Scrapy代理和中间件
去重
内置去重
scrapy默认会对url进行去重,使用的去重类是from scrapy.dupefilter import RFPDupeFilter,看一下源码流程
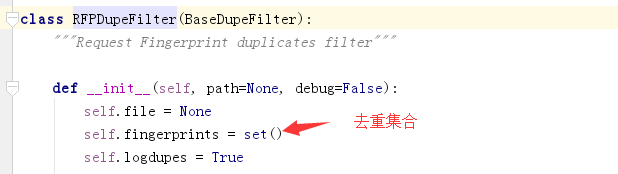

因为'http://www.baidu.com?k1=1&k2=2'和'http://www.baidu.com?k2=2&k1=1'应该是同一个请求,但是如果单纯地把url或者url的md5值放到集合中肯定是有问题的,我们使用内置的request_fingerprint方法就可以解决这个问题
自定义去重
dupfilter.py
import scrapy
from scrapy.dupefilter import BaseDupeFilter
from scrapy.utils.request import request_fingerprint
class MyFilter(BaseDupeFilter):
def __init__(self):
self.visited = set()
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
fd = request_fingerprint(request=request)
if fd not in self.visited:
return True
self.visited.add(fd)
def open(self): # can return deferred
print('starting')
def close(self, reason): # can return a deferred
print('ending')
def log(self, request, spider): # log that a request has been filtered
pass
settings.py
DUPEFILTER_CLASS = 'nj.dupfilter.MyFilter'
深度
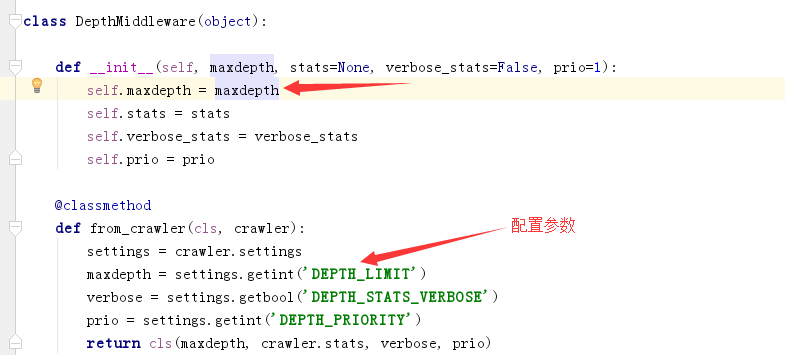
scrapy的深度控制是通过一个爬虫中间件来控制的from scrapy.spidermiddlewares.depth import DepthMiddleware,如果请求的深度不符合设定,那么请求就不会发给引擎,也就到不了调度器,看一下源码

下载中间件
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.http import HtmlResponse
from scrapy.http import Request
class Md1(object):
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request 继续后续中间件去下载
# - or return a Response object 停止process_request的执行,开始执行process_response
# - or return a Request object 停止中间件的执行,将Request重新调度器
# - or raise IgnoreRequest: process_exception() methods of installed downloader middleware will be called 停止process_request的执行,开始执行process_exception(从最后的中间件开始)
print('m1.process_request',request)
# 1. 返回Response,在这个返回response,那么就不会真正去下载,而且process_response从下一个中间件开始,这一点和django1.9之前的版本类似
# import requests
# result = requests.get(request.url)
# return HtmlResponse(url=request.url, status=200, headers=None, body=result.content)
# 2. 返回Request, 返回request表示你让我发的这个请求我不想发,我抛出一个请求放到调度器,这时候起点就又到了调度器了,中间件又要从头开始走了
# return Request('https://www.cnblogs.com/longyunfeigu/p/9485291.html')
# 3. 抛出异常, 请求就不再往下走了,到此为止
# from scrapy.exceptions import IgnoreRequest
# raise IgnoreRequest
# 4. 对请求进行加工(*),这是经常使用的功能
# request.headers['user-agent'] = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
raise AttributeError('hhh')
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object 转交给其他中间件process_response
# - return a Request object 按道理说,如果请求不合适,想要重新抛出一个请求应该在process_request做,但是这里也同样支持,这时候起点就又到了调度器
# - or raise IgnoreRequest 调用Request.errback
print('m1.process_response',request,response)
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
print('m1.process_exception')
class Md2(object):
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print('md2.process_request',request)
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
print('m2.process_response', request,response)
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception 继续交给后续中间件处理异常
# - return a Response object: stops process_exception() chain 停止后续process_exception方法, 从最后一层中间件开始执行process_response
# - return a Request object: stops process_exception() chain 停止中间件,request将会被重新调用下载
# from scrapy.exceptions import IgnoreRequest
# # 异常被忽略,此时process_response 也不会被执行了
# raise IgnoreRequest
# print('m2.process_exception')
# return HtmlResponse(url=request.url, status=200, headers=None, body=b'xx')
内置代理
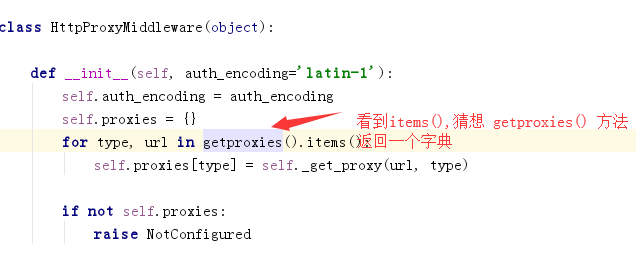




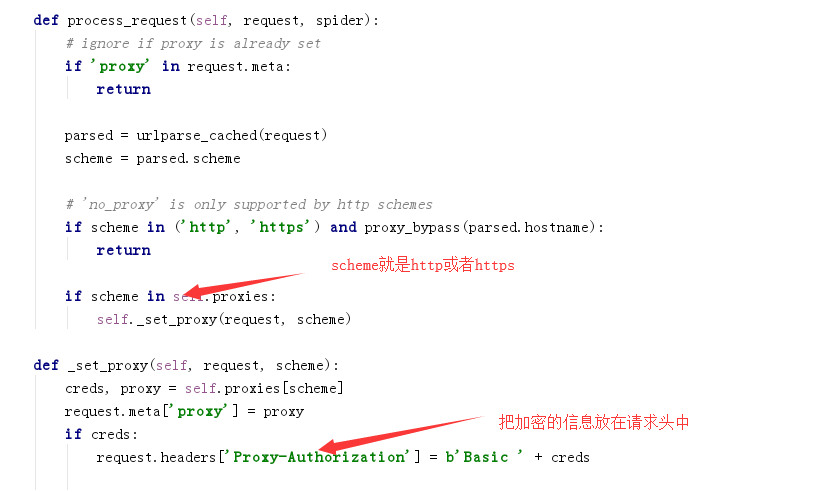
通过源码可以看出几点:
- os.environ当作一个字典设置代理信息,但是格式需要注意,而且os.environ得到的是当前进程的环境变量设置的值,其他进程是拿不到这个进程在os.environ设置的值的
- 在request的meta里也能定义proxy,而且通过源码知道优先级比os.environ更高
自定义代理
根据源码修改
import base64
import random
from six.moves.urllib.parse import unquote
try:
from urllib2 import _parse_proxy
except ImportError:
from urllib.request import _parse_proxy
from six.moves.urllib.parse import urlunparse
from scrapy.utils.python import to_bytes
class XdbProxyMiddleware(object):
def _basic_auth_header(self, username, password):
user_pass = to_bytes(
'%s:%s' % (unquote(username), unquote(password)),
encoding='latin-1')
return base64.b64encode(user_pass).strip()
def process_request(self, request, spider):
PROXIES = [
"http://root:123456@192.168.11.11:9999/",
"http://root:123456@192.168.11.12:9999/",
"http://root:123456@192.168.11.13:9999/",
"http://root:123456@192.168.11.14:9999/",
"http://root:123456@192.168.11.15:9999/",
"http://root:123456@192.168.11.16:9999/",
]
url = random.choice(PROXIES)
orig_type = ""
proxy_type, user, password, hostport = _parse_proxy(url)
proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
if user:
creds = self._basic_auth_header(user, password)
else:
creds = None
request.meta['proxy'] = proxy_url
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
或者
from scrapy.utils.python import to_bytes
class DdbProxyMiddleware(object):
def process_request(self, request, spider):
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': 'root@123456'},
{'ip_port': '120.198.243.22:80', 'user_pass': 'root@123456'},
{'ip_port': '111.8.60.9:8123', 'user_pass': 'root@123456'},
{'ip_port': '101.71.27.120:80', 'user_pass': 'root@123456'},
{'ip_port': '122.96.59.104:80', 'user_pass': 'root@123456'},
{'ip_port': '122.224.249.122:8088', 'user_pass': 'root@123456'},
]
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.b64encode(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
else:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
爬虫中间件
class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
"""
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
"""
pass
def process_spider_output(self,response, result, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
"""
return result
def process_spider_exception(self,response, exception, spider):
"""
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
"""
return None
def process_start_requests(self,start_requests, spider):
"""
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
"""
return start_requests
自定义命令
单个爬虫
from scrapy.cmdline import execute
if __name__ == '__main__':
execute(["scrapy","crawl", "cnblog","--nolog"])
单进程多个爬虫同时启动
- 在spiders同级创建任意目录,如:commands
- 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start() - 在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
- 在项目目录执行命令:scrapy crawlall

