王道408---DS---查找
基本概念
ASL
平均查找长度
在查找过程中,一次查找的长度是指需要比较的关键字次数,而平均查找长度则是所有查找过程中进行关键字的比较次数的平均值
顺序查找与折半查找
一般线性表的顺序查找
没啥好说的
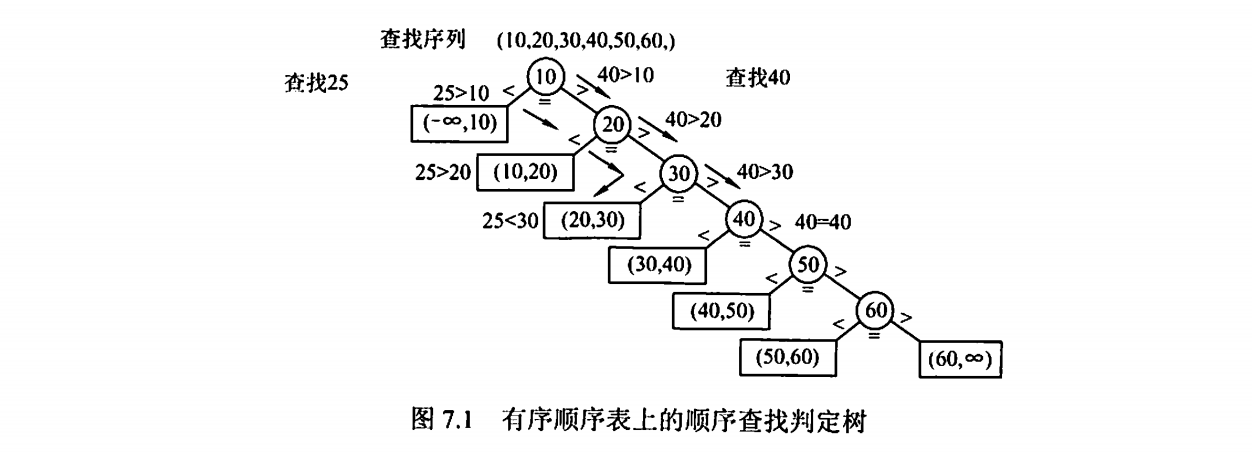
有序表的顺序查找
树中的圆形结点表示有序线性表中存在的元素;树中的矩形结点称为失败结,点(若有n个结点,则相应地有n+1个查找失败
结点),它描述的是那些不在表中的数据值的集合。若查找到失败结点,则说明查找不成功。
折半查找
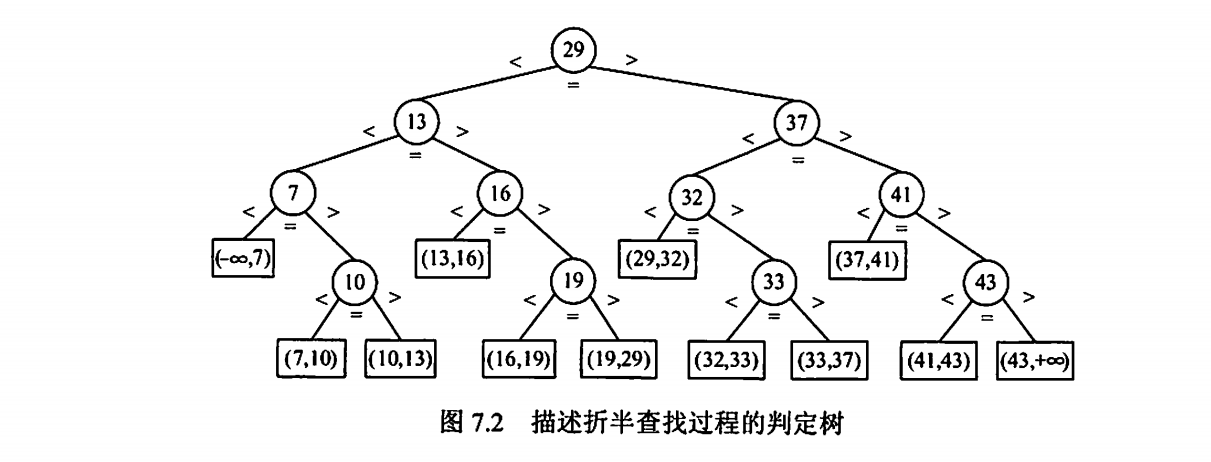
判定树是一颗平衡二叉树
若有序序列有n个元素,则对应的判定树有n个圆形的非叶结点和n+1个方形的叶结点。显然,判定树是一棵平衡二叉树。
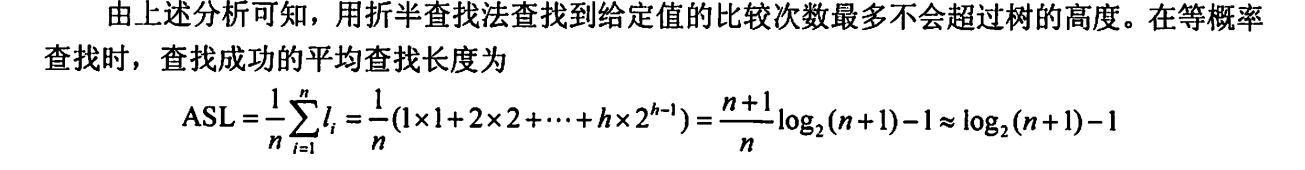
注意点:
1、根据折半查找判定树不难发现:
不难看出最大分支高度为 ,那么其最小分支高则为 (因为是平衡二叉树,高低差不超过1)
BST树
二叉排序树
这里只需要记一下删除的操作即可
二叉排序树删除时,要用该节点中序遍历时的直接前驱或后继来替代
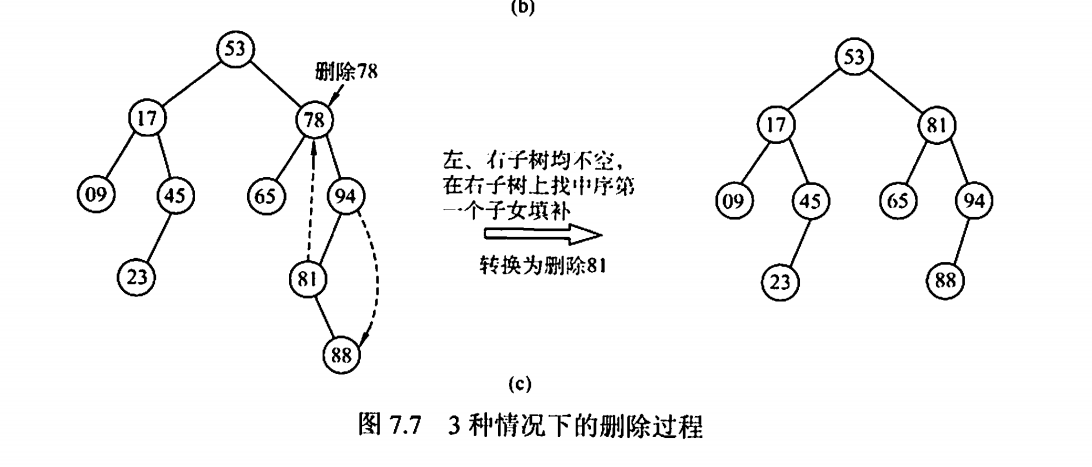
实际上,我们删除时某节点时,如果该节点有前驱和后继,那么用哪个前驱和后继都可以,上图是用的后继
另外,图中还有一个隐藏细节: 删除78时,并不是直接删除78,而是把78的位置与81的位置对调了一下,对调后的78只有右子树,因此可以用右子树来代替78,至此78被移到了最底层,也就是叶子节点的位置,即删除成功
AVL树
平衡二叉树
平衡因子
定义节点左子树于右子树的高度差为该节点的平衡因子
平衡二叉树的递推公式(重要,在解一些题目时可以大大加快解题速度)
设表示高度为h的平衡二叉树中含有的最少节点数,注意是所有层的节点和
= 1
= 2
有点像斐波那契数列捏
插入
每次调整的对象都是最小不平衡子树,即以插入路径上离插入结,点最近的平衡因子的绝对值大于1的结点作为根的子树。
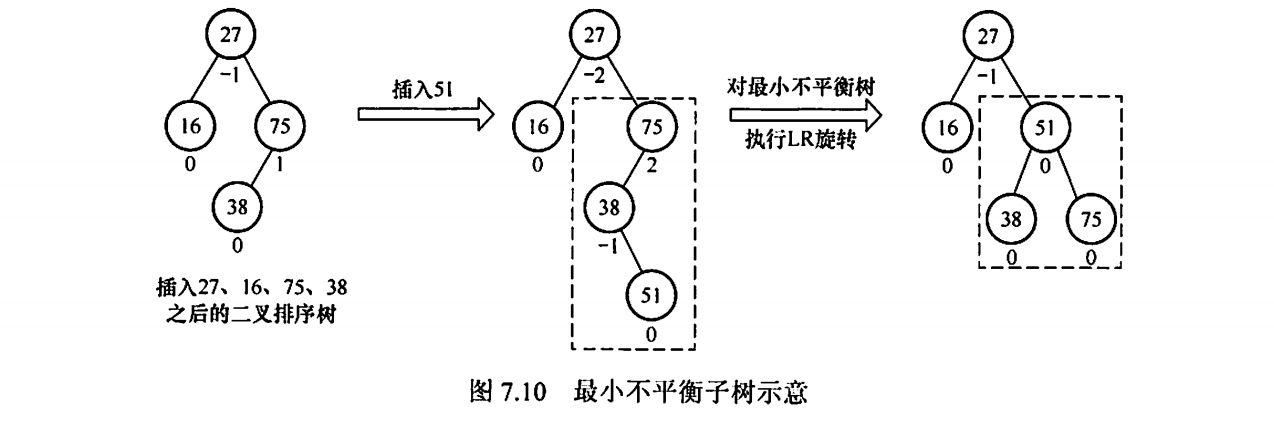
如图,我们是从75开始,按照LR的顺序旋转,而不是从27开始,虽然这俩都是不平衡因子
LL
右单旋转,至于为什么叫LL的原因是因为在结点A的左孩子(L)的左子树(L)上插入了新结点
旋转时,选取中间的节点作为旋转节点
RR
左单旋转
旋转时,选取中间的节点作为旋转节点
LR
先左旋再右旋
旋转时,选取最下面的节点左旋,再选中间值作为旋转节点
RL
先右旋后左旋
旋转时,选取最下面的节点左旋,再选中间值作为旋转节点,实际上,这个中间值是被移过来的最小面的节点
