从frida到va_list
背景
在用frida hook CallStaticVoidMethodV 函数参数的时候,发现va_list结构有些复杂,不好hook,故进行了学习
va_list介绍
va_list 是在c语言中解决变参问题的一组宏。
va_list的内部结构由编译器与平台架构决定,不同组合可能会导致va_list 的定义和行为存在显著差异。
在 x86_64 架构下 gcc/clang 编译器下的 va_list定义如下:
参数介绍:
reg_save_area,参数指向寄存器保存区域的开始。overflow_arg_area,该指针用于获取在堆栈上传递的参数。它被初始化为堆栈上传递的第一个参数的地址(如果有的话),然后总是更新为指向堆栈上下一个参数的开始。gp_offset,元素以字节为单位保存从reg_save_area到保存下一个可用通用参数寄存器的位置的偏移量。如果所有参数寄存器都已用尽,则将其设置为值48(6 * 8)。fp_offset,元素保存从reg_save_area到保存下一个可用浮点参数寄存器的位置的偏移量(以字节为单位)。如果所有参数寄存器都已用尽,则将其设置为值304(6 * 8 + 16 * 16)。(每个通用寄存器占8字节,浮点寄存器占16字节)- ps:
经过我的调试,可以发现,gp_offset与fp_offset这俩值都是在不断变化的,使reg_save_area或overflow_arg_area+fp_offset或gp_offset后,始终指向下一个参数的地址。
我们可以看到,这里引入了一个叫做 寄存器保存区域 的概念,我们可能会想,既然已经是寄存器传参了,那寄存器保存区域是干嘛的呢?
事实上,如果我们定义了一个变参函数,我们在进入这个函数的时候,可以发现,这些本该由寄存器传递的参数会被保存到栈上。如下图:
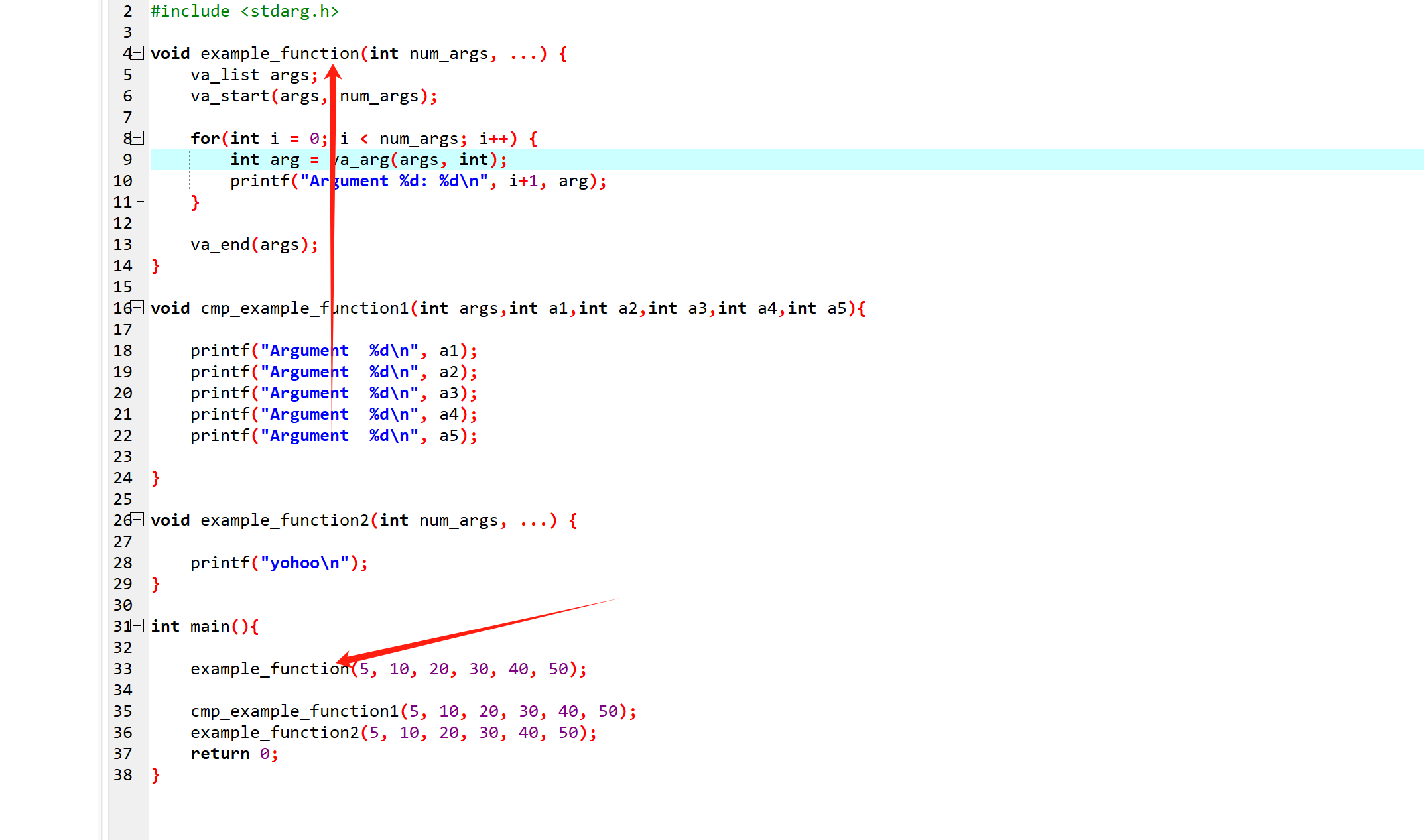
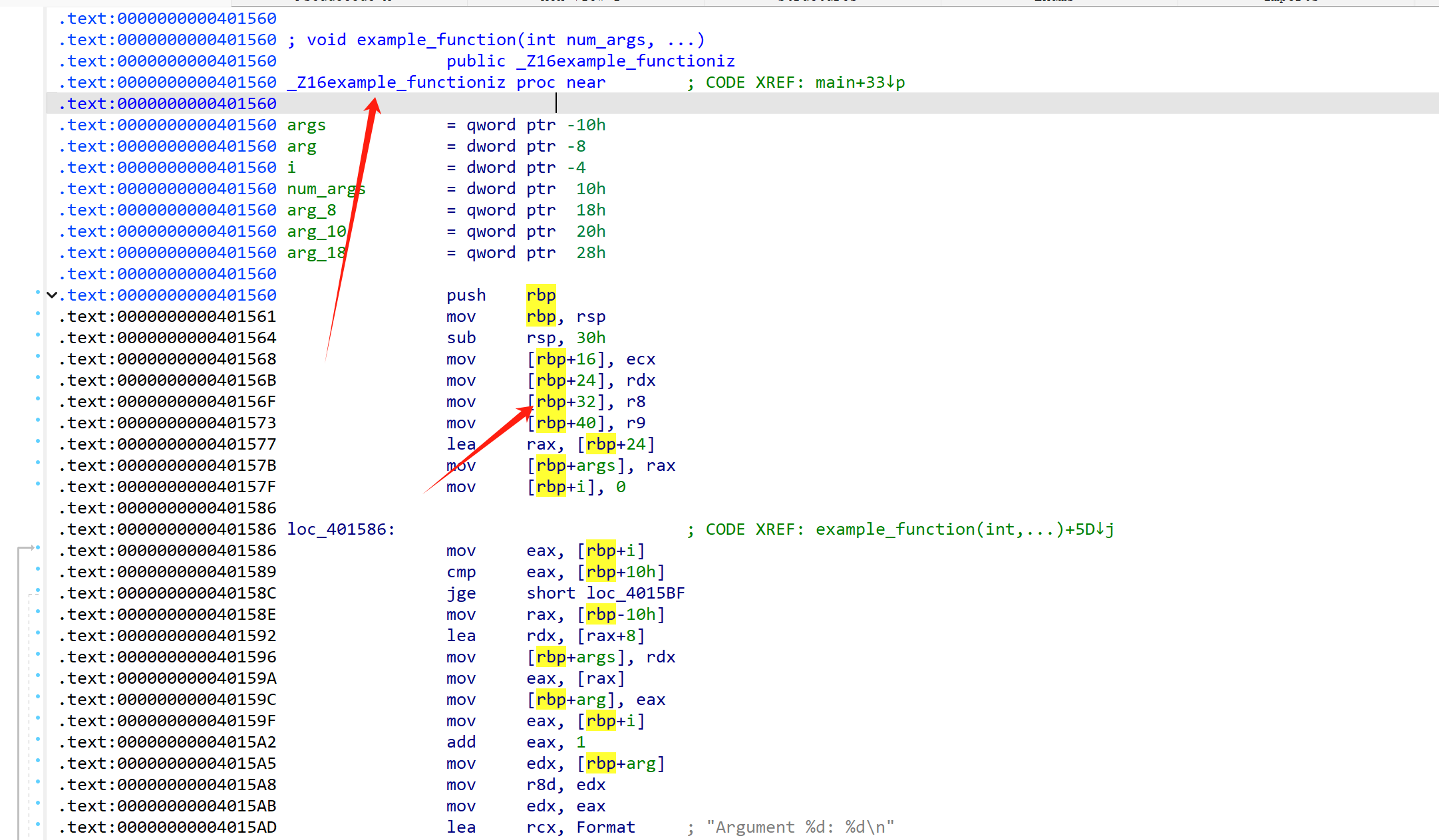
这实际上是为了方便 va_list与其相关宏函数的工作:
va_list的相关宏函数
-
va_start函数功能: 初始化
va_list变量ap,使其指向函数参数列表中的第一个可变参数。last是最后一个固定参数的名称。 -
va_arg获取当前参数的值,并使
ap指向下一个参数。type是参数的类型。 -
va_end清理
va_list变量ap。
举个例子,printf的内部实现:
