06-数据加载
写在前面的话:
该系列博文是我学习《 Hive源码解析与开发实战》视频课程的一个笔记,或者说总结,暂时没有对视频中的操作去做验证,只是纯粹的学习记录。
有兴趣看该视频的博友可以留言,我会共享出来,相互交流学习 ^.^。
*********************************************************************************************************
本文目录:
一、内表数据加载:
1.1、创建表时查询插入加载:
1.2、创建表时指定数据位置:
1.3、本地数据加载:
1.4、加载hdfs数据:
1.5、使用hadoop命令拷贝数据到指定位置:
1.6、由查询语句加载数据:
二、外表的数据加载:
2.1、创建表时指定数据位置:
2.2、创建表后查询插入:
2.3、使用hadoop命令拷贝数据到指定位置:
三、分区表数据加载:
内部分区表加载;外部分区表加载。
四、数据加载要注意的问题:
4.1、分割符的问题:
4.2、数据类型对应问题:
4.3、Hive分区表需要添加分区才能看到数据:
分别就内表、外表、分区表进行讲解数据加载。
一、内表数据加载:
下面加载数据的方式可以分为两类:①创建表时进行加载(有两种方式,前面两种);②创建表后,进行加载(有三种方式,后面三种);
1.1、创建表时查询插入加载:
命令:

演示:

然后在hive中查询该表的数据,这样该表中就有数据了:

1.2、创建表时指定数据位置:
命令:

这种方式和外表location指定数据位置的方式的区别在于:
内表对该数据目录有拥有权,当该表删除后,该目录也会删除,也就是表和数据是绑定在一块的。
演示:
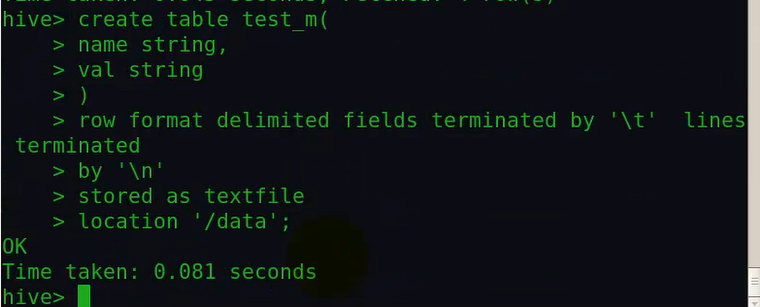
这里的/data是指hdfs上的路径根下的data目录,我们可以看下该目录的文件结构:
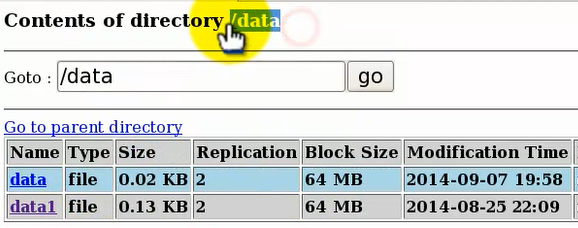
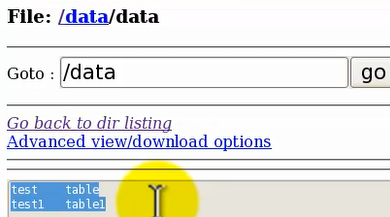
/data目录下有两个文件data和data1,我们看下这两个文件的内容:

然后我们看下加载该数据后的表里面的数据:
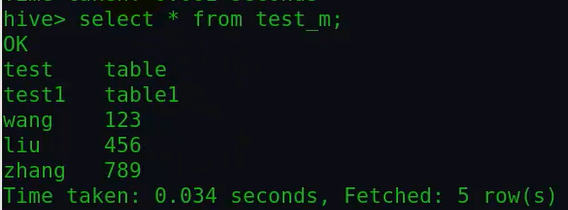
对比发现,由于这个表只有两个字段,因此表里面的数据只取文件中的前两个字段,虽然data1文件每一行有超过两个字段,但只取前面两个字段。
也就是说,如果创建表的字段个数小于了文件中每一行对应的字段个数的话,那么只会取前面那几个字段;如果表的字段个数大于文件每一行字段个数的话,
那么多余的字段值会为NULL;
另外,注意和后面从hdfs加载数据区别开来,虽然这里的location指定的就是hdfs路径,但加载数据的过程,只是从hdfs上的该路径下拷贝文件内容到表中,
而不像通过load从hdfs中加载数据那样,是移动文件到该表目录下。
1.3、本地数据加载:
命令:
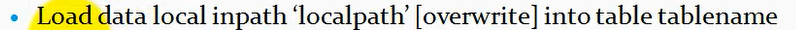
在hive对话框中使用这条命令,这里如果有overwrite,那么就是直接覆盖表的内容,否则就是追加到表数据中。
演示:

再查下该表的内容,由于省略了overwrite,因此是追加到表末尾:
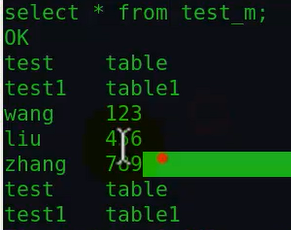
如果加overwrite就是覆盖了。
1.4、加载hdfs数据:
命令:
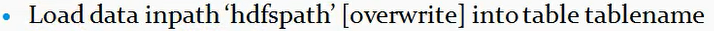
注意这个操作是移动数据,也就是在加载hdfs上的数据的时候,是把hdfs上的该数据文件移动到表目录下去。
相对于上一个从本地加载数据的命令,少了local。
演示:

在这里产生了一个问题:在创建表时通过location指定数据位置的时候,会在hdfs上创建表目录吗?表目录不是用来存储数据的吗?为什么location指定目录为data后,
通过load加载hdfs上的文件也会移动到该data目录下?为什么不是移动到表目录下?表目录和location指定的数据位置目录有什么区别?
产生这个疑问 在视频的11:00。
参考博文可以得到解答:http://www.cnblogs.com/qiaoyihang/p/6225151.html
根据上面博文:如果创建的时候指定了location数据位置,那么不会创建表目录,如果没有指定才会创建表目录。
1.5、使用hadoop命令拷贝数据到指定位置:
在hive的shell中执行或者在linux的shell中执行hadoop的命令。
演示:
1> 在linux 的shell终端中执行hadoop命令的 方式加载数据:
通过hadoop命令拷贝本地文件到创建该表时locaion指定的数据位置目录data下:

此时查询表,可以看到增加的数据:
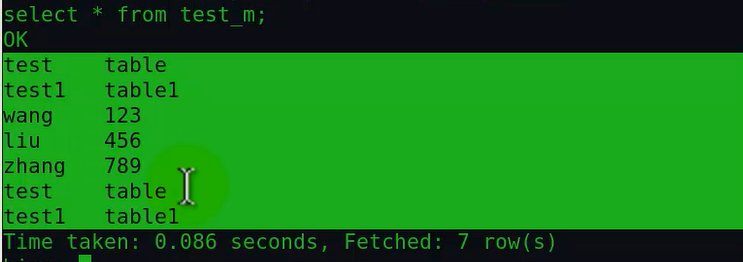
如果才执行该命令,发现拷贝失败,因为hadoop的hdfs上面不允许重名:

这个时候可以用hive的load命令,将本地的该文件load到表中去,然后会在该表的数据目录位置出现一个以copy结尾的文件副本,因为原来已经有了该文件,
比如:

2> 在hive客户端直接执行hadoop命令的方式加载数据:

然后在hdfs对应的数据目录中就多了一个data2文件:
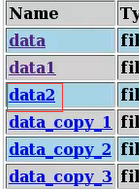
由此看出,hadoop的命令是可以直接在hive终端运行的,比如:

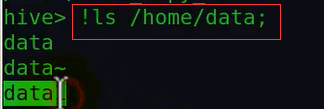
另外,在hive终端也可以执行linux的shell命令,主要就是在shell前面加个感叹号:
1.6、由查询语句加载数据:
方法1:
方法2:

方法3:
就是把整个select语句放在insert的前面,最后执行insert。
select col1,col2
from table1
where ...
insert [overwrite|into] tablename;
注意:上面这三种写法,overwrite和into不能同时存在,只能出现一个。
演示:
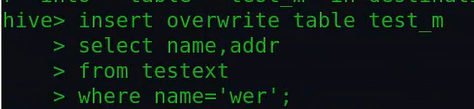
查询结果:
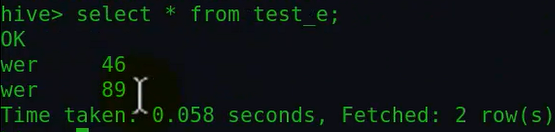
注意:如果我从table1表中查询两个字段的数据到table2中,不需要这四个字段两两名字对应相同,只是按照查询表的字段顺序将查出来的数据一次放到要插入的表中。
二、外表的数据加载:
加载的方法和上面内表加载数据有些类似。
相对于内表,下面介绍的方法中少了三个加载数据方法:创建表是通过查询加载、load本地数据文件、load加载hdfs上的文件数据。为什么呢?
首先,对于外表来说,由于它的作用就是用来指定现成的数据位置,然后去使用,所以不需要去加载数据,也就不需要load的那两种方法;而对于创建表时通过查询的方式来加载的方式,对于外表来说,在开始创建的时候,没有存储数据的目录,所以这种方式不行。
2.1、创建表时指定数据位置:
命令:
create extenal table tablename() location ''
外表没有数据的所有权,在删除表的时候只能删除元数据信息,不能删除数据目录。
演示:

2.2、创建表后查询插入:
和内表一样。
2.3、使用hadoop命令拷贝数据到指定位置:
可以在linux的shell终端也可以在hive终端执行hadoop命令。
三、分区表数据加载:
分区表加载数据可以分为两种:①内部分区表加载;②外部分区表加载。
内部分区表数据加载方式和内部表是类似的;外部分区表加载数据方式和外表类似,但是要注意的是,外部分区表指定的数据位置目录结构需要和分区表的表级结构对应,否则会查询不到数据。
分区表和内部表、外部表加载数据唯一不同的地方是:加载数据指定目标表的同时,需要指定分区,也就是指定数据到那个分区,如果不指定分区会报错误的。

