Linux生产故障排查
一、生产环境服务器变慢,诊断思路和性能评估
从这几个方面思考:cpu、内存、硬盘(磁盘)、磁盘io、网络io。
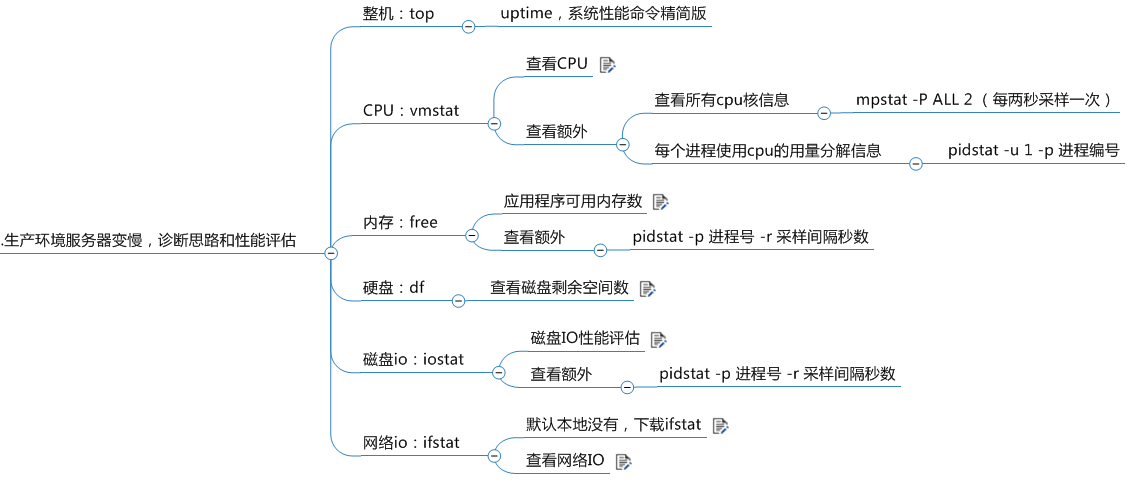
1. CPU
1.1. 整机查看
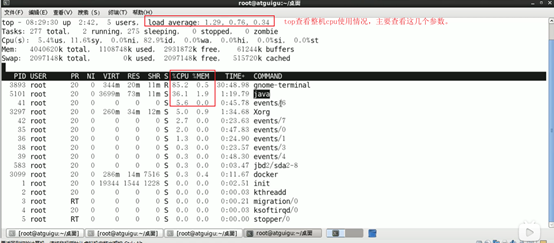
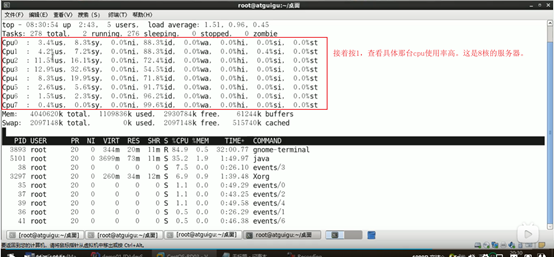
top
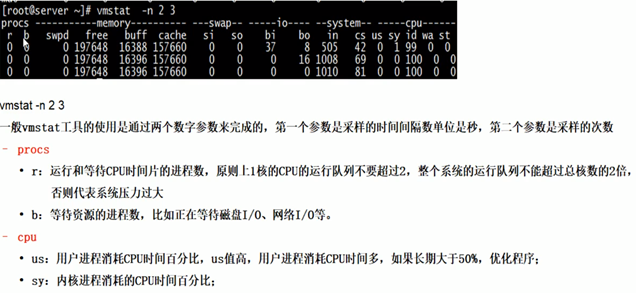
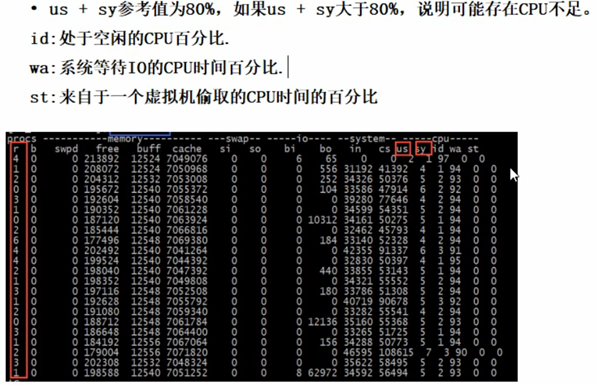
主要看两点,一时cup和内存,而是看load average(一分钟,5分钟,10分钟的平均值,需要三个数相加求平均值,如果大于60%就是负责过大)
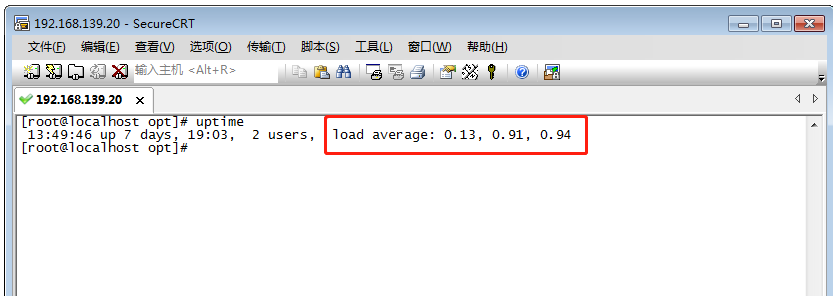
uptime
系统性能命令的精简版,即top命令的精简版。
1.2. 具体查看

1.2.1.查看cpu(包含不限于)
vmstat -n 2 3
1.2.2.查看额外
查看所有cpu信息
mpstat -P All 2
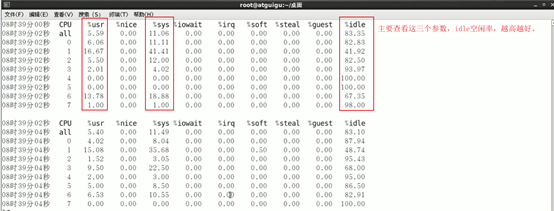
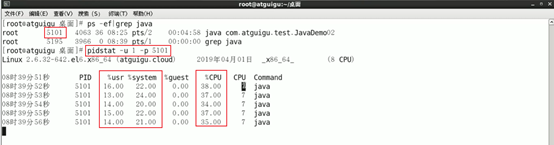
每个进程使用cpu的用量分解信息
pidstat -u 1 -p
2. 内存
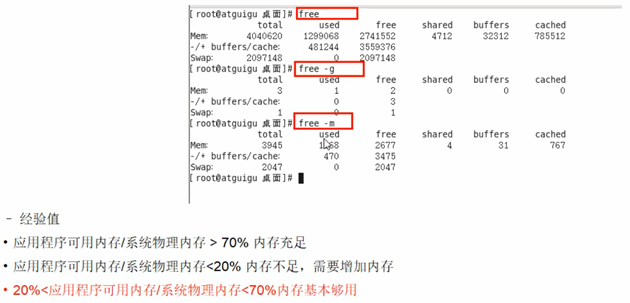
2.1. 整机查看:free查看整机内存使用情况。
常用free -m(-m以mb为单位显示)
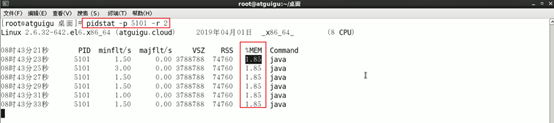
2.2. 具体查看:pidstat -p pid -r 2
查看具体进程(比如进程id为5101)内存使用情况
代码demo是死循环,会占用内存,不会占用io。
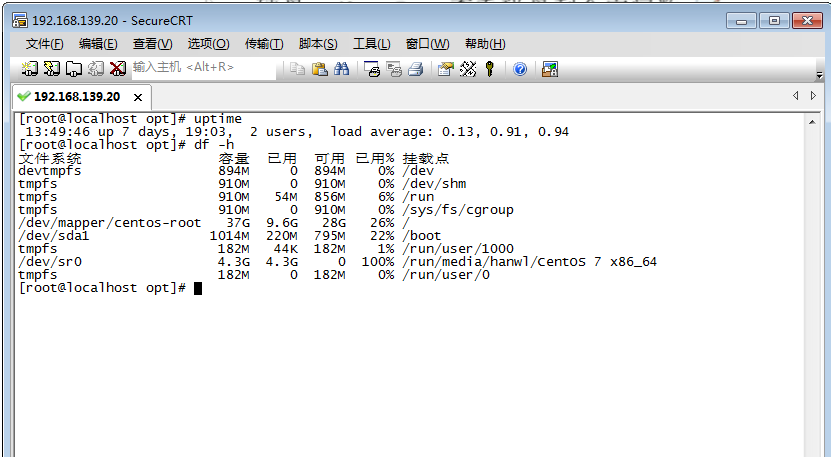
3. 硬盘
df -h (h是以人类看得懂的方式打印出来,既以G为单位)
4. 磁盘IO
4.1 整机查看:磁盘I/O性能评估
iostat -xdk 2 3 (每隔2秒采集一次,一共采集3次)
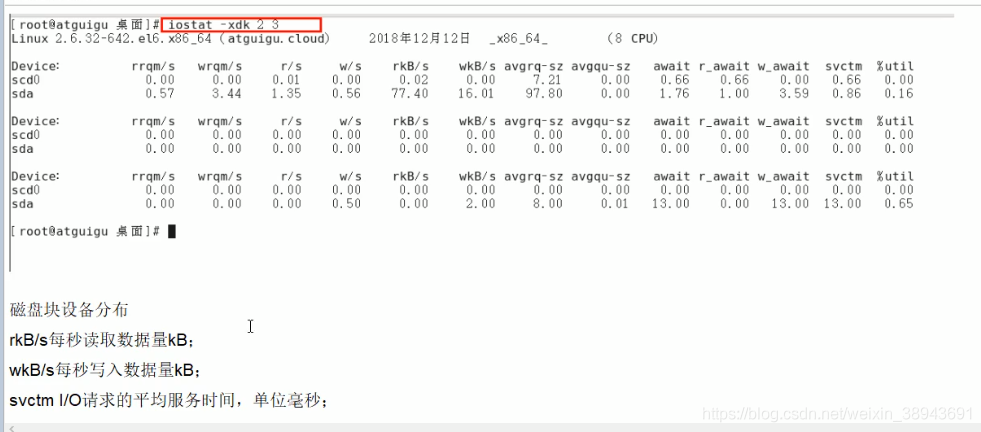
主要查看最后一个参数util即可。

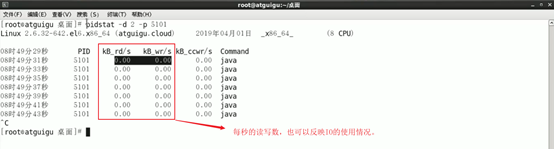
4.2. 具体查看:pidstat -d 2 -p 5101
查看具体进程(比如进程id为5101)磁盘io情况,
每秒读写都是0,说明5101进程没有占用磁盘io资源。(代码demo是死循环,会占用内存,没有读写操作,不会占用磁盘io),对比2.2中查看内存
5. 网络IO
5.1.本地没有ifstat命令,可以下载
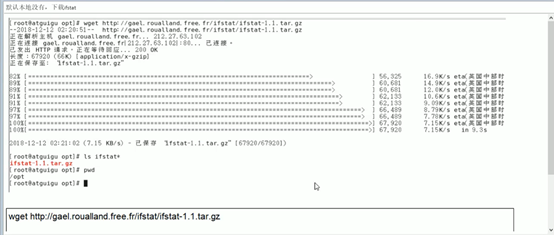
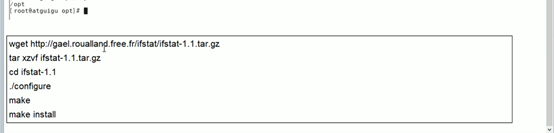
5.2.查看整机网络io情况
in/out都是0,说明没有占用资源,不是导致程序变慢的原因。
(代码demo是死循环,会占用内存,没有下载/上传或者远程接口交互操作,不会占用网络io)

ip addr 就可以发现,eth1是我们的网卡信息。
二、假如生产环境出现CPU过高,请谈谈你的分析思路和定位
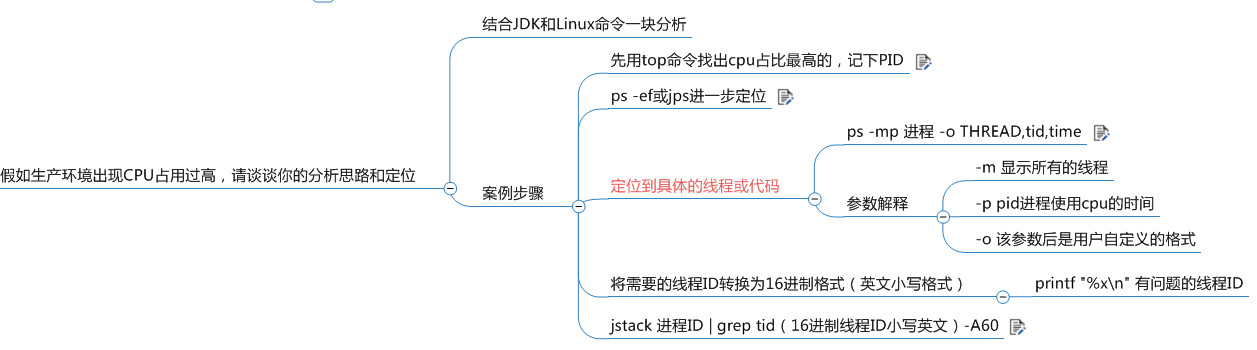
分如下五个步骤
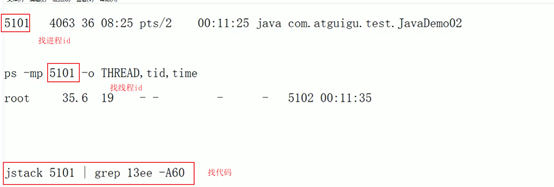
1. 查看所有进程
先用top命令找出cpu占用比最高的
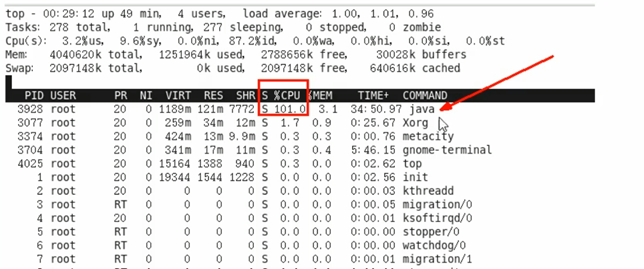
2. 查看具体进程
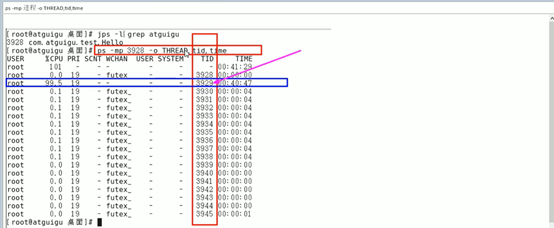
ps -ef或者jps进一步定位,得知是一个怎么样的一个后台程序给我们惹事

已近定位到我们java进程的具体类了

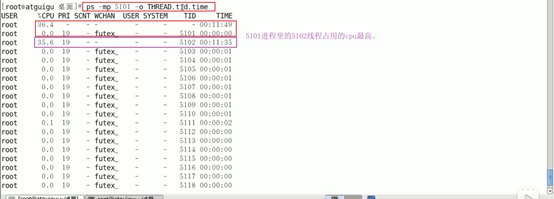
3. 定位到具体线程或者代码
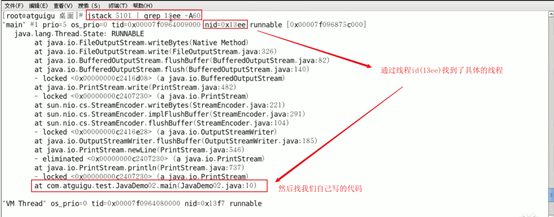
ps -mp pid -o HTREAD,tid,time