删除
这个知识点连接较少,着重记录一下
1、若删除结点后,有一个结点造成产生不平衡因子
如图,执行RR旋转
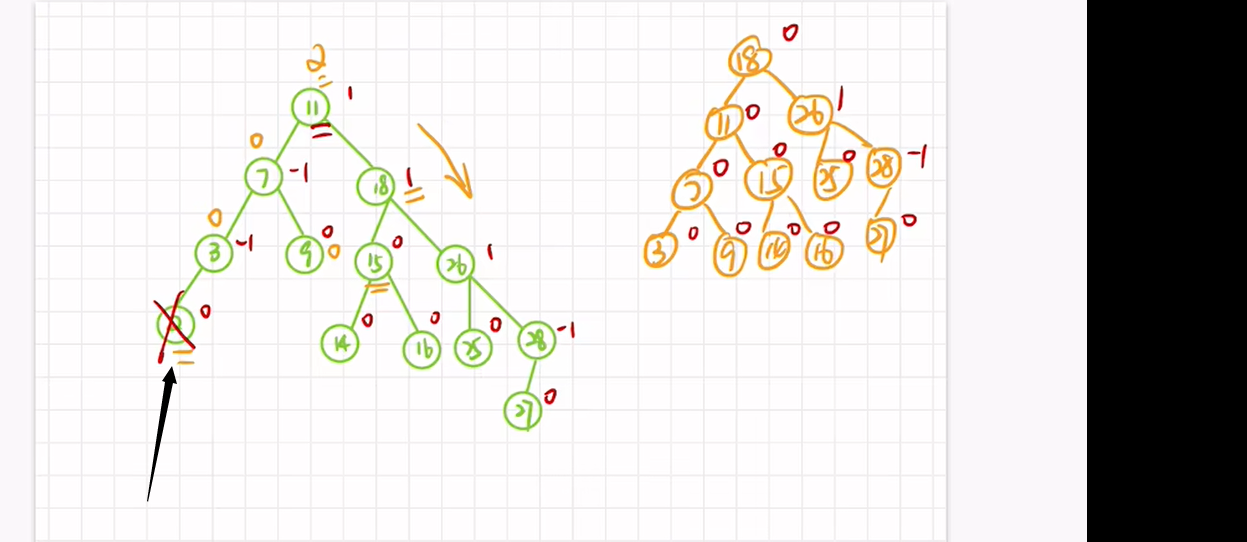
2、若删除结点后,有两个结点造成产生不平衡因子
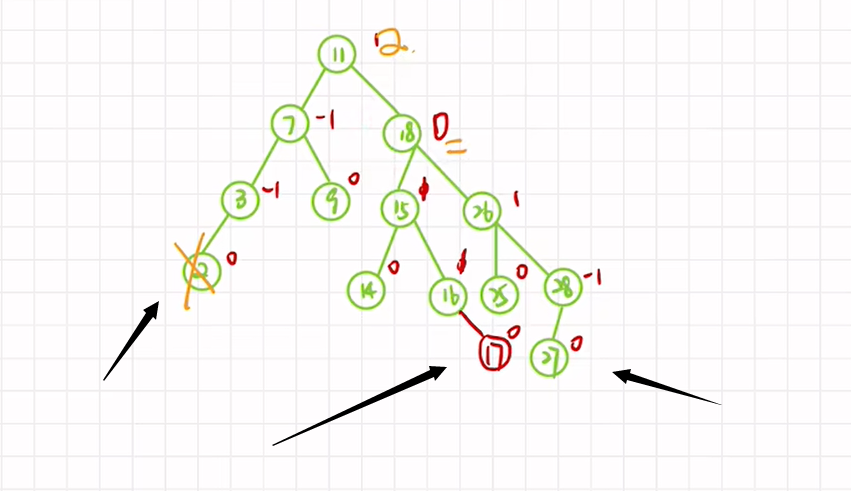
这时,我们应该选RL还是RR旋转呢?
都可以!!!
但明显选RR更简单
3、旋转后还不平衡的情况
那就多次旋转
删除9:
执行LL操作:
发现还不平衡,并且11作为平衡因子
这时我们可以采取RR或RL旋转策略,RR更简便
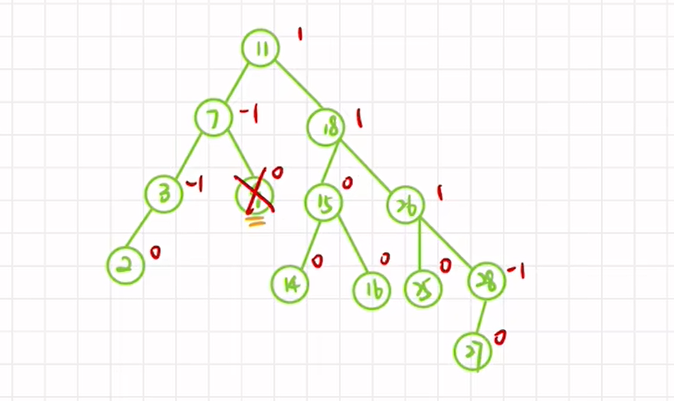
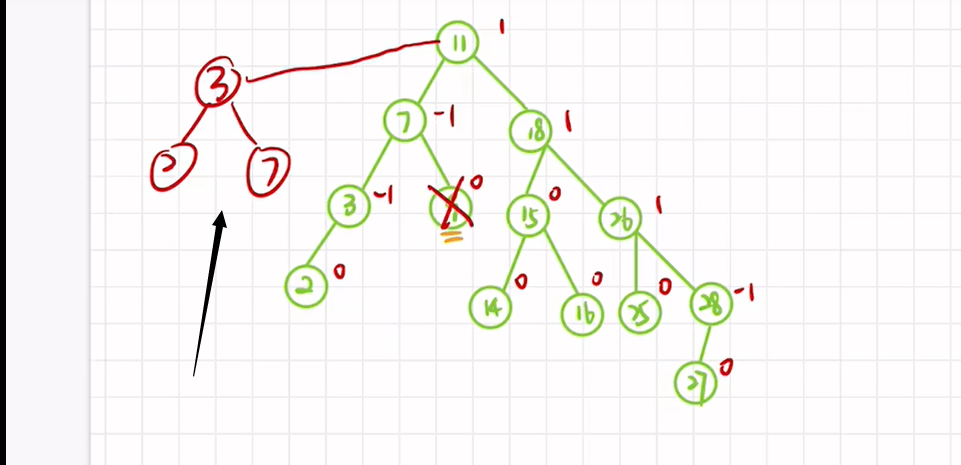
4、删除非叶子结点
与排序二叉树差不多
先按中序序列用前驱或后继替换,再进行平衡性调整
比如,删除根结点:
或
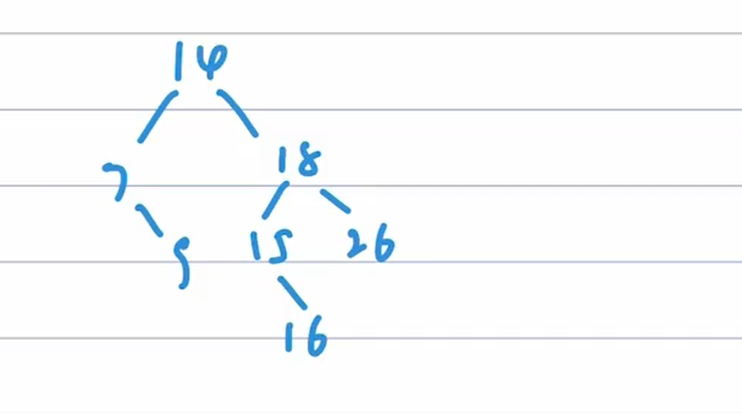
红黑树
自加入新大纲以来还没考过,必须狠狠的提防
红黑树的概念
AVL树插入和删除操作后,需要非常频繁的调整全树整体拓扑,代价很大,因此引入了红黑树
1、每个结点或是红色或是黑色
2、根节点一定是黑色
3、叶结点一定是黑的
4、不存在两个相邻的的红结点(红结点的父节点与子结点均是黑色的)
5、对每个结点,从该结点到任一叶结,点的简单路径上,所含黑结点的数量相同。
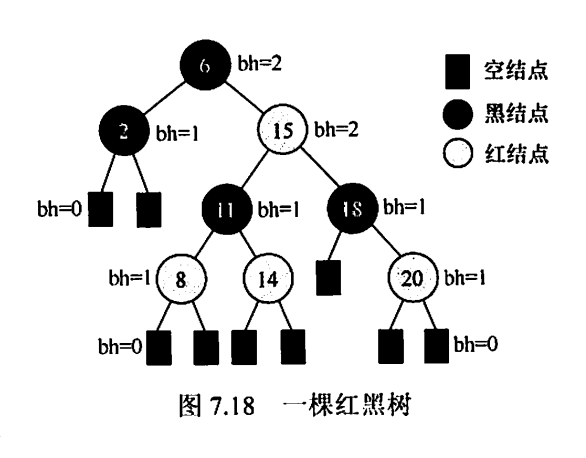
黑高
从某结点出发(不含该结点)到达一个叶结点的任一简单路径上的黑结点总数称为该结点的黑高(记为bh),黑高的概念是由性质⑤确定的。根结点的黑高称为红黑树的黑高。
结论一
从根到叶结点的最长路径不大于最短路径的2倍
原因:
1、当根到任一叶结点的简单路径最短时,这条路径必然全由黑结点组成
2、当路径最长时,一定是黑红相见
结论二
有n个内部结点的红黑树的高度为:
证明:由结论1可知,从根到叶结点(不含叶结点)的任何一条简单路径上都至少有一半是黑结点,因此,根的黑高至少为h/2,于是有,即可求得结论。
证明过程参考:
https://blog.csdn.net/luixiao1220/article/details/104648112
结论三
新插入红黑树的结点初始着色为红色
如果新插入结点着色为黑色,那么这个结点所在路径比其他路径多出一个黑结点,破环了性质5,需要进行调整,比较麻烦
如果新插入结点的着色是红色,仅需出现连续的两个红结点才需调整
红黑树的插入
设结点z为将要插入的结点
1、若插入的z为根节点,则将其着色为黑色
2、按二叉排序树的方法插入,着色为红色。若z的父节点为黑色,则不进行任何处理
3、若z不是根节点且父节点为红色,则分三种情况
首先,要明白,z的父节点为红色的花,z的爷节点一定为黑色
设z.p是z的父节点
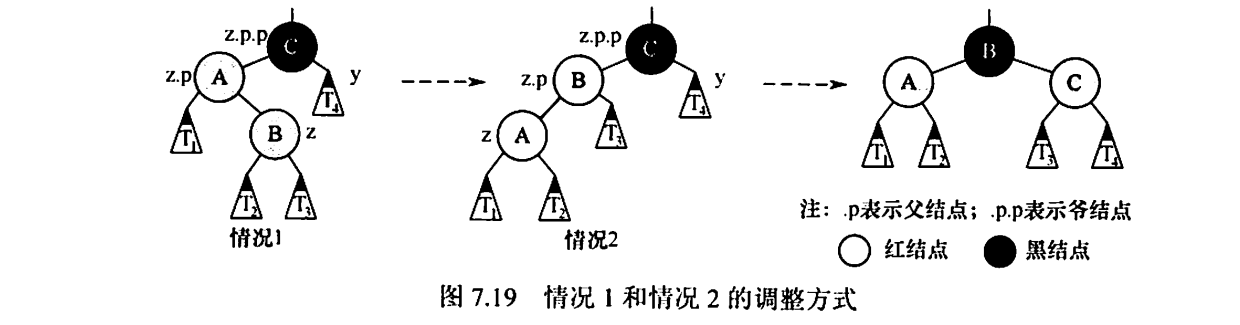
情况一: z的叔节点y是黑色的,且z是一个右孩子
没有叔叔也把叔叔当成黑色处理
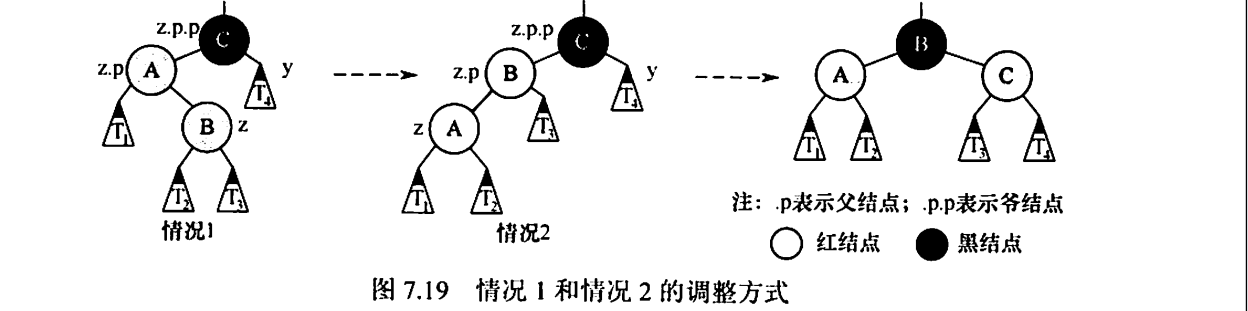
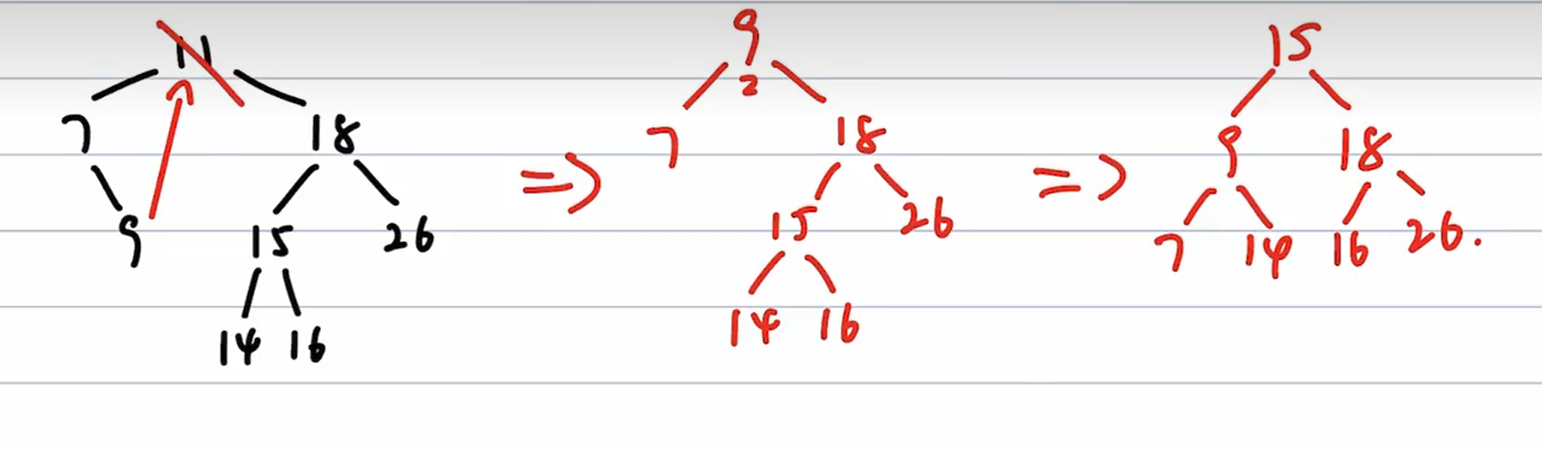
情况1(LR,先左旋,再右旋),即z是爷结点的左孩子的右孩子。先做一次左旋将此情形转变为情况2(变为情况2后再做一次右旋),左旋后z和父结点z.p交换位置。因为z和z.p都是红色的,所以左旋操作对结点的黑高和性质⑤都无影响。
情况二: z的叔节点是黑色的,且z是一个左孩子
没有叔叔也把叔叔当成黑色处理
情况2(LL,右单旋),即z是爷结点的左孩子的左孩子。做一次右旋,并交换z的原父结点和原爷结点的颜色,就可以保持性质⑤,也不会改变树的黑高。这样,红黑树中也不再有连续两个红结点,结束。
情况三: z的叔节点y是红色的
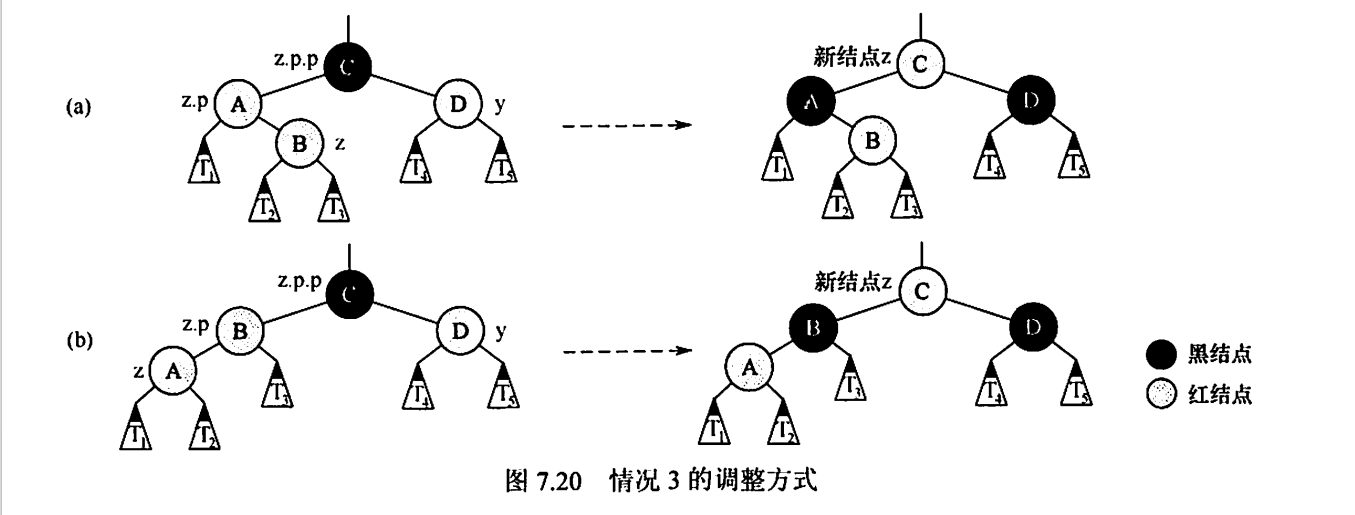
情况3(z是左孩子或右孩子无影响),z的父结点z.p和叔结点y都是红色的,因为爷结点z.p.p是黑色的,将z.p和y都着为黑色,将z.p.p着为红色,以在局部保持性质④和⑤。然后,把z.p.p作为新结点z来重复循环,指针z在树中上移两层。
总结:
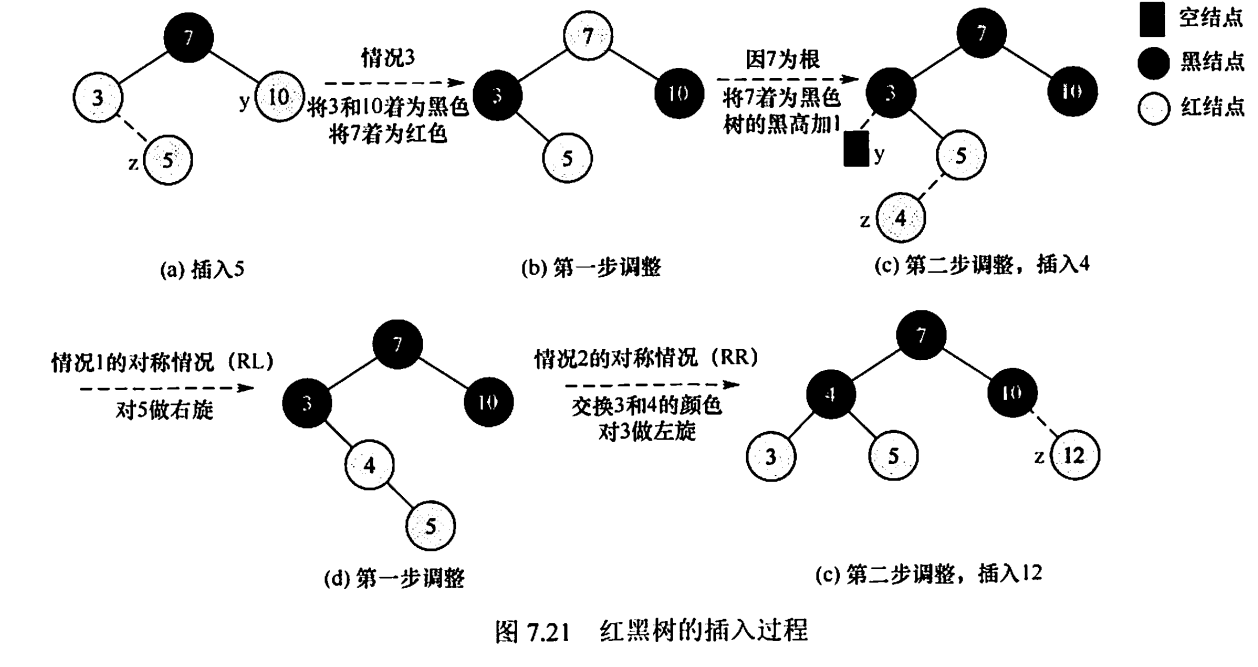
1、插入节点后先看父节点,父节点为黑直接插
2、父不为黑(爷必为黑),看叔叔,若叔为黑,则左右旋,且交换原父爷的颜色,若叔不为黑,则爷变红,父叔变黑
注意: 交换原父爷颜色的是相对于最近的一次移动说的,例如,我们设一棵红黑树的初始状态为T,让其执行LR操作,执行LR操作后T状态变为TL状态,此时是不需要交换任何颜色的,之后执行R操作,我们设执行R操作之后的状态为TLR;TLR的变色操作是对于TR状态的父爷进行颜色交换,如下图
练习:
这个up讲的很通透:
https://www.bilibili.com/video/BV1fw41117zt/?p=3&spm_id_from=pageDriver
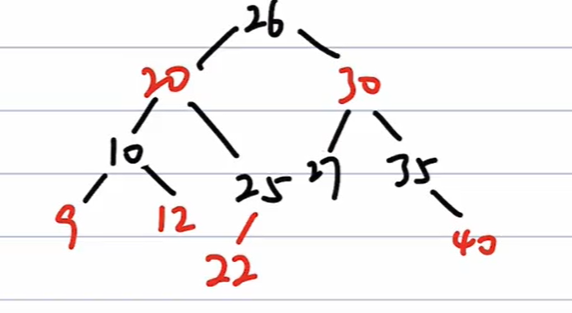
练习一
插入22的步骤:
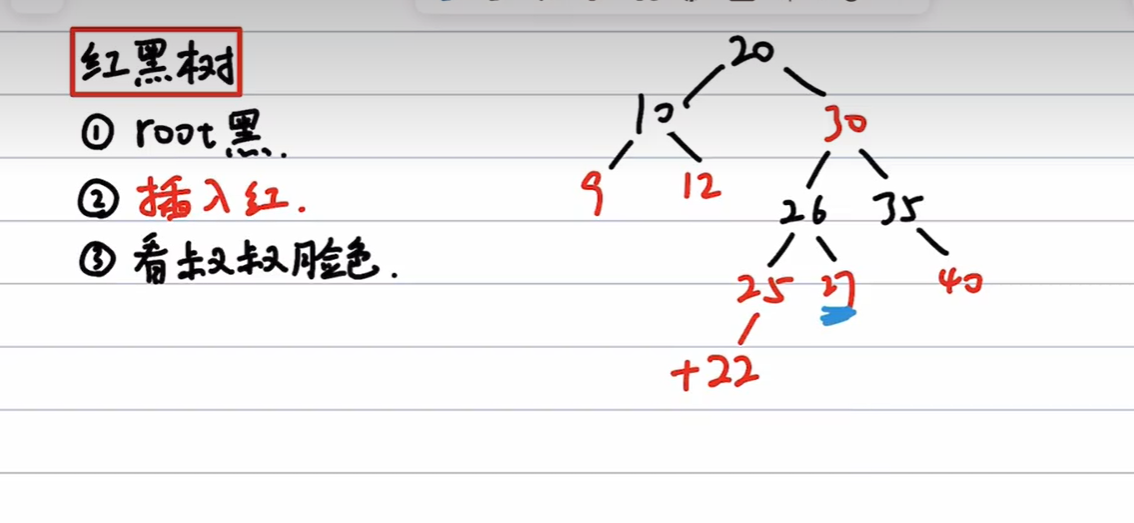
(1)、不为根且父为红,叔为红,则进行只变色不旋转:
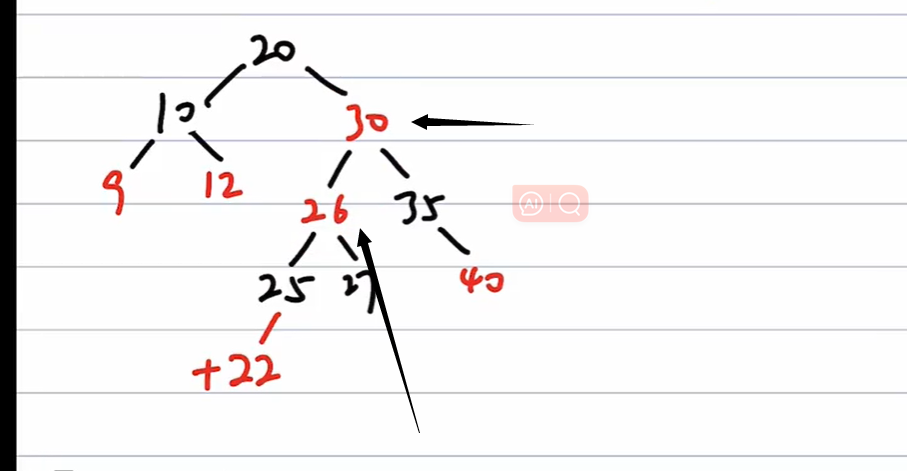