内部分区表和外部分区表加载数据的区别和内部表与外部表加载数据区别类似。
①本地数据加载方式:
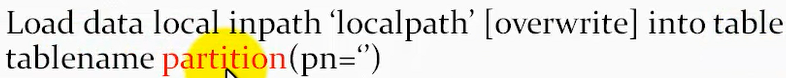
②加载hdfs数据:
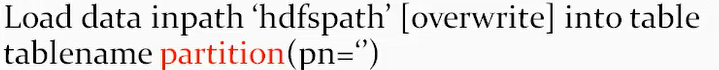
③由查询语句加载数据:

上面这几种加载方式都是在原来的基础上,多了个partition, 然后小括号里是 字段名字等于某个分区的值;
内部分区表演示:
①首先创建一个又分区的内表:

注意这里表其实定义了三个字段,其中dt也是一个字段,只不过写在了指定分区那里,就不用在定义在表中了。
②然后加载数据:
使用load本地数据,这个和load加载hdfs上的数据区别之处在于load本地不移动数据而是复制,但加载hdfs上是移动数据。
如果加载数据时不指定分区,那么会报错,因为该表在创建的时候是有分区的:

在这个时候加载数据之前,创建分区表之后,表目录下是空的,还没有分区表目录。然后我们再来重新加载数据,指定一个partition:

然后查询下,发现已经有结果了:
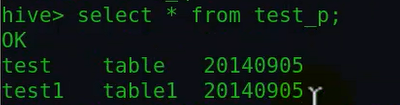
注意这里原来data文件里面只有两个字段,后面第三个字段是自动添加的分区名;
然后看下hdfs目录结构:

这里我发现,如果创建一个分区表后,分区表的表目录名字是以"分区名=字段值"的格式来进行命名的,那么如果是对于外部分区表来说,如果指定的数据位置原理就有数据,那么数据文件夹目录名字需要匹配这样一个格式。

最后我们查看下该表所拥有的分区,通过show partitions tablename命令:

外部分区表演示:
①同样的首先创建外部分区表:

然后查询下该表数据,发现该表没有数据:
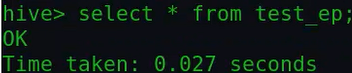
但其实在data数据目录下面是有一部分数据的,那为什么查询该表不能查询出数据呢?该表是分了区的,而data下的文件不和分区进行匹配,所以查不到。
于是我们通过hadoop命令在该数据目录下创建一个名字格式匹配分区的目录:

注意这里的分区表目录文件夹的名字格式。
然后我们拷贝一些数据到该分区中去:

hdfs上对应该分区表目录下就会多一个data文件:
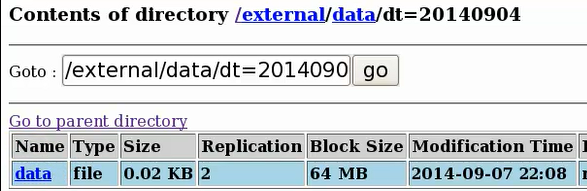
这个时候我再查下该表是否有数据:

结果还是没有数据,那为什么呢?按理说现在的目录结构已经满足分区表的目录需求,那为什么表中还是没有插入数据呢?原因在于我们是直接在表目录下面创建的
文件夹,虽然名字格式满足要求,但表的元数据里并没有记录该创建的目录文件夹是分区,因此我们应该通过alter table tablename add partition(partitionname='')的方式来
指明创建的该目录是分区,这样才查询的时候才可以查到数据:

然后在查询该表就有数据了:

其实这里我们采用的是特别的创建分区并且加载数据的方法:是通过hadoop命令手动的创建分区目录结构,然后手动的拷贝数据到该目录中,这种由于不是通过hive命令的方式,所以hive没有对应的元数据信息记录,因此才查不到数据。正规的做法是:创建分区表后=》通过hive的alter table tablename add partition(partitionname='')命令来添加分区=》通过hive分区表加载数据的三种方式加载数据到相应分区;这样既可以查询到数据了。
四、数据加载要注意的问题:
4.1、分割符的问题:
原始数据的分隔符是#,那么在定义分隔符的时候就要定义为#。另外分隔符默认只有单个字符,比如:如果你定义了两个字符来分割,那么hive只取第一个字符作为分隔符。
4.2、数据类型对应问题:

对于load数据的时候,如果字段类型不匹配,那么查询的时候得不到正确结果,但数据是存在在hdfs相应目录下的;但select查询插入,如果不匹配,那么是没有相应数据的。
4.3、Hive分区表需要添加分区才能看到数据:
这个问题参考上面。
最后注意:Hive在加载数据的时候不做类型检查,只有在查询的时候才检查。因为外部表,它是指定数据位置,它不可能知道什么时候加了数据。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号