

PHP是一门很灵活的语言。正因为它太灵活了,甚至有些怪异,所以大家对它的评价褒贬不一。其实我想说的是,任何一门语言都有它自身的哲学,有它存在的出发点。PHP为Web而生,它以快速上手、快速开发而著称,所以它也常被冠以简单、新手用的语言等标签。我倒不这么认为,所谓选对的工具去做对的事,没有包打天下的语言。而至于说其简单,倒也未必。
目录[-]
PHP是一门很灵活的语言。正因为它太灵活了,甚至有些怪异,所以大家对它的评价褒贬不一。其实我想说的是,任何一门语言都有它自身的哲学,有它存在的出发点。PHP为Web而生,它以快速上手、快速开发而著称,所以它也常被冠以简单、新手用的语言等标签。我倒不这么认为,所谓选对的工具去做对的事,没有包打天下的语言。而至于说其简单,却也未必。
引子
我之前有篇文详细介绍过pack和unpack:PHP: 深入pack/unpack ,如果有不明白的地方,建议再回过头去看多几遍。现在应该能够写出以下代码:
|
1
2
|
<?phpecho pack("C", 97) . "\n"; |
|
1
2
|
$ php -f test.phpa |
但是,为什么会输出'a'呢?虽然我们知道字符'a'的ASCII码就是97,但是pack方法返回的是二进制字符串,为什么不是输出一段二进制而是'a'?为了确认pack方法返回的是一段二进制字符串,这里我对官方的pack的描述截了个图:

确实如此,pack返回包含二进制字符串的数据,接下来详细进行分析。
程序是如何显示字符的
这里所说的'程序',其实是个宏观的概念。
对于在控制台中执行脚本(这里是指PHP作为cli脚本来执行),脚本的输出会写入标准输出(stdin)或标准错误(stderr),当然也有可能会重定向到某个文件描述符。拿标准输出来说,暂且忽略它是行缓冲、全缓冲或者是无缓冲。脚本进程执行完毕后如果有输出则会在控制台上输出字符串。那这里的控制台就是所说的'程序'。
对于Web来说(这里是指PHP作为Web的服务器端语言),程序执行完后会将结果响应给浏览器或其它UserAgent,为了方便描述,这里统一称为UserAgent。这里的UserAgent就是所说的'程序'。
当然还有其它情况,比如在GUI窗口中的输出,编辑器打开一个文件等等,这都涉及到如何显示字符串的问题。
在控制台中执行
控制台通过shell命令来执行脚本,它会fork一个子进程,之后通过exec替换子进程的地址空间,因为这个子进程不是会话首进程,所以它可以关联到控制终端。脚本输出执行完毕后退出,回到控制台。来看下面的例子:
|
1
2
3
|
<?php$str = '回';echo $str . "\n"; |
|
1
2
|
$ php -f test.php回 |
test.php是UTF-8编码的文件,我的Linux系统的Locales是zh_CN.UTF-8。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$ localeLANG=zh_CN.UTF-8LANGUAGE=LC_CTYPE="zh_CN.UTF-8"LC_NUMERIC="zh_CN.UTF-8"LC_TIME="zh_CN.UTF-8"LC_COLLATE="zh_CN.UTF-8"LC_MONETARY="zh_CN.UTF-8"LC_MESSAGES="zh_CN.UTF-8"LC_PAPER="zh_CN.UTF-8"LC_NAME="zh_CN.UTF-8"LC_ADDRESS="zh_CN.UTF-8"LC_TELEPHONE="zh_CN.UTF-8"LC_MEASUREMENT="zh_CN.UTF-8"LC_IDENTIFICATION="zh_CN.UTF-8"LC_ALL= |
回到刚才的代码,test.php是UTF-8编码的文件,汉字'回'是三个字节表示的UTF8字符(如果不明白,可以看我的另一篇文章:JavaScript: 详解Base64编码和解码),所以test.php文件的内容保存在硬盘上的数据就是4个字节('\n'是ASCII字符,用1个字节表示)。test.php执行输出时,将这4个字节发送到标准输出,之后被冲洗(这里忽略掉被flush的时机),由控制台来显示。回想一下Linux系统上的locale设置,很显然是采用UTF8的机制来显示字符,所以前三个字节被当成一个UTF8字符,它被组合在一起转成Unicode码然后查表,再显示出来。
|
1
2
3
4
|
<?php$str = '回';echo $str . "\n";echo $str{0} . $str{1} . $str{2} . "\n"; |
|
1
2
3
|
$ php -f test.php回回 |
可以看到,不管是整个字符输出,还是三个字节连在一起输出,结果是一样的。我们接下来看看不同平台上同一个字符的Unicode编码和UTF-8编码是否一样:
PHP测试:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?php$str = '回';$bin = pack("C3", ord($str{0}), ord($str{1}), ord($str{2}));$hex = strtoupper(bin2hex($bin));echo "UTF-8编码: " . $hex . "\n";/*** 1110xxxx 10xxxxxx 10xxxxxx*/$byte1 = ord($str{0});$byte2 = ord($str{1});$byte3 = ord($str{2});$c1 = (($byte1 & 0x0F) << 4) | (($byte2 & 0x3F) >> 2);$c2 = (($byte2 & 0x03) << 6) | ($byte3 & 0x3F);$dec = (($c1 & 0x00FF) << 8) | $c2;echo "Unicode编码: " . $dec . "\n"; |
|
1
2
3
|
$ php -f test.phpUTF-8编码: E59B9EUnicode编码: 22238 |
JavaScript测试:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<script type="text/javascript">/*** UTF16和UTF8转换对照表* U+00000000 – U+0000007F 0xxxxxxx* U+00000080 – U+000007FF 110xxxxx 10xxxxxx* U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx* U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx* U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx* U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx*/var code = ('回').charCodeAt(0);// 1110xxxxvar byte1 = 0xE0 | ((code >> 12) & 0x0F);// 10xxxxxxvar byte2 = 0x80 | ((code >> 6) & 0x3F);// 10xxxxxxvar byte3 = 0x80 | (code & 0x3F);console.group('Test chr: ');console.log("UTF-8编码:", byte1.toString(16).toUpperCase() + '' + byte2.toString(16).toUpperCase() + '' + byte3.toString(16).toUpperCase());console.log("Unicode编码: ", code);console.groupEnd();</script> |