通过进程id,已经定位到了具体的线程id。
4. 线程id转换
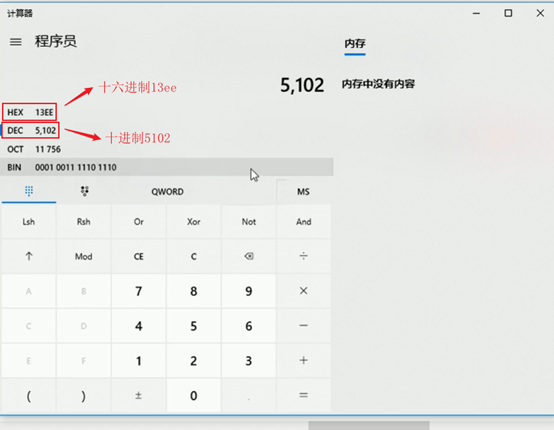
将需要的线程id转换为16进制格式(英文小写格式)
命令查到的线程id为可读性较高的十进制,而快照文件中是十六进制,所以需要转换一下。
a.使用命令转换:printf "%x\n" n代表有问题的线程id
b.使用科学计算器转换:
5. 定位到具体代码并查看
jstack进程id|grep tid(16进制线程id小写英文)-A60
总结:
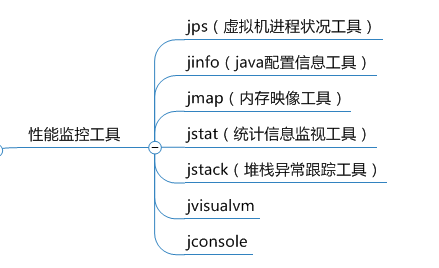
jdk自带的jvm监控和性能分析工具,大多数都在jdk的bin目录下: Java\jdk1.8.0_202\bin
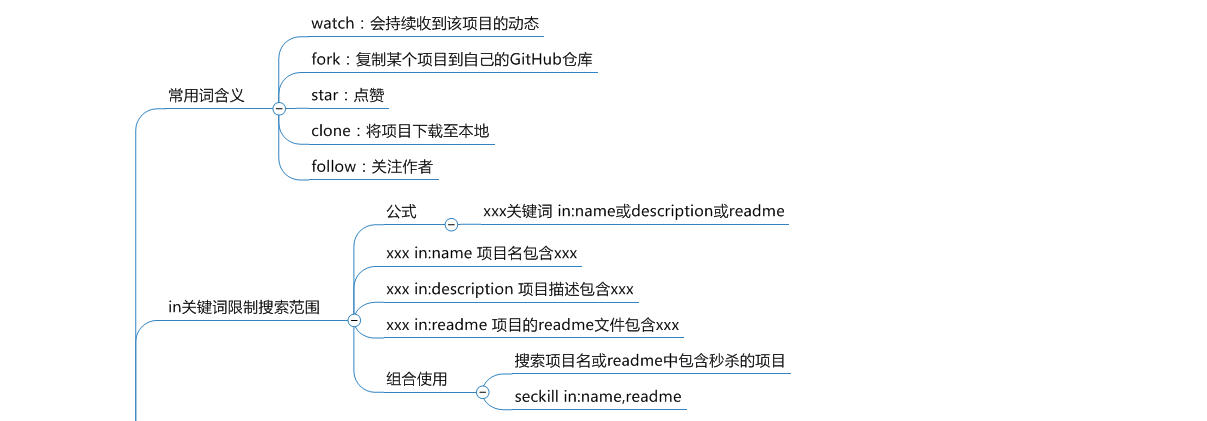
二、GitHub的一些骚操作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号