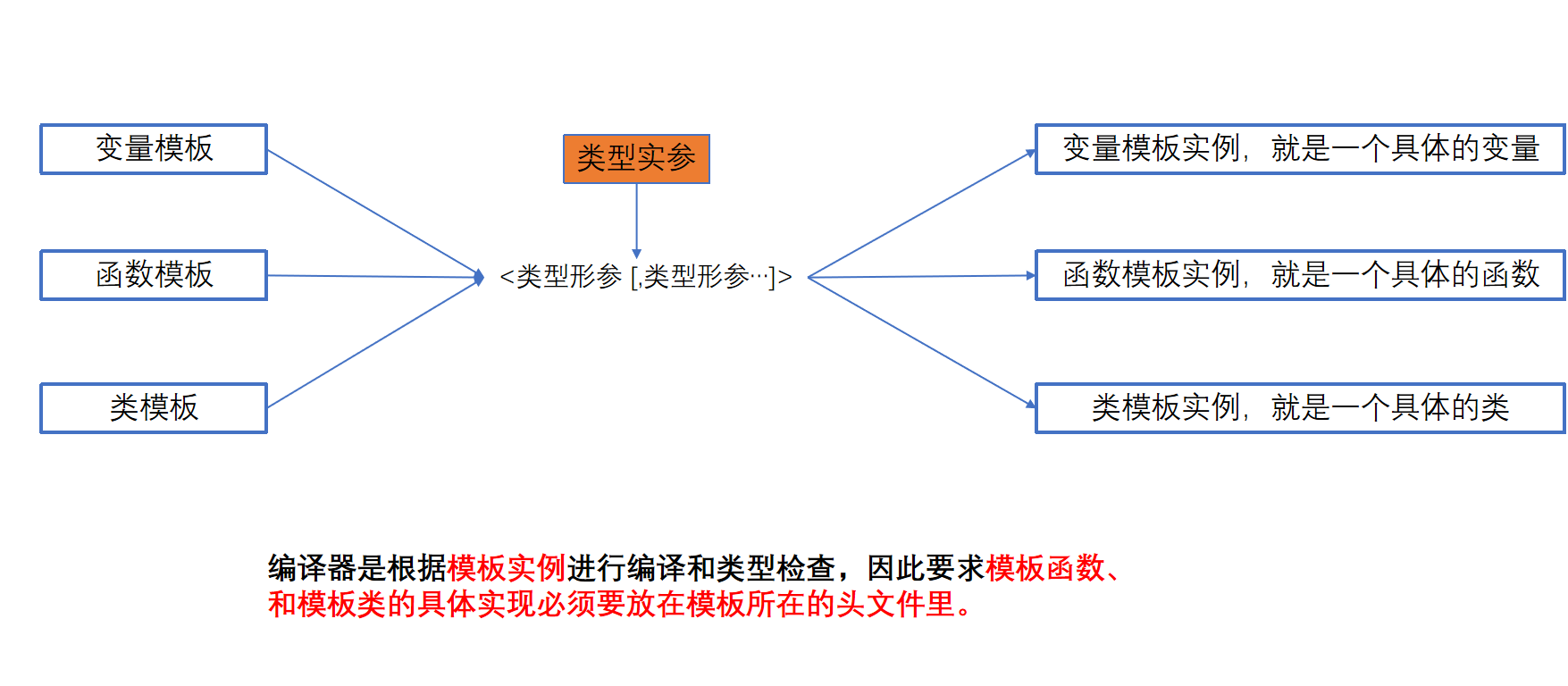
【例13.1】定义变量模板并生成模板实例变量。
#include <iostream>
using namespace std;
template<typename T>
constexpr T pi = T(3.1415926535897932385L); //定义变量模板pi,其类型形参为T
template<class T> T area(T r) { //定义函数模板area,其类型形参为T
printf(" % p\n", &pi<T>); //生成模板函数实例时附带生成变量模板pi<T>的变量模板实例
return pi<T> *r * r;
}
template const float pi<float>; //显式生成变量实例pi<float>,不能使用constexpr
//等价于“const float pi<float>= float (3.1415926535897932385L);”
template const double pi<double>; //生成模板实例变量pi<double>,实参类型为double
//等价于“const double pi<double >= double (3.1415926535897932385L);”
void main(void)
{
const float& d1 = pi<float>; //引用变量模板生成的模板实例变量pi< float>
const double& d2 = pi<double>; //引用变量模板生成的模板实例变量pi<double>
const long double& d3 = pi<long double>; //生成并引用模板实例变量pi<long double>
float a1 = area<float>(3); // area<float>为函数模板area<T>的实例函数
double a2 = area<double>(3);
long double a3 = area<long double>(3);
int a4 = area<int>(3); //调用area<int>时,隐式生成变量模板实例pi<int>
}
显式实例化模板必须在命名空间作用域内进行,而不能在函数内部进行。此外,template 关键字在显式实例化时是不必要的
- 变量模板不能在函数内部声明。
- 显式或隐式实例化生成的变量模板实例和变量模板的作用域相同。因此,变量模板生成的变量模板实例只能为全局变量或者模块静态变量。
- 模板的参数列表除了可以使用类型形参外,还可以使用非类型的形参。
- 在变量模板实例化时,非类型形参需要传递常量作为实参。
- 非类型形参也可以定义默认值,若变量模板实例化时未给出实参,则使用其默认值实例化变量模板。
【例13.2】使用非类型形参定义变量模板,并生成变量模板的模板实例变量
#include <iostream>
using namespace std;
template<typename T> //定义变量模板pi,其类型形参为T
constexpr T pi = T(3.1415926535897932385L);
template<class T> T area(T r) { //定义函数模板area,其类型形参为T
return pi<T> *r * r;
}
template<class T, int x = 3> //定义变量模板girth,其类型形参为T
static T girth = T(3.1415926535897932385L * 2 * x);
template float girth<float>; //生成变量模板实例static girth<float>,作用域与变量模板相同
void main(void)
{
const double& f = pi<double>; //引用在main()外生成的全局变量pi<double>
double& g = girth<double, 4>; //引用在main()外生成的static girth <double>,非类型实参传递常量
double& h = girth<double, sizeof(printf("abc"))>;//引用在main()外生成的static girth <double>
double& k = girth<double>; //引用在main()外用默认值生成的static girth <double>
printf(" % lf\n", girth<double, 4>); //生成的模板实例变量不是main函数的局部自动变量
printf("%lf\n", area<double>(4));
}
13.2 函数模板
- 函数模板是使用类型形参定义的函数框架,可根据类型实参生成函数模板的模板实例函数。
- 模板(变量模板、函数模板、类模板)的声明或定义只能在全局范围、命名空间或类范围内进行。
- 根据函数模板生成的模板实例函数也和函数模板的作用域相同。
- 在函数模板时,可以使用类型形参和非类型形参。
- 模板实例化时非类型形参需要传递常量作为实参。
- 可以单独定义类的函数成员为函数模板。
【例13.3】定义用于变量交换和类型转换的两个函数模板
template <class T, int m=0> //class可用typename代替
void swap(T& x, T& y=m)
{
T temp = x;
x = y;
y = temp;
}
template <class D, class S> //class可用typename来代替定义形参D、S