我们看到输出是一样的。
作为Web的服务器端语言执行
这次无非是由刚才的控制台执行变成了UserAgent,其实道理还是一样的。服务器端PHP脚本输出会通过HTTP的响应返回给UserAgent,那么UserAgent就要对它进行显示。当然,这里还有点例外。数据是通过网络作为字节流发送回UserAgent,通常UserAgent有几种方式来判断字节流是属于什么编码(或许还涉及到压缩,但这里将不考虑这个因素)。
服务器端可以通过响应头部来告诉UserAgent应该用什么编码来处理这些数据,比如:
|
1
2
|
<?phpheader("Content-Type: text/html; charset=utf8"); |
或者是HTML页面中的<meta />标签,比如:
|
1
|
<meta charset="utf-8" /> |
但是万一这两种方式都没有提供,那也只能靠猜了。事实也确实如此,据我所知,Firefox就是这么做的,并且将代码开源了:universalchardet 。但是这种方式并不能百分之百正确检测,所以偶尔会访问到乱码的页面。
编辑器打开一个文件
在windows上用notepad新建文本文件另存为时有几种编码选项:ANSI, Unicode, Unicode BigEndian, UTF-8。

在其它编辑器中选项更多,包括有BOM和无BOM的。BOM是文件头的前几个字节,通过BOM,处理它的程序就知道这个文件是采用什么编码,并且是什么字节序。然而在PHP中,从来都没有将BOM考虑进去,所以PHP解释器去执行一个PHP文件时,不会忽略前几个BOM字节,这就导致了问题。一般的问题在于发送cookie前,BOM被输出了。所以现在一般推荐无BOM的文件。
无BOM有时候也是会有问题的,因为这需要处理它的程序去检测它是什么编码。检测的方式一般是扫描文件,然后根据不同编码的规则来判断二进制。这里举一个出现问题的例子。在windows上新建一个文本文件并保存为ANSI编码,然后在文件中输入'联通',如图所示:
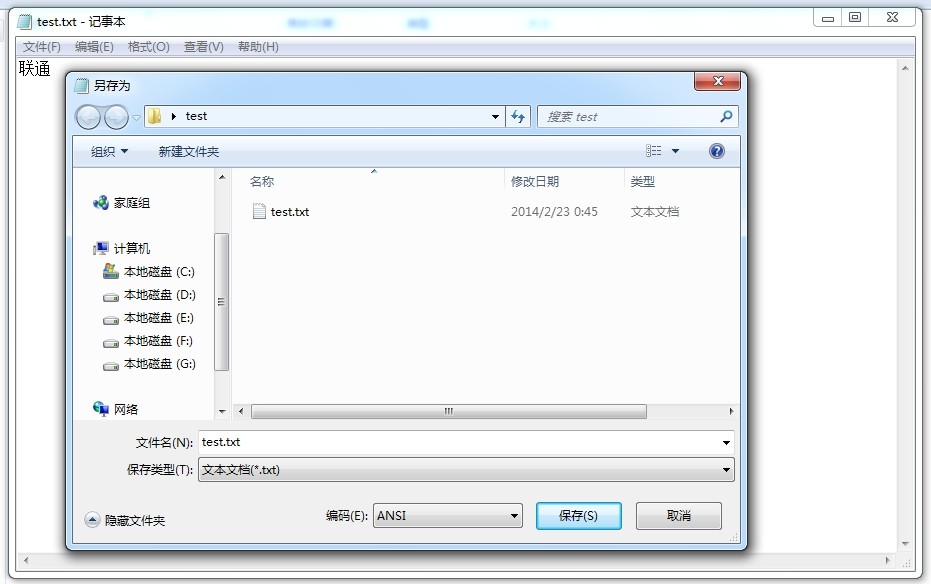
保存好后关闭test.txt文件,然后再双击打开,如图所示:

我们看到显示的是乱码,具体我们可以分析一下产生乱码的原因。用Editplus新建一个ANSI文件,输入'联通',然后切换到十六进制查看方式,如下图所示:

对应的十六进制是:C1 AA CD A8,转成二进制后如下:
|
1
|
11000001 10101010 11001101 10101000 |
接着我们来看下UTF-8的转换表:
|
1
2
3
4
5
6
|
U+00000000 – U+0000007F 0xxxxxxxU+00000080 – U+000007FF 110xxxxx 10xxxxxxU+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxxU+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxxU+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxxU+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
很显然都被当作了二字节的UTF-8字符,拿GBK的编码去UTF-8的码表里查,您说能查到吗?
总结
现在我们已经知道了不管是什么编码的数据,总是一个字节一个字的存储,并且在存储时会进行相应的编码转换。比如汉字'回'的GBK编码和UTF-8编码的字节数和编码值都不一样,所以在将GBK的文件另存为UTF-8时必然会存在转换,反之也是一样的。而在读取时如果有BOM就按BOM规定的编码来处理,否则要进行编码检测后再处理。
再说pack
之前讲了这么多编码方面的问题,其实就是为了让大家更好的理解接下来要讲的。pack可以将ASCII进行打包然后输出(事实上就是将一个多字节变成多个单字节,之后可以通过unpack转换回来),这个我们已经知道了。但是方式有很多种,原理是一样的。我们来详细分析。对pack/unpack不太熟悉的还是建议去翻看我之前的一篇文章:PHP: 深入pack/unpack 。因为本人的机器是小端序的,所以本文只考虑小端序。大端序是一样的方式,只不过字节序不一样罢了,可以先判断本机的字节序再处理。
|
1
2
3
4
5
6
7
|
<?phpecho pack("C", 0x61) . "\n";echo pack("S", 0x6161) . "\n";echo pack("L", 0x61616161) . "\n";echo pack("L", 0x9E9BE561) . "\n";echo chr(0xE5) . chr(0x9B) . chr(0x9E) . "\n";echo pack("H6", "E59B9E") . "\n"; |
|
1
2
3
4
5
6
7
|
$ php -f test.phpaaaaaaaa回回回 |
我们一句句的来分析,首先是:
|
1
2
3
|
echo pack("C", 0x61) . "\n";echo pack("S", 0x6161) . "\n";echo pack("L", 0x61616161) . "\n"; |
这三句代码很简单,C是无符号字节,S是2个无符号字节,L是4个无符号字节,所以输出也没什么疑问。无论几个字节,都是ASCII码,0x61的二进制的高位为0,所以能正确显示。
|
1
|
echo pack("L", 0x9E9BE561) . "\n"; |
我们或许还记得汉字'回'的UTF-8编码为:0xE59B9E,L是按主机字节序打包的,而我的机器是小端序,所以0x9E9BE561打包后就变为:0x61E59B9E。0x61是字符'a'的ASCII码,而后面的三个字节程序通过判断0xE5就能知道这是一个三字节的UTF-8字符,因此这三个字节会转成Unicode码去查表,然后显示。
|
1
|
echo chr(0xE5) . chr(0x9B) . chr(0x9E) . "\n"; |
chr是返回ASCII码所代码的字符,它其实不仅仅是转换单字节的字符,对于多字节同样适用。它会根据刚才所说的规则将三个UTF-8字节转成Unicode码然后去查表。
|
1
|
echo pack("H6", "E59B9E") . "\n"; |
对于H格式字符,它和h的区别就是前者是高四位在前,后者是低四位在前,但它们都是以半字节为单位读取的,并且以十六进制的方式。您应该看到我在用H进行打包时传的是字符串"E59B9E",如果传的是0xE59B9E就不对了,这样的话先会转成十进制15047582,然后在前面加上0x变成十六进制0x15047582。
所谓按半字节读取其实是这样的,比如0x47,先转成十进制71,然后变成十六进制的0x71。按半字节读取必然会丢弃4位,然后要补0。读取了0x7,对H来说,它是高位,那么在低位补0变成0x70。对于h来说,它是低位,那么在高位补0变成0x07。
再说unpack
unpack是pack的逆函数,当然unpack有自己的语法,但这不是重点,因为这些只是表象。
unpack其实只是将多个字节压缩成一个字节。比如0x12和0x34这两个字节如果要组成一个双字节,则可以使用unpack的S格式化字符来实现,代码如下:
|
1
2
3
4
|
<?php$data = unpack("S", pack("H*", "3412"));print_r($data);echo '0x' . dechex($data[1]) . "\n"; |
|
1
2
3
4
5
6
|
$ php -f test.phpArray( [1] => 4660)0x1234 |
因为是小端序,所以要写成"3421"。其实还可以用位运算的方式来实现。这个时候就不需要考虑字节序了,因为字节序只是存储时才需要考虑的问题,对于输出来说,是按照我们自然的方式:
|
1
2
|
<?phpprint "0x" . dechex((0x12 << 8) | 0x34) . "\n"; |
|
1
2
|
$ php -f test.php0x1234 |
再说chr
PHP官方文档上所描述的chr方法的原型参数是一个int型,虽然形参名为ascii,但不要被骗了。如图所示:

chr确实是可以接收一个int类型的参数,而不仅仅是一个ASCII码。还记得之前所做的测试吗?通过chr方法将三个UTF-8的字节组合在一起。很显然UTF-8的每个字节都大于127,因为最高位都是1。
不过说起来chr方法还是比较傻的,比如有如下代码:
|
1
2
3
|
<?phpecho chr(0xE5) . chr(0x9B) . chr(0x9E) . "\n";echo chr(0xE59B9E) . "\n"; |
|
1
2
3
|
$ php -f test.php回? |
chr方法完全没有考虑将0xE59B9E拆成三个字节来组合,所以最终是乱码。
再说ord
ord接受一个string类型的参数,它用于返回参数的ASCII码。如下图所示:

虽然它只返回ASCII码,但它的参数却不限定。比如您可以传递单字节或多字节。举例如下:
|
1
2
3
4
|
<?phpecho ord("a") . "\n";echo ord("回") . "\n";echo 0xE5 . "\n"; |
|
1
2
3
4
|
$ php -f test.php97229229 |
传入汉字'回',它会自动截取第一个字节,然后返回它的十进制表示。
实现自己的pack/unpack
理解了原理,其实自己去实现也就是那么回事。本文以格式化字符L为例,L是无符号32位整型,它是按主机字节序来打包的。所以我们要先判断机器的字节序。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?phpfunction IsBigEndian(){ $bin = pack("L", 0x12345678); $hex = bin2hex($bin); if (ord(pack("H2", $hex)) === 0x78) { return FALSE; } return TRUE;}if (IsBigEndian()){ echo "大端序";}else{ echo "小端序";}echo "\n"; |
|
1
2
|
$ php -f test.php小端序 |
代码非常简单,因为PHP不能直接操作内存,所以借助于pack来实现。L格式化字符表示主机字节序,如果机器是小端序,则0x12345678通过L打包后会变成4个字节并且字节序是:0x78, 0x56, 0x34, 0x12,如果是大端序则是:0x12, 0x34, 0x56, 0x78。然后通过H2格式化字符获取2个高4位(即一个高位字节),如果是0x78那就是小端序,否则就是大端序。
接下来是my_pack方法的实现,仅仅实现了L格式化字符,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
<?php// 判断字节序function IsBigEndian(){ $bin = pack("L", 0x12345678); $hex = bin2hex($bin); if (ord(pack("H2", $hex)) === 0x78) { return FALSE; } return TRUE;}// 自定义打包方法function my_pack($num){ $bin = ""; $padding = 0; if ($num >= 0x00 && $num <= 0xFF) { // 补3个字节 $padding = str_repeat(chr(0), 3); if (IsBigEndian()) { // 大端序 $bin = $padding . chr($num); } else { // 小端序 $bin = chr($num) . $padding; } } else if ($num > 0xFF && $num <= 0xFFFF) { // 补2个字节 $padding = str_repeat(chr(0), 2); $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = $padding . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . $padding; } } else if ($num > 0xFFFF && $num <= 0x7FFFFF) { // 补1个字节 $padding = chr(0); $byte2 = ($num >> 16) & 0xFF; $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = $padding . chr($byte2) . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . chr($byte2) . $padding; } } else { $byte1 = ($num >> 24) & 0xFF; $byte2 = ($num >> 16) & 0xFF; $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = chr($byte1) . chr($byte2) . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . chr($byte2) . chr($byte1); } } return $bin;}$bin = my_pack(0x12);print_r(unpack("L", $bin));$bin = pack("L", 0x12);print_r(unpack("L", $bin));$bin = my_pack(0x1234);print_r(unpack("L", $bin));$bin = pack("L", 0x1234);print_r(unpack("L", $bin));$bin = my_pack(0x123456);print_r(unpack("L", $bin));$bin = pack("L", 0x123456);print_r(unpack("L", $bin));$bin = my_pack(0x12345678);print_r(unpack("L", $bin));$bin = pack("L", 0x12345678);print_r(unpack("L", $bin)); |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
$ php -f test.phpArray( [1] => 18)Array( [1] => 18)Array( [1] => 4660)Array( [1] => 4660)Array( [1] => 1193046)Array( [1] => 1193046)Array( [1] => 305419896)Array( [1] => 305419896) |
测试中调用pack和my_pack的结果是一样的。unpack的实现就是pack的逆操作,只需把pack的结果的每一个字节取到它的ASCII码(可以通过ord方法来得到),然后将4个字节根据高低位次序(这还要根据大小端)通过位运算变成一个4字节的整数,其它格式化字符也是类似如此实现。接下来仅仅实现格式化字符L的unpack版本,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
|
