Python爬虫开发【第1篇】【正则表达式】
非结构化数据:HTML(正则表达式、XPath、CSS选择器)
结构化数据:JSON文件(JSON Path、转化为Python类型进行操作)
XML文件(转化成Python类型、XPath、CSS选择器)
1、正则表达式
它是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
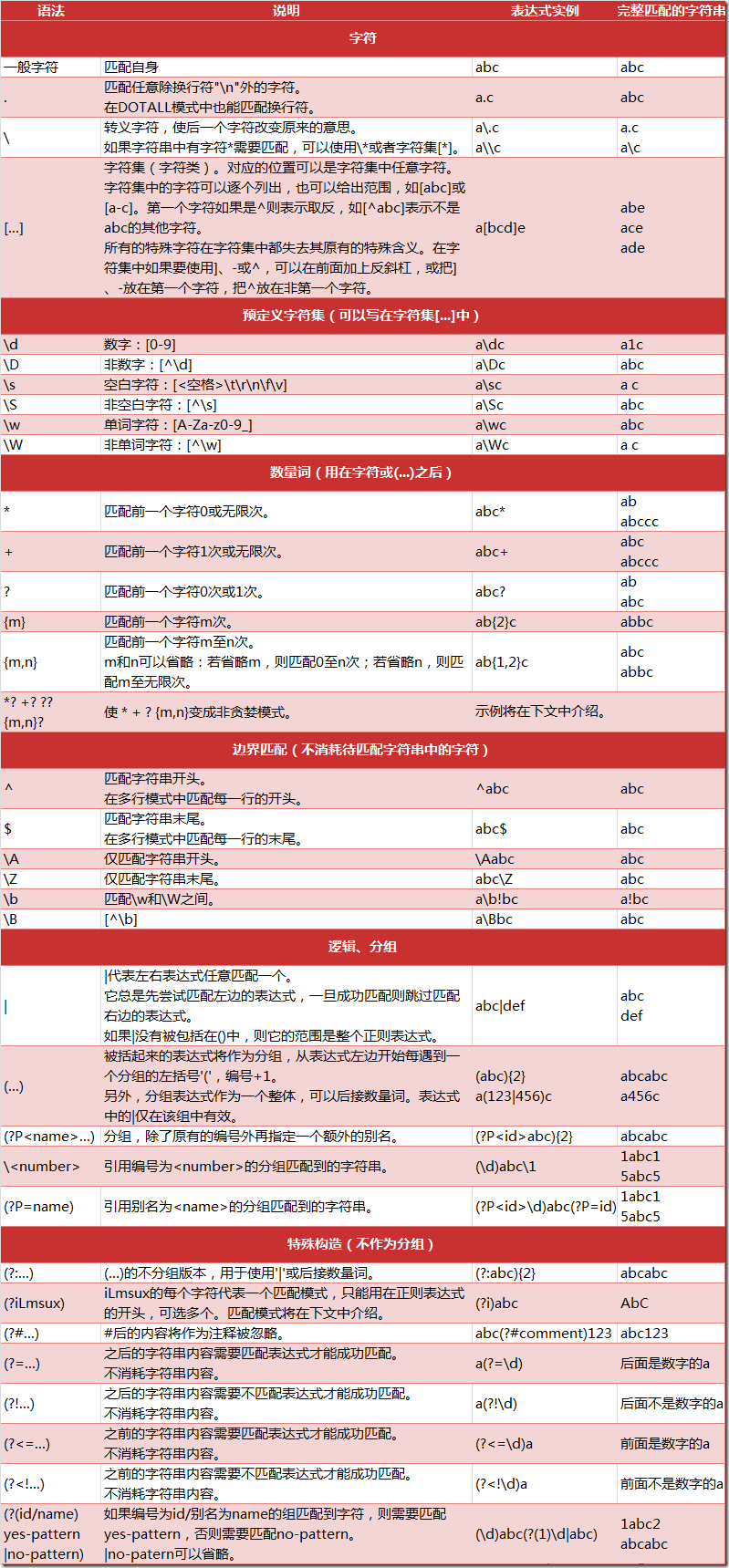
2、re模块
2.1、re模块使用步骤:
-
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 -
通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
2.2、compile()
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re # 将正则表达式编译成 Pattern 对象 pattern = re.compile(r'\d+')
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
2.2.1、match方法:
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。
它的一般使用形式如下:re.match(pattern, string, flags=0)
其中,pattern表示匹配的正则表达式,string 是要匹配的字符串,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
例1:
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象 <_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0 '12'
>>> m.start(0) # 可省略 0 3
>>> m.end(0) # 可省略 0 5
>>> m.span(0) # 可省略 0 (3, 5) group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,
当要获得整个匹配的子串时,可直接使用 group() 或 group(0); start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0; end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0; span([group]) 方法返回 (start(group), end(group))。
例2:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
2.2.2、Search方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,
它的一般使用形式如下:search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
例1:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
'34'
>>> m.span()
(13, 15)
例2:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 无法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 获得分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
执行结果:
matching string: 123456
position: (6, 12)
2.2.3、findall方法
findall可以搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
例1:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
执行结果:
['123456', '789']
['1', '2']
例2:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#通过partten.findall()方法就能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回全部能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
2.2.4、finditer方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
2.2.5、spilt方法
split 方法按照能够匹配的子串将字符串分割后返回列表,
它的使用形式如下:split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
执行结果:
['a', 'b', 'c', 'd']
2.2.6、sub方法
sub 方法用于替换。
它的使用形式如下:sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
-
-
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
-
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
-
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
2.2.7、匹配中文
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做: import re title = u'你好,hello,世界' pattern = re.compile(ur'[\u4e00-\u9fa5]+') result = pattern.findall(title) print result
正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。 执行结果: [u'\u4f60\u597d', u'\u4e16\u754c']
3、贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
例1 : 源字符串:abbbc
使用贪婪的数量词的正则表达式 ab* ,匹配结果: abbb。 * 决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。 使用非贪婪的数量词的正则表达式ab*?,匹配结果: a。 即使前面有 *,但是 ? 决定了尽可能少匹配 b,所以没有 b。
例2: 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:<div>.*</div> 匹配结果:<div>test1</div>bb<div>test2</div> 这里采用的是贪婪模式。在匹配到第一个“</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>”
5、正则表达式爬虫案例:
5.1、目标:爬取内涵段子网站: http://www.neihan8.com/article/list_5_1.html
5.2、获取数据:
5.2.1、需要一个加载页面的方法
统一定义一个类,将url请求作为一个成员方法处理。
创建一个文件,叫duanzi_spider.py
然后定义一个Spider类,并且添加一个加载页面的成员方法
import urllib2
class Spider:
"""
内涵段子爬虫类
"""
def loadPage(self, page):
"""
@brief 定义一个url请求网页的方法
@param page 需要请求的第几页
@returns 返回的页面html
"""
url = "http://www.neihan8.com/article/list_5_" + str(page) + ".html"
#User-Agent头
user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT;6.1; Trident/5.0')
headers = {'User-Agent': user_agent}
req = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(req)
html = response.read()
print html
#return html
5.2.2、 写main函数测试一个loadPage方法
if __name__ == '__main__':
"""
======================
内涵段子小爬虫
======================
"""
print '请按下回车开始'
raw_input()
#定义一个Spider对象
mySpider = Spider()
mySpider.loadpage(1)
程序正常执行的话,我们会在屏幕上打印了内涵段子第一页的全部html代码。 但是我们发现,html中的中文部分显示的可能是乱码 。
5.2.3、乱码问题解决办法
对源码进行处理:
def loadPage(self, page):
"""
@brief 定义一个url请求网页的方法
@param page 需要请求的第几页
@returns 返回的页面html
"""
url = "http://www.neihan8.com/article/list_5_" + str(page) + ".html"
#User-Agent头
user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT;6.1; Trident/5.0')
headers = {'User-Agent': user_agent}
req = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(req)
html = response.read()
gbk_html = html.decode('gbk').encode('utf-8')
# print gbk_html
return gbk_html
注意 :对于每个网站对中文的编码各自不同,所以html.decode(‘gbk’)的写法并不是通用写法,根据网站的编码而异
5.3、筛选数据
- 首先:
import re 然后, 在得到的gbk_html中进行筛选匹配- 编写匹配规则
def loadPage(self, page):
"""
@brief 定义一个url请求网页的方法
@param page 需要请求的第几页
@returns 返回的页面html
"""
url = "http://www.neihan8.com/article/list_5_" + str(page)
+ ".html"
#User-Agent头
user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT
6.1; Trident/5.0'
headers = {'User-Agent': user_agent}
req = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(req)
html = response.read()
gbk_html = html.decode('gbk').encode('utf-8')
#找到所有的段子内容<div class = "f18 mb20"></div>
#re.S 如果没有re.S 则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配
# 如果加上re.S 则是将所有的字符串将一个整体进行匹配
pattern = re.compile(r'<div.*?class="f18 mb20">(.*?)</div>', re.S)
item_list = pattern.findall(gbk_html)
return item_list
def printOnePage(self, item_list, page):
"""
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page 处理第几页
"""
print "******* 第 %d 页 爬取完毕...*******" %page
for item in item_list:
print "================"
print ite
这里需要注意一个是re.S是正则表达式中匹配的一个参数。
如果 没有re.S 则是 只匹配一行 有没有符合规则的字符串,如果没有则下一行重新匹配。
如果 加上re.S 则是将 所有的字符串 将一个整体进行匹配,findall 将所有匹配到的结果封装到一个list中。
然后我们写了一个遍历item_list的一个方法 printOnePage() 。 ok程序写到这,我们再一次执行一下。
Power@PowerMac ~$ python duanzi_spider.py
我们第一页的全部段子,不包含其他信息全部的打印了出来。
你会发现段子中有很多 <p> , </p> 很是不舒服,实际上这个是html的一种段落的标签。
在浏览器上看不出来,但是如果按照文本打印会有<p>出现,那么我们只需要把我们不希望的内容去掉即可了。
我们可以如下简单修改一下 printOnePage().
def printOnePage(self, item_list, page):
"""
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page 处理第几页
"""
print "******* 第 %d 页 爬取完毕...*******" %page
for item in item_list:
print "================"
item = item.replace("<p>", "").replace("</p>", "").repl
ace("<br />", "")
print item
5.4、保存数据
def writeToFile(self, text):
'''
@brief 将数据追加写进文件中
@param text 文件内容
'''
myFile = open("./duanzi.txt", 'a') #追加形式打开文件
myFile.write(text)
myFile.write("---------------------------------------------
--------")
myFile.close()
然后我们将print的语句 改成writeToFile() ,当前页面的所有段子就存在了本地的MyStory.txt文件中。
def printOnePage(self, item_list, page):
'''
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page 处理第几页
'''
print "******* 第 %d 页 爬取完毕...*******" %page
for item in item_list:
# print "================"
item = item.replace("<p>", "").replace("</p>", "").repl
ace("<br />", "")
# print item
self.writeToFile(item)
5.5、显示数据
def doWork(self):
'''
让爬虫开始工作
'''
while self.enable:
try:
item_list = self.loadPage(self.page)
except urllib2.URLError, e:
print e.reason
continue
#对得到的段子item_list处理
self.printOnePage(item_list, self.page)
self.page += 1 #此页处理完毕,处理下一页
print "按回车继续..."
print "输入 quit 退出"
command = raw_input()
if (command == "quit"):
self.enable = False
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号