羊城杯_2021 OddCode 天堂之门 + unicorn反混淆
一、天堂之门
输入字符串并进行校验后,有一处远跳,看其硬编码,发现cs段寄存器变成了0x33,天堂之门无疑,

并且,我们通过硬编码发现,IDA解析的函数跳转有误,应该是 jmp far ptr 0x405310才对
0x0405315地址的位置,显然是天堂之门切换为了32位

我们修改exe的PE结构中的魔数,使其能在IDA64位下分析,再次打开后,发现代码还是混淆严重,无法阅读,各种垃圾指令干扰阅读...
那我们就考虑到使用unicorn来模拟64位代码的运行
二、unicorn模拟代码运行
为什么使用unicorn呢? unicorn中有一类Hook函数,它可以记录程序读写了那些指令或地址,跳转到了哪些地址,我们可以观察程序对关键地址的读写或程序的转移位置来忽视混淆
我们首先用Hook函数查看程序的转移位置,查看程序对input和key的地址做了什么
from unicorn import * from unicorn.x86_const import * from struct import * with open(r"C:\Users\TLSN\Desktop\OddCode.exe",'rb') as fp: fp.seek(0x400) X64code = fp.read(0x5000) class UniVm: def __init__(self,strr): # 创建虚拟机 mu = Uc(UC_ARCH_X86, UC_MODE_64) # 分配内存 分配10 * 0x1000的大小 ADDRESS = 0x7d1000 # 初始地址 20mb mu.mem_map(ADDRESS, 20 * 0x100000) # 填充内存 mu.mem_write(ADDRESS, X64code) # 填充寄存器 注意入口点的选取和寄存器有关系 mu.reg_write(UC_X86_REG_RAX, 1) mu.reg_write(UC_X86_REG_RBX, 0xc8402d) mu.reg_write(UC_X86_REG_RCX, 0x9098de57) mu.reg_write(UC_X86_REG_RDX, 0x768c9cca) mu.reg_write(UC_X86_REG_RSI, 0x7d701d) mu.reg_write(UC_X86_REG_RDI, 0x7d705c) mu.reg_write(UC_X86_REG_RBP, 0xf5faf8) mu.reg_write(UC_X86_REG_RIP, 0x7d1010) mu.reg_write(UC_X86_REG_RSP, 0xf5fae0) # mu.reg_write(UC_X86_REG_FLAGS, 0x202) # 填充堆栈 # mu.mem_write(0x0f5fae0, b'\x15\x53\x7d\x00\x00\x00\x00\x00') # mu.mem_write(0x0f5fae8, b'\x6c\x52\x7d\x00\x39\x67\xa1\x76') # mu.mem_write(0x0f5faf0, b'\x00\x40\xc8\x00\x20\x67\xa1\x76') # mu.mem_write(0x0f5faf8, b'\x50\xfb\xf5\x00\xef\x8f\x29\x77') # 填充input 和 key mu.mem_write(0x007d701D, strr) # mu.mem_write(0x007d705C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D') # 关键指令,通过Hook函数代码保存代码轨迹 mu.hook_add(UC_HOOK_CODE, self.hook_code, begin=ADDRESS, end=ADDRESS + len(X64code)) mu.hook_add(UC_HOOK_MEM_READ, self.hook_read_mem) ADDRESS = 0x7d1000 LocIns_Addr = 0 Pre_Ins_Size = 0 Nums = 0 Save_Rip = [] self.mu = mu self.LocIns_Addr = LocIns_Addr self.Nums = Nums self.Save_Rip = Save_Rip self.ADDRESS = ADDRESS self.Pre_Ins_Size = Pre_Ins_Size # Hook指令 def hook_code(self, mu, address, size, data): if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size: self.Save_Rip.append(address) self.Nums += 1 self.LocIns_Addr = address self.Pre_Ins_Size = size #Hook读地址 def hook_read_mem(self,uc, access, address, size, value, data): if address >= 0x007d701D and address <= 0x007d701D + 41: print(f'Read input[{address - 0x007d701D}] : {hex(uc.reg_read(UC_X86_REG_RIP))}') if address >= 0x007d705C and address <= 0x007d705C + 15: print(f'Read key[{address - 0x007d705C}] : {hex(uc.reg_read(UC_X86_REG_RIP))}') if uc.reg_read(UC_X86_REG_RIP) == 0x07D531A: print("okkkk") def start(self): try: self.mu.emu_start(self.ADDRESS + 0x10, self.ADDRESS + len(X64code) - 0x10) except UcError as e: print("ERROR: %s " % e) self.p_Rip() self.mu.emu_stop() def p_Rip(self): ans = 1 for i in self.Save_Rip: print(hex(i), end=",") if ans % 16 == 0: print() ans += 1 strr = b"SangFor{01234567890123456789012345678901}" UniVm(strr).start()
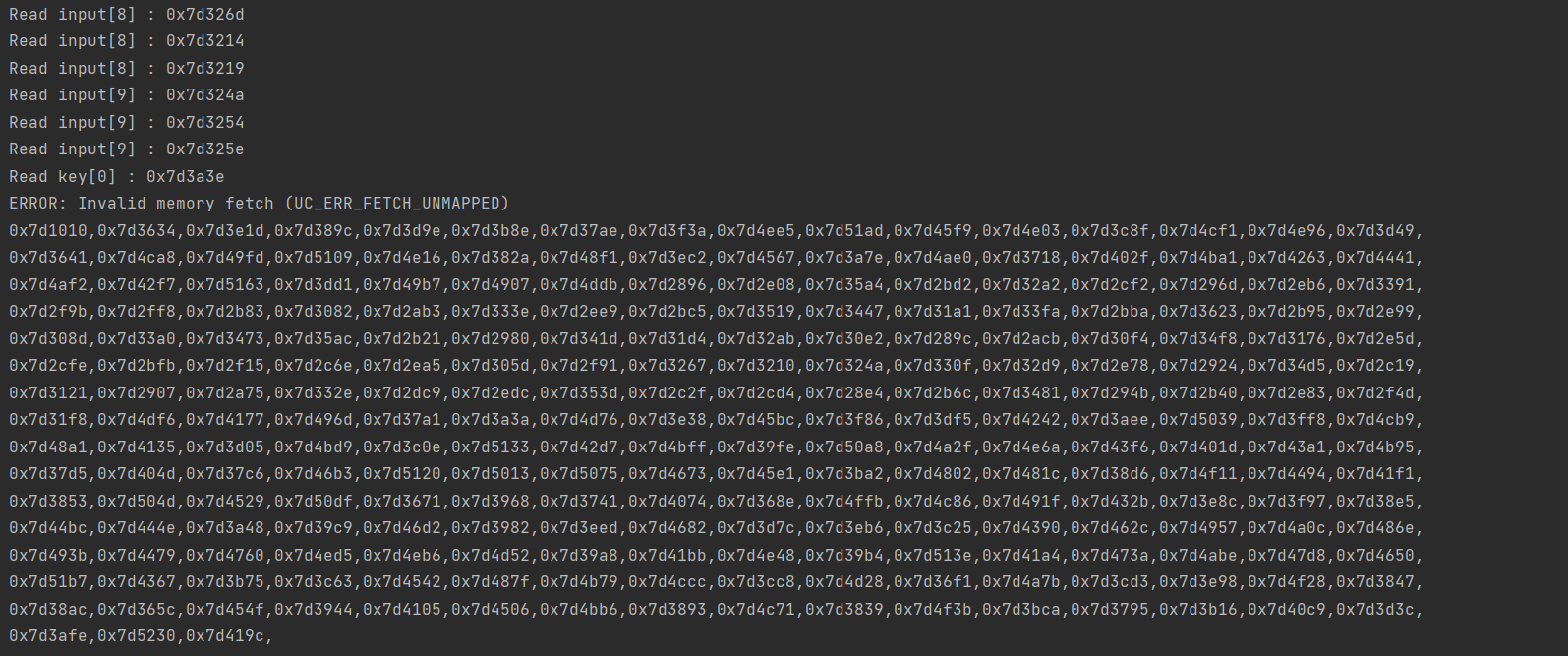
根据程序对input和key的读取,我们可以看出,程序应该是两字符两字符的进行处理,并且限制了字符的范围:

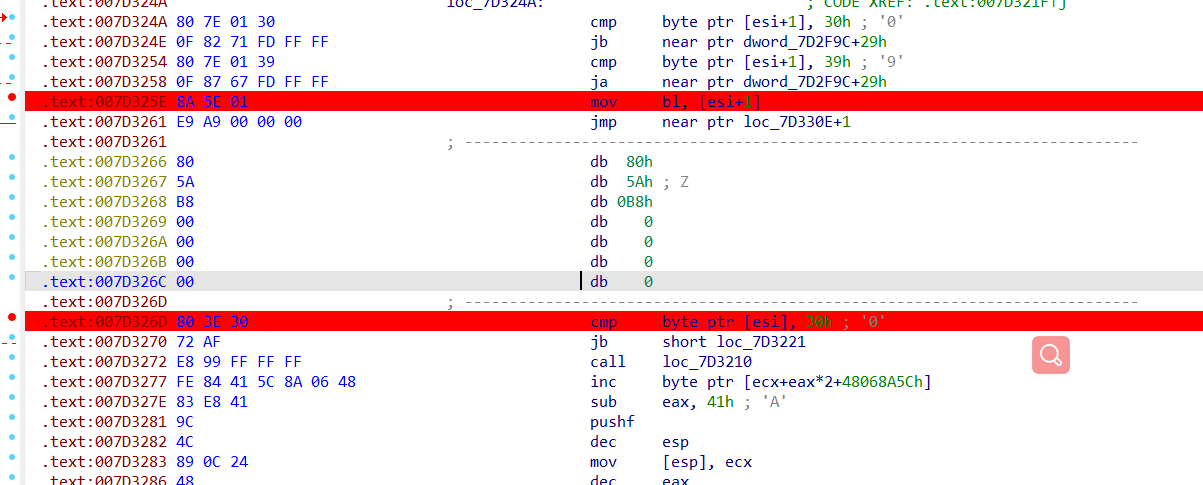
我们尝试先爆破前两个字符,得到前两个字符是A7,我们用A7替换输入并再次查看Hook的结果:
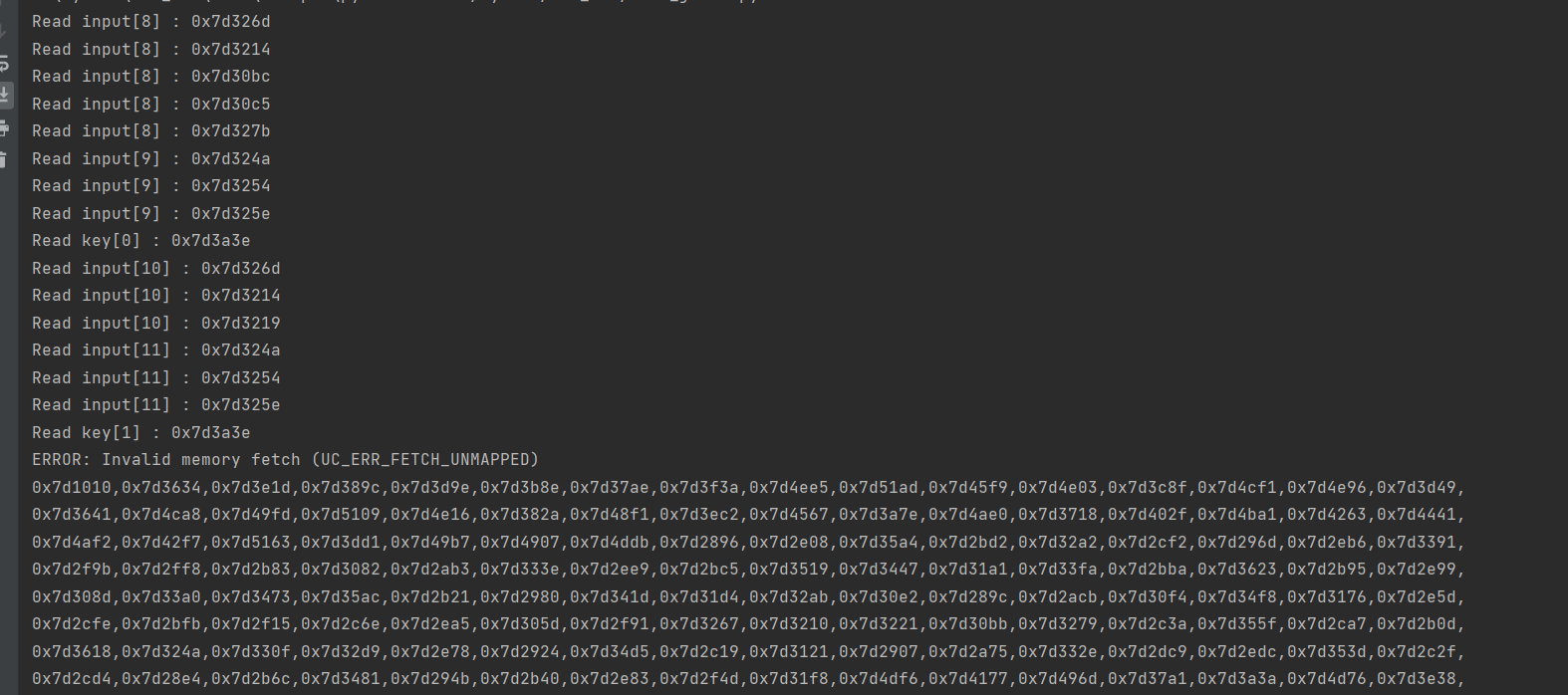
可以发现,读取input的次数变多了并且程序开始读取下两个字符,而且读取下两个字符的地址和第一次读取的地址一模一样,猜测程序是在循环读取并且两个字节两个字节的进行比较,只不过这个大循环被混淆了,那爆破思路就有了,只需要两个字符两个字符的爆破就行了
三、爆破脚本(前30个字符)
from unicorn import * from unicorn.x86_const import * from struct import * with open(r"./OddCode.exe",'rb') as fp: fp.seek(0x400) X64code = fp.read(0x5000) times = 0 class UniVm: index = [] def __init__(self,strr,bs): # 创建虚拟机 mu = Uc(UC_ARCH_X86, UC_MODE_64) # 分配内存 分配10 * 0x1000的大小 ADDRESS = 0x7d1000 # 初始地址 20mb mu.mem_map(ADDRESS, 20 * 0x100000) # 填充内存 mu.mem_write(ADDRESS, X64code) # 填充寄存器 注意入口点的选取和寄存器有关系 mu.reg_write(UC_X86_REG_RAX, 1) mu.reg_write(UC_X86_REG_RBX, 0xc8402d) mu.reg_write(UC_X86_REG_RCX, 0x9098de57) mu.reg_write(UC_X86_REG_RDX, 0x768c9cca) mu.reg_write(UC_X86_REG_RSI, 0x7d701d) mu.reg_write(UC_X86_REG_RDI, 0x7d705c) mu.reg_write(UC_X86_REG_RBP, 0xf5faf8) mu.reg_write(UC_X86_REG_RIP, 0x7d1010) mu.reg_write(UC_X86_REG_RSP, 0xf5fae0) # 填充input 和 key mu.mem_write(0x007d701D, strr) # mu.mem_write(0x007d705C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D') # 关键指令,通过Hook函数代码保存代码轨迹 mu.hook_add(UC_HOOK_CODE, self.hook_code, begin=ADDRESS, end=ADDRESS + len(X64code)) mu.hook_add(UC_HOOK_MEM_READ, self.hook_read_mem) ADDRESS = 0x7d1000 LocIns_Addr = 0 Pre_Ins_Size = 0 Nums = 0 Save_Rip = [] self.mu = mu self.LocIns_Addr = LocIns_Addr self.Nums = Nums self.Save_Rip = Save_Rip self.ADDRESS = ADDRESS self.Pre_Ins_Size = Pre_Ins_Size self.strrr = strr self.bns = bs # Hook指令 def hook_code(self, mu, address, size, data): if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size: self.Save_Rip.append(address) self.Nums += 1 self.LocIns_Addr = address self.Pre_Ins_Size = size #Hook读地址 def hook_read_mem(self,uc, access, address, size, value, data): if address >= 0x007d701D and address <= 0x007d701D + 41: self.index.append(address - 0x007d701D) def start(self): global times try: self.mu.emu_start(self.ADDRESS + 0x10, self.ADDRESS + len(X64code) - 0x10) except UcError as e: self.mu.emu_stop() num = len(list(set(self.index))) // 2 #print(num,self.bns) if num == self.bns: print(self.strrr) return 1 else: return 0 from alive_progress import alive_bar map = b"0123456789ABCDEFabcdef" #爆破的时候发现,输入中存在小写字符 fflag = b"SangFor{" bns = 2 with alive_bar(16*len(map)*len(map)) as bar: for z in range(8,40,2): print(f"{z},{z+1}:") for i in map: ans = 0 for j in map: strr = (fflag[:z] + pack("B",i)+ pack("B",j)).ljust(40,b"0") + b"}" if UniVm(strr,bns).start() == 1: ans = 1 bns += 1 fflag += pack("B",i) + pack("B",j) break bar() if ans == 1: break
爆破结果如下:
不知道为什么,程序在windows下跑不了,但在linux上可以跑
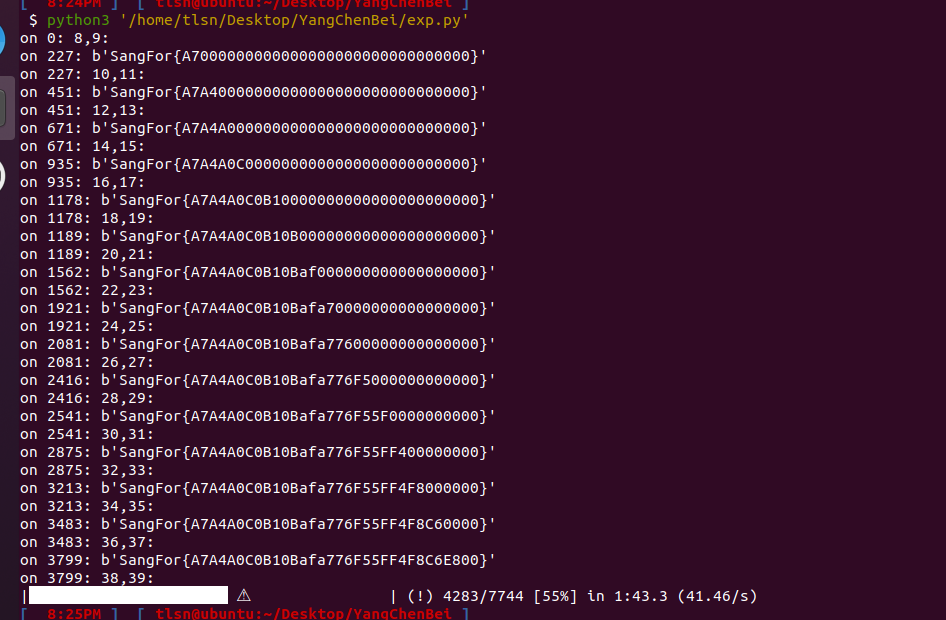
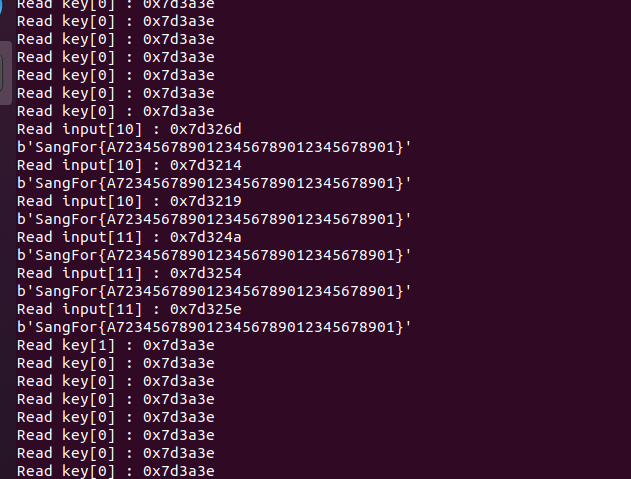
这个脚本只能爆破得到前30个字符,猜测最后两个字符的校验不在循环之内,那我们只好再另写脚本爆破最后两个字符了
四、爆破最后两个字符
#下面代码在windows下运行 import os map = "0123456789ABCDEFabcdef" flag = "SangFor{A7A4A0C0B10Bafa776F55FF4F8C6E8" for i in map: for j in map: strr = flag + str(i) + str(j) + "}" tmp = os.popen(fr'echo {strr} | C:\Users\TLSN\Desktop\各种ctf题目\RE刷\混淆\OddCode.exe').readlines()[2:3] # print(tmp)#出错原因,一开始用bytes进行爆破,发现echo的时候多出了 b'' 等多余字符 if "Success." in tmp: print(strr) exit(0)
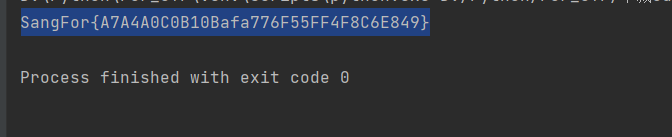
五、总脚本和flag
最后的总脚本如下
from unicorn import * from unicorn.x86_const import * from struct import * with open(r"./OddCode.exe",'rb') as fp: fp.seek(0x400) X64code = fp.read(0x5000) times = 0 class UniVm: index = [] def __init__(self,strr,bs): # 创建虚拟机 mu = Uc(UC_ARCH_X86, UC_MODE_64) # 分配内存 分配10 * 0x1000的大小 ADDRESS = 0x7d1000 # 初始地址 20mb mu.mem_map(ADDRESS, 20 * 0x100000) # 填充内存 mu.mem_write(ADDRESS, X64code) # 填充寄存器 注意入口点的选取和寄存器有关系 mu.reg_write(UC_X86_REG_RAX, 1) mu.reg_write(UC_X86_REG_RBX, 0xc8402d) mu.reg_write(UC_X86_REG_RCX, 0x9098de57) mu.reg_write(UC_X86_REG_RDX, 0x768c9cca) mu.reg_write(UC_X86_REG_RSI, 0x7d701d) mu.reg_write(UC_X86_REG_RDI, 0x7d705c) mu.reg_write(UC_X86_REG_RBP, 0xf5faf8) mu.reg_write(UC_X86_REG_RIP, 0x7d1010) mu.reg_write(UC_X86_REG_RSP, 0xf5fae0) # 填充input 和 key mu.mem_write(0x007d701D, strr) # mu.mem_write(0x007d705C, b'\x90\xF0\x70\x7C\x52\x05\x91\x90\xAA\xDA\x8F\xFA\x7B\xBC\x79\x4D') # 关键指令,通过Hook函数代码保存代码轨迹 mu.hook_add(UC_HOOK_CODE, self.hook_code, begin=ADDRESS, end=ADDRESS + len(X64code)) mu.hook_add(UC_HOOK_MEM_READ, self.hook_read_mem) ADDRESS = 0x7d1000 LocIns_Addr = 0 Pre_Ins_Size = 0 Nums = 0 Save_Rip = [] self.mu = mu self.LocIns_Addr = LocIns_Addr self.Nums = Nums self.Save_Rip = Save_Rip self.ADDRESS = ADDRESS self.Pre_Ins_Size = Pre_Ins_Size self.strrr = strr self.bns = bs # Hook指令 def hook_code(self, mu, address, size, data): if abs(address - self.LocIns_Addr) > self.Pre_Ins_Size: self.Save_Rip.append(address) self.Nums += 1 self.LocIns_Addr = address self.Pre_Ins_Size = size #Hook读地址 def hook_read_mem(self,uc, access, address, size, value, data): if address >= 0x007d701D and address <= 0x007d701D + 41: self.index.append(address - 0x007d701D) def start(self): global times try: self.mu.emu_start(self.ADDRESS + 0x10, self.ADDRESS + len(X64code) - 0x10) except UcError as e: self.mu.emu_stop() num = len(list(set(self.index))) // 2 #print(num,self.bns) if num == self.bns: print(self.strrr) return 1 else: return 0 from alive_progress import alive_bar map = b"0123456789ABCDEFabcdef" fflag = b"SangFor{" bns = 2 with alive_bar(16*len(map)*len(map)) as bar: for z in range(8,40,2): print(f"{z},{z+1}:") for i in map: ans = 0 for j in map: strr = (fflag[:z] + pack("B",i)+ pack("B",j)).ljust(40,b"0") + b"}" if UniVm(strr,bns).start() == 1: ans = 1 bns += 1 fflag += pack("B",i) + pack("B",j) break bar() if ans == 1: break # #下面代码在windows下运行 # import os # map = "0123456789ABCDEFabcdef" # flag = "SangFor{A7A4A0C0B10Bafa776F55FF4F8C6E8" # for i in map: # for j in map: # strr = flag + str(i) + str(j) + "}" # tmp = os.popen(fr'echo {strr} | C:\Users\TLSN\Desktop\各种ctf题目\RE刷\混淆\OddCode.exe').readlines()[2:3] # # print(tmp)#出错原因,一开始用bytes进行爆破,发现echo的时候多出了 b'' 等多余字符 # if "Success." in tmp: # print(strr) # exit(0)
flag即为
SangFor{A7A4A0C0B10Bafa776F55FF4F8C6E849}
第一次接触unicorn ,感觉是真滴好用,尤其是Hook函数...
这道题也是参考无名侠和地球人大佬的博客才做了出来,也是有很大收获
