B+树和B树的区别
1.B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
如下所示B-树/B+树查询节点 key 为 50 的 data。
B-树:
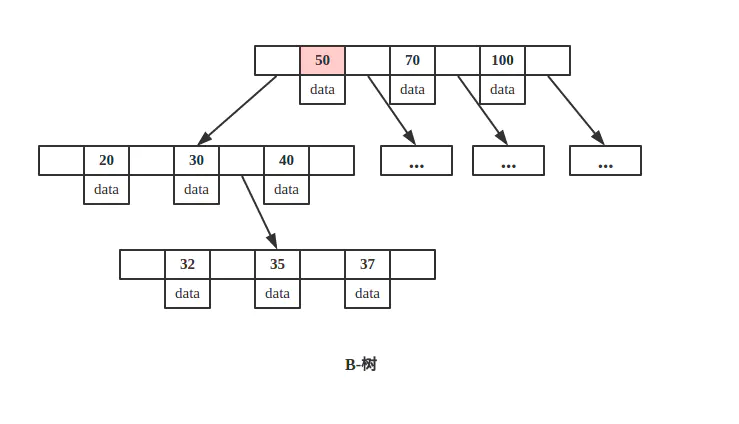
从上图可以看出,key 为 50 的节点就在第一层,B-树只需要一次磁盘 IO 即可完成查找。所以说B-树的查询最好时间复杂度是 O(1)。

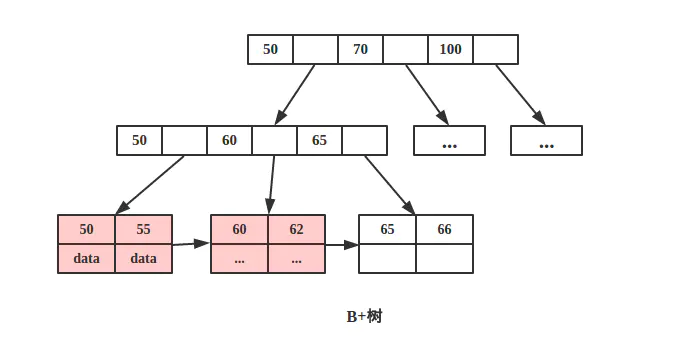
由于B+树所有的 data 域都在根节点,所以查询 key 为 50的节点必须从根节点索引到叶节点,时间复杂度固定为 O(log n)。
点评:B树的由于每个节点都有key和data,所以查询的时候可能不需要O(logn)的复杂度,甚至最好的情况是O(1)就可以找到数据,而B+树由于只有叶子节点保存了data,所以必须经历O(logn)复杂度才能找到数据
2. B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
根据空间局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问。
B+树可以很好的利用局部性原理,若我们访问节点 key为 50,则 key 为 55、60、62 的节点将来也可能被访问,我们可以利用磁盘预读原理提前将这些数据读入内存,减少了磁盘 IO 的次数。
当然B+树也能够很好的完成范围查询。比如查询 key 值在 50-70 之间的节点。
点评:由于B+树的叶子节点的数据都是使用链表连接起来的,而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快
3.B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
这个很好理解,由于B-树节点内部每个 key 都带着 data 域,而B+树节点只存储 key 的副本,真实的 key 和 data 域都在叶子节点存储。前面说过磁盘是分 block 的,一次磁盘 IO 会读取若干个 block,具体和操作系统有关,那么由于磁盘 IO 数据大小是固定的,在一次 IO 中,单个元素越小,量就越大。这就意味着B+树单次磁盘 IO 的信息量大于B-树,从这点来看B+树相对B-树磁盘 IO 次数少。
点评:由于B树的节点都存了key和data,而B+树只有叶子节点存data,非叶子节点都只是索引值,没有实际的数据,这就时B+树在一次IO里面,能读出的索引值更多。从而减少查询时候需要的IO次数!
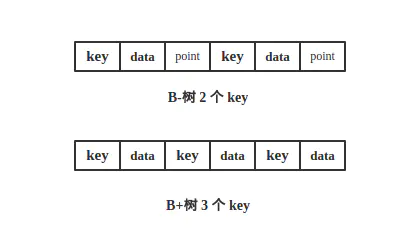
从上图可以看出相同大小的区域,B-树仅有 2 个 key,而B+树有 3 个 key。
拓展:MySQL为什么使用B-Tree(B+Tree)&& 存储知识
上文说过,红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构,这一节将结合计算机组成原理相关知识讨论B-/+Tree作为索引的理论基础。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
存储数据最小单元
我们都知道计算机在存储数据的时候,有最小存储单元,这就好比我们今天进行现金的流通最小单位是一毛。
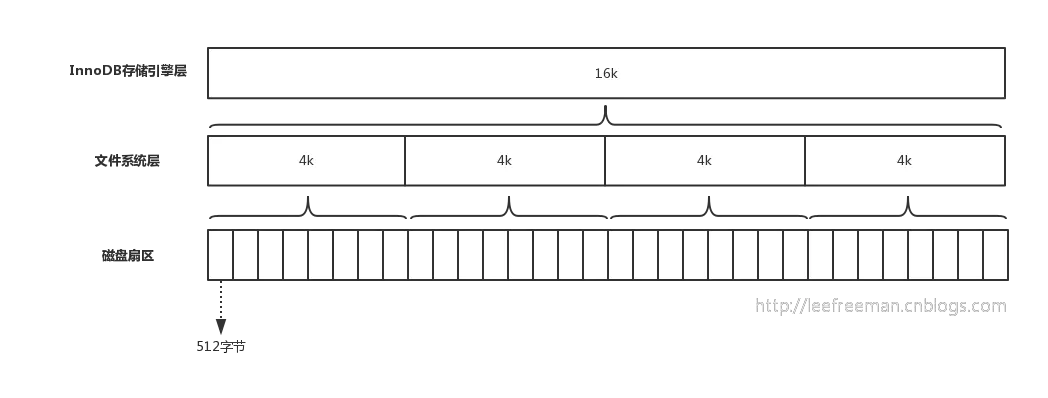
在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)他的最小单元是块,一个块的大小是4k
而对于我们的InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是16K。
下面几张图可以帮你理解最小存储单元:
文件系统中一个文件大小只有1个字节,但不得不占磁盘上4KB的空间。
磁盘扇区、文件系统、InnoDB存储引擎都有各自的最小存储单元。
在MySQL中我们的InnoDB页的大小默认是16k,当然也可以通过参数设置:

数据表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
主存存取原理
目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,这里本文抛却具体差别,抽象出一个十分简单的存取模型来说明RAM的工作原理。

从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。图5展示了一个4 x 4的主存模型。
主存的存取过程如下:
当系统需要读取主存时,则将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取。
写主存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
磁盘存取原理
上文说过,索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
图6是磁盘的整体结构示意图。
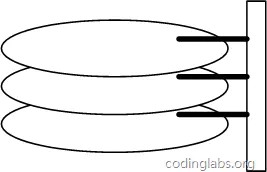
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不能转动,但是可以沿磁盘半径方向运动(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。
图7是磁盘结构的示意图。
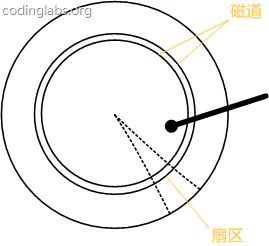
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。为了简单起见,我们下面假设磁盘只有一个盘片和一个磁头。
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
所以IO一次就是读一页的大小
本文转载自:https://www.jianshu.com/p/ace3cd6526c4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号