MIT6.s081/6.828 lectrue4:page tables 以及 Lab3 心得
不管是计算机组成还是操作系统,虚拟内存都是其中的重要内容,所以这一节我会结合 CSAPP 第九章:虚拟内存 来一起复习(顺便一说,CSAPP 这一节的 lab 是要求设计一个内存分配器,也是很有意思的,有时间一定要把 CSAPP 的 lab 博客也补上!)
这一节主要讨论虚拟内存和页表的话题,主要内容有 3 个部分:
-
地址空间(Address Spaces)的概念
-
RISC-V 中支持虚拟内存的硬件。当然,所有的现代处理器都有某种形式的硬件,来作为实现虚拟内存的默认机制。
-
XV6 中支持的虚拟内存代码。
在 RISC-V 中,内存地址是按照字节来寻址的,即每个地址代表一个字节。指令和数据可以以字节为基本单位进行存储和访问。
所有代码见:我的GitHub实现
一、地址空间
上一节的一个话题是 OS 的隔离性,主要包括两种隔离:
- OS 内核和用户程序之间的隔离
- 用户程序之间的隔离
这两种隔离具体来说都属于“内存隔离”,内存隔离的一种实现方式就是“地址空间”
CSAPP 中给出地址空间的准确定义:一个n位的地址空间,包含2^n个地址,现代OS一般支持32位或者64位虚拟地址空间。同一个物理地址,在不同的地址空间中有着不同的地址。
地址空间的概念简单且直观,我们给包括内核在内的所有程序专属的地址空间。shell 和 cat 程序都有自己的地址空间,互相都不知道对方地址空间的存在,所以现在我们的问题是如何在一个物理内存上,创建不同的地址空间,因为归根到底,物理上的 DRAM 芯片是所有程序共用的。

页表(page table)
在共享的物理内存上如何创建出不同程序的地址空间呢?
最常见的方法,同时也是非常灵活的一种方法就是使用页表(Page Tables)。页表就是一个数组,他的元素就是一个个页表条目(PTE),使用 页表可以实现虚拟内存地址到物理内存地址的翻译,页表存储在内存中,由 OS 负责维护,内存管理单元(Memory Management Unit) 有查询页表的权限,MMU由一般被集成在 CPU 中。
特别注意:MMU是硬件的一部分而不是操作系统的一部分
以下图为例,当一条指令被传入 CPU 中,如果指令中含有地址,CPU 会被为指令中的地址是虚拟地址,然后将这个虚拟地址通过 MMU 翻译为物理地址,从而去物理内存上找到相应的值。
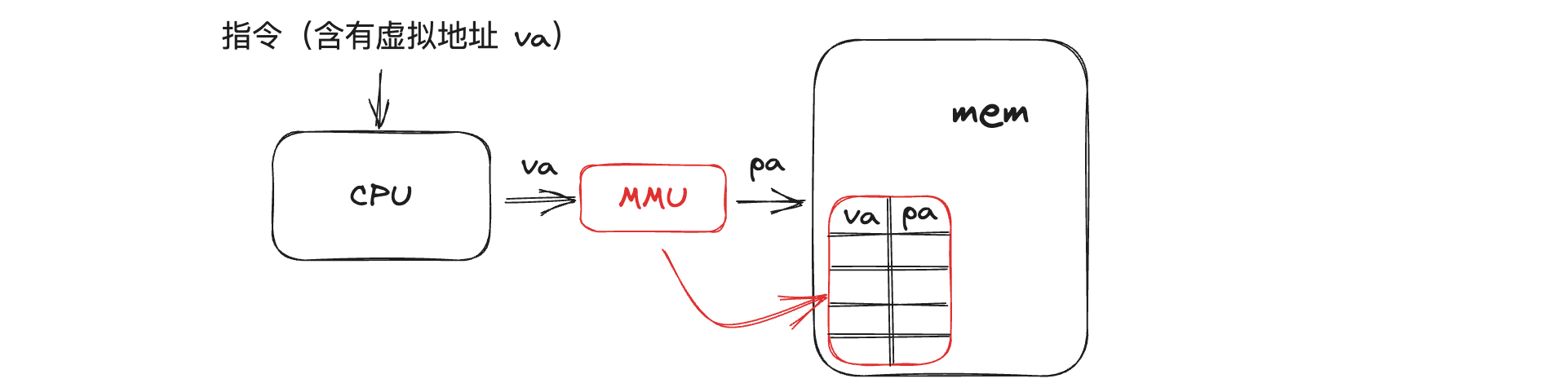
到目前位置,一切看上去很简单、很美好,但魔鬼隐藏在细节中,下面是要注意的细节
-
页表存在哪里?页表是保存在内存中的,MMU只是会去查看 page table,MMU并不会保存 page table
-
在 RISC-V 上 SATP 的寄存器会存储页表的地址(这里简单思考一下,存的是物理地址还是虚拟地址?肯定是物理啊!不然成了地址翻译套娃了,永远得不到物理地址)
-
page table 中 PTE 的粒度是:page,所以这里要清楚,内存中每个字节都有自己的地址没错,但不是每个字节都有对应的PTE,是每一页才有对应的PTE(RISC-V中,一个page是4KB,4096Bytes)
-
