(四) 一文搞懂 JMM - 内存模型
4、JMM - 内存模型
1、JMM内存模型
JMM与happen-before
1、可见性问题产生原因
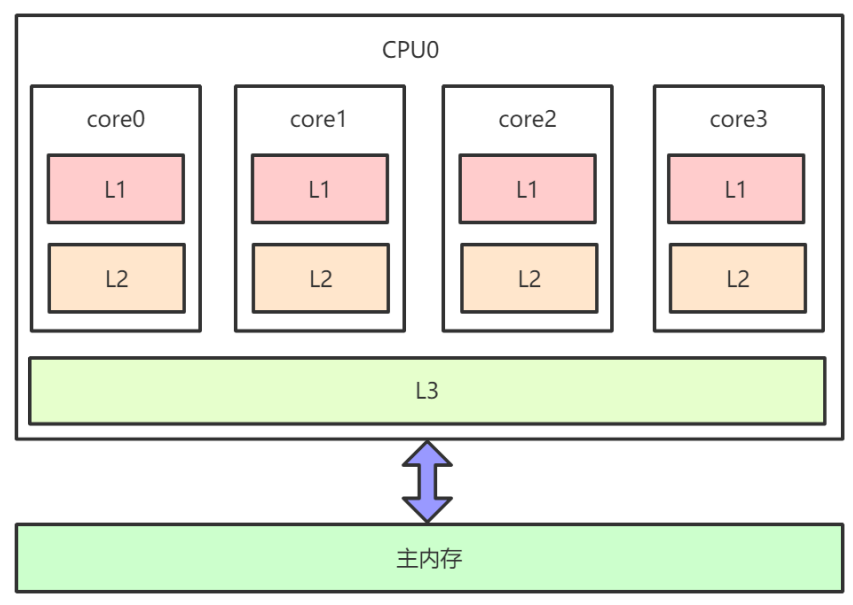
- 下图为x86架构下CPU缓存的布局,即在一个
CPU 4核下,L1、L2、L3三级缓存与主内存的布局。 每个核上面有L1、L2缓存,L3缓存为所有核共用。
- 因为存在
CPU缓存一致性协议,例如MESI,多个CPU核心之间缓存不会出现不同步的问题,不会有 “内存可见性”问题。 - 缓存一致性协议对
性能有很大损耗,为了解决这个问题,又进行了各种优化。例如,在计算单元和 L1之间加了Store Buffer、Load Buffer(还有其他各种Buffer),如下图:
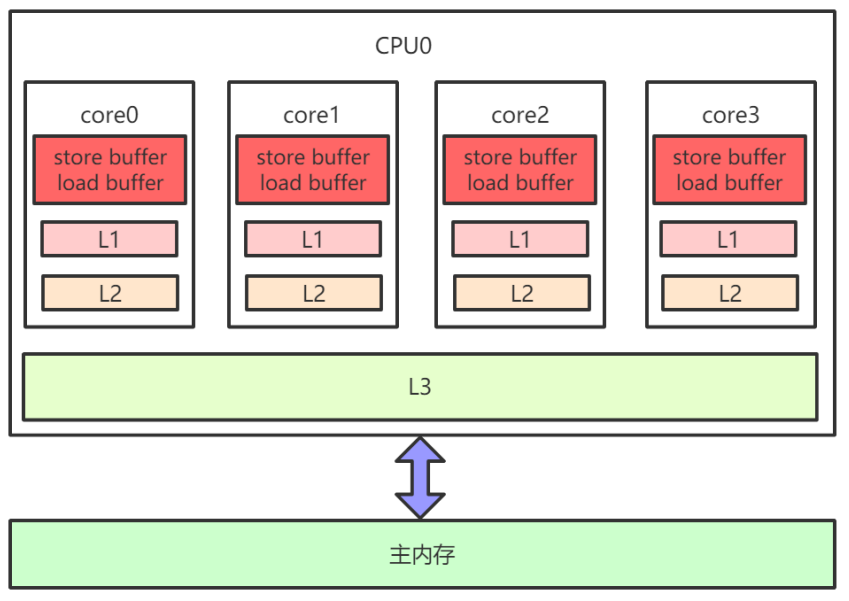
L1、L2、L3和主内存之间是同步的,有缓存一致性协议的保证,但是Store Buffer、Load Buffer和 L1之间却是异步的。向内存中写入一个变量,这个变量会保存在Store Buffer里面,稍后才异步地写入 L1中,同时同步写入主内存中。- 操作系统内核视角下的CPU缓存模型:
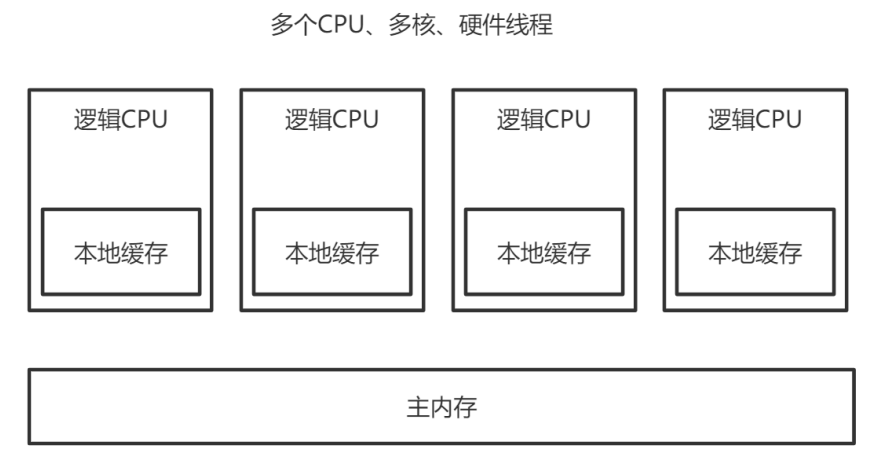