D convert(D& x, const S& y) //模板形参D、S必须在函数参数表中出现
{
return x = y; //将y转换成类型D后赋给x
}
struct A {
double i, j, k;
public:
A(double x, double y, double z) :i(x), j(y), k(z) { };
};
void main(void){
long x = 123, y = 456;
char a = 'A', b = 'B';
A c(1, 2, 3), d(4, 5, 6);
swap<long, 0>(x, y); //显式给出类型实参,必须用常量传给非类型实参m,函数模板实例化得到实例函数
swap(x, y); //自动生成实例函数void swap(long &x, long &y),通过实参推断类型形参T,隐式实例化函数模板
swap(a, b); //自动生成实例函数void swap(char &x, char &y),隐式给出类型实参char,m=0
swap(c, d); //自动生成实例函数void swap(A &x, A &y)
convert(a, y); //自动生成实例函数char convert (char &x, const long &y)
}
【例13.4】单独定义函数成员为模板
#include<typeinfo>
class ANY { //定义一个可存储任何简单类型值的类ANY
void* p;
const char* t;
public:
template <typename T> ANY(T x) {//单独定义构造函数模板
p = new T(x);
t = typeid(T).name();
}
void* P() { return p; }
const char* T() { return t; } //此T为函数成员的名称,不是模板的类型形参
~ANY() noexcept { if (p) { delete p; p = nullptr; } }
}a(20); //自动从构造函数模板生成构造函数ANY::ANY(int) ,通过实参类型推断
void main(void){
double* q(nullptr); //等价于“double* q=nullptr;”
if (a.T() == typeid(double).name()) q = (double*)a.P(); //a.P()返回void *
}
- 函数模板的类型形参允许参数个数可变,用省略参数“…”表示任意个类型形参
- 用递归定义的方法可展开并处理这些类型形参。
- 生成实例函数时,可能因递归生成多个实例函数,这些实例函数之间递归调用。
【例13.5】定义任意个类型形参的函数模板
#include <iostream>
using namespace std;
template<class... Args> //类型形参个数可变的函数模板声明
int println(Args... args);
template<class... Args> //递归下降展开的停止条件:println( )的参数表为空
int println( ) {
cout << endl;
return 0;
}
template < class H, class... T> //递归下降展开println()的参数表
int println(H h, T... t) {
cout << h<<'*';
return 1+println(t...); //递归下降调用
}
int main( ) {
int n= println(1, '2', 3.3, "expand"); //根据实参,递归的推断类型实参并展开,生成实例函数(递归调用)
cout<<"n="<<n<<endl; //返回n=4
}
13.3 函数模板实例化
- 在调用函数时可隐式自动生成模板实例函数(根据实参推断)。
- 也可使用“template 返回类型 函数名<类型实参>(形参列表)”,显式强制函数模板按类型实参显式生成模板实例函数。
- 有时候生成的模板实例函数不能满足要求,可定义特化的模板实例函数隐藏自动生成的模板实例函数。
- 在特化定义模板的实例函数时,一定要给出特化函数的完整定义。
- 一般的比较为浅比较,当涉及字符串运算时,应通过特化实现深比较。
//显式强制函数模板按类型实参显式生成模板实例函数
template <class T> //class可用typename代替
T sum(const T& x, const T& y)
{
return x + y;
}
//显式实例化函数模板,得到实例函数sum<int>
template int sum<int>(const int & x, const int &y);
int i = sum<int>(1,2); //调用函数sum<int>
【例13.8】模板实例函数的生成以及隐藏。
#define _CRT_SECURE_NO_WARNINGS //防止strcmp出现指针使用安全警告
#include <iostream>
#include <string.h> //定义函数模板max()
using namespace std;
template <typename T>
T Max(T a, T b)
{
return a>b?a:b;
}
template < > //此行可省, template < >表示特化实例函数:特化函数将被优先调用
const char *Max(const char *x, const char *y) //特化函数:用于隐藏模板实例函数
{
return strcmp(x, y)>0?x:y; //进行字符串内容比较