<?php// 判断字节序function IsBigEndian(){ $bin = pack("L", 0x12345678); $hex = bin2hex($bin); if (ord(pack("H2", $hex)) === 0x78) { return FALSE; } return TRUE;}// 自定义打包方法function my_pack($num){ $bin = ""; $padding = 0; if ($num >= 0x00 && $num <= 0xFF) { // 补3个字节 $padding = str_repeat(chr(0), 3); if (IsBigEndian()) { // 大端序 $bin = $padding . chr($num); } else { // 小端序 $bin = chr($num) . $padding; } } else if ($num > 0xFF && $num <= 0xFFFF) { // 补2个字节 $padding = str_repeat(chr(0), 2); $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = $padding . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . $padding; } } else if ($num > 0xFFFF && $num <= 0x7FFFFF) { // 补1个字节 $padding = chr(0); $byte2 = ($num >> 16) & 0xFF; $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = $padding . chr($byte2) . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . chr($byte2) . $padding; } } else { $byte1 = ($num >> 24) & 0xFF; $byte2 = ($num >> 16) & 0xFF; $byte3 = ($num >> 8) & 0xFF; $byte4 = $num & 0xFF; if (IsBigEndian()) { // 大端序 $bin = chr($byte1) . chr($byte2) . chr($byte3) . chr($byte4); } else { // 小端序 $bin = chr($byte4) . chr($byte3) . chr($byte2) . chr($byte1); } } return $bin;}// 自定义解包方法function my_unpack($bin){ $byte1 = ord($bin{0}); $byte2 = ord($bin{1}); $byte3 = ord($bin{2}); $byte4 = ord($bin{3}); if (IsBigEndian()) { // 大端序 $num = ($byte1 << 24) | ($byte2 << 16) | ($byte3 << 8) | $byte4; } else { // 小端序 $num = ($byte4 << 24) | ($byte3 << 16) | ($byte2 << 8) | $byte1; } return array($num);}$bin = my_pack(0x12);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = pack("L", 0x12);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = my_pack(0x1234);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = pack("L", 0x1234);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = my_pack(0x123456);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = pack("L", 0x123456);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = my_pack(0x12345678);print_r(unpack("L", $bin));print_r(my_unpack($bin));$bin = pack("L", 0x12345678);print_r(unpack("L", $bin));print_r(my_unpack($bin)); |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
$ php -f test.phpArray( [1] => 18)Array( [0] => 18)Array( [1] => 18)Array( [0] => 18)Array( [1] => 4660)Array( [0] => 4660)Array( [1] => 4660)Array( [0] => 4660)Array( [1] => 1193046)Array( [0] => 1193046)Array( [1] => 1193046)Array( [0] => 1193046)Array( [1] => 305419896)Array( [0] => 305419896)Array( [1] => 305419896)Array( [0] => 305419896) |
知道了原理,实现起来就一点也不难,无非就是要注意字节序的问题。
关于ISO 8859-1编码
ISO 8859-1又称 Latin-1 或西欧语言。是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。
从定义可知,Latin-1编码是单字节编码,向下兼容 ASCII ,其编码范围是0x00~0xFF。0x00~0x7F之间完全和ASCII码一致,0x80~0x9F之间是控制字符,0xA0~0xFF之间是文字符号。
ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,MySQL数据库默认编码是Latin-1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。
结束语
pack/unpack在实际工作中用得非常多,因为很多公司用PHP做前端,通过TCP调用接口,这就需要用到pack/unpack来打包和解包。希望本文能对大家有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号