- 多CPU,每个CPU多核,每个核上面可能还有多个硬件线程,对于操作系统来讲,就相当于一个个的逻辑
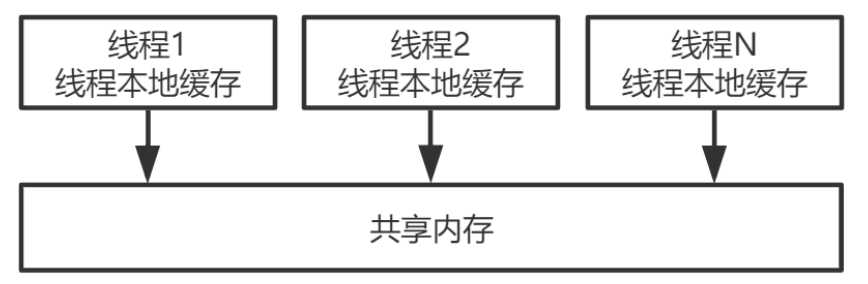
CPU。每个逻辑CPU都有自己的缓存,这些缓存和主内存之间不是完全同步的。 - 对应到Java里,就是JVM抽象内存模型,如下图所示:
2、重排序与内存可见性的关系
-
Store Buffer(存储缓冲区)的延迟写入是重排序的一种,称为内存重排序(Memory Ordering)。除此之外,还 有编译器和CPU的指令重排序。 -
重排序类型:
-
-
编译器重排序。
对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序。
-
-
-
CPU指令重排序。
在指令级别,让没有依赖关系的多条指令并行。
-
-
-
CPU内存重排序。
CPU有自己的缓存,指令的执行顺序和写入主内存的顺序不完全一致。
-
-
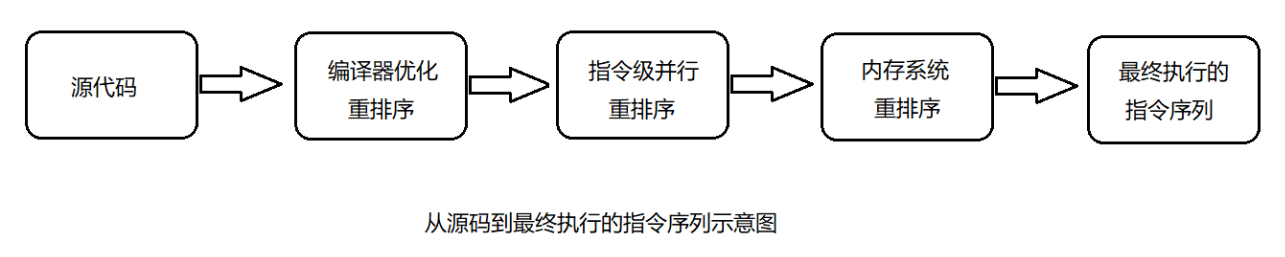
- 在三种重排序中,
第三类就是造成内存可见性问题的主因,如下案例:
// 线程1中
x=1;
a=y;
// 线程2中
y=1;
b=x;
- 假设X、Y是两个全局变量,初始的时候,X=0,Y=0。请问,这两个线程执行完毕之后,a、b的正确结果应该是什么?
- 很显然,线程1和线程2的执行先后顺序是不确定的,可能顺序执行,也可能交叉执行,最终正确的 结果可能是:
1. a=0,b=1
2. a=1,b=0
3. a=1,b=1
- 也就是不管谁先谁后,执行结果应该是这三种场景中的一种。但实际可能是a=0,b=0。
- 两个线程的指令都没有重排序,执行顺序就是代码的顺序,但仍然可能出现a=0,b=0。原因是
线程1先执行x=1,后执行a=Y,但此时x=1还在自己的Store Buffer(存储缓冲区)里面,没有及时写入主内存中。所以,线程2看到的x还是0。线程2的道理与此相同。 - 虽然线程1觉得自己是按代码顺序正常执行的,但在线程2看来,a=Y和X=1顺序却是颠倒的。指令没 有重排序,是写入内存的操作被延迟了,也就是内存被重排序了,这就造成内存可见性问题。
3、内存屏障
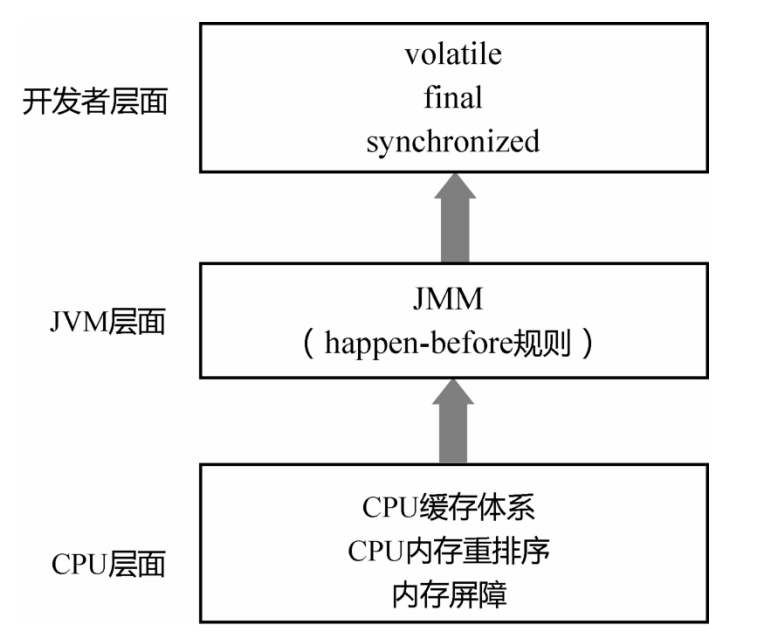
- 为了禁止
编译器重排序和CPU 重排序,在编译器和 CPU 层面都有对应的指令,也就是内存屏障 (Memory Barrier)。这也正是JMM和happen-before规则的底层实现原理。 - 编译器的内存屏障,只是为了告诉编译器不要对指令进行重排序。当编译完成之后,这种内存屏障就消失了,CPU并不会感知到编译器中内存屏障的存在。
- 而CPU的内存屏障是
CPU提供的指令,可以由开发者显示调用。 - 内存屏障是很底层的概念,对于 Java 开发者来说,一般用
volatile关键字就足够了。但从JDK 8开 始,Java在Unsafe类中提供了三个内存屏障函数,如下所示。
public final class Unsafe {
// ...
public native void loadFence();
public native void storeFence();
public native void fullFence();
// ...
}
- 在理论层面,可以把基本的CPU内存屏障分成四种:
- LoadLoad:禁止读和读的重排序。
- StoreStore:禁止写和写的重排序。
- LoadStore:禁止读和写的重排序。
- StoreLoad:禁止写和读的重排序。
- Unsafe中的方法:
- loadFence=LoadLoad+LoadStore
- storeFence=StoreStore+LoadStore
- fullFence=loadFence+storeFence+StoreLoad
4、as-if-serial语义
- 重排序的原则是什么?什么场景下可以重排序,什么场景下不能重排序呢?
- 单线程程序的重排序规则
- 无论什么语言,站在编译器和CPU的角度来说,不管怎么重排序,单线程程序的执行结果不能改变,这就是单线程程序的重排序规则。
- 即只要操作之间没有数据依赖性,编译器和CPU都可以任意重排序,因为执行结果不会改变,代码看起来就像是完全串行地一行行从头执行到尾,这也就是as-if-serial语义。
- 对于
单线程程序来说,编译器和CPU可能做了重排序,但开发者感知不到,也不存在内存可见性问题。
- 多线程程序的重排序规则
- 编译器和CPU的这一行为对于单线程程序没有影响,但对多线程程序却有影响。
- 对于多线程程序来说,线程之间的数据
依赖性太复杂,编译器和CPU没有办法完全理解这种依赖性、并据此做出最合理的优化。 - 编译器和CPU只能保证
每个线程的as-if-serial语义。 - 线程之间的数据依赖和相互影响,需要编译器和CPU的上层来确定。
- 上层要告知编译器和CPU在多线程场景下什么时候可以重排序,什么时候不能重排序。
5、happen-before是什么
使用happen-before描述两个操作之间的内存可见性。
- java内存模型(JMM)是一套规范,在多线程中,一方面,要让编译器和CPU可以灵活地重排序; 另一方面,要对开发者做一些承诺,明确告知开发者不需要感知什么样的重排序,需要感知什么样的重排序。然后,根据需要决定这种重排序对程序是否有影响。如果有影响,就需要开发者显示地通过
volatile、synchronized等线程同步机制来禁止重排序。 - 关于happen-before:
- 如果A
happen-before(在.. 之前)B,意味着A的执行结果必须对B可见,也就是保证线程间的内存可见性。A happen before B不代表A一定在B之前执行。因为,对于多线程程序而言,两个操作的执行顺序是不确定的。happen-before只确保如果A在B之前执行,则A的执行结果必须对B可见。定义了内存可见性的约束,也就定义了一系列重排序的约束。- 基于happen-before的这种描述方法,JMM对开发者做出了一系列承诺:
- 单线程中的每个操作,happen-before 对应该线程中任意后续操作(也就是 as-if-serial语义保证)。
- 对
volatile变量的写入,happen-before对应 后续对这个变量的读取。 - 对synchronized的解锁,happen-before对应后续对这个锁的加锁。
- JMM对编译器和CPU 来说,volatile 变量不能
重排序;非 volatile 变量可以任意重排序。
- 基于happen-before的这种描述方法,JMM对开发者做出了一系列承诺:
6 happen-before的传递性
除了这些基本的happen-before规则,happen-before还具有传递性,即若A happen-before B,B happen-before C,则A happen-before C。
- 如果一个变量不是volatile变量,当一个线程读取、一个线程写入时可能有问题。那岂不是说,在多线程程序中,我们要么加锁,要么必须把所有变量都声明为volatile变量?这显然不可能,而这就得归功于happen-before的传递性。
class A {
private int a = 0;
private volatile int c = 0;
public void set() {
a = 5; // 操作1
c = 1; // 操作2
}
public int get() {
int d = c; // 操作3
return a; // 操作4
}
}
- 假设线程A先调用了set,设置了a=5;之后线程B调用了get,返回值一定是a=5。为什么呢?
- 操作1和操作2是在同一个线程内存中执行的,操作1 happen-before 操作2,同理,操作3 happenbefore操作4。又因为c是volatile变量,对c的写入happen-before对c的读取,所以操作2 happenbefore操作3。利用happen-before的传递性,就得到:
- 操作1 happen-before 操作2 happen-before 操作3 happen-before操作4。
- 所以,操作1的结果,一定对操作4可见。
class A {
private int a = 0;
private int c = 0;
public synchronized void set() {
a = 5; // 操作1
c = 1; // 操作2
}
public synchronized int get() {
return a;
}
}
- 假设线程A先调用了set,设置了a=5;之后线程B调用了get,返回值也一定是a=5。
- 因为与
volatile一样,synchronized同样具有happen-before语义。展开上面的代码可得到类似于下 面的伪代码:
线程A:
加锁; // 操作1
a = 5; // 操作2
c = 1; // 操作3
解锁; // 操作4
线程B:
加锁; // 操作5
读取a; // 操作6
解锁; // 操作7
- 根据
synchronized的happen-before语义,操作4 happen-before 操作5,再结合传递性,最终就 会得到: 操作1 happen-before 操作2……happen-before 操作7。所以,a、c都不是volatile变量,但仍然有内存可见性。
2、volatile
1、64位写入的原子性(Half Write)
- 如,对于一个long型变量的赋值和取值操作而言,在多线程场景下,
线程A调用set(100),线程B调 用get(),在某些场景下,返回值可能不是100。
public class MyClass {
private long a = 0;
// 线程A调用set(100)
public void set(long a) {
this.a = a;
}
// 线程B调用get(),返回值一定是100吗?