}
int u, v;
int greed(int x, int y=Max(u, v)) //产生默认值时生成模板实例函数int max(int, int)
{
return x*y;
}
int main()
{
const char *p="ABCD"; //字符串常量"ABCD"的默认类型为const char*
const char *q="EFGH";
p=Max(p, q); //调用特化定义的实例函数,进行字符串内容比较
cout<<p<<endl; //输出字符串"EFGH"
return 0;
}
13.4 类模板
- 类模板也称为类属类或类型参数化的类,用于为相似的类定义一种通用模式。
- 编译程序根据类型实参生成相应的类模板实例类
- 类模板既可包含类型参数,也可包括非类型参数。
- 类型参数可以包含1个以上乃至任意个类型形参。
- 非类型形参在实例化是必须使用常量做为实参。
【例13.9.1】定义向量类的类模板。
#include <iostream>
template <class T, int v = 20> //类模板的模板参数列表有非类型形参v,默认值为20
class VECTOR
{
T* data;
int size;
public:
VECTOR(int n = v + 5); //由v构成表达式v+5,将其作为构造函数成员形参的默认值
~VECTOR() noexcept;
T& operator[ ](int);
};
template <class T, int v> //在类体外函数实现时,加template<class T, int v>, v不能给缺省值
VECTOR <T, v>::VECTOR(int n) //须用VECTOR <T, v>作为类名
{
data = new T[size = n];
}
template <class T, int v> //函数实现时,加template<class T, int v>, v不能给缺省值
VECTOR <T, v>::~VECTOR() noexcept //须用VECTOR <T, v>作为类名
{
if (data) delete[] data;
data = nullptr;
size = 0;
}
template <class T, int v>
T& VECTOR <T, v>::operator[ ](int i) //须用VECTOR <T, v>作为类名
{
return data[i];
}
int main()
{
VECTOR<int> LI(10); //定义包含10个元素的整型向量LI
VECTOR<short> LS; //定义包含25个元素的短整型向量LS
VECTOR<long> LL(30); //定义包含30个元素的长整型向量LL
VECTOR<char*> LC(40); //定义包含40个元素的字符型向量LC
VECTOR<double, 10> LD(40); //非类型形参必须使用常量作为实参
VECTOR<int>* p = &LI; //定义指向整型向量的指针p
//以下q指向40个由VECTOR<int>元素构成的数组,其中
//每个VECTOR<int>元素又是包含25个int元素的向量
VECTOR<VECTOR<int>>* q = new VECTOR<VECTOR<int>>[40];
delete []q;
return 0;
}
【例13.9.2】定义向量类的类模板。
#pragma once
#include <algorithm> // for std::copy
#include <stdexcept> // for std::out_of_range
template <class T>
class vector {
public:
// 数据
T* data;
// 大小
int Size;
// 容量
int capacity;
// 构造函数
vector() : Size(0), capacity(1), data(new T[1]) {}
// 析构函数
~vector() {
delete[] data;
}
//含参构造函数(初始化大小,元素)
vector(int n, T t) : Size(n), capacity(n), data(new T[n]) {
for (int i = 0; i < n; i++) {
data[i] = t;
}
}
// 拷贝构造函数
vector(const vector& v) : Size(v.Size), capacity(v.capacity), data(new T[v.capacity]) {
std::copy(v.data, v.data + v.Size, data);
}
// 赋值运算符
vector& operator=(const vector& v) {
if (this != &v) {
T* new_data = new T[v.capacity];
std::copy(v.data, v.data + v.Size, new_data);
delete[] data;
data = new_data;
Size = v.Size;
capacity = v.capacity;
}
return *this;
}
// 添加元素
void push_back(T t) {
if (Size == capacity) {
resize(capacity * 2);
}
data[Size++] = t; // 添加元素
}
// 删除元素
void pop_back() // 删除最后一个元素
{
if (Size > 0) Size--;
}
// 返回大小
int size() const {
return Size;
}
// 返回元素(非 const 版本)
T& operator[](int index) {
if (index < 0 || index >= Size) {
throw std::out_of_range("Index out of range");//抛出异常
}
return data[index];
}
// 返回元素(const 版本)
const T& operator[](int index) const
{
if (index < 0 || index >= Size) {
throw std::out_of_range("Index out of range");//抛出异常
}
return data[index];
}
//判断是否为空
bool empty() const
{
return Size == 0;
}
void clear() {
Size = 0;
}
// 迭代器类
class iterator {
public:
T* ptr;
iterator(T* p) : ptr(p) {}
T& operator*() const { return *ptr; }
T* operator->() const { return ptr; }
iterator& operator++() { ++ptr; return *this; }
iterator operator++(int) { iterator tmp = *this; ++ptr; return tmp; }
iterator& operator--() { --ptr; return *this; }
iterator operator--(int) { iterator tmp = *this; --ptr; return tmp; }
bool operator==(const iterator& other) const { return ptr == other.ptr; }
bool operator!=(const iterator& other) const { return ptr != other.ptr; }
};
// 常量迭代器类
class const_iterator {
public:
const T* ptr;
const_iterator(const T* p) : ptr(p) {}
const T& operator*() const { return *ptr; }
const T* operator->() const { return ptr; }
const_iterator& operator++() { ++ptr; return *this; }
const_iterator operator++(int) { const_iterator tmp = *this; ++ptr; return tmp; }
const_iterator& operator--() { --ptr; return *this; }
const_iterator operator--(int) { const_iterator tmp = *this; --ptr; return tmp; }
bool operator==(const const_iterator& other) const { return ptr == other.ptr; }
bool operator!=(const const_iterator& other) const { return ptr != other.ptr; }
};
// 返回迭代器的开始
iterator begin() { return iterator(data); }
// 返回迭代器的结束
iterator end() { return iterator(data + Size); }
// 返回常量迭代器的开始
const_iterator begin() const { return const_iterator(data); }
// 返回常量迭代器的结束
const_iterator end() const { return const_iterator(data + Size); }
// 调整容量
void resize(int new_capacity) {
T* new_data = new T[new_capacity];//新建一个数组
std::copy(data, data + Size, new_data);//复制数据
delete[] data;//删除原来的数组
data = new_data;
capacity = new_capacity;
}
};
- 可以用类模板定义基类和派生类。
- 在实例化派生类时,如果基类是用类模板定义的,也会同时实例化基类。这里的实例化指模板类实例化,生成实例类
- 派生类函数在调用基类的函数时,最好使用“基类<类型参数>::”限定基类函数成员的名称,以帮助编译程序识别函数成员所属的基类。
- 对于实例化的模板类,如果其名字太长,可以使用typedef重新命名定义。
【例13.10】类模板的派生用法。
#include<iostream>
template <class T> //定义基类的类模板
class VECTOR
{
T* data;
int size;
public:
int getsize() { return size; };
VECTOR(int n) { data = new T[size = n]; };
~VECTOR() noexcept { if (data) { delete[]data; data = nullptr; size = 0; } };
T& operator[ ](int i) { return data[i]; };
};
template <class T> //定义派生类的类模板
class STACK : public VECTOR<T> { //派生类类型形参T作为实参,实例化VECTOR<T>
int top;
public:
int full() { return top == VECTOR<T>::getsize(); }
int null() { return top == 0; }
int push(T t);
int pop(T& t);
STACK(int s) : VECTOR<T>(s) { top = 0; };
~STACK() noexcept { };
};
template <class T>
int STACK<T>::push(T t)
{
if (full()) return 0;
(*this)[top++] = t; //调用operator[]
return 1;
}
template <class T>
int STACK<T>::pop(T& t)
{
if (null()) return 0;
t = (*this)[--top];
return 1;
}
int main(void)
{
typedef STACK<double> DOUBLESTACK; //对实例化的类重新命名定义
STACK <int> LI(20); //类模板实例化得到实例类STACK<int>(及其父类VECTOR<int>)
STACK <long> LL(30);
DOUBLESTACK LD(40); //等价于“STACK<double> LD(40);”
return 0;
}
【例13.11】类模板中的多个类型形参的顺序变化对类模板的定义没有影响。
#include <iostream>
template<class T1, class T2> struct A { //定义类模板A
void f1();
void f2();
};
template<class T2, class T1> //正确:A<T2, T1>同类型形参一致
void A<T2, T1>::f1() { }
template<class T1, class T2> //正确:A<T1, T2>同类型形参一致
void A<T1, T2>::f2() { }
//template<class T2, class T1> //错误:A<T1, T2>与类型形参不同
//void A<T1, T2>::f2() {}
template<class...Types> struct B {
void f3();
void f4();
};
template<class ...Types> void B<Types ... >::f3() { } //正确:Types表示类型形参列表
template<class ...Types> void B<Types ... >::f4() { } //正确:Types表示类型形参列表
//template<class ...Types> void B<Types>::f4( ){ } //错误:必须用“Types ...”的形式
void main(void) { }
- 当一个类模板有多个类型形参时,在类中只要使用同样的类型形参顺序,都不会影响他们是同一个类型形参模式。
- 当使用“…”表示类型形参时,表示类型形参有任意个类型参数。可通过递归定义展开类模板。
【例13.13】
//通过auto定义变量模板n,元素全部初始化为0
template <class T> auto n = new VECTOR<T>[10] {};
//通过auto定义变量模板p
template <class T> static auto p = new VECTOR<T>[10];
//定义Lambda表达式模板
template <class T> auto q = [](T& x)->T& { return x; };
template <class T> //定义类模板
class VECTOR
{
T* data; int size;
public:
int getsize() { return size; };
VECTOR(int n = 10) { data = new T[size = n]; }; //在类体里实现函数不用再加模板形参
~VECTOR() noexcept { if (data) { delete[]data; data = nullptr; size = 0; } };
T& operator[ ](int i) { return data[i]; };
};
template <typename T> auto m = new T[10];
//显式将变量模板实例化,产生变量m<int>。可以注释下面一行,直接使用m<int>(隐式实例化),特别是使用auto时
template int* m<int>;
//通过auto定义变量模板,元素全部初始化为0
template <class T> auto n = new VECTOR<T>[10] {};
//显式将变量模板实例化,产生变量n<int>。可以注释下一行,直接使用n<int>(隐式实例化),特别是使用auto时
template VECTOR<int>* n<int>;
//定义Lambda表达式模板,可以直接(实际上只能)隐式实例化Lambda表达式模板,如q<int>(i)
template <class T> auto q = [](T& x)->T& { return x; };
const char* unreadable_type_name_m = typeid(m<int>).name(); //隐式实例化变量模板,得到变量m<int>
char* type_name_m = abi::__cxa_demangle(unreadable_type_name_m, nullptr, nullptr, nullptr);
cout << m<int> << "," << typeid(m<int>).name() << endl; //gcc下输出:0xf12200, Pi 输出指针的值还有内部的符号Pi
cout << m<int> << "," << type_name_m << endl; //gcc下输出:0xf12200, int *
//abi::__cxa_demangle 将低级符号名解码(demangle)成用户级名字,
//现在输出int* 了
const char* unreadable_type_name_n = typeid(n<int>).name();
char* type_name_n = abi::__cxa_demangle(unreadable_type_name_n, nullptr, nullptr, nullptr);
cout << n<int> << "," << typeid(n<int>).name() << endl; //gcc下输0xdf2238,PN15class_template36VECTORIiEE
cout << n<int> << "," << type_name_n << endl; //gcc下输出:0xdf2238,class_template3::VECTOR<int>*
int i = 3;
int j = q<int>(i); //前面显式初始化Lambda表达式模板,得到Lambda表达式实例q<int>,并调用
cout << “j = ” << j << endl; //输出3
const char* unreadable_type_name_q = typeid(q<int>).name();
char* type_name_q = abi::__cxa_demangle(unreadable_type_name_q, nullptr, nullptr, nullptr);
cout << typeid(q<int>).name() << endl; //gcc下输出:1N15class_template31qIiEUlRiE_E
cout << type_name_q << endl; //gcc下输出:1class_template3::q<int>::{lambda(int&)#1}
13. 5 类模板的实例化及特化
- 可采用“template 类名<类型实参列表>”的形式显示直接实例化类模板。参见例13.14中的:template A
;。 - 也可在变量、函数参数、返回类型等定义时实例化类模板。
- 实例化生成的实例类同类模板的作用域相同。使用非类型形参的模板必须用常量作为非类型形参的实参。
- 当实例化生成的类实例、函数成员实例不合适时,可以自定义(特化)类、函数成员隐藏编译自动生成的类实例或函数成员。
【例13.13】
template <class T>
class VECTOR //定义主类模板
{
T* data;
int size;
public:
VECTOR(int n) : data(new T[n]), size(data ? n : 0) { };
virtual ~VECTOR() noexcept { //实例类的析构函数将成为虚函数
if (data) { delete data; data = nullptr; size = 0; }
cout << "DES O\n";
};
T& operator[ ](int i) { return data[i]; };
};
template < > //定义特化的字符指针向量类
class VECTOR <char*>
{
char** data;
int size;
public:
VECTOR(int); //特化后其所属类名为VECTOR <char*>
~VECTOR() noexcept; //特化后其所属类名为VECTOR <char*>,不是虚函数
virtual char*& operator[ ](int i) { return data[i]; }; //特化后为虚函数
};
VECTOR <char*>::VECTOR(int n) //使用特化后的类名VECTOR <char*>
{
data = new char* [size = n];
for (int i = 0; i < n; i++) data[i] = 0;
}
//如果类模板定义了虚函数,由编译器自动实例化产生的实例类的对应函数是虚函数。但如果自己定义特化类,可以修改为非虚函数。
//特化就是自己定义实例类,不是由编译器自动产生。
VECTOR <char*>::~VECTOR() noexcept //使用特化后的类名VECTOR <char*>
{
if (data == nullptr) return;
for (int i = 0; i < size; i++) delete data[i];
delete data; data = nullptr;
cout << "DES C\n";
}
class A : public VECTOR<int> { //VECTOR<int>是类模板的实例类,由编译器自动产生,A继承VECTOR<int>
public:
A(int n) : VECTOR<int>(n) { }; //调用父类VECTOR<int>的构造函数
~A() { cout << "DES A\n"; } //自动成为虚函数:因为基类析构函数是虚函数
};
class B : public VECTOR<char*> {//VECTOR<char *>是自定义的特化实例类,B继承VECTOR<char *>
public:
B(int n) : VECTOR<char*>(n) { };
~B() noexcept { cout << "DES B\n"; }//特化的VECTOR<char *>析构函数不是虚函数,故~B也不是
};
void main(void)
{
VECTOR <int> LI(10); //自动生成的实例类VECTOR <int>
VECTOR <char*> LC(10); //优先使用特化的实例类VECTOR<char*>
VECTOR<int>* p = new VECTOR<int>(3);
delete p;
p = new A(3); //VECTOR<int>是A的父类,父类指针指向子类对象
delete p;
VECTOR<char*>* q = new VECTOR<char*>(3);
delete q;
q = new B(3); //VECTOR<char *>是B的父类,父类指针指向子类对象
delete q;
}
//除了可以特化整个类外,还可以仅特化部分函数成员,见例13.18中的:
//template < > VECTOR <char*>::~VECTOR() noexcept { }
- 在定义类模板时,可以使用类模板的类型形参进行类型推导。
- 实例类可以作为基类
- 实例函数可以成为类的友元函数
【例13.19】 定义模板类实例作为基类,模板函数实例作为友元
定义Lambda模板和自动类型推导
template<class T>
class A { //定义主类模板
T i;
public:
A(T x) { i = x; }
virtual operator T() { //重载强制类型转换()
auto x = [this]()->T {return this->i; }; //定义Lmabda表达式模板,必须显式捕获this,返回this->i
return x(); //返回调用Lambda得到的值
// return i; //上面代码只是演示Lambda表达式。直接返回i也可。
}
};
template<class T>
void output(T& x) { cout << x.k; } //定义函数模板
//定义派生类B时,自动生成实例类A<int>作为B的父类
class B :public A<int> {
int k;
friend void output<B>(B&); //生成模板函数实例并将其作为B的友元
public:
B(int x) :A<int>(x) { k = x; } //必须显式调用父类构造
operator int() { return k + A<int>::operator int(); } //自动成为虚函数
};
void test() {
A<int> a(4); //自动从模板类生成实例类A<int>
auto b = a; //b的类型推导为A<int>
auto c = a.operator int(); //c的类型:int
auto d = A<double>(5); //d的类型为A<double>
//e为double,自动调用 A<double>::operator double()
auto e = 1 + A<double>(5);
B f(6); output(f);
}
- 类模板或类模板的实例均可以定义实例成员指针。见如下例13.20。
- 实例化类模板时,类模板中的成员指针类型随之实例化。
- 当使用类模板的实例化类,作为类模板实例化的实参时,会出现嵌套的实例化现象。原本没有问题的类型形参T,用实参int实例化new T[10]时没有问题;但在嵌套实例化时,若用A
实例化new T[10]时,则会要求类模板A定义定义无参构造函数A ::A()。 - 若类模板中使用非类型形参,实例化时使用表达式很可能出现“>”,导致编译误认为模板参数列表已经结束,此时可用“()” 如List<int, (3>2)> L1(8);,见例子13.21。
- 类模板常用在STL标准类库等需要泛型定义的场合。见如下例13.20:注意其中类型转换static_cast等的用法。
【例13.20】实例类的实例成员指针和静态成员指针的用法。
template <class T, int n = 10>
struct A {
static T t;
T u;
T* v;
T A::* w; //实例成员指针指向A的T类型成员
T A::* A::* x; //实例成员指针指向A的T A::*类型成员
T A::** y; //普通指针y指向T A::*类型成员
T* A::* z; //实例成员指针指向A的T* 类型成员
A(T k = 0, int h = n); //因A( )被调用,故必须定义A( ),等价于调用A(0, n)
~A() { delete[]v; }
};
template <class T, int n> T A<T, n>::t = 0; //类模板静态成员的初始化
template <class T, int n>
A<T, n>::A(T k, int h) //不得再次为h指定默认值,因为其类模板已指定
{
u = k;
v = new T[h]; //初始化数组对象,必须调用无参构造函数T( )
w = &A::u;
x = &A::w;
y = &w;
z = &A::v;
v = &A::t; // &A::t:取静态成员t的地址,因此v是普通指针
}
template struct A<double>; //从类模板生成实例类A<double,10>
int main(void)
{
A<int> a(5); //等价于“A<int,10> a(5);”
int u = 10, * v = &u;
int A<int>::* w = &A<int>::u; //等价于“int A<int, 10>::* w;”
int A<int>::* A<int>::* x = &A<int>::w;
int A<int>::** y = &w;
int* A<int>::* z = &A<int>::v;
v = &A<int>::t;
v = &a.u;
y = &a.w;
//使用类模板的实例化类A<int>,作为类模板A(外面一层A)实例化的类型实参时,出现嵌套的实例化现象
A<A<int>> b(a); //等价于“A<A<int,10>, 10> b(a);”,构造b时调用 A<int>::A( )构造a
A<int> A<A<int>>::* c = &A<A<int>>::u;
a = b.*c;
A<int> A<A<int>>::* A<A<int>>::* d = &A<A<int>>::w;
}
【例13.22】定义用两个栈模拟一个队列的类模板
template <typename T> //定义主类模板
class STACK {
T* const elems; //申请内存,用于存放栈的元素
const int max; //栈能存放的最大元素个数
int pos; //栈实际已有元素个数,栈空时pos=0;
public:
STACK(int m = 0); //等价于定义了STACK(),防嵌套实例化出问题
STACK(const STACK& s); //用栈s初始化p指向的栈
STACK(STACK&& s)noexcept; //用栈s初始化p指向的栈
virtual T operator [ ] (int x)const; //返回x指向的栈的元素
virtual STACK& operator<<(T e); //将e入栈,并返回p
virtual STACK& operator>>(T& e); //出栈到e,并返回p
virtual ~STACK()noexcept; //销毁p指向的栈
……
};
template <typename T>
STACK<T>::STACK(STACK&& s) noexcept : elems(s.elems), max(s.max), pos(s.pos) {
const_cast<T*&>(s.elems) = nullptr; // 等价于*(T**)&(s.elems) = nullptr;
const_cast<int&>(s.max) = s.pos = 0;
}
template <typename T>
class QUEUE : public STACK<T> {
STACK<T> s2; //队列首尾指针
public:
QUEUE(int m = 0); //初始化队列:最多m个元素
QUEUE(const QUEUE& s); //用队列s复制初始化队列
QUEUE(QUEUE&& s) noexcept; //移动构造
virtual QUEUE& operator=(QUEUE&& s) noexcept; //移动赋值
~QUEUE()noexcept; //销毁队列
……
};
【例13.20】定义用两个栈模拟一个队列的类模板
template <typename T>
//以下初始化一定要用move, 否则QUEUE是移动赋值而其下层是深拷贝赋值
QUEUE<T>::QUEUE(QUEUE&& s) noexcept: STACK<T>(move(s)), s2(move(s.s2)) { }
template <typename T>
QUEUE<T>& QUEUE<T>::operator=(QUEUE<T>&& s) noexcept {
//以下赋值一定用static_cast,否则QUEUE是移动赋值而其下层是深拷贝赋值
*(STACK<T>*)this = static_cast<STACK<T>&&>(s);
//等价于STACK<T>::operator=(static_cast<STACK<T>&&>(s));
//或等价于STACK<T>::operator=(std::move(s));
s2 = static_cast<STACK<T>&&>(s.s2);
//等价于“s2=std::move(s.s2);”,可用“std::move”代替“static_cast<STACK<T>&&>”
return *this;
}
- 为解决内存泄漏问题,可像Java那样定义一个始祖基类Object。
- 所有其他类都从Object继承,比如Name。参见例13.21。
- 定义一个Type类模板,用于管理类Name的对象引用计数,若对象被引用次数为0,则可析构该对象。Type类模板的构造函数使用Name*作为参数,一遍所有Name的对象都是通过new产生的。 Type类模板的赋值运算符重载函数负责对象的引用计数。
- 当要使用Name产生对象时,可用Name作为类模板Type的类型实参,产生实例化类,然后使用该实例化类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号