2022 腾讯游戏安全大赛 mobile 初赛 wp
外挂程序分析流程
过反调试
frida改一下端口就过掉了...
AndrLua+
给出的cheat app是用lua编写的jni,在 assets目录下能找到相关文件

不过貌似都被加密了

那么我们只能去分析 libluajava.so 文件,搜字符串能搜到这是lua5.3.3的版本,在github上找到了 https://github.com/nirenr/AndroLua_pro 闭源前的 AndroLua+项目,想编译一下bindiff恢复符号呢,编译了大半天,没编译成功。。
参考我之前写的这篇文章: https://www.cnblogs.com/lordtianqiyi/articles/17000585.html 并结合源码很容易定位到这里: f_parser函数
int __fastcall f_parser(int a1, int *a2)
{
_DWORD *v4; // r0
int v5; // r1
unsigned __int8 *v6; // r1
int v7; // r6
int v8; // r1
bool v9; // zf
int v10; // r0
v4 = (_DWORD *)*a2;
v5 = *(_DWORD *)*a2;
*v4 = v5 - 1;
if ( v5 )
{
v6 = (unsigned __int8 *)v4[1];
v4[1] = v6 + 1;
v7 = *v6;
}
else
{
v7 = xluaZ_fill((int)v4);
}
v8 = a2[13];
v9 = v7 == 26;
if ( v7 != 26 )
v9 = v7 == 28;
if ( v9 )
{
((void (__fastcall *)(int, int, const char *))checkmode)(a1, v8, "binary");
v10 = xluaU_undump(a1, *a2, (const char *)a2[14]);
}
else if ( v7 == 27 )
{
((void (__fastcall *)(int, int, const char *))checkmode)(a1, v8, "binary");
v10 = luaU_undump(a1, *a2, (const char *)a2[14]);
}
else
{
((void (__fastcall *)(int, int, const char *))checkmode)(a1, v8, "text");
v10 = ((int (__fastcall *)(int, int, int *, int *, int, int))luaY_parser)(a1, *a2, a2 + 1, a2 + 4, a2[14], v7);
}
return sub_DA413178(a1, v10);
}
原以为程序走的是 luaY_parser 这条路线,分析了大半天,才发现实际走的是 xluaU_undump 这个路线,结合lua5.3.3的源码,我们可以发现,原本是没有xluaU_undump这条线的,xluaU_undump这条线是Andrlua加上去的,用来解密 加密后的lua文件并分析的。
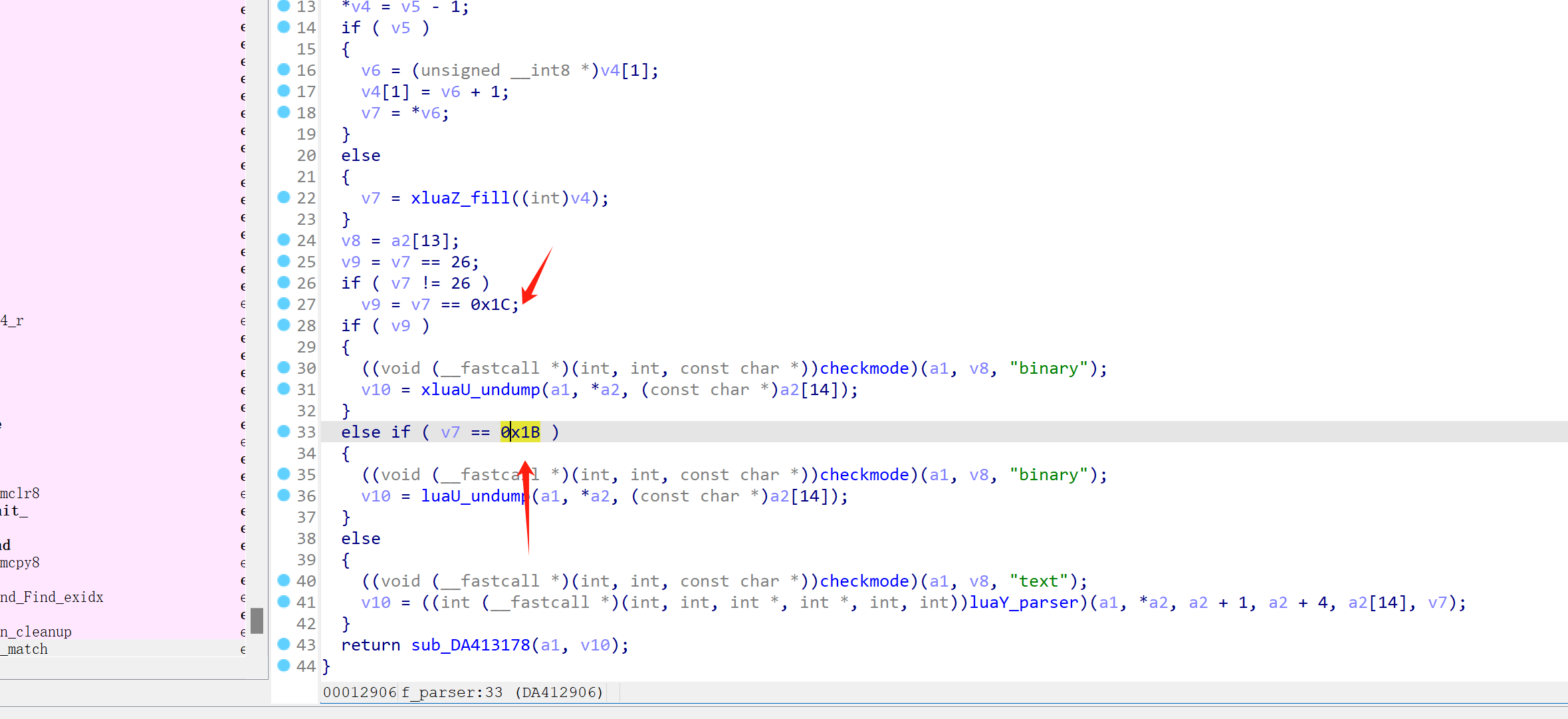
从这里的魔数字也能看出端倪,这其实就是在检测 lua文件的首字节,判断是需要解密的lua文件,还是不需要解密的lua文件,我们这里当然是需要解密的lua文件
luaL_loadbufferx
0x000E7D4处的luaL_loadbufferx函数会对加载来的lua文件进行base64解密
int __fastcall luaL_loadbufferx(int a1, unsigned __int8 *a2, size_t byte_count, int *a4, int a5)
{
unsigned __int8 *v7; // r6
int v8; // r9
int v10; // r0
unsigned __int8 *v11; // r0
int v12; // r1
int v13; // r2
signed int v14; // r1
int *v15; // r0
__int64 v16; // r4
size_t v17; // r11
int v18; // r9
unsigned int v19; // r0
unsigned __int8 v20; // r0
int v21; // r0
uInt v22; // r0
char *v23; // r1
int v24; // r2
uInt v25; // r0
signed int total_in; // r9
bool v27; // zf
uInt avail_in; // r9
bool v29; // zf
char v30; // r1
int v31; // r2
int v32; // r6
int v33; // r4
unsigned __int8 *v34; // r0
bool v35; // zf
int *v37; // [sp+8h] [bp-2080h]
int v38; // [sp+Ch] [bp-207Ch]
int v39; // [sp+10h] [bp-2078h]
unsigned __int8 *v40; // [sp+14h] [bp-2074h] BYREF
size_t total_out; // [sp+18h] [bp-2070h]
int v42[2]; // [sp+1Ch] [bp-206Ch] BYREF
int v43; // [sp+24h] [bp-2064h]
int v44; // [sp+28h] [bp-2060h]
int v45; // [sp+2Ch] [bp-205Ch] BYREF
z_stream strm; // [sp+202Ch] [bp-5Ch] BYREF
v7 = a2;
v8 = a5;
v40 = a2;
total_out = byte_count;
v10 = *a2;
if ( v10 == 61 )
{
v14 = 3 * ((byte_count + 3) >> 2);
if ( v14 <= 256 )
v15 = v42;
else
v15 = (int *)j_lua_newuserdata(a1, v14);
v37 = v15;
if ( !byte_count )
{
v38 = 0;
goto LABEL_49;
}
v17 = 0;
v38 = 0;
while ( 1 )
{
v18 = 0;
v39 = 0;
do
{
while ( 1 )
{
if ( v17 >= byte_count )
j_luaL_error(a1, "Invalid base64 text");
if ( v17 )
{
v19 = v7[v17];
if ( v19 < 0x2B || (v20 = v19 - 43, v20 >= 0x50u) )
{
*((_DWORD *)&strm.next_in + v18) = -1;
goto LABEL_24;
}
}
else
{
v20 = 29;
}
v21 = dword_318D8[v20];
*((_DWORD *)&strm.next_in + v18) = v21;
if ( v21 != -0x1 )
break;
LABEL_24:
++v17;
}
if ( v21 == -2 )
++v39;
++v18;
++v17;
}
while ( v18 != 4 );
switch ( v39 )
{
case 2:
avail_in = strm.avail_in;
v29 = strm.next_out == (Bytef *)-2;
if ( strm.next_out == (Bytef *)-2 )
v29 = strm.total_in == -0x2;
if ( !v29 || (strm.avail_in & 0xF) != 0 )
j_luaL_error(a1, "Invalid base64 text");
*((_BYTE *)v37 + v38++) = (4 * LOBYTE(strm.next_in)) | (avail_in >> 4);
break;
case 1:
total_in = strm.total_in;
v27 = strm.next_out == (Bytef *)-2;
if ( strm.next_out == (Bytef *)-2 )
v27 = (strm.total_in & 3) == 0;
if ( !v27 )
j_luaL_error(a1, "Invalid base64 text");
v25 = ((int)strm.next_in << 10) | (total_in >> 2) | (16 * strm.avail_in);
*((_BYTE *)v37 + v38) = BYTE1(v25);
v23 = (char *)v37 + v38;
v24 = v38 + 2;
LABEL_37:
v23[1] = v25;
v38 = v24;
break;
case 0:
v22 = (strm.avail_in << 12) | ((int)strm.next_in << 18) | (strm.total_in << 6) | (uInt)strm.next_out;
*((_BYTE *)v37 + v38) = BYTE2(v22);
v23 = (char *)v37 + v38;
v24 = v38 + 3;
*((_BYTE *)v37 + v38 + 2) = v22;
v25 = v22 >> 8;
goto LABEL_37;
default:
j_luaL_error(a1, "Invalid base64 text");
break;
}
if ( v17 >= byte_count )
{
LABEL_49:
HIDWORD(v16) = v38;
v7 = (unsigned __int8 *)j_lua_pushlstring(a1, v37, v38);
j_lua_settop(a1, -2);
v10 = *v7;
v8 = a5;
goto LABEL_50;
}
}
}
if ( v10 == 27 )
{
if ( a2[1] != 76 )
{
v11 = (unsigned __int8 *)malloc(byte_count);
if ( byte_count )
{
*v11 = 27;
if ( byte_count != 1 )
{
v12 = 0;
v13 = 1;
do
{
v12 += byte_count;
v11[v13] = v7[v13];
++v13;
}
while ( byte_count != v13 );
}
}
v40 = v11;
}
}
else
{
HIDWORD(v16) = byte_count;
LABEL_50:
if ( v10 == 28 )
{
LODWORD(v16) = malloc(HIDWORD(v16));
if ( HIDWORD(v16) )
{
v30 = 0;
v31 = 0;
do
{
v30 ^= v7[v31];
*(_BYTE *)(v16 + v31++) = v30;
}
while ( HIDWORD(v16) != v31 );
}
else
{
HIDWORD(v16) = 0;
}
*(_BYTE *)v16 = 120;
strm.zalloc = 0;
strm.zfree = 0;
if ( inflateInit_(&strm, "1.2.3", 56) )
j_luaL_error(a1, "load error");
*(_QWORD *)&strm.next_in = v16;
v44 = a1;
v43 = 0;
v42[1] = 0x2000;
v42[0] = (int)&v45;
do
{
strm.next_out = (Bytef *)j_luaL_prepbuffsize(v42, 0x2000);
strm.avail_out = 0x2000;
v32 = inflate(&strm, 4);
v33 = v32 + 5;
if ( (unsigned int)(v32 + 5) > 6 || ((1 << v33) & 0x61) == 0 )
j_luaL_error(a1, "load error %s", strm.msg);
v43 += 0x2000 - strm.avail_out;
}
while ( !strm.avail_out );
*(_BYTE *)v42[0] = 28;
v34 = (unsigned __int8 *)j_luaL_resultBuffer((int)v42);
v35 = v32 == 1;
v40 = v34;
total_out = strm.total_out;
if ( v32 != 1 )
v35 = v33 == 0;
if ( v35 )
inflateEnd(&strm);
else
j_luaL_error(a1, "load error %s", strm.msg);
v8 = a5;
}
}
return j_lua_load(a1, (int)sub_EB76, (int)&v40, a4, v8);
}
xLoadString
与源码比对,发现程序魔改了 LoadString函数
int __fastcall xLoadString(int *a1)
{
size_t v2; // r0
size_t v3; // r2
size_t v4; // r2
unsigned int v5; // r6
int v6; // r3
size_t v7; // r1
signed int v8; // r3
int v9; // r5
int v10; // r5
size_t v11; // r0
int v12; // r2
int v13; // r3
size_t v14; // r6
int v15; // r2
int v16; // r3
size_t v17; // r1
size_t size; // [sp+0h] [bp-48h] BYREF
char a2[40]; // [sp+4h] [bp-44h] BYREF
xLoadByte((int)a1, a2, 1u);
v2 = (unsigned __int8)a2[0];
size = (unsigned __int8)a2[0];
if ( (unsigned __int8)a2[0] == 255 )
{
xLoadByte((int)a1, (char *)&size, 4u);
v2 = size;
}
if ( !v2 )
return 0;
v3 = v2 - 1;
size = v2 - 1;
if ( v2 - 1 > 0x28 )
{
v10 = xluaS_createlngstrobj(*a1, v3);
xLoadByte((int)a1, (char *)(v10 + 0x10), size);
v11 = size;
if ( size )
{
v12 = *(unsigned __int8 *)(v10 + 16);
v13 = (unsigned __int64)(2155905153LL * (int)size) >> 32;
*(_BYTE *)(v10 + 0x10) = v12;
v14 = size;
if ( size >= 2 )
{
v15 = v12 ^ (v11 - 255 * ((v13 >> 7) + ((unsigned int)v13 >> 0x1F)));
v16 = 17;
do
{
v11 += v15 + v14;
*(_BYTE *)(v10 + v16) = *(_BYTE *)(v10 + v16);
v17 = v16 - 0xF;
v14 = size;
++v16;
}
while ( v17 < size );
}
}
}
else
{
xLoadByte((int)a1, a2, v3);
v4 = size;
if ( size )
{
if ( size != 1 )
{
v5 = 1;
v6 = ((int)size % 255) ^ (unsigned __int8)a2[0];
v7 = size + v6;
v8 = v6 + 2 * size;
do
{
v9 = v8 % 255;
v8 += v7;
a2[v5++] ^= v9;
}
while ( v5 < v4 );
}
}
else
{
v4 = 0;
}
return xluaS_newlstr(*a1, a2, v4);
}
return v10;
}
全都是在加密字符串,加密手段我没关注,直接用frida hook住 0x1292c处的函数dump出base64解密的lua文件,再hook住Load函数以及LoadString函数定位被加密的字符串所在文件位置,并dump出解密字符串,这个工作实际上类似于这个操作:

path脚本:
def dec(path,patch):
fp1 = open(path,"rb")
fp2 = open(path+".bin","wb")
all_data = bytearray(fp1.read())
for i in range(len(patch)):
one= patch[i]
idx = one[0]
leng = one[1]
data = one[2]
for j in range(leng):
all_data[idx + j] = data[j]
all_data[0] = 0x1b;
fp2.write(bytes(all_data))
fp2.close()
fp1.close()
print("finish " + path)
path = "./init.lua"
patch = [
(0x70,7,[0x61, 0x70, 0x70, 0x6e, 0x61, 0x6d, 0x65] ),
(0x79,6,[0x4d, 0x79, 0x41, 0x70, 0x70, 0x32] ),
(0x81,6,[0x61, 0x70, 0x70, 0x76, 0x65, 0x72] ),
(0x89,3,[0x31, 0x2e, 0x30] ),
(0x8e,7,[0x61, 0x70, 0x70, 0x63, 0x6f, 0x64, 0x65] ),
(0x97,1,[0x31] ),
(0x9a,6,[0x61, 0x70, 0x70, 0x73, 0x64, 0x6b] ),
(0xa2,2,[0x31, 0x35] ),
(0xa6,11,[0x70, 0x61, 0x63, 0x6b, 0x61, 0x67, 0x65, 0x6e, 0x61, 0x6d, 0x65] ),
(0xb3,20,[0x63, 0x6f, 0x6d, 0x2e, 0x6d, 0x79, 0x63, 0x6f, 0x6d, 0x70, 0x61, 0x6e, 0x79, 0x2e, 0x6d, 0x79, 0x61, 0x70, 0x70, 0x32] ),
(0xc9,9,[0x64, 0x65, 0x62, 0x75, 0x67, 0x6d, 0x6f, 0x64, 0x65] ),
(0xd6,15,[0x75, 0x73, 0x65, 0x72, 0x5f, 0x70, 0x65, 0x72, 0x6d, 0x69, 0x73, 0x73, 0x69, 0x6f, 0x6e] ),
(0xe7,8,[0x49, 0x4e, 0x54, 0x45, 0x52, 0x4e, 0x45, 0x54] ),
(0xf1,22,[0x57, 0x52, 0x49, 0x54, 0x45, 0x5f, 0x45, 0x58, 0x54, 0x45, 0x52, 0x4e, 0x41, 0x4c, 0x5f, 0x53, 0x54, 0x4f, 0x52, 0x41, 0x47, 0x45] ),
(0x109,16,[0x73, 0x6b, 0x69, 0x70, 0x5f, 0x63, 0x6f, 0x6d, 0x70, 0x69, 0x6c, 0x61, 0x74, 0x69, 0x6f, 0x6e] ),
]
dec(path,patch)
...
...
...
反编译回lua文件
luadec好像反编译不了32位的,这里我用的是 unluac.jar进行的反编译:
import os
# 当前目录
base_dir = './'
files = [os.path.join(base_dir, file) for file in os.listdir(base_dir)]
file_list =[]
for file in files:
if "lua.bin" in file:
file_list.append(file)
for i in range(len(file_list)):
file_name = (file_list[i])[2:]
os.system(f"java -jar unluac.jar ./{file_name} > src_lua/{file_name[:-4]}")
lua文件显示中文
完事后可以看到好多这种莫名其妙的字符串

实际上这是中文。
我写了个脚本把他们转化为了中文
import urllib
import os
import re
PATTERN = re.compile(r'"\s*\\[0-9]+(?:\\[0-9]+)*\s*"')
def convet2chinese(text):
str_match = text
array = str_match.split("\\")
sb = []
for s in array:
if s:
if s == " ":
continue
s = hex(int(s))[2:] # Convert to hex string
sb.append(f"%{s}")
new_str = urllib.parse.unquote(''.join(sb))
return new_str
fileDir = "./"
file_list = []
fileList = os.listdir(fileDir)
for file in fileList:
if ".lua" in file:
file_list.append(file)
for i in range(len(file_list)):
file_name = file_list[i]
fp = open(file_name,"r")
fp1 = open("111/" + file_name,"w",encoding="utf8")
all_data_lines = fp.readlines()
for j in range(len(all_data_lines)):
line = all_data_lines[j]
matcher =PATTERN.findall(line)
if matcher != []:
assert len(matcher) == 1
for match in matcher:
new_str = convet2chinese(match.replace('"',""))
new_line = line.replace(matcher[0], '"' + new_str + '"')
fp1.write(new_line)
else:
fp1.write(line)
fp1.close()
fp.close()

分析lua文件功能
实际上就做了这几件事:
1、反调试
2、rc4解密 assest文件下的aes文件
3、执行aes文件。
由此看来,外挂的主要逻辑就在aes文件中
解密aes文件:
from Crypto.Cipher import ARC4 as rc4cipher
def enrc4(cip:bytes,key:bytes):
from Crypto.Cipher import ARC4 as rc4cipher
enc = rc4cipher.new(key)
res = enc.encrypt(cip)
return res
fp = open("./aes","rb")
cip = fp.read()
key = b"zyp"
enc = enrc4(cip,key)
fp1 = open("./aes_enrc4","wb")
fp1.write(enc)
fp1.close()
fp.close()
分析aes文件
先脱upx壳,再进行分析
混淆的处理
文件中存在大量的br混淆,我简单的patch了一下基本块的间接跳转,虽然修改了程序的执行逻辑,但可以让伪代码勉强可读。
import idc
def Get_Asm(begin,end):
nop = [0x0,0xBF]
ea = begin
while ea < end:
ttt = str(hex(ea)) + ": " + idc.generate_disasm_line(ea, 0) + "\n"
if "MOV PC," in ttt:
idc.patch_byte(ea,nop[0])
idc.patch_byte(ea+1,nop[1])
ea = idc.next_head(ea)
import idc
import idaapi
def upc(begin,end):
for i in range(begin,end):
idc.del_items(i)
for i in range(begin,end):
idc.create_insn(i)
for i in range(begin,end):
idaapi.add_func(i)
print("Finish!!!")
begin = 0x0004140
end = 0x001143C
Get_Asm(begin,end)
upc(begin,end)
反调试相关
2
1、通过执行 ls /proc/self/fd -all ,检查有无frida、injector字样来反调试
anon:scudo:primary]:E9307760 aTotal0DrX2Root DCB "total 0",0xA
[anon:scudo:primary]:E9307768 DCB "dr-x------ 2 root root 0 2025-03-05 21:39:58.720001106 +0800 .",0xA
[anon:scudo:primary]:E93077A8 DCB "dr-xr-xr-x 9 root root 0 2025-03-05 21:39:58.712001106 +0800 .."
[anon:scudo:primary]:E93077E8 DCB 0xA
[anon:scudo:primary]:E93077E9 DCB "lrwx------ 1 root root 64 2025-03-05 21:39:58.752001106 +0800 0 "
[anon:scudo:primary]:E9307829 DCB "-> /debug_ramdisk/.magisk/pts/0",0xA
[anon:scudo:primary]:E9307849 DCB "l-wx------ 1 root root 64 2025-03-05 21:39:58.752001106 +0800 1 "
[anon:scudo:primary]:E9307889 DCB "-> pipe:[139906]",0xA
[anon:scudo:primary]:E930789A DCB "lrwx------ 1 root root 64 2025-03-05 21:39:58.752001106 +0800 2 "
[anon:scudo:primary]:E93078DA DCB "-> /debug_ramdisk/.magisk/pts/0",0xA
[anon:scudo:primary]:E93078FA DCB "lrwx------ 1 root root 64 2025-03-05 21:39:58.752001106 +0800 3 "
[anon:scudo:primary]:E930793A DCB "-> socket:[120560]",0xA
[anon:scudo:primary]:E930794D DCB "lr-x------ 1 root root 64 2025-03-05 21:39:58.720001106 +0800 4 "
[anon:scudo:primary]:E930798D DCB "-> /proc/11548/fd",0xA
[anon:scudo:primary]:E930799F DCB "lr-x------ 1 root root 64 2025-03-05 21:39:58.728001106 +0800 5 "
[anon:scudo:primary]:E93079DF DCB "-> /proc/11548/fd",0xA,0
0xE3F1B0E:
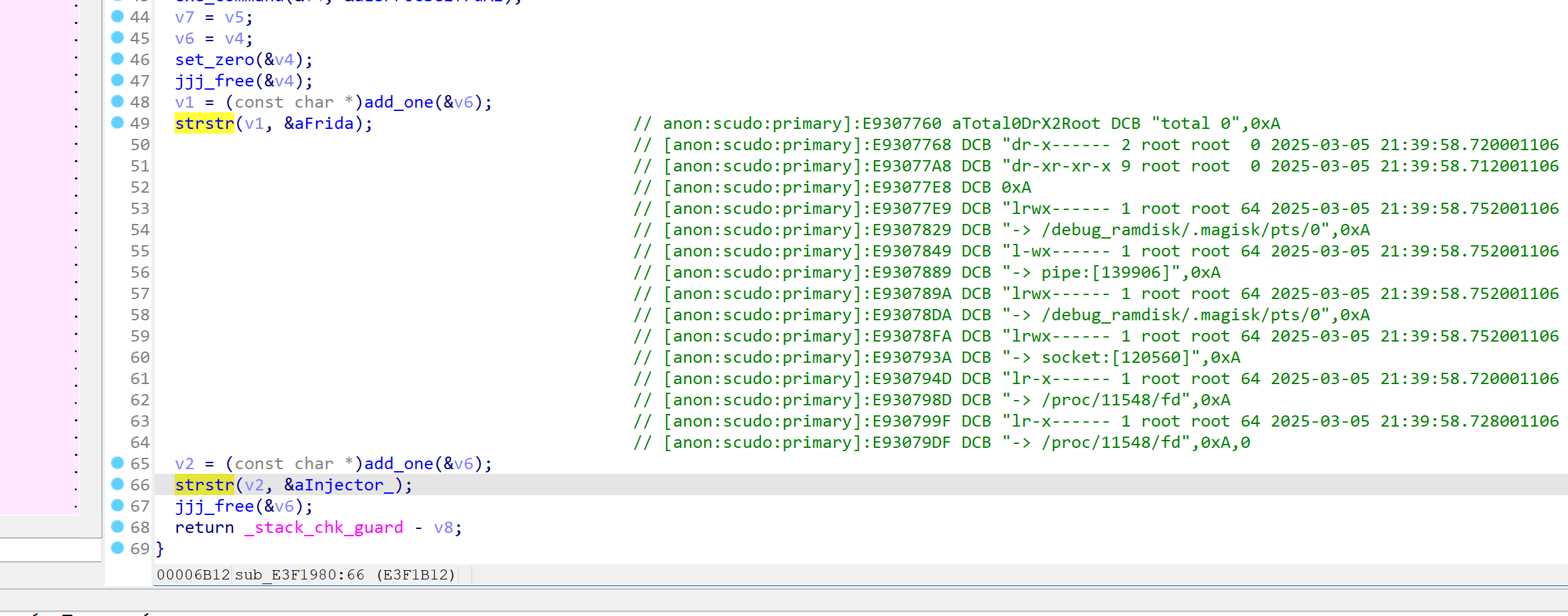
如果检查到,则触发 found debugger 2
3
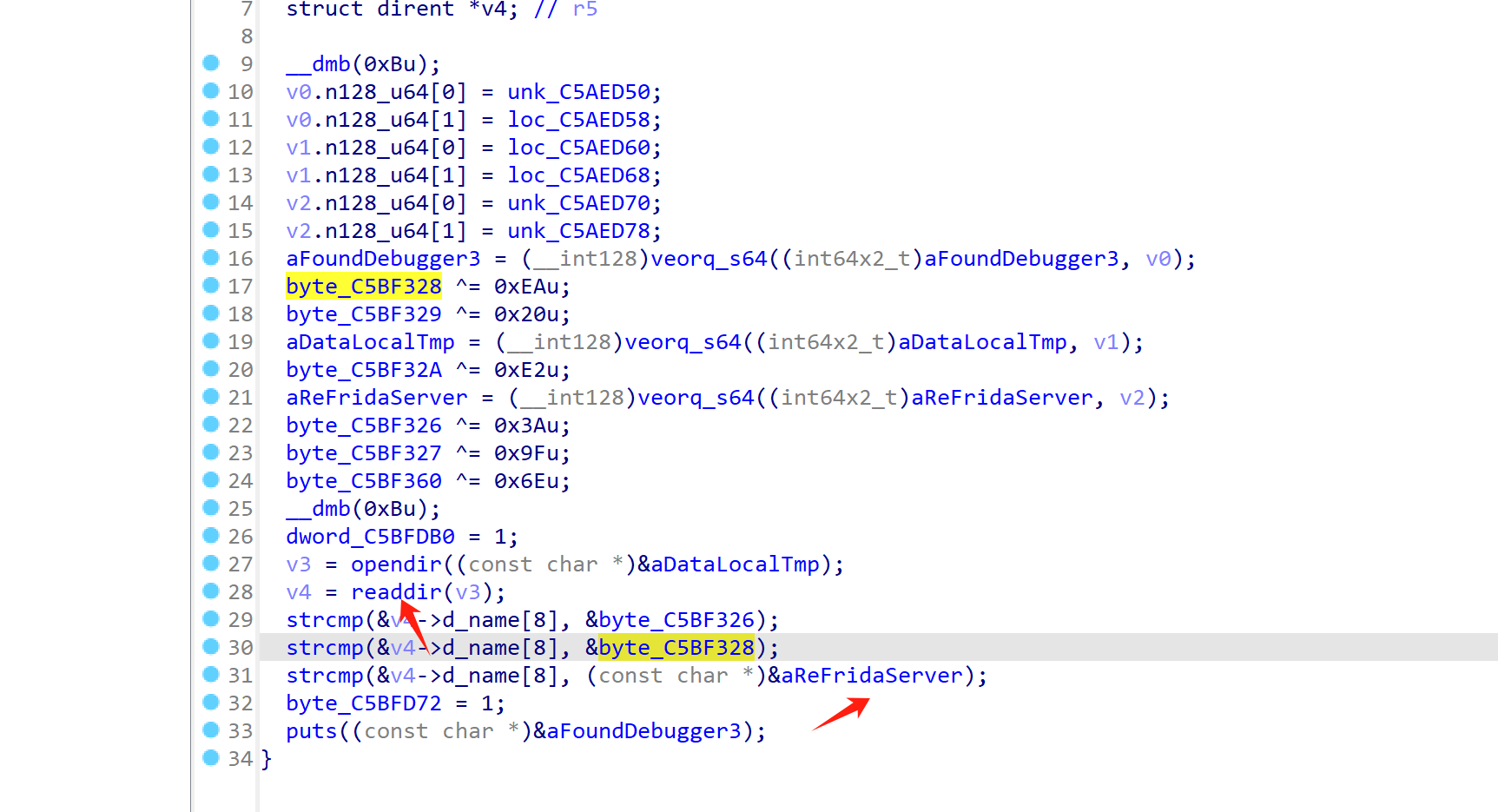
打开 /data/local/tmp目录,搜索有无 re.frida.server 特征?有点没看懂,这岂不是包搜不到
貌似早期frida-server在运行的时候会创建 re.frida.server文件夹
4
/proc/self/task 反frida 调试
0xs5050DD0
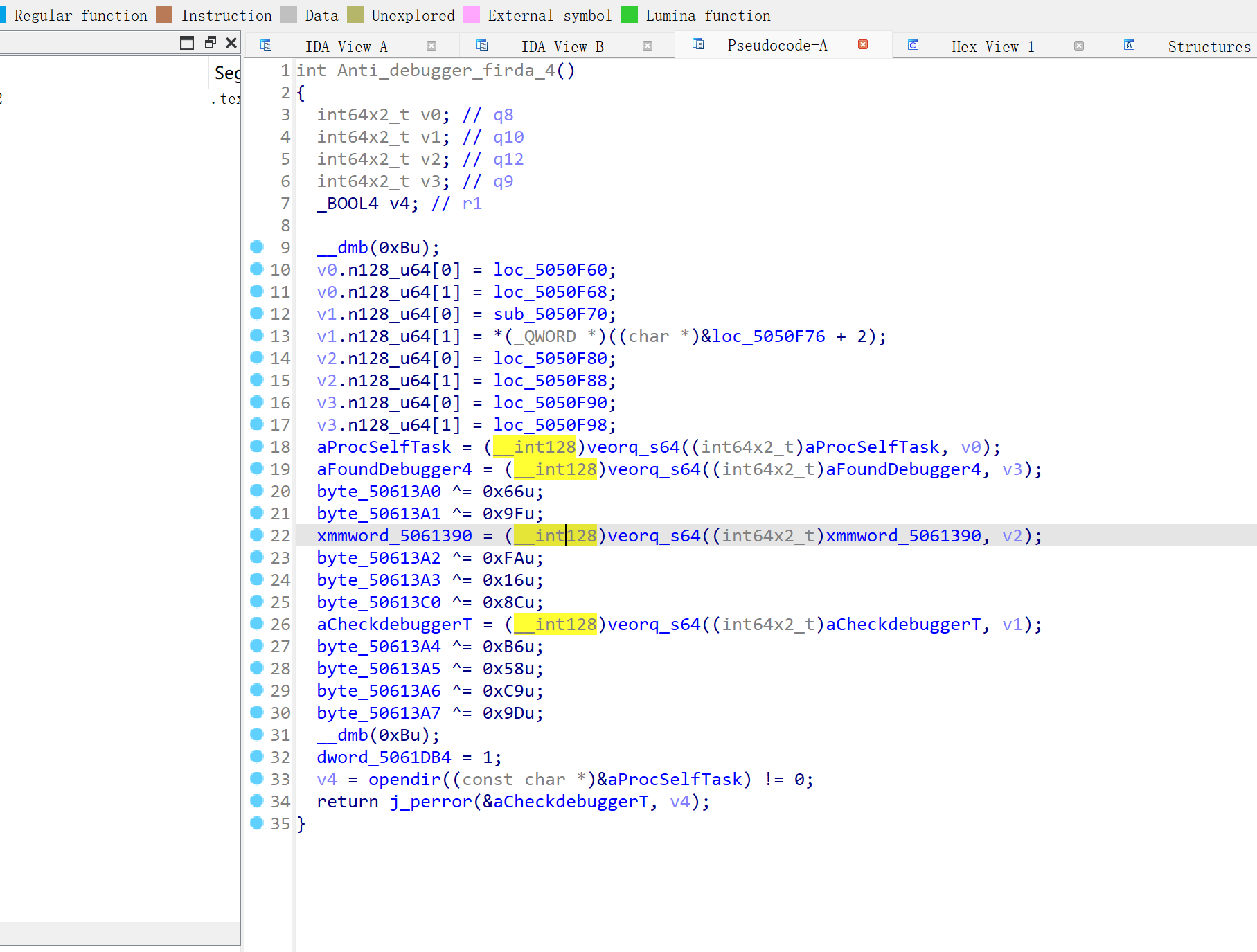
5
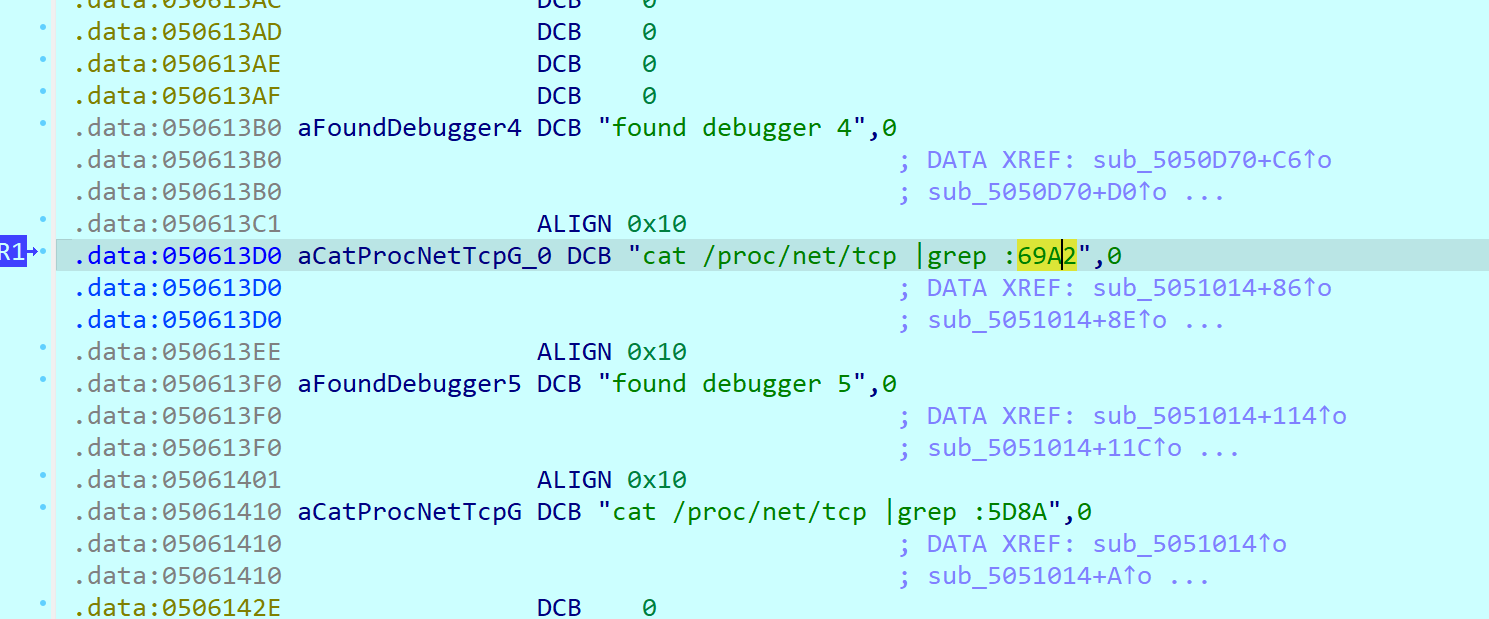
检查端口
实际上反调试基本都是和frida相关的,我们只要用ida调试,改个端口就完事了。
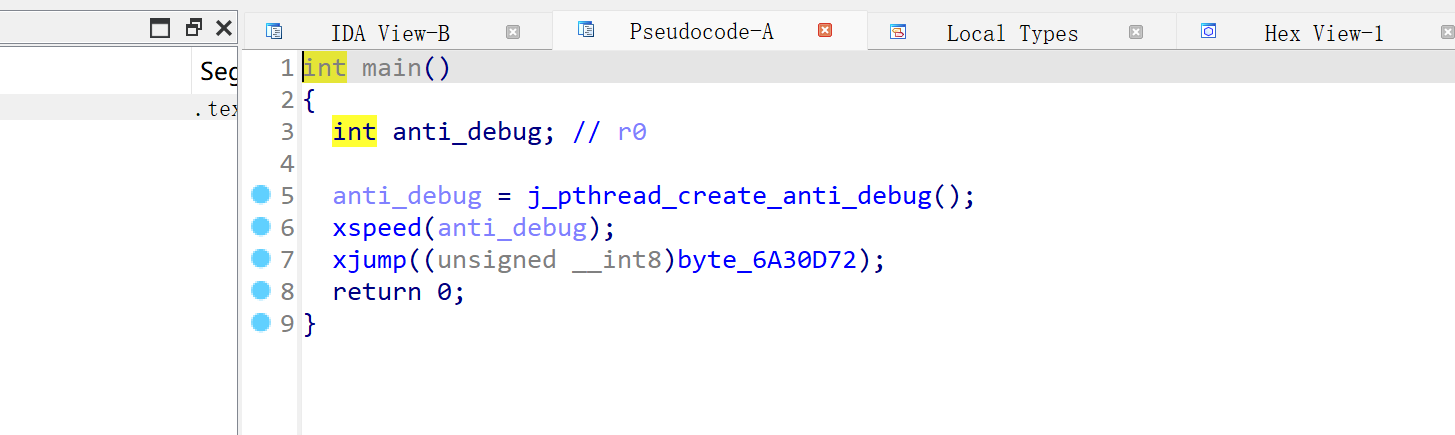
修改速度的外挂
主要逻辑大致如下:
dest = (char *)&v24;
read2 = (iovec *)&v21;
v27 = (iovec *)&v20;
app_pid = get_app_pid((const char *)&aComYourcompany);
if ( app_pid >= 10 )
{
pid = app_pid;
so = find_so(app_pid, &aLibue4So); // 读/proc/pid/self,找 libUE4.so
g_GWorld = jjjj_j_process_vm_readv(pid, so + 0x4924570);// GWorld 0xB7056124
val = jjjj_j_process_vm_readv(pid, g_GWorld + 0x20);// 0xB5073C80
local = (iovec *)&read1;
v32 = 8;
LODWORD(remote) = val + 0x70; // iov_base
HIDWORD(remote) = 8;
syscall(j_process_vm_read, pid, &local, 1, &remote, 1, 0);
g_import_reverse_2 = jjjj_j_process_vm_readv(pid, so + 0x4877034);
local = read2;
v32 = 120;
g_import_reverse_2_ = g_import_reverse_2;
remote = (unsigned int)g_import_reverse_2 | 0x7800000000LL;
process_vm_readv(pid, &local, 1, &remote, 1, 0);
if ( v23 >= (int)0xFFFFFFD1 )
{
v8 = -1;
v9 = 0;
do
{
v10 = jjjj_j_process_vm_readv(pid, v9 + read1);
v11 = jjjj_j_process_vm_readv(pid, v10 + 0x10);
if ( (unsigned int)(v11 - 0x4000) >> 0xF <= 0xE )
{
page = v11 / 0x4000;
offset = v11 % 0x4000;
v14 = *((_DWORD *)&read2->iov_base + v11 / 0x4000);
if ( !v14 )
{
v14 = jjjj_j_process_vm_readv(pid, g_import_reverse_2_ + 4 * page);
*((_DWORD *)&read2->iov_base + page) = v14;
}
v15 = jjjj_j_process_vm_readv(pid, v14 + 4 * offset);
j_vm_read_string(pid, v15);
v16 = dest;
strcpy(dest, &B_WorldInfo);
if ( (unsigned int)strlen(v16) >= 5 && strstr(dest, &aFirstpersonc) )
{
LODWORD(v17) = jjjj_j_process_vm_readv(pid, v10 + 0x2F0) + 0x164;
v18 = v27;
v27->iov_base = (void *)dword_6A3026C;
HIDWORD(v17) = 4;
local = v18;
v32 = 4;
remote = v17;
process_vm_writev(pid, &local, 1, &remote, 1, 0);
}
}
v9 += 4;
++v8;
}
while ( v8 < v23 + 47 );
}
}
没看明白怎么实现的,但我自己实现了一个,只需要钩住 01FD6430 的返回值即可,把返回值改大点即可完成
修改jump高度的外挂
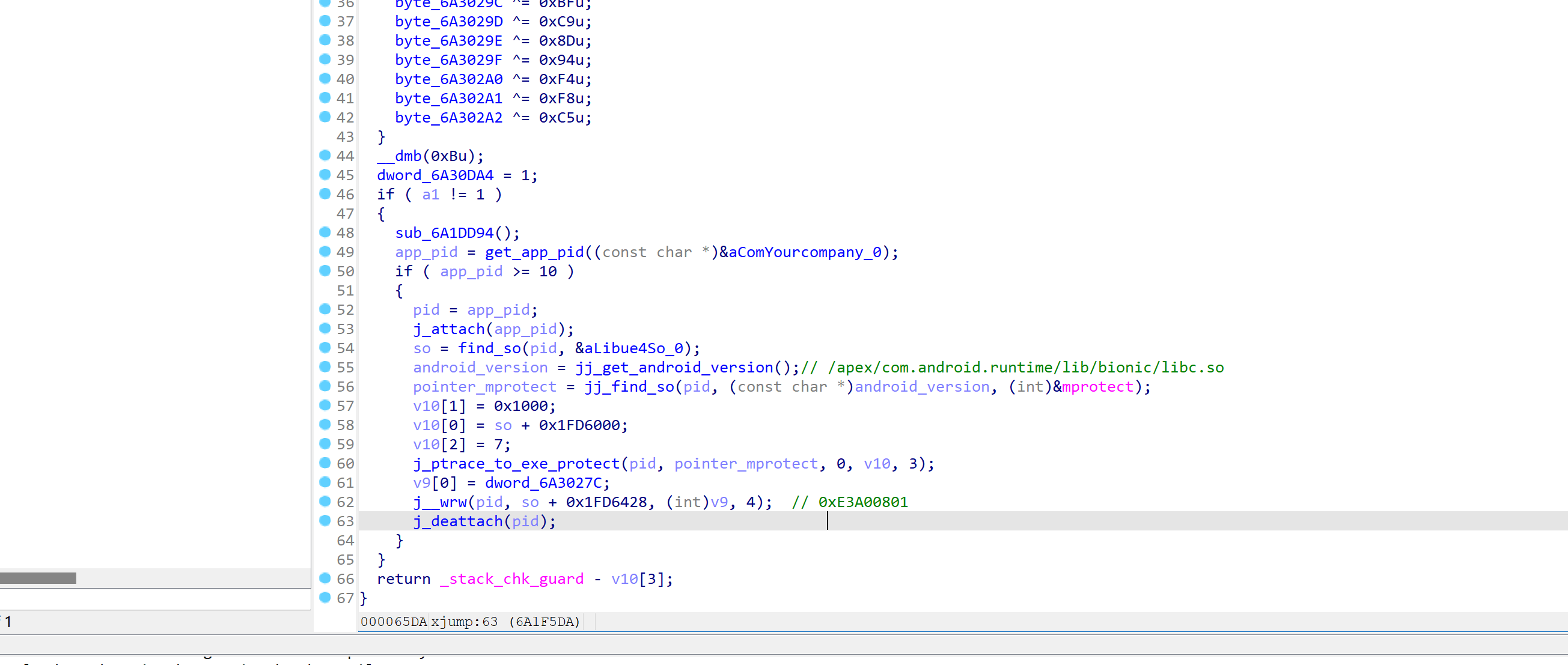
实际上就是通过ptrace,修改程序的寄存器,让程序执行 mprotect(0x1FD6000 + so,0x1000,7)函数,给
0x1FD6000 所在页可读可写可执行的权限。之后修改0x1FD6428地址处的代码,修改为: 01 08 a0 e3
修改前:
修改后:

外挂源码复现
由于没看明白移动加速外挂是如何实现的,因此这里只用c复现了无限跳跃。移速外挂用frida草草实现的
无限跳跃
外挂使用ptrace + process_vm_writev 实现的内存读写,这里我采用第三种方式实现了内存读写
#include <string>
#include <iostream>
using namespace std;
#define LOGE printf
pid_t get_pid_by_app_package(string package){
string command = "pidof " + package;
FILE* fp = popen(command.c_str(),"r");
if (fp == NULL) {
LOGE("Failed to run command: %s\n", command.c_str());
return -1;
}
char str_pid[256] = {0};
if(fgets(str_pid, 10,fp) == NULL){
LOGE("Failed to read PID from output\n");
fclose(fp);
return -1;
}
pid_t pid = atoi(str_pid);
LOGE("pid: %d\n",pid);
return pid;
}
void* get_module_base(pid_t pid, const char* module_name ){
FILE *fp;
long addr = 0;
char *pch;
char filename[32];
char line[1024];
if ( pid < 0 )
{
/* self process */
snprintf( filename, sizeof(filename), "/proc/self/maps", pid );
}
else
{
snprintf( filename, sizeof(filename), "/proc/%d/maps", pid );
}
fp = fopen( filename, "r" );
if ( fp != NULL )
{
while ( fgets( line, sizeof(line), fp ) )
{
if ( strstr( line, module_name ) )
{
pch = strtok( line, "-" );
addr = strtoul( pch, NULL, 16 );
if ( addr == 0x8000 )
addr = 0;
break;
}
}
fclose( fp ) ;
}
return (void *)addr;
}
void procfs_read_mem(pid_t pid,unsigned int target_addr){
char path[256] = {0};
sprintf(path, "/proc/%d/mem", pid);
FILE *file = fopen(path, "r");
if (file == NULL){
printf("fopen error\n");
return ;
}
// Set the file index to our required offset, representing the memory address
if(fseek(file, (unsigned long long int)target_addr, SEEK_SET) != 0 ){
printf("fseek failed, error: %s\n", strerror(errno)); // 输出详细的错误信息
// fclose(file);
// return;
}else{
printf("111\n");
}
char buffer[0x10] = {0};
size_t read_bytes = fread(buffer,1,4,file);
if (read_bytes != 4) {
printf("Failed to read the expected number of bytes: expected 4, got %zu\n", read_bytes);
}
for(int i=0;i<4;i++){
printf("0x%x,",buffer[i]);
}
puts("");
}
void procfs_write_mem(pid_t pid,unsigned int target_addr,unsigned char payload[],int inject_size){
printf("tar: 0x%x\n",target_addr);
char path[256] = {0};
sprintf(path, "/proc/%d/mem", pid);
FILE *file = fopen(path, "w");
if (file == NULL){
printf("fopen error\n");
return ;
}
// Set the file index to our required offset, representing the memory address
fseek(file, (unsigned int)target_addr, SEEK_SET);
fwrite(payload, sizeof(char), inject_size, file);
printf("Inject finish\n");
}
void xjump(){
pid_t pid = get_pid_by_app_package("com.YourCompany.FPSTest1");
size_t libUE4_base = (size_t)get_module_base(pid,"libUE4.so");
LOGE( "libUE4_base :0x%x\n", libUE4_base );
procfs_read_mem(pid ,libUE4_base+0x1FD6428);
unsigned char payload[4] = {0x1,0x8,0xa0,0xe3};
procfs_write_mem(pid,libUE4_base+0x1FD6428,payload,4);
}
int main(){
xjump();
}
// /home/tlsn/Btools/NDKXX/NDK24/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android31-clang++ -g ./hook.cpp -o hook -static
加速
function hook_xspeed(){
var libUE4_so = Module.findBaseAddress("libUE4.so")
var hook_list = [
0x1fd6430,
0x1fd64dc,
0x20018fc, // 判断有没有超过最大速度
]
for(var i in hook_list){
const offset = hook_list[i]
Interceptor.attach(ptr(libUE4_so).add(offset),{
onEnter: function(args){
if(offset == 0x20018fc){
stack_backstace(this)
}
},
onLeave: function(ret){
// if(offset == 0x1FD6430){ // 这个就是角色能达到的最大速度
// console.log(ret)
// ret.replace(0x75559312) // 固定值为: 0x44160000
// }
// if (offset == 0x1FD64DC){
// console.log(ret)
// ret.replace(0x44160000)
// }
}
})
}
}
hook_xspeed()
实际上挂钩0x1fd6430函数的返回值即可
ue4逆向基础知识
Ue4还可以吧整个游戏的所有结构体、变量名、函数名、函数定义都dump下来
Gworld
UWorld其实就是世界数组基地址 .可以通过这个对象数组获取所有对象。
GName
class FNamePool
{
public:
FNameEntryAllocator Entries;
…………
};
这个NamePoolData就是常说的GName
GName存储了全局的字符串
我的疑问
1、字符串加密
2、br混淆
3、frida特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号