注意到还是有红相连
(2)、对于26,不为根,父为红,叔为黑,则以20 - 30 - 26 为轴进行RL旋转:
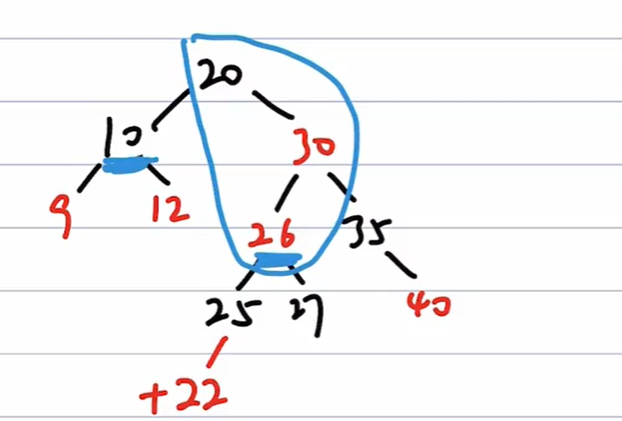
=>
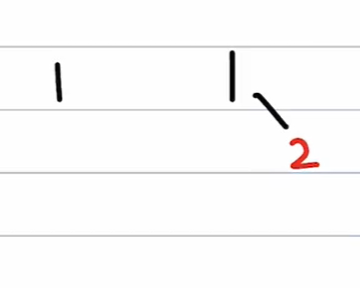
练习二
红黑树依次插入 1 2 3 4 5 6 7
插入1 2
插入 3
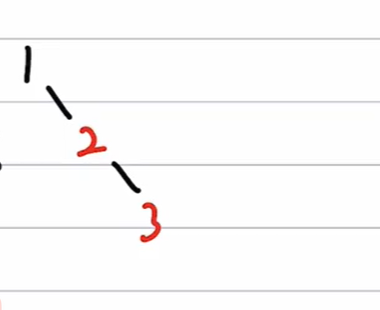
=> 非根,父红,叔黑 => RR旋转,旋转后交换爷父颜色
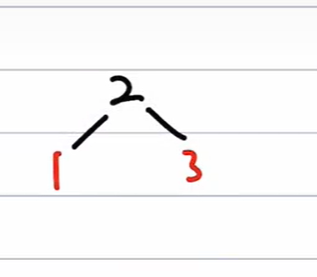
插入4
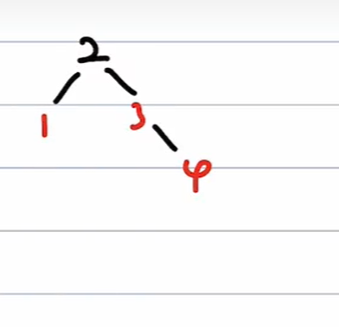
=> 非根,父红,叔红 => 只变色,爷、叔、父翻转颜色 => 爷为根节点,必须为黑色
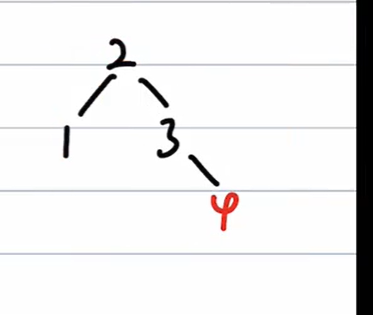
插入5
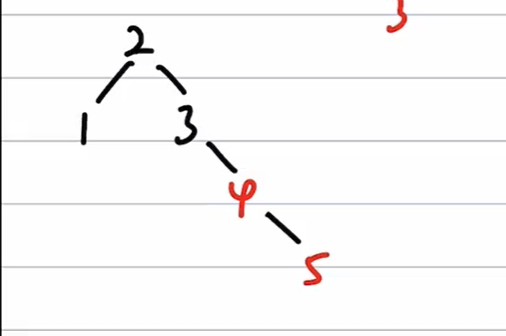
=> 非根,父红,叔黑 => RR旋转
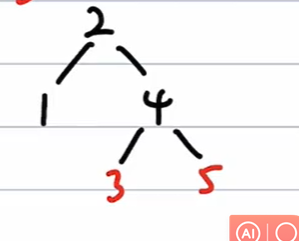
插入6
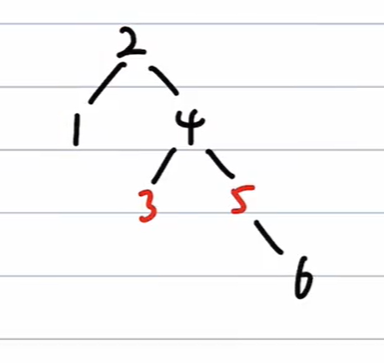
=> 非根,父红,叔红 => 只改变颜色,父、爷、叔翻转颜色
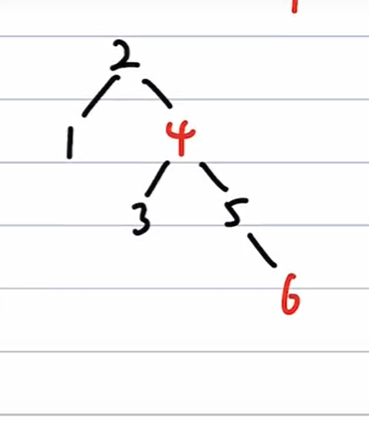
插入7
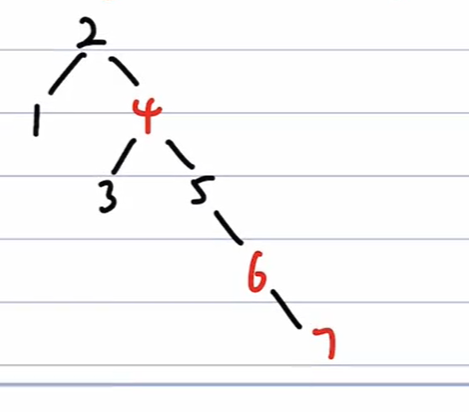
=> RR变换
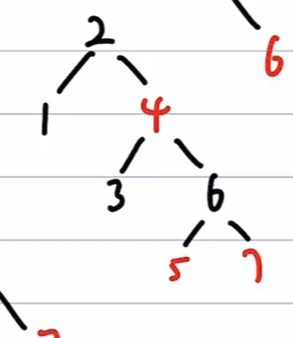
红黑树删除(不打算复习了)
红黑树与其他树的比较
1、红黑树的查找效率一般低于AVL树,查找、插入、删除的时间复杂度相同
红黑树在维护方面强于AVL,空间开销类似,内容多时略优于AVL
两者在不同的场景下均有各自略微的优势
B树
B树掌握的很不好
B树的应用主要用在文件系统以及数据库中做索引等
概念
m阶B树是所有节点的平衡因子均等于0的m路平衡查找树
1、树中每个节点至多有m棵子树
2、若根节点不是叶节点,则至少有两棵子树
3、除根节点外所有非叶子节点至少有 棵子树,即最少含有 个关键字
4、所有叶节点都出现在同一层上,并且不携带信息(可以视为外部节点或类似于折半查找判定树的查找失败节点)
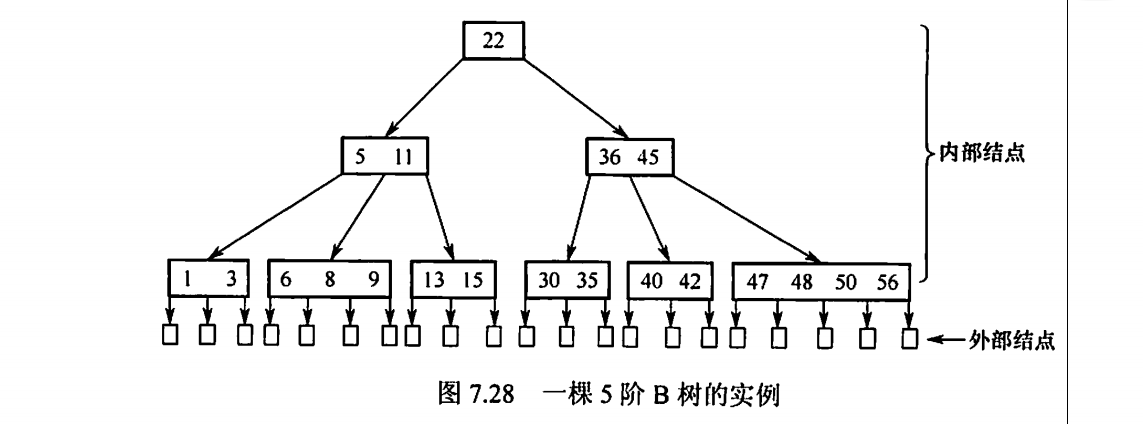
性质
1、节点的孩子个数等于该节点中关键字的个数加1.
这是显然的。。
2、如果根节点没有关键字就没有子树,此时B树为空;如果根节点有关键字,则其子树个数必大于等于2,因为子树个数等于关键字个数加1
当然,根节点的关键字可以大于1
3、除根节点外所有非叶节点至少有 棵子树,至多有m棵子树
4、所有叶节点均在最后一层,代表查找失败的位置
B树高度的性质
性质一
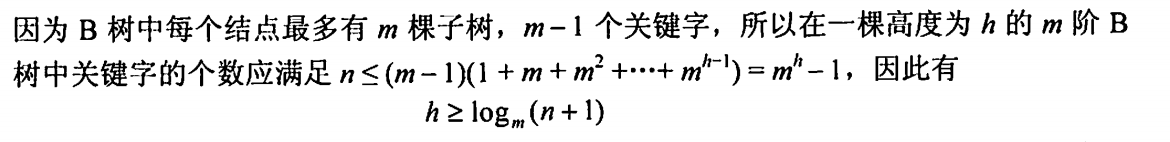
性质二
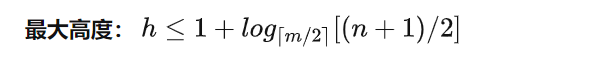

B树的查找
B树的查找包含两个基本操作:①在B树中找结点;②在结点内找关键字。由于B树常存储在磁盘上,因此前一个查找操作是在磁盘上进行的,而后一个查找操作是在内存中进行的,即在找到目标结点后,先将结点信息读入内存,然后在结点内采用顺序查找法或折半查找法
拓展---B树的磁盘读取过程
文件系统的设计者利用了磁盘预读原理,将一个结点的大小设为等于一个页(1024个字节或其整数倍),这样每个结点只需要一次I/O就可以完全载入。那么3层的B树可以容纳102410241024差不多10亿个数据,如果换成二叉查找树,则需要30层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在10亿个数据中查找目标值,只需要小于3次硬盘读取就可以找到目标值,但红黑树需要小于30次,因此B树大大提高了IO的操作效率。
磁盘首先看根节点,找到根节点相对应的节点,之后从磁盘中读取该节点,再找该节点指向的节点,再读取磁盘...
B树的插入
1、定位
找到在哪个节点实行插入操作
2、插入
在 B 树中,每个非失败结点的关键字个数都在区间,插入后的结点关键字个数小于m,可以直接插入;插入后检查被插入结点内关键字的个数,当插入后的结点关键字个数大于m一1时,必须对结点进行分裂。

例如:
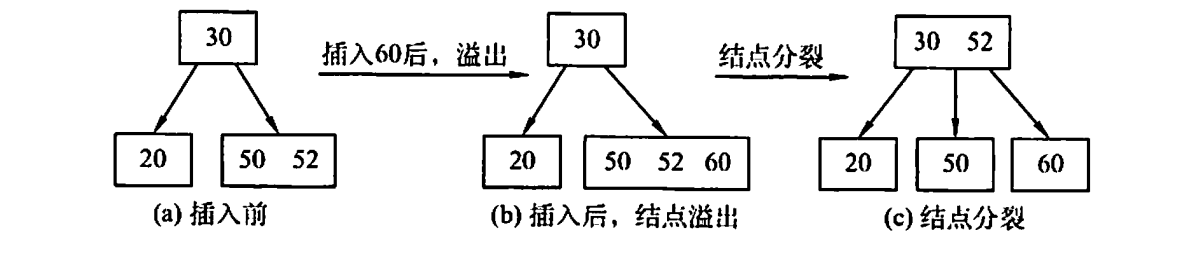
插入例题
要能熟练的完成B树的插入,我们需要记住
1、关键字的范围在 到 这个范围内
2、每次分裂的时候,是从中间位置 做分界线,做部分放在原节点,右部分放在新节点,中间位置 上移
口诀就是,满了之后网上挤
参考:
讲的十分通透
B树的删除
相比于插入,删除要难上一些
一、删除非终端节点k时
与之前学的类似,用k的前驱或后继代替(交换)k的位置,然后再删除k
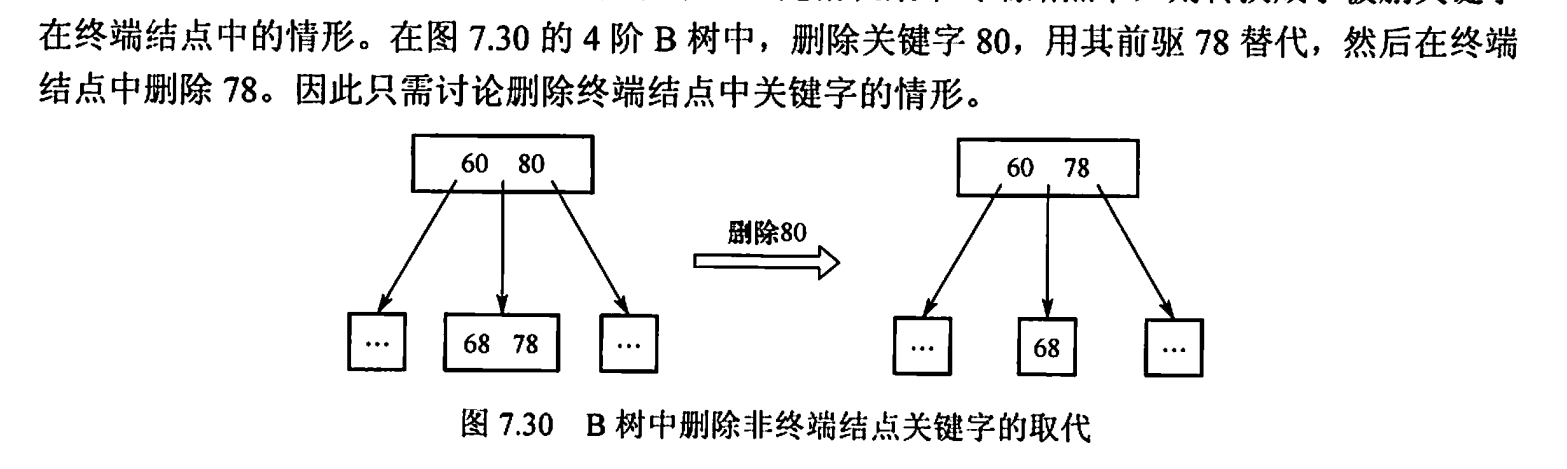
二、删除终端节点k时
-
直接删除关键字
当被删除关键字所在节点的关键字个数 时,直接删去即可
-
兄弟够借
当被删除关键字所在节点的关键字个数 ,且与其相邻的左/右兄弟节点的关键字 时,则可以借节点,需要注意的是要使用父子换位法
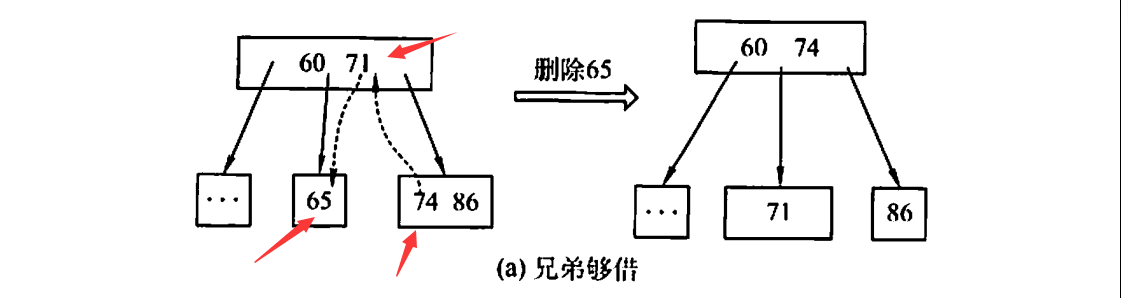
-
兄弟不够借
当被删除关键字所在节点的关键字个数 ,且与其相邻的左/右兄弟节点的关键字也 时,则将关键字删除后与左/右兄弟节点以及双亲结点>的关键字进行合并。
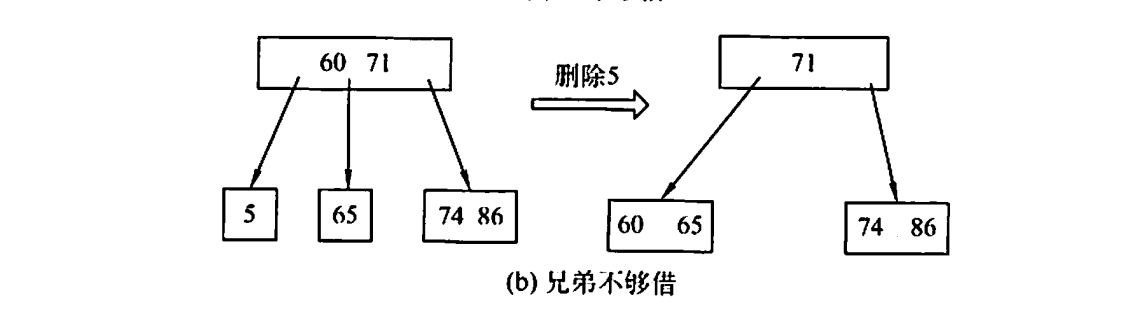
在合并过程中,双亲结点中的关键字个数可能会减一,若其双亲结点是根结点且关键字个数减少至0,则直接删除根结点,合并后的新结点成为根;
若双亲结点不是根结点,且关键字个数减少至 ,则又要与他自己的兄弟结点进行调整或合并,并重复上步骤
B树的删除例子---一直向子/兄弟结点借且最后能借到
对于这样一个B树,我们删除25
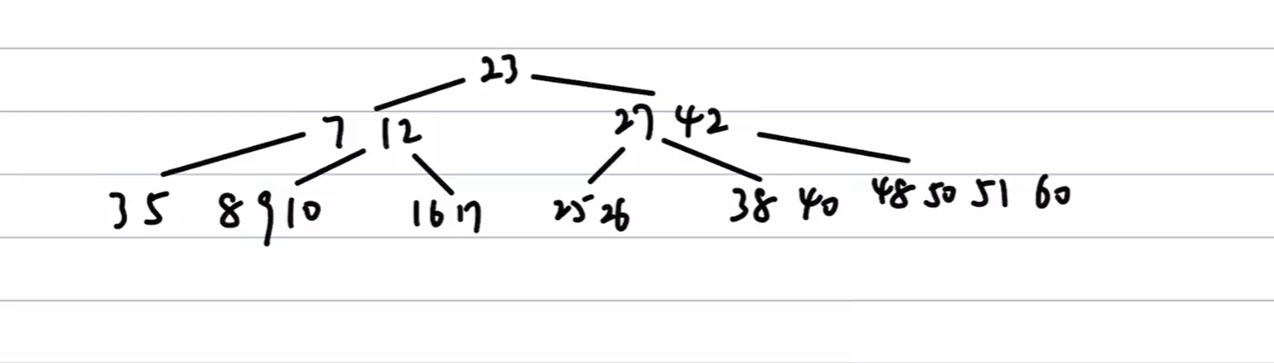
有:
- 删除25后,结点大小不满足 大于 ,则向父节点借27
- 借27之后,父节点也不满足 ,父结点向 38,40结点借 38
- 借38之后,40结点不满足 ,向父节点借42
- 借42之后,父结点不满足 ,则向 48,50,51,60结点借48
完毕
如图:
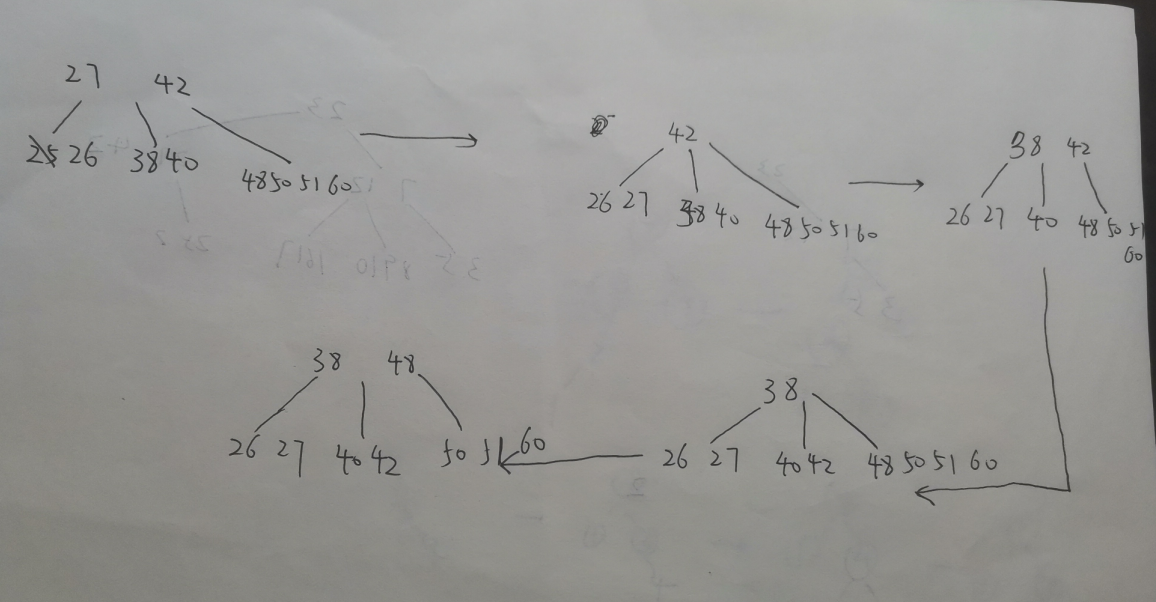
B树删除的例子---合并父节点 节点相对富有
第一种情况:
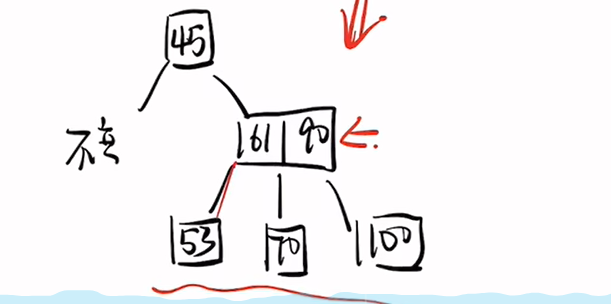
删除53:
1、删除53,61下去
2、合并61与70
再看一中复杂的情况:
这是一棵五阶B树
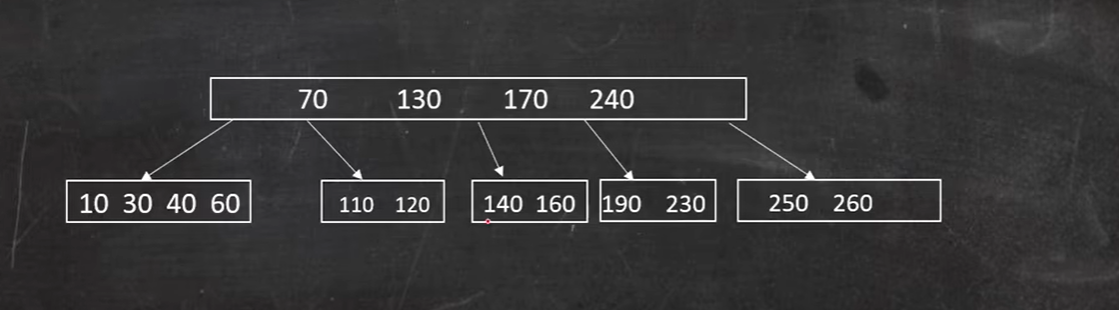
删除 140
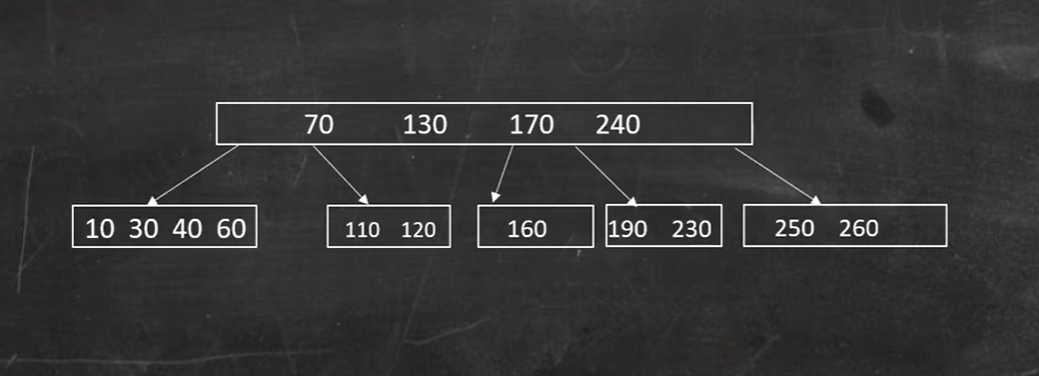
兄弟借不到,借父节点:
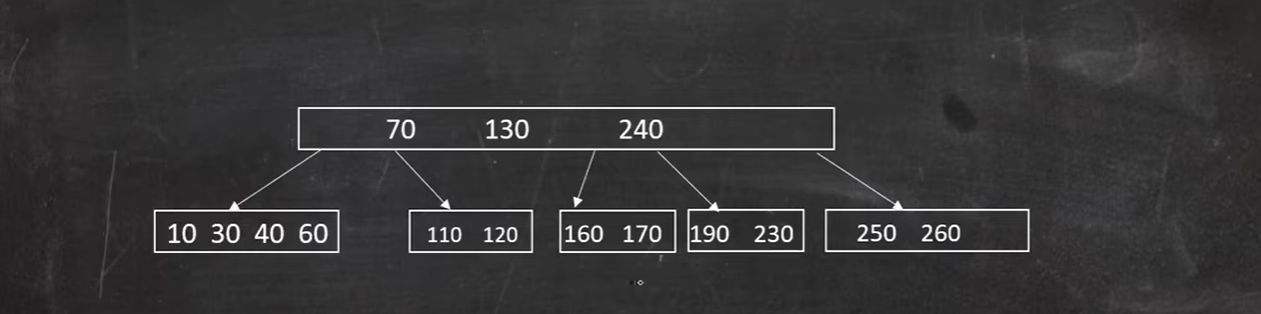
此时父节点不满足条件,则合并160 170 190 230 :
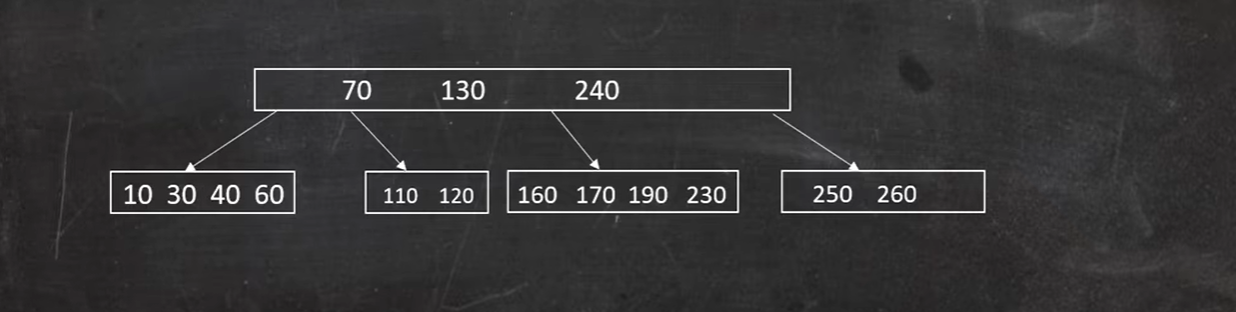
B树删除的例子---合并父节点 节点不富裕的情况下
这是一棵五阶B树
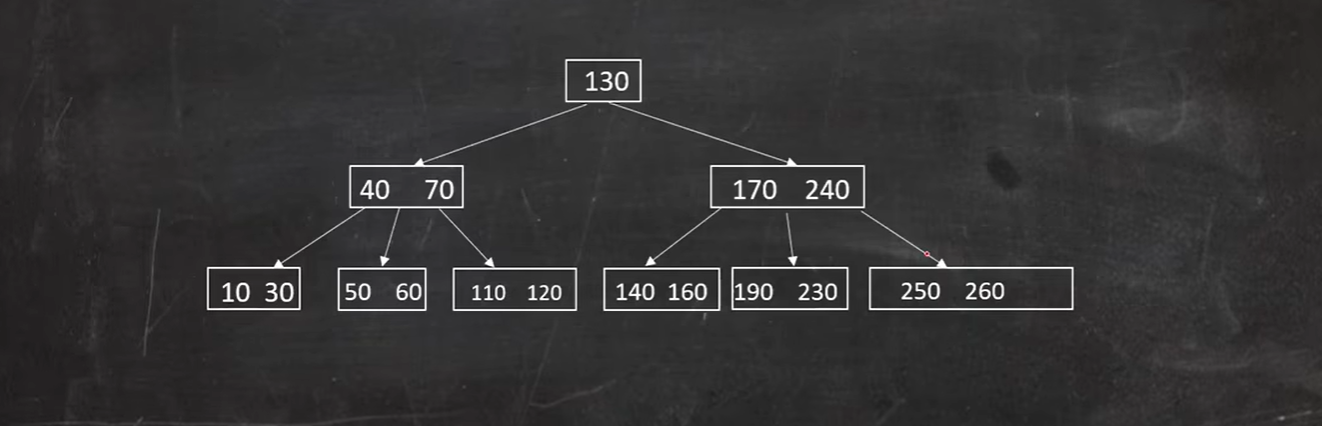
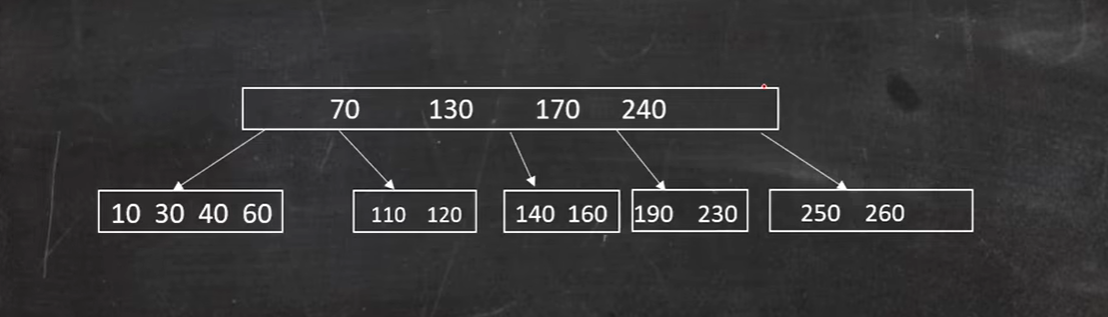
如图,删除50:
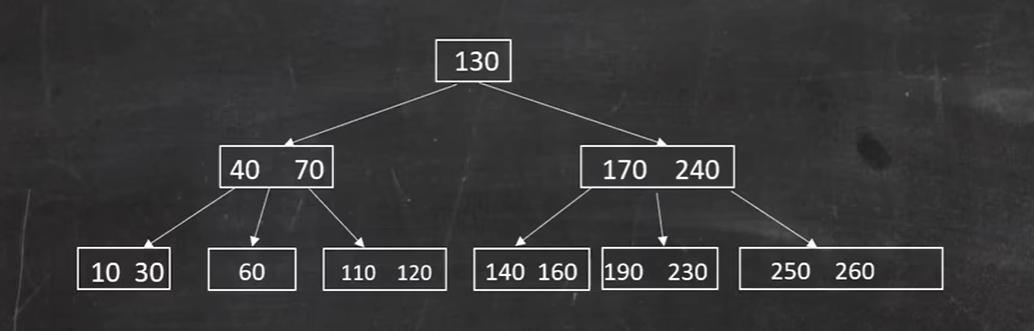
60节点借不到兄弟节点,只能借父节点的40,父节点只有70,则只能合并节点:
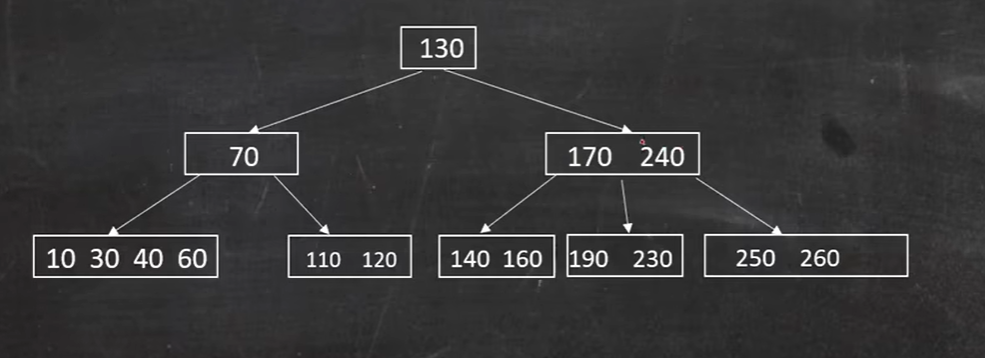
此时父节点还是不满足 大于
向兄弟节点借借不到,只能向父节点借,
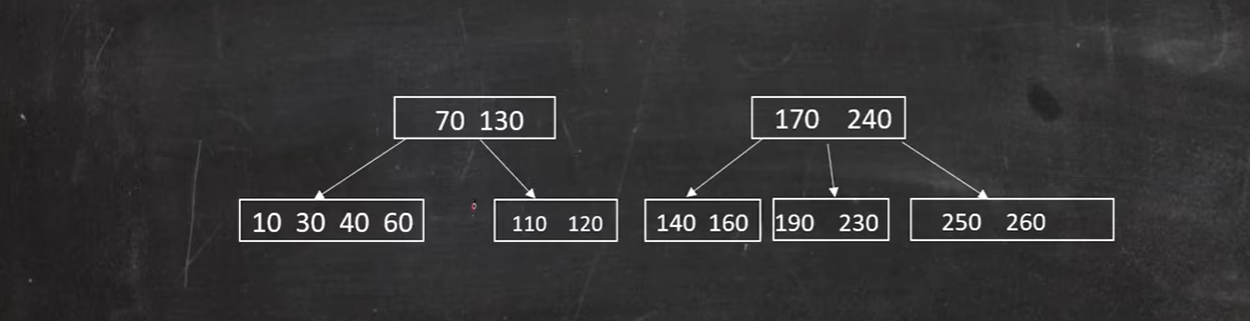
合并:
B+树