va_start宏会初始化args,使其指向format参数之后的第一个可变参数。vprintf是printf的一个变体,直接接受一个va_list参数。它负责解析格式字符串并处理可变参数。va_end宏完成对va_list的清理,释放任何与其关联的资源。
从上面可以看到,va_start会初始化 args,使其指向 format 参数之后的第一个可变参数。如果我们没有把寄存器放到栈上,是不是就不能获取 format参数后的第一个可变参数地址了呢?
我们再来看一下这些宏的实现:
手动实现一下变参函数:
实现参数的遍历:
frida hook CallObjectMethodV 中的 va_list参数
aarch64 & gcc编译器下的va_list结构
事实上,arrch64 & gcc编译器下的 va_list结构体与 x86 & gcc下的 va_list 结构体略有不同:
void __stack;
- 作用:指向参数列表中位于栈上的部分。
- 解释:在调用函数时,参数可能通过寄存器传递,也可能通过栈传递。
__stack指针用于跟踪那些未通过寄存器传递、需要从栈中读取的参数的位置。
void __gr_top;
- 作用:指向通用寄存器(General Registers)区域的顶部。
- 解释:在许多体系结构(例如 x86-64)中,前几个参数会通过通用寄存器(如
RDI,RSI,RDX,RCX,R8,R9)传递。__gr_top用于指向这些寄存器中可用的下一个位置,以便依次读取通过寄存器传递的参数。
void __vr_top;
- 作用:指向向量寄存器(Vector Registers)区域的顶部。
- 解释:某些参数(如浮点数或 SIMD 类型)可能通过向量寄存器传递。
__vr_top用于跟踪这些向量寄存器中可用的位置,确保能够正确读取通过向量寄存器传递的参数。
int __gr_offs;
- 作用:通用寄存器区域的偏移量。
- 解释:
__gr_offs用于记录已经使用的通用寄存器数量或字节偏移量。这有助于在读取下一个通过通用寄存器传递的参数时,正确调整__gr_top指针的位置。
int __vr_offs;
- 作用:向量寄存器区域的偏移量。
- 解释:类似于
__gr_offs,__vr_offs用于记录已经使用的向量寄存器数量或字节偏移量,确保能够正确管理通过向量寄存器传递的参数。
事实上,我觉得不同编译器很有可能影响 va_list的结构,我的建议还是具体编译器具体分析,如下图,就是arrch64下gcc编译的.so的va_list的结构体
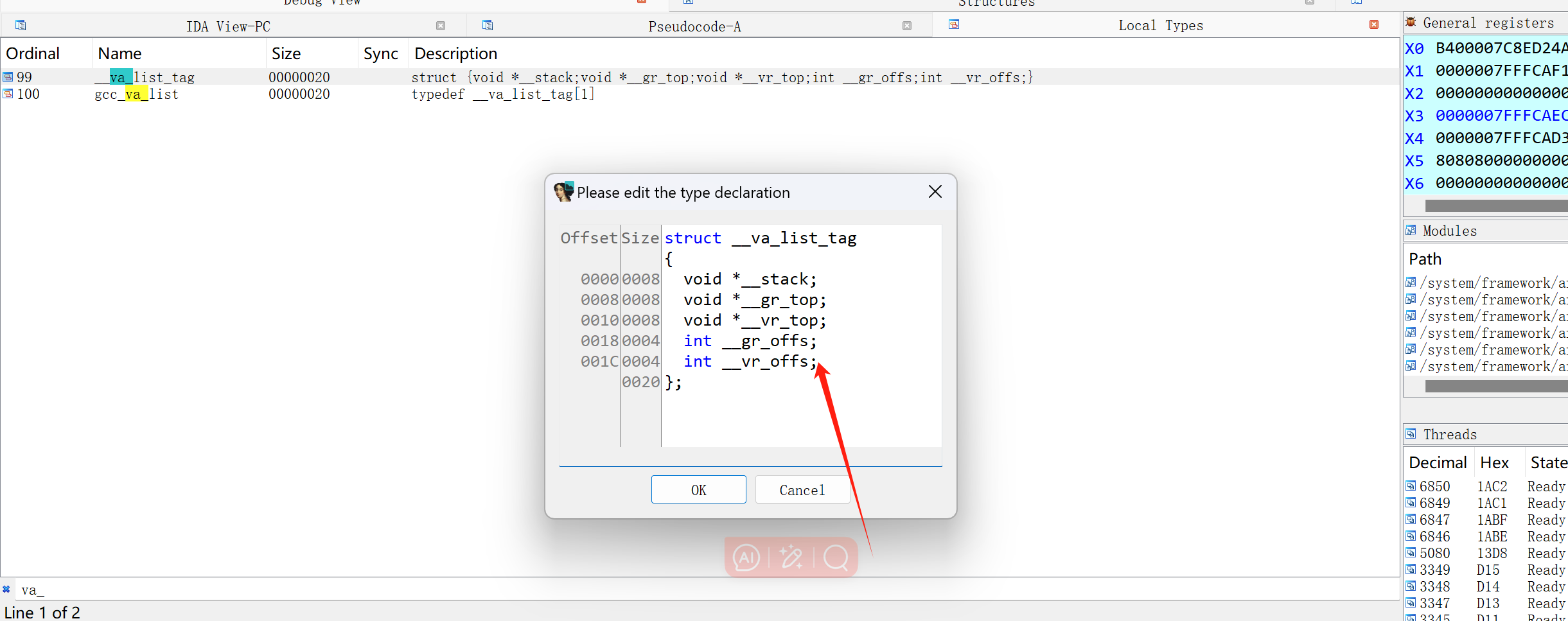
jstring 结构体 句柄
看源码可以看到,jstring是继承于 jobject类的
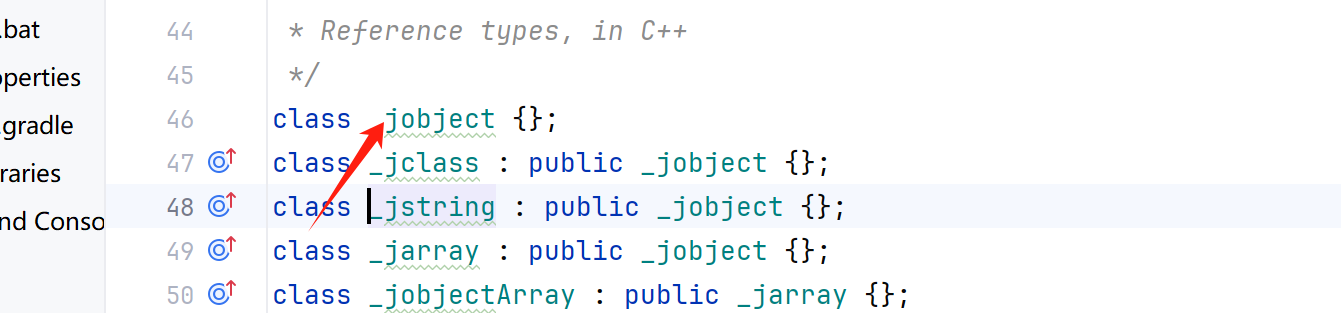
事实上,jobject以及其派生类(jstring、jclass等)都被视为句柄,而不是直接的结构体指针。
在使用 jstring等jobject类的时候,程序会根据句柄值,去JVM中维护的句柄表中来处理数据,这种做法有助于jvm垃圾回收机制的实现,也能够避免本地代码直接操作JVM内存,从而提高安全性和稳定性。
总的来说,jstring 保存的并不是一个指向结构图的指针,而是一个句柄值。
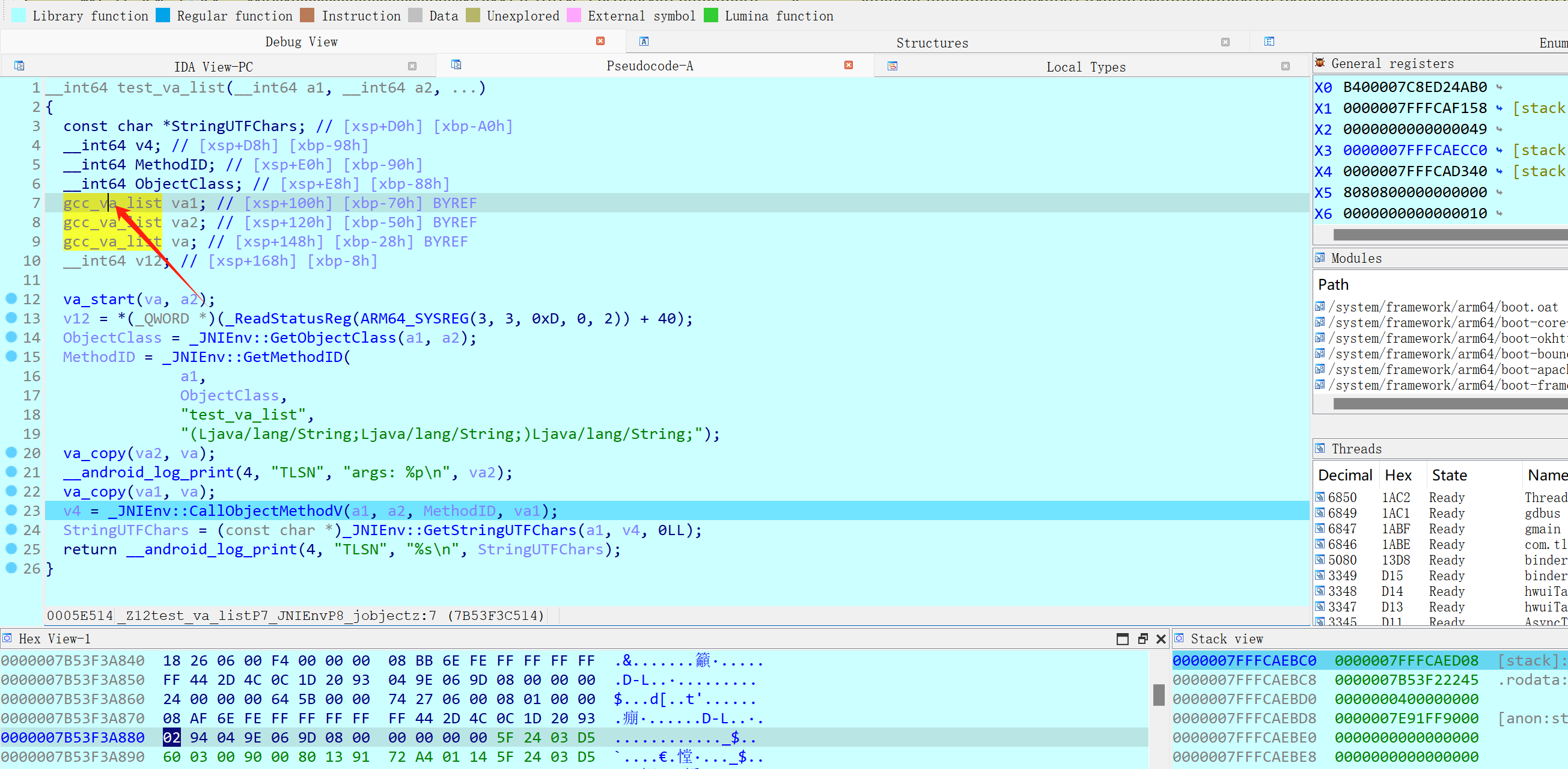
frida hook CallObjectMethodV 得到va_list中的jstring
js代码如下:
__EOF__

本文链接:https://www.cnblogs.com/lordtianqiyi/p/18603315.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现