public long get() {
return this.a;
}
}
- 因为JVM的规范并没有要求64位的long或者double的写入是原子的。在32位的机器上,一个64位变量的写入可能被拆分成两个32位的写操作来执行。这样一来,读取的线程就可能读到“一半的值”。解决 办法也很简单,在long前面加上volatile关键字。
2、重排序:DCL问题
- 单例模式的线程安全的写法不止一种,常用写法为
DCL(Double Checking Locking),如下所示:
public class Singleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
// 此处代码有问题
instance = new Singleton();
}
}
}
return instance;
}
}
- 上述的 instance = new Singleton(); 代码有问题:其底层会分为
三个操作:- 分配一块内存。
- 在内存上初始化成员变量。
- 把instance引用指向内存。
- 在这三个操作中,操作2和操作3
可能重排序,即先把instance指向内存,再初始化成员变量,因为二者并没有先后的依赖关系。此时,另外一个线程可能拿到一个未完全初始化的对象。这时,直接访问里面的成员变量,就可能出错。这就是典型的“构造方法溢出”问题。 - 解决办法也很简单,就是为instance变量加上
volatile修饰。 - volatile的三重功效:
64位写入的原子性、内存可见性和禁止重排序。
3、volatile实现原理
- 由于不同的CPU架构的缓存体系不一样,重排序的策略不一样,所提供的内存屏障指令也就有差异。
- 这里只探讨为了实现volatile关键字的语义的一种参考做法:
- 在volatile写操作的前面插入一个StoreStore屏障。保证volatile
写操作不会和之前的写操作重排序。 - 在volatile写操作的后面插入一个StoreLoad屏障。保证volatile
写操作不会和之后的读操作重排序。 - 在volatile读操作的后面插入一个LoadLoad屏障+LoadStore屏障。保证volatile
读操作不会和之后的读操作、写操作重排序。
- 在volatile写操作的前面插入一个StoreStore屏障。保证volatile
- 具体到x86平台上,其实不会有LoadLoad、LoadStore和StoreStore重排序,只有StoreLoad一种 重排序(内存屏障),也就是只需要在volatile写操作后面加上StoreLoad屏障。
4、JSR-133对volatile语义的增强
- 在JSR -133之前的旧内存模型中,一个64位long / double型变量的读/ 写操作可以被拆分为两个32位 的读/写操作来执行。从JSR -133内存模型开始 (即从JDK5开始),仅仅只允许把一个64位long/ double 型变量的写操作拆分为两个32位的写操作来执行,任意的读操作在JSR -133中都必须具有原子性(即 任意读操作必须要在单个读事务中执行)。
- 这也正体现了Java对
happen-before规则的严格遵守。
3、final
1、构造方法溢出问题
- 考虑下面的代码:
public class MyClass {
private int num1;
private int num2;
private static MyClass myClass;
public MyClass() {
num1 = 1;
num2 = 2;
}
/**
* 线程A先执行write()
*/
public static void write() {
myClass = new MyClass();
}
/**
* 线程B接着执行write()
*/
public static void read() {
if (myClass != null) {
int num3 = myClass.num1;
int num4 = myClass.num2;
}
}
}
- num3和num4的值是否一定是1和2?
- num3、num4不见得一定等于1,2。和DCL的例子类似,也就是构造方法溢出问题。
- myClass = new MyClass()这行代码,分解成三个操作:
- 分配一块内存;
- 在内存上初始化i=1,j=2;
- 把myClass指向这块内存。
- 操作2和操作3可能重排序,因此线程B可能看到未正确初始化的值。对于构造方法溢出,就是一个对象的构造并不是
“原子的”,当一个线程正在构造对象时,另外一个线程却可以读到未构造好的“一半对象”。
2、final的happen-before语义
- 要解决这个问题,不止有一种办法。
- 办法1:给num1,num2加上volatile关键字。
- 办法2:为read/write方法都加上synchronized关键字。
- 如果num1,num2只需要初始化一次,还可以使用final关键字。
- 之所以能解决问题,是因为同
volatile一样,final关键字也有相应的happen-before语义:- 对final域的写(构造方法内部),happen-before于后续对final域所在对象的读。
- 对final域所在对象的读,happen-before于后续对final域的读。
- 通过这种happen-before语义的限定,保证了final域的赋值,一定在构造方法之前完成,不会出现另外一个线程读取到了对象,但对象里面的变量却还没有初始化的情形,避免出现构造方法溢出的问题。
happen-before规则总结
- 单线程中的每个操作,happen-before于该线程中任意后续操作。
- 对volatile变量的写,happen-before于后续对这个变量的读(写的结果,对读可见,写在读之前完成)。
- 对synchronized的解锁,happen-before于后续对这个锁的加锁。
- 对final变量的写,happen-before于final域对象的读,happen-before于后续对final变量的读。
- 四个基本规则再加上happen-before的传递性,就构成JMM对开发者的整个承诺。在这个承诺以外的部分,程序都可能被重排序,都需要开发者小心地处理内存可见性问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix