ElasticSearch 准实时原理
Elasticsearch 是一个基于 Lucene 库的搜索引擎。它提供了一个准实时的、分布式、支持多租户的全文搜索引擎。 ————维基百科
那么问题来了,为啥 Elasticsearch 不是实时的,是什么阻碍了它的实时性?
文章引用自:https://juejin.im/post/5d1b35a1e51d45775746b990
概念
elasticsearch 被称为准实时搜索,原因是对 Elasticsearch 的写入操作成功后,写入的数据需要1秒钟后才能被搜索到,因此 Elasticsearch 搜索是准实时或者又称为近实时(near real time)。
elasticsearch底层使用的 Lucene,而 Lucene 的写入是实时的。但 Lucene 的实时写入意味着每一次写入请求都直接将数据写入硬盘,因此频繁的I/O操作会导致很大的性能问题。
原理
图1 表示是 es 写操作流程,当一个写请求发送到 es 后,es 将数据写入 memory buffer 中,并添加事务日志(translog)。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
因此 es 在设计时在 memory buffer 和硬盘间加入了 Linux 的页面高速缓存(File system cache)来提高 es 的写效率。
当写请求发送到 es 后,es 将数据暂时写入 memory buffer 中,此时写入的数据还不能被查询到。默认设置下,es 每1秒钟将 memory buffer 中的数据 refresh 到 Linux 的 File system cache,并清空 memory buffer,此时写入的数据就可以被查询到了。
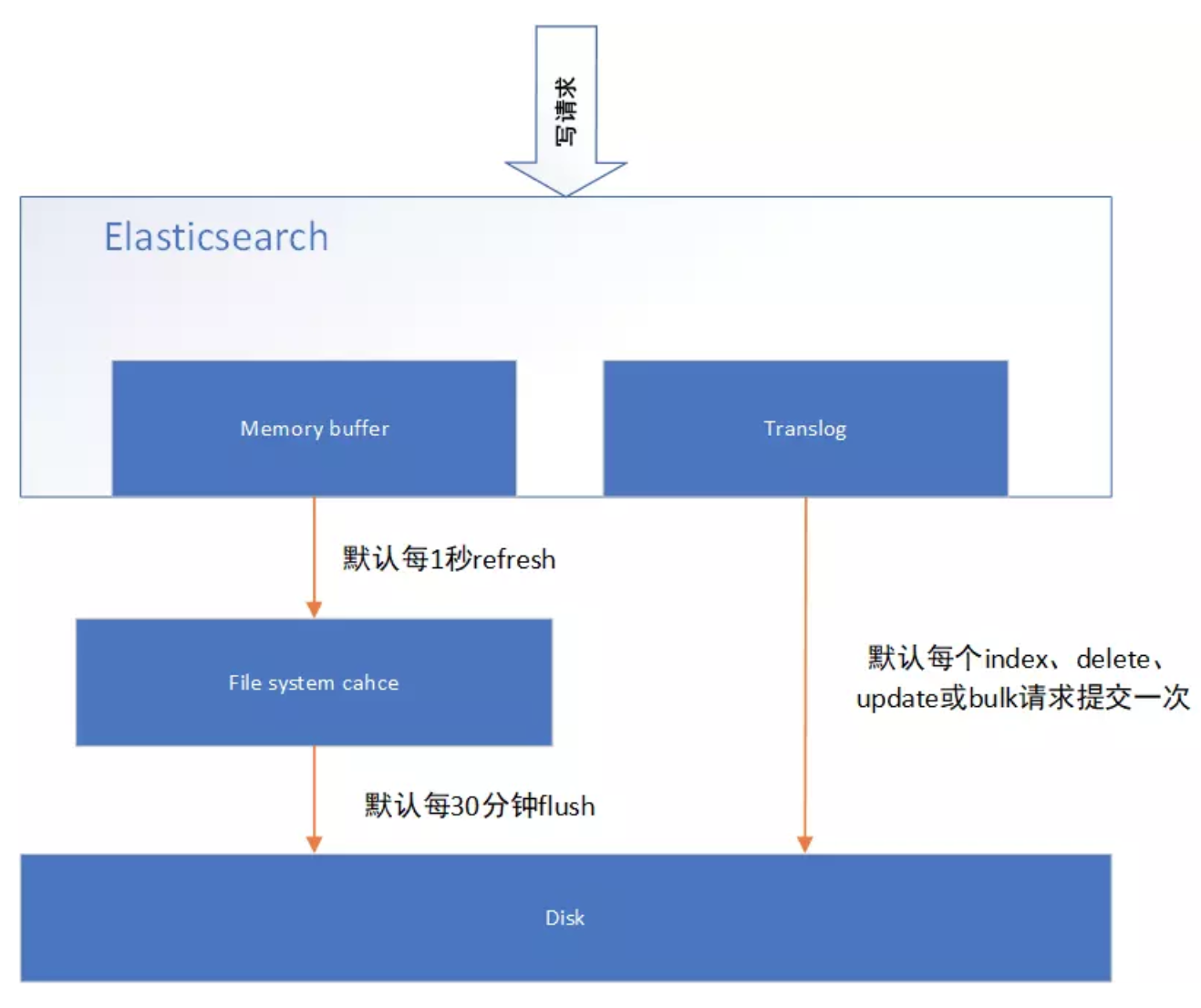 图1 ElasticSearch 日志写入
图1 ElasticSearch 日志写入
但 File system cache 依然是内存数据,一旦断电,则 File system cache 中的数据全部丢失。默认设置下,es 每30分钟调用 fsync 将 File system cache 中的数据 flush 到硬盘。因此需要通过 translog 来保证即使因为断电 File system cache 数据丢失,es 重启后也能通过日志回放找回丢失的数据。
translog 默认设置下,每一个 index、delete、update 或 bulk 请求都会直接 fsync 写入硬盘。为了保证 translog 不丢失数据,在每一次请求之后执行 fsync 确实会带来一些性能问题。对于一些允许丢失几秒钟数据的场景下,可以通过设置 index.translog.durability 和 index.translog.sync_interval 参数让 translog 每隔一段时间才调用 fsync 将事务日志数据写入硬盘。
修改刷新时间
对于需要写入后实时查询的数据,可以通过手动 refresh 操作将 memory buffer 的数据立即写入到 File system cache。当然,该解决方案的代价就是降低了 ES 的写性能。
1、单个文档更新后立即refresh
PUT /test/_doc/1?refresh {"test": "test"} PUT /test/_doc/2?refresh=true {"test": "test"}
2、refresh整个索引的memory buffer
POST /test/_refresh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号