

排序算法之快速排序
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,常常出现快速排序的身影。总的说来,要直接默写出快速排序还是有一定难度的,自己总结整理一下,希望对大家理解有帮助。
原理
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。说白了就是给基准数据找其正确索引位置的过程。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
- 1.先从数列中取出一个数作为基准数。
- 2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 3.再对左右区间重复第二步,直到各区间只有一个数。
快速排序使用分治法来把一个数列分为两个子数列。具体算法描述如下:
1)从数列中挑出一个元素,称为 “基准”(pivot);
2)重新排序数列,所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),该基准就处于数列的中间位置。这称为分区(partition)操作;
3)递归地(recursive)对小于基准值元素的子数列和大于基准值元素的子数列进行快速排序。

2 首先从后半部分开始,如果扫描到的值大于基准数据就让high减1,如果发现有元素比该基准数据的值小(如上图中18<=tmp),就将high位置的值赋值给low位置 ,结果如下:
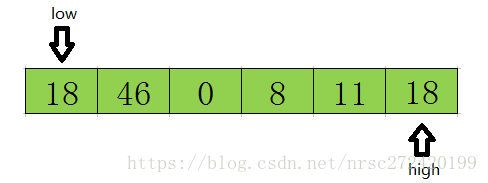
3 然后开始从前往后扫描,如果扫描到的值小于基准数据就让low加1,如果发现有元素大于基准数据的值(如上图46=>tmp),就再将low位置的值赋值给high位置的值,指针移动并且数据交换后的结果如下:
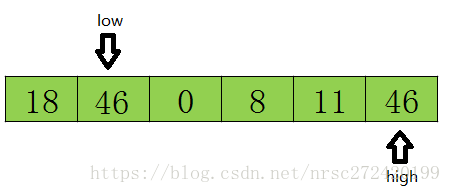
4 然后再开始从后向前扫描,原理同上,发现上图11<=tmp,则将high位置的值赋值给low位置的值,结果如下:
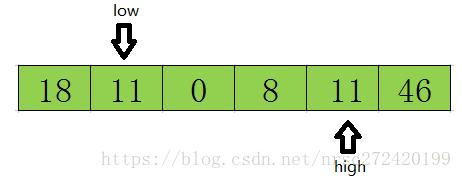
5 然后再开始从前往后遍历,直到low=high结束循环,此时low或high的下标就是基准数据23在该数组中的正确索引位置.如下图所示.

6 这样一遍走下来,可以很清楚的知道,其实快速排序的本质就是把基准数大的都放在基准数的右边,把比基准数小的放在基准数的左边,这样就找到了该数据在数组中的正确位置.
以后采用递归的方式分别对前半部分和后半部分排序,当前半部分和后半部分均有序时该数组就自然有序了。
从上面的过程中可以看到:
①先从队尾开始向前扫描且当low < high时,如果a[high] > tmp,则high–,但如果a[high] < tmp,则将high的值赋值给low,即arr[low] = a[high],同时要转换数组扫描的方式,即需要从队首开始向队尾进行扫描了
②同理,当从队首开始向队尾进行扫描时,如果a[low] < tmp,则low++,但如果a[low] > tmp了,则就需要将low位置的值赋值给high位置,即arr[low] = arr[high],同时将数组扫描方式换为由队尾向队首进行扫描.
③不断重复①和②,知道low>=high时(其实是low=high),low或high的位置就是该基准数据在数组中的正确索引位置.
按照上诉理论代码如下:
public class QuickSort { public static void main(String[] args) { int[] arr = { 49, 38, 65, 97, 23, 22, 76, 1, 5, 8, 2, 0, -1, 22 }; quickSort(arr, 0, arr.length - 1); System.out.println("排序后:"); for (int i : arr) { System.out.println(i); } } private static void quickSort(int[] arr, int low, int high) { if (low < high) { // 找寻基准数据的正确索引 int index = getIndex(arr, low, high); // 进行迭代对index之前和之后的数组进行相同的操作使整个数组变成有序 quickSort(arr, low, index - 1); quickSort(arr, index + 1, high); } } private static int getIndex(int[] arr, int low, int high) { // 基准数据 int tmp = arr[low]; while (low < high) { // 当队尾的元素大于等于基准数据时,向前挪动high指针 while (low < high && arr[high] >= tmp) { high--; } // 如果队尾元素小于tmp了,需要将其赋值给low arr[low] = arr[high]; // 当队首元素小于等于tmp时,向前挪动low指针 while (low < high && arr[low] <= tmp) { low++; } // 当队首元素大于tmp时,需要将其赋值给high arr[high] = arr[low]; } // 跳出循环时low和high相等,此时的low或high就是tmp的正确索引位置 // 由原理部分可以很清楚的知道low位置的值并不是tmp,所以需要将tmp赋值给arr[low] arr[low] = tmp; return low; // 返回tmp的正确位置 } }
三、代码实现
快速排序最核心的步骤就是partition操作,即从待排序的数列中选出一个数作为基准,将所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),该基准就处于数列的中间位置。partition函数返回基准的位置,然后就可以对基准位置的左右子序列递归地进行同样的快排操作,从而使整个序列有序。
下面我们来介绍partition操作的两种实现方法:左右指针法 和 挖坑法。
方法一:左右指针法
基本思路:
1.将数组的最后一个数 right 作为基准数 key。
2.分区过程:从数组的首元素 begin 开始向后找比 key 大的数(begin 找大);end 开始向前找比 key 小的数(end 找小);找到后交换两者(swap),直到 begin >= end 终止遍历。最后将 begin(此时begin == end)和最后一个数交换( 这个时候 end 不是最后一个位置),即 key 作为中间数(左区间都是比key小的数,右区间都是比key大的数)
3.再对左右区间重复第二步,直到各区间只有一个数。

/** * partition操作 * @param array * @param left 数列左边界 * @param right 数列右边界 * @return */ public static int partition(int[] array,int left,int right) { int begin = left; int end = right; int key = right; while( begin < end ) { //begin找大 while(begin < end && array[begin] <= array[key]) begin++; //end找小 while(begin < end && array[end] >= array[key]) end--; swap(array,begin,end); } swap(array,begin,right); return begin; //返回基准位置 } /** * 交换数组内两个元素 * @param array * @param i * @param j */ public static void swap(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; }
方法二:挖坑法
基本思路:
1.定义两个指针 left 指向起始位置,right 指向最后一个元素的位置,然后指定一个基准 key(right),作为坑。
2.left 寻找比基准(key)大的数字,找到后将 left 的数据赋给 right,left 成为一个坑,然后 right 寻找比基数(key)小的数字,找到将 right 的数据赋给 left,right 成为一个新坑,循环这个过程,直到 begin 指针与 end指针相遇,然后将 key 填入那个坑(最终:key的左边都是比key小的数,key的右边都是比key大的数),然后进行递归操作。

/** * partition操作 * @param array * @param left 数列左边界 * @param right 数列右边界 * @return */ public static int partition(int[] array,int left,int right) { int key = array[right];//初始坑 while(left < right) { //left找大 while(left < right && array[left] <= key ) left++; array[right] = array[left];//赋值,然后left作为新坑 //right找小 while(left <right && array[right] >= key) right--; array[left] = array[right];//right作为新坑 } array[left] = key; /*将key赋值给left和right的相遇点, 保持key的左边都是比key小的数,key的右边都是比key大的数*/ return left;//最终返回基准 }
实现了partition操作,我们就可以递归地进行快速排序了
/** * 快速排序方法 * @param array * @param left 数列左边界 * @param right 数列右边界 * @return */ public static void Quicksort(int array[], int left, int right) { if(left < right){ int pos = partition(array, left, right); Quicksort(array, left, pos - 1); Quicksort(array, pos + 1, right); } }
四、代码优化
我们之前选择基准的策略都是固定基准,即固定地选择序列的右边界值作为基准,但如果在待排序列几乎有序的情况下,选择的固定基准将是序列的最大(小)值,快排的性能不好(因为每趟排序后,左右两个子序列规模相差悬殊,大的那部分最后时间复杂度很可能会达到O(n2))。
下面提供几种常用的快排优化:
优化一:随机基准
每次随机选取基准值,而不是固定选取左或右边界值。将随机选取的基准值和右边界值进行交换,然后就回到了之前的解法。
只需要在 partition 函数前增加如下操作即可:
int random = (int) (left + Math.random() * (right - left + 1)); //随机选择 left ~ right 之间的一个位置作为基准 swap(array, random, right); //把基准值交换到右边界
基本思想:
取第一个数,最后一个数,第(N/2)个数即中间数,三个数中数值中间的那个数作为基准值。
举个例子,对于int[] array = { 2,5,4,9,3,6,8,7,1,0},2、3、0分别是第一个数,第(N/2)个是数以及最后一个数,三个数中3最大,0最小,2在中间,所以取2为基准值。
实现getMid函数即可:
/** * 三数取中,返回array[left]、array[mid]、array[right]三者的中间者下标作为基准 * @param array * @param left * @param right * @return */ public static int getMid(int[] array,int left,int right) { int mid = left + ((right - left) >> 1); int a = array[left]; int b = array[mid]; int c = array[right]; if ((b <= a && a <= c) || (c <= a && a <= b)) { //a为中间值 return left; } if ((a <= b && b <= c) || (c <= b && b <= a)) { //b为中间值 return mid; } if ((a <= c && c <= b) || (b <= c && c <= a)) { //c为中间值 return right; } return left; }
在子序列比较小的时候,直接插入排序性能较好,因为对于有序的序列,插排可以达到O(n)的复杂度,如果序列比较小,使用插排效率要比快排高。
实现方式也很简单,快排是在子序列元素个数为 1 时才停止递归,我们可以设置一个阈值n,假设为5,则大于5个元素,子序列继续递归,否则选用插排。
此时QuickSort()函数如下:
public static void Quicksort(int array[], int left, int right) { if(right - left > 5){ int pos = partition(array, left, right); Quicksort(array, left, pos - 1); Quicksort(array, pos + 1, right); }else{ insertionSort(array); } }
这种优化非常实用。
实测发现当待排序列为 [100000,99999,99998,...,3,2,1] 时,不加插入优化的快排由于递归次数过多甚至抛出了 java.lang.StackOverflowError!

而加入了插入优化并选择阈值为 12500 时,排序用时如下:

实验发现阈值的选择也很关键,选择阈值为 5 ,排序用时如下:

优化四:三路划分
如果待排序列中重复元素过多,也会大大影响排序的性能,这是因为大量相同元素参与快排时,左右序列规模相差极大,快排将退化为冒泡排序,时间复杂度接近O(n2)。这时候,如果采用三路划分,则会很好的避免这个问题。
三路划分的思想是利用 partition 函数将待排序列划分为三部分:第一部分小于基准v,第二部分等于基准v,第三部分大于基准v。这样在递归排序区间的时候,我们就不必再对第二部分元素均相等的区间进行快排了,这在待排序列存在大量相同元素的情况下能大大提高快排效率。
来看下面的三路划分示意图:

说明:红色部分为小于基准v的序列,绿色部分为等于基准v的序列,白色部分由于还未被 cur 指针遍历到,属于大小未知的部分,蓝色部分为大于基准v的序列。
left 指针为整个待排区间的左边界,right 指针为整个待排区间的右边界。less 指针指向红色部分的最后一个数(即小于v的最右位置),more 指针指向蓝色部分的第一个数(即大于v的最左位置)。cur 指针指向白色部分(未知部分)的第一个数,即下一个要判断大小的位置。
算法思路:
1)由于最初红色和蓝色区域没有元素,初始化 less = left - 1,more = right + 1,cur = left。整个区间为未知部分(白色)。
2)如果当前 array[cur] < v,则 swap(array,++less,cur++),即把红色区域向右扩大一格(less指针后移),把 array[cur] 交换到该位置,cur 指针前移判断下一个数。
3)如果当前 array[cur] = v,则不必交换,直接 cur++
4)如果当前 array[cur] > v,则 swap(array,--more,cur),即把蓝色区域向左扩大一格(more指针前移),把 array[cur] 交换到该位置。特别注意!此时cur指针不能前移,这是因为交换到cur位置的元素来自未知区域,还需要进一步判断array[cur]。
利用三路划分,我们就可以递归地进行三路快排了!并且可以愉快地避开所有重复元素区间。
代码如下:
public static int[] partition(int[] array,int left,int right){ int v = array[right]; //选择右边界为基准 int less = left - 1; // < v 部分的最后一个数 int more = right + 1; // > v 部分的第一个数 int cur = left; while(cur < more){ if(array[cur] < v){ swap(array,++less,cur++); }else if(array[cur] > v){ swap(array,--more,cur); }else{ cur++; } } return new int[]{less + 1,more - 1}; //返回的是 = v 区域的左右下标 } public static void Quicksort(int array[], int left, int right) { if (left < right) { int[] p = partition(array,left,right); Quicksort(array,left,p[0] - 1); //避开重复元素区间 Quicksort(array,p[1] + 1,right); } }
三路划分可以解决经典的荷兰国旗问题,具体见 leetcode 75
解法如下:
class Solution { // 方法一:使用计数排序解决,但需要两趟扫描,不符合要求 /*public void sortColors(int[] nums) { int[] count = new int[3]; for(int i = 0; i < nums.length; i++) count[nums[i]]++; int k = 0; for(int i = 0; i < 3; i++){ for(int j = 0; j < count[i]; j++){ nums[k++] = i; } } }*/ // 方法二:使用快速排序的三路划分,时间复杂度为O(n),空间复杂度为O(1) public void sortColors(int[] nums) { int len = nums.length; if(len == 0) return; int less = -1; int more = len; int cur = 0; while(cur < more){ if(nums[cur] == 0){ swap(nums,++less,cur++); }else if(nums[cur] == 2){ swap(nums,--more,cur); }else{ cur++; } } } public static void swap(int[] array,int i,int j){ int temp = array[i]; array[i] = array[j]; array[j] = temp; } }
拓展:快速选择算法
快速选择算法用于求解 Kth Element 问题(无序数组第K大元素),使用快速排序的 partition() 进行实现。
快速排序的 partition() 方法会返回一个整数 j 使得 a[left..j-1] 小于等于 a[j],且 a[j+1..right] 大于等于 a[j]。
此时 a[j] 就是数组的第 j 小的元素,我们可以转换一下题意,第 k 大的元素就是第 nums.size() - k 小的元素。
找到 Kth Element 之后,再遍历一次数组,所有大于等于 Kth Element 的元素都是 TopK Elements。
时间复杂度 O(N),空间复杂度 O(1)。
还可以使用小根堆求解此问题,时间复杂度 O(NlogK),空间复杂度 O(K)。具体见:leetcode 215
解法如下:
class Solution { private int partition(vector<int>& array,int left,int right) { int key = array[right]; //初始坑 while(left < right) { //left找大 while(left < right && array[left] <= key ) left++; array[right] = array[left]; //赋值,然后left作为新坑 //right找小 while(left <right && array[right] >= key) right--; array[left] = array[right]; //right作为新坑 } array[left] = key; /*将key赋值给left和right的相遇点, 保持key的左边都是比key小的数,key的右边都是比key大的数*/ return left;//最终返回基准 } /*方法1:堆。用于求解 TopK Elements 问题,通过维护一个大小为 K 的小根堆, 堆中的元素就是TopK Elements。堆顶元素就是 Kth Element。如果是第K小的元素 就建立大根堆。时间复杂度 O(NlogK),空间复杂度 O(K)。*/ /* int findKthLargest(vector<int>& nums, int k) { int n = nums.size(); priority_queue<int,vector<int>,greater<int>> q; for(int i = 0;i < n;i++){ q.push(nums[i]); if(q.size() > k) q.pop(); } return q.top(); }*/ /*方法2:快速选择。用于求解 Kth Element 问题,使用快速排序的 partition() 进行实现。 快速排序的 partition() 方法会返回一个整数 j 使得 a[left..j-1] 小于等于 a[j], 且 a[j+1..right] 大于等于 a[j],此时 a[j] 就是数组的第 j 小的元素, 我们可以转换一下题意,第 k 大的元素就是第 nums.size() - k 小的元素。 找到 Kth Element 之后,再遍历一次数组,所有大于等于 Kth Element 的元素都是 TopK Elements。时间复杂度 O(N),空间复杂度 O(1)*/ public int findKthLargest(vector<int>& nums, int k) { k = nums.size() - k; int left = 0, right = nums.size() - 1; while (left < right) { int j = partition(nums, left, right); if (j == k) { //选择的基准等于目标,跳出循环 break; } else if (j < k) { //选择的基准小于目标,在右侧子序列中继续选择 left = j + 1; } else { //选择的基准大于目标,在左侧子序列中继续选择 right = j - 1; } } return nums[k]; } }
拓展:Arrays.sort() 和 Collections.sort() 原理,Collections.sort() 底层调用的是 Arrays.sort(),元素少于47用插入排序,至于大过INSERTION_SORT_THRESHOLD(47)的,少于阀值QUICKSORT_THRESHOLD(286)的用快速排序,至于大于286的,它会进入归并排序(Merge Sort)。Arrays.sort() 原理见 剖析JDK8中Arrays.sort底层原理及其排序算法的选择 。
总结
最坏情况:选择了最大或者最小数字作为基准,每次划分只能将序列分为一个元素与其他元素两部分,此时快速排序退化为冒泡排序,如果用树画出来,得到的将会是一棵单斜树,即所有的结点只有左(右)结点的树,树的深度为 n,时间复杂度为O(n2)。
在最好情况下,即partition函数每次恰好能均分序列,空间复杂度为O(logn);在最坏情况下,即退化为冒泡排序,空间复杂度为O(n)。平均空间复杂度为O(logn)。
参考地址:
https://blog.csdn.net/nrsc272420199/article/details/82587933