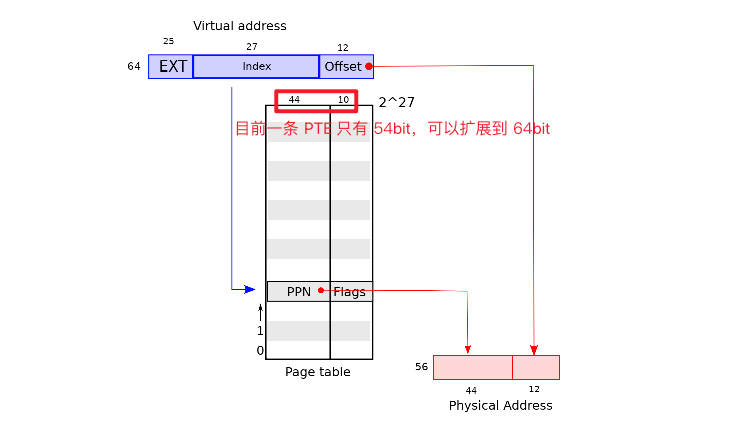
页表翻译的过程,以下图为例说明,一个虚拟地址有 64bit,而 xv6 运行在 Sv39 模式下,即 64bit 的虚拟地址只用到了低 39bit,高 25bit 没有使用。
2^39 bytes = 512 GB,所以 RISCV 虚拟地址空间有 512GB。- 将 39 bit 虚拟地址分为 2 部分,前 27 bit 称为 index,后 12bit 称为 offset
- index 部分就是页表的索引,取出页表中第 index 条PTE,PTE 有 54bit ,前 44bit 称为 PPN(Physical Page Number 物理页号),后 10bit 称为 Flags,目前我们只关注前 44bit
- 将 PPN 和 offset 拼接到一起,就是翻译出来的物理地址
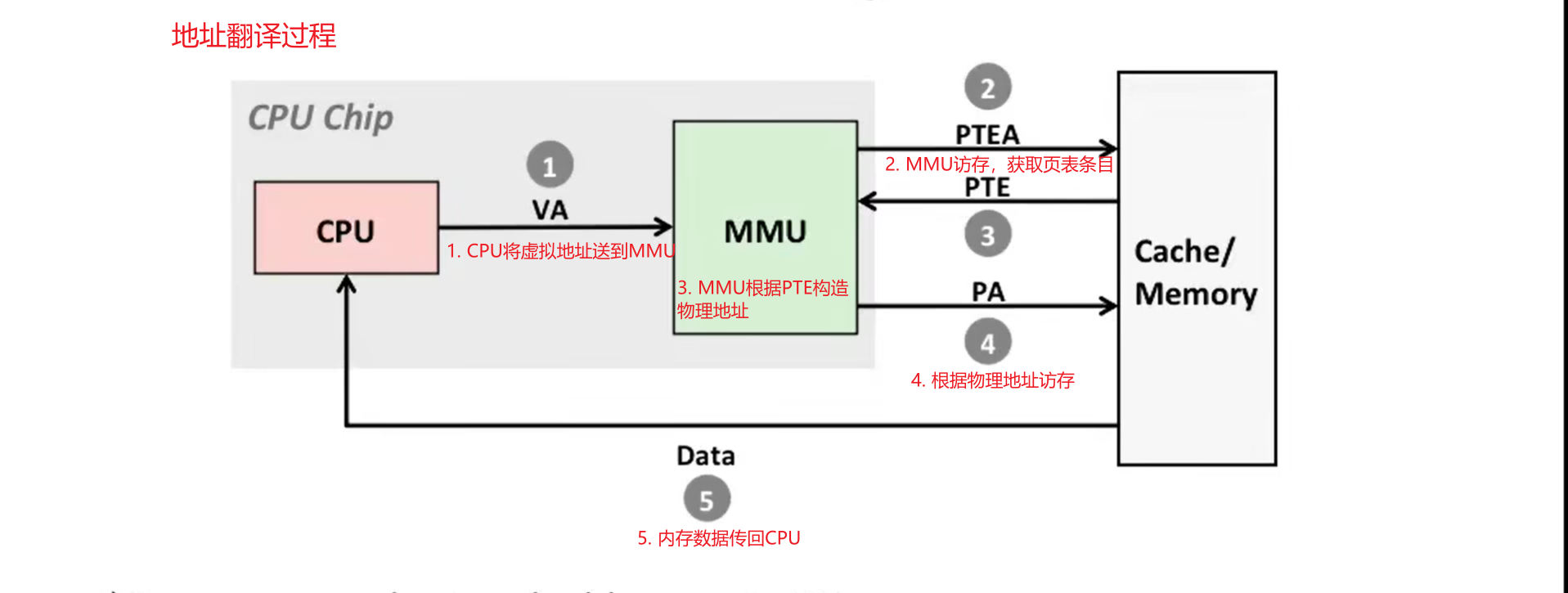
附一张 CSAPP 的课件图,从宏观上再次理解一下地址翻译的过程:
思考:offset 的含义是什么,为什么是 12bit?
回答:offset 是指一个字节在一个 paeg 中的偏移量,一个 page 是 4096KB,即 2^12字节,由于 RISC-V 是字节寻址,每个地址代表一个字节,所以一个 page 中就有 2^12个地址,而 offset 使用 12bit 就可以覆盖这 2^12 个地址
比如 offset 是 0000 0000 0101,表示的是这个 page 中的第 5 个字节(从 0 开始)
关于 Sv39 模式:
为什么使用 39bit,是因为 RISC-V 的设计者认为这个数字在可预测的将来可以容纳足够多的 I/O设备 和 DRAM芯片;如果需要更多的虚拟地址,RISC-V设计者已经定义了具有48位虚拟地址的Sv48模式
多级页表
单级页表的困境:巨大的内存占用
为什么要提出多级页表的概念,简单计算一下就知道,以 XV6 为例,现有以下事实:
- 一条 PTE 占 8bytes:一条 PTE 有54bit,由于可以扩展到 64bit,所以我们以一条 PTE 64bit = 8bytes 计算
- 一页 4KB
- RISCV 虚拟地址空间有 239 bytes = 512GB
开始计算:
- 虚拟地址空间一共有 239 / 4kB = 239 / 212 = 227 页( 227 ≈ 1 亿 3 千万,意味着页表中有约 1 亿 3 千万条 PTE)
- 页表需要的内存为 :227 * 8bytes = 230 bytes = 1GB
计算结果是不是大跌眼镜?而且这只是一张页表就需要 1GB 的内存,那 n 个用户进程可是有 n 张不同的页表的,难道计算机跑 10 个进程,光页表就占据 10GB 内存吗?
很显然计算结果告诉我们,由于GB 级别的内存占用,页表不能简单粗暴地单级存储,所以多级页表的概念被提出来了
多级页表的概念以及翻译过程
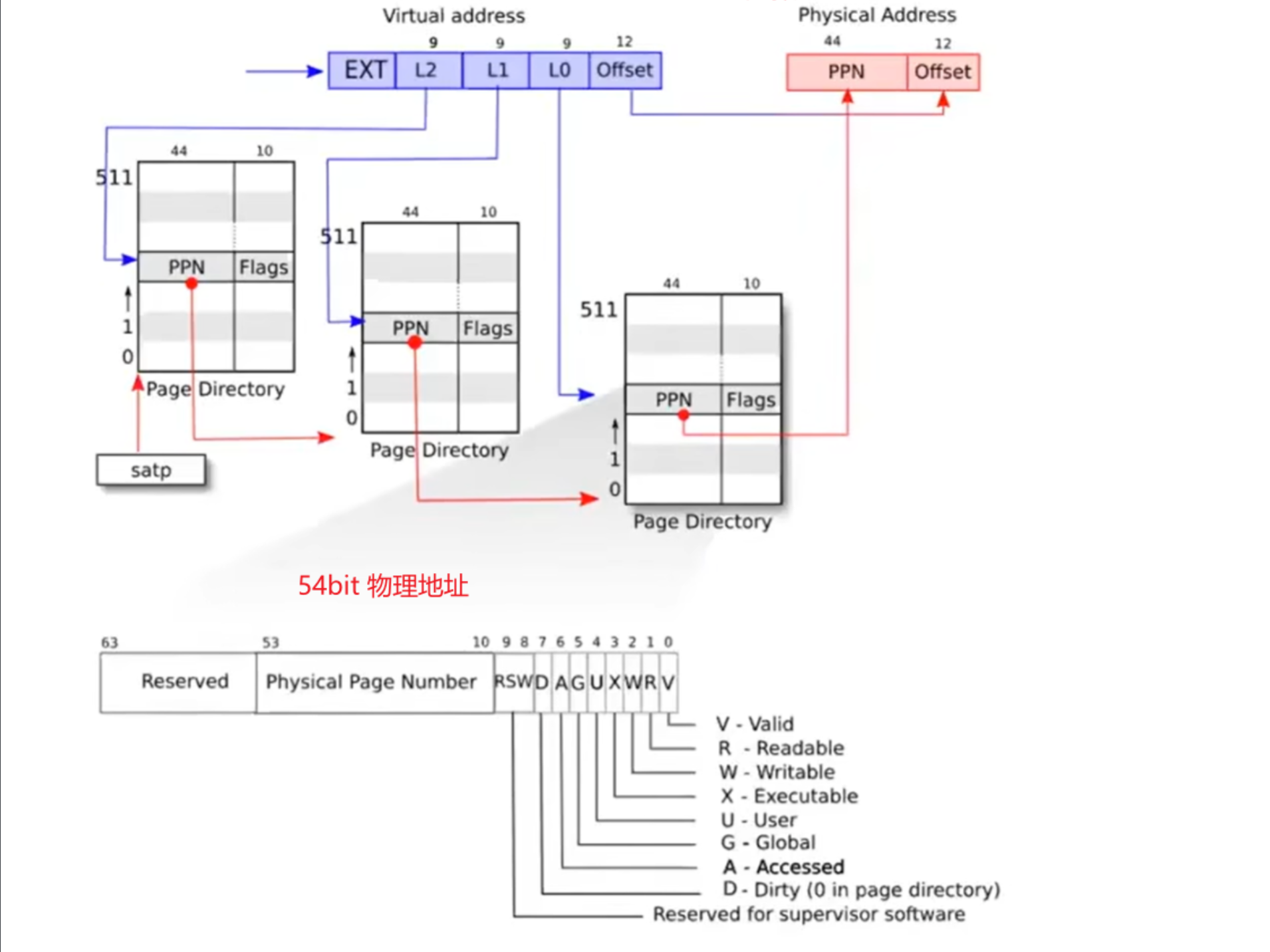
上一节知道,以 RISC-V 的 sv39 模式为例,有效虚拟地址空间是39位,一页大小为4K字节(212 byte),一条PTE为 8 byte,需要 1GB的内存空间存放页表!
解决方案就是使用层次结构的页表-多级页表,这个结构的关键就是,之前的页表PTE的内容是内存的物理页号PPN+Flags,而现在一级页表PTE的内容是下一级页表的基地址+Flags(之所以叫基地址,是因为补 0 后是下一级页表的最低地址),直到最后一级页表PTE的内容才是内存的"物理页号PPN+Flags"
以下图为例,展示多级页表的翻译过程:
- 虚拟地址依旧是 27bit index + 12bit offset,但是 27bit 的 index 被分成了 3 部分,每部分 9bit,9bit 意味着可以表示29 = 512 条PTE,以一级页表为例,每条 PTE 对应 一张二级页表,所以 512 条 PTE 对应 512 张二级页表
- 从 satp 寄存器中找到一级页表的物理地址,然后利用L2 的 9bit 在一级页表中定位一条 PTE,其中的 PPN + 12个 0 就是某张二级页表的物理地址,然后利用 L2 的 9bit在这张二级页表中定位一条 PTE
- 利用二级页表中某条 PTE 中的 PPN,+ 12个 0的得到三级页表的物理地址,然后利用 L0 的 9bit 在三级页表中定位一条 PTE,这条 PTE + offset 就是最终的物理地址
CSAPP:多级页表为什么节省内存
这其实是一个很棒的面试题,这一问能想通,说明学习者对于页表的知识真正"参透"了。
以一个32位系统(虚拟地址有32bit),一页4KB(212bytes),每条PTE 4bytes为例,解释一下多级页表如何节省空间:
- 单级页表:需要为32位地址的每一个 page 提供一条PTE,即这张页表必须对整个虚拟地址空间做到全覆盖(因为如果虚拟地址在页表中找不到对应的页表项,地址翻译无法继续,整个计算机系统就无法工作了),页表一共需要 232 / 212 * 4 byte = 4MB 内存空间才能覆盖全部 4GB 的地址空间。
- 多级页表:如下图所示,如果只需要使用部分虚拟地址空间,比如图中的
VP 0~VP 2047以及VP 9215,只需要1张4KB 大小的一级页表,就可以覆盖了整个地址空间:4GB。再加上 3 张二级页表,就可以对VP 0~VP 2047、VP 9215完成映射,一共 4 张页表共16KB。对比单张页表的 4MB 内存空间节省很多。
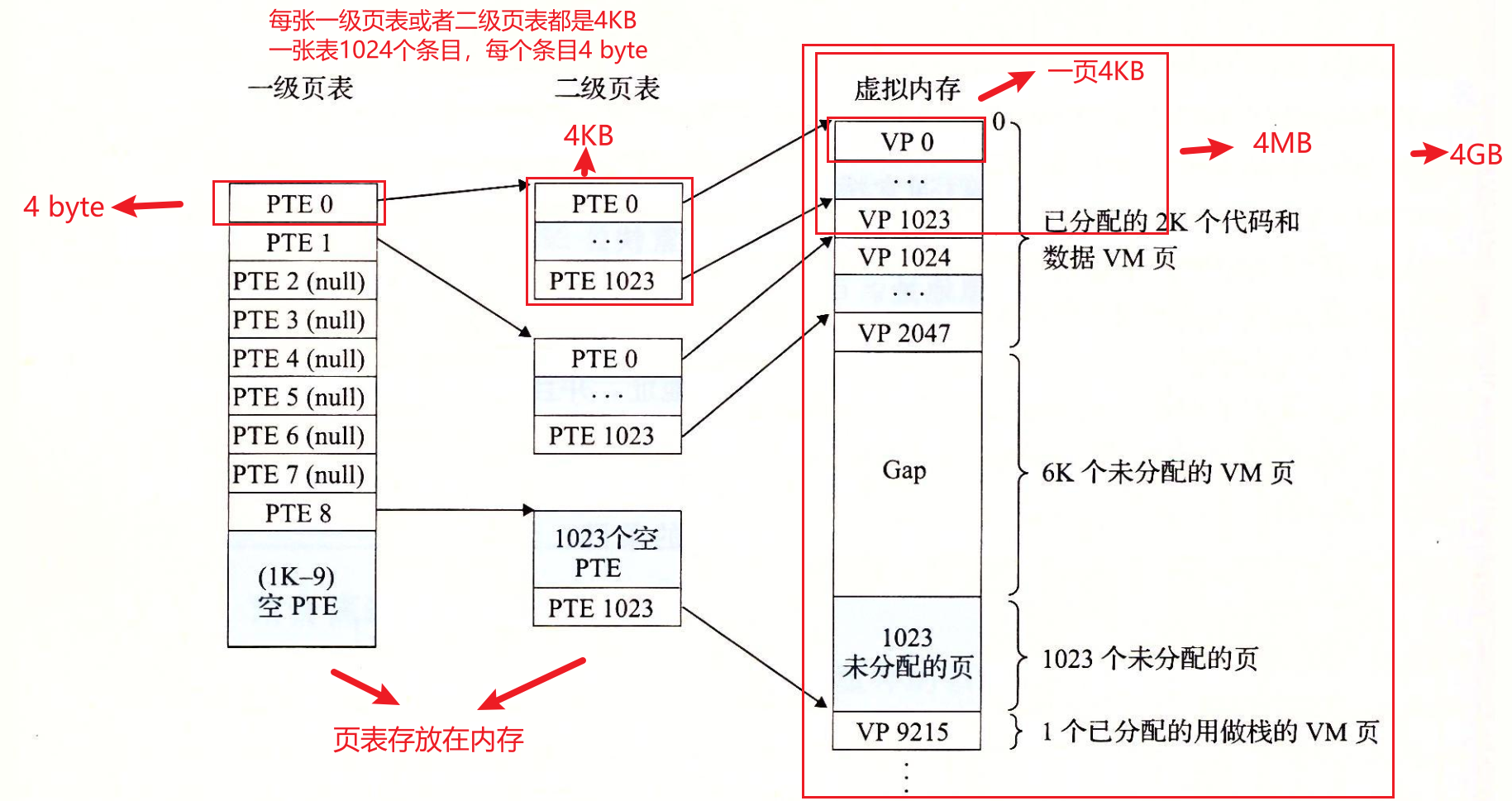
一个至关重要的问题是:这里为什么可以只使用部分空间而不用像单级页表那样全部覆盖(每一个 page 都有 PTE)呢?其实多级页表也是做了全覆盖的,那就是第一级页表,在多级页表中,一级页表是常驻内存的,而且一级页表一条 PTE 就覆盖了 4MB 的内存、整张一级页表覆盖了 4GB 内存,对比单级页表一条 PTE 就映射了 4KB 的内存,效率大大提升。
所以使用多级页表能够节省内存的原因有以下两个,但重要的是在这个前提下:多级页表的一级页表依旧做到了内存全覆盖:
- 一级页表覆盖了整个4GB虚拟地址空间,但如果某个一级页表的PTE没有被用到,那么二级页表和三级页表就不会存在,这是一种巨大的节约(xv6book也有类似的表述:在大范围的虚拟地址没有映射的常见情况下,三层结构可以省略整个页面目录)
- 只有一级页表(与最经常使用的二级页表)常驻主存,其他页表可以在从磁盘调入
所以总结一下就是:无论是单级页表还是多级页表,他们都需要、也都做到了内存(虚拟)地址的全覆盖,但是多级页表更加灵活,如果某个一级页表的PTE没有被用到,那么二级页表和三级页表就不会存在,这是一种巨大的节约!而单级页表只能老老实实对所有虚拟地址进行映射,因为如果不这样的话,单级页表就不是“全覆盖”,地址翻译就无法进行了
参考:https://www.zhihu.com/question/63375062
PTE 的辅助位
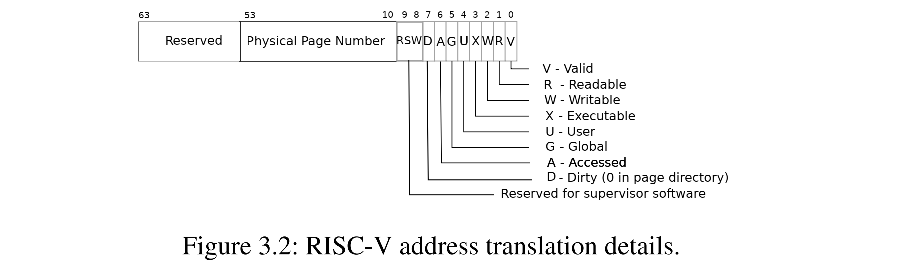
前面讲过一条 PTE 有 54bit,44bit 属于 PPN,10bit 属于 Flags,又称为辅助位
-
V-bit :Valid,有效位,如果Valid bit位为1,那么表明这是一条合法的PTE,可以用来做地址翻译,否则,不能使用这条PTE,因为这条PTE并不包含有用的信息。(用 CSAPP 中的概念解释的话,有效 = 该页处于“已缓存”状态,具体见下面的引用)
-
R-bit :Readable,该页是否允许被读
-
W-bit :Writable,该页是否允许被写
-
X-bit :Executable,CPU是否可以将页面的内容解释为指令并执行
-
U-bit:User, 是否(只)允许在 user mode 下使用该条 PTE
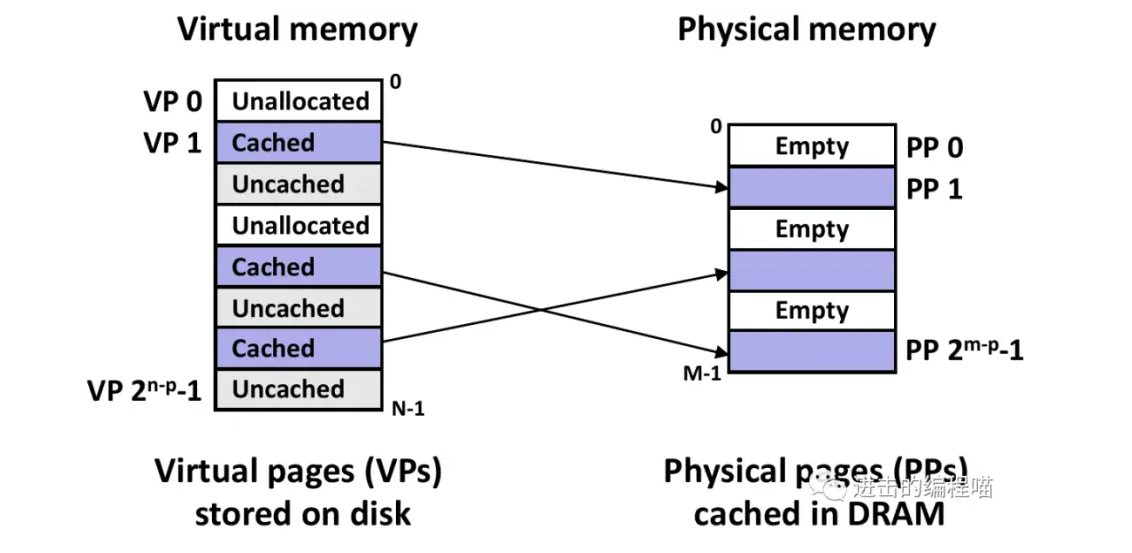
CSAPP:任何时刻,虚拟页都可分为三种类型
未分配的:VM系统还未分配或创建的页,不占用任何磁盘空间,上图中的VP0、3(在磁盘上还不存在!)这是一种为了和下面两个类型统一的表达方式,因为我们不至于、不必要把虚拟地址空间中的每个页面都存储起来
已缓存:已缓存在内存中的已分配的页,上图中的VP1、4、6
未缓存:未缓存在内存中的已分配页,上图中的VP2、5、7
注意,PTE 的这些辅助位是给分页硬件(paging hardware)看的,在xv6 book 中它被频繁提及,分页硬件总是和页表交互。
二、支持虚拟内存的硬件
这里有一块 RISC-V 主板,中间是RISC-V处理器,处理器处理器旁边就是DRAM芯片。处理器下方就是DRAM芯片。一个主板是由 CPU、DRAM、以及各种外设(如网卡、通信接口、定时器、PWM、DMA 等)组成的,DRAM 和各种外设都有自己地址,这是由硬件设计者决定的,当我们需要操作外设或者存取数据时,只需要往对应地址发送信号或者数据,这是最基本的计算原理。

在常见的地址映射方案中,当 CPU 访问物理地址空间时,若得到的物理地址小于 0x80000000,则可以认为该访问是针对各类 I/O 设备(外设)的操作;而若得到的物理地址大于等于 0x80000000,则可以认为该访问是针对 DRAM 的操作。下面的讲解也遵循这个惯例。
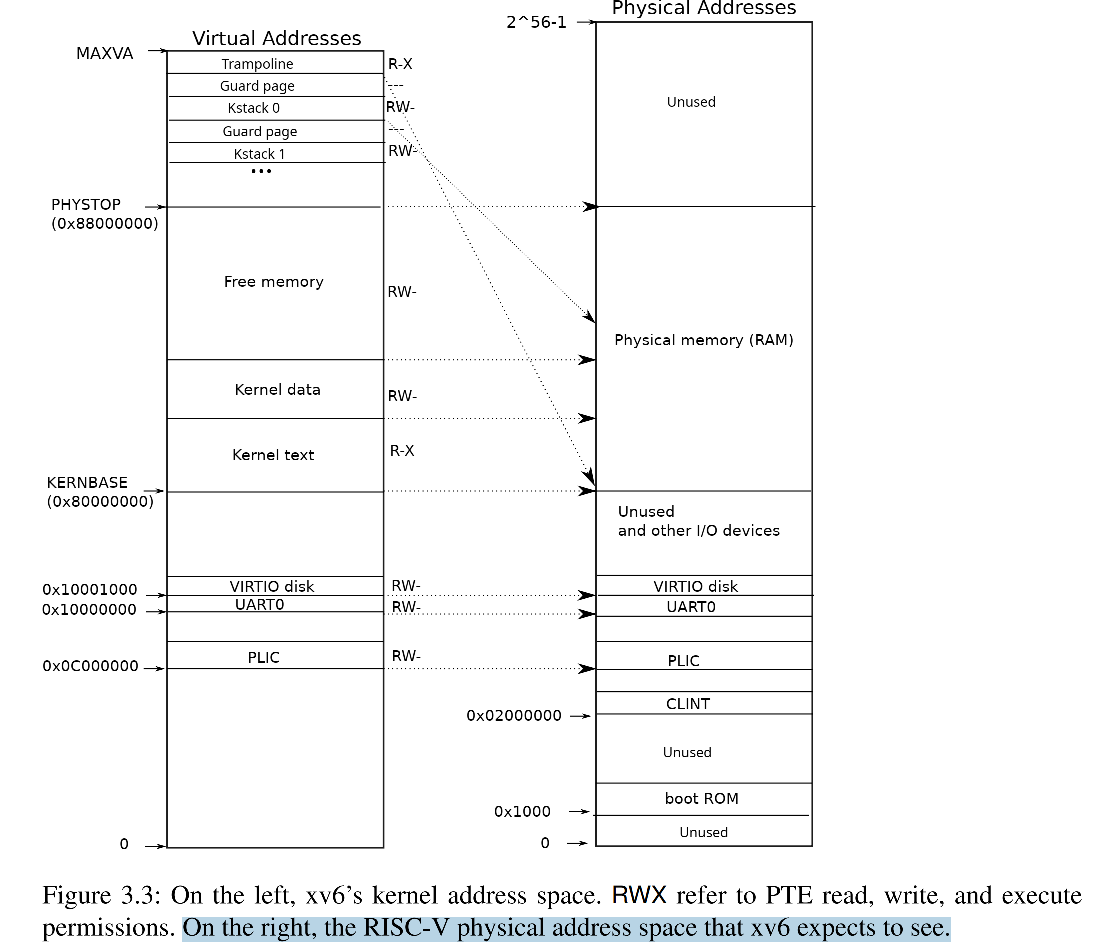
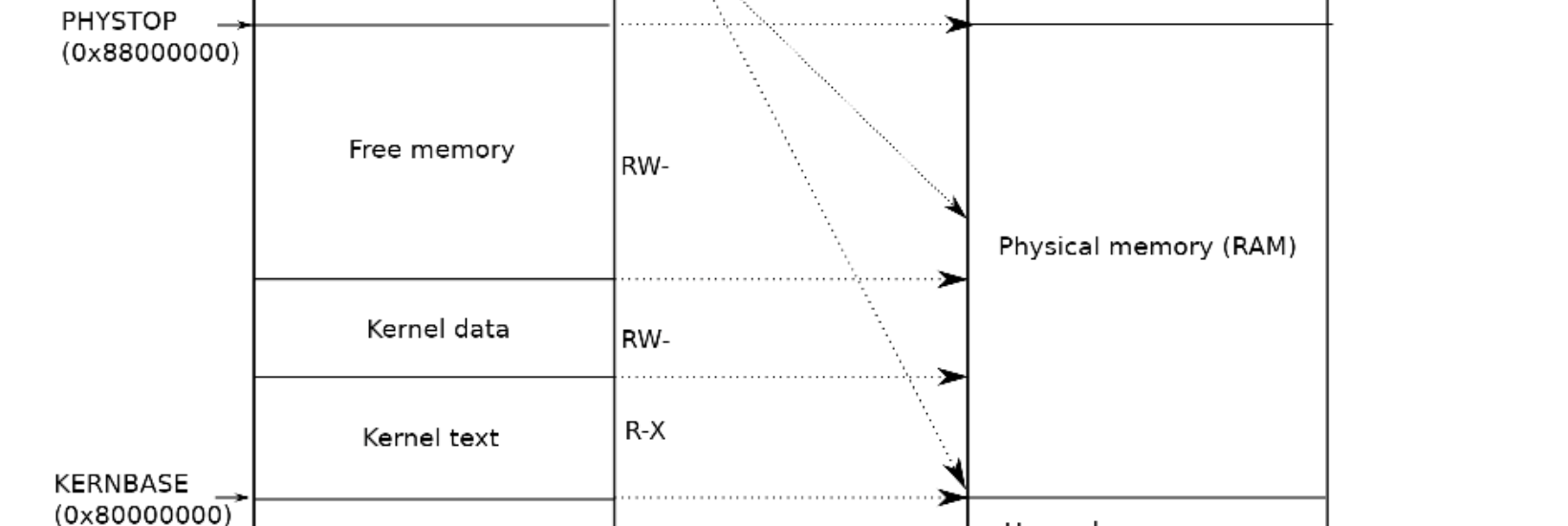
下图左边是 xv6 内核的虚拟地址空间,右半部分是一块 RISC-V 主板的物理地址,该结构完全由硬件设计者决定,上半部分是物理内存或者说是 DRAM,右边下半部分是I/O设备。
右边的物理地址
细看右边的物理地址:
- 最下面(地址为0)是未被使用的地址;
- 地址 0x1000 是 boot ROM 的物理地址,当主板上电后,做的第一件事情就是运行存储在 boot ROM 中的代码。这里的代码会启动 boot loader ,把 xv6 kernel 加载到内存中的 0x8000000 处。当 boot 完成之后,会跳转到地址0x80000000,开始执行 OS 的代码
- PLIC是中断控制器(Platform-Level Interrupt Controller)
- CLINT(Core Local Interruptor)也是中断的一部分。地址0x02000000对应CLINT,当你向这个地址执行读写指令,你是向实现了CLINT的芯片执行读写。(看样子是在读写物理内存,但由于地址小于 0x80000000,实际上是以这种形式操作外设)
- UART0(Universal Asynchronous Receiver/Transmitter)负责与Console和显示器交互。
- VIRTIO disk,与磁盘进行交互。
左边的 XV6 的内核的虚拟地址空间
XV6 内核会设置好内核使用的虚拟地址空间,也就是上图左边的地址分布,因为设计者想让XV6尽可能的简单易懂,所以左侧低于 PHYSTOP(0x8800 0000) 的虚拟地址,使用的是直接映射的方式,比如虚拟地址 0x02000000 对应物理地址 0x02000000
这里需要注意一点就是权限,XV6 的虚拟地址空间每一段都有不同的权限。例如 Kernel text page 被标记为 R-X,意味着你可以读它,也可以在这个地址段执行指令,但是你不能向Kernel text写数据。
三、XV6 中支持虚拟内存的代码
阅读完第二节,了解了主板的物理地址结构和 XV6 内核的虚拟地址空间结构,那么这两者是如何映射到一起的?其实仔细想想就知道了,映射完成意味着可以根据 va 找到 pa,那么怎么根据 va 找 pa?当然是 page table 啦!所以映射就是在 page table 中把这两者的关系记录下来,就意味着映射完成!
来看代码:
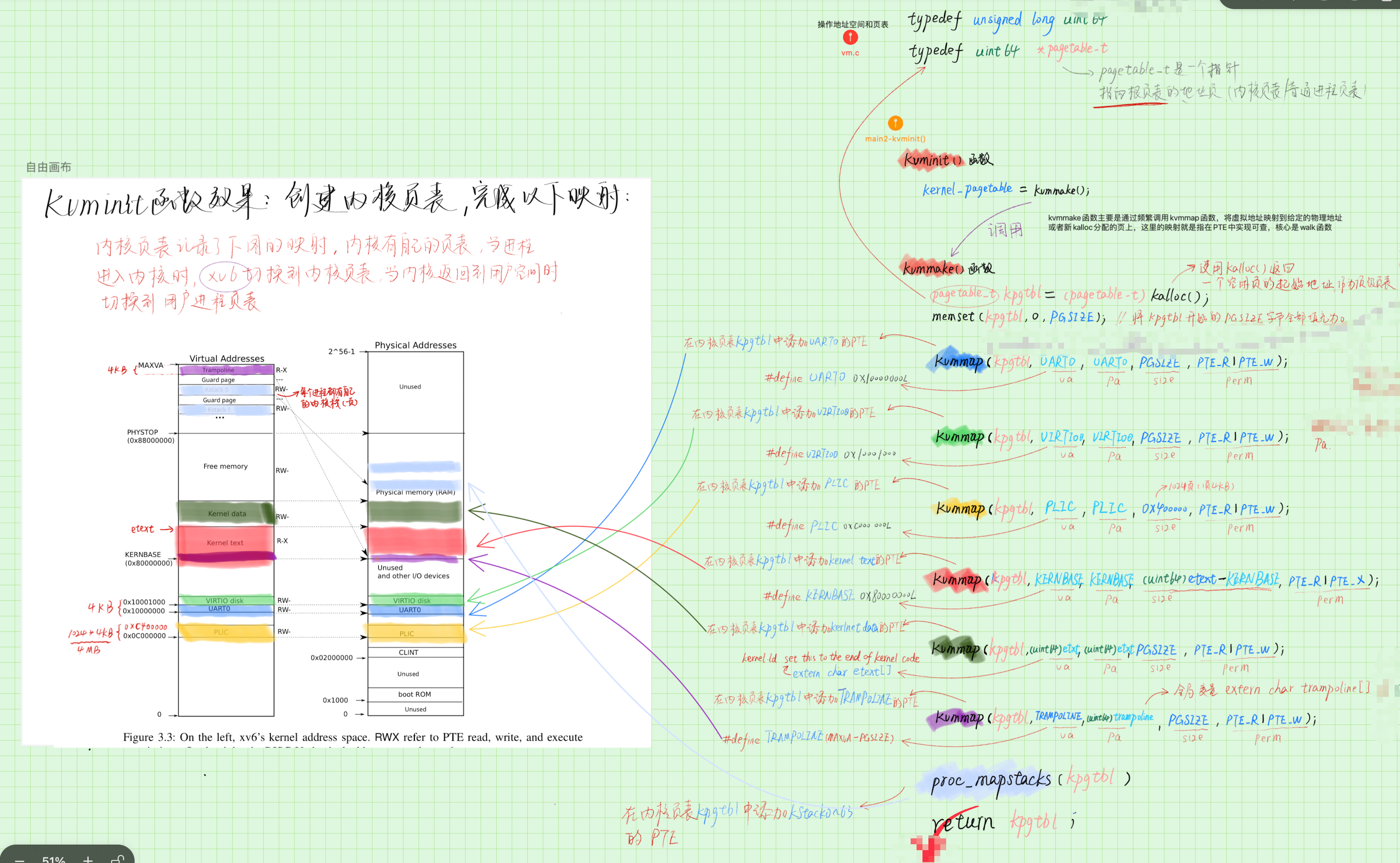
// Initialize the one kernel_pagetable
void kvminit(void)
{
kernel_pagetable = kvmmake();
}
//-------------------------------------------------------------------
// Make a direct-map page table for the kernel.
pagetable_t kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// allocate and map a kernel stack for each process.
proc_mapstacks(kpgtbl);
return kpgtbl;
}
这里的逻辑其实非常简单,来看我帮你梳理一下,以主板上UART0的物理地址0x1000 0000为例,你现在有了这个物理地址,想要在内核的页表中添加一条 PTE,将虚拟地址0x1000 0000与物理地址对应起来,所以:
- 先在页表中找到这个 va 对应的 pte,找不到则使用 kalloc 分配一个新 page
- 然后修改这条 pte,使其指向物理地址
0x1000 0000
我们来详解这两步:
-
页表中寻找 va 对应的 pte,这是 walk() 函数的责任,walk()函数模拟了三级页表中根据 va 寻找 pte 的流程,之所以说模拟,是因为在真实的计算机中,这个寻找过程是 MMU 实现的,而不是 OS 实现的。

-
修改这条 pte 内容,将其指向物理地址

总结 kvminit() 的效果就是,创建使用 kalloc() 函数分配一个 4KB 的 page 作为内核页表,然后按照 XV6 内核的虚拟地址空间结构,将所有的虚拟地址和物理地址一一映射。下图中各色矩形就是映射结果:
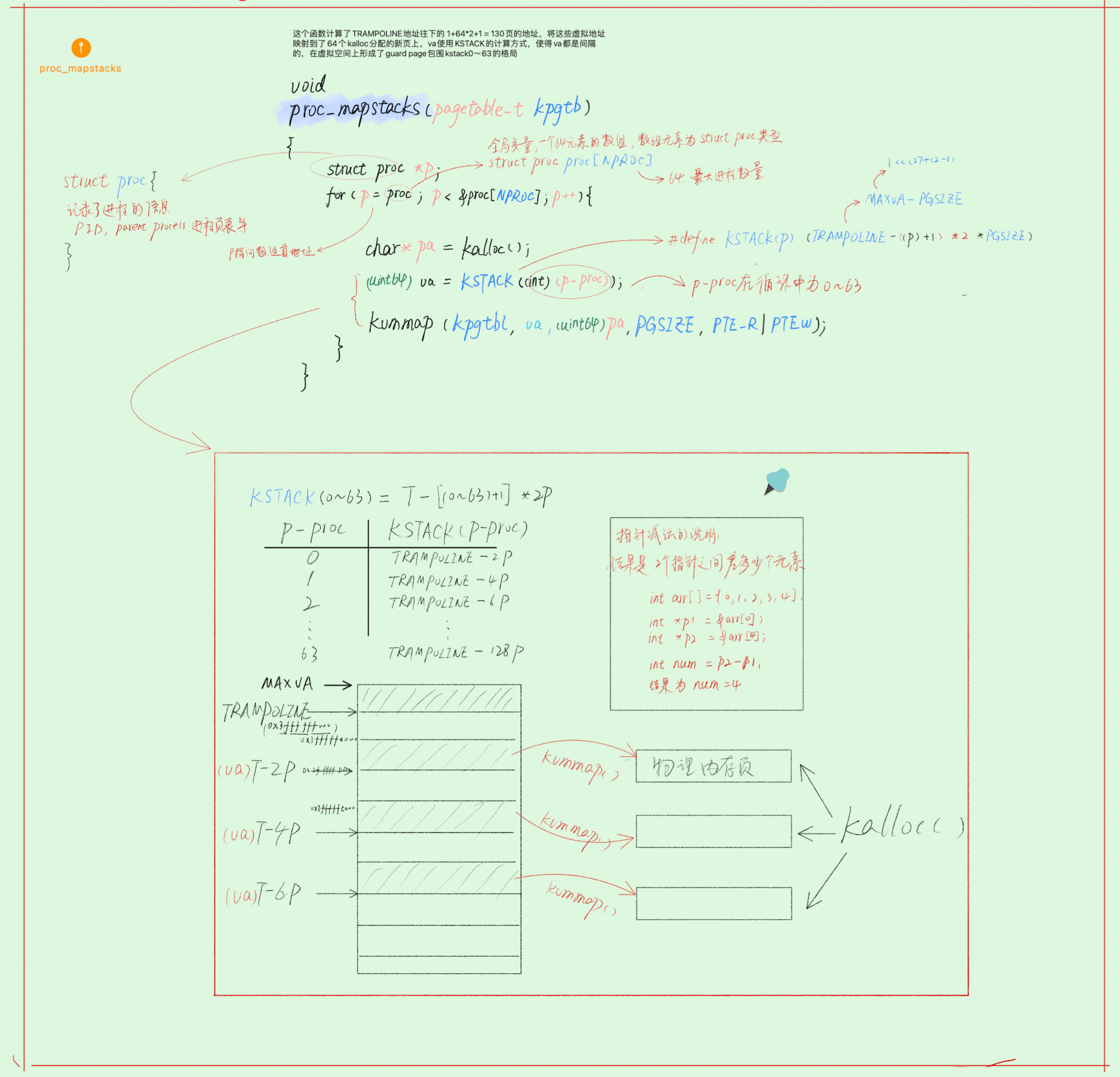
其中 proc_mapstacks()函数比较有趣,它的作用是,计算了 TRAMPOLINE 地址(最大的虚拟地址)往下的 1+64*2+1 = 130页的地址,将这些虚拟地址映射到了64个 kalloc 分配的新页上,va使用 KSTACK 的计算方式,使得 va 的值依次是:
&TRAMPOLINE - 2*PGSIZE
&TRAMPOLINE - 4*PGSIZE
&TRAMPOLINE - 6*PGSIZE
......
这样 va 都是间隔的,所以在虚拟空间上形成了guard page包围 kstack0~63 的格局,最终实现把这些虚拟地址映射到 kalloc 分配的的内存空间(物理的 DRAM芯片)
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
详细分析见下图:
四、Lab3 :pgtbl 心得
Lab3.1 speed up the systemcall
从上一个 lab 中可以知道,要想进行系统调用,必须有从用户态进入到内核态才可以实现这种调用。
以系统调用:getpid() 为例,正常流程是:在用户态使用 ecall 实现系统调用,执行 ecall 后进入内核态,在内核态中调用 myproc() 得到当前进程 proc 结构体,返回 proc->pid 即可
而 lab 想让我们实现的是:直接在“每个进程”启动时,指定一个名为 USYSCALL 的 page 存放 pid,并且设置该 page 的权限为 R | U,U 是指可以该 PTE 可以 user mode下使用,所以不用陷入内核态就可以使用这条 PTE 找到存放 pid 的 page(小小的吐槽,一个 page 就放一个 pid,属实浪费......)
根据提示可以很容易写出来:
提示:
可以使用kernel/proc.c中的proc_pagetable()执行映射。
选择只允许用户空间读取页面的权限位。
您可能会发现 mappages() 是一个有用的实用程序。
不要忘记在allocproc()中分配和初始化这个页面。
确保在freeproc()中释放页面。
首先定义 USYSCALL 的虚拟地址
#define USYSCALL (TRAPFRAME - PGSIZE)
struct usyscall {
int pid; // Process ID
};
那么如何实现在“创建每个进程时”完成映射呢?分析源码创建进程只有两种情况,一种是最初的 userinit(),另一种就是以后都用的 fork() 来创建进程,这两种创建进程的情况都是使用 allocproc() 函数:从 process table 中返回一个未使用的状态的进程,所以在 allocproc() 中分配这个页面的物理地址:p->usyscall,模仿上面的分配 trapframe page 的函数,可以很快写出来:
// in allocproc()
struct proc *p;
// Allocate a trapframe page.
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// 为 USYSCALL page(虚拟地址)分配物理页面
if((p->usyscall = (struct usyscall *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// 初始化 USYSCALL page
p->p_usyscall->pid = p->pid
在 allocproc() 中要为进程分配对应的页表,使用 proc_pagetable() 函数,所以在这个函数中将 kalloc() 分配的物理地址p->usyscall 和虚拟地址 USYSCALL 完成映射:
// in proc_pagetable()
// 将 kalloc() 分配的物理地址p->usyscall 和虚拟地址 USYSCALL 映射
if(mappages(pagetable, USYSCALL, PGSIZE,
(uint64)p->usyscall, PTE_R | PTE_U) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
根据提示最后要确保在 freeproc() 中释放页面。
// Free a process's page table, and free the
// physical memory it refers to.
void proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
//在 freeproc() 中释放页面
uvmunmap(pagetable, USYSCALL, 1, 0);
uvmfree(pagetable, sz);
}
Lab3.2 Print a page table (easy)
这个 lab 要求启动 XV6 时,打印出页表的内容。定义函数 vmprint() ,它接收一个 pagetable_t 类型的参数,并且按照下面的格式打印:
page table 0x0000000087f6b000 //第一行显示vmprint的参数,即页表指针
..0: pte 0x0000000021fd9c01 pa 0x0000000087f67000 // .. 表示第1层深度的页表,pte后就是pte的内容,截取后10bit,再补足12个0就是pa
.. ..0: pte 0x0000000021fd9801 pa 0x0000000087f66000 // .. .. 表示第2层深度的页表,pa后就是物理地址
.. .. ..0: pte 0x0000000021fda01b pa 0x0000000087f68000
.. .. ..1: pte 0x0000000021fd9417 pa 0x0000000087f65000
.. .. ..2: pte 0x0000000021fd9007 pa 0x0000000087f64000
.. .. ..3: pte 0x0000000021fd8c17 pa 0x0000000087f63000
..255: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..511: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..509: pte 0x0000000021fdcc13 pa 0x0000000087f73000
.. .. ..510: pte 0x0000000021fdd007 pa 0x0000000087f74000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
init: starting sh
这个函数很简单,给出提示,可以仿照 freewalk 函数的递归写法来遍历页表,但是也就三层,我就直接循环遍历了:
//print pte
void vmprint(pagetable_t level2){
//好,现在已经拿到了宝贵的顶级页表指针 pagetable,接下来打印 pte
printf("page table %p\n", level2); //第一行直接打印pagetablr,得到页表地址
//接下来遍历这个页表,找到PTE_V有效的就打印
//这个打印顺序很有趣,就是很符合递归的顺序
for(int i = 0; i < 512; i++) {
pte_t level2_pte = level2[i];
if(level2_pte & PTE_V) {
printf("..%d: ", i);
// 注意%p 用来打印指针变量的值
printf("pte %p pa %p\n", level2_pte, PTE2PA(level2_pte));
uint64 level1 = PTE2PA(level2_pte);
for(int j = 0; j < 512; j++) {
pte_t level1_pte = ((pagetable_t)level1)[j];
if(level1_pte & PTE_V) {
printf(".. ..%d: ", j);
printf("pte %p pa %p\n", level1_pte, PTE2PA(level1_pte));
uint64 level0 = PTE2PA(level1_pte);
for(int k = 0; k < 512; k++) {
pte_t level0_pte = ((pagetable_t)level0)[k];
if(level0_pte & PTE_V) {
printf(".. .. ..%d: ", k);
printf("pte %p pa %p\n", level0_pte, PTE2PA(level0_pte));
}
}
}
}
}
}
}
使用递归的难点是每一层打印的点点 “.. .. ”是和标准输出不一样的,但这也不是大问题,下面给出递归的写法:
void
vmprint(pagetable_t pagetable)
{
if (printdeep == 0)
printf("page table %p\n", (uint64)pagetable);
for (int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
if (pte & PTE_V) {
for (int j = 0; j <= printdeep; j++) {
printf("..");
}
printf("%d: pte %p pa %p\n", i, (uint64)pte, (uint64)PTE2PA(pte));
}
// pintes to lower-level page table
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
printdeep++;
uint64 child_pa = PTE2PA(pte);
vmprint((pagetable_t)child_pa);
printdeep--;
}
}
}
Lab 3.3 Detect which pages have been accessed
在 lab 的这一部分,将向 xv6 添加一个新特性:检查指定页表中的访问位,并向用户空间返回访问信息:即实现 pgaccess(),这是一个报告哪些页面已被访问的系统调用。系统调用接受三个参数:
- base,这是一个 page 的地址,从这个 page 开始检查
- len,需要检查页面的数量。
- mask,这是一个用户空间的地址,用来存储 bitmask,bitmask 反映了哪些 page 被访问
实现其实非常简单,要检查一个 page 是否被访问,只需要检查 PTE 中的 A bit 是否被设置,难点是理解 pgacess 的作用。
lab 要求阅读测试文件来分析出 pgaccess() 函数的作用:
void
pgaccess_test()
{
char *buf;
unsigned int abits;
printf("pgaccess_test starting\n");
testname = "pgaccess_test";
buf = malloc(32 * PGSIZE);
if (pgaccess(buf, 32, &abits) < 0)//pgaccess需要自己实现,自己定义返回被访问的页数总和
err("pgaccess failed");
buf[PGSIZE * 1] += 1;//buf[1024],访问第1页第一个字节(最早是0页)
buf[PGSIZE * 2] += 1;//buf[2048],访问第2页第一个字节(最早是0页)
buf[PGSIZE * 30] += 1;//访问第30页第一个字节
if (pgaccess(buf, 32, &abits) < 0)
err("pgaccess failed");
printf("abits: %d\n", abits);
if (abits != ((1 << 1) | (1 << 2) | (1 << 30)))//pgacess的效果就是设置abits,由于第1,2,30页被访问,所以abits的1,2,30位被设置为1
err("incorrect access bits set");
free(buf);
printf("pgaccess_test: OK\n");
}
malloc分配了 32 page 给 buf,然后访问第1、2、30个page,pgaccess函数就输出了maskbits,将maskbitsd的第1、2、30bit设置为1,注意pgacess不能直接返回maskbits(第四章会有说明,可以直接返回,但是有问题,因为 xv6 只能返回 8bytes 的数据,如果是复杂一点的结构体就拉了),所以要使用 copyout 函数将 maskbits 返回到用户空间
使用argint函数和argaddr函数进行系统调用传参
int
sys_pgaccess(void)
{
// lab pgtbl: your code here.
uint64 base;
int len;
uint64 mask;
argaddr(0, &base);
argint(1, &len);
argaddr(2, &mask);
return pgaccess((void*)base, len, (void*)mask);
}
先不用理解原理,传参原理第四章节会将,现在知道怎么用就好了。
在proc.c中实现 pgaccess
int pgaccess(void *base, int len, void *mask)
{
void *pg = base;//用来遍历所有页的指针
struct proc *proc = myproc();
uint32 ans = 0;
pagetable_t pagetable = proc->pagetable;
for(int i = 0; i < len; i++) {
pg = base + PGSIZE * i;//这里void *类型的指针加法效果和 char * 是一样的:即指针加1代表加1字节
pte_t *pte = walk(pagetable, (uint64)pg, 0);//注意walk要求 pg 进行 void* -> uint64 的类型转换
// 检查PTE_A是否设置
if (pte != 0 && ((*pte) & PTE_A)){
ans = ans | (1 << i);
*pte &= ~PTE_A; // clear PTE_A 这里要对检查PTE_A是否设置后,一定要清除。因为检查本身就会导致 PTE_A 被 set
}
}
//return ans;
return copyout(pagetable, (uint64)mask, (char *)&ans, sizeof(int));
}
OK,以上就是 MIT-OS-04 的所有内容了,比起后面学的 CMU15-445 和 MIT6.824 来说,返回头来看这些 lab 发现非常简单,但当时记得写的还是有点痛苦的,或许是我确实成长了吧!这次复习,让我真正理解了一个以前没想清楚的知识点:为什么多级页表节省空间?为什么多级页表可以不创建没有映射的 PTE,单级页表却要一条都不能少?关键在于"全部映射"这四个字~
所有代码见:我的GitHub实现