B+树考的很少,且都是概念上的,感觉重要性与红黑树差不多
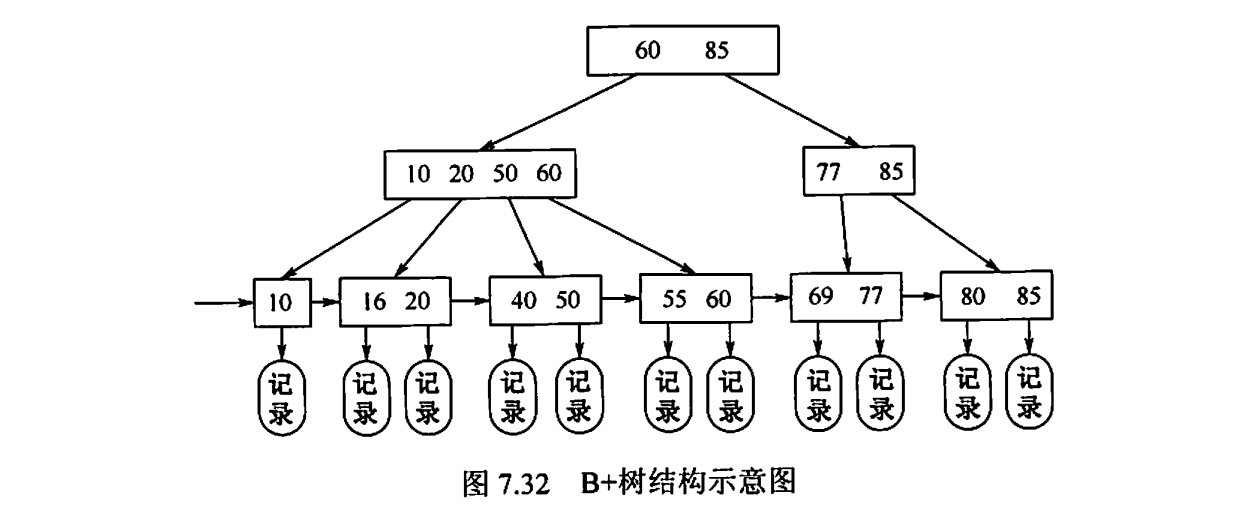
B+树概念
一棵m阶的B+树需要满足下面条件:
-
每个分支结点最多有m棵子树(孩子结点)。
-
非叶根结点至少有两棵子树,其他每个分支结点至少有 [m/2]棵子树。
-
节点子树个数与关键字个数相等
-
所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来。
-
所有分支结点(可视为索引的索引)中仅包含它的各个子结点(即下一级的索引块)中关键字的最大值及指向其子结点的指针。
上面标黄的部分是重点要记住的部分
B与B+树的主要差异
-
m阶B+树中,具有n个关键字的节点就会含有n个子树,而B树中会含义n+1个
-
在B+树中,每个结点(非根内部结点)的关键字个数n的范围是[m/2]≤n≤m(根结点:2≤n≤m),在B树中,每个结点(非根内部结点)的关键字个数n的范围是[m/2]-1≤n≤m-1(根结点:1≤n≤m-1)。
B+树的根节点的关键字数可以为2
-
在B+树中,叶结点包含所有信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
-
在B+树中,叶结点包含了全部关键字,即在非叶结点中出现的关键字也会出现在叶结点>中:
而在B树中,叶结点(最外层内部结点)包含的关键字和其他结点包含的关键字是不重复的。
B+树在查找过程中,非叶结点上的关键字值等于给定值时并不终止,而是继续向下查找,直到叶结点上的该关键字为止。所以,在B+树中查找时,无论查找成功与否,每次查找都是一条从根结点到叶结点的路径。
拓展---B/B+树的各自优势
B+ 树的优点在于:
-
由于B+树在非叶子结点上不包含真正的数据,只当做索引使用,因此在内存相同的情况下,能够存放更多的 key。
-
B+树的叶子结点都是相连的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序 排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。
B树的优点在于:
- 由于B树的每一个节点都包含key和value,因此我们根据key查找value时,只需要找到key所在的位置,就能找到value,但B+树只有叶子结点存储数据,索引每一次查找,都必须一次一次,一直找到树的最大深度处,也就是叶子结点的深度,才能找到value。
拓展---B+树的应用
在操作数据库时,我们为了提高查询效率,可以基于某张表的某个字段建立索引,就可以提高查询效率,那其实这个索引就是B+树这种数据结构实现的
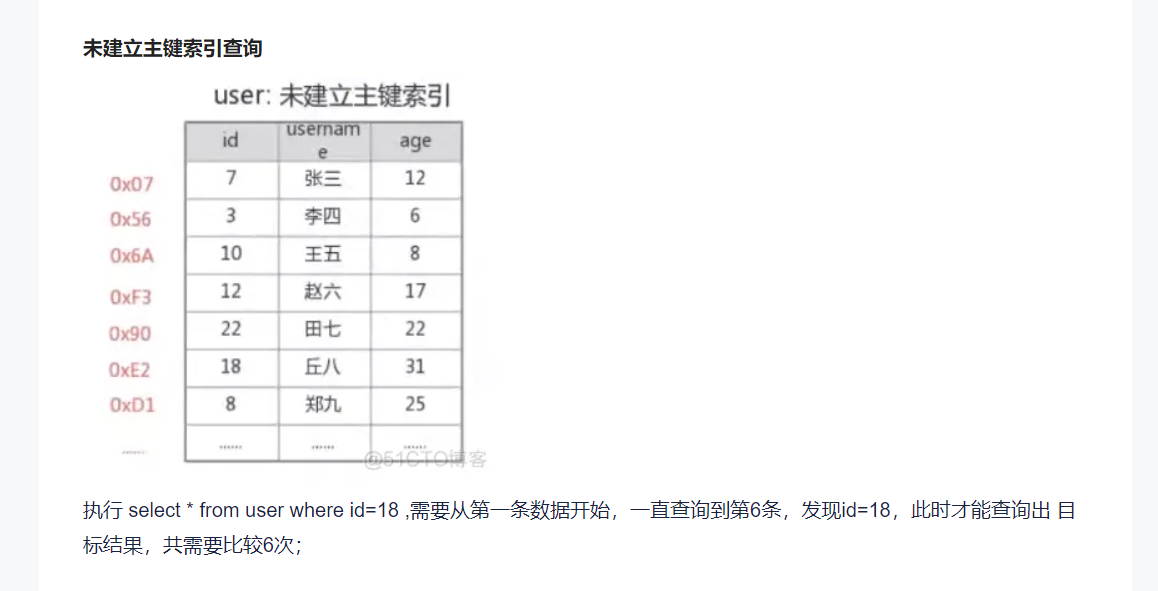
执行 select * from user where id=18 ,需要从第一条数据开始,一直查询到第6条,发现id=18,此时才能查询出 目标结果,共需要比较6次;
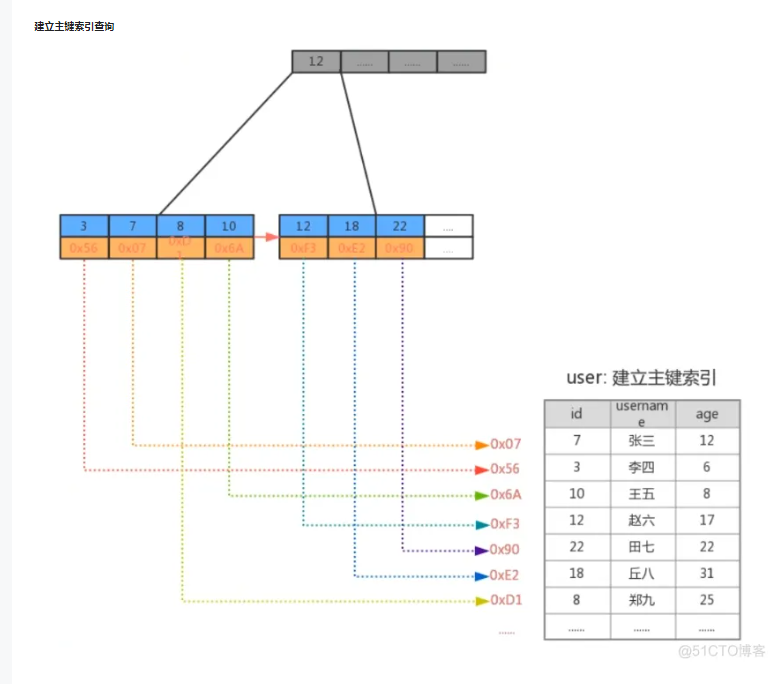
执行 select * from user where id>=12 and id<=18 ,如果有了索引,由于B+树的叶子结点形成了一个有序链表, 所以我们只需要找到id为12的叶子结点,按照遍历链表的方式顺序往后查即可,效率非常高
B/B+树的应用---考点
B+树更适合文件索引和数据库索引
散列表
散列表没啥好记得,用好小本本即可
另外,牢牢记住开放定址法的查找失败的ASL的坑!!!
还有拉链法的ASL也有坑
---12·3日补充---
散列表的删除
1、散列表的删除是懒惰删除
2、懒惰删除仅仅是指标记一个元素被删除,而不是整个清除它。被删除的位点在插入时被当作空元素,在搜索之时被当作已占据
3、原因
我们不能单纯地把要删除的元素设置为空,因为我们在讲述查找操作的时候,一旦我们通过线性探测方法,找到一个空闲 位置,我们就可以认定散列表中不存在这个数据。
但是,如果这个空闲位置是我们后来删除 的,就会导致原来的查找算法失效。本来存在的数据,会被认定为不存在。这个问题如何解 决呢?
我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
时间复杂度分析
二叉排序树
查找效率:
AVL树
https://www.cnblogs.com/biyeymyhjob/archive/2012/07/24/2606718.html
查找效率:
插入效率:
删除效率:
红黑树
查找效率:
插入效率:
删除效率:
修改效率:
B+树
https://juejin.cn/s/b%2B树的时间复杂度
查找效率:
插入效率:
删除效率:
B树
查找效率:
插入效率:
删除效率:
总结
1、折半查找的生成树是平衡二叉树,平衡二叉树的最大分支高度为$ H=\lceil\log_{2}(n+1)\rceilH-1$ (因为是平衡二叉树,高低差不超过1)
2、平衡二叉树的递推公式(重要,在解一些题目时可以大大加快解题速度)
设表示高度为h的平衡二叉树中含有的最少节点数,注意是所有层的节点和
= 1
= 2
有点像斐波那契数列捏
3、B树
4、红黑树、B+树
__EOF__

本文链接:https://www.cnblogs.com/lordtianqiyi/p/17760065.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现