一文学会线程池、任务调度的使用
一文学会线程池、任务调度的使用
本文主要讲解线程池以及定时任务的使用,以及在分布式环境下、JUC线程池和Spring线程池的弊端。

起因:
分布式换环境下的定时任务问题
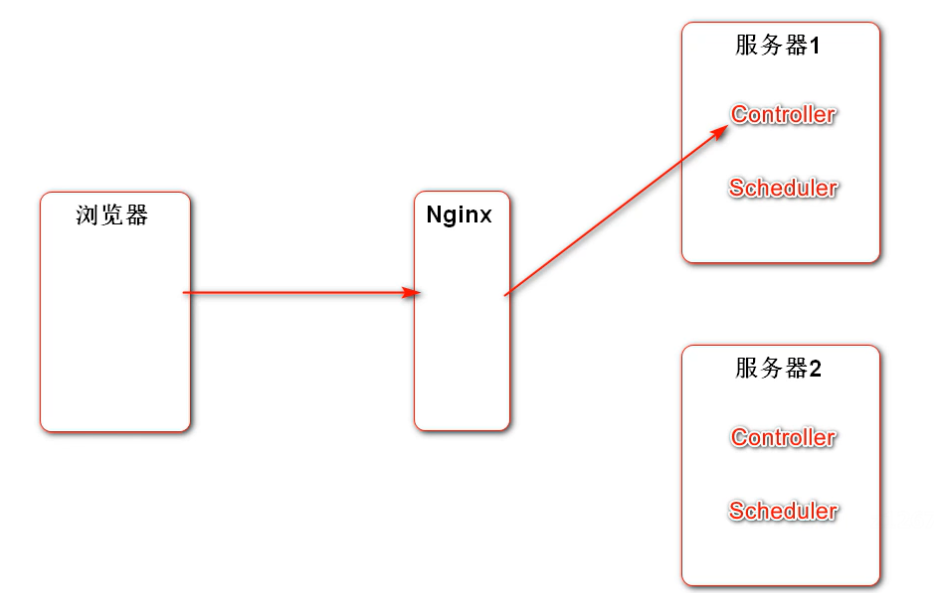
- ❓ 有没有可能会出现这个问题,使用
JUC或者Spring线程池的话,他们只能配置间隔多长时间执行一次,因为是集群的缘故,他们重复执行,这样有意义吗?
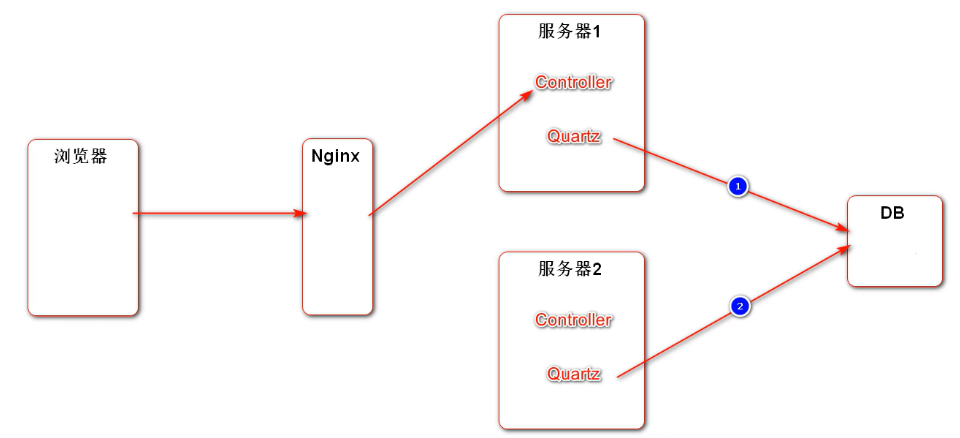
- ❓ 而Quartz定时任务驱动的参数存到数据库里,通过排队加锁等这样的机制实现共享(也就是同一时间,只有一台服务器执行)
1、JUC线程池
ExecutorService
-
❗️ 使用步骤:
Executors.newFixedThreadPool(5);初始化线程池线程数量并构造出ExecutorService- 通过Runnable接口,构造需要执行的内容
- 通过
ExecutorService的submit启动任务
-
❗️ 具体代码:
-
private ExecutorService executorService = Executors.newFixedThreadPool(5); // 初始化线程池线程数量 public void testExecutorService() { // 线程任务 Runnable task = new Runnable() { @Override public void run() { log.debug("HELLO ExecutorService"); } }; for (int i = 0; i < 10; i++) { executorService.submit(task); // 多次执行 } sleep(10); // 防止线程终止 }
ScheduledExecutorService
可执行定时任务的线程池
- ❗️ 使用步骤:
Executors.newScheduledThreadPool(5)初始化线程池线程数量并构造出ScheduledExecutorService- 通过Runnable接口,构造需要执行的内容
- 通过
ScheduledExecutorService的scheduleAtFixedRate启动任务
- ❗️ 具体代码
scheduledExecutorService还有需要重载的方法:
/**
* JDK可执行定时任务的线程池
*/
private ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
public void testScheduleExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
log.debug("HELLO ScheduleExecutorService");
}
};
// 需要执行的任务,第一次延迟多久执行,每个多久执行一次,时间单位
scheduledExecutorService.scheduleAtFixedRate(task, 1, 1, TimeUnit.SECONDS);
sleep(10);
}
2、Spring线程池
注意:
- Spring线程池的使用需要创建配置文件开启任务调度才可使用,需要初始化
ThreadPoolTaskScheduler(线程池任务调度器) 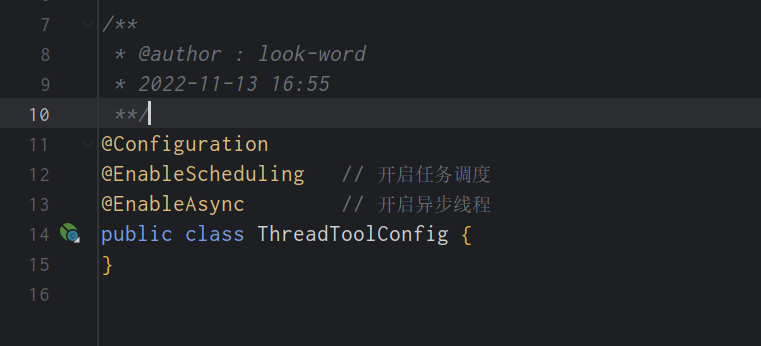
ThreadPoolTaskExecutor
- ❗️ 使用步骤:
application.yaml配置线程池属性 可通过TaskExecutionProperties查看更为详细的配置信息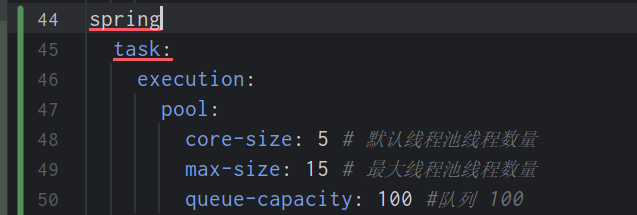
- 注入
ThreadPoolTaskExecutor - 通过
Runnable接口,构造需要执行的内容
- ❗️ 具体代码
@Resource
private ThreadPoolTaskExecutor taskExecutor;
public void testThreadPoolTaskExecutor() {
// 需要执行的任务
Runnable task = new Runnable() {
@Override
public void run() {
log.debug("HELLO ThreadPoolTaskExecutor");
}
};
for (int i = 0; i < 10; i++) {
taskExecutor.submit(task);
}
sleep(10);
}
ThreadPoolTaskScheduler
可执行定时任务的线程池
-
❗️ 使用步骤:
application.yaml配置调度属性,可通过TaskSchedulingProperties查看更为详细的配置信息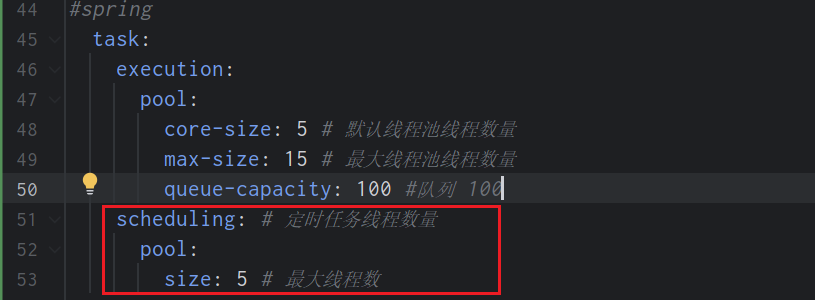
- 容器中注入
ThreadPoolTaskScheduler - 通过
Runnable接口,构造需要执行的内容
-
❗️ 具体代码
-
// Spring定时任务线程池 @Resource private ThreadPoolTaskScheduler taskScheduler; @Test public void testThreadPoolTaskScheduler() { Runnable task = new Runnable() { @Override public void run() { log.debug("HELLO ThreadPoolTaskScheduler"); } }; // 需要执行的任务,隔多久执行一次 taskScheduler.scheduleAtFixedRate(task, 2000); sleep(10); }
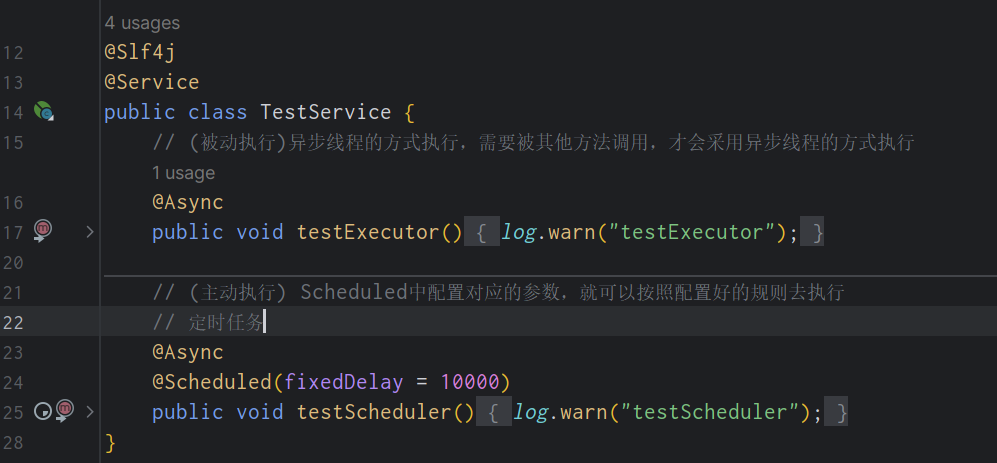
简化使用
你以为不觉得这样的配置过于繁杂了吗,Spring也想到了这点,使用注解的方式来简化使用。
3、Quratz
配置
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
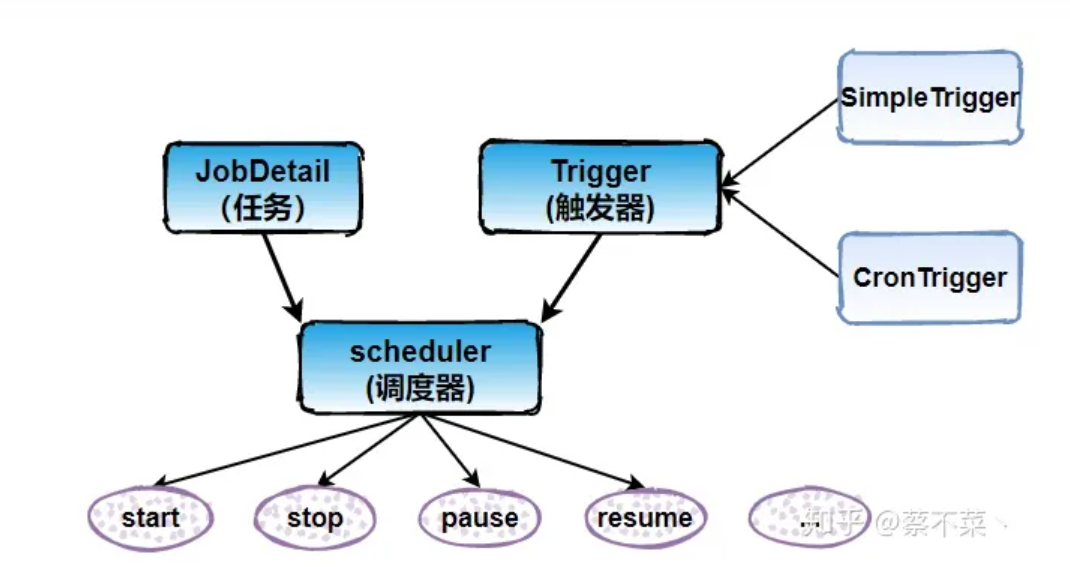
核心概念
-
任务 Job
- 我们想要调度的任务都必须实现
org.quartz.job接口,然后实现接口中定义的execute()方法即可,类似于TimerTask
- 我们想要调度的任务都必须实现
-
触发器 Trigger
- Trigger 作为执行任务的调度器。我们如果想要凌晨1点执行备份数据的任务,那么 Trigger 就会设置凌晨1点执行该任务。
- 其中 Trigger 又分为
SimpleTrigger和CronTrigger两种
-
调度器 Scheduler
Scheduler为任务的调度器,它会将任务Job及触发器Trigger整合起来,负责基于 Trigger 设定的时间来执行 Job
使用
使用步骤:
- 定义
Job - 实例化
JobDetail和SimpleTigger - (需要持久化到数据库,就得配置)
- 定义Job 也就是需要执行的内容
@Slf4j
public class AlphaJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
log.warn(Thread.currentThread().getName()+": execute a quartz job.");
}
}
- 实例化
JobDetail和SimpleTigger
/**
* 启动项目,将配置信息初始化到数据库中,之后直接访问数据库,
* 数据库可以被每个实例所获取,从而实现了分布式定时任务
*
* @author : look-word
* 2022-11-13 20:11
**/
@Configuration
public class QuartzConfig {
// 配置JobDetail(任务)
@Bean
public JobDetailFactoryBean alphaJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(AlphaJob.class); // 需要被执行的任务
factoryBean.setName("alphaJob");
factoryBean.setGroup("alphaJobGroup");
factoryBean.setDurability(true); // 是否持久化到数据库
factoryBean.setRequestsRecovery(true); // 当出现问题,是否可恢复
return factoryBean;
}
// 配置 Trigger(触发器)
@Bean
public SimpleTriggerFactoryBean alphaTrigger(JobDetail alphaJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(alphaJobDetail);
factoryBean.setName("alphaTrigger");
factoryBean.setGroup("alphaTriggerGroup");
factoryBean.setRepeatInterval(3000); // 间隔多久执行
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}
}
配置好上面信息,启动项目,我们的Quratz就是执行了。
如若想要实现持久化到数据,配置下面步骤。
持久化
为什么持久化到数据中
- 没有配置的都是存储在内存里面的。 当程序突然被中断时,如断电,内存超出时,很有可能造成任务的丢失。 可以将调度信息存储到数据库里面,进行持久化,当程序被中断后,再次启动,仍然会保留中断之前的数据,继续执行,而并不是重新开始。
创建 持久化表
持久化到数据库的配置
# quartz 分布式定时任务
spring:
quartz:
job-store-type: jdbc
scheduler-name: communityScheduler
properties:
org:
quartz:
scheduler:
instanceId: AUTO #调度器id自动生成
jobStore:
class: org.quartz.impl.jdbcjobstore.JobStoreTX # 完成Job持久化配置的类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate # 存储使用的JDBC
isClustered: true # 是否以集群的方式
threadPool:
class: org.quartz.simpl.SimpleThreadPool # 使用的线程类
threadCount: 5 # 线程池的数量
- 然后再次启动项目,我们对于
Quartz的配置,就会持久化到数据库中。
当然,我们的任务持久到数据库中,假如不需要了呢,不可能一个个的去删除吧,那么
Quratz也为我们提供了具体的方法。
- JobKey(配置的任务名称,配置的组名称)
@Resource
private Scheduler scheduler;
@Test
public void testDeleteJob() throws SchedulerException {
System.out.println(scheduler.deleteJob(new JobKey("alphaJob", "alphaJobGroup")));
}
执行后,会发现持久化到数据库中的信息,被删除了。
分类:
Springboot
, 常见